How to Label SCADA Data for Smart Grid AI Applications
JUN 26, 2025 |
Supervisory Control and Data Acquisition (SCADA) systems play a critical role in the operation and management of smart grids. These systems are responsible for collecting, analyzing, and visualizing real-time data from various grid components such as substations, transformers, and transmission lines. The data gathered is crucial for maintaining the reliability and efficiency of electrical grids. With the advent of Artificial Intelligence (AI), leveraging this data for predictive analytics, fault detection, and optimization has become a focal point for enhancing grid operations. However, to effectively utilize AI in this domain, accurately labeled SCADA data is essential.
Understanding SCADA Data and Its Complexity
SCADA data is inherently complex due to its multi-dimensional nature. It includes time-series data, event logs, alarms, and status updates from numerous devices. Each data type has its own characteristics and requires different handling techniques for proper labeling. The complexity arises from the vast amount of data generated, the variability in data types, and the need for precise synchronization among data streams. Additionally, ensuring data integrity and dealing with missing or corrupted data can pose significant challenges.
The Importance of Data Labeling in AI Applications
Data labeling involves annotating data with meaningful tags or labels that enable AI models to recognize patterns and make accurate predictions. In the context of smart grids, labeled SCADA data can help in training AI models for various applications such as fault detection, load forecasting, and grid optimization. Accurate labeling ensures that AI algorithms can effectively learn from historical data, identify anomalies, and provide actionable insights. Without proper labeling, the potential of AI in enhancing smart grid operations cannot be fully realized.
