As artificial intelligence continues to evolve, the underlying hardware responsible for executing AI workloads must keep pace. Two of the most prominent processing units driving modern AI development are Tensor Processing Units (TPUs) and Graphics Processing Units (GPUs).What’s the difference between TPU vs GPU? Each offers unique advantages, making the choice between them crucial for optimal performance and cost-effectiveness.
With the PatSnap Eureka AI Agent, users can delve into architecture-specific innovations, patent trends, and performance metrics to select the best solution for their AI pipelines.
What is a TPU?
Tensor Processing Units (TPUs) are custom-designed ASICs (application-specific integrated circuits) developed by Google specifically for accelerating machine learning workloads. Initially introduced in 2016, TPUs are now a staple of Google’s AI infrastructure and are available through Google Cloud. These processors are optimized for operations common in deep learning models, such as matrix multiplications, convolutions, and activation functions.
Key Characteristics of TPUs
- Application-Specific Design: Unlike general-purpose processors, TPUs are built for a narrow but intensive set of tasks—specifically deep learning inference and training.
- Systolic Array Architecture: TPUs use a grid of interconnected processing elements. Data pulses through the array in waves, achieving high throughput and reducing the need for frequent memory access.
- Deep Integration with TensorFlow: TPUs are deeply embedded into the TensorFlow ecosystem, benefiting from compiler-level optimizations via XLA (Accelerated Linear Algebra).
- High Performance for ML Models: TPUs can perform trillions of operations per second, enabling faster training of large-scale models.
- Energy Efficiency: TPUs deliver superior performance-per-watt compared to many general-purpose processors.
What is a GPU?
Originally developed for rendering 3D graphics, Graphics Processing Units (GPUs) have become versatile computing platforms for parallel tasks. With their massive core counts and ability to run thousands of threads simultaneously, GPUs are well-suited to handle the matrix and vector operations at the heart of AI and deep learning.
Key Characteristics of GPUs
- Massive Parallelism: A typical GPU can have thousands of cores that perform computations simultaneously, making them ideal for data-parallel workloads.
- Flexibility: GPUs are used in a wide range of applications—from video rendering and gaming to scientific computing and deep learning.
- Precision Variety: GPUs support multiple numeric formats, including float16, float32, and float64, allowing users to balance performance and accuracy.
- Framework Compatibility: GPUs support major AI frameworks like PyTorch, TensorFlow, and MXNet. NVIDIA’s CUDA toolkit has become the de facto standard for GPU programming.
- Broad Availability: GPUs are accessible in both consumer-grade laptops and enterprise-level data centers, making them highly scalable.

Pros and Cons of TPUs
Pros
- Exceptional Performance: Designed for deep learning, TPUs accelerate matrix-heavy computations, drastically reducing training times for large models.
- Efficient Resource Usage: TPUs offer better energy efficiency per training task compared to many GPU counterparts.
- Cloud Scalability: Google Cloud provides seamless TPU scaling for distributed training.
- Software Optimization: Integration with TensorFlow and XLA enables low-level hardware acceleration without manual tuning.
Cons
- Limited to TensorFlow: Most TPUs require TensorFlow for operation, limiting flexibility for users of other frameworks.
- Restricted Local Access: TPUs are mostly accessible via Google Cloud, with limited support for on-premise deployment.
- Narrow Workload Compatibility: TPUs are specialized and not well-suited for general-purpose or graphics workloads.
Pros and Cons of GPUs
Pros
- Framework Agnostic: Supports a wide variety of AI and ML tools, making GPUs a popular choice for developers.
- Accessible Hardware: Available across multiple platforms and price ranges, from laptops to cloud instances.
- Versatile Applications: Ideal not just for deep learning but also for rendering, simulation, and scientific modeling.
- Robust Ecosystem: CUDA and other developer tools offer mature programming environments.
Cons
- High Power Consumption: GPUs, especially high-end models, can consume substantial energy.
- Hardware Cost: Premium GPUs can be expensive, especially when scaling across a data center.
- Less Specialized: While powerful, GPUs are not as optimized for AI-specific tasks as TPUs.
