

Noisy speech gender identification method and system based on lightweight neural network
A technology of gender recognition and neural network, which is applied in the field of noise-containing speech gender recognition methods and systems, can solve problems such as difficult to extract audio features, low accuracy of male and female voice recognition, and small models, so as to avoid the superposition of time delay and improve Accuracy, Effect of Simplified Algorithms
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
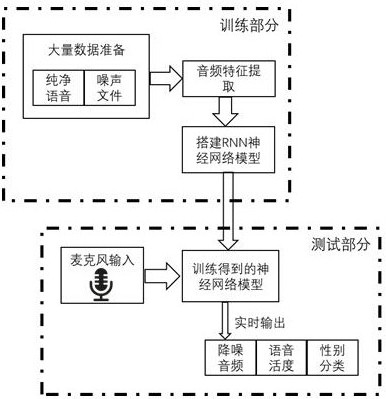
[0056] like figure 1 and figure 2 As shown, the present invention provides a kind of noise-containing speech gender recognition method based on lightweight neural network, and the method comprises the following steps:
[0057] S100: Mix pure male and female speech audio and pure noise audio to synthesize noisy speech.
[0058] S110: Collect pure male and female voice audio; use the pure male and female voice data in the TIMIT open source corpus and Librivox free audiobook audio prediction library, the number of pure male and female voice samples is 1:1, and the sampling rate is self-determined, only the sampling rate of the audio to be predicted and The sampling rate of the training samples here should be the same, for example, the sampling rate of the samples is 16kHz (but not limited to this);
[0059] S120: Complete the voice activity labeling and male and female category labeling corresponding to the pure voice; since it is pure voice, use the data window length of 30 m...
Embodiment 2
[0107] like Figure 10 As shown, the present invention provides a noise-containing speech gender recognition system based on a lightweight neural network, including a noise-containing speech synthesis module, an audio feature extraction module, a lightweight neural network model construction and training module, and a gender prediction module;
[0108] The noisy speech synthesis module is used to mix pure male and female voice audio and pure noise audio to synthesize noisy speech;
[0109] The audio feature extraction module is used to extract the audio feature of the noise-containing speech; the audio feature only includes: multiple BFCC features and first-order derivatives and second-order derivatives of some BFCC features, pitch gain value, fundamental frequency cycle value, voice short-term Zero crossing rate;
[0110] The lightweight neural network model construction and training module is used to construct and train a lightweight neural network model based on audio feat...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More