Comparing Vision-Language Models in Virtual Assistants Efficiency
APR 22, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Vision-Language Model Development Background and Objectives
Vision-language models represent a convergence of computer vision and natural language processing technologies, emerging from decades of parallel development in both domains. The foundational work began in the early 2000s with basic image captioning systems, but significant breakthroughs occurred around 2014-2015 with the introduction of attention mechanisms and encoder-decoder architectures. The evolution accelerated dramatically with transformer-based architectures, leading to sophisticated models like CLIP, DALL-E, and GPT-4V that can understand and generate content across visual and textual modalities.
The integration of vision-language capabilities into virtual assistants represents a natural progression from traditional text-based and voice-only interactions. Early virtual assistants like Siri and Alexa were limited to audio processing, but the proliferation of mobile devices with cameras and the increasing demand for multimodal interactions have driven the need for more sophisticated understanding capabilities. This technological evolution reflects broader user expectations for seamless, intuitive interfaces that can process visual context alongside spoken or written queries.
Current development trajectories focus on achieving real-time processing capabilities while maintaining high accuracy across diverse visual scenarios. The primary technical objectives center on reducing computational overhead without compromising model performance, enabling deployment on edge devices with limited processing power. Latency optimization has become crucial, as virtual assistant applications require response times under 200 milliseconds to maintain natural conversation flow.
Efficiency optimization encompasses multiple dimensions including model size reduction through techniques like knowledge distillation, quantization, and pruning. These approaches aim to compress large-scale vision-language models while preserving their multimodal understanding capabilities. Additionally, architectural innovations focus on developing specialized attention mechanisms that can selectively process relevant visual and textual information, reducing unnecessary computational burden.
The strategic objectives extend beyond mere technical performance to encompass user experience enhancement and practical deployment feasibility. This includes developing robust evaluation frameworks that can accurately measure efficiency gains across different virtual assistant use cases, from simple object recognition to complex scene understanding and reasoning tasks. The ultimate goal involves creating standardized benchmarks that enable fair comparison of different vision-language model architectures in real-world virtual assistant scenarios.
The integration of vision-language capabilities into virtual assistants represents a natural progression from traditional text-based and voice-only interactions. Early virtual assistants like Siri and Alexa were limited to audio processing, but the proliferation of mobile devices with cameras and the increasing demand for multimodal interactions have driven the need for more sophisticated understanding capabilities. This technological evolution reflects broader user expectations for seamless, intuitive interfaces that can process visual context alongside spoken or written queries.
Current development trajectories focus on achieving real-time processing capabilities while maintaining high accuracy across diverse visual scenarios. The primary technical objectives center on reducing computational overhead without compromising model performance, enabling deployment on edge devices with limited processing power. Latency optimization has become crucial, as virtual assistant applications require response times under 200 milliseconds to maintain natural conversation flow.
Efficiency optimization encompasses multiple dimensions including model size reduction through techniques like knowledge distillation, quantization, and pruning. These approaches aim to compress large-scale vision-language models while preserving their multimodal understanding capabilities. Additionally, architectural innovations focus on developing specialized attention mechanisms that can selectively process relevant visual and textual information, reducing unnecessary computational burden.
The strategic objectives extend beyond mere technical performance to encompass user experience enhancement and practical deployment feasibility. This includes developing robust evaluation frameworks that can accurately measure efficiency gains across different virtual assistant use cases, from simple object recognition to complex scene understanding and reasoning tasks. The ultimate goal involves creating standardized benchmarks that enable fair comparison of different vision-language model architectures in real-world virtual assistant scenarios.
Market Demand for Multimodal Virtual Assistant Solutions
The global virtual assistant market is experiencing unprecedented growth driven by the increasing demand for multimodal interaction capabilities. Organizations across industries are seeking sophisticated AI solutions that can process and respond to both visual and textual inputs simultaneously, moving beyond traditional voice-only interfaces. This shift reflects users' expectations for more natural and intuitive human-computer interactions that mirror real-world communication patterns.
Enterprise adoption of multimodal virtual assistants is accelerating across customer service, healthcare, education, and retail sectors. Companies are recognizing the competitive advantage of deploying systems that can understand context from images, documents, and text queries concurrently. The healthcare industry particularly values assistants capable of analyzing medical imagery while processing patient inquiries, while retail organizations leverage visual product recognition combined with natural language processing for enhanced customer experiences.