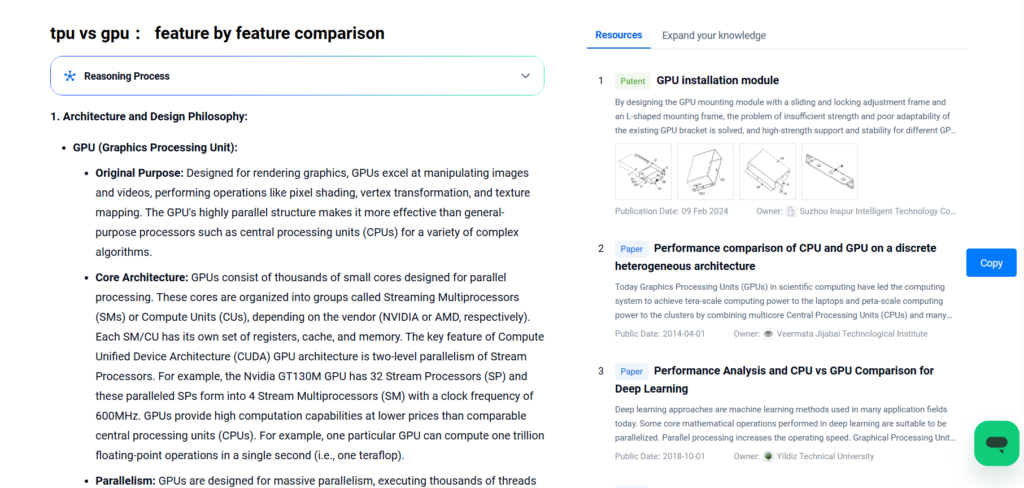
TPU vs GPU: Feature-by-Feature Comparison
Architecture and Design Philosophy
GPU (Graphics Processing Unit):
- Original Purpose: GPUs were designed to render graphics. They specialize in handling images and videos. They perform pixel shading, vertex transformation, and texture mapping. Their parallel structure outperforms CPUs for complex algorithms.
- Core Architecture: GPUs contain thousands of small cores. These cores work in parallel. Vendors group them into Streaming Multiprocessors (SMs) or Compute Units (CUs). Each SM or CU has registers, cache, and memory. CUDA GPUs use two-level parallelism. For instance, the Nvidia GT130M GPU has 32 Stream Processors. These form 4 SMs running at 600MHz. GPUs deliver high computing power at lower cost than CPUs. One GPU can execute one trillion floating-point operations per second (one teraflop).
- Parallelism: GPUs run thousands of threads at once. This suits workloads that split into smaller, independent tasks. Unlike CPUs, which execute a few fast tasks, GPUs run many slower ones in parallel. Modern GPUs handle up to tens of thousands of threads. While CPUs have a few cores, GPUs offer much broader parallelism.
- Memory Hierarchy: GPUs feature a layered memory structure. This includes registers, shared memory (within an SM/CU), and global memory (for the whole GPU). Memory latency is high—around 400 clock cycles. However, bandwidth between vector cores and on-device memory is very high.
TPU (Tensor Processing Unit)
- Original Purpose: TPUs are ASICs—custom chips. Google designed them for machine learning. They focus on tensor operations like matrix multiplications and convolutions.
- Core Architecture: TPUs use systolic arrays. These arrays allow efficient data flow. MXUs (Matrix Units) execute 16K multiply-accumulate operations per cycle. TPUs perform many simple calculations on blocks of data quickly. They’re fast at matrix operations but slower at tasks with heavy conditionals.
- Parallelism: TPUs exploit parallelism but in a different way. Instead of general-purpose threads, they optimize parallelism for ML. Their structure suits repetitive tensor calculations.
- Memory Hierarchy: TPUs have simpler memory designs than GPUs. They rely on high-bandwidth memory (HBM) to feed data. Each TPU core has two MXUs. A TPU pod can include 2048 cores and 32 TiB of memory.
Performance Characteristics:
GPU
- Strengths: GPUs excel in parallelized tasks—image processing, video rendering, simulations. GPGPU (general-purpose computing on GPUs) is also efficient. Graphics pipelines show two key features: high data parallelism and high arithmetic intensity. Each data point goes through many sequential instructions. Data points operate independently, allowing massive parallelism.
- Weaknesses: GPUs falter in tasks with strong data dependencies, irregular memory access, or complex branches. CPUs handle such diverse tasks better. GPUs, by design, are best at massive, predictable, repetitive calculations.
TPU
- Strengths: TPUs shine in ML workloads. They’re fast and power-efficient. Training and inference for deep learning models see major speedups. Tests show GPUs can outperform CPUs by 4-5x. With large tasks, a GPU at 100% utilization is 51% faster than a multithreaded CPU. GPU throughput can be 2.1 times greater for large problems.
- Weaknesses: TPUs perform poorly outside ML. Their hardware is tailored, so flexibility is limited. They don’t adapt well to varied workloads.
