

AI Accelerators for High-Performance NLP Model Training: How to Scale
MAY 19, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
AI Accelerator Evolution and NLP Training Goals
The evolution of AI accelerators has been fundamentally driven by the exponential growth in computational demands of deep learning models, particularly in natural language processing. From the early adoption of Graphics Processing Units (GPUs) for parallel computing in the 2010s to the emergence of specialized tensor processing units and neuromorphic chips, the hardware landscape has continuously adapted to meet the scaling requirements of increasingly complex NLP architectures.
The transition from traditional CPU-based training to GPU acceleration marked the first major milestone, enabling researchers to train larger neural networks with millions of parameters. This shift was followed by the development of purpose-built AI chips, including Google's Tensor Processing Units (TPUs), NVIDIA's specialized AI GPUs, and emerging solutions from companies like Cerebras and Graphcore, each designed to optimize specific aspects of neural network computation.
Modern NLP model training faces unprecedented scaling challenges, with transformer-based architectures like GPT and BERT requiring massive computational resources. The goal of contemporary AI accelerator development centers on achieving efficient distributed training across multiple devices while maintaining numerical stability and convergence properties. This involves optimizing memory bandwidth utilization, reducing communication overhead in multi-node setups, and implementing advanced parallelization strategies.
The primary technical objectives include minimizing training time for large language models through improved tensor operations, enabling mixed-precision training to reduce memory footprint without sacrificing model quality, and supporting dynamic computational graphs that modern NLP frameworks demand. Additionally, accelerators must handle the irregular memory access patterns characteristic of attention mechanisms and support efficient gradient synchronization across distributed training environments.
Energy efficiency has emerged as a critical design goal, as training state-of-the-art NLP models can consume megawatt-hours of electricity. Modern accelerator architectures incorporate specialized matrix multiplication units, optimized memory hierarchies, and advanced cooling solutions to maximize performance per watt. The integration of emerging technologies like photonic computing and in-memory processing represents the next frontier in addressing the computational intensity of large-scale NLP model training.
The transition from traditional CPU-based training to GPU acceleration marked the first major milestone, enabling researchers to train larger neural networks with millions of parameters. This shift was followed by the development of purpose-built AI chips, including Google's Tensor Processing Units (TPUs), NVIDIA's specialized AI GPUs, and emerging solutions from companies like Cerebras and Graphcore, each designed to optimize specific aspects of neural network computation.
Modern NLP model training faces unprecedented scaling challenges, with transformer-based architectures like GPT and BERT requiring massive computational resources. The goal of contemporary AI accelerator development centers on achieving efficient distributed training across multiple devices while maintaining numerical stability and convergence properties. This involves optimizing memory bandwidth utilization, reducing communication overhead in multi-node setups, and implementing advanced parallelization strategies.
The primary technical objectives include minimizing training time for large language models through improved tensor operations, enabling mixed-precision training to reduce memory footprint without sacrificing model quality, and supporting dynamic computational graphs that modern NLP frameworks demand. Additionally, accelerators must handle the irregular memory access patterns characteristic of attention mechanisms and support efficient gradient synchronization across distributed training environments.
Energy efficiency has emerged as a critical design goal, as training state-of-the-art NLP models can consume megawatt-hours of electricity. Modern accelerator architectures incorporate specialized matrix multiplication units, optimized memory hierarchies, and advanced cooling solutions to maximize performance per watt. The integration of emerging technologies like photonic computing and in-memory processing represents the next frontier in addressing the computational intensity of large-scale NLP model training.
Market Demand for High-Performance NLP Training Solutions
The global demand for high-performance NLP training solutions has experienced unprecedented growth, driven by the exponential expansion of large language models and their widespread adoption across industries. Organizations ranging from technology giants to financial institutions are increasingly recognizing the strategic importance of deploying sophisticated NLP capabilities to maintain competitive advantages in data-driven markets.
Enterprise adoption patterns reveal a significant shift toward custom NLP model development rather than relying solely on third-party APIs. This transition stems from requirements for domain-specific optimization, data privacy concerns, and the need for greater control over model behavior. Companies are investing heavily in internal AI infrastructure to support proprietary language model training, creating substantial demand for specialized acceleration hardware.
