

AI Model Compression for Efficient AI Inference
MAR 17, 20268 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
AI Model Compression Background and Efficiency Goals
The evolution of artificial intelligence has witnessed remarkable progress in model sophistication and capability, yet this advancement has come at the cost of increasingly complex and resource-intensive architectures. Modern deep learning models, particularly large language models and computer vision networks, often contain billions of parameters and require substantial computational resources for inference operations. This computational burden has created a significant gap between the theoretical capabilities of AI systems and their practical deployment in resource-constrained environments.
The emergence of edge computing, mobile applications, and Internet of Things devices has intensified the demand for efficient AI inference solutions. These deployment scenarios typically feature limited processing power, memory constraints, battery life considerations, and real-time performance requirements that cannot accommodate the computational overhead of full-scale models. Consequently, the field of AI model compression has emerged as a critical research area bridging the gap between model performance and practical deployment feasibility.
AI model compression encompasses a diverse range of techniques designed to reduce the computational and memory footprint of neural networks while preserving their predictive accuracy. The fundamental challenge lies in identifying and eliminating redundancies within model architectures without compromising the essential information pathways that contribute to model performance. This optimization process requires sophisticated understanding of neural network behavior, information theory principles, and hardware-software co-design considerations.
The primary efficiency goals driving model compression research include reducing inference latency, minimizing memory consumption, decreasing energy consumption, and enabling deployment on resource-constrained hardware platforms. Latency reduction is particularly crucial for real-time applications such as autonomous vehicles, augmented reality systems, and interactive AI assistants where response time directly impacts user experience and safety.
Memory optimization addresses both storage requirements for model parameters and runtime memory allocation during inference operations. This dual consideration is essential for mobile devices and embedded systems where both persistent storage and working memory are limited resources. Energy efficiency has become increasingly important as AI deployment scales across battery-powered devices and data centers seeking to minimize operational costs and environmental impact.
The compression challenge extends beyond simple parameter reduction to encompass maintaining model robustness, generalization capabilities, and accuracy across diverse input distributions. Successful compression techniques must preserve the learned representations that enable models to handle edge cases, domain variations, and adversarial inputs while operating within strict resource constraints.
The emergence of edge computing, mobile applications, and Internet of Things devices has intensified the demand for efficient AI inference solutions. These deployment scenarios typically feature limited processing power, memory constraints, battery life considerations, and real-time performance requirements that cannot accommodate the computational overhead of full-scale models. Consequently, the field of AI model compression has emerged as a critical research area bridging the gap between model performance and practical deployment feasibility.
AI model compression encompasses a diverse range of techniques designed to reduce the computational and memory footprint of neural networks while preserving their predictive accuracy. The fundamental challenge lies in identifying and eliminating redundancies within model architectures without compromising the essential information pathways that contribute to model performance. This optimization process requires sophisticated understanding of neural network behavior, information theory principles, and hardware-software co-design considerations.
The primary efficiency goals driving model compression research include reducing inference latency, minimizing memory consumption, decreasing energy consumption, and enabling deployment on resource-constrained hardware platforms. Latency reduction is particularly crucial for real-time applications such as autonomous vehicles, augmented reality systems, and interactive AI assistants where response time directly impacts user experience and safety.
Memory optimization addresses both storage requirements for model parameters and runtime memory allocation during inference operations. This dual consideration is essential for mobile devices and embedded systems where both persistent storage and working memory are limited resources. Energy efficiency has become increasingly important as AI deployment scales across battery-powered devices and data centers seeking to minimize operational costs and environmental impact.
The compression challenge extends beyond simple parameter reduction to encompass maintaining model robustness, generalization capabilities, and accuracy across diverse input distributions. Successful compression techniques must preserve the learned representations that enable models to handle edge cases, domain variations, and adversarial inputs while operating within strict resource constraints.
Market Demand for Efficient AI Inference Solutions
The global demand for efficient AI inference solutions has experienced unprecedented growth driven by the proliferation of AI applications across diverse industries. Edge computing environments, mobile devices, and IoT systems require AI models that can deliver real-time performance while operating under strict resource constraints. This demand stems from the fundamental challenge of deploying sophisticated AI models in environments with limited computational power, memory, and energy budgets.
