Cluster excavation method of large-scale data set of single machine
A large-scale data and clustering mining technology, which is applied in the fields of electrical digital data processing, special data processing applications, instruments, etc., can solve problems such as insufficient memory of a single physical machine, and achieve the effect of improving mining efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Example Embodiment
[0017] In the following, the present invention will be further clarified with reference to specific examples. It should be understood that these examples are only used to illustrate the present invention and not to limit the scope of the present invention. After reading the present invention, those skilled in the art will understand various equivalents All the modifications fall within the scope defined by the appended claims of this application.
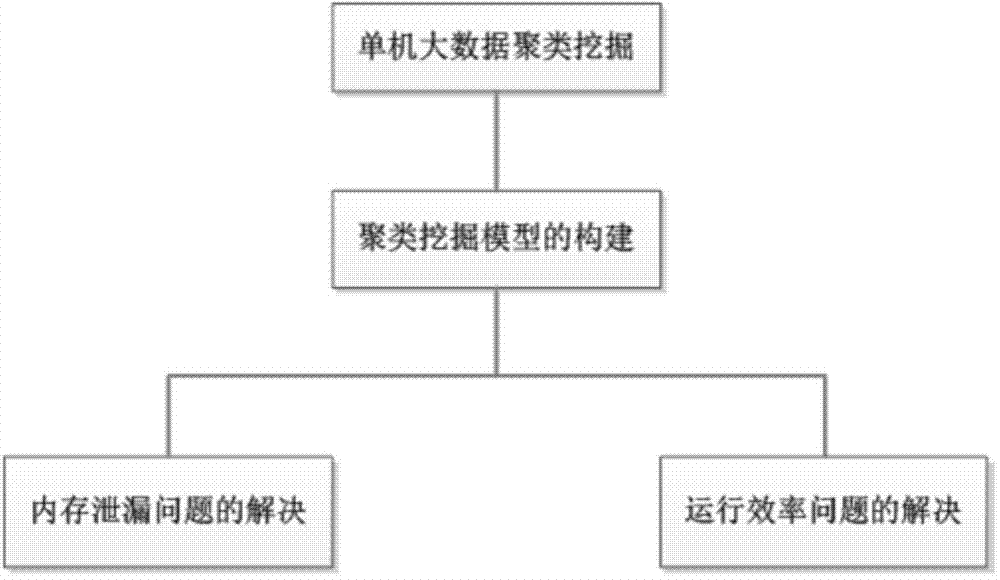
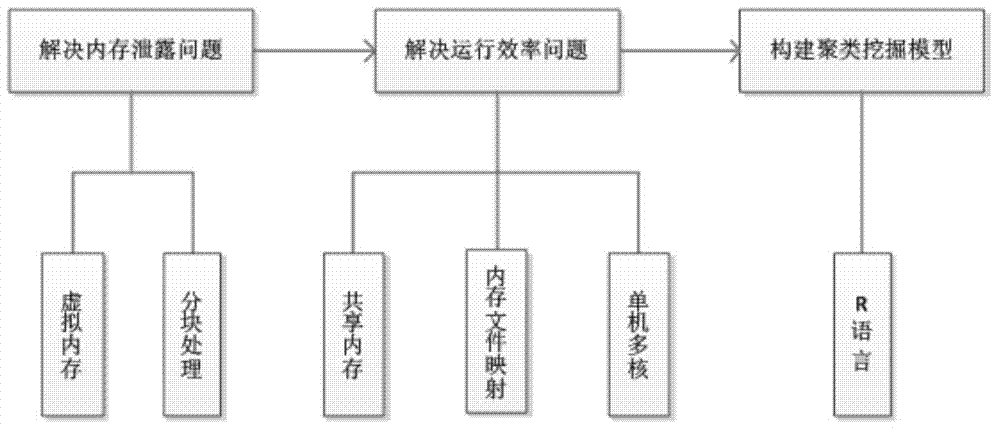
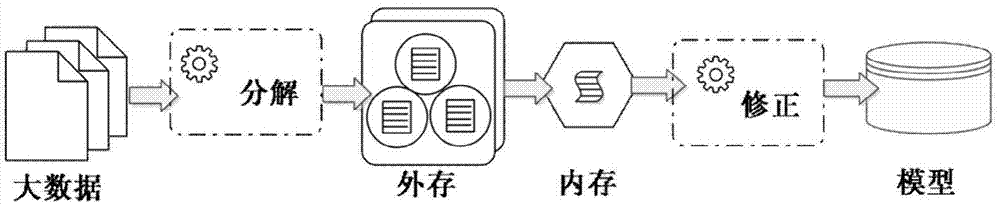
[0018] The method provided by the present invention roughly divides the cluster mining of large-scale data sets on a single machine into three steps, such as figure 1 As shown, first build a cluster mining model, and then solve the memory leak and operating efficiency issues separately; figure 2 Said, the implementation steps of the method of the present invention are: the solution of the memory leakage problem, that is, the large data is read into the memory in blocks based on the virtual memory and the block processing mechanism; the ...
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap