As artificial intelligence continues to transform industries, the demand for faster, more efficient computation has brought specialized processors into the spotlight. Two leading types of processors—Neural Processing Units (NPUs) and Graphics Processing Units (GPUs)—are driving innovation in AI deployment across edge devices, data centers, and everything in between. What the difference between NPU vs GPU?
While GPUs have been the dominant force in AI training and general-purpose compute acceleration, NPUs are emerging as efficient, task-specific alternatives built solely for neural network processing. Understanding their capabilities, differences, and best-fit scenarios is crucial for hardware developers, AI engineers, and product strategists.
With PatSnap Eureka AI Agent, stakeholders gain access to a powerful toolset that surfaces competitive intelligence, maps global patent activity, and highlights cutting-edge innovation in both GPU and NPU ecosystems.
What Are NPUs?
Neural Processing Units (NPUs) are AI-dedicated hardware accelerators designed to process large volumes of matrix and tensor operations at high speed and low power. These processors are built specifically for deep learning tasks, such as image recognition, speech processing, and natural language understanding.
NPUs support parallelized execution of key AI functions like convolution, activation, pooling, and normalization. They are highly optimized for low-precision arithmetic (e.g., INT8, FP16) and are often integrated into mobile SoCs, edge devices, or AI co-processors.
Key Characteristics of NPUs:
- Dedicated to AI inference and sometimes limited training
- Highly parallelized architecture for tensor and matrix computation
- Support for low-precision operations, improving speed and energy efficiency
- Embedded in SoCs, making them ideal for mobile, automotive, and IoT devices
- Low latency and deterministic performance
- Vendor-specific SDKs and compilers required for model deployment (e.g., Huawei’s CANN, Apple’s Core ML)

What Are GPUs?
Graphics Processing Units (GPUs) were originally developed for real-time rendering of images and video. Their architecture, built for parallel data processing, made them an ideal match for training deep neural networks and solving large-scale numerical problems.
Today, GPUs are essential in high-performance computing (HPC), scientific simulation, data analytics, and AI model training. Their ability to process floating-point operations with precision and scale has made them a staple in both consumer devices and enterprise cloud platforms.
Key Characteristics of GPUs:
- Massively parallel architecture, often with thousands of cores
- Excellent floating-point performance (FP32, FP64, FP16)
- Programmable with mature frameworks like CUDA, OpenCL, and Vulkan
- Versatile for training, inference, and non-AI workloads
- Scalable across form factors, from laptops to servers and clusters
- Large memory bandwidth for processing large datasets

NPU vs GPU: Feature-by-Feature Comparison
Architecture and Design Philosophy
GPU (Graphics Processing Unit)
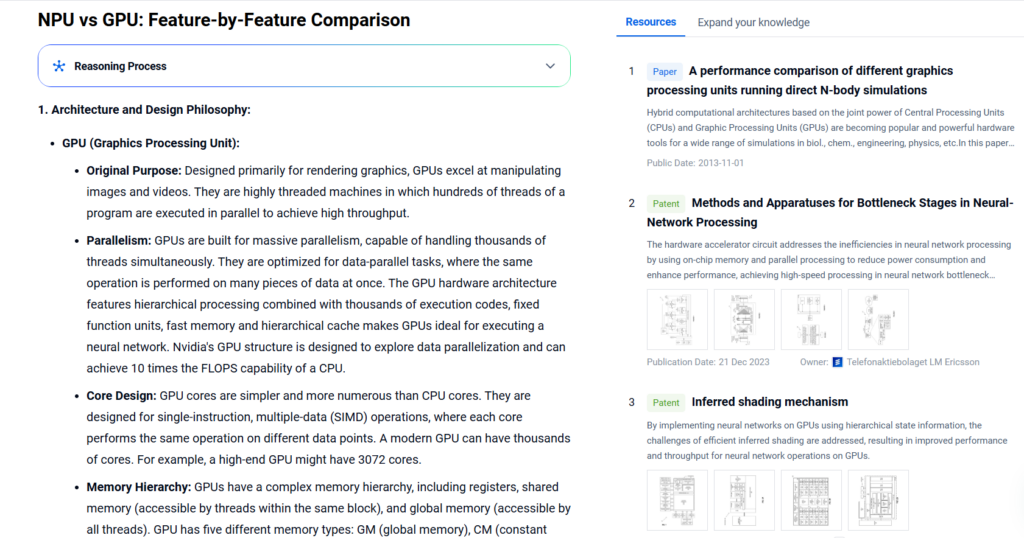
- Original Purpose: GPUs were originally built to render graphics. They handle images and videos efficiently. These processors run hundreds of threads in parallel, delivering high throughput.
