

Data Augmentation for E-Commerce: Impact on Personalization
FEB 27, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
E-Commerce Data Augmentation Background and Objectives
E-commerce has undergone a revolutionary transformation over the past two decades, evolving from simple online catalogs to sophisticated platforms powered by artificial intelligence and machine learning algorithms. The exponential growth of digital commerce, accelerated by global events such as the COVID-19 pandemic, has fundamentally altered consumer behavior and expectations. Modern consumers demand highly personalized shopping experiences that mirror their individual preferences, browsing patterns, and purchasing history.
The emergence of data augmentation techniques represents a critical technological advancement in addressing the personalization challenges faced by e-commerce platforms. Traditional recommendation systems often struggle with data sparsity, cold start problems, and limited user interaction data, particularly for new users or niche products. Data augmentation offers a promising solution by artificially expanding existing datasets through various computational methods, thereby enhancing the quality and quantity of training data available for personalization algorithms.
The primary objective of implementing data augmentation in e-commerce personalization is to overcome the inherent limitations of sparse user-item interaction matrices that plague most recommendation systems. By generating synthetic data points that maintain statistical properties of original datasets while introducing controlled variations, platforms can significantly improve the robustness and accuracy of their personalization engines. This approach aims to reduce the cold start problem for new users and products while enhancing recommendation diversity and coverage.
Furthermore, data augmentation techniques seek to address the challenge of temporal dynamics in user preferences. Consumer behavior patterns evolve continuously, influenced by seasonal trends, market changes, and personal circumstances. Advanced augmentation methods aim to capture and simulate these temporal variations, enabling personalization systems to adapt more effectively to changing user preferences and market conditions.
The strategic implementation of data augmentation in e-commerce personalization also targets the enhancement of cross-domain knowledge transfer. By leveraging augmented datasets, platforms can better understand user behavior patterns across different product categories, enabling more sophisticated cross-selling and up-selling strategies. This comprehensive approach to personalization ultimately aims to increase customer satisfaction, engagement rates, and revenue generation while reducing customer acquisition costs and improving long-term customer lifetime value.
The emergence of data augmentation techniques represents a critical technological advancement in addressing the personalization challenges faced by e-commerce platforms. Traditional recommendation systems often struggle with data sparsity, cold start problems, and limited user interaction data, particularly for new users or niche products. Data augmentation offers a promising solution by artificially expanding existing datasets through various computational methods, thereby enhancing the quality and quantity of training data available for personalization algorithms.
The primary objective of implementing data augmentation in e-commerce personalization is to overcome the inherent limitations of sparse user-item interaction matrices that plague most recommendation systems. By generating synthetic data points that maintain statistical properties of original datasets while introducing controlled variations, platforms can significantly improve the robustness and accuracy of their personalization engines. This approach aims to reduce the cold start problem for new users and products while enhancing recommendation diversity and coverage.
Furthermore, data augmentation techniques seek to address the challenge of temporal dynamics in user preferences. Consumer behavior patterns evolve continuously, influenced by seasonal trends, market changes, and personal circumstances. Advanced augmentation methods aim to capture and simulate these temporal variations, enabling personalization systems to adapt more effectively to changing user preferences and market conditions.
The strategic implementation of data augmentation in e-commerce personalization also targets the enhancement of cross-domain knowledge transfer. By leveraging augmented datasets, platforms can better understand user behavior patterns across different product categories, enabling more sophisticated cross-selling and up-selling strategies. This comprehensive approach to personalization ultimately aims to increase customer satisfaction, engagement rates, and revenue generation while reducing customer acquisition costs and improving long-term customer lifetime value.
Market Demand for Enhanced E-Commerce Personalization
The global e-commerce landscape is experiencing unprecedented growth, with online retail sales continuing to expand across all major markets. This expansion has intensified competition among retailers, making customer retention and engagement critical success factors. Traditional one-size-fits-all approaches to online shopping experiences are increasingly inadequate for meeting diverse consumer expectations, creating substantial demand for sophisticated personalization technologies.
Consumer behavior patterns reveal a clear preference for tailored shopping experiences. Modern shoppers expect platforms to understand their preferences, anticipate their needs, and present relevant products at optimal moments. This expectation spans across product recommendations, pricing strategies, content presentation, and communication timing. The gap between generic experiences and personalized interactions directly impacts conversion rates, customer lifetime value, and brand loyalty.
E-commerce platforms face significant challenges in delivering effective personalization due to data limitations. Many retailers struggle with insufficient customer interaction data, particularly for new users or seasonal shoppers. Cold start problems, where systems lack adequate information to generate meaningful recommendations, represent a major obstacle to personalization effectiveness. Additionally, privacy regulations and changing consumer attitudes toward data sharing have reduced available datasets for training personalization algorithms.
