

Active Memory Expansion in Genetic Research: Data Volume Management
MAR 19, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Genetic Data Storage Evolution and Research Goals
The evolution of genetic data storage has undergone a remarkable transformation over the past three decades, fundamentally reshaping how researchers approach genomic analysis and biological discovery. Initially, genetic research relied on limited computational infrastructure capable of handling only small-scale sequencing projects, with the Human Genome Project representing the pinnacle of early genomic endeavors requiring over a decade and billions of dollars to complete.
The advent of next-generation sequencing technologies around 2005 marked a pivotal shift in data generation capabilities. Sequencing costs plummeted from thousands of dollars per genome to under $1,000 today, while throughput increased exponentially. This technological leap created an unprecedented data deluge, with modern sequencing platforms generating terabytes of raw data daily. Single research institutions now routinely produce more genetic data in a month than the entire scientific community generated in the previous decade.
Contemporary genetic research encompasses diverse data types beyond traditional DNA sequences, including RNA expression profiles, epigenetic modifications, protein interactions, and multi-omics datasets. Each category demands specialized storage architectures and processing methodologies. The complexity is further amplified by the integration of population-scale studies, longitudinal cohorts, and real-time clinical genomics applications.
Current storage paradigms face critical limitations in scalability, accessibility, and cost-effectiveness. Traditional file systems struggle with the massive scale and heterogeneous nature of genomic datasets. Cloud-based solutions offer improved scalability but introduce concerns regarding data sovereignty, transfer costs, and computational proximity. The challenge extends beyond mere storage capacity to encompass data organization, metadata management, and efficient retrieval mechanisms.
The primary research goals driving active memory expansion initiatives focus on developing intelligent storage systems that can dynamically adapt to varying workload demands while maintaining optimal performance. These systems must seamlessly integrate with existing bioinformatics pipelines while providing transparent access to both frequently accessed "hot" data and archived "cold" datasets.
Advanced compression algorithms specifically designed for genomic data represent another crucial objective. Unlike generic compression methods, genomic-specific approaches leverage biological patterns and redundancies to achieve superior compression ratios without compromising data integrity or analysis speed.
Federated storage architectures emerge as essential goals for enabling collaborative research across institutions while respecting privacy regulations and data governance requirements. These systems must facilitate secure data sharing and joint analysis without requiring physical data movement.
The advent of next-generation sequencing technologies around 2005 marked a pivotal shift in data generation capabilities. Sequencing costs plummeted from thousands of dollars per genome to under $1,000 today, while throughput increased exponentially. This technological leap created an unprecedented data deluge, with modern sequencing platforms generating terabytes of raw data daily. Single research institutions now routinely produce more genetic data in a month than the entire scientific community generated in the previous decade.
Contemporary genetic research encompasses diverse data types beyond traditional DNA sequences, including RNA expression profiles, epigenetic modifications, protein interactions, and multi-omics datasets. Each category demands specialized storage architectures and processing methodologies. The complexity is further amplified by the integration of population-scale studies, longitudinal cohorts, and real-time clinical genomics applications.
Current storage paradigms face critical limitations in scalability, accessibility, and cost-effectiveness. Traditional file systems struggle with the massive scale and heterogeneous nature of genomic datasets. Cloud-based solutions offer improved scalability but introduce concerns regarding data sovereignty, transfer costs, and computational proximity. The challenge extends beyond mere storage capacity to encompass data organization, metadata management, and efficient retrieval mechanisms.
The primary research goals driving active memory expansion initiatives focus on developing intelligent storage systems that can dynamically adapt to varying workload demands while maintaining optimal performance. These systems must seamlessly integrate with existing bioinformatics pipelines while providing transparent access to both frequently accessed "hot" data and archived "cold" datasets.
Advanced compression algorithms specifically designed for genomic data represent another crucial objective. Unlike generic compression methods, genomic-specific approaches leverage biological patterns and redundancies to achieve superior compression ratios without compromising data integrity or analysis speed.
Federated storage architectures emerge as essential goals for enabling collaborative research across institutions while respecting privacy regulations and data governance requirements. These systems must facilitate secure data sharing and joint analysis without requiring physical data movement.