The computational requirements for modern NLP training have grown exponentially with model complexity. Training state-of-the-art transformer architectures requires massive parallel processing capabilities that traditional computing infrastructure cannot efficiently support. This computational bottleneck has created urgent market demand for purpose-built AI accelerators capable of handling the unique workload characteristics of NLP training, including attention mechanisms and sequence processing.
Cloud service providers represent a major demand segment, as they seek to offer competitive NLP training services while managing operational costs. The economics of cloud-based model training directly depend on hardware efficiency, making AI accelerators essential for maintaining profitable service margins while delivering acceptable training times to customers.
Research institutions and academic organizations constitute another significant demand driver, particularly as government funding for AI research increases globally. These entities require cost-effective solutions for training large-scale models within budget constraints, creating demand for both high-performance and economically viable acceleration solutions.
The pharmaceutical and biotechnology sectors have emerged as unexpected but substantial consumers of NLP training infrastructure, utilizing language models for drug discovery, scientific literature analysis, and regulatory document processing. These applications require specialized training approaches that benefit significantly from dedicated acceleration hardware.
Market dynamics indicate strong growth momentum, with demand consistently outpacing supply capacity. This imbalance has created opportunities for innovative acceleration solutions that can address specific NLP training challenges while offering superior price-performance ratios compared to general-purpose alternatives.
Enterprise adoption patterns reveal a significant shift toward custom NLP model development rather than relying solely on third-party APIs. This transition stems from requirements for domain-specific optimization, data privacy concerns, and the need for greater control over model behavior. Companies are investing heavily in internal AI infrastructure to support proprietary language model training, creating substantial demand for specialized acceleration hardware.
The computational requirements for modern NLP training have grown exponentially with model complexity. Training state-of-the-art transformer architectures requires massive parallel processing capabilities that traditional computing infrastructure cannot efficiently support. This computational bottleneck has created urgent market demand for purpose-built AI accelerators capable of handling the unique workload characteristics of NLP training, including attention mechanisms and sequence processing.
Cloud service providers represent a major demand segment, as they seek to offer competitive NLP training services while managing operational costs. The economics of cloud-based model training directly depend on hardware efficiency, making AI accelerators essential for maintaining profitable service margins while delivering acceptable training times to customers.
Research institutions and academic organizations constitute another significant demand driver, particularly as government funding for AI research increases globally. These entities require cost-effective solutions for training large-scale models within budget constraints, creating demand for both high-performance and economically viable acceleration solutions.
The pharmaceutical and biotechnology sectors have emerged as unexpected but substantial consumers of NLP training infrastructure, utilizing language models for drug discovery, scientific literature analysis, and regulatory document processing. These applications require specialized training approaches that benefit significantly from dedicated acceleration hardware.
Market dynamics indicate strong growth momentum, with demand consistently outpacing supply capacity. This imbalance has created opportunities for innovative acceleration solutions that can address specific NLP training challenges while offering superior price-performance ratios compared to general-purpose alternatives.
Current AI Accelerator Limitations in NLP Model Scaling
Current AI accelerators face significant architectural constraints when scaling NLP model training, particularly as transformer models grow beyond hundreds of billions of parameters. Traditional GPU architectures, while powerful for parallel computation, encounter memory bandwidth bottlenecks that severely limit their effectiveness for large language model training. The memory wall problem becomes increasingly pronounced as model sizes expand, with GPU memory capacity often insufficient to accommodate the full model parameters, gradients, and optimizer states simultaneously.
Memory hierarchy inefficiencies represent another critical limitation in existing accelerator designs. Current accelerators rely heavily on high-bandwidth memory (HBM) that, despite its speed advantages, cannot keep pace with the computational throughput demands of massive transformer architectures. This mismatch creates idle compute cycles where processing units wait for data transfers, significantly reducing overall training efficiency and extending training timelines from weeks to months.
Interconnect bandwidth constraints further compound scaling challenges in distributed training scenarios. Existing accelerator interconnects, including NVLink and InfiniBand, struggle to maintain efficient communication patterns required for gradient synchronization across hundreds or thousands of devices. The all-reduce operations necessary for parameter updates become increasingly expensive as the number of participating accelerators grows, creating communication overhead that can consume up to 40% of total training time.
Power efficiency limitations pose substantial barriers to large-scale deployment. Current accelerators consume excessive power per operation, making it economically unfeasible to scale training clusters beyond certain thresholds. The power-to-performance ratio becomes particularly problematic for attention mechanisms, which require quadratic computational complexity relative to sequence length, leading to exponentially increasing energy costs for longer context processing.
