Audio Signal Processing for AI Voice Assistants: Key Methods
JUN 27, 2025 |
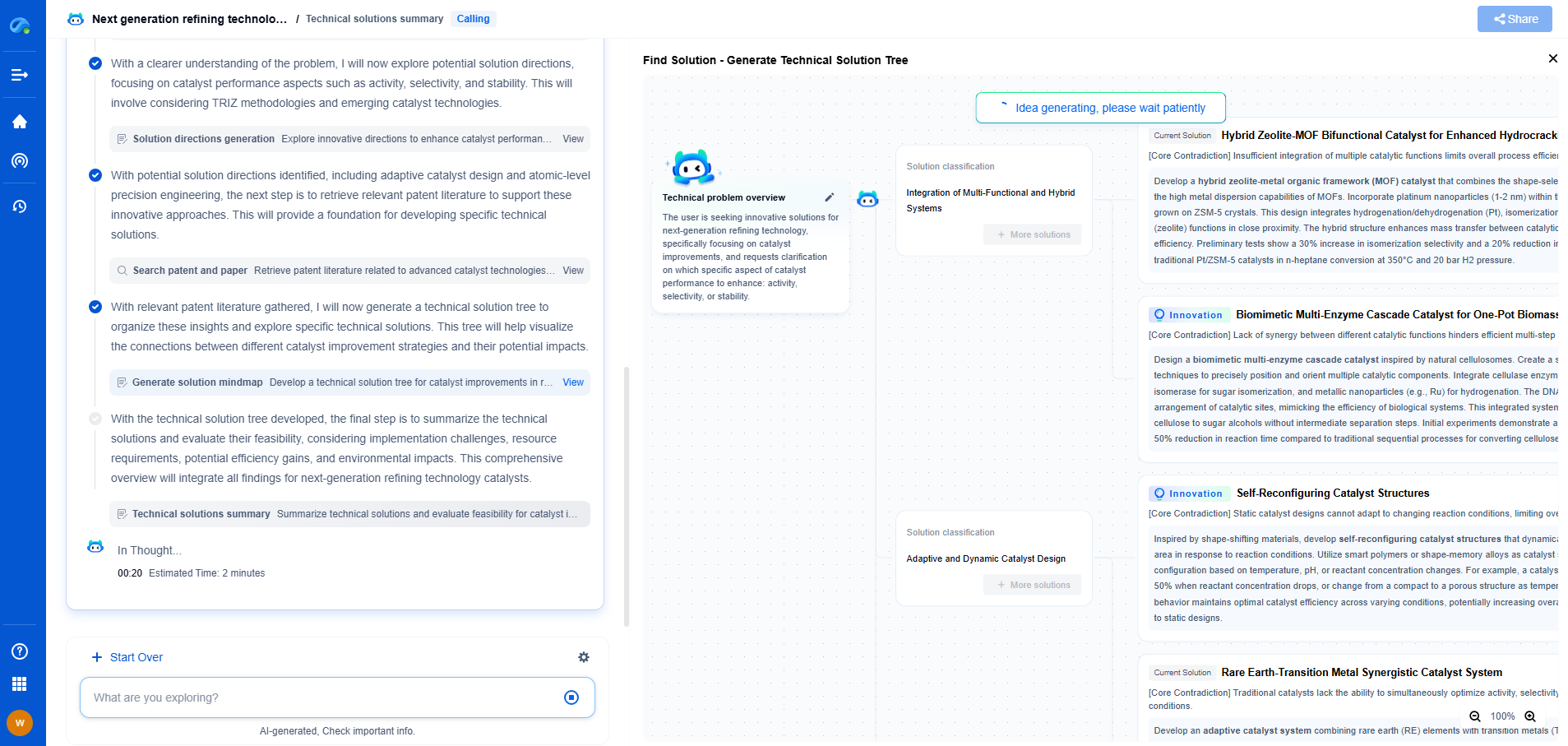
Understanding Audio Signal Processing
The first step in audio signal processing is to comprehend the nature of sound signals. Sound is an analog signal, and it needs to be converted into a digital format for processing. This involves sampling the signal at discrete intervals, quantizing the sampled values into a finite range, and encoding them into digital data. This conversion is fundamental for AI voice assistants to interpret and process audio inputs efficiently.