Market Demand for Genomic Data Management Solutions
The genomic data management solutions market is experiencing unprecedented growth driven by the exponential increase in genetic research activities worldwide. Healthcare institutions, pharmaceutical companies, and research organizations are generating massive volumes of genomic data that require sophisticated storage, processing, and analysis capabilities. The complexity of managing multi-terabyte datasets from whole genome sequencing, population studies, and personalized medicine initiatives has created substantial demand for advanced data management platforms.
Precision medicine represents one of the most significant market drivers, as healthcare providers seek to leverage genomic information for personalized treatment strategies. The integration of genomic data with electronic health records and clinical decision support systems requires robust data management infrastructure capable of handling real-time processing and secure data sharing across multiple stakeholders.
Research institutions face mounting pressure to manage increasingly large genomic datasets while maintaining data integrity and accessibility. The need for collaborative research platforms that enable secure data sharing between institutions has intensified, particularly for large-scale population genomics studies and international research consortiums. These organizations require solutions that can scale dynamically to accommodate varying computational demands and storage requirements.
The pharmaceutical industry represents a substantial market segment, with companies investing heavily in genomic data analytics for drug discovery and development. The ability to process and analyze genomic data efficiently directly impacts research timelines and development costs, making advanced data management solutions critical for maintaining competitive advantage.
Cloud-based genomic data management solutions are gaining significant traction due to their scalability and cost-effectiveness. Organizations are increasingly adopting hybrid cloud architectures that combine on-premises infrastructure with cloud resources to optimize performance and manage costs while ensuring data security and regulatory compliance.
Regulatory compliance requirements, particularly in healthcare and clinical research environments, drive demand for solutions that incorporate robust security features, audit trails, and data governance capabilities. The need to comply with regulations such as HIPAA, GDPR, and FDA guidelines for genomic data handling creates additional market opportunities for specialized compliance-focused solutions.
The market also encompasses emerging applications in agriculture, environmental research, and biotechnology, where genomic data management solutions support crop improvement programs, biodiversity studies, and industrial biotechnology applications. These diverse application areas contribute to the overall market expansion and create opportunities for specialized solutions tailored to specific industry requirements.
Precision medicine represents one of the most significant market drivers, as healthcare providers seek to leverage genomic information for personalized treatment strategies. The integration of genomic data with electronic health records and clinical decision support systems requires robust data management infrastructure capable of handling real-time processing and secure data sharing across multiple stakeholders.
Research institutions face mounting pressure to manage increasingly large genomic datasets while maintaining data integrity and accessibility. The need for collaborative research platforms that enable secure data sharing between institutions has intensified, particularly for large-scale population genomics studies and international research consortiums. These organizations require solutions that can scale dynamically to accommodate varying computational demands and storage requirements.
The pharmaceutical industry represents a substantial market segment, with companies investing heavily in genomic data analytics for drug discovery and development. The ability to process and analyze genomic data efficiently directly impacts research timelines and development costs, making advanced data management solutions critical for maintaining competitive advantage.
Cloud-based genomic data management solutions are gaining significant traction due to their scalability and cost-effectiveness. Organizations are increasingly adopting hybrid cloud architectures that combine on-premises infrastructure with cloud resources to optimize performance and manage costs while ensuring data security and regulatory compliance.
Regulatory compliance requirements, particularly in healthcare and clinical research environments, drive demand for solutions that incorporate robust security features, audit trails, and data governance capabilities. The need to comply with regulations such as HIPAA, GDPR, and FDA guidelines for genomic data handling creates additional market opportunities for specialized compliance-focused solutions.
The market also encompasses emerging applications in agriculture, environmental research, and biotechnology, where genomic data management solutions support crop improvement programs, biodiversity studies, and industrial biotechnology applications. These diverse application areas contribute to the overall market expansion and create opportunities for specialized solutions tailored to specific industry requirements.
Current State of Active Memory in Genetic Computing
Active memory technologies in genetic computing have evolved significantly over the past decade, driven by the exponential growth of genomic datasets and the computational demands of modern bioinformatics applications. Current implementations primarily rely on hybrid memory architectures that combine traditional DRAM with emerging non-volatile memory technologies such as Intel Optane DC Persistent Memory and Samsung Z-NAND. These solutions enable genetic research platforms to maintain larger working datasets in memory while providing persistence capabilities essential for long-running genomic analyses.