The market demand for enhanced personalization solutions is driving innovation in data augmentation technologies. Retailers recognize that synthetic data generation and advanced augmentation techniques can address data scarcity issues while maintaining privacy compliance. These technologies enable more robust personalization models by expanding training datasets and improving algorithm performance across diverse customer segments.
Industry adoption patterns indicate strong market pull for personalization enhancement tools. Large e-commerce platforms are investing heavily in machine learning infrastructure and data science capabilities to improve customer experiences. Mid-market retailers are seeking accessible solutions that can deliver personalization benefits without requiring extensive technical resources. This creates opportunities for both enterprise-grade platforms and simplified tools targeting smaller merchants.
The economic impact of personalization improvements is substantial. Enhanced recommendation systems directly influence revenue through increased conversion rates and average order values. Improved customer segmentation enables more effective marketing spend allocation and inventory management. These tangible business benefits are driving continued investment in personalization technologies and creating sustained market demand for innovative solutions that can overcome current technical limitations.
Consumer behavior patterns reveal a clear preference for tailored shopping experiences. Modern shoppers expect platforms to understand their preferences, anticipate their needs, and present relevant products at optimal moments. This expectation spans across product recommendations, pricing strategies, content presentation, and communication timing. The gap between generic experiences and personalized interactions directly impacts conversion rates, customer lifetime value, and brand loyalty.
E-commerce platforms face significant challenges in delivering effective personalization due to data limitations. Many retailers struggle with insufficient customer interaction data, particularly for new users or seasonal shoppers. Cold start problems, where systems lack adequate information to generate meaningful recommendations, represent a major obstacle to personalization effectiveness. Additionally, privacy regulations and changing consumer attitudes toward data sharing have reduced available datasets for training personalization algorithms.
The market demand for enhanced personalization solutions is driving innovation in data augmentation technologies. Retailers recognize that synthetic data generation and advanced augmentation techniques can address data scarcity issues while maintaining privacy compliance. These technologies enable more robust personalization models by expanding training datasets and improving algorithm performance across diverse customer segments.
Industry adoption patterns indicate strong market pull for personalization enhancement tools. Large e-commerce platforms are investing heavily in machine learning infrastructure and data science capabilities to improve customer experiences. Mid-market retailers are seeking accessible solutions that can deliver personalization benefits without requiring extensive technical resources. This creates opportunities for both enterprise-grade platforms and simplified tools targeting smaller merchants.
The economic impact of personalization improvements is substantial. Enhanced recommendation systems directly influence revenue through increased conversion rates and average order values. Improved customer segmentation enables more effective marketing spend allocation and inventory management. These tangible business benefits are driving continued investment in personalization technologies and creating sustained market demand for innovative solutions that can overcome current technical limitations.
Current State of Data Augmentation in E-Commerce Systems
Data augmentation in e-commerce systems has evolved from basic rule-based transformations to sophisticated AI-driven approaches that enhance personalization capabilities. Current implementations primarily focus on addressing data scarcity issues in recommendation systems, user behavior modeling, and product catalog management. The technology landscape shows a clear division between traditional statistical methods and emerging deep learning-based augmentation techniques.
Most established e-commerce platforms currently employ synthetic data generation methods to expand their training datasets for recommendation algorithms. These approaches include collaborative filtering enhancement through matrix completion, user profile synthesis based on demographic clustering, and product attribute interpolation. Major platforms utilize techniques such as generative adversarial networks (GANs) to create realistic user interaction patterns and purchase histories that mirror authentic customer behavior while preserving privacy constraints.
The integration of data augmentation with personalization engines has reached varying levels of maturity across different market segments. Large-scale platforms demonstrate advanced implementations that combine multiple augmentation strategies, including temporal data synthesis for seasonal pattern recognition, cross-domain transfer learning for new user onboarding, and multi-modal data fusion for enhanced product recommendations. These systems typically process augmented datasets containing 30-50% synthetic data points alongside original user interactions.
Current technical implementations face significant challenges in maintaining data quality and relevance. Existing solutions struggle with preserving semantic consistency in augmented user preferences, managing computational overhead in real-time personalization scenarios, and ensuring that synthetic data accurately reflects evolving market trends. The technology stack commonly includes frameworks such as TensorFlow Extended (TFX) for pipeline management, Apache Spark for distributed processing, and specialized libraries like Synthetic Data Vault (SDV) for structured data generation.