Precision and numerical stability issues emerge as additional constraints when scaling training workloads. Existing accelerators often rely on mixed-precision training to improve throughput, but this approach introduces gradient underflow problems in very large models. The accumulation of numerical errors across extended training runs can destabilize convergence, requiring frequent checkpointing and recovery procedures that further extend training duration and increase computational overhead.
Memory hierarchy inefficiencies represent another critical limitation in existing accelerator designs. Current accelerators rely heavily on high-bandwidth memory (HBM) that, despite its speed advantages, cannot keep pace with the computational throughput demands of massive transformer architectures. This mismatch creates idle compute cycles where processing units wait for data transfers, significantly reducing overall training efficiency and extending training timelines from weeks to months.
Interconnect bandwidth constraints further compound scaling challenges in distributed training scenarios. Existing accelerator interconnects, including NVLink and InfiniBand, struggle to maintain efficient communication patterns required for gradient synchronization across hundreds or thousands of devices. The all-reduce operations necessary for parameter updates become increasingly expensive as the number of participating accelerators grows, creating communication overhead that can consume up to 40% of total training time.
Power efficiency limitations pose substantial barriers to large-scale deployment. Current accelerators consume excessive power per operation, making it economically unfeasible to scale training clusters beyond certain thresholds. The power-to-performance ratio becomes particularly problematic for attention mechanisms, which require quadratic computational complexity relative to sequence length, leading to exponentially increasing energy costs for longer context processing.
Precision and numerical stability issues emerge as additional constraints when scaling training workloads. Existing accelerators often rely on mixed-precision training to improve throughput, but this approach introduces gradient underflow problems in very large models. The accumulation of numerical errors across extended training runs can destabilize convergence, requiring frequent checkpointing and recovery procedures that further extend training duration and increase computational overhead.
Existing Scaling Solutions for NLP Model Training
01 Hardware architecture optimization for AI acceleration
Advanced hardware architectures are designed to optimize AI workload processing through specialized processing units, memory hierarchies, and interconnect systems. These architectures focus on parallel processing capabilities, reduced latency, and improved throughput for machine learning operations. The designs incorporate dedicated tensor processing units, optimized data paths, and enhanced computational efficiency to handle complex AI algorithms.- Hardware architecture optimization for AI acceleration: Advanced hardware architectures are designed to optimize AI workload processing through specialized processing units, memory hierarchies, and interconnect systems. These architectures focus on parallel processing capabilities, reduced latency, and improved throughput for machine learning operations. The designs incorporate custom silicon solutions, neuromorphic computing elements, and domain-specific accelerators to enhance computational efficiency for AI applications.
- Distributed computing and multi-node scalability: Scalable AI systems utilize distributed computing frameworks that enable workload distribution across multiple processing nodes. These systems implement load balancing mechanisms, fault tolerance protocols, and dynamic resource allocation to handle increasing computational demands. The architecture supports horizontal scaling through cluster management and coordinated processing across heterogeneous computing environments.
- Memory management and data flow optimization: Efficient memory management systems are crucial for AI accelerator performance, implementing advanced caching strategies, data prefetching, and bandwidth optimization techniques. These systems manage data movement between different memory levels, reduce memory bottlenecks, and optimize data locality for improved processing efficiency. The solutions include intelligent memory controllers and adaptive data placement algorithms.
- Performance monitoring and adaptive optimization: Real-time performance monitoring systems track AI accelerator metrics and implement adaptive optimization strategies to maintain peak performance. These systems analyze computational patterns, identify bottlenecks, and dynamically adjust system parameters to optimize resource utilization. The monitoring frameworks provide feedback mechanisms for continuous performance improvement and workload-specific tuning.
- Power efficiency and thermal management: Power-efficient AI accelerators incorporate advanced power management techniques and thermal control systems to maintain optimal performance while minimizing energy consumption. These solutions implement dynamic voltage and frequency scaling, intelligent power gating, and thermal-aware scheduling algorithms. The designs balance computational performance with power constraints to enable sustainable high-performance AI processing.
