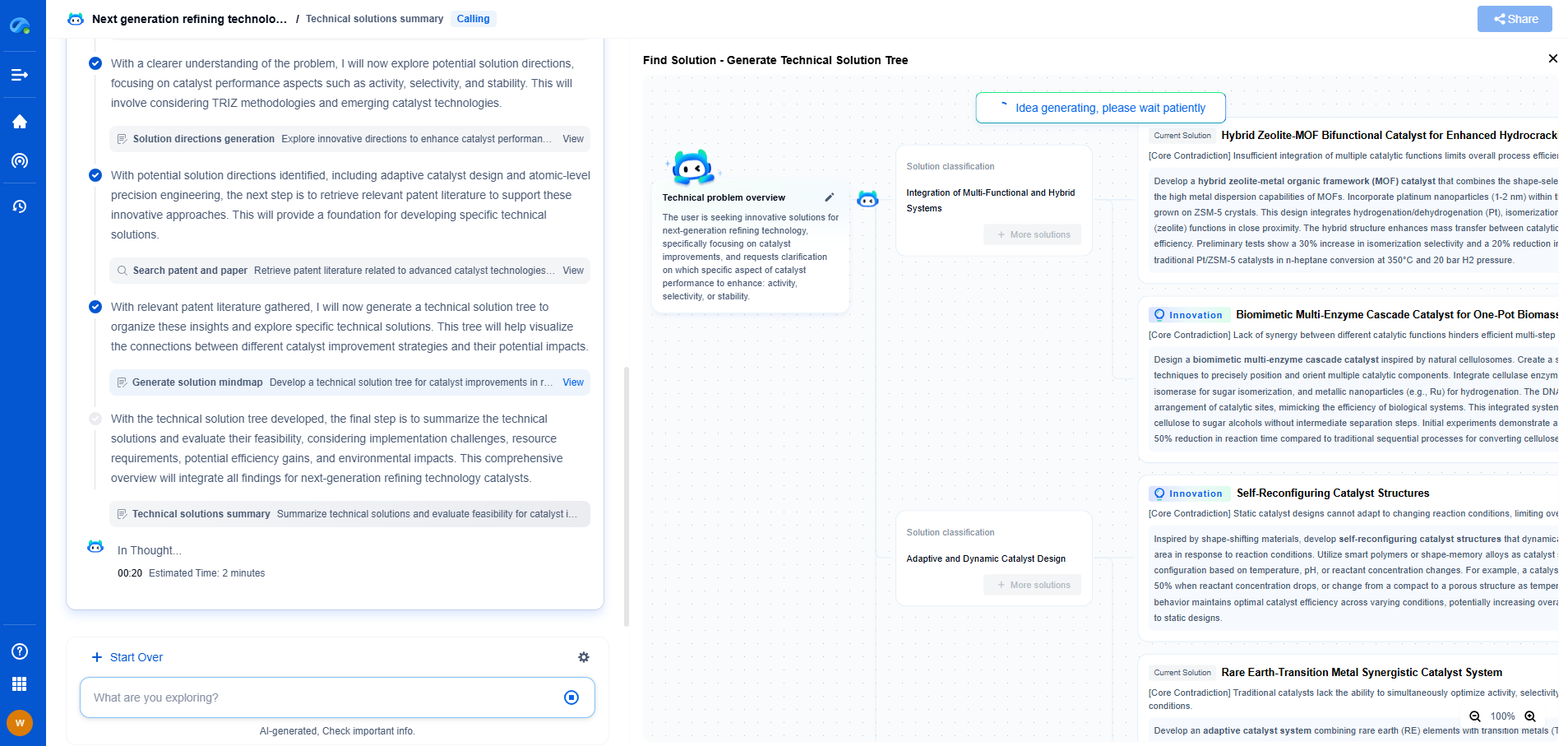
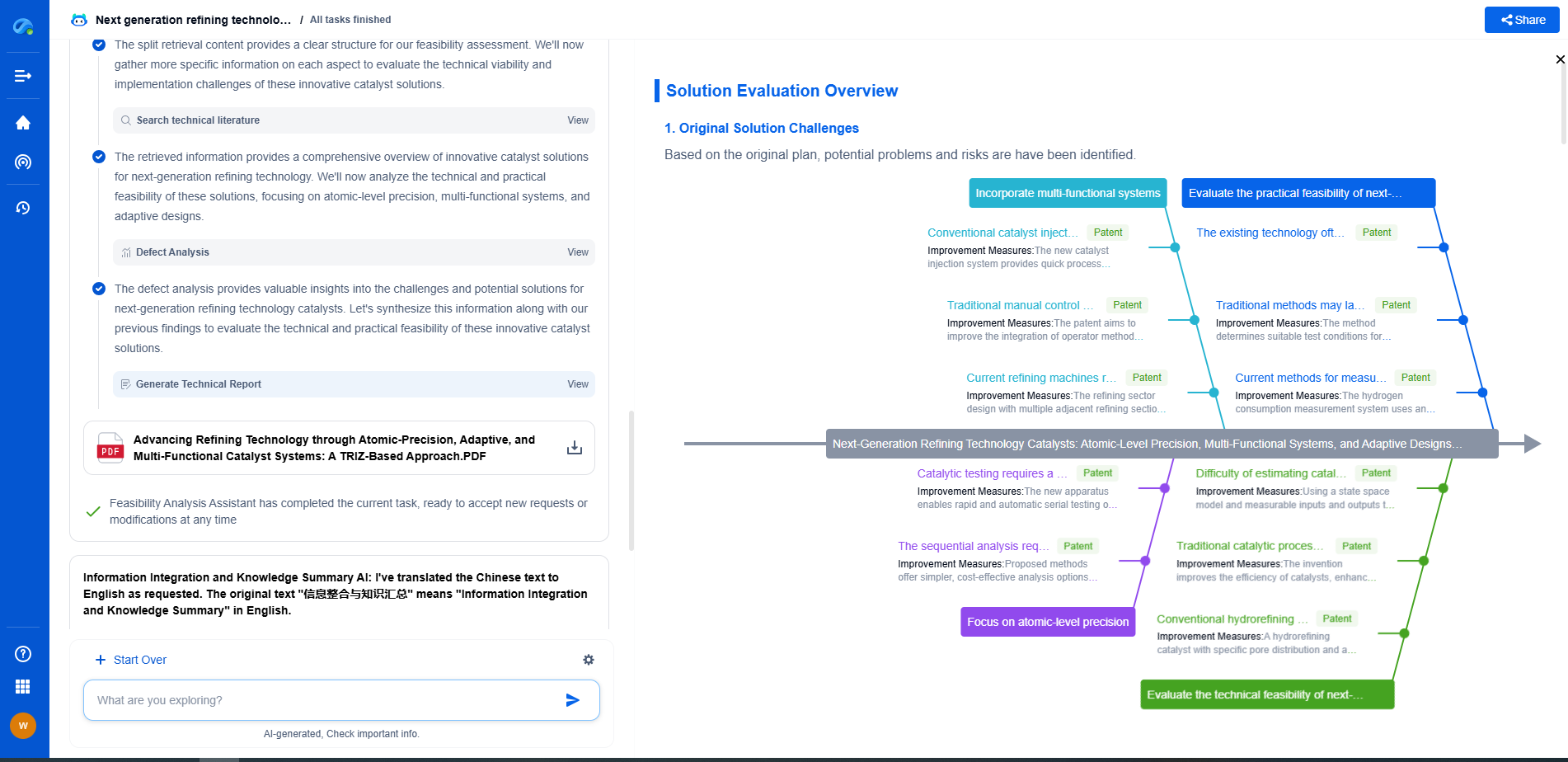
How to Design Scalable ML Pipelines for Grid Data?
