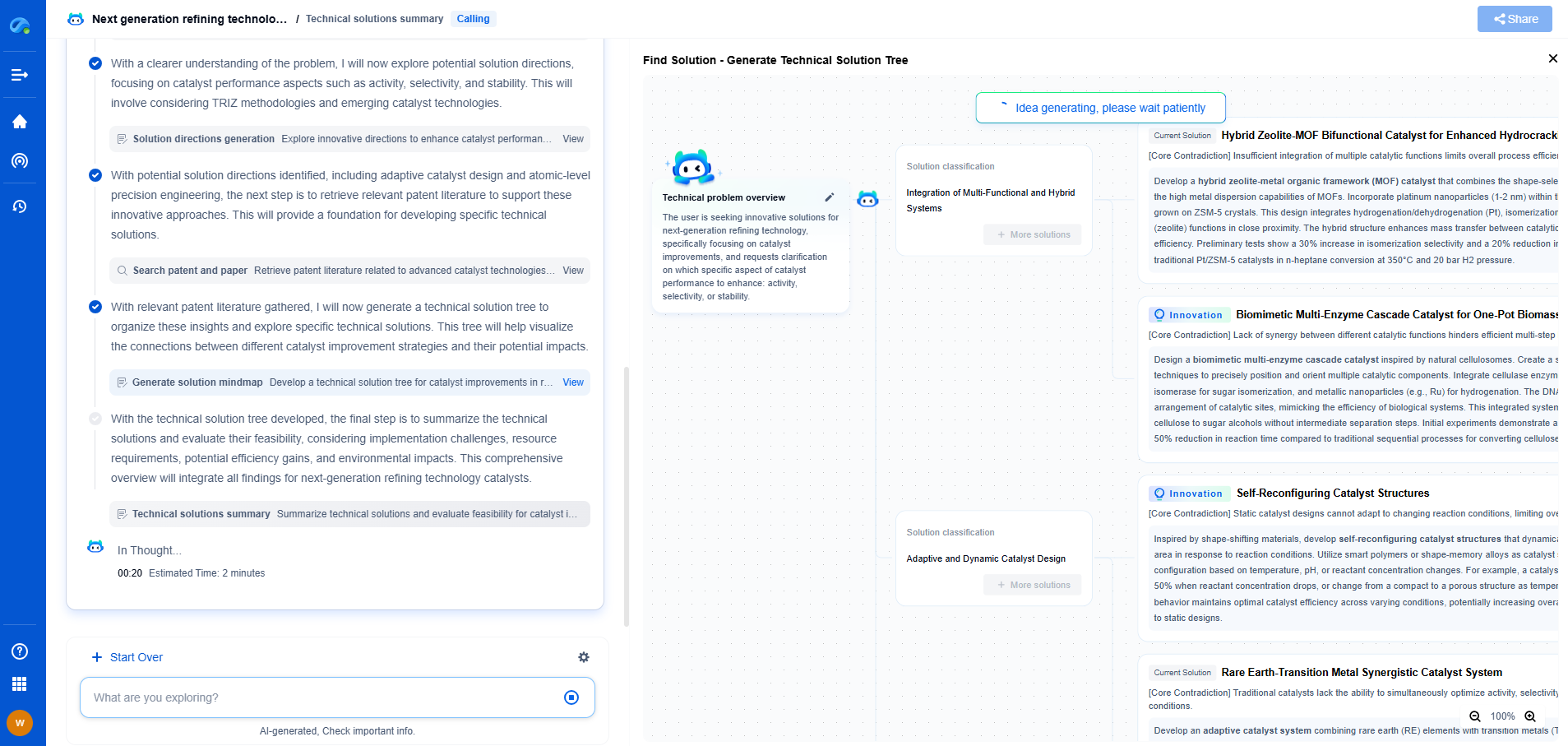
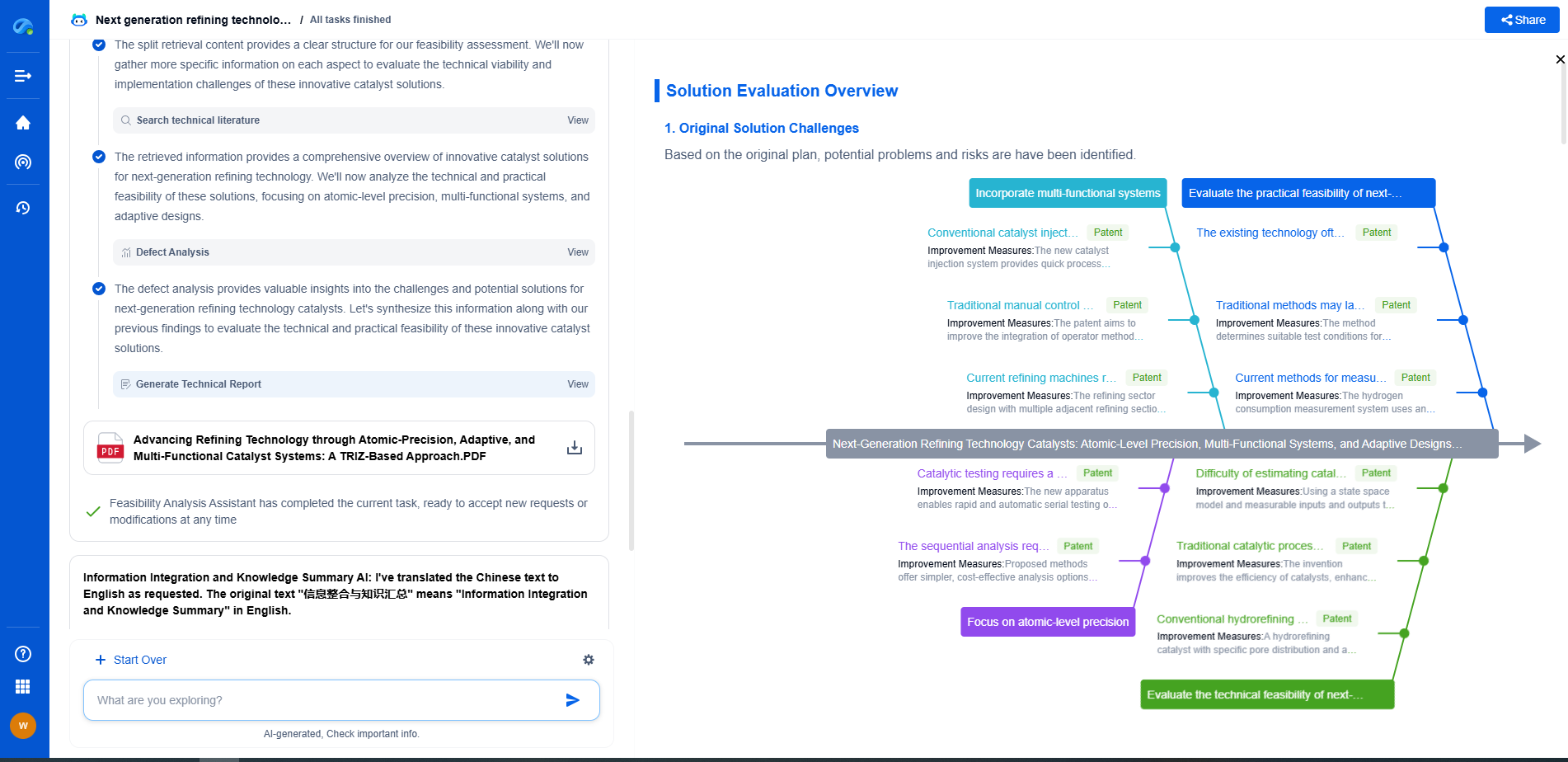
For fifty years the computing hierarchy was settled: CPU → OS → Compiler → DB → App. Each layer spoke the layer below it in deterministic, syntactic terms. The arrival of foundation models and specialized silicon is collapsing these boundaries. Five new abstractions—LLM as OS, Matrix Processor as CPU, Agent as App, Natural Language as IDE, Semantic Vector as DB—are emerging simultaneously. Together they form a single, coherent AI-native software stack that trades precision for probability, syntax for semantics, and rigidity for adaptation.
LLM as Operating System
1. Core Idea
A large language model no longer “runs on” an OS; it is the OS. It schedules tasks (planning), allocates cognitive resources (attention heads), manages I/O (tool calls), and even enforces security (alignment). GPT-4, Claude, PaLM 2, and open-source LLaMA variants already expose “system calls” in the form of function-calling APIs and plug-in registries.
2. Architecture in Practice
• Context Window = RAM: Attention spans of 32 k–2 M tokens act like virtual memory, swapped in and out via retrieval-augmented generation (RAG).
• Skill Plug-ins = Device Drivers: Weather, code execution, or SQL connectors are hot-loaded on demand.
• Fine-tuning = Kernel Patches: LoRA adapters update policy without recompiling the whole kernel.
3. Implications
Traditional kernels still manage hardware, but the LLM kernel orchestrates intent. This pushes the OS boundary upward—from managing registers to managing goals.
Vector / Matrix Processor as the New CPU
1.Hardware Shift
GPUs, TPUs, NPUs and custom ASICs now spend more FLOPs on inference than HPC. NVIDIA’s H100 delivers 989 TFLOPS of FP8, dwarfing any general-purpose CPU. Google’s 4th-gen TPU achieves 26× the perf/W of contemporary CPUs on transformer workloads.
2.Instruction-Set Analogy
SIMT/SIMD warp execution maps to “matrix instructions”; CUDA kernels or TPU ops are the new assembly. Compilers (XLA, Triton) translate high-level graphs into these instructions, just as GCC once translated C to x86.
3.System Consequences
• OS schedulers must allocate tensor time slices.
• Memory hierarchies now prioritise HBM3e over L3 cache.
