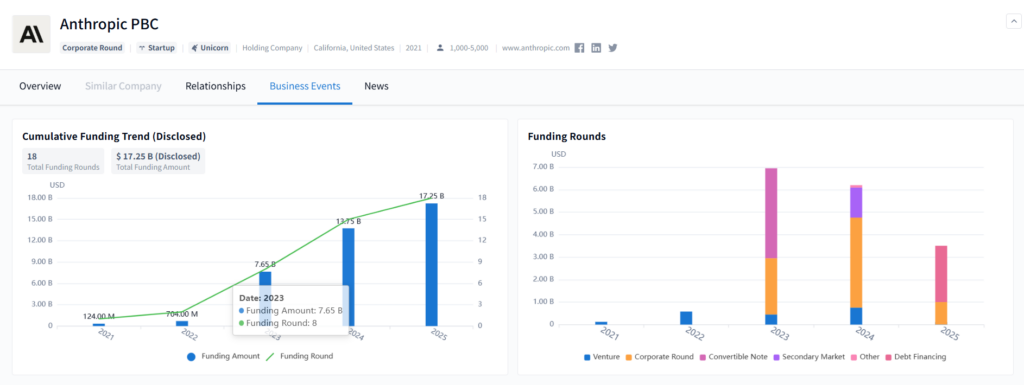
Anthropic, headquartered in San Francisco, California, is an AI safety and research company building reliable and steerable foundation models to support human values in advanced artificial intelligence. Best known for its Claude family of language models, the company emphasizes AI alignment, transparency, and scalable safety mechanisms in model development.
This article provides a comprehensive overview of Anthropic’s corporate structure, product portfolio, innovation strategy, and competitive positioning—revealing how it stays ahead in the rapidly evolving AI space and how you can explore similar insights using the PatSnap Eureka AI Agent, which uncovers R&D trends, patent landscapes, and strategic innovation patterns across the AI ecosystem.
Company Overview
| Key Attribute | Description |
|---|---|
| Founded | 2021 |
| Headquarters | San Francisco, California, USA |
| Founders | Dario Amodei, Daniela Amodei, and former OpenAI team members |
| Core Focus | AI alignment, safety, interpretability, and large-scale language modeling |
| Flagship Product | Claude (1, 2, and 3 series) |
| Key Technology | Constitutional AI, long-context LLMs, scalable safety systems |
| Notable Partners | Amazon AWS, Google Cloud, Slack, Notion, Zoom |
| Employees | ~200 (2024) |

Corporate Structure
| Division | Description |
|---|---|
| Research | Focuses on alignment, interpretability, and model safety |
| Engineering | Model training, API infrastructure, and inference optimization |
| Policy and Governance | Engages in AI ethics, regulation, and institutional collaboration |
| Product | API development, commercial use cases, and integrations |
| Partnerships | Strategic alliances with cloud, enterprise, and productivity platforms |
Products and Services of Anthropic
Anthropic’s product ecosystem centers on Claude, its family of large language models designed with safety and interpretability at the core.
Claude Models
- Claude 1 & 2: Early models with emphasis on harmlessness, helpfulness, and honesty
- Claude 3 Family: Includes Claude 3 Haiku, Sonnet, and Opus
- Claude 3.5 Opus (2024): One of the most capable models in benchmarks like MMLU, HumanEval, and GSM8K
- Supports context windows up to 200K tokens, advanced reasoning, and code generation

Claude API
- Self-serve API via Anthropic’s platform
- Available on Amazon Bedrock and Google Cloud Vertex AI
- Use cases: enterprise chatbots, virtual assistants, summarization, legal analysis, code writing, AI copilots
Constitutional AI (CAI)
Anthropic’s unique alignment methodology replaces traditional RLHF with a set of written principles (“a constitution”) that models use to self-improve during training.
- Encourages explainability, fairness, and reduced bias
- Allows for greater customizability and transparency in enterprise environments
- Models learn to refuse harmful requests and justify their decisions
Enterprise Integrations
- Slack AI: Summarization and smart search
- Notion AI: Creative writing and productivity enhancements
- Zoom AI Companion: Automated meeting recaps and insights
- Claude models are also used in legal, financial, and education sectors for regulated AI deployments
Business Model
Anthropic operates a Model-as-a-Service (MaaS) framework with strong enterprise and cloud integration components.
| Revenue Stream | Description |
|---|---|
| Claude API | Pay-per-token model access with tiered plans |
| Enterprise Licensing | Custom deployments with compliance and security options |
| Cloud Co-revenue | Revenue sharing with AWS and Google for Claude delivery |
| Strategic Partnerships | Co-development, integration, and white-label deployments |
Anthropic monetizes through scalable, aligned AI services, designed to meet both consumer-grade and enterprise-level requirements.