Programming Model
GPU
- Languages/Frameworks: GPUs use CUDA (NVIDIA), OpenCL, Vulkan.
- Parallelism Model: GPU code runs as kernels. Kernels are functions executed by many threads in parallel. Threads group into blocks. Blocks form a grid. Each thread has a thread ID (threadIdx). Blocks have IDs (blockIdx). These IDs help assign data to threads.
- Memory Management: Efficient memory use is critical. Latency must be reduced. Bandwidth must be maximized. GPU programming requires effort to match data structures and flow to GPU capabilities. Hard-coded sizes and tailored code can improve performance.
TPU
- Languages/Frameworks: TPUs are built around TensorFlow. Optimizations are handled by the framework.
- Parallelism Model: ML practitioners use TPUs easily. The system manages memory and parallel execution internally.
- Memory Management: The ML framework abstracts memory handling. Developers can focus on model design.
Power Efficiency
GPU: GPUs use significant power, especially under heavy loads. Power draw often exceeds several hundred watts.
TPU: TPUs consume less energy. They offer more computation per watt. GPUs average around 2.7 GFLOP/s per watt. CPUs offer around 0.9 GFLOP/s per watt.
Cost
GPU: GPUs can be pricey. High-end models cost thousands.
TPU: TPUs cost more. For example, Google’s TPU v3 costs $8/hour, TPU v2 is $4.50/hour. In contrast, the NVIDIA Tesla P100 costs around $1.46/hour—TPUs can cost five times more.
Typical Applications
GPU:
- Graphics Rendering: Games, VR, 3D design.
- Scientific Computing: Simulations, modeling.
- Machine Learning: Training and inference.
- General-Purpose: Data analysis, image and video processing.

TPU:
- Machine Learning: Large deep learning models.
- AI: NLP, image recognition, speech recognition.
Innovation in TPU Technology
Google has consistently refined TPU technology with each new generation. TPU v4, for example, features:
- Advanced Interconnects: High-speed links for multi-core and multi-host communication.
- Increased On-Chip Memory: Reduces dependency on external memory, cutting latency.
- Enhanced Matrix Multiplication Units: Capable of performing larger operations per cycle.
PatSnap Eureka AI Agent enables users to:
- Explore TPU-related patents on systolic array architectures.
- Compare proprietary innovations across vendors.
- Analyze trends in AI hardware design and energy efficiency.
Which Accelerator Is Right for You?
Choose TPUs if:
- You’re deeply embedded in the TensorFlow ecosystem.
- You want to accelerate large-scale AI training on Google Cloud.
- You prioritize power efficiency for ML inference tasks.
Choose GPUs if:
- You use diverse AI frameworks like PyTorch and TensorFlow.
- Your workload spans beyond ML to include simulation or visualization.
- You need both on-premise and cloud deployment flexibility.
PatSnap Eureka AI Agent Capabilities
PatSnap Eureka AI Agentprovides:
- Patent Landscape Mapping: Discover who’s innovating in TPU and GPU tech.
- Competitive Intelligence: Compare feature sets and performance claims.
- Benchmarking: Evaluate energy usage, FLOPS, and memory bandwidth.
- Strategic Forecasting: Identify emerging trends in accelerator architecture.
This intelligence empowers organizations to make strategic investments in hardware that align with long-term AI goals.
Conclusion
TPUs and GPUs each offer distinct strengths in the AI hardware ecosystem. TPUs lead in TensorFlow-native, matrix-intensive workloads with energy efficiency. GPUs shine in flexibility, broader framework support, and general-purpose computing. Using thePatSnap Eureka AI Agent, organizations can base their hardware decisions on verified data, technical benchmarks, and IP trends—ensuring both immediate performance gains and future readiness.
FAQs
Q1: Are TPUs faster than GPUs?
A: Yes, for TensorFlow models. TPUs can train models faster and more efficiently in those environments.
Q2: Can I use a TPU without Google Cloud?
A: Not easily. Most TPUs are hosted within Google Cloud infrastructure.
Q3: Are GPUs better for AI beginners?
A: Yes. GPUs offer more documentation, broader framework support, and easier access.
Q4: Can I use PyTorch with TPU?
A: No, TPUs currently only support TensorFlow natively.
Q5: Which is more cost-effective?
A: TPUs are cost-effective for TensorFlow-based large-scale workloads. GPUs offer better overall value for varied and smaller tasks.
To get more scientific explanations of TPU vs GPU, try PatSnap Eureka AI Agent.