Harnessing Data Augmentation for Climate Change Models
FEB 27, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Climate Data Augmentation Background and Objectives
Climate change modeling has emerged as one of the most critical scientific endeavors of the 21st century, driven by the urgent need to understand and predict Earth's evolving climate system. The complexity of atmospheric, oceanic, and terrestrial interactions requires sophisticated computational models that can process vast amounts of observational data to generate reliable projections for policy-making and adaptation strategies.
The historical development of climate modeling began in the 1960s with simple energy balance models and has evolved into comprehensive Earth System Models that integrate multiple physical, chemical, and biological processes. However, these models face significant limitations due to sparse observational data, particularly in remote regions and for historical periods where instrumental records are incomplete or entirely absent.
Data augmentation techniques, originally developed for machine learning applications in computer vision and natural language processing, have recently gained attention as a potential solution to address data scarcity challenges in climate science. These methods can artificially expand limited datasets by generating synthetic but realistic data points that preserve the statistical properties and physical relationships inherent in the original observations.
The primary objective of harnessing data augmentation for climate change models is to enhance model training effectiveness and improve prediction accuracy across multiple temporal and spatial scales. This involves developing sophisticated algorithms that can generate synthetic climate data while maintaining physical consistency and preserving critical climate patterns such as seasonal cycles, extreme weather events, and long-term trends.
Key technical goals include creating augmentation methods that respect fundamental physical laws governing atmospheric dynamics, ensuring generated data maintains proper correlations between different climate variables, and developing validation frameworks to assess the quality and reliability of augmented datasets. Additionally, the technology aims to address regional data gaps, particularly in developing countries and polar regions where observational networks are limited.
The evolution of this field represents a convergence of traditional climate science with modern artificial intelligence techniques, promising to unlock new capabilities in climate prediction and risk assessment. Success in this domain could significantly enhance our ability to model climate extremes, improve seasonal forecasting accuracy, and provide more robust projections for climate impact assessments across various sectors including agriculture, water resources, and disaster management.
The historical development of climate modeling began in the 1960s with simple energy balance models and has evolved into comprehensive Earth System Models that integrate multiple physical, chemical, and biological processes. However, these models face significant limitations due to sparse observational data, particularly in remote regions and for historical periods where instrumental records are incomplete or entirely absent.
Data augmentation techniques, originally developed for machine learning applications in computer vision and natural language processing, have recently gained attention as a potential solution to address data scarcity challenges in climate science. These methods can artificially expand limited datasets by generating synthetic but realistic data points that preserve the statistical properties and physical relationships inherent in the original observations.
The primary objective of harnessing data augmentation for climate change models is to enhance model training effectiveness and improve prediction accuracy across multiple temporal and spatial scales. This involves developing sophisticated algorithms that can generate synthetic climate data while maintaining physical consistency and preserving critical climate patterns such as seasonal cycles, extreme weather events, and long-term trends.
Key technical goals include creating augmentation methods that respect fundamental physical laws governing atmospheric dynamics, ensuring generated data maintains proper correlations between different climate variables, and developing validation frameworks to assess the quality and reliability of augmented datasets. Additionally, the technology aims to address regional data gaps, particularly in developing countries and polar regions where observational networks are limited.
The evolution of this field represents a convergence of traditional climate science with modern artificial intelligence techniques, promising to unlock new capabilities in climate prediction and risk assessment. Success in this domain could significantly enhance our ability to model climate extremes, improve seasonal forecasting accuracy, and provide more robust projections for climate impact assessments across various sectors including agriculture, water resources, and disaster management.
Market Demand for Enhanced Climate Modeling Accuracy
The global climate modeling market is experiencing unprecedented growth driven by escalating concerns over climate change impacts and the urgent need for accurate predictive capabilities. Governments, research institutions, and private organizations are increasingly investing in sophisticated climate modeling solutions to support policy decisions, risk assessments, and adaptation strategies. This surge in demand stems from the recognition that traditional climate models often lack the precision required for localized predictions and extreme weather event forecasting.
Financial institutions represent a rapidly expanding market segment, particularly following the implementation of climate risk disclosure requirements by regulatory bodies worldwide. Banks, insurance companies, and investment firms require highly accurate climate projections to assess portfolio risks, price climate-related financial products, and comply with emerging regulations. The insurance sector alone demonstrates substantial appetite for enhanced modeling accuracy to improve catastrophe risk pricing and reduce underwriting uncertainties.
