

A Query Optimization Method for Distributed Database
A query optimization and database technology, applied in the field of query optimization of distributed databases, can solve the problems of heavy task load, unpredictable time consumption, and time-consuming HDFS data, so as to optimize retrieval and query and shorten query time.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
[0038] The present invention will be further described below in conjunction with the accompanying drawings.
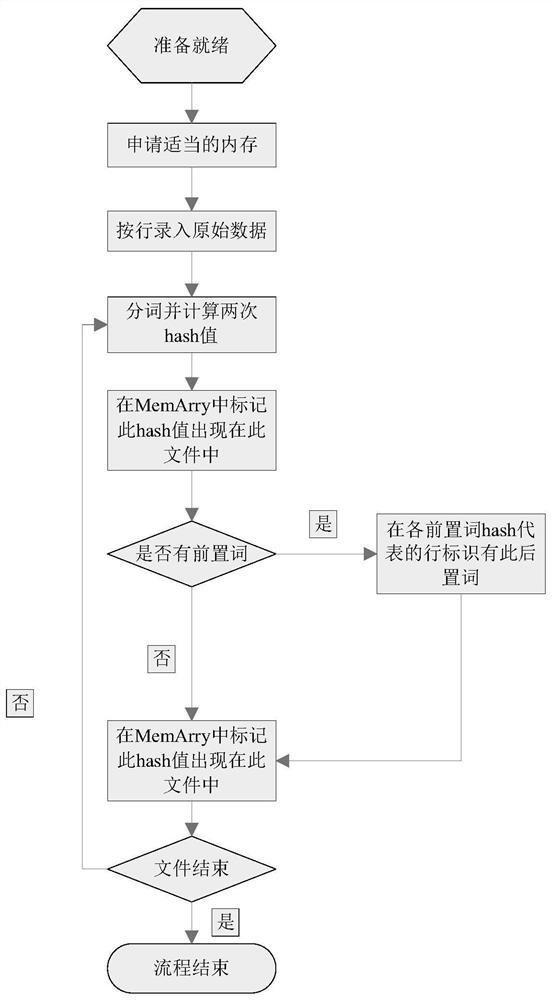
[0039] The present invention filters the files under the framework of the distributed file system in the form of index construction, generates an index file within 15M for each file in the data storage stage, and checks the index file in advance before searching and traversing the original file; Judging whether the file contains (must contain, may contain, and must not contain three results) the character string to be fuzzy searched, thereby avoiding scanning a large number of unnecessary original files.
[0040] The index file generation process is as follows figure 1 :
[0041] Step 1: Apply for a piece of memory with a size of 9801594B. The size of the index is determined according to the demand. The larger the index, the more accurate the matching rate. The present invention takes the 9M index as an example;
[0042] Step 2: Segment the word for the field to be i...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More