

Comparing Data Models for Predicting Air Pollutant Dispersion
JUN 8, 20268 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Air Pollution Modeling Background and Objectives
Air pollution has emerged as one of the most pressing environmental challenges of the 21st century, affecting billions of people worldwide and causing significant health, economic, and ecological impacts. The World Health Organization estimates that air pollution contributes to approximately 7 million premature deaths annually, making it a critical public health priority. As urbanization accelerates and industrial activities expand globally, the complexity of air pollution sources and their dispersion patterns has increased dramatically.
The evolution of air pollution modeling can be traced back to the 1960s when simple Gaussian plume models were first developed to predict pollutant concentrations from point sources. Over the decades, modeling approaches have evolved from basic statistical correlations to sophisticated computational fluid dynamics simulations and machine learning algorithms. Early models primarily focused on single pollutants and simple meteorological conditions, but contemporary approaches must account for complex chemical reactions, multiple emission sources, and dynamic atmospheric conditions.
Modern air pollution modeling faces unprecedented challenges due to the increasing diversity of emission sources, including vehicular traffic, industrial processes, residential heating, and natural phenomena such as wildfires and dust storms. The interaction between different pollutants creates complex chemical transformation processes that significantly influence dispersion patterns. Additionally, climate change has introduced new variables, including altered wind patterns, temperature inversions, and extreme weather events that affect pollutant transport and accumulation.
The primary objective of contemporary air pollution dispersion modeling is to develop accurate, real-time predictive capabilities that can support both regulatory decision-making and public health protection. These models must provide reliable forecasts across multiple spatial scales, from local street-level concentrations to regional air quality patterns. Furthermore, they need to integrate diverse data sources, including satellite observations, ground-based monitoring networks, and meteorological data, while maintaining computational efficiency for operational deployment.
Advanced modeling systems aim to achieve several key technical goals: improving spatial and temporal resolution to capture fine-scale pollution gradients, enhancing chemical mechanism representation for better secondary pollutant prediction, and developing ensemble modeling approaches that quantify prediction uncertainties. The integration of artificial intelligence and machine learning techniques represents a significant paradigm shift, offering opportunities to identify complex non-linear relationships between meteorological conditions, emission patterns, and pollutant concentrations that traditional physics-based models may not capture effectively.
The evolution of air pollution modeling can be traced back to the 1960s when simple Gaussian plume models were first developed to predict pollutant concentrations from point sources. Over the decades, modeling approaches have evolved from basic statistical correlations to sophisticated computational fluid dynamics simulations and machine learning algorithms. Early models primarily focused on single pollutants and simple meteorological conditions, but contemporary approaches must account for complex chemical reactions, multiple emission sources, and dynamic atmospheric conditions.
Modern air pollution modeling faces unprecedented challenges due to the increasing diversity of emission sources, including vehicular traffic, industrial processes, residential heating, and natural phenomena such as wildfires and dust storms. The interaction between different pollutants creates complex chemical transformation processes that significantly influence dispersion patterns. Additionally, climate change has introduced new variables, including altered wind patterns, temperature inversions, and extreme weather events that affect pollutant transport and accumulation.
The primary objective of contemporary air pollution dispersion modeling is to develop accurate, real-time predictive capabilities that can support both regulatory decision-making and public health protection. These models must provide reliable forecasts across multiple spatial scales, from local street-level concentrations to regional air quality patterns. Furthermore, they need to integrate diverse data sources, including satellite observations, ground-based monitoring networks, and meteorological data, while maintaining computational efficiency for operational deployment.
Advanced modeling systems aim to achieve several key technical goals: improving spatial and temporal resolution to capture fine-scale pollution gradients, enhancing chemical mechanism representation for better secondary pollutant prediction, and developing ensemble modeling approaches that quantify prediction uncertainties. The integration of artificial intelligence and machine learning techniques represents a significant paradigm shift, offering opportunities to identify complex non-linear relationships between meteorological conditions, emission patterns, and pollutant concentrations that traditional physics-based models may not capture effectively.