Agricultural industries constitute another critical demand driver, as farmers and agribusiness companies seek precise seasonal forecasting and long-term climate projections to optimize crop planning, irrigation management, and supply chain operations. The growing emphasis on sustainable agriculture and food security amplifies the need for granular, location-specific climate predictions that current models struggle to provide consistently.
Urban planning and infrastructure development sectors increasingly rely on detailed climate projections for designing resilient cities and critical infrastructure. Municipal governments and engineering firms require enhanced modeling accuracy to assess flood risks, heat island effects, and extreme weather impacts on transportation networks, energy systems, and water resources. The integration of climate considerations into building codes and infrastructure standards further drives demand for precise modeling capabilities.
The renewable energy sector presents substantial market opportunities, as wind and solar project developers require accurate long-term climate forecasts for site selection, energy yield predictions, and financial modeling. Enhanced climate modeling accuracy directly impacts investment decisions and project viability assessments in this rapidly expanding industry.
Research institutions and academic organizations continue to represent core market segments, driven by increasing research funding for climate science and the need to improve model performance for scientific publications and policy recommendations. International climate research collaborations and government-funded climate programs sustain consistent demand for advanced modeling technologies and methodologies.
Financial institutions represent a rapidly expanding market segment, particularly following the implementation of climate risk disclosure requirements by regulatory bodies worldwide. Banks, insurance companies, and investment firms require highly accurate climate projections to assess portfolio risks, price climate-related financial products, and comply with emerging regulations. The insurance sector alone demonstrates substantial appetite for enhanced modeling accuracy to improve catastrophe risk pricing and reduce underwriting uncertainties.
Agricultural industries constitute another critical demand driver, as farmers and agribusiness companies seek precise seasonal forecasting and long-term climate projections to optimize crop planning, irrigation management, and supply chain operations. The growing emphasis on sustainable agriculture and food security amplifies the need for granular, location-specific climate predictions that current models struggle to provide consistently.
Urban planning and infrastructure development sectors increasingly rely on detailed climate projections for designing resilient cities and critical infrastructure. Municipal governments and engineering firms require enhanced modeling accuracy to assess flood risks, heat island effects, and extreme weather impacts on transportation networks, energy systems, and water resources. The integration of climate considerations into building codes and infrastructure standards further drives demand for precise modeling capabilities.
The renewable energy sector presents substantial market opportunities, as wind and solar project developers require accurate long-term climate forecasts for site selection, energy yield predictions, and financial modeling. Enhanced climate modeling accuracy directly impacts investment decisions and project viability assessments in this rapidly expanding industry.
Research institutions and academic organizations continue to represent core market segments, driven by increasing research funding for climate science and the need to improve model performance for scientific publications and policy recommendations. International climate research collaborations and government-funded climate programs sustain consistent demand for advanced modeling technologies and methodologies.
Current Limitations in Climate Data Availability and Quality
Climate change modeling faces significant constraints due to fundamental limitations in data availability and quality, which directly impact the accuracy and reliability of predictive models. These limitations create substantial barriers to developing robust climate projections and understanding regional climate variations.
Temporal data coverage represents one of the most critical challenges in climate modeling. Instrumental climate records typically span only 150-200 years, providing insufficient historical context for understanding long-term climate variability and extreme events. This limited temporal scope makes it difficult to capture rare but significant climate phenomena, such as multi-decadal oscillations or century-scale climate shifts that are crucial for accurate long-term predictions.
Spatial data distribution exhibits severe geographical imbalances, with dense observation networks concentrated in developed regions while vast areas remain under-monitored. Ocean regions, polar areas, and developing countries often lack adequate meteorological stations, creating significant data gaps. This uneven spatial coverage introduces systematic biases in global climate models and limits the ability to accurately represent regional climate processes.
Data quality issues further compound these availability challenges. Historical climate records suffer from inconsistencies due to changes in measurement techniques, station relocations, and varying observation practices over time. Many datasets contain missing values, measurement errors, and temporal discontinuities that require extensive preprocessing and quality control procedures before use in modeling applications.