02 Scalable distributed computing frameworks for AI workloads
Distributed computing frameworks enable AI accelerators to scale across multiple nodes and processing units, allowing for efficient handling of large-scale machine learning tasks. These frameworks implement load balancing, resource allocation, and communication protocols to coordinate processing across distributed systems. The solutions focus on maintaining performance consistency while scaling computational resources dynamically based on workload demands.Expand Specific Solutions03 Memory management and data flow optimization
Advanced memory management techniques optimize data movement and storage in AI accelerator systems to minimize bottlenecks and improve overall performance. These approaches include intelligent caching strategies, memory bandwidth optimization, and efficient data prefetching mechanisms. The solutions address the challenge of managing large datasets and model parameters while maintaining high-speed access patterns required for AI computations.Expand Specific Solutions04 Performance monitoring and adaptive optimization
Real-time performance monitoring systems track AI accelerator metrics and implement adaptive optimization strategies to maintain peak efficiency. These systems analyze computational patterns, resource utilization, and thermal characteristics to dynamically adjust operating parameters. The monitoring frameworks provide feedback mechanisms that enable automatic tuning of processing schedules, power management, and resource allocation to optimize performance under varying workload conditions.Expand Specific Solutions05 Power efficiency and thermal management in AI accelerators
Power management techniques focus on optimizing energy consumption while maintaining high performance in AI accelerator systems. These solutions implement dynamic voltage and frequency scaling, intelligent power gating, and thermal-aware scheduling algorithms. The approaches balance computational performance with energy efficiency requirements, incorporating advanced cooling strategies and power delivery optimization to ensure sustainable operation under intensive AI workloads.Expand Specific Solutions
Leading AI Accelerator and NLP Platform Providers
The AI accelerator market for high-performance NLP model training is experiencing rapid growth as the industry transitions from early adoption to mainstream deployment. The market has reached multi-billion dollar scale, driven by increasing demand for large language models and generative AI applications. Technology maturity varies significantly across players, with established leaders like NVIDIA and Samsung Electronics offering proven GPU and memory solutions, while Chinese companies including Huawei Technologies, Biren Technology, and Hygon Information Technology are developing competitive alternatives. Emerging specialists such as D-Matrix and Mythic are pioneering novel architectures like digital in-memory computing to address specific inference and edge deployment challenges. Cloud providers like Huawei Cloud and major tech companies including Microsoft, Tencent, and Baidu are integrating these accelerators into comprehensive AI platforms, indicating strong ecosystem development and market validation for scalable NLP training solutions.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei's Ascend series processors, particularly the Ascend 910B, are designed for large-scale AI training workloads. The architecture features a custom Da Vinci core optimized for matrix operations common in transformer models, delivering competitive performance per watt ratios. Their MindSpore framework provides distributed training capabilities across Ascend clusters, supporting automatic parallelization strategies including data, model, and pipeline parallelism. The Ascend platform integrates with their Atlas training servers to create end-to-end solutions for NLP model development, featuring advanced memory hierarchies and interconnect technologies for scaling to thousands of processors in distributed training scenarios.
Strengths: Strong performance-per-watt, integrated software stack, competitive pricing. Weaknesses: Limited global availability, smaller ecosystem compared to NVIDIA, geopolitical restrictions.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft develops custom AI accelerators through their Azure infrastructure, including partnerships with hardware vendors and internal chip development initiatives. Their approach focuses on optimizing cloud-based training through specialized silicon and software co-design. Microsoft's DeepSpeed framework enables efficient distributed training of large language models, supporting techniques like ZeRO optimizer states partitioning and gradient compression. Their Azure AI infrastructure provides scalable training environments with custom networking and storage optimizations specifically designed for large NLP workloads, integrating with their cognitive services and OpenAI partnership to deliver production-ready training pipelines.
Strengths: Cloud-native optimization, strong software integration, enterprise-grade reliability. Weaknesses: Primarily cloud-focused, limited on-premises solutions, dependency on third-party hardware.
Core Innovations in AI Accelerator Architecture for NLP
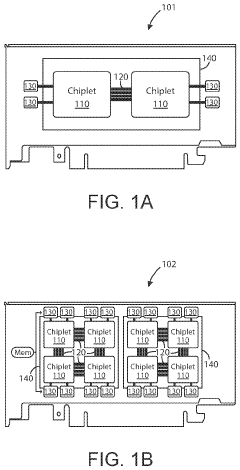
Ai accelerator apparatus using in-memory compute chiplet devices for transformer workloads
PatentActiveUS20240241841A1
Innovation
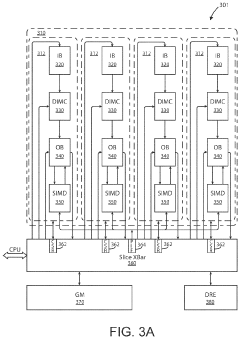
- The implementation of AI accelerator apparatuses using chiplet devices with digital in-memory compute functionality, which integrate computational functions and memory fabric, and include SIMD devices to accelerate attention functions and softmax computations, enabling high-throughput operations and reduced power consumption.