Enterprise applications represent a significant portion of this market demand, particularly in sectors such as autonomous vehicles, healthcare diagnostics, industrial automation, and smart city infrastructure. These applications require AI models that can process data locally with minimal latency while maintaining high accuracy standards. The shift toward edge-based AI processing has intensified the need for compressed models that can operate efficiently without relying on cloud connectivity.
Mobile and consumer electronics markets have emerged as primary drivers of demand for efficient AI inference solutions. Smartphone manufacturers, wearable device companies, and smart home appliance producers increasingly integrate AI capabilities into their products. These applications demand models that can perform complex tasks such as image recognition, natural language processing, and predictive analytics while preserving battery life and ensuring smooth user experiences.
The automotive industry has become a particularly compelling market for AI model compression technologies. Advanced driver assistance systems, autonomous driving features, and in-vehicle infotainment systems require real-time AI processing capabilities that must operate reliably under varying environmental conditions. The safety-critical nature of automotive applications creates additional demand for efficient inference solutions that can maintain consistent performance.
Cloud service providers and data center operators also drive significant demand for efficient AI inference solutions, albeit for different reasons. While these environments typically have abundant computational resources, the scale of AI workloads and the need to optimize operational costs create strong incentives for deploying compressed models that can serve more requests per unit of hardware investment.
The healthcare sector presents unique market opportunities for efficient AI inference solutions, particularly in medical imaging, diagnostic devices, and patient monitoring systems. Regulatory requirements, privacy concerns, and the need for real-time decision-making in clinical settings drive demand for AI models that can operate locally while maintaining high accuracy and reliability standards.
Enterprise applications represent a significant portion of this market demand, particularly in sectors such as autonomous vehicles, healthcare diagnostics, industrial automation, and smart city infrastructure. These applications require AI models that can process data locally with minimal latency while maintaining high accuracy standards. The shift toward edge-based AI processing has intensified the need for compressed models that can operate efficiently without relying on cloud connectivity.
Mobile and consumer electronics markets have emerged as primary drivers of demand for efficient AI inference solutions. Smartphone manufacturers, wearable device companies, and smart home appliance producers increasingly integrate AI capabilities into their products. These applications demand models that can perform complex tasks such as image recognition, natural language processing, and predictive analytics while preserving battery life and ensuring smooth user experiences.
The automotive industry has become a particularly compelling market for AI model compression technologies. Advanced driver assistance systems, autonomous driving features, and in-vehicle infotainment systems require real-time AI processing capabilities that must operate reliably under varying environmental conditions. The safety-critical nature of automotive applications creates additional demand for efficient inference solutions that can maintain consistent performance.
Cloud service providers and data center operators also drive significant demand for efficient AI inference solutions, albeit for different reasons. While these environments typically have abundant computational resources, the scale of AI workloads and the need to optimize operational costs create strong incentives for deploying compressed models that can serve more requests per unit of hardware investment.
The healthcare sector presents unique market opportunities for efficient AI inference solutions, particularly in medical imaging, diagnostic devices, and patient monitoring systems. Regulatory requirements, privacy concerns, and the need for real-time decision-making in clinical settings drive demand for AI models that can operate locally while maintaining high accuracy and reliability standards.
Current State and Challenges in AI Model Compression
AI model compression has emerged as a critical technology domain driven by the exponential growth in model complexity and the increasing demand for edge deployment. Current deep learning models, particularly large language models and computer vision networks, often contain billions of parameters, making them computationally intensive and memory-demanding. This creates significant barriers for deployment in resource-constrained environments such as mobile devices, IoT systems, and edge computing platforms.
The contemporary landscape of AI model compression encompasses several mature techniques that have demonstrated substantial effectiveness. Quantization methods, including post-training quantization and quantization-aware training, have achieved widespread adoption by reducing numerical precision from 32-bit floating-point to 8-bit or even lower representations. Knowledge distillation techniques enable the transfer of learned representations from large teacher models to smaller student networks, maintaining performance while significantly reducing computational overhead.