The predominant approach in contemporary genetic computing environments involves tiered memory management systems that automatically migrate data between different memory layers based on access patterns and computational requirements. Leading genomic analysis platforms like GATK, BWA-MEM, and Trinity have integrated memory-aware algorithms that can dynamically adjust their memory footprint based on available active memory capacity. These implementations typically achieve 2-3x performance improvements compared to traditional storage-based approaches when processing large-scale whole genome sequencing datasets.
Current active memory solutions face significant scalability challenges when handling population-scale genomic studies involving thousands of samples. The memory bandwidth bottleneck becomes particularly pronounced during variant calling operations and phylogenetic analyses, where random access patterns dominate the computational workflow. Existing systems struggle to maintain consistent performance when active memory utilization exceeds 80% capacity, leading to frequent memory swapping and degraded analytical throughput.
Major cloud computing providers have developed specialized genetic computing instances that incorporate high-capacity active memory configurations. Amazon EC2 X1e instances provide up to 3.8TB of DRAM, while Google Cloud offers memory-optimized instances with persistent memory integration specifically designed for genomic workloads. However, these solutions remain cost-prohibitive for many research institutions, limiting widespread adoption of active memory expansion technologies.
The current technological landscape reveals a critical gap between available active memory capacity and the growing demands of multi-omics data integration. Emerging approaches focus on intelligent data compression algorithms and memory-efficient data structures that can reduce the active memory footprint of genetic datasets by 40-60% without compromising analytical accuracy. These developments represent the current frontier in addressing the fundamental challenge of data volume management in genetic research computing environments.
The predominant approach in contemporary genetic computing environments involves tiered memory management systems that automatically migrate data between different memory layers based on access patterns and computational requirements. Leading genomic analysis platforms like GATK, BWA-MEM, and Trinity have integrated memory-aware algorithms that can dynamically adjust their memory footprint based on available active memory capacity. These implementations typically achieve 2-3x performance improvements compared to traditional storage-based approaches when processing large-scale whole genome sequencing datasets.
Current active memory solutions face significant scalability challenges when handling population-scale genomic studies involving thousands of samples. The memory bandwidth bottleneck becomes particularly pronounced during variant calling operations and phylogenetic analyses, where random access patterns dominate the computational workflow. Existing systems struggle to maintain consistent performance when active memory utilization exceeds 80% capacity, leading to frequent memory swapping and degraded analytical throughput.
Major cloud computing providers have developed specialized genetic computing instances that incorporate high-capacity active memory configurations. Amazon EC2 X1e instances provide up to 3.8TB of DRAM, while Google Cloud offers memory-optimized instances with persistent memory integration specifically designed for genomic workloads. However, these solutions remain cost-prohibitive for many research institutions, limiting widespread adoption of active memory expansion technologies.
The current technological landscape reveals a critical gap between available active memory capacity and the growing demands of multi-omics data integration. Emerging approaches focus on intelligent data compression algorithms and memory-efficient data structures that can reduce the active memory footprint of genetic datasets by 40-60% without compromising analytical accuracy. These developments represent the current frontier in addressing the fundamental challenge of data volume management in genetic research computing environments.
Existing Active Memory Solutions for Genetic Data
01 Virtual memory management and expansion techniques
Systems and methods for expanding available memory through virtual memory management, including techniques for mapping virtual addresses to physical memory locations, managing page tables, and implementing memory expansion beyond physical RAM limitations. These approaches enable efficient utilization of storage devices as extended memory space.- Virtual memory management and expansion techniques: Systems and methods for expanding available memory through virtual memory management, including techniques for mapping virtual addresses to physical memory locations, managing page tables, and implementing memory expansion beyond physical RAM limitations. These approaches enable efficient utilization of storage devices as extended memory space.
- Dynamic memory allocation and compression: Technologies for dynamically expanding memory capacity through compression algorithms and intelligent allocation strategies. These methods involve compressing inactive data in memory, implementing adaptive compression ratios, and managing compressed memory pools to effectively increase available memory without additional hardware.