Generative ai accelerator apparatus using in-memory compute chiplet devices for transformer workloads
PatentActiveUS20230168899A1
Innovation
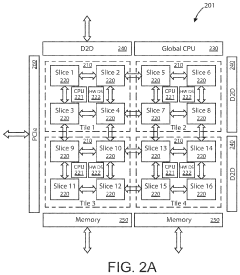
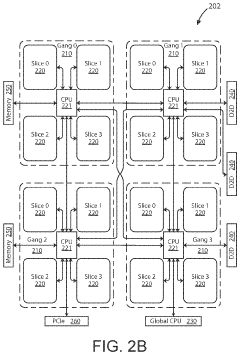
- The implementation of AI accelerator apparatuses using chiplet devices with digital in-memory compute functionality, which includes multiple slices with CPUs and hardware dispatch devices, along with die-to-die interconnects and PCIe buses, to accelerate transformer computations by integrating computational functions and memory fabric, enabling efficient processing and reducing power consumption.
Energy Efficiency Standards for Large-Scale AI Training
The exponential growth in computational demands for large-scale NLP model training has necessitated the establishment of comprehensive energy efficiency standards to address environmental sustainability and operational cost concerns. Current training operations for transformer-based models with billions of parameters consume substantial electrical power, often requiring megawatt-scale data centers that operate continuously for weeks or months.
Industry leaders have begun implementing power usage effectiveness (PUE) metrics specifically tailored for AI workloads, extending beyond traditional data center measurements. These specialized metrics account for the dynamic power consumption patterns characteristic of deep learning training, including GPU utilization spikes, memory bandwidth bottlenecks, and thermal management requirements. Leading cloud providers now report AI-specific energy consumption data, with targets of achieving PUE ratios below 1.2 for dedicated AI training facilities.
Regulatory frameworks are emerging across multiple jurisdictions to establish mandatory energy reporting requirements for large-scale AI training operations. The European Union's proposed AI Act includes provisions for energy disclosure when training models exceed specific computational thresholds, measured in floating-point operations. Similar initiatives in California and Singapore focus on carbon footprint reporting and renewable energy sourcing requirements for AI infrastructure.
Hardware manufacturers have responded by developing energy-aware training accelerators that incorporate dynamic voltage and frequency scaling optimized for neural network workloads. These solutions enable real-time power management during training phases, automatically adjusting computational intensity based on gradient complexity and convergence patterns. Advanced cooling technologies, including liquid immersion and direct-chip cooling, are becoming standard requirements for meeting efficiency benchmarks.
Emerging standards emphasize holistic energy optimization approaches that consider model architecture efficiency alongside hardware performance. Techniques such as mixed-precision training, gradient checkpointing, and adaptive batch sizing are being codified into best practice guidelines. Organizations are increasingly adopting carbon-aware scheduling systems that automatically shift training workloads to time periods and geographic regions with higher renewable energy availability, demonstrating measurable improvements in overall environmental impact while maintaining training performance objectives.
Industry leaders have begun implementing power usage effectiveness (PUE) metrics specifically tailored for AI workloads, extending beyond traditional data center measurements. These specialized metrics account for the dynamic power consumption patterns characteristic of deep learning training, including GPU utilization spikes, memory bandwidth bottlenecks, and thermal management requirements. Leading cloud providers now report AI-specific energy consumption data, with targets of achieving PUE ratios below 1.2 for dedicated AI training facilities.
Regulatory frameworks are emerging across multiple jurisdictions to establish mandatory energy reporting requirements for large-scale AI training operations. The European Union's proposed AI Act includes provisions for energy disclosure when training models exceed specific computational thresholds, measured in floating-point operations. Similar initiatives in California and Singapore focus on carbon footprint reporting and renewable energy sourcing requirements for AI infrastructure.