Performance metrics indicate that contemporary data augmentation approaches achieve 15-25% improvements in recommendation accuracy for cold-start scenarios and 10-20% enhancement in user engagement metrics. However, the technology remains constrained by limited standardization across platforms, insufficient validation methodologies for synthetic data quality, and challenges in balancing augmentation diversity with realistic user behavior patterns.
Most established e-commerce platforms currently employ synthetic data generation methods to expand their training datasets for recommendation algorithms. These approaches include collaborative filtering enhancement through matrix completion, user profile synthesis based on demographic clustering, and product attribute interpolation. Major platforms utilize techniques such as generative adversarial networks (GANs) to create realistic user interaction patterns and purchase histories that mirror authentic customer behavior while preserving privacy constraints.
The integration of data augmentation with personalization engines has reached varying levels of maturity across different market segments. Large-scale platforms demonstrate advanced implementations that combine multiple augmentation strategies, including temporal data synthesis for seasonal pattern recognition, cross-domain transfer learning for new user onboarding, and multi-modal data fusion for enhanced product recommendations. These systems typically process augmented datasets containing 30-50% synthetic data points alongside original user interactions.
Current technical implementations face significant challenges in maintaining data quality and relevance. Existing solutions struggle with preserving semantic consistency in augmented user preferences, managing computational overhead in real-time personalization scenarios, and ensuring that synthetic data accurately reflects evolving market trends. The technology stack commonly includes frameworks such as TensorFlow Extended (TFX) for pipeline management, Apache Spark for distributed processing, and specialized libraries like Synthetic Data Vault (SDV) for structured data generation.
Performance metrics indicate that contemporary data augmentation approaches achieve 15-25% improvements in recommendation accuracy for cold-start scenarios and 10-20% enhancement in user engagement metrics. However, the technology remains constrained by limited standardization across platforms, insufficient validation methodologies for synthetic data quality, and challenges in balancing augmentation diversity with realistic user behavior patterns.
Existing Data Augmentation Methods for Personalization
01 Machine learning-based personalized data augmentation
Systems and methods utilize machine learning algorithms to generate personalized augmented data based on user characteristics and behavior patterns. The approach involves training models on user-specific data to create synthetic variations that maintain relevance to individual preferences. This technique enables adaptive data generation that evolves with user interactions and feedback, improving the quality and applicability of augmented datasets for personalized applications.- Machine learning-based personalized data augmentation: Systems and methods utilize machine learning algorithms to generate personalized augmented data based on user behavior patterns and preferences. The approach involves training models on user-specific data to create synthetic variations that maintain individual characteristics while expanding the dataset. This technique enables adaptive learning systems that can better predict and respond to individual user needs through customized data generation.
- User profile-driven content augmentation: Methods for augmenting content based on detailed user profiles that capture demographic information, interaction history, and preference data. The system dynamically generates additional personalized content variations by analyzing user profile attributes and applying transformation rules specific to individual characteristics. This enables delivery of customized experiences through intelligent content expansion tailored to each user segment.
- Context-aware personalized data generation: Techniques for generating augmented data that considers contextual factors such as time, location, device type, and user activity state. The system monitors real-time context parameters and applies appropriate augmentation strategies to create personalized data variations relevant to current user situations. This approach ensures that augmented content remains contextually appropriate and personally relevant across different usage scenarios.
- Feedback-based adaptive augmentation refinement: Systems that incorporate user feedback mechanisms to continuously refine and improve personalized data augmentation processes. The approach collects explicit and implicit feedback signals to evaluate the effectiveness of augmented data and adjusts generation parameters accordingly. This iterative refinement process ensures that augmentation strategies evolve to better match individual user preferences over time.
- Privacy-preserving personalized augmentation: Methods for performing personalized data augmentation while maintaining user privacy through techniques such as federated learning, differential privacy, and on-device processing. The system generates personalized augmented data without requiring centralized storage of sensitive user information, enabling customization while protecting individual privacy. This approach balances the benefits of personalization with stringent data protection requirements.