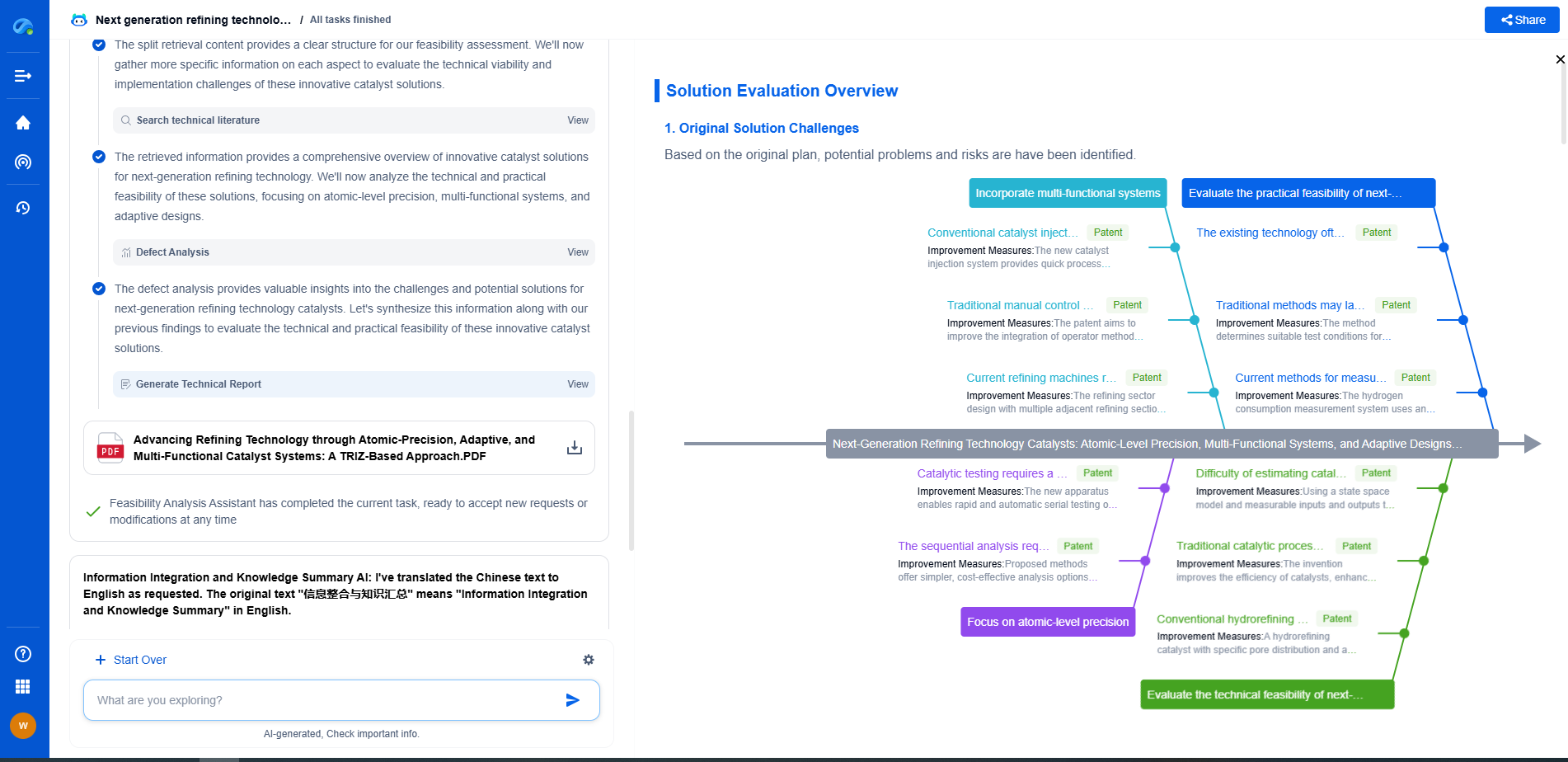
Challenges in Labeling SCADA Data
Labeling SCADA data is not without its challenges. One of the primary issues is the sheer volume of data, which requires scalable and automated labeling processes. Moreover, the data is often unstructured and can come with noise, requiring careful preprocessing to ensure quality. Another challenge is the need for domain expertise to accurately interpret the data and apply the correct labels. This requires collaboration between data scientists and grid operators to ensure that the labels are not only technically accurate but also contextually relevant.
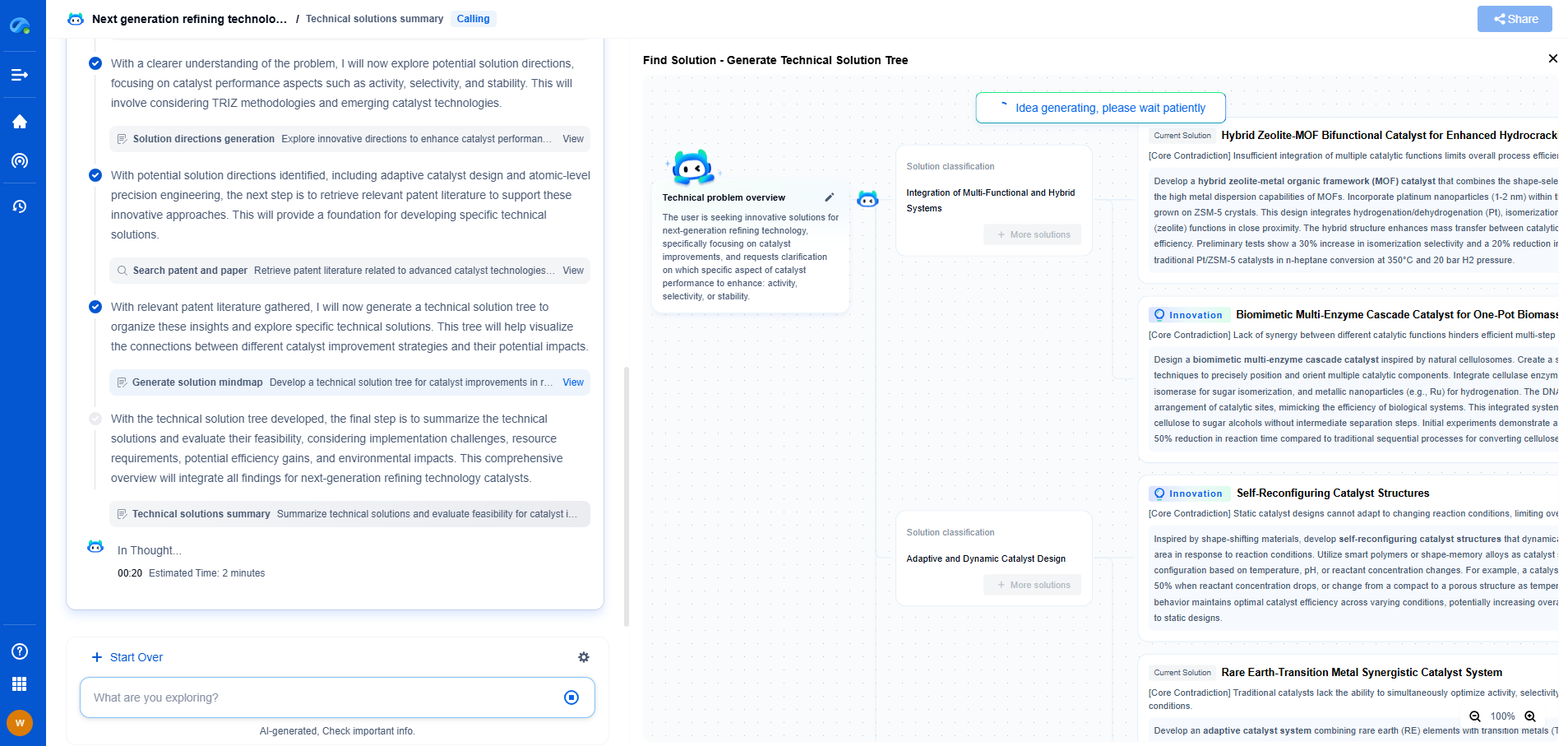
Methods for Labeling SCADA Data
To overcome these challenges, several methods can be employed for labeling SCADA data:
1. Automated Labeling Techniques: Leveraging machine learning algorithms to automate the labeling process can significantly reduce time and effort. These techniques can include clustering and classification algorithms that identify similar data patterns and assign labels accordingly.
2. Manual Labeling with Expert Input: In cases where automated methods fall short, manual labeling by domain experts is essential. Experts can provide insights and context that algorithms may miss, ensuring that the data is correctly interpreted.
3. Hybrid Approaches: Combining automated tools with human expertise often yields the best results. Tools can handle large datasets efficiently, while experts can focus on complex or ambiguous cases.
4. Active Learning: This approach involves using AI models to identify and label the most informative data samples, reducing the amount of data that needs to be labeled manually.