Pruning methodologies represent another established approach, systematically removing redundant parameters or entire network components based on magnitude, gradient information, or structured patterns. Neural architecture search has evolved to automatically discover efficient model architectures optimized for specific hardware constraints and performance requirements.
Despite these advances, several fundamental challenges persist in the field. The accuracy-efficiency trade-off remains a primary concern, as aggressive compression often leads to significant performance degradation, particularly for complex tasks requiring high precision. Hardware-specific optimization presents another challenge, as compression techniques must be tailored to diverse deployment targets with varying computational capabilities and memory hierarchies.
The lack of standardized evaluation frameworks complicates comparative analysis across different compression methods. Current approaches often focus on individual metrics such as model size or inference speed, failing to provide comprehensive assessments that consider real-world deployment scenarios and energy consumption patterns.
Emerging challenges include compression of multimodal models, handling dynamic input sequences, and maintaining robustness under adversarial conditions. The integration of compression techniques with modern training paradigms such as self-supervised learning and few-shot adaptation requires further investigation to ensure optimal performance across diverse application domains.
The contemporary landscape of AI model compression encompasses several mature techniques that have demonstrated substantial effectiveness. Quantization methods, including post-training quantization and quantization-aware training, have achieved widespread adoption by reducing numerical precision from 32-bit floating-point to 8-bit or even lower representations. Knowledge distillation techniques enable the transfer of learned representations from large teacher models to smaller student networks, maintaining performance while significantly reducing computational overhead.
Pruning methodologies represent another established approach, systematically removing redundant parameters or entire network components based on magnitude, gradient information, or structured patterns. Neural architecture search has evolved to automatically discover efficient model architectures optimized for specific hardware constraints and performance requirements.
Despite these advances, several fundamental challenges persist in the field. The accuracy-efficiency trade-off remains a primary concern, as aggressive compression often leads to significant performance degradation, particularly for complex tasks requiring high precision. Hardware-specific optimization presents another challenge, as compression techniques must be tailored to diverse deployment targets with varying computational capabilities and memory hierarchies.
The lack of standardized evaluation frameworks complicates comparative analysis across different compression methods. Current approaches often focus on individual metrics such as model size or inference speed, failing to provide comprehensive assessments that consider real-world deployment scenarios and energy consumption patterns.
Emerging challenges include compression of multimodal models, handling dynamic input sequences, and maintaining robustness under adversarial conditions. The integration of compression techniques with modern training paradigms such as self-supervised learning and few-shot adaptation requires further investigation to ensure optimal performance across diverse application domains.
Current AI Model Compression Solution Approaches
01 Quantization techniques for model compression
Quantization methods reduce model size by converting high-precision weights and activations to lower-precision representations. This approach significantly decreases memory footprint and computational requirements while maintaining acceptable accuracy levels. Various quantization strategies include post-training quantization, quantization-aware training, and mixed-precision quantization to optimize the trade-off between model size and performance.- Quantization techniques for model compression: Quantization methods reduce model size by converting high-precision weights and activations to lower-precision representations. This approach significantly decreases memory footprint and computational requirements while maintaining acceptable accuracy levels. Various quantization strategies include post-training quantization, quantization-aware training, and mixed-precision quantization to optimize the trade-off between model size and performance.
- Neural network pruning methods: Pruning techniques eliminate redundant or less important connections, neurons, or layers from neural networks to reduce model complexity. Structured and unstructured pruning approaches identify and remove parameters based on various criteria such as magnitude, gradient information, or learned importance scores. These methods enable significant compression ratios while preserving model accuracy through iterative pruning and fine-tuning processes.
- Knowledge distillation for model efficiency: Knowledge distillation transfers learned representations from large teacher models to smaller student models, enabling compact architectures to achieve comparable performance. This technique involves training student networks to mimic the output distributions or intermediate representations of teacher networks. Various distillation strategies optimize the compression process through attention transfer, feature matching, and response-based learning mechanisms.