02 Context-aware data augmentation for personalization
Methods for augmenting data by incorporating contextual information such as location, time, device type, and environmental factors to enhance personalization. The system analyzes contextual parameters to generate relevant variations of original data that align with specific usage scenarios. This approach ensures that augmented data reflects real-world conditions and user circumstances, leading to more accurate and personalized outcomes.Expand Specific Solutions03 User profile-based synthetic data generation
Techniques for creating synthetic data based on comprehensive user profiles that include demographic information, preferences, historical interactions, and behavioral patterns. The system builds detailed user models and generates augmented data that reflects individual characteristics while maintaining privacy. This method enables scalable personalization by creating diverse training datasets tailored to specific user segments without requiring additional real user data.Expand Specific Solutions04 Adaptive augmentation with feedback loops
Systems that implement feedback mechanisms to continuously refine data augmentation strategies based on user responses and engagement metrics. The approach monitors the effectiveness of personalized content and adjusts augmentation parameters dynamically to optimize relevance. This iterative process ensures that generated data remains aligned with evolving user preferences and improves personalization accuracy over time.Expand Specific Solutions05 Privacy-preserving personalized data augmentation
Methods for augmenting data while protecting user privacy through techniques such as differential privacy, federated learning, and anonymization. The system generates personalized variations without exposing sensitive user information or requiring centralized data storage. This approach enables effective personalization while complying with privacy regulations and maintaining user trust through secure data handling practices.Expand Specific Solutions
Key Players in E-Commerce Personalization Solutions
The data augmentation for e-commerce personalization landscape represents a rapidly evolving market in its growth phase, driven by increasing demand for enhanced customer experiences and AI-driven recommendations. The market demonstrates significant scale with major technology giants like Microsoft Technology Licensing LLC, IBM, and Oracle International Corp. leading infrastructure development, while specialized e-commerce players including Alibaba Group, Coupang Corp., and Walmart Apollo LLC drive practical applications. Technology maturity varies considerably across segments, with established companies like Visa International Service Association and Stripe Inc. offering mature payment personalization solutions, while emerging specialists such as GroupBy Inc. and Klevu Oy focus on advanced search and discovery personalization. Academic institutions including Nanjing University and Xidian University contribute cutting-edge research, indicating strong foundational development. The competitive landscape shows convergence between traditional tech infrastructure providers and specialized e-commerce solution vendors, suggesting the technology is transitioning from experimental to mainstream adoption phases.
Oracle International Corp.
Technical Solution: Oracle's data augmentation approach for e-commerce personalization centers on their Autonomous Database and AI services, which automatically generate synthetic customer data to enhance personalization models. Their solution includes intelligent data sampling techniques that create representative customer segments and behavioral patterns from limited datasets. Oracle implements advanced statistical methods and machine learning algorithms to augment transactional data, customer profiles, and product interaction histories. Their platform provides automated feature engineering and data synthesis capabilities that help e-commerce businesses overcome data scarcity challenges while maintaining statistical validity and business relevance in personalization algorithms.
Strengths: Enterprise-grade database management, automated ML capabilities, strong data governance features. Weaknesses: High licensing costs, steep learning curve, primarily suited for large enterprises.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft's data augmentation strategy for e-commerce personalization focuses on Azure-based machine learning services that provide automated data augmentation capabilities. Their approach includes semantic data augmentation using natural language processing to enhance product descriptions and user reviews, creating variations that maintain semantic meaning while expanding training datasets. Microsoft implements federated learning techniques combined with differential privacy to augment user data without compromising individual privacy. Their Cognitive Services APIs enable e-commerce platforms to generate synthetic user interactions and product recommendations through advanced AI models, improving personalization accuracy while maintaining data compliance standards.
Strengths: Strong cloud infrastructure, enterprise-grade security, comprehensive AI toolkit. Weaknesses: Higher costs for small businesses, complexity in implementation for non-technical teams.
Core Innovations in E-Commerce Data Enhancement
System and method for web-based personalization and ecommerce management
PatentInactiveUS7499948B2
Innovation
- A rules-based personalization system that uses a rules engine to analyze user interactions in real-time, allowing for dynamic content customization and business function personalization through scenarios and campaigns, enabling personalized content delivery based on user profiles and session information without relying on secondary data sources.