Hardware manufacturers have responded by developing energy-aware training accelerators that incorporate dynamic voltage and frequency scaling optimized for neural network workloads. These solutions enable real-time power management during training phases, automatically adjusting computational intensity based on gradient complexity and convergence patterns. Advanced cooling technologies, including liquid immersion and direct-chip cooling, are becoming standard requirements for meeting efficiency benchmarks.
Emerging standards emphasize holistic energy optimization approaches that consider model architecture efficiency alongside hardware performance. Techniques such as mixed-precision training, gradient checkpointing, and adaptive batch sizing are being codified into best practice guidelines. Organizations are increasingly adopting carbon-aware scheduling systems that automatically shift training workloads to time periods and geographic regions with higher renewable energy availability, demonstrating measurable improvements in overall environmental impact while maintaining training performance objectives.
Data Privacy Regulations in Distributed NLP Training
The deployment of AI accelerators for high-performance NLP model training in distributed environments faces increasingly complex data privacy regulatory landscapes across global jurisdictions. The European Union's General Data Protection Regulation (GDPR) establishes stringent requirements for data processing, particularly affecting cross-border distributed training scenarios where sensitive textual data may traverse multiple geographic regions. These regulations mandate explicit consent mechanisms, data minimization principles, and the right to erasure, creating significant technical challenges for maintaining training dataset integrity across distributed accelerator clusters.
In the United States, sector-specific regulations such as HIPAA for healthcare data and FERPA for educational records impose additional constraints on NLP training workflows. The California Consumer Privacy Act (CCPA) and emerging state-level privacy laws further complicate compliance frameworks for organizations operating distributed AI accelerator infrastructures. These regulations require sophisticated data governance mechanisms that can track data lineage, implement granular access controls, and ensure audit trails throughout the distributed training process.
China's Personal Information Protection Law (PIPL) and Cybersecurity Law introduce data localization requirements that significantly impact distributed NLP training architectures. Organizations must implement technical measures to ensure that Chinese citizen data remains within national boundaries while maintaining the computational efficiency of distributed accelerator networks. This creates architectural constraints that affect model parallelization strategies and cross-regional data synchronization protocols.
The technical implementation of privacy-compliant distributed NLP training requires advanced cryptographic techniques such as federated learning, differential privacy, and secure multi-party computation. These approaches enable organizations to leverage distributed AI accelerators while maintaining compliance with varying regulatory requirements. However, these privacy-preserving techniques often introduce computational overhead and communication latency that can significantly impact training performance and scalability.
Emerging regulatory frameworks in jurisdictions such as India, Brazil, and the United Kingdom are creating a patchwork of compliance requirements that organizations must navigate when deploying global distributed training infrastructures. The lack of harmonization between these regulatory frameworks necessitates flexible, adaptive privacy architectures that can dynamically adjust data handling procedures based on the geographic location of both data subjects and computational resources.
In the United States, sector-specific regulations such as HIPAA for healthcare data and FERPA for educational records impose additional constraints on NLP training workflows. The California Consumer Privacy Act (CCPA) and emerging state-level privacy laws further complicate compliance frameworks for organizations operating distributed AI accelerator infrastructures. These regulations require sophisticated data governance mechanisms that can track data lineage, implement granular access controls, and ensure audit trails throughout the distributed training process.
China's Personal Information Protection Law (PIPL) and Cybersecurity Law introduce data localization requirements that significantly impact distributed NLP training architectures. Organizations must implement technical measures to ensure that Chinese citizen data remains within national boundaries while maintaining the computational efficiency of distributed accelerator networks. This creates architectural constraints that affect model parallelization strategies and cross-regional data synchronization protocols.
The technical implementation of privacy-compliant distributed NLP training requires advanced cryptographic techniques such as federated learning, differential privacy, and secure multi-party computation. These approaches enable organizations to leverage distributed AI accelerators while maintaining compliance with varying regulatory requirements. However, these privacy-preserving techniques often introduce computational overhead and communication latency that can significantly impact training performance and scalability.
Emerging regulatory frameworks in jurisdictions such as India, Brazil, and the United Kingdom are creating a patchwork of compliance requirements that organizations must navigate when deploying global distributed training infrastructures. The lack of harmonization between these regulatory frameworks necessitates flexible, adaptive privacy architectures that can dynamically adjust data handling procedures based on the geographic location of both data subjects and computational resources.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!