Consumer market demand is equally robust, with users increasingly expecting virtual assistants to understand visual context from their environment. Smart home integration, mobile applications, and automotive systems are driving requirements for assistants that can interpret visual scenes while responding to spoken or written commands. This convergence of modalities addresses fundamental limitations of single-mode interfaces and creates more engaging user experiences.
The enterprise segment represents the largest growth opportunity, as businesses seek to automate complex workflows requiring both visual and linguistic understanding. Document processing, quality control, and customer support applications demonstrate strong market pull for vision-language capabilities. Organizations are willing to invest significantly in solutions that can reduce manual processing while maintaining accuracy across diverse input types.
Market research indicates strong preference for integrated multimodal solutions over separate vision and language systems. Users demand seamless experiences where visual and textual information processing appears unified rather than fragmented across multiple interfaces. This preference is driving technology providers to develop more sophisticated vision-language models that can deliver cohesive multimodal experiences.
Regional demand patterns show particularly strong growth in North America and Asia-Pacific markets, where digital transformation initiatives and AI adoption rates are highest. European markets demonstrate growing interest, particularly in regulated industries where multimodal assistants can enhance compliance and documentation processes while improving operational efficiency.
Enterprise adoption of multimodal virtual assistants is accelerating across customer service, healthcare, education, and retail sectors. Companies are recognizing the competitive advantage of deploying systems that can understand context from images, documents, and text queries concurrently. The healthcare industry particularly values assistants capable of analyzing medical imagery while processing patient inquiries, while retail organizations leverage visual product recognition combined with natural language processing for enhanced customer experiences.
Consumer market demand is equally robust, with users increasingly expecting virtual assistants to understand visual context from their environment. Smart home integration, mobile applications, and automotive systems are driving requirements for assistants that can interpret visual scenes while responding to spoken or written commands. This convergence of modalities addresses fundamental limitations of single-mode interfaces and creates more engaging user experiences.
The enterprise segment represents the largest growth opportunity, as businesses seek to automate complex workflows requiring both visual and linguistic understanding. Document processing, quality control, and customer support applications demonstrate strong market pull for vision-language capabilities. Organizations are willing to invest significantly in solutions that can reduce manual processing while maintaining accuracy across diverse input types.
Market research indicates strong preference for integrated multimodal solutions over separate vision and language systems. Users demand seamless experiences where visual and textual information processing appears unified rather than fragmented across multiple interfaces. This preference is driving technology providers to develop more sophisticated vision-language models that can deliver cohesive multimodal experiences.
Regional demand patterns show particularly strong growth in North America and Asia-Pacific markets, where digital transformation initiatives and AI adoption rates are highest. European markets demonstrate growing interest, particularly in regulated industries where multimodal assistants can enhance compliance and documentation processes while improving operational efficiency.
Current State of Vision-Language Models in Virtual Assistants
Vision-language models have emerged as a transformative technology in virtual assistant systems, fundamentally changing how users interact with AI-powered devices. Current implementations leverage sophisticated neural architectures that combine computer vision and natural language processing capabilities to enable multimodal understanding and response generation.
The technological landscape is dominated by several architectural approaches, with transformer-based models leading the field. CLIP (Contrastive Language-Image Pre-training) and its variants have established the foundation for many commercial applications, enabling virtual assistants to understand visual content and respond appropriately to user queries. More recent developments include GPT-4V, LLaVA, and BLIP-2, which demonstrate enhanced capabilities in visual reasoning and contextual understanding.
Major technology companies have integrated these models into their virtual assistant ecosystems with varying degrees of success. Google Assistant utilizes advanced vision-language capabilities through its Bard integration and Lens technology, allowing users to ask questions about images and receive contextual responses. Amazon's Alexa has incorporated visual understanding through Echo Show devices, enabling multimodal interactions for shopping, entertainment, and smart home control. Apple's Siri leverages on-device vision-language processing for privacy-focused applications, while Microsoft's Cortana integration with GPT-4V provides sophisticated visual analysis capabilities.
Current technical challenges center around computational efficiency, latency optimization, and accuracy trade-offs. Most implementations struggle with real-time processing requirements, particularly on edge devices with limited computational resources. Model compression techniques, including quantization and knowledge distillation, are being employed to address these constraints, though often at the cost of reduced accuracy.