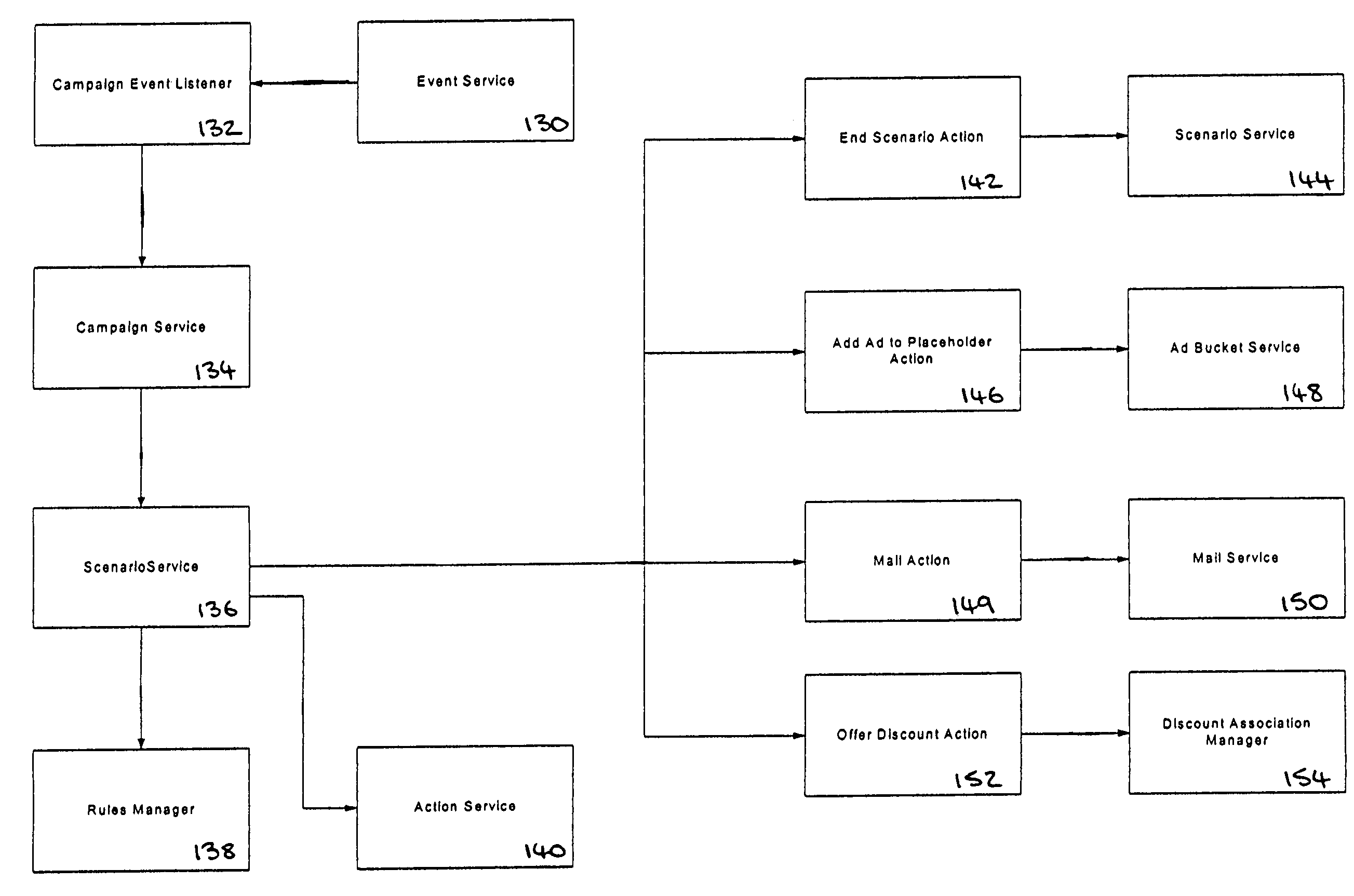
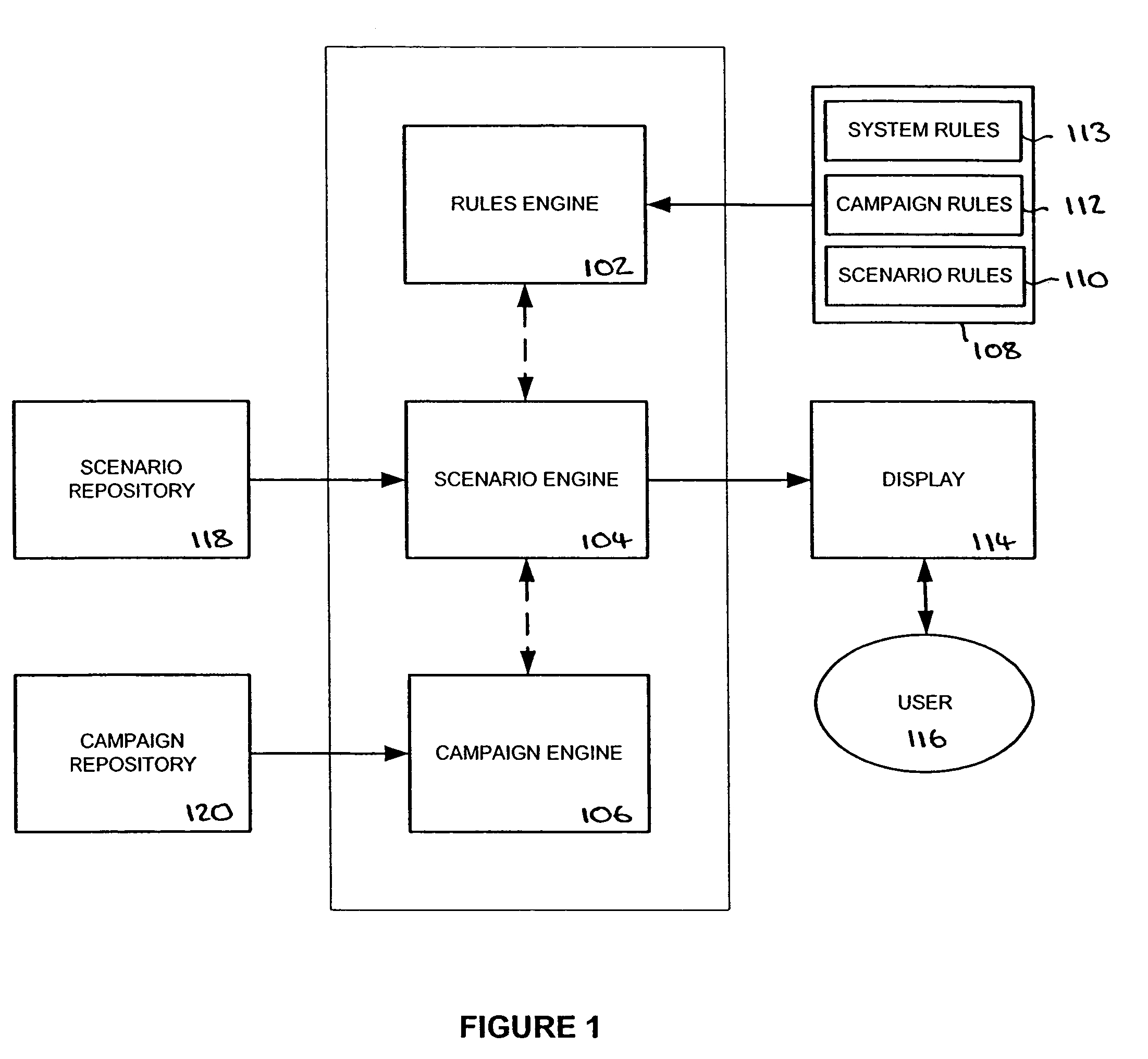
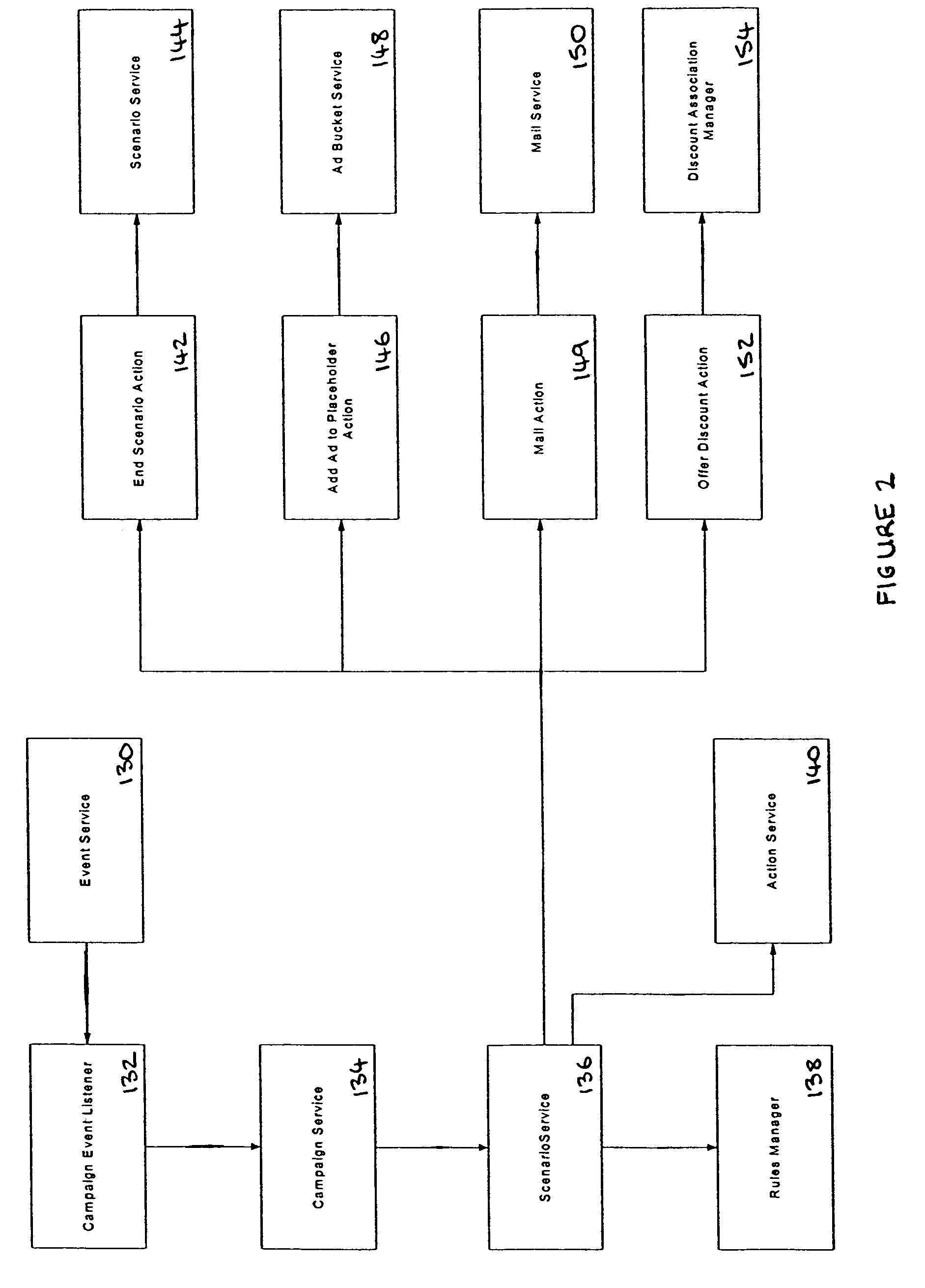

Improved collaborative filtering recommendation method under big data based on random forest correction
PatentActiveCN108920709A
Innovation
- An improved collaborative filtering recommendation method based on big data based on random forest correction is adopted. By constructing a random forest classification model of user preferences, the improved user similarity and prediction score are calculated, and the recommendation results are modified based on the random forest classification model to improve the accuracy of recommendations. sex and diversity.




Privacy Regulations Impact on E-Commerce Data Usage
The implementation of data augmentation techniques in e-commerce personalization systems faces significant constraints from evolving privacy regulations worldwide. The General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) have established stringent requirements for data collection, processing, and user consent, fundamentally altering how e-commerce platforms can leverage customer data for augmentation purposes.
Privacy regulations impose strict limitations on the types of data that can be collected and processed for personalization enhancement. Under GDPR, e-commerce platforms must obtain explicit consent for data processing activities, including synthetic data generation and cross-user behavioral