Hardware acceleration implementation architecture for forward prediction of convolutional neural network based on FPGA
A convolutional neural network and forward prediction technology, applied in the field of deep learning, can solve problems such as insufficient storage bandwidth, and achieve significant acceleration effects, neat structure, and fast processing speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
example 1
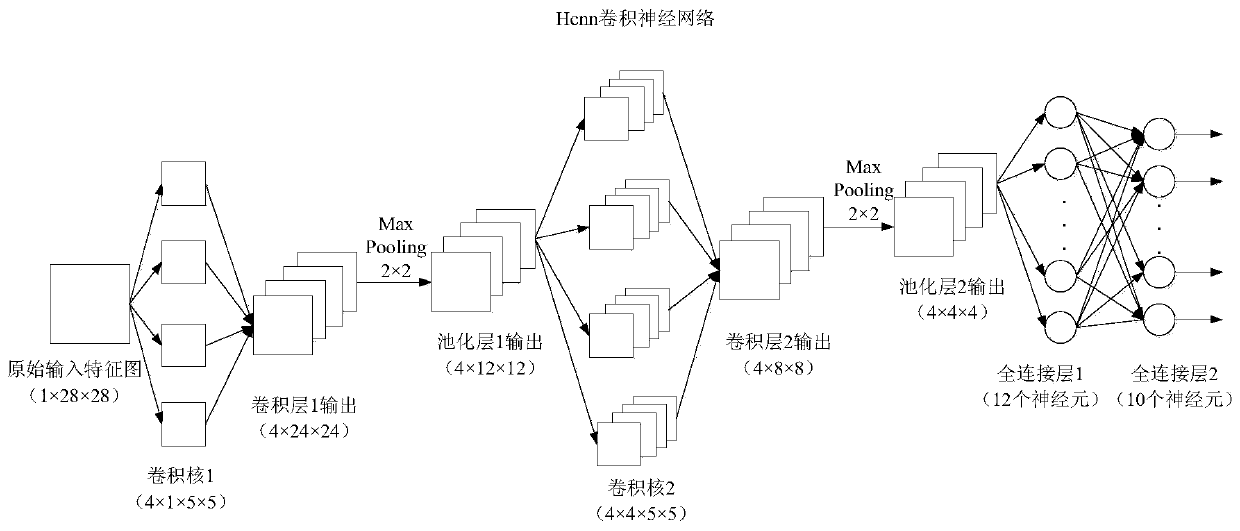
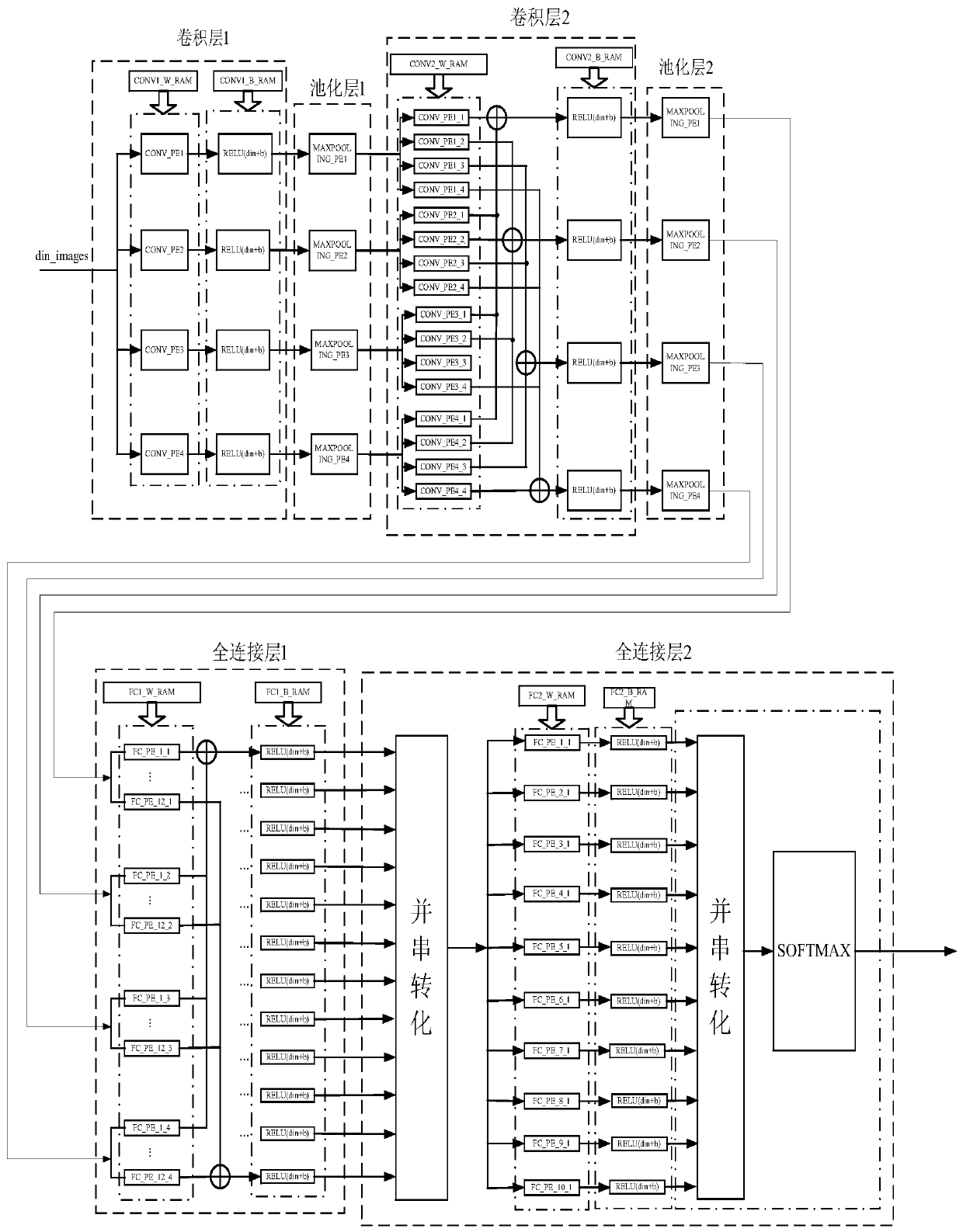
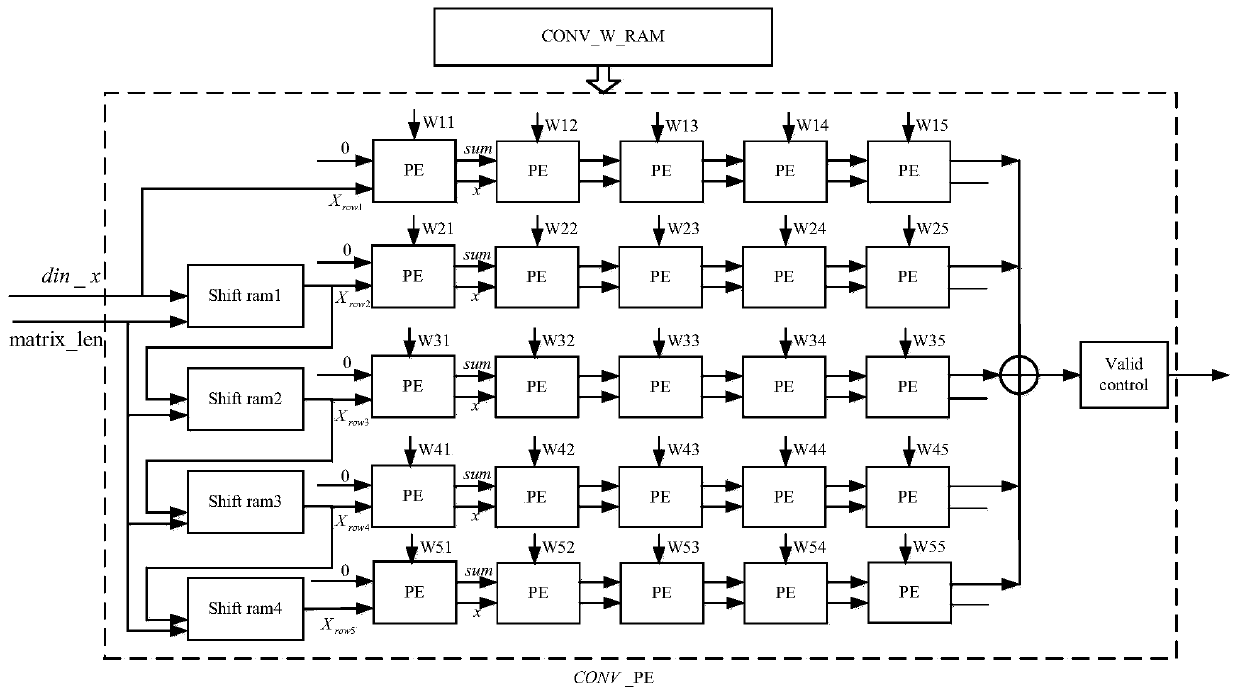
[0057] 1. Example 1: FPGA simulation and implementation of convolutional neural network Hcnn forward prediction process
[0058] The simulation platform used in Example 1 is Pycharm, ISE 14.7 and Modelsim 10.1a, and the implemented architecture is as follows figure 2 shown. First in Pycharm for figure 2 The Hcnn convolutional neural network is modeled and trained, and the accuracy of the model can reach 96.64%. Save the parameters of the trained Hcnn convolutional neural network model, that is, the weights and bias items of each layer, for FPGA simulation and implementation. It should be noted that in the FPGA implementation, most of the parameters and intermediate register variables adopt the fixed-point method of fi(1,18,12), that is, 1 bit of sign, 5 bits of integer, and 12 bits of decimal. However, in the implementation of the softmax unit, the fitting function coefficient values fluctuate too much in different intervals, so segmental fixed points are required, that...
example 2
[0062] The simulation platform used in Example 2 is ISE 14.7 and PyCharm. The data processing time of this model is 233 clks (excluding the time to read input data). According to analysis and statistics, the total number of fixed-point number operations in the forward prediction process is 170510 times. Therefore, at a clock frequency of 200M, the number of FLOPS per second is 170510×200×10 6 / 233=146.36G.
[0063] Then, on the simulation platform PyCharm, use the CPU model of Intel E3-1230V2@3.30GHz and the GPU model of TitanX to complete the calculation of the architecture in Example 1, and the calculation time of CPU and GPU processing a sample is respectively 3620ns and 105ns, so the number of floating-point operations per second of the CPU is 47.10GFLOPs, and the number of floating-point operations per second of the GPU is 1623.90GFLOPs.
[0064] The speed and power consumption performance analysis comparison diagram of the architecture of Example 1 implemented in FPGA...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com