Market Position
Anthropic is one of the leading AI labs, frequently compared to OpenAI, DeepMind, and Mistral in benchmark evaluations. It is widely recognized for:
- Model Alignment Leadership: Pioneer of Constitutional AI
- High-Performance Models: Claude 3.5 Opus competes at the top tier with GPT-4, Gemini 1.5
- Low-Risk Use Preference: Preferred in sectors requiring AI safety and auditability
- Enterprise Flexibility: Broad integrations with productivity, financial, and customer service tools
Research & Academic Contribution of Anthropic
Anthropic is not only a commercial AI lab but also a major contributor to the academic and scientific AI safety ecosystem. Its research agenda reflects a long-term vision of aligned artificial general intelligence (AGI) that is beneficial, interpretable, and steerable at scale.
Key Areas of Research:
- Constitutional AI: Anthropic’s landmark papers on this topic have established a new paradigm in language model alignment. These works demonstrate how models can be taught to reflect ethical principles through self-supervision rather than direct human ranking.
- Mechanistic Interpretability: The lab actively studies the internals of LLMs—such as how specific neurons represent abstract concepts or how attention heads correlate with reasoning steps.
- Scalable Oversight: Research focuses on how to monitor, evaluate, and constrain increasingly capable AI systems without human supervision for every step.
- Model Evaluation Techniques: Anthropic is also involved in developing new benchmarks and stress tests to assess AI safety, refusal quality, and long-term coherence.
Collaborations and Citations:
- Cited extensively by Stanford HAI, Berkeley CHAI, MIT CSAIL, and DeepMind’s safety teams
- Academic collaborations with researchers on topics such as multi-agent alignment, robust refusal training, and harmlessness benchmarks
- Participates in peer-reviewed AI safety workshops at venues like NeurIPS, ICLR, and ICML
With PatSnap Eureka AI Agent, researchers and technologists can explore Anthropic’s research lineage, cross-citations, and technology influence across academic and industrial AI communities.
Ethics, Safety & Governance
Anthropic’s mission is deeply rooted in a commitment to AI that benefits humanity, which is reflected in its organizational structures and public policy engagement.
Core Ethical Commitments:
- Safe-by-default modeling: Claude models are trained to avoid harmful outputs even in adversarial scenarios.
- Refusal behavior: Claude can detect and politely reject requests that are dangerous, illegal, or violate ethical boundaries.
- Explainability standards: All major models undergo alignment audits and are tested for transparency and traceability.
Policy Engagement:
- Member of the White House AI Safety Consortium
- Participant in the UK AI Safety Summit (2023), where it contributed to shaping cross-border AI safety agreements
- Active in NIST AI Risk Management Frameworks, helping guide U.S. standards for safe AI system development
- Promotes AI incident tracking, risk disclosures, and responsible release strategies across the industry
Internal Governance Structure:
| Entity | Role |
|---|---|
| Ethics Review Board | Reviews new model releases and enterprise deployments |
| Policy & Governance Team | Coordinates with regulators and ensures policy compliance |
| Safety Research Unit | Builds protocols for alignment testing, adversarial prompting, and red teaming |
These policies are visible to clients and partners, fostering trust and accountability in real-world use cases.
Innovation & Technology of Anthropic
Anthropic stands at the forefront of frontier AI safety, developing not only powerful models but also rigorous tools and frameworks to make those models transparent, reliable, and aligned. Its core innovation stems from three integrated pillars: model architecture, alignment mechanisms, and interpretability tools.
1. Constitutional AI: A New Standard for Alignment
Anthropic pioneered Constitutional AI (CAI) as an alternative to traditional reinforcement learning from human feedback (RLHF). This approach uses a curated set of principles—such as “be helpful,” “avoid harmful content,” or “respect human rights”—that guide model behavior.
- Claude learns to self-criticize and revise outputs based on these principles.
- This promotes consistency, transparency, and fewer biases across model generations.