- Tiered memory architecture and storage class memory: Hierarchical memory systems that combine different memory technologies to create expanded memory pools. These architectures utilize multiple memory tiers with varying performance characteristics, enabling seamless data migration between fast and slow memory layers to optimize capacity and performance.
- Memory pooling and resource sharing: Techniques for aggregating memory resources across multiple systems or nodes to create shared memory pools. These solutions enable memory expansion through network-attached memory, remote direct memory access, and distributed memory management protocols that allow applications to access memory beyond local physical constraints.
- Persistent memory and non-volatile memory expansion: Methods for utilizing non-volatile memory technologies to expand active memory capacity. These approaches leverage persistent memory devices that retain data without power, enabling larger memory footprints while maintaining performance characteristics similar to traditional volatile memory through specialized controllers and access protocols.
02 Dynamic memory allocation and compression
Technologies for dynamically expanding memory capacity through compression algorithms and intelligent allocation strategies. These methods involve compressing inactive data in memory, implementing adaptive compression ratios, and managing compressed memory pools to effectively increase available memory space without additional hardware.Expand Specific Solutions03 Tiered memory architecture and storage integration
Hierarchical memory systems that integrate multiple storage tiers including RAM, flash memory, and disk storage to create expanded memory pools. These architectures employ intelligent data migration policies, hot/cold data classification, and automated tiering mechanisms to optimize performance while expanding effective memory capacity.Expand Specific Solutions04 Memory pooling and resource sharing
Techniques for aggregating memory resources across multiple systems or nodes to create shared memory pools. These solutions enable memory expansion through network-attached memory, distributed memory architectures, and resource pooling mechanisms that allow applications to access memory beyond local physical constraints.Expand Specific Solutions05 Persistent memory and non-volatile storage utilization
Methods for leveraging persistent memory technologies and non-volatile storage devices to expand active memory capacity. These approaches utilize storage-class memory, implement byte-addressable persistent storage, and provide mechanisms for treating non-volatile media as extended memory with near-DRAM performance characteristics.Expand Specific Solutions
Key Players in Genomic Computing Infrastructure
The active memory expansion in genetic research represents a rapidly evolving market driven by exponential data growth from next-generation sequencing and multi-omics studies. The industry is in a growth phase with significant market expansion, as genomic data volumes are doubling annually, creating urgent demands for scalable storage solutions. Technology maturity varies across segments, with established players like IBM, Hitachi Ltd., and Hewlett Packard Enterprise Development LP offering mature enterprise storage infrastructure, while specialized genomics companies such as BGI Genomics, Foundation Medicine, and Rosalind Inc. develop domain-specific solutions. Cloud providers like Inspur Cloud Information Technology are emerging as key enablers, offering scalable platforms for genomic data management. The competitive landscape spans traditional IT giants, specialized genomics firms, and academic institutions like University of Zurich and Washington University, indicating a diverse ecosystem addressing this critical technological challenge.
Hitachi Ltd.
Technical Solution: Hitachi develops active memory expansion solutions for genomic data management through their Advanced Server DS series and Hitachi Content Platform for healthcare data. Their approach combines high-capacity memory modules with intelligent data placement algorithms to optimize genomic data access patterns. The system utilizes non-volatile memory express technology and memory channel storage to create hybrid memory hierarchies that can accommodate large genomic datasets while maintaining low-latency access to frequently referenced sequences. Hitachi's solution includes automated memory tiering capabilities that analyze genomic data usage patterns and dynamically allocate memory resources based on research workflow requirements. The platform supports integration with major genomic analysis pipelines and provides enterprise-grade data protection features for sensitive genetic information.
Strengths: Enterprise reliability and security features, automated memory optimization, strong data protection capabilities. Weaknesses: Higher costs compared to commodity solutions, limited genomics-specific optimizations, complex deployment requirements.
International Business Machines Corp.