Feature Extraction
Once the audio signal is digitized, the next step is feature extraction. This process involves identifying and isolating relevant attributes of the audio signal that are critical for further analysis. Techniques like Mel-Frequency Cepstral Coefficients (MFCCs), Linear Predictive Coding (LPC), and spectrogram analysis are commonly used. These methods help in extracting features that encapsulate the essence of the audio signal, such as pitch, tempo, and timbre, which are essential for accurate speech recognition.
Speech Recognition
Speech recognition is the heart of AI voice assistants. This technology enables devices to understand and interpret human speech. The process starts with the digital audio signal, which is analyzed to detect phonemes—the smallest sound units in speech. Advanced algorithms, often powered by deep learning models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, are employed to decode these phonemes into words and sentences. This transformation is intricate, as it involves understanding context, accents, and nuances of human speech.
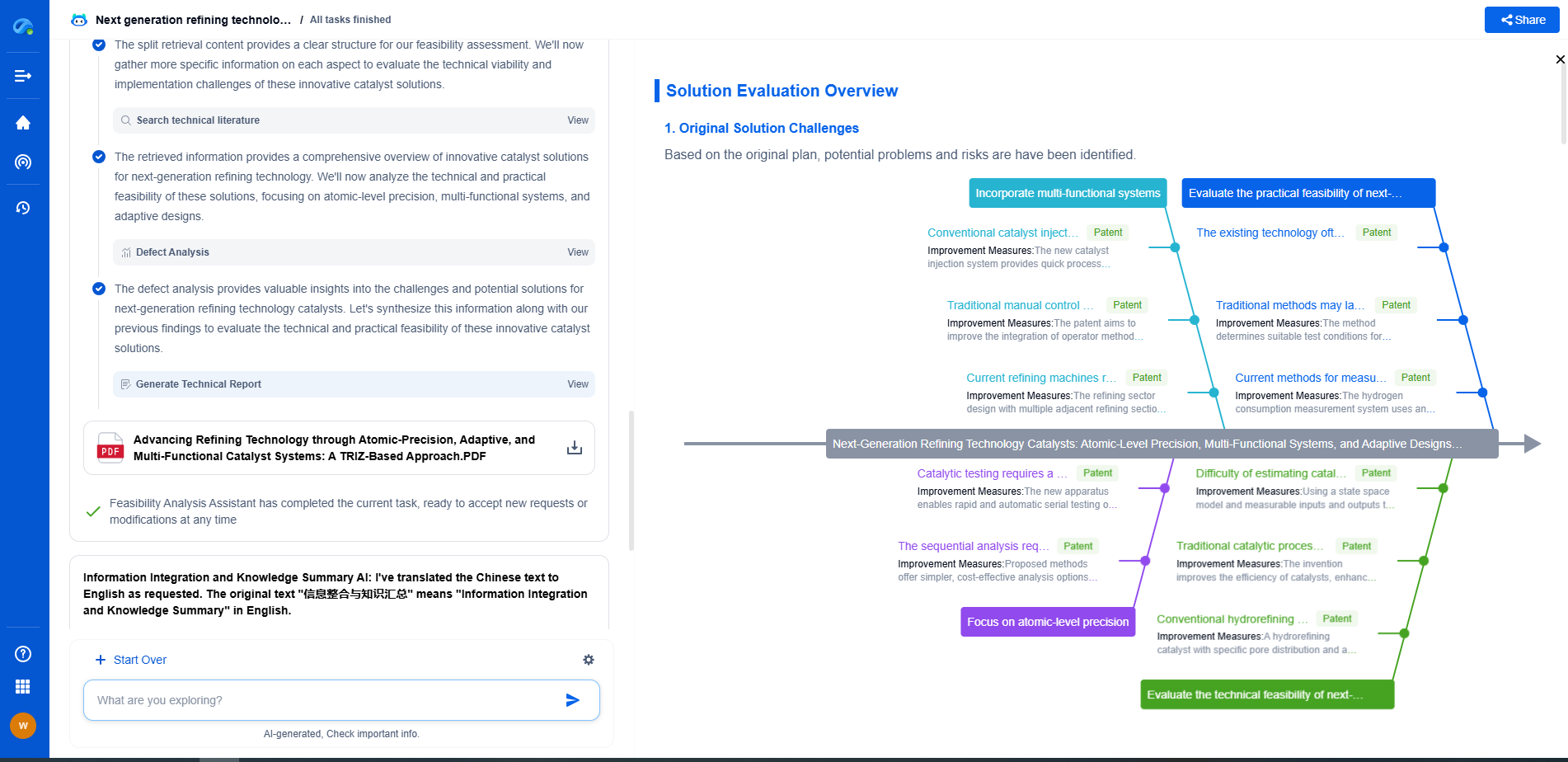
Noise Reduction and Echo Cancellation
In real-world applications, audio signals are often contaminated with background noise and echoes. Noise reduction techniques are employed to enhance the clarity of the audio input. Common methods include spectral subtraction, Wiener filtering, and beamforming. Echo cancellation, on the other hand, is crucial for removing echoes that can interfere with the signal quality, particularly in environments where the voice assistant is expected to perform reliably.
Natural Language Processing (NLP)
Once the speech recognition engine transcribes the speech into text, natural language processing comes into play. NLP algorithms analyze the text to understand the intent behind the user's command. These algorithms are designed to interpret human language, taking into account syntax, semantics, and context. Through NLP, voice assistants can perform tasks like answering queries, setting reminders, and controlling smart devices.
Emotion Detection and Response
A sophisticated dimension of audio signal processing is emotion detection. Modern AI voice assistants are being designed to discern emotional cues from a user's voice, enabling a more empathetic interaction. Techniques such as prosody analysis, which examines the rhythm, stress, and intonation of speech, are employed to detect emotions. This capability adds a layer of personalization, making interactions more engaging and user-friendly.