- Low-rank decomposition and factorization: Matrix decomposition techniques approximate weight matrices using lower-rank representations to reduce parameter count and computational complexity. These methods apply tensor decomposition, singular value decomposition, or other factorization approaches to compress fully connected and convolutional layers. The resulting factorized structures maintain essential information while significantly reducing storage and inference costs.
- Hardware-aware compression optimization: Hardware-specific compression strategies optimize models for deployment on target devices by considering architectural constraints and computational capabilities. These approaches integrate compression techniques with hardware characteristics such as memory bandwidth, processing units, and energy consumption. Co-design methodologies balance compression ratios with inference speed and resource utilization to maximize efficiency on edge devices, mobile platforms, and specialized accelerators.
02 Neural network pruning methods
Pruning techniques eliminate redundant or less important connections, neurons, or layers from neural networks to reduce model complexity. Structured and unstructured pruning approaches identify and remove parameters based on various criteria such as magnitude, gradient information, or importance scores. These methods enable significant compression ratios while preserving model accuracy through iterative pruning and fine-tuning processes.Expand Specific Solutions03 Knowledge distillation for model efficiency
Knowledge distillation transfers learned representations from large teacher models to smaller student models, enabling compact architectures to achieve comparable performance. This technique involves training student networks to mimic the output distributions or intermediate representations of teacher networks. The approach facilitates deployment of efficient models on resource-constrained devices while maintaining high accuracy levels.Expand Specific Solutions04 Low-rank decomposition and factorization
Matrix decomposition techniques approximate weight matrices using lower-rank representations to reduce parameter count and computational complexity. Methods such as singular value decomposition, tensor decomposition, and low-rank factorization compress neural network layers while preserving essential information. These approaches are particularly effective for fully-connected and convolutional layers in deep learning models.Expand Specific Solutions05 Hardware-aware optimization and acceleration
Hardware-specific optimization techniques tailor model compression strategies to target deployment platforms, considering memory bandwidth, computational capabilities, and power constraints. These methods include architecture search, operator fusion, and platform-specific quantization schemes that maximize efficiency on particular hardware accelerators. The approach ensures optimal performance across diverse deployment scenarios from edge devices to cloud infrastructure.Expand Specific Solutions
Key Players in AI Compression and Edge Computing
The AI model compression field is experiencing rapid growth as the industry transitions from research-focused development to commercial deployment, driven by increasing demand for efficient edge computing and mobile AI applications. The market demonstrates significant expansion potential, with enterprise adoption accelerating across sectors requiring real-time inference capabilities. Technology maturity varies considerably among key players: established semiconductor leaders like NVIDIA, Intel, and Samsung possess advanced hardware-software integration capabilities, while specialized AI companies such as Groq and Nota focus on purpose-built inference acceleration solutions. Chinese technology giants including Huawei, Baidu, and Xiaomi are developing comprehensive compression frameworks for mobile devices, and academic institutions like Carnegie Mellon University contribute foundational research. The competitive landscape shows convergence toward standardized compression techniques, with companies increasingly emphasizing deployment-ready solutions that balance model accuracy with computational efficiency for production environments.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed the MindSpore framework with built-in model compression capabilities including adaptive quantization that reduces model size by 75% while maintaining 98% accuracy. Their Ascend AI processors support hardware-accelerated pruning and knowledge distillation techniques. The company's compression solution integrates structured pruning algorithms that can achieve 5x inference speedup on mobile devices. Huawei also implements dynamic precision adjustment and efficient memory management for edge AI deployment, particularly optimized for their Kirin chipsets and HiSilicon processors.
Strengths: Integrated hardware-software optimization, strong mobile device deployment, comprehensive AI ecosystem. Weaknesses: Limited global market access, dependency on proprietary hardware platforms.
Intel Corp.
Technical Solution: Intel provides OpenVINO toolkit that enables model compression through post-training quantization achieving up to 4x performance improvement with INT8 optimization. Their Neural Compressor framework supports various pruning techniques including magnitude-based and structured pruning, delivering up to 90% sparsity while preserving model accuracy. Intel's approach includes knowledge distillation capabilities and automatic mixed-precision optimization specifically designed for CPU inference. The solution supports multiple deep learning frameworks and provides hardware-aware optimization for Intel processors and accelerators.