Technical Solution: IBM develops advanced memory expansion solutions for genomic data management through their Watson for Genomics platform and hybrid cloud infrastructure. Their approach combines high-performance computing with intelligent data tiering, utilizing NVMe storage arrays and memory-mapped file systems to handle petabyte-scale genomic datasets. The system employs machine learning algorithms to predict data access patterns and automatically migrate frequently accessed genomic sequences to high-speed memory while archiving cold data to cost-effective storage tiers. IBM's Power Systems servers with large memory configurations support real-time analysis of whole genome sequencing data, enabling researchers to process multiple genomes simultaneously without performance degradation.
Strengths: Enterprise-grade reliability, advanced AI-driven data management, scalable hybrid cloud architecture. Weaknesses: High implementation costs, complex system integration requirements, vendor lock-in concerns.
Core Innovations in Dynamic Memory Management
Active memory expansion in a database environment to query needed/uneeded results
PatentInactiveUS9009120B2
Innovation
- A method is implemented where a DBMS selectively uncompresses only the necessary data in response to queries, ignoring or partially uncompressing compressed data based on system conditions and query types to minimize resource usage and optimize query execution times.




Active memory expansion and rdbms meta data and tooling
PatentInactiveUS20120109908A1
Innovation
- Implement a method that identifies indicatory data associated with retrieved data to determine whether to compress it, using compression criteria to selectively compress data based on metadata, query types, and access frequencies, thereby optimizing memory usage and reducing processing time.
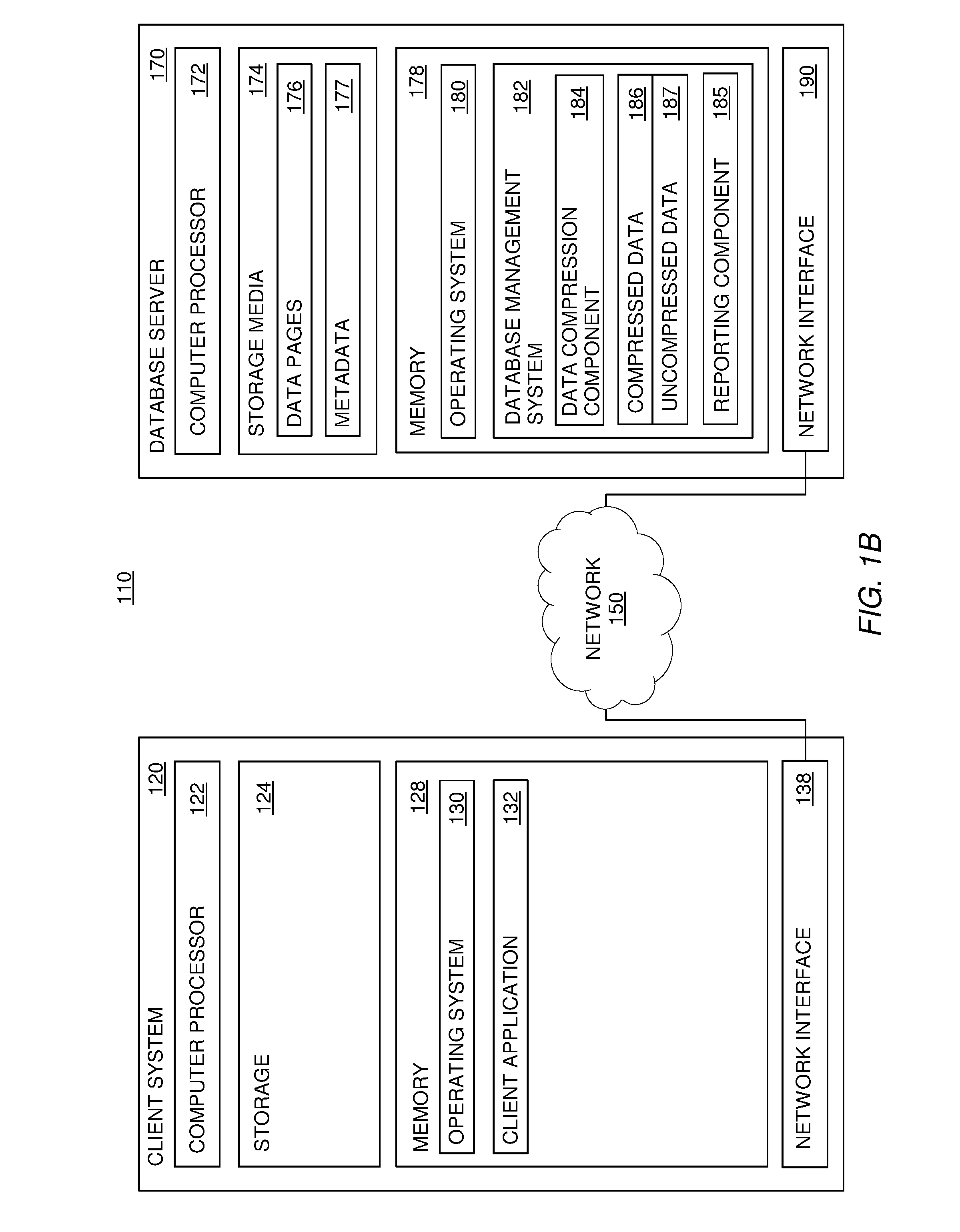

Data Privacy Regulations in Genetic Research
The management of vast genetic datasets in active memory expansion systems operates within an increasingly complex regulatory landscape that governs data privacy and protection. As genetic research generates unprecedented volumes of sensitive biological information, regulatory frameworks have evolved to address the unique challenges posed by genomic data handling, storage, and processing across different jurisdictions.
The General Data Protection Regulation (GDPR) in the European Union establishes stringent requirements for genetic data processing, classifying genomic information as special category data requiring explicit consent and enhanced protection measures. Under GDPR Article 9, genetic data processing for research purposes must demonstrate substantial public interest and implement appropriate safeguards, including data minimization principles that directly impact how active memory systems can cache and manage genetic datasets.
In the United States, the Genetic Information Nondiscrimination Act (GINA) provides foundational protections against genetic discrimination, while the Health Insurance Portability and Accountability Act (HIPAA) governs the handling of genetic information in healthcare contexts. These regulations create specific requirements for data encryption, access controls, and audit trails that must be integrated into active memory expansion architectures handling genetic research data.