Market Demand for Air Quality Prediction Systems
The global air quality prediction systems market has experienced substantial growth driven by increasing environmental awareness and stringent regulatory requirements. Urban areas worldwide face mounting pressure to monitor and forecast air pollution levels, creating significant demand for sophisticated prediction technologies. Government agencies, environmental monitoring organizations, and public health institutions represent primary customer segments seeking reliable air quality forecasting solutions.
Industrial sectors including manufacturing, energy production, and transportation increasingly require air quality prediction systems to ensure regulatory compliance and minimize environmental impact. These industries face substantial penalties for exceeding emission thresholds, driving investment in predictive technologies that enable proactive pollution management. The integration of air quality forecasting into industrial operations has become essential for sustainable business practices.
Smart city initiatives across developed and emerging economies have accelerated market demand for comprehensive air quality monitoring and prediction infrastructure. Municipal governments seek integrated systems that combine real-time monitoring with predictive analytics to inform public health advisories and traffic management decisions. The growing emphasis on citizen health and environmental transparency has made air quality prediction systems critical components of urban planning strategies.
The healthcare sector represents an emerging market segment with increasing recognition of air pollution's impact on respiratory diseases, cardiovascular conditions, and overall public health outcomes. Medical institutions and public health agencies require accurate pollution forecasts to issue health warnings and manage patient care protocols during high pollution episodes.
Commercial applications in agriculture, outdoor event management, and logistics have expanded market opportunities beyond traditional environmental monitoring. Agricultural operations utilize air quality predictions to optimize crop protection and livestock management, while event organizers and transportation companies integrate pollution forecasts into operational planning to ensure safety and efficiency.
The market demonstrates strong growth potential in developing regions where rapid industrialization and urbanization have intensified air quality challenges. These markets present opportunities for cost-effective prediction systems tailored to local environmental conditions and regulatory frameworks, driving innovation in accessible air quality forecasting technologies.
Industrial sectors including manufacturing, energy production, and transportation increasingly require air quality prediction systems to ensure regulatory compliance and minimize environmental impact. These industries face substantial penalties for exceeding emission thresholds, driving investment in predictive technologies that enable proactive pollution management. The integration of air quality forecasting into industrial operations has become essential for sustainable business practices.
Smart city initiatives across developed and emerging economies have accelerated market demand for comprehensive air quality monitoring and prediction infrastructure. Municipal governments seek integrated systems that combine real-time monitoring with predictive analytics to inform public health advisories and traffic management decisions. The growing emphasis on citizen health and environmental transparency has made air quality prediction systems critical components of urban planning strategies.
The healthcare sector represents an emerging market segment with increasing recognition of air pollution's impact on respiratory diseases, cardiovascular conditions, and overall public health outcomes. Medical institutions and public health agencies require accurate pollution forecasts to issue health warnings and manage patient care protocols during high pollution episodes.
Commercial applications in agriculture, outdoor event management, and logistics have expanded market opportunities beyond traditional environmental monitoring. Agricultural operations utilize air quality predictions to optimize crop protection and livestock management, while event organizers and transportation companies integrate pollution forecasts into operational planning to ensure safety and efficiency.
The market demonstrates strong growth potential in developing regions where rapid industrialization and urbanization have intensified air quality challenges. These markets present opportunities for cost-effective prediction systems tailored to local environmental conditions and regulatory frameworks, driving innovation in accessible air quality forecasting technologies.
Current State of Pollutant Dispersion Modeling
Air pollutant dispersion modeling has evolved significantly over the past several decades, establishing itself as a critical component of environmental management and public health protection. The field encompasses various computational approaches designed to predict how pollutants released from sources spread through the atmosphere under different meteorological and topographical conditions.
Currently, three primary categories of models dominate the landscape of pollutant dispersion prediction. Gaussian plume models represent the most traditional approach, utilizing analytical solutions based on statistical descriptions of atmospheric turbulence. These models, including AERMOD and CALPUFF, remain widely adopted due to their computational efficiency and regulatory acceptance by agencies such as the US EPA.