Resolution limitations present another significant constraint, as observational data often lacks the spatial and temporal resolution required for high-fidelity climate modeling. Satellite data, while providing global coverage, may have limited temporal depth or suffer from calibration drift over time. Ground-based observations, though more accurate locally, cannot capture the full three-dimensional structure of atmospheric and oceanic processes.
The integration of heterogeneous data sources creates additional complexity, as different measurement systems, units, and protocols must be harmonized. This integration challenge is particularly acute when combining traditional meteorological observations with newer remote sensing data or paleoclimate proxies, each having distinct uncertainty characteristics and temporal resolutions.
These data limitations collectively constrain the development of comprehensive climate models and highlight the critical need for innovative approaches, such as data augmentation techniques, to enhance the quantity and quality of available climate datasets for improved modeling capabilities.
Temporal data coverage represents one of the most critical challenges in climate modeling. Instrumental climate records typically span only 150-200 years, providing insufficient historical context for understanding long-term climate variability and extreme events. This limited temporal scope makes it difficult to capture rare but significant climate phenomena, such as multi-decadal oscillations or century-scale climate shifts that are crucial for accurate long-term predictions.
Spatial data distribution exhibits severe geographical imbalances, with dense observation networks concentrated in developed regions while vast areas remain under-monitored. Ocean regions, polar areas, and developing countries often lack adequate meteorological stations, creating significant data gaps. This uneven spatial coverage introduces systematic biases in global climate models and limits the ability to accurately represent regional climate processes.
Data quality issues further compound these availability challenges. Historical climate records suffer from inconsistencies due to changes in measurement techniques, station relocations, and varying observation practices over time. Many datasets contain missing values, measurement errors, and temporal discontinuities that require extensive preprocessing and quality control procedures before use in modeling applications.
Resolution limitations present another significant constraint, as observational data often lacks the spatial and temporal resolution required for high-fidelity climate modeling. Satellite data, while providing global coverage, may have limited temporal depth or suffer from calibration drift over time. Ground-based observations, though more accurate locally, cannot capture the full three-dimensional structure of atmospheric and oceanic processes.
The integration of heterogeneous data sources creates additional complexity, as different measurement systems, units, and protocols must be harmonized. This integration challenge is particularly acute when combining traditional meteorological observations with newer remote sensing data or paleoclimate proxies, each having distinct uncertainty characteristics and temporal resolutions.
These data limitations collectively constrain the development of comprehensive climate models and highlight the critical need for innovative approaches, such as data augmentation techniques, to enhance the quantity and quality of available climate datasets for improved modeling capabilities.
Existing Data Augmentation Approaches for Climate Models
01 Synthetic data generation for training machine learning models
Data augmentation techniques involve generating synthetic training data to expand limited datasets. This approach creates artificial samples by applying transformations, variations, or generative models to existing data. The synthetic data helps improve model robustness and generalization by providing diverse training examples that capture different variations and edge cases not present in the original dataset.- Synthetic data generation for training machine learning models: Data augmentation techniques involve generating synthetic training data to expand limited datasets. This approach creates artificial samples by applying transformations, variations, or generative models to existing data. The synthetic data helps improve model robustness and generalization by providing diverse training examples that capture different variations and edge cases not present in the original dataset.
- Image transformation and manipulation techniques: Various image processing methods are applied to augment visual data, including rotation, scaling, cropping, flipping, color adjustment, and noise injection. These transformations create multiple variations of original images while preserving their semantic content. Such techniques are particularly effective for computer vision applications where training data diversity is crucial for model performance.
- Generative adversarial networks for data augmentation: Advanced neural network architectures are employed to generate realistic synthetic data samples. These systems use adversarial training processes where generator networks create new data instances while discriminator networks evaluate their authenticity. This approach produces high-quality augmented data that closely resembles real-world distributions and can significantly expand training datasets.
- Domain-specific augmentation for specialized applications: Tailored augmentation strategies are developed for specific domains such as medical imaging, autonomous driving, or natural language processing. These methods incorporate domain knowledge to generate meaningful variations that reflect real-world scenarios. The techniques ensure that augmented data maintains domain-relevant characteristics while introducing appropriate diversity for improved model training.
- Automated augmentation policy learning and optimization: Machine learning systems automatically discover and optimize data augmentation strategies through reinforcement learning or evolutionary algorithms. These methods search through possible augmentation operations and their parameters to identify the most effective combinations for specific tasks. The automated approach eliminates manual tuning and adapts augmentation policies to different datasets and model architectures.