Strengths: CPU-optimized inference, broad framework compatibility, enterprise-grade deployment tools. Weaknesses: Limited GPU acceleration capabilities, lower performance compared to specialized AI chips.
Core Compression Algorithms and Patent Analysis
Compression of machine learning models via sparsification and quantization
PatentPendingUS20250094864A1
Innovation
- The method involves apportioning machine learning model values into data structures with defined structured sparse patterns and non-uniform data representations, allowing inlier and outlier values to be stored with different sparsity and precision levels.




Method and system for lightening model for optimizing to equipment- friendly model
PatentPendingUS20250029002A1
Innovation
- A model compression method that combines unstructured pruning with structured pruning, using criteria and sparsity to determine filters for pruning, thereby generating a compressed AI model that can be optimized for equipment-friendly performance.
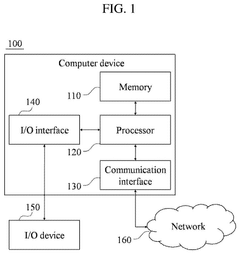
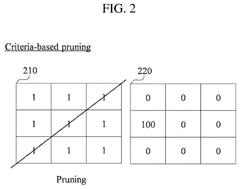
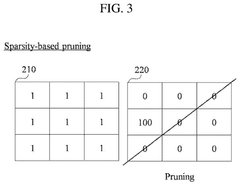
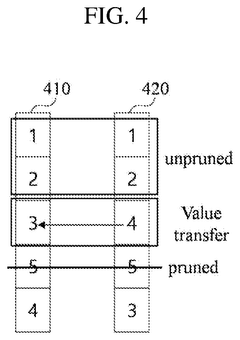
Hardware-Software Co-optimization for AI Inference
Hardware-software co-optimization represents a paradigm shift in AI inference system design, moving beyond traditional isolated optimization approaches to achieve unprecedented efficiency gains. This methodology recognizes that hardware capabilities and software implementations are intrinsically linked, requiring simultaneous consideration during the design process to maximize performance while minimizing resource consumption.
The foundation of co-optimization lies in understanding the bidirectional relationship between hardware architecture and software algorithms. Modern AI accelerators, including specialized chips like TPUs, neuromorphic processors, and edge computing units, are designed with specific computational patterns in mind. Simultaneously, software frameworks must be tailored to exploit these hardware features effectively, creating a symbiotic relationship that enhances overall system performance.
Contemporary co-optimization strategies focus on several key areas. Memory hierarchy optimization ensures that data movement patterns align with hardware cache structures and bandwidth limitations. Computational graph optimization restructures neural network operations to match hardware execution units, while precision optimization leverages mixed-precision capabilities of modern accelerators. These approaches collectively reduce latency and energy consumption significantly.
Emerging trends in hardware-software co-optimization include dynamic adaptation mechanisms that adjust software behavior based on real-time hardware conditions. Advanced compiler technologies now incorporate hardware-aware optimizations that automatically generate efficient code for specific target platforms. Additionally, cross-layer optimization techniques consider the entire stack from application requirements down to transistor-level implementations.
The integration of co-optimization with model compression techniques creates multiplicative efficiency gains. Quantization strategies are now designed considering specific hardware arithmetic units, while pruning patterns align with hardware memory access patterns. This holistic approach ensures that compressed models not only maintain accuracy but also achieve optimal performance on target hardware platforms, representing the future direction of efficient AI inference systems.
The foundation of co-optimization lies in understanding the bidirectional relationship between hardware architecture and software algorithms. Modern AI accelerators, including specialized chips like TPUs, neuromorphic processors, and edge computing units, are designed with specific computational patterns in mind. Simultaneously, software frameworks must be tailored to exploit these hardware features effectively, creating a symbiotic relationship that enhances overall system performance.