Integration with Machine Learning
Machine learning plays a pivotal role in refining and enhancing audio signal processing. By training models on vast datasets, AI voice assistants can continuously learn and adapt to users' speech patterns and preferences. This integration allows for improved accuracy in speech recognition and better contextual understanding, making the assistants more intuitive and responsive over time.
Future Directions
The ongoing advancements in audio signal processing are paving the way for more sophisticated AI voice assistants. Future innovations might include more nuanced emotion recognition, support for additional languages and dialects, and enhanced capabilities in understanding complex commands. As technology evolves, AI voice assistants are expected to become even more integral to our daily lives, offering seamless and intelligent interactions.
In conclusion, audio signal processing is a cornerstone of AI voice assistant technology, leveraging a combination of digital signal processing, machine learning, and natural language processing to create systems that understand and respond to human speech with remarkable precision. As research in this field progresses, we can anticipate even greater advancements that will continue to revolutionize the way we interact with technology.
Accelerate Electronic Circuit Innovation with AI-Powered Insights from Patsnap Eureka
The world of electronic circuits is evolving faster than ever—from high-speed analog signal processing to digital modulation systems, PLLs, oscillators, and cutting-edge power management ICs. For R&D engineers, IP professionals, and strategic decision-makers in this space, staying ahead of the curve means navigating a massive and rapidly growing landscape of patents, technical literature, and competitor moves.
Patsnap Eureka, our intelligent AI assistant built for R&D professionals in high-tech sectors, empowers you with real-time expert-level analysis, technology roadmap exploration, and strategic mapping of core patents—all within a seamless, user-friendly interface.
🚀 Experience the next level of innovation intelligence. Try Patsnap Eureka today and discover how AI can power your breakthroughs in electronic circuit design and strategy. Book a free trial or schedule a personalized demo now.