Computational Fluid Dynamics (CFD) models constitute the second major category, offering detailed three-dimensional simulations of airflow and pollutant transport. These models solve the Navier-Stokes equations numerically, providing high-resolution spatial predictions particularly valuable for complex urban environments and industrial facilities with intricate geometries.
The third category encompasses Lagrangian particle models, which track individual particles or particle clusters as they move through the atmosphere. Models like FLEXPART and HYSPLIT follow stochastic approaches, simulating the random motion of particles while accounting for mean wind transport and turbulent dispersion processes.
Recent technological advances have introduced machine learning and artificial intelligence approaches to pollutant dispersion modeling. Neural networks, particularly deep learning architectures, are increasingly being integrated with traditional physical models to enhance prediction accuracy and computational speed. These hybrid approaches leverage large datasets from monitoring networks and satellite observations.
The current state also reflects growing integration of real-time data sources, including IoT sensor networks, weather radar, and satellite remote sensing. This integration enables dynamic model updating and improved nowcasting capabilities, moving beyond traditional static modeling approaches toward more responsive prediction systems.
Despite these advances, significant challenges persist in the field. Model validation remains complex due to the inherent variability of atmospheric conditions and limited observational data for comprehensive verification. Uncertainty quantification and ensemble modeling approaches are gaining prominence as methods to address these limitations and provide more robust predictions for decision-making processes.
Currently, three primary categories of models dominate the landscape of pollutant dispersion prediction. Gaussian plume models represent the most traditional approach, utilizing analytical solutions based on statistical descriptions of atmospheric turbulence. These models, including AERMOD and CALPUFF, remain widely adopted due to their computational efficiency and regulatory acceptance by agencies such as the US EPA.
Computational Fluid Dynamics (CFD) models constitute the second major category, offering detailed three-dimensional simulations of airflow and pollutant transport. These models solve the Navier-Stokes equations numerically, providing high-resolution spatial predictions particularly valuable for complex urban environments and industrial facilities with intricate geometries.
The third category encompasses Lagrangian particle models, which track individual particles or particle clusters as they move through the atmosphere. Models like FLEXPART and HYSPLIT follow stochastic approaches, simulating the random motion of particles while accounting for mean wind transport and turbulent dispersion processes.
Recent technological advances have introduced machine learning and artificial intelligence approaches to pollutant dispersion modeling. Neural networks, particularly deep learning architectures, are increasingly being integrated with traditional physical models to enhance prediction accuracy and computational speed. These hybrid approaches leverage large datasets from monitoring networks and satellite observations.
The current state also reflects growing integration of real-time data sources, including IoT sensor networks, weather radar, and satellite remote sensing. This integration enables dynamic model updating and improved nowcasting capabilities, moving beyond traditional static modeling approaches toward more responsive prediction systems.
Despite these advances, significant challenges persist in the field. Model validation remains complex due to the inherent variability of atmospheric conditions and limited observational data for comprehensive verification. Uncertainty quantification and ensemble modeling approaches are gaining prominence as methods to address these limitations and provide more robust predictions for decision-making processes.
Existing Data Models for Pollutant Dispersion
01 Machine learning algorithms for improving prediction accuracy
Various machine learning algorithms and techniques are employed to enhance the accuracy of predictive models. These methods include ensemble learning, deep learning networks, and advanced statistical modeling approaches that can better capture complex patterns in data and reduce prediction errors through sophisticated computational methods.- Machine learning model validation and accuracy assessment techniques: Various methods and systems are employed to validate machine learning models and assess their prediction accuracy. These techniques include cross-validation, holdout validation, and statistical measures to evaluate model performance. The approaches focus on measuring how well models generalize to unseen data and provide reliable predictions across different datasets and scenarios.
- Data preprocessing and feature engineering for improved model accuracy: Methods for enhancing data quality and selecting optimal features to improve prediction accuracy of machine learning models. This includes data cleaning, normalization, feature selection algorithms, and dimensionality reduction techniques. These preprocessing steps are crucial for removing noise, handling missing values, and identifying the most relevant variables that contribute to accurate predictions.