The accuracy landscape reveals significant disparities across different use cases. While these models excel in general image captioning and basic visual question answering, they face limitations in specialized domains requiring precise technical knowledge or cultural context understanding. Performance metrics indicate accuracy rates ranging from 70-85% for common scenarios, with notable degradation in complex reasoning tasks or ambiguous visual contexts.
Deployment strategies vary significantly across platforms, with cloud-based processing dominating due to computational requirements. However, emerging trends toward edge computing and on-device processing are gaining momentum, driven by privacy concerns and latency reduction needs. Hybrid approaches combining local preprocessing with cloud-based inference are becoming increasingly common, offering balanced solutions for performance and privacy requirements.
The technological landscape is dominated by several architectural approaches, with transformer-based models leading the field. CLIP (Contrastive Language-Image Pre-training) and its variants have established the foundation for many commercial applications, enabling virtual assistants to understand visual content and respond appropriately to user queries. More recent developments include GPT-4V, LLaVA, and BLIP-2, which demonstrate enhanced capabilities in visual reasoning and contextual understanding.
Major technology companies have integrated these models into their virtual assistant ecosystems with varying degrees of success. Google Assistant utilizes advanced vision-language capabilities through its Bard integration and Lens technology, allowing users to ask questions about images and receive contextual responses. Amazon's Alexa has incorporated visual understanding through Echo Show devices, enabling multimodal interactions for shopping, entertainment, and smart home control. Apple's Siri leverages on-device vision-language processing for privacy-focused applications, while Microsoft's Cortana integration with GPT-4V provides sophisticated visual analysis capabilities.
Current technical challenges center around computational efficiency, latency optimization, and accuracy trade-offs. Most implementations struggle with real-time processing requirements, particularly on edge devices with limited computational resources. Model compression techniques, including quantization and knowledge distillation, are being employed to address these constraints, though often at the cost of reduced accuracy.
The accuracy landscape reveals significant disparities across different use cases. While these models excel in general image captioning and basic visual question answering, they face limitations in specialized domains requiring precise technical knowledge or cultural context understanding. Performance metrics indicate accuracy rates ranging from 70-85% for common scenarios, with notable degradation in complex reasoning tasks or ambiguous visual contexts.
Deployment strategies vary significantly across platforms, with cloud-based processing dominating due to computational requirements. However, emerging trends toward edge computing and on-device processing are gaining momentum, driven by privacy concerns and latency reduction needs. Hybrid approaches combining local preprocessing with cloud-based inference are becoming increasingly common, offering balanced solutions for performance and privacy requirements.
Existing Vision-Language Integration Solutions for Virtual Assistants
01 Model compression and quantization techniques
Vision-language models can be made more efficient through compression and quantization methods that reduce model size and computational requirements while maintaining performance. These techniques include weight pruning, knowledge distillation, and low-bit quantization that enable deployment on resource-constrained devices. The approaches focus on reducing memory footprint and inference latency without significant accuracy degradation.- Model compression and quantization techniques: Vision-language models can be made more efficient through compression and quantization methods that reduce model size and computational requirements while maintaining performance. These techniques include weight pruning, knowledge distillation, and low-bit quantization that enable deployment on resource-constrained devices. The methods optimize memory footprint and inference speed without significant accuracy degradation.
- Efficient attention mechanisms and architectural optimization: Optimized attention mechanisms and architectural designs improve the computational efficiency of vision-language models. These approaches include sparse attention patterns, linear attention approximations, and efficient cross-modal fusion strategies that reduce the quadratic complexity of standard attention operations. Such optimizations enable faster processing of visual and textual inputs while preserving model capabilities.
- Dynamic and adaptive inference strategies: Dynamic inference methods adapt computational resources based on input complexity and task requirements. These strategies include early exit mechanisms, adaptive token selection, and conditional computation that allocate processing power efficiently. The approaches enable variable computational budgets depending on the difficulty of vision-language tasks, improving overall system efficiency.
- Efficient training and fine-tuning methods: Training efficiency improvements focus on reducing the computational cost of adapting vision-language models to specific tasks. Techniques include parameter-efficient fine-tuning, adapter modules, and prompt-based learning that update only a small subset of model parameters. These methods significantly reduce training time and resource requirements while achieving comparable performance to full model fine-tuning.
- Hardware-aware optimization and deployment: Hardware-specific optimizations tailor vision-language models for efficient execution on various computing platforms. These include operator fusion, memory access optimization, and platform-specific kernel implementations that leverage specialized hardware accelerators. The techniques ensure optimal utilization of available computational resources across different deployment scenarios from edge devices to cloud infrastructure.