The regulatory landscape becomes particularly complex when considering cross-border data transfers in collaborative genetic research projects. Active memory systems must accommodate varying national requirements, such as Canada's Personal Information Protection and Electronic Documents Act (PIPEDA) and emerging regulations in Asia-Pacific regions, each imposing distinct obligations for genetic data processing and storage.
Compliance challenges intensify with the dynamic nature of genetic research data, where active memory systems must maintain detailed provenance tracking and consent management across distributed computing environments. Regulations increasingly require granular control over data usage, including the ability to implement data subject rights such as erasure and portability, which presents technical challenges for high-performance memory expansion systems optimized for rapid data access.
Recent regulatory developments emphasize the need for privacy-by-design approaches in genetic research infrastructure. This includes implementing differential privacy techniques, federated learning architectures, and secure multi-party computation methods within active memory systems to ensure compliance while maintaining research utility and performance requirements.
The General Data Protection Regulation (GDPR) in the European Union establishes stringent requirements for genetic data processing, classifying genomic information as special category data requiring explicit consent and enhanced protection measures. Under GDPR Article 9, genetic data processing for research purposes must demonstrate substantial public interest and implement appropriate safeguards, including data minimization principles that directly impact how active memory systems can cache and manage genetic datasets.
In the United States, the Genetic Information Nondiscrimination Act (GINA) provides foundational protections against genetic discrimination, while the Health Insurance Portability and Accountability Act (HIPAA) governs the handling of genetic information in healthcare contexts. These regulations create specific requirements for data encryption, access controls, and audit trails that must be integrated into active memory expansion architectures handling genetic research data.
The regulatory landscape becomes particularly complex when considering cross-border data transfers in collaborative genetic research projects. Active memory systems must accommodate varying national requirements, such as Canada's Personal Information Protection and Electronic Documents Act (PIPEDA) and emerging regulations in Asia-Pacific regions, each imposing distinct obligations for genetic data processing and storage.
Compliance challenges intensify with the dynamic nature of genetic research data, where active memory systems must maintain detailed provenance tracking and consent management across distributed computing environments. Regulations increasingly require granular control over data usage, including the ability to implement data subject rights such as erasure and portability, which presents technical challenges for high-performance memory expansion systems optimized for rapid data access.