- Ensemble methods and model combination strategies: Techniques that combine multiple predictive models to achieve higher accuracy than individual models. These approaches include bagging, boosting, stacking, and voting methods that leverage the strengths of different algorithms. The ensemble strategies help reduce overfitting, improve generalization, and provide more robust predictions by aggregating outputs from multiple base learners.
- Real-time model performance monitoring and adaptive accuracy optimization: Systems and methods for continuously monitoring model performance in production environments and automatically adjusting parameters to maintain prediction accuracy. These solutions detect model drift, concept drift, and data distribution changes that can degrade performance over time. The adaptive mechanisms ensure models remain accurate as underlying data patterns evolve.
- Domain-specific accuracy enhancement and specialized prediction frameworks: Tailored approaches for improving prediction accuracy in specific application domains such as healthcare, finance, or manufacturing. These frameworks incorporate domain knowledge, specialized algorithms, and industry-specific validation metrics. The methods address unique challenges and requirements of particular fields to achieve optimal prediction performance for specialized use cases.
02 Data preprocessing and feature engineering techniques
Methods for improving data quality and extracting relevant features from raw datasets to enhance model performance. These techniques involve data cleaning, normalization, feature selection, and transformation processes that prepare input data in optimal formats for predictive modeling, leading to more accurate predictions.Expand Specific Solutions03 Cross-validation and model evaluation methodologies
Systematic approaches for assessing and validating model performance to ensure prediction accuracy. These methodologies include various cross-validation techniques, performance metrics, and statistical tests that help determine model reliability and generalization capabilities across different datasets.Expand Specific Solutions04 Ensemble methods and model combination strategies
Techniques that combine multiple predictive models to achieve higher accuracy than individual models. These approaches leverage the strengths of different algorithms by aggregating their predictions through voting, averaging, or more sophisticated combination methods to reduce overall prediction errors.Expand Specific Solutions05 Real-time prediction systems and adaptive modeling
Systems designed for continuous model updating and real-time prediction accuracy optimization. These implementations include streaming data processing, online learning algorithms, and adaptive mechanisms that allow models to maintain high accuracy as new data becomes available and underlying patterns change over time.Expand Specific Solutions
Core Algorithms in Air Quality Prediction Models
Air pollutant concentration forecast method and system thereof
PatentActiveCN106485353A
Innovation
- The Stacked Auto-Encoder (SAE) model is used to forecast air pollutant concentration, and the Spatio-Temporal Deep Learning (STDL) model is used to extract deep features and spatio-temporal correlations in air pollutant data. , use grid search to optimize model structure parameters, and combine layer-by-layer training method and back-propagation algorithm for model training.
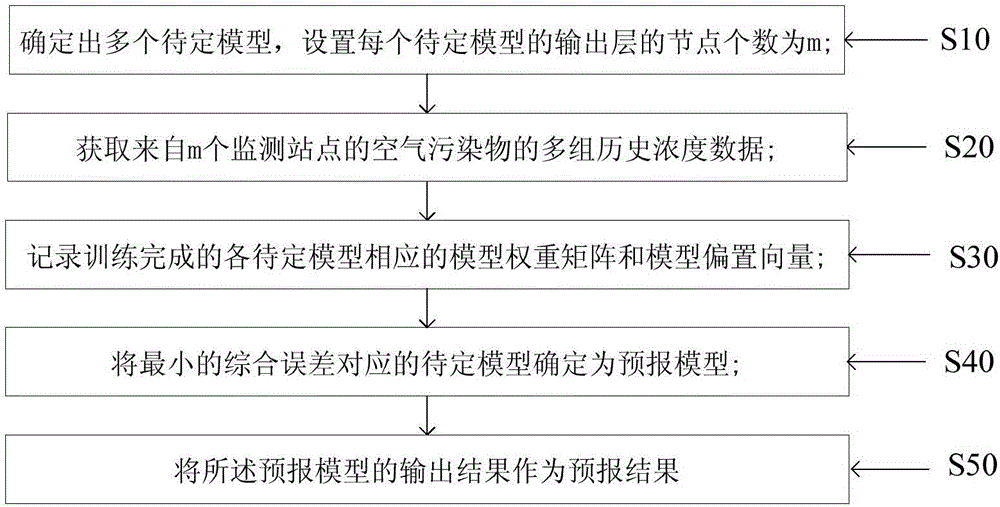
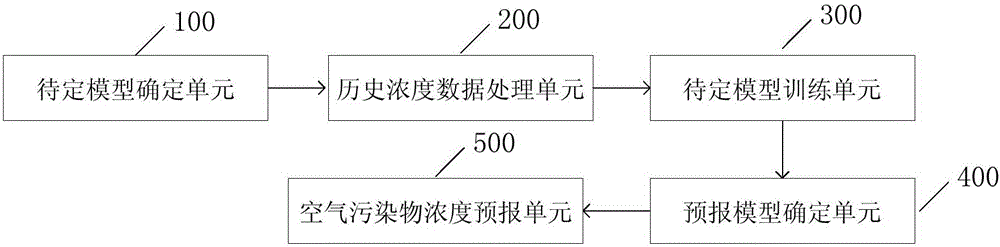
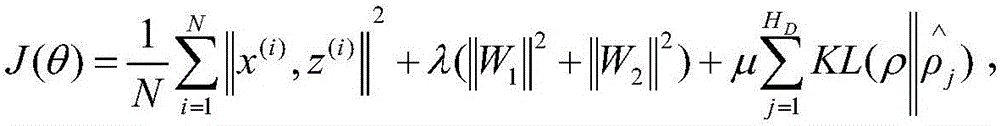