- Parallelism: GPUs shine at parallel processing. They run thousands of threads at the same time. They focus on data-parallel tasks—performing the same operation on multiple data points. GPU architecture includes hierarchical processing units, thousands of execution cores, fixed-function units, and fast, tiered memory. This makes them well-suited for neural networks. For instance, Nvidia’s GPU design emphasizes data parallelism and delivers up to 10× the FLOPS of CPUs.
- Core Design: GPU cores are simple and numerous. They follow SIMD (Single Instruction, Multiple Data) logic, where one instruction acts on many data points. A high-end GPU can have around 3,000 cores.
- Memory Hierarchy: GPUs manage a complex memory structure. This includes registers, shared memory, and global memory. Specifically, they use global memory (GM), constant memory (CM), texture memory (TM), shared memory, and private memory (PM). GM and TM are larger. PM is less than 16KB per thread. CM is 64KB. Each processor has 32-bit registers (up to 8,192 or 16,384). Register, CM, and shared memory latency is up to 24 cycles. GM and TM access takes 400–600 cycles.
NPU (Neural Processing Unit)
- Original Purpose: NPUs are tailored for neural network workloads, especially inference. They accelerate tasks like matrix multiplication and convolution. NPUs are microprocessors built to speed up machine learning models.
- Parallelism: Like GPUs, NPUs handle parallelism, but in a different way. They use model parallelism—processing different neural network segments on separate cores. This matches well with the multi-layer structure of neural networks. Some NPUs even outnumber GPUs in core count. Their cores are efficient and have focused interconnects.
- Core Design: NPU cores handle neural network tasks directly. They come with circuits optimized for operations like convolution, activation, pooling, and stride. These hardware accelerators greatly reduce processing time.
- Memory Hierarchy: NPU memory is built for neural networks. It features dedicated buffers for weights and activations. It ensures smooth data flow between memory and computation units. Some NPUs have multi-domain memory. This supplies feature maps and weights at once, speeding up execution.
Performance Characteristics
GPU
- Strengths: GPUs excel at parallel workloads like graphics rendering and matrix math. A single GPU can deliver up to 1.5 TFLOPs—comparable to small computing clusters. When reading large data blocks, GPUs offer much higher bandwidth than CPUs (up to 288 GB/s on Nvidia Tesla K40 versus 68 GB/s on quad-channel DDR3).
- Weaknesses: GPUs are less efficient at tasks that lack parallelism or require complex branching logic. They also consume a lot of power.
NPU
- Strengths: NPUs are built for inference. They deliver high efficiency with low energy use. They’re ideal for AI tasks like vision and language models. For example, Kneron’s KL730 NPU is four times more efficient than its predecessor. NPUs generally outperform GPUs in power efficiency.
- Weaknesses: NPUs lack flexibility. They’re optimized for specific AI tasks and may struggle with others. Hardware differences across NPUs also affect their ability to run certain neural networks or manage data transfers efficiently.
Power Efficiency
GPU
GPUs consume a lot of power. Their many cores and wide memory bandwidth raise energy demands. Power draw depends on architecture, core count, and task type.
NPU
NPUs are designed to use less power. Their architecture and memory setup reduce energy use. They are highly efficient at running neural network inference. For instance, KL730 NPUs target transformer-based AI models with optimized power use.
Use Cases
GPU
- Graphics Rendering: GPUs are ideal for 3D graphics, image processing, and video playback.
- Scientific Computing: GPUs support simulations in molecular dynamics, fluid flow, and more. Though powerful, porting solvers to GPUs may require major changes.