02 Image transformation and manipulation techniques
Various image processing methods are applied to augment visual data, including rotation, scaling, cropping, flipping, color adjustment, and noise injection. These transformations create multiple variations of original images while preserving essential features and labels. Such techniques are particularly effective for computer vision applications where training data diversity is crucial for model performance.Expand Specific Solutions03 Neural network-based augmentation strategies
Advanced augmentation methods utilize neural networks and deep learning architectures to generate augmented data. These approaches include generative adversarial networks and autoencoder-based systems that learn data distributions and create realistic synthetic samples. The neural network-driven methods can produce more sophisticated and contextually appropriate augmented data compared to traditional transformation techniques.Expand Specific Solutions04 Domain-specific data augmentation for specialized applications
Tailored augmentation strategies are developed for specific domains such as medical imaging, autonomous vehicles, speech recognition, or natural language processing. These specialized techniques consider domain-specific constraints, characteristics, and requirements to generate meaningful augmented data. The methods ensure that synthetic samples maintain domain relevance and validity while expanding dataset diversity.Expand Specific Solutions05 Automated and adaptive augmentation policies
Systems that automatically determine optimal augmentation strategies through learning-based approaches or policy search methods. These techniques dynamically adjust augmentation parameters based on model performance, dataset characteristics, or task requirements. Automated augmentation reduces manual effort in selecting appropriate transformations and can discover novel augmentation strategies that improve model accuracy.Expand Specific Solutions
Key Players in Climate Modeling and AI Data Solutions
The competitive landscape for harnessing data augmentation in climate change models represents an emerging yet rapidly evolving sector. The industry is in its early-to-mid development stage, with significant growth potential as climate modeling becomes increasingly critical for policy and business decisions. Market size is expanding driven by urgent climate adaptation needs and regulatory requirements. Technology maturity varies considerably across players, with established tech giants like Tencent Technology and IBM leveraging advanced AI capabilities, while specialized climate-focused companies like ClimateAI demonstrate targeted expertise. Academic institutions including Tsinghua University, Beihang University, and Nanjing University of Information Science & Technology contribute foundational research, while state-owned enterprises such as State Grid Corp. and China Three Gorges Corp. provide practical implementation platforms, creating a diverse ecosystem spanning pure research to commercial applications.
Tencent Technology (Shenzhen) Co., Ltd.
Technical Solution: Tencent has leveraged its cloud computing and AI capabilities to develop climate modeling solutions incorporating advanced data augmentation techniques. Their approach utilizes deep learning frameworks for generating synthetic climate data, particularly focusing on extreme weather event simulation and prediction. Tencent Cloud's AI platform provides scalable infrastructure for processing large-scale climate datasets, implementing data augmentation through variational autoencoders and transformer-based models. The company's solution includes real-time data ingestion from multiple sources, automated data quality assessment, and intelligent augmentation strategies that adapt to regional climate characteristics. Their platform supports collaborative research initiatives and provides APIs for integrating augmented climate data into various applications including urban planning and disaster management systems.
Strengths: Massive cloud infrastructure, strong AI and machine learning capabilities, extensive data processing experience. Weaknesses: Limited domain expertise in climate science, primarily technology-focused rather than climate research-oriented.
Nanjing University of Information Science & Technology
Technical Solution: NUIST has established comprehensive research programs focusing on meteorological data augmentation for climate modeling applications. Their approach combines traditional statistical methods with modern machine learning techniques to enhance climate dataset quality and coverage. The university's research includes developing specialized augmentation algorithms for precipitation data, temperature records, and atmospheric circulation patterns. Their methodologies incorporate ensemble-based augmentation strategies, utilizing multiple climate model outputs to generate probabilistic training datasets. NUIST's research team has developed innovative approaches for handling missing data in historical climate records through intelligent interpolation and extrapolation techniques. Their work emphasizes maintaining physical consistency in augmented data while addressing temporal and spatial gaps in observational datasets for improved climate change impact assessments.
Strengths: Specialized meteorological expertise, strong research foundation in atmospheric sciences, comprehensive understanding of climate data characteristics. Weaknesses: Limited computational resources compared to commercial entities, primarily academic research focus with slower technology transfer.