Method for predicting multiple air pollutants based on multi-scale spatio-temporal spectrum feature fusion framework
PatentPendingCN119782748A
Innovation
- Using a multi-scale spatiotemporal and spatial spectrum feature fusion framework, a data set of air quality characteristics is constructed by obtaining data from multiple air quality monitoring sites, and a multi-scale spatiotemporal and spatial spectrum feature fusion model is constructed, and the model is trained to predict the concentration of multiple pollutants in the future period.




Environmental Regulations Impact on Modeling Standards
Environmental regulations serve as fundamental drivers shaping the development and standardization of air pollutant dispersion modeling practices worldwide. Regulatory frameworks establish mandatory requirements for model accuracy, validation protocols, and reporting standards that directly influence how data models are designed, implemented, and evaluated across different jurisdictions.
The Clean Air Act in the United States has established stringent requirements for dispersion modeling through EPA guidelines, mandating the use of approved models such as AERMOD for regulatory applications. These regulations specify minimum data quality standards, meteorological input requirements, and validation criteria that modeling systems must meet. Similar regulatory frameworks in the European Union, including the Industrial Emissions Directive and Ambient Air Quality Directive, have created parallel but distinct modeling standards that emphasize different aspects of model performance and validation.
International harmonization efforts have emerged as regulatory bodies recognize the need for consistent modeling approaches across borders. The World Health Organization and various international environmental agencies have worked to establish baseline standards that can be adapted to local regulatory contexts while maintaining scientific rigor. These efforts have led to the development of standardized protocols for model comparison studies and performance evaluation metrics.
Regulatory compliance requirements significantly impact the selection criteria for dispersion models in practical applications. Models must demonstrate compliance with specific accuracy thresholds, uncertainty quantification methods, and documentation standards before gaining regulatory acceptance. This regulatory oversight has driven innovation in model development, pushing researchers to develop more robust validation frameworks and uncertainty analysis techniques.
The evolving nature of environmental regulations continues to influence modeling standards as new pollutants are regulated and monitoring technologies advance. Recent regulatory trends toward real-time monitoring and adaptive management strategies are creating demand for more responsive and flexible modeling approaches that can integrate diverse data sources while maintaining regulatory compliance standards.
The Clean Air Act in the United States has established stringent requirements for dispersion modeling through EPA guidelines, mandating the use of approved models such as AERMOD for regulatory applications. These regulations specify minimum data quality standards, meteorological input requirements, and validation criteria that modeling systems must meet. Similar regulatory frameworks in the European Union, including the Industrial Emissions Directive and Ambient Air Quality Directive, have created parallel but distinct modeling standards that emphasize different aspects of model performance and validation.