02 Efficient attention mechanisms and architecture optimization
Optimizing the attention mechanisms and overall architecture of vision-language models can significantly improve computational efficiency. This includes sparse attention patterns, linear attention approximations, and streamlined cross-modal fusion modules that reduce the quadratic complexity of standard attention operations. Architecture modifications focus on reducing redundant computations while preserving the model's ability to capture cross-modal relationships.Expand Specific Solutions03 Dynamic and adaptive inference strategies
Implementing dynamic inference mechanisms allows vision-language models to adaptively allocate computational resources based on input complexity. These strategies include early exit mechanisms, dynamic layer selection, and conditional computation that skip unnecessary processing for simpler inputs. Such approaches enable variable computational costs depending on the difficulty of the task, improving overall efficiency.Expand Specific Solutions04 Efficient training and fine-tuning methods
Reducing the computational cost of training and fine-tuning vision-language models through parameter-efficient methods improves overall efficiency. Techniques such as adapter modules, prompt tuning, and low-rank adaptation enable model customization with minimal trainable parameters. These methods significantly reduce training time, memory requirements, and energy consumption while achieving comparable performance to full fine-tuning.Expand Specific Solutions05 Hardware-aware optimization and deployment
Optimizing vision-language models for specific hardware platforms enhances deployment efficiency across different devices. This includes hardware-aware neural architecture search, operator fusion, and platform-specific optimizations for GPUs, mobile processors, and edge devices. The approaches consider memory bandwidth, computational capabilities, and power constraints to maximize throughput and minimize latency on target hardware.Expand Specific Solutions
Key Players in Vision-Language Model and Virtual Assistant Market
The vision-language model integration in virtual assistants represents a rapidly evolving competitive landscape characterized by intense technological advancement and market consolidation. The industry is transitioning from early adoption to mainstream deployment, with market leaders like Apple, Google, and Amazon establishing dominant positions through their respective ecosystems (Siri, Assistant, Alexa). Technology giants including NVIDIA, Qualcomm, and Samsung provide essential hardware acceleration, while Chinese players like Tencent, Huawei, and Alipay drive regional innovation. The technology maturity varies significantly across companies, with established tech leaders demonstrating advanced multimodal capabilities, while emerging players focus on specialized applications. Enterprise solutions from IBM, Salesforce, and Adobe target business automation, indicating market segmentation. The competitive dynamics suggest a bifurcated market where platform owners leverage ecosystem advantages while specialized providers compete on technical differentiation and vertical integration capabilities.
Apple, Inc.
Technical Solution: Apple's Siri leverages advanced vision-language models through on-device processing capabilities, integrating computer vision with natural language understanding for enhanced user interactions. The system utilizes Apple's Neural Engine to process multimodal inputs efficiently, combining visual scene understanding with conversational AI. Siri's vision-language integration enables features like visual lookup, text recognition in images, and contextual assistance based on what users are viewing. The architecture emphasizes privacy-first design with federated learning approaches, processing sensitive visual and linguistic data locally on devices rather than in cloud servers.
Strengths: Strong privacy protection through on-device processing, seamless integration across Apple ecosystem, optimized hardware-software integration. Weaknesses: Limited to Apple devices, less flexible for third-party integrations, smaller training dataset compared to cloud-based competitors.
NVIDIA Corp.
Technical Solution: NVIDIA provides the foundational AI infrastructure for vision-language models in virtual assistants through their GPU computing platforms and AI frameworks like NVIDIA Riva and Omniverse. Their technology enables real-time processing of multimodal AI workloads, supporting transformer-based architectures for vision-language understanding. NVIDIA's approach focuses on optimizing inference performance for large-scale models, providing tools and SDKs for developers to build efficient virtual assistants with advanced computer vision and natural language processing capabilities. The platform supports edge deployment scenarios with optimized model compression and quantization techniques.
Strengths: Industry-leading GPU performance for AI workloads, comprehensive development tools and frameworks, strong optimization for transformer models. Weaknesses: Hardware dependency creates vendor lock-in, high power consumption requirements, primarily infrastructure provider rather than end-user solution developer.
Core Innovations in Multimodal Processing for Virtual Assistants
Efficient vision-language retrieval using structural pruning
PatentPendingUS20250013866A1
Innovation
- A progressive pruning process is applied to the embedding neural network, selectively pruning neurons with the least influence on downstream tasks and fine-tuning the model multiple times to maintain alignment across modalities, reducing the number of parameters and improving inference speed.