pattern analysis commonly used in augmentation strategies. This requirement significantly reduces the available data pool for training personalization algorithms, as many users opt out of extensive data collection practices.
The principle of data minimization mandated by privacy laws directly conflicts with traditional data augmentation approaches that rely on comprehensive user profiling. E-commerce companies must now balance the need for rich datasets to improve personalization accuracy with regulatory requirements to collect only necessary data. This constraint forces organizations to develop more efficient augmentation techniques that can achieve comparable personalization results with limited data inputs.
Cross-border data transfer restrictions further complicate data augmentation strategies for global e-commerce platforms. Regulations require data localization in specific jurisdictions, preventing the aggregation of international user datasets that could enhance augmentation models. This fragmentation reduces the effectiveness of machine learning algorithms that benefit from diverse, large-scale datasets for generating synthetic user behaviors and preferences.
The right to data portability and deletion under privacy regulations creates additional challenges for maintaining consistent augmentation datasets. When users exercise their rights to data removal, e-commerce platforms must ensure that synthetic data derived from original user information is also appropriately handled, requiring sophisticated data lineage tracking systems.
Compliance costs associated with privacy regulations significantly impact the economic viability of advanced data augmentation projects. Organizations must invest in privacy-preserving technologies, legal compliance frameworks, and audit systems, potentially reducing resources available for personalization algorithm development and deployment.
Privacy regulations impose strict limitations on the types of data that can be collected and processed for personalization enhancement. Under GDPR, e-commerce platforms must obtain explicit consent for data processing activities, including synthetic data generation and cross-user behavioral pattern analysis commonly used in augmentation strategies. This requirement significantly reduces the available data pool for training personalization algorithms, as many users opt out of extensive data collection practices.
The principle of data minimization mandated by privacy laws directly conflicts with traditional data augmentation approaches that rely on comprehensive user profiling. E-commerce companies must now balance the need for rich datasets to improve personalization accuracy with regulatory requirements to collect only necessary data. This constraint forces organizations to develop more efficient augmentation techniques that can achieve comparable personalization results with limited data inputs.