JUN 26, 2025 |
Understanding Grid Data
Grid data refers to spatial data that is organized into a structured grid format. Each cell in this grid holds a data point, often representing physical phenomena like temperature, wind speeds, or other environmental variables. The inherent spatial nature of grid data poses unique challenges and opportunities for ML models to learn and predict patterns effectively.
Key Challenges in Handling Grid Data
1. Volume and Velocity: Grid data can be vast, especially if it is collected in real-time from multiple sources. Managing this high volume and velocity requires robust data ingestion and processing capabilities.
2. Spatial Correlation: Data points in a grid are often spatially correlated. This spatial correlation must be effectively captured by the ML model to ensure accurate predictions.
3. Data Quality and Consistency: Ensuring consistent and high-quality data across large grids is a challenging task. Inconsistent data can lead to unreliable model outputs.
Designing Scalable ML Pipelines
1. Data Ingestion and Preprocessing
The first step in designing a scalable ML pipeline is efficient data ingestion. Using distributed systems like Apache Kafka or AWS Kinesis can handle real-time data streams effectively. Once ingested, preprocessing involves cleaning the data, handling missing values, and transforming it into a suitable format for analysis. Employing parallel processing frameworks like Apache Spark can significantly speed up this stage.
2. Feature Engineering for Grid Data
Feature engineering is crucial in enhancing model performance. For grid data, this might involve deriving features that capture spatial relationships, such as distance-based features or aggregating data over specific zones. Leveraging geospatial libraries can facilitate the extraction of meaningful features from grid data.
3. Model Selection and Training
Choosing the right model architecture is vital. For grid data, convolutional neural networks (CNNs) are often preferred due to their ability to capture spatial hierarchies effectively. However, depending on the problem, recurrent neural networks (RNNs) or even transformer models might be more suitable. Training these models in a distributed manner using frameworks like TensorFlow or PyTorch can optimize resource use and reduce training times.
4. Scaling and Deployment
Once the model is trained, deploying it in a scalable manner is crucial for handling real-time data. Containerization technologies like Docker and orchestration tools like Kubernetes can ensure that the application scales seamlessly with demand. Implementing continuous integration and continuous deployment (CI/CD) pipelines can facilitate automated deployments and updates.
5. Monitoring and Maintenance
After deployment, continuous monitoring is essential to maintain the model’s performance. Tools like Prometheus or Grafana can be used to track model metrics and ensure that the system is functioning as expected. Regular maintenance, including retraining the model with new data and updating the pipeline to fix any issues, ensures long-term scalability and reliability.
Leveraging Cloud Solutions
Leveraging cloud platforms such as AWS, Google Cloud, or Azure can provide the necessary infrastructure to handle scalable ML pipelines. These platforms offer services that can manage data storage, processing, and machine learning, allowing teams to focus on building robust models without worrying about infrastructure limitations.
Conclusion
Designing scalable ML pipelines for grid data involves understanding the unique challenges posed by grid formats and employing the right tools and techniques to address them. By focusing on efficient data ingestion, effective feature engineering, choosing the right machine learning models, and leveraging cloud solutions, businesses can unlock the full potential of grid data for insightful predictions and informed decision-making. As technologies continue to evolve, staying abreast of the latest advancements will further enhance the scalability and efficiency of these pipelines.
Stay Ahead in Power Systems Innovation
From intelligent microgrids and energy storage integration to dynamic load balancing and DC-DC converter optimization, the power supply systems domain is rapidly evolving to meet the demands of electrification, decarbonization, and energy resilience.
In such a high-stakes environment, how can your R&D and patent strategy keep up?
Patsnap Eureka, our intelligent AI assistant built for R&D professionals in high-tech sectors, empowers you with real-time expert-level analysis, technology roadmap exploration, and strategic mapping of core patents—all within a seamless, user-friendly interface.
👉 Experience how Patsnap Eureka can supercharge your workflow in power systems R&D and IP analysis. Request a live demo or start your trial today.