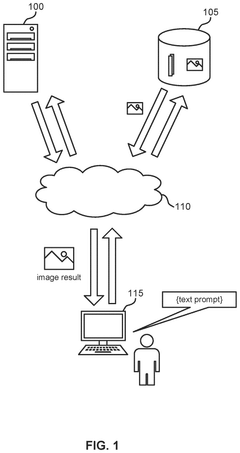
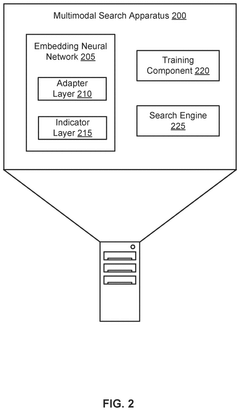
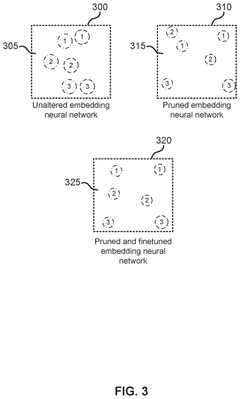
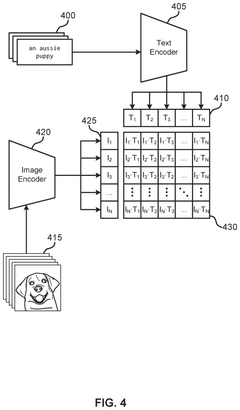
Comparing performance of virtual assistants
PatentInactiveUS20210209441A1
Innovation
- A system and method that allows users to select and weight metrics for evaluating virtual assistants, analyze chat sessions using these metrics, and generate scores for comparison, enabling recommendations on which virtual assistant provides better customer service.




Privacy and Data Protection Considerations in Multimodal AI
Privacy and data protection represent critical considerations in the deployment of vision-language models within virtual assistant systems. These multimodal AI systems process vast amounts of sensitive user data, including visual inputs from cameras, audio recordings, text conversations, and contextual information about user behaviors and preferences. The integration of multiple data modalities creates compound privacy risks that extend beyond traditional single-modal systems.
The collection and processing of multimodal data raise significant concerns regarding user consent and data minimization principles. Vision-language models require extensive training datasets that often contain personally identifiable information, biometric data, and intimate details about users' daily lives. Current regulatory frameworks such as GDPR, CCPA, and emerging AI governance standards impose strict requirements on how this data must be handled, stored, and processed.
Data anonymization and pseudonymization techniques face unique challenges in multimodal contexts. While traditional methods may effectively anonymize text or audio data independently, the combination of visual and linguistic information can enable re-identification through cross-modal correlation. Advanced techniques such as differential privacy, federated learning, and homomorphic encryption are being explored to address these vulnerabilities while maintaining model performance.
Edge computing and on-device processing emerge as promising approaches to enhance privacy protection. By performing inference locally rather than transmitting raw data to cloud servers, these architectures can significantly reduce privacy exposure. However, the computational requirements of sophisticated vision-language models often exceed current mobile device capabilities, necessitating careful balance between privacy protection and system efficiency.
Transparency and explainability requirements add another layer of complexity to privacy considerations. Users must understand what data is being collected, how it is processed, and what decisions are being made based on their information. This is particularly challenging for vision-language models, which often operate as black-box systems with limited interpretability.
Cross-border data transfer regulations further complicate the deployment of global virtual assistant services. Different jurisdictions maintain varying standards for data protection, requiring sophisticated compliance frameworks that can adapt to local requirements while maintaining consistent user experiences across regions.
The collection and processing of multimodal data raise significant concerns regarding user consent and data minimization principles. Vision-language models require extensive training datasets that often contain personally identifiable information, biometric data, and intimate details about users' daily lives. Current regulatory frameworks such as GDPR, CCPA, and emerging AI governance standards impose strict requirements on how this data must be handled, stored, and processed.
Data anonymization and pseudonymization techniques face unique challenges in multimodal contexts. While traditional methods may effectively anonymize text or audio data independently, the combination of visual and linguistic information can enable re-identification through cross-modal correlation. Advanced techniques such as differential privacy, federated learning, and homomorphic encryption are being explored to address these vulnerabilities while maintaining model performance.