- It also enables easier customization by enterprises or regulators who want to define their own AI “constitution.”
2. Model Transparency and Mechanistic Interpretability
Unlike most closed-box foundation models, Anthropic is committed to developing tools to understand how and why models behave a certain way. Research areas include:
- Neuron tracing and activation maps: Understanding internal logic circuits in LLMs
- Attention pattern analysis: Revealing which parts of input influence decisions
- Model self-reflection mechanisms: Claude can explain and revise its reasoning in response to critiques
- Anthropic’s internal tools aim to make AI explainable even for non-engineers, which is critical for fields like law and medicine.
3. Long-Context Reasoning
Claude 3.5 models can handle up to 200K tokens—enabling real-time understanding of large documents such as legal contracts, technical manuals, or research corpora.
- Key innovation: Efficient memory management and sparse attention algorithms
- Applications: Legal tech, customer support, scientific research, enterprise knowledge management
4. AI Refusal and Safety Behavior Modeling
Anthropic’s Claude models are fine-tuned to refuse harmful, unethical, or manipulative requests with well-reasoned justifications.
- Models are trained on counterexamples and adversarial prompts to improve robustness
- Refusal behavior is auditable and adjustable, allowing for customized AI governance
5. Tool Use and Multi-Agent Coordination (Emerging)
- Claude is evolving to integrate with external APIs, databases, and other AI agents for multi-step tasks
- Anthropic is researching agent collaboration and resource-aware planning, paving the way for Claude-powered AI agents that can coordinate like virtual teams
PatSnap Eureka IP Analysis Takeaways:
Using PatSnap Eureka AI Agent reveals:
- Patent activity clustering around instruction modeling, conversational reasoning, alignment safeguards, and self-monitoring systems
- Cross-citation with top AI labs and academic groups (e.g., Stanford, Berkeley, OpenAI, DeepMind)
- Potential for white-space innovation in safe multi-agent systems, open interpretability frameworks, and AI accountability protocols
Market Presence and Financials
| Metric | Value (2024) |
|---|---|
| Total Funding | ~$7.3 billion USD |
| Valuation | Estimated $15–18 billion |
| Top Investors | Amazon ($4B+), Google ($2B+), Salesforce, Zoom Ventures |
| Revenue Sources | Claude API, Cloud integrations, strategic enterprise deployments |
| Key Markets | North America, Europe, select APAC via cloud partners |
| R&D Spend | >$400 million annually (est.) |
| Open Contributions | Multiple safety research papers, interpretability demos, and ethics studies |
Competitors Analysis
| Competitor | Focus Area | Key Differentiator |
|---|---|---|
| OpenAI | General-purpose AGI | GPT-4, ChatGPT platform, plug-ins, multimodal AI |
| Google DeepMind | Multimodal and scientific AI | Gemini models, AlphaFold, high research velocity |
| Mistral | Lightweight, open-weight LLMs | Strong performance on compact models, open-source emphasis |
| xAI | Truth-seeking AI aligned with X | Integrated into social media, led by Elon Musk |
| Cohere | Retrieval-Augmented Generation | Optimized for enterprise RAG and document intelligence |
Anthropic’s differentiation lies in its alignment-first philosophy, building Claude not just to be powerful, but safe by default.
Conclusion
Anthropic is setting new standards in ethical AI development, with the Claude model family standing at the intersection of technical excellence and aligned behavior. Its Constitutional AI framework, long-context modeling, and commitment to transparency make it a trusted name for both cutting-edge research and enterprise deployment.
With the PatSnap Eureka AI Agent, organizations can explore Anthropic’s full innovation spectrum—from model architecture to alignment philosophy—and extract strategic insights to thrive in an era increasingly shaped by large language models.
FAQs
Anthropic stands for developing safe, interpretable, and steerable artificial intelligence aligned with human values.
“Anthropic” means relating to human beings or the human race.
No, Anthropic is an independent company. Google is a major investor but does not own it.
No, Anthropic is a private company and not publicly traded.
Anthropic builds large language models—like Claude—that prioritize AI safety, alignment, and reliability for enterprise and research applications.
By leveraging the PatSnap Eureka’s Company Search AI Agent, you can unlock actionable insights into Anthropic’s alignment-driven AI innovations—empowering your organization to harness safe, transparent, and scalable artificial intelligence.