• Power budgets shift from 250 W CPUs to 700 W accelerators, forcing liquid-cooling and chiplet 3D stacking.
AI Agent as Application
1.Concept
An Agent is an autonomous, goal-driven process wrapped around an LLM. It plans, remembers, and acts via tools—analogous to an entire micro-service distilled into a single conversational entity.
2. Current Manifestations
• AutoGPT / BabyAGI: early proof-of-concept loops of plan-execute-reflect.
• Microsoft Copilot Ecosystem: Office, Windows, and Edge agents share context through a common identity graph.
• LangChain & CrewAI: frameworks that treat agents as composable micro-services.
3. New Runtime Requirements
Agent platforms must provide:
• Long-term memory (vector DB + graph DB).
• Tool registry (REST, SQL, shell).
• Observability hooks (why did it book that flight?).
These primitives sit above today’s OS and below the business logic, effectively creating a new middleware layer.
Natural Language as IDE
1. From Syntax Trees to Intent Trees
GitHub Copilot, StarCoder and Code Llama already auto-complete 30–50 % of professional code. Cursor, Replit AI and JetBrains AI Assistant extend this to refactoring, testing and deployment via chat.
2. Workflow Re-wiring
• Prompt = Source File: developers version-control prompts instead of code; diffs are semantic.
• Copilot X Chat = Debugger: stack traces are explained in plain English, fixes proposed inline.
• Self-healing CI: failed builds trigger LLM patches that are human-reviewed before merge.
3. Limits & Guardrails
Hallucinations and IP leakage remain open issues. Emerging practices include “prompt linting”, deterministic test harnesses around LLM outputs, and private model fine-tunes on corporate codebases.
Semantic Query as Database
1. Post-SQL Retrieval
Vector databases (Milvus, Pinecone, Weaviate) approximate nearest-neighbour search in 768–1536-dimensional space. Combined with RAG, they answer questions like “Which Q3 reports discuss supply-chain risk?” without a single WHERE clause.
2. Hybrid Architectures
PostgreSQL + pgvector, Elasticsearch + kNN, and MongoDB Atlas Vector Search illustrate how legacy DBs are grafting embedding indexes onto relational or document models. Future systems will offer SQL + ANN + LLM in a single query planner.
3. Governance Challenges
• Recall vs Precision: ANN algorithms sacrifice exactness for speed; new benchmarks (ANN-Benchmarks, BEIR) quantify the trade-off.
• Explainability: each answer must cite source chunks to satisfy compliance.
• Update Cascade: re-embedding millions of documents after content changes remains a DevOps headache.
The Integrated Stack
Putting it together, the AI-native stack looks like:
User → Natural Language → LLM OS → Agent Orchestrator → Vector DB & Tools → Matrix Processor → Hardware
• LLM OS handles intent and state.
• Agent Orchestrator dispatches sub-tasks.
• Vector DB provides semantic memory.
• Matrix Processor executes tensor kernels.
• Hardware remains heterogeneous (CPU + GPU/TPU).
Ecosystem Snapshot
1. Giants
OpenAI, Google, Microsoft, Anthropic dominate model compute; NVIDIA, AMD, Google TPU supply silicon; AWS, Azure, GCP host the stack.
2. Open Source
Meta LLaMA, Hugging Face Transformers, LangChain, Milvus, StarCoder, Triton compiler, ONNX Runtime, RISC-V AI extensions.
3. China Angle
ChangXin DRAM, SMIC 14 nm XRING SoCs, NAURA etchers, Empyrean EDA, and Biren GPUs show coordinated vertical push across wafers, tools, and capital.
Roadblocks & Research Agenda
• Reliability: hallucination mitigation, guardrail DSLs, formal verification of LLM policies.
• Efficiency: 1000× inference cost reduction via sparsity, quantisation, edge distillation.
• Memory: million-token context or hierarchical “semantic swap”.
• Standards: vector query SQL extensions, agent-to-agent protocols, LLM audit trails.
• Ethics: attribution, bias, labour displacement, export-control resilience.
Conclusion
The five new paradigms are not isolated upgrades; they form a coherent, AI-first computing fabric. Traditional layers survive but recede into plumbing. The centre of gravity moves from deterministic logic to probabilistic understanding, from explicit code to implicit intent. Mastering this transition—balancing innovation with safety, performance with accessibility—will define the next decade of computing.
Infuse Insights into Chip R&D with PatSnap Eureka
Whether you're exploring novel transistor architectures, monitoring global IP filings in advanced packaging, or optimizing your semiconductor innovation roadmap—Patsnap Eureka empowers you with AI-driven insights tailored to the pace and complexity of modern chip development.
Patsnap Eureka, our intelligent AI assistant built for R&D professionals in high-tech sectors, empowers you with real-time expert-level analysis, technology roadmap exploration, and strategic mapping of core patents—all within a seamless, user-friendly interface.
👉 Join the new era of semiconductor R&D. Try Patsnap Eureka today and experience the future of innovation intelligence.