Edge computing and on-device processing emerge as promising approaches to enhance privacy protection. By performing inference locally rather than transmitting raw data to cloud servers, these architectures can significantly reduce privacy exposure. However, the computational requirements of sophisticated vision-language models often exceed current mobile device capabilities, necessitating careful balance between privacy protection and system efficiency.
Transparency and explainability requirements add another layer of complexity to privacy considerations. Users must understand what data is being collected, how it is processed, and what decisions are being made based on their information. This is particularly challenging for vision-language models, which often operate as black-box systems with limited interpretability.
Cross-border data transfer regulations further complicate the deployment of global virtual assistant services. Different jurisdictions maintain varying standards for data protection, requiring sophisticated compliance frameworks that can adapt to local requirements while maintaining consistent user experiences across regions.
Performance Benchmarking Standards for Vision-Language Models
Establishing comprehensive performance benchmarking standards for vision-language models in virtual assistant applications requires a multi-dimensional evaluation framework that addresses both technical capabilities and practical deployment considerations. Current benchmarking approaches often focus on isolated metrics, failing to capture the holistic performance requirements of real-world virtual assistant scenarios.
The foundation of effective benchmarking lies in defining standardized evaluation datasets that reflect authentic user interactions. These datasets must encompass diverse visual content types, including natural scenes, user interfaces, documents, and multimedia presentations, paired with corresponding natural language queries. The complexity of these interactions should span from simple object identification to sophisticated reasoning tasks involving temporal sequences and contextual understanding.
Computational efficiency metrics form a critical component of benchmarking standards, particularly for resource-constrained deployment environments. Standard measurements should include inference latency, memory consumption, energy efficiency, and throughput capacity under varying load conditions. These metrics must be evaluated across different hardware configurations, from edge devices to cloud-based infrastructures, ensuring scalability assessments align with deployment realities.
Response quality evaluation requires sophisticated scoring mechanisms that extend beyond traditional accuracy measures. Benchmarking standards should incorporate semantic coherence assessment, contextual relevance scoring, and user satisfaction metrics derived from human evaluation studies. Multi-modal alignment quality becomes particularly crucial, measuring how effectively models integrate visual and textual information to generate coherent responses.
Robustness testing protocols must address model performance under adverse conditions, including low-quality images, ambiguous queries, and edge cases that commonly occur in real-world applications. Standardized stress testing procedures should evaluate model degradation patterns and failure modes, providing insights into reliability characteristics essential for production deployment.
Cross-model comparison frameworks require normalized evaluation environments that eliminate implementation-specific advantages while highlighting genuine architectural innovations. These standards should facilitate fair comparisons across different model architectures, training methodologies, and optimization strategies, enabling objective assessment of technological advancement and practical applicability in virtual assistant systems.
The foundation of effective benchmarking lies in defining standardized evaluation datasets that reflect authentic user interactions. These datasets must encompass diverse visual content types, including natural scenes, user interfaces, documents, and multimedia presentations, paired with corresponding natural language queries. The complexity of these interactions should span from simple object identification to sophisticated reasoning tasks involving temporal sequences and contextual understanding.
Computational efficiency metrics form a critical component of benchmarking standards, particularly for resource-constrained deployment environments. Standard measurements should include inference latency, memory consumption, energy efficiency, and throughput capacity under varying load conditions. These metrics must be evaluated across different hardware configurations, from edge devices to cloud-based infrastructures, ensuring scalability assessments align with deployment realities.
Response quality evaluation requires sophisticated scoring mechanisms that extend beyond traditional accuracy measures. Benchmarking standards should incorporate semantic coherence assessment, contextual relevance scoring, and user satisfaction metrics derived from human evaluation studies. Multi-modal alignment quality becomes particularly crucial, measuring how effectively models integrate visual and textual information to generate coherent responses.
Robustness testing protocols must address model performance under adverse conditions, including low-quality images, ambiguous queries, and edge cases that commonly occur in real-world applications. Standardized stress testing procedures should evaluate model degradation patterns and failure modes, providing insights into reliability characteristics essential for production deployment.
Cross-model comparison frameworks require normalized evaluation environments that eliminate implementation-specific advantages while highlighting genuine architectural innovations. These standards should facilitate fair comparisons across different model architectures, training methodologies, and optimization strategies, enabling objective assessment of technological advancement and practical applicability in virtual assistant systems.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!