International harmonization efforts have emerged as regulatory bodies recognize the need for consistent modeling approaches across borders. The World Health Organization and various international environmental agencies have worked to establish baseline standards that can be adapted to local regulatory contexts while maintaining scientific rigor. These efforts have led to the development of standardized protocols for model comparison studies and performance evaluation metrics.
Regulatory compliance requirements significantly impact the selection criteria for dispersion models in practical applications. Models must demonstrate compliance with specific accuracy thresholds, uncertainty quantification methods, and documentation standards before gaining regulatory acceptance. This regulatory oversight has driven innovation in model development, pushing researchers to develop more robust validation frameworks and uncertainty analysis techniques.
The evolving nature of environmental regulations continues to influence modeling standards as new pollutants are regulated and monitoring technologies advance. Recent regulatory trends toward real-time monitoring and adaptive management strategies are creating demand for more responsive and flexible modeling approaches that can integrate diverse data sources while maintaining regulatory compliance standards.
Real-time Data Integration Challenges and Solutions
Real-time data integration in air pollutant dispersion modeling presents multifaceted challenges that significantly impact prediction accuracy and system performance. The primary obstacle lies in managing heterogeneous data streams from diverse monitoring sources, including ground-based sensors, satellite observations, meteorological stations, and mobile monitoring units. Each source operates on different temporal resolutions, ranging from seconds to hours, creating synchronization complexities that require sophisticated buffering and interpolation mechanisms.
Data quality assurance emerges as another critical challenge, particularly when dealing with sensor malfunctions, communication interruptions, and varying measurement accuracies across different monitoring networks. Missing data points and outlier detection become increasingly complex in real-time environments where traditional batch processing validation methods are insufficient. The system must implement adaptive quality control algorithms that can distinguish between genuine pollution events and sensor anomalies without introducing significant processing delays.
Scalability concerns intensify as monitoring networks expand and data volumes increase exponentially. Traditional database architectures struggle to handle the concurrent ingestion of thousands of data points while maintaining query performance for real-time model execution. This necessitates the adoption of distributed computing frameworks and specialized time-series databases optimized for high-throughput operations.
Current solutions leverage stream processing technologies such as Apache Kafka and Apache Storm to handle real-time data ingestion and preprocessing. These platforms enable parallel processing of multiple data streams while maintaining data consistency and fault tolerance. Advanced interpolation algorithms, including kriging and machine learning-based gap-filling methods, address temporal and spatial data discontinuities in real-time scenarios.
Edge computing architectures are increasingly deployed to reduce latency by processing data closer to monitoring sources. This approach enables preliminary data validation and aggregation before transmission to central processing systems, significantly reducing bandwidth requirements and improving response times for time-critical applications such as emergency alert systems.
Data quality assurance emerges as another critical challenge, particularly when dealing with sensor malfunctions, communication interruptions, and varying measurement accuracies across different monitoring networks. Missing data points and outlier detection become increasingly complex in real-time environments where traditional batch processing validation methods are insufficient. The system must implement adaptive quality control algorithms that can distinguish between genuine pollution events and sensor anomalies without introducing significant processing delays.
Scalability concerns intensify as monitoring networks expand and data volumes increase exponentially. Traditional database architectures struggle to handle the concurrent ingestion of thousands of data points while maintaining query performance for real-time model execution. This necessitates the adoption of distributed computing frameworks and specialized time-series databases optimized for high-throughput operations.
Current solutions leverage stream processing technologies such as Apache Kafka and Apache Storm to handle real-time data ingestion and preprocessing. These platforms enable parallel processing of multiple data streams while maintaining data consistency and fault tolerance. Advanced interpolation algorithms, including kriging and machine learning-based gap-filling methods, address temporal and spatial data discontinuities in real-time scenarios.
Edge computing architectures are increasingly deployed to reduce latency by processing data closer to monitoring sources. This approach enables preliminary data validation and aggregation before transmission to central processing systems, significantly reducing bandwidth requirements and improving response times for time-critical applications such as emergency alert systems.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!