Recent regulatory developments emphasize the need for privacy-by-design approaches in genetic research infrastructure. This includes implementing differential privacy techniques, federated learning architectures, and secure multi-party computation methods within active memory systems to ensure compliance while maintaining research utility and performance requirements.
Scalability Challenges in Genomic Computing
The exponential growth of genomic data presents unprecedented scalability challenges that fundamentally reshape computational requirements in genetic research. Modern sequencing technologies generate terabytes of raw data per experiment, with whole genome sequencing projects producing datasets ranging from 30GB to over 200GB per individual sample. This data explosion creates a cascading effect across the entire computational pipeline, from initial data acquisition through final analysis and long-term storage.
Memory bandwidth limitations represent a critical bottleneck in genomic computing scalability. Traditional computing architectures struggle to maintain adequate data throughput when processing large-scale genomic datasets, particularly during memory-intensive operations such as sequence alignment, variant calling, and population-scale analyses. The mismatch between processor speed and memory access rates becomes increasingly pronounced as dataset sizes grow exponentially, creating significant performance degradation that scales non-linearly with data volume.
Parallel processing complexities emerge as another fundamental scalability challenge. Genomic algorithms often exhibit irregular memory access patterns and data dependencies that resist efficient parallelization. Load balancing becomes increasingly difficult when processing heterogeneous genomic datasets with varying computational requirements across different genomic regions. The overhead associated with data distribution and synchronization across multiple processing units can significantly impact overall system performance.
Storage infrastructure scalability presents both technical and economic challenges. The need for high-performance storage systems capable of supporting concurrent read/write operations while maintaining data integrity creates substantial infrastructure requirements. Network bandwidth limitations further compound these challenges, particularly in distributed computing environments where data must be transferred between storage systems and processing nodes.
Real-time processing demands add another layer of complexity to genomic computing scalability. Applications requiring immediate analysis results, such as clinical diagnostics or real-time monitoring systems, must maintain consistent performance levels regardless of dataset size. This requirement necessitates sophisticated resource management strategies and often requires over-provisioning of computational resources to handle peak workloads.
The heterogeneous nature of genomic data types further complicates scalability solutions. Different analysis workflows exhibit varying computational characteristics, memory access patterns, and storage requirements, making it challenging to develop unified scalability approaches that efficiently handle diverse genomic computing workloads across different research domains and application scenarios.
Memory bandwidth limitations represent a critical bottleneck in genomic computing scalability. Traditional computing architectures struggle to maintain adequate data throughput when processing large-scale genomic datasets, particularly during memory-intensive operations such as sequence alignment, variant calling, and population-scale analyses. The mismatch between processor speed and memory access rates becomes increasingly pronounced as dataset sizes grow exponentially, creating significant performance degradation that scales non-linearly with data volume.
Parallel processing complexities emerge as another fundamental scalability challenge. Genomic algorithms often exhibit irregular memory access patterns and data dependencies that resist efficient parallelization. Load balancing becomes increasingly difficult when processing heterogeneous genomic datasets with varying computational requirements across different genomic regions. The overhead associated with data distribution and synchronization across multiple processing units can significantly impact overall system performance.
Storage infrastructure scalability presents both technical and economic challenges. The need for high-performance storage systems capable of supporting concurrent read/write operations while maintaining data integrity creates substantial infrastructure requirements. Network bandwidth limitations further compound these challenges, particularly in distributed computing environments where data must be transferred between storage systems and processing nodes.
Real-time processing demands add another layer of complexity to genomic computing scalability. Applications requiring immediate analysis results, such as clinical diagnostics or real-time monitoring systems, must maintain consistent performance levels regardless of dataset size. This requirement necessitates sophisticated resource management strategies and often requires over-provisioning of computational resources to handle peak workloads.
The heterogeneous nature of genomic data types further complicates scalability solutions. Different analysis workflows exhibit varying computational characteristics, memory access patterns, and storage requirements, making it challenging to develop unified scalability approaches that efficiently handle diverse genomic computing workloads across different research domains and application scenarios.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!