Contemporary co-optimization strategies focus on several key areas. Memory hierarchy optimization ensures that data movement patterns align with hardware cache structures and bandwidth limitations. Computational graph optimization restructures neural network operations to match hardware execution units, while precision optimization leverages mixed-precision capabilities of modern accelerators. These approaches collectively reduce latency and energy consumption significantly.
Emerging trends in hardware-software co-optimization include dynamic adaptation mechanisms that adjust software behavior based on real-time hardware conditions. Advanced compiler technologies now incorporate hardware-aware optimizations that automatically generate efficient code for specific target platforms. Additionally, cross-layer optimization techniques consider the entire stack from application requirements down to transistor-level implementations.
The integration of co-optimization with model compression techniques creates multiplicative efficiency gains. Quantization strategies are now designed considering specific hardware arithmetic units, while pruning patterns align with hardware memory access patterns. This holistic approach ensures that compressed models not only maintain accuracy but also achieve optimal performance on target hardware platforms, representing the future direction of efficient AI inference systems.
Energy Efficiency Standards for Edge AI Deployment
The deployment of compressed AI models on edge devices necessitates adherence to stringent energy efficiency standards to ensure sustainable and practical implementation. Current industry standards primarily focus on power consumption metrics, thermal management requirements, and computational efficiency benchmarks that directly impact battery life and operational costs in edge environments.
IEEE 2857 standard provides foundational guidelines for energy-aware AI system design, establishing baseline power consumption thresholds for different device categories. Mobile edge devices typically require AI inference operations to consume less than 2 watts during peak performance, while IoT sensors must operate within 100-500 milliwatt ranges to maintain acceptable battery longevity.
The Energy Star certification framework has recently expanded to include AI-enabled edge devices, introducing specific criteria for inference energy efficiency measured in operations per joule. These standards mandate that compressed models achieve at least 50% energy reduction compared to their uncompressed counterparts while maintaining accuracy within 5% degradation thresholds.
Thermal design power (TDP) regulations play a crucial role in edge AI deployment, particularly for fanless embedded systems. Current standards limit continuous operation temperatures to 85°C for commercial applications and 125°C for industrial environments, directly constraining the computational intensity of deployed compressed models.
Dynamic voltage and frequency scaling (DVFS) compliance requirements ensure that compressed AI models can adapt their power consumption based on workload demands. Modern standards require support for at least four power states, enabling energy savings of up to 70% during idle or low-activity periods.
Emerging standards from organizations like the Green Software Foundation emphasize carbon footprint metrics, requiring edge AI deployments to report energy consumption per inference operation. These evolving frameworks push for compressed models that not only reduce computational requirements but also minimize environmental impact through optimized energy utilization patterns across diverse edge computing scenarios.
IEEE 2857 standard provides foundational guidelines for energy-aware AI system design, establishing baseline power consumption thresholds for different device categories. Mobile edge devices typically require AI inference operations to consume less than 2 watts during peak performance, while IoT sensors must operate within 100-500 milliwatt ranges to maintain acceptable battery longevity.
The Energy Star certification framework has recently expanded to include AI-enabled edge devices, introducing specific criteria for inference energy efficiency measured in operations per joule. These standards mandate that compressed models achieve at least 50% energy reduction compared to their uncompressed counterparts while maintaining accuracy within 5% degradation thresholds.
Thermal design power (TDP) regulations play a crucial role in edge AI deployment, particularly for fanless embedded systems. Current standards limit continuous operation temperatures to 85°C for commercial applications and 125°C for industrial environments, directly constraining the computational intensity of deployed compressed models.
Dynamic voltage and frequency scaling (DVFS) compliance requirements ensure that compressed AI models can adapt their power consumption based on workload demands. Modern standards require support for at least four power states, enabling energy savings of up to 70% during idle or low-activity periods.
Emerging standards from organizations like the Green Software Foundation emphasize carbon footprint metrics, requiring edge AI deployments to report energy consumption per inference operation. These evolving frameworks push for compressed models that not only reduce computational requirements but also minimize environmental impact through optimized energy utilization patterns across diverse edge computing scenarios.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!