Core Innovations in Synthetic Climate Data Generation
Systems and methods of data preprocessing and augmentation for neural network climate forecasting models
PatentActiveUS20230128989A1
Innovation
- A neural network-based climate forecasting model is developed, trained on pre-processed multi-model ensemble global climate simulation data, using techniques like spatial and temporal homogenization, augmentation with synthetic data, and fine-tuned with observational historical data to enhance forecasting accuracy and efficiency.
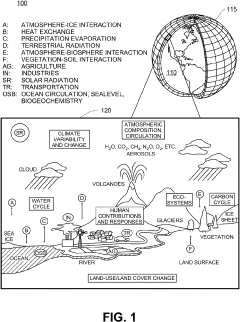
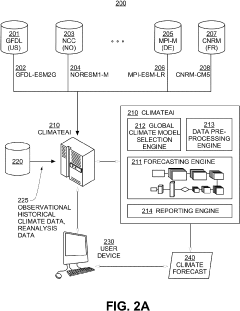
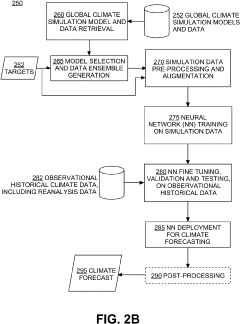
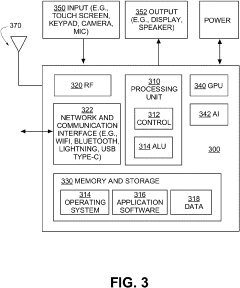
Methods and systems for climate forecasting using artificial neural networks
PatentActiveUS20220146708A1
Innovation
- A neural network-based climate forecasting model is developed, trained on global climate simulation data and fine-tuned with observational historical data, utilizing Convolutional Recurrent Neural Networks (CRNN) and Spherical Convolutional Neural Networks (S2-CNN) to extract spatial-temporal features and correlations, reducing computational power requirements while achieving forecasting skills comparable to dynamical models.




Policy Framework for Climate Data Standards
The establishment of comprehensive policy frameworks for climate data standards represents a critical foundation for advancing data augmentation techniques in climate change modeling. Current regulatory landscapes across major economies demonstrate varying approaches to climate data governance, with the European Union's Climate Data Directive leading in standardization requirements, while the United States relies primarily on agency-specific guidelines through NOAA and EPA protocols.
International coordination mechanisms have emerged through multilateral agreements, particularly the Paris Agreement's Enhanced Transparency Framework, which mandates standardized reporting methodologies for climate data. These frameworks increasingly recognize the importance of data quality assurance and interoperability standards that directly impact the effectiveness of augmentation techniques in climate models.
Regulatory compliance requirements for climate data augmentation present both opportunities and constraints for model development. Data provenance tracking mandates ensure that augmented datasets maintain clear lineage documentation, while privacy protection regulations, particularly for socioeconomic climate impact data, require careful anonymization protocols that may limit certain augmentation approaches.
Emerging policy trends indicate growing emphasis on algorithmic transparency and bias mitigation in climate modeling applications. The proposed AI Climate Governance Act in several jurisdictions would require explicit documentation of data augmentation methodologies and their potential impacts on model predictions, particularly for policy-relevant climate assessments.
Standardization bodies including ISO/TC 211 and the World Meteorological Organization have initiated development of technical standards specifically addressing synthetic climate data generation and validation protocols. These standards aim to establish minimum quality thresholds and validation requirements for augmented climate datasets used in official climate assessments.
Cross-border data sharing agreements increasingly incorporate provisions for harmonized climate data standards, facilitating international collaboration in climate modeling while ensuring consistent quality metrics across different augmentation techniques and regional climate datasets.
International coordination mechanisms have emerged through multilateral agreements, particularly the Paris Agreement's Enhanced Transparency Framework, which mandates standardized reporting methodologies for climate data. These frameworks increasingly recognize the importance of data quality assurance and interoperability standards that directly impact the effectiveness of augmentation techniques in climate models.
Regulatory compliance requirements for climate data augmentation present both opportunities and constraints for model development. Data provenance tracking mandates ensure that augmented datasets maintain clear lineage documentation, while privacy protection regulations, particularly for socioeconomic climate impact data, require careful anonymization protocols that may limit certain augmentation approaches.