Ensuring Quality and Consistency in Labeled Data
The quality and consistency of labeled data are paramount for the success of AI models. Implementing quality control measures such as cross-validation, peer reviews, and regular audits can help maintain high standards. Additionally, creating a detailed labeling guide with clear definitions and examples for each label can ensure consistency across different labelers.
Conclusion: The Path Forward
Labeling SCADA data is a foundational step in harnessing the power of AI for smart grid applications. By addressing the challenges and implementing effective labeling strategies, utilities can unlock the full potential of AI in optimizing grid operations, improving reliability, and enhancing sustainability. As the smart grid continues to evolve, the importance of accurate and efficient data labeling will only grow, paving the way for a more intelligent and resilient energy future.
Stay Ahead in Power Systems Innovation
From intelligent microgrids and energy storage integration to dynamic load balancing and DC-DC converter optimization, the power supply systems domain is rapidly evolving to meet the demands of electrification, decarbonization, and energy resilience.
In such a high-stakes environment, how can your R&D and patent strategy keep up?
Patsnap Eureka, our intelligent AI assistant built for R&D professionals in high-tech sectors, empowers you with real-time expert-level analysis, technology roadmap exploration, and strategic mapping of core patents—all within a seamless, user-friendly interface.
👉 Experience how Patsnap Eureka can supercharge your workflow in power systems R&D and IP analysis. Request a live demo or start your trial today.