- AI Training: GPUs are the standard for training deep learning models. They’re used in machine vision, finite element analysis, and more.
- General Computing: Through CUDA and OpenCL, GPUs can handle a wide range of compute tasks beyond graphics.
NPU
- Neural Network Inference: NPUs specialize in tasks like object detection, speech recognition, and language modeling.
- Edge AI: NPUs are widely used in low-power edge devices. Kneron’s chips target self-driving cars, medical tools, and industrial systems.
- Real-Time AI: NPUs enable real-time AI in robots and autonomous platforms.

Programming Models
GPU
- CUDA: A parallel computing framework by NVIDIA for GPU acceleration.
- OpenCL: A cross-platform standard for heterogeneous computing, supporting many GPU vendors.
NPU
- Vendor APIs: Most NPUs require proprietary SDKs. For instance, Kneron uses a reconfigurable AI architecture.
- ONNX Support: Some NPUs run models exported from frameworks like TensorFlow and PyTorch through the ONNX format.
Cost and Availability
GPU
- Cost: High-end GPUs can be expensive, especially for gaming or professional use. Still, budget GPUs work well for scientific applications.
- Availability: GPUs are easy to find. Brands include NVIDIA, AMD, and Intel.
NPU
- Cost: NPU prices vary by model and vendor. Some are built into SoCs, keeping costs low. For example, in Apple’s M3 Max, the GPU takes up nearly half the chip, while the NPU uses only 5–10%.
- Availability: NPUs are becoming common. New CPUs like AMD’s Ryzen 8040 include NPUs with OS-level integration like Windows Task Manager monitoring.
Innovation in NPU Technology
In recent years, NPUs have seen tremendous innovation, particularly in the areas of edge AI, power optimization, and chip-level integration. Key advancements include:
- Heterogeneous chip architectures combining NPU, CPU, and DSP cores
- Dynamic sparsity and quantization techniques to reduce computation without loss in accuracy
- AI-native memory hierarchy, improving data locality and reducing bottlenecks
- On-device learning, enabling continual model updates at the edge
- Automotive-grade NPUs (e.g., for ADAS and self-driving modules)
Which Processor Is Right for You?
Choose an NPU if:
- You’re deploying AI on smartphones, wearables, or embedded systems
- You need low-latency and low-power inference
- Your AI models are trained elsewhere and deployed at the edge
- You prioritize on-device privacy and cost efficiency
Choose a GPU if:
- You’re training complex models with large datasets
- Your applications include HPC, graphics, or general compute
- You require broad framework support and community resources
- Power consumption is not a primary concern
PatSnap Eureka AI Agent Capabilities
PatSnap Eureka AI Agent enables:
- Technology scouting: Discover who’s leading in GPU/NPU innovation
- Patent analytics: Analyze filing trends, forward citations, and IP strengths
- Competitive intelligence: Compare IP portfolios of rivals
- Market whitespace: Identify underserved application areas or geographic gaps
- M&A insights: Spot promising startups or licensing targets in AI chip development
Using Eureka, organizations can align R&D with industry trajectories and protect core innovations in this rapidly evolving space.
Conclusion
The choice between NPU vs GPU depends on your application, deployment environment, and performance requirements. GPUs remain dominant in training and high-performance compute, while NPUs are ideal for inference on the edge. Both play crucial roles in the AI hardware ecosystem.
With PatSnap Eureka AI Agent, tech leaders can evaluate both solutions through a patent and innovation lens—making every hardware decision more strategic, data-driven, and future-proof.
FAQs
It depends. NPUs are better for neural network inference. GPUs are more versatile and handle a wider range of tasks, including training.
Not entirely. NPUs can replace GPUs in edge AI and inference tasks but not for graphics rendering or general-purpose computing.
In specific tasks, yes. NPUs often beat GPUs in power efficiency and inference speed, especially in embedded or low-power devices.
GPUs are general-purpose accelerators for graphics and parallel computing.
NPUs are specialized for deep learning inference, with lower power use and higher efficiency in AI tasks.
Some do via vendor SDKs, but support is more limited than on GPUs
To get more scientific explanations of NPU vs GPU, try PatSnap Eureka AI Agent.