Cross-border data transfer restrictions further complicate data augmentation strategies for global e-commerce platforms. Regulations require data localization in specific jurisdictions, preventing the aggregation of international user datasets that could enhance augmentation models. This fragmentation reduces the effectiveness of machine learning algorithms that benefit from diverse, large-scale datasets for generating synthetic user behaviors and preferences.
The right to data portability and deletion under privacy regulations creates additional challenges for maintaining consistent augmentation datasets. When users exercise their rights to data removal, e-commerce platforms must ensure that synthetic data derived from original user information is also appropriately handled, requiring sophisticated data lineage tracking systems.
Compliance costs associated with privacy regulations significantly impact the economic viability of advanced data augmentation projects. Organizations must invest in privacy-preserving technologies, legal compliance frameworks, and audit systems, potentially reducing resources available for personalization algorithm development and deployment.
Ethical AI Considerations in E-Commerce Personalization
The integration of data augmentation techniques in e-commerce personalization systems raises significant ethical considerations that organizations must carefully navigate. As artificial intelligence becomes increasingly sophisticated in generating synthetic customer data and behavioral patterns, the boundary between authentic user preferences and algorithmically created profiles becomes increasingly blurred, necessitating robust ethical frameworks to guide implementation decisions.
Privacy preservation emerges as a fundamental concern when employing data augmentation for personalization. While synthetic data generation can help protect individual customer identities by creating anonymized datasets, the process itself may inadvertently expose sensitive information through pattern recognition and reverse engineering techniques. Organizations must ensure that augmented datasets do not compromise user privacy or enable re-identification of individuals through behavioral fingerprinting or demographic inference.
Algorithmic bias represents another critical ethical challenge in augmented personalization systems. Data augmentation techniques may inadvertently amplify existing biases present in historical customer data, leading to discriminatory recommendations or exclusionary practices. When synthetic data generation models learn from biased training sets, they can perpetuate and even magnify unfair treatment of certain demographic groups, potentially violating anti-discrimination principles and regulatory requirements.
Transparency and explainability become increasingly complex when augmented data influences personalization algorithms. Customers have legitimate expectations to understand how their personal information shapes their shopping experience, but the introduction of synthetic data creates opacity in decision-making processes. Organizations must develop mechanisms to maintain algorithmic accountability while leveraging augmented datasets for improved personalization outcomes.
Consent and data governance frameworks require careful reconsideration in the context of augmented personalization. Traditional consent models may not adequately address scenarios where customer data is transformed, synthesized, or combined with artificially generated information. Clear policies must define how augmented data is created, stored, and utilized, ensuring customers maintain control over their digital footprint and derived insights.
The potential for manipulation through hyper-personalized experiences powered by augmented data raises additional ethical concerns. Enhanced personalization capabilities may enable exploitative practices that target vulnerable consumers or create addictive shopping behaviors, requiring organizations to balance commercial objectives with responsible AI deployment and consumer protection principles.
Privacy preservation emerges as a fundamental concern when employing data augmentation for personalization. While synthetic data generation can help protect individual customer identities by creating anonymized datasets, the process itself may inadvertently expose sensitive information through pattern recognition and reverse engineering techniques. Organizations must ensure that augmented datasets do not compromise user privacy or enable re-identification of individuals through behavioral fingerprinting or demographic inference.
Algorithmic bias represents another critical ethical challenge in augmented personalization systems. Data augmentation techniques may inadvertently amplify existing biases present in historical customer data, leading to discriminatory recommendations or exclusionary practices. When synthetic data generation models learn from biased training sets, they can perpetuate and even magnify unfair treatment of certain demographic groups, potentially violating anti-discrimination principles and regulatory requirements.
Transparency and explainability become increasingly complex when augmented data influences personalization algorithms. Customers have legitimate expectations to understand how their personal information shapes their shopping experience, but the introduction of synthetic data creates opacity in decision-making processes. Organizations must develop mechanisms to maintain algorithmic accountability while leveraging augmented datasets for improved personalization outcomes.
Consent and data governance frameworks require careful reconsideration in the context of augmented personalization. Traditional consent models may not adequately address scenarios where customer data is transformed, synthesized, or combined with artificially generated information. Clear policies must define how augmented data is created, stored, and utilized, ensuring customers maintain control over their digital footprint and derived insights.
The potential for manipulation through hyper-personalized experiences powered by augmented data raises additional ethical concerns. Enhanced personalization capabilities may enable exploitative practices that target vulnerable consumers or create addictive shopping behaviors, requiring organizations to balance commercial objectives with responsible AI deployment and consumer protection principles.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!