Emerging policy trends indicate growing emphasis on algorithmic transparency and bias mitigation in climate modeling applications. The proposed AI Climate Governance Act in several jurisdictions would require explicit documentation of data augmentation methodologies and their potential impacts on model predictions, particularly for policy-relevant climate assessments.
Standardization bodies including ISO/TC 211 and the World Meteorological Organization have initiated development of technical standards specifically addressing synthetic climate data generation and validation protocols. These standards aim to establish minimum quality thresholds and validation requirements for augmented climate datasets used in official climate assessments.
Cross-border data sharing agreements increasingly incorporate provisions for harmonized climate data standards, facilitating international collaboration in climate modeling while ensuring consistent quality metrics across different augmentation techniques and regional climate datasets.
Computational Infrastructure for Large-Scale Climate Data
The computational infrastructure supporting large-scale climate data processing has evolved into a critical enabler for advanced data augmentation techniques in climate modeling. Modern climate research generates petabytes of observational data from satellites, weather stations, ocean buoys, and atmospheric sensors, requiring sophisticated distributed computing architectures to handle the massive data volumes effectively.
High-performance computing clusters equipped with GPU acceleration have become the backbone of climate data processing workflows. These systems leverage parallel processing capabilities to execute complex data augmentation algorithms, including generative adversarial networks and variational autoencoders, which can synthesize realistic climate scenarios from limited observational datasets. The integration of specialized tensor processing units further enhances the computational efficiency for machine learning-based augmentation methods.
Cloud-based infrastructure platforms have revolutionized accessibility to computational resources for climate research institutions. Major providers offer specialized climate computing services with pre-configured environments optimized for atmospheric and oceanic modeling. These platforms enable seamless scaling of computational resources based on data processing demands, allowing researchers to handle seasonal variations in data volume and complexity without maintaining expensive on-premises hardware.
Data storage and management systems represent another crucial component of the computational infrastructure. Distributed file systems and object storage solutions ensure reliable access to historical climate datasets spanning decades or centuries. Advanced data compression techniques and hierarchical storage management optimize storage costs while maintaining rapid access to frequently used datasets for augmentation processes.
Network infrastructure plays a vital role in facilitating data sharing and collaborative research efforts. High-bandwidth connections enable real-time data streaming from remote sensing platforms and support federated learning approaches where multiple institutions contribute to shared climate models. Edge computing deployments at data collection sites perform preliminary processing and quality control, reducing bandwidth requirements for central processing facilities.
The emergence of specialized climate data centers has created dedicated facilities optimized for environmental research workloads. These centers incorporate energy-efficient cooling systems and renewable energy sources, aligning computational infrastructure with sustainability goals inherent in climate research missions.
High-performance computing clusters equipped with GPU acceleration have become the backbone of climate data processing workflows. These systems leverage parallel processing capabilities to execute complex data augmentation algorithms, including generative adversarial networks and variational autoencoders, which can synthesize realistic climate scenarios from limited observational datasets. The integration of specialized tensor processing units further enhances the computational efficiency for machine learning-based augmentation methods.
Cloud-based infrastructure platforms have revolutionized accessibility to computational resources for climate research institutions. Major providers offer specialized climate computing services with pre-configured environments optimized for atmospheric and oceanic modeling. These platforms enable seamless scaling of computational resources based on data processing demands, allowing researchers to handle seasonal variations in data volume and complexity without maintaining expensive on-premises hardware.
Data storage and management systems represent another crucial component of the computational infrastructure. Distributed file systems and object storage solutions ensure reliable access to historical climate datasets spanning decades or centuries. Advanced data compression techniques and hierarchical storage management optimize storage costs while maintaining rapid access to frequently used datasets for augmentation processes.
Network infrastructure plays a vital role in facilitating data sharing and collaborative research efforts. High-bandwidth connections enable real-time data streaming from remote sensing platforms and support federated learning approaches where multiple institutions contribute to shared climate models. Edge computing deployments at data collection sites perform preliminary processing and quality control, reducing bandwidth requirements for central processing facilities.
The emergence of specialized climate data centers has created dedicated facilities optimized for environmental research workloads. These centers incorporate energy-efficient cooling systems and renewable energy sources, aligning computational infrastructure with sustainability goals inherent in climate research missions.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!