

How to Minimize Bandwidth Usage in Remote Neural Rendering
MAR 30, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Neural Rendering Bandwidth Optimization Background and Goals
Neural rendering represents a paradigm shift in computer graphics, leveraging deep learning techniques to synthesize photorealistic images from 3D scene representations. This technology has evolved from traditional rasterization and ray tracing methods, incorporating neural networks to achieve unprecedented visual quality in real-time applications. The emergence of Neural Radiance Fields (NeRFs), Gaussian Splatting, and other neural representation methods has revolutionized how we approach 3D scene reconstruction and rendering.
The evolution of neural rendering has been marked by significant milestones, beginning with early neural texture synthesis in the 2010s, progressing through the development of generative adversarial networks for image synthesis, and culminating in the breakthrough NeRF paper in 2020. Subsequent developments have focused on improving rendering speed, quality, and memory efficiency, with techniques like Instant NGP, Plenoxels, and 3D Gaussian Splatting pushing the boundaries of real-time performance.
Remote neural rendering applications span diverse domains including cloud gaming, virtual reality, augmented reality, digital twins, and telepresence systems. These applications demand high-quality visual output while operating under strict bandwidth constraints, particularly in mobile and edge computing scenarios. The challenge intensifies when considering multi-user environments, real-time collaboration platforms, and streaming services where bandwidth efficiency directly impacts user experience and operational costs.
Current bandwidth limitations in remote neural rendering stem from the substantial data requirements of neural scene representations. Traditional approaches often require transmitting dense volumetric data, high-resolution textures, or frequent model updates, resulting in prohibitive bandwidth consumption. This creates a fundamental tension between visual fidelity and network efficiency, particularly problematic for applications targeting consumer markets with limited internet infrastructure.
The primary technical objectives for bandwidth optimization in neural rendering include developing compact scene representations that maintain visual quality, implementing efficient compression algorithms tailored to neural data structures, and creating adaptive streaming protocols that dynamically adjust quality based on network conditions. Additionally, the goal encompasses minimizing latency while maximizing throughput, ensuring seamless user experiences across varying network environments.
Strategic goals extend beyond pure technical optimization to encompass broader market accessibility and scalability. By reducing bandwidth requirements, neural rendering applications can reach underserved markets with limited internet infrastructure, enable deployment on mobile networks, and support large-scale concurrent users. This optimization directly impacts the commercial viability of neural rendering services, influencing pricing models, infrastructure costs, and competitive positioning in emerging markets such as metaverse platforms and cloud-based creative tools.
The evolution of neural rendering has been marked by significant milestones, beginning with early neural texture synthesis in the 2010s, progressing through the development of generative adversarial networks for image synthesis, and culminating in the breakthrough NeRF paper in 2020. Subsequent developments have focused on improving rendering speed, quality, and memory efficiency, with techniques like Instant NGP, Plenoxels, and 3D Gaussian Splatting pushing the boundaries of real-time performance.
Remote neural rendering applications span diverse domains including cloud gaming, virtual reality, augmented reality, digital twins, and telepresence systems. These applications demand high-quality visual output while operating under strict bandwidth constraints, particularly in mobile and edge computing scenarios. The challenge intensifies when considering multi-user environments, real-time collaboration platforms, and streaming services where bandwidth efficiency directly impacts user experience and operational costs.
Current bandwidth limitations in remote neural rendering stem from the substantial data requirements of neural scene representations. Traditional approaches often require transmitting dense volumetric data, high-resolution textures, or frequent model updates, resulting in prohibitive bandwidth consumption. This creates a fundamental tension between visual fidelity and network efficiency, particularly problematic for applications targeting consumer markets with limited internet infrastructure.
The primary technical objectives for bandwidth optimization in neural rendering include developing compact scene representations that maintain visual quality, implementing efficient compression algorithms tailored to neural data structures, and creating adaptive streaming protocols that dynamically adjust quality based on network conditions. Additionally, the goal encompasses minimizing latency while maximizing throughput, ensuring seamless user experiences across varying network environments.
Strategic goals extend beyond pure technical optimization to encompass broader market accessibility and scalability. By reducing bandwidth requirements, neural rendering applications can reach underserved markets with limited internet infrastructure, enable deployment on mobile networks, and support large-scale concurrent users. This optimization directly impacts the commercial viability of neural rendering services, influencing pricing models, infrastructure costs, and competitive positioning in emerging markets such as metaverse platforms and cloud-based creative tools.
Market Demand for Efficient Remote Neural Rendering
The market demand for efficient remote neural rendering is experiencing unprecedented growth driven by the convergence of several technological and societal trends. The proliferation of extended reality applications, including virtual reality, augmented reality, and mixed reality experiences, has created an urgent need for high-quality rendering capabilities that can be delivered remotely without overwhelming network infrastructure. Enterprise adoption of metaverse platforms and virtual collaboration tools has further amplified this demand, as organizations seek to provide immersive experiences while maintaining cost-effective infrastructure.
Cloud gaming represents one of the most significant market drivers, with major technology companies investing heavily in streaming platforms that require real-time neural rendering capabilities. The bandwidth constraints inherent in current network infrastructure create a substantial bottleneck, making efficient rendering solutions critical for market viability. Service providers are actively seeking technologies that can deliver photorealistic graphics while minimizing data transmission requirements.
The automotive industry presents another substantial market opportunity, particularly in the development of autonomous vehicles and advanced driver assistance systems. These applications require real-time processing of complex visual data, often transmitted between vehicles and cloud-based processing centers. The bandwidth limitations of cellular networks make efficient neural rendering essential for safety-critical applications.
Healthcare and medical training applications are driving demand for remote neural rendering solutions that can deliver high-fidelity anatomical visualizations and surgical simulations. Medical institutions require systems that can provide detailed visual information while operating within the bandwidth constraints of hospital networks and telemedicine infrastructure.
The education sector is increasingly adopting immersive learning platforms that rely on remote rendering capabilities. Educational institutions need solutions that can deliver engaging visual content to students across diverse network conditions, from high-speed campus connections to limited home broadband services.
Manufacturing and industrial design sectors are embracing remote collaboration tools that enable distributed teams to work with complex three-dimensional models and simulations. These applications require efficient rendering solutions that can maintain visual fidelity while accommodating the bandwidth limitations of industrial networks and remote work environments.
The growing emphasis on edge computing and distributed processing architectures is creating new market opportunities for bandwidth-efficient neural rendering technologies. Organizations are seeking solutions that can optimize the balance between local processing capabilities and remote rendering services, minimizing bandwidth usage while maximizing performance and user experience quality.
Cloud gaming represents one of the most significant market drivers, with major technology companies investing heavily in streaming platforms that require real-time neural rendering capabilities. The bandwidth constraints inherent in current network infrastructure create a substantial bottleneck, making efficient rendering solutions critical for market viability. Service providers are actively seeking technologies that can deliver photorealistic graphics while minimizing data transmission requirements.
The automotive industry presents another substantial market opportunity, particularly in the development of autonomous vehicles and advanced driver assistance systems. These applications require real-time processing of complex visual data, often transmitted between vehicles and cloud-based processing centers. The bandwidth limitations of cellular networks make efficient neural rendering essential for safety-critical applications.
Healthcare and medical training applications are driving demand for remote neural rendering solutions that can deliver high-fidelity anatomical visualizations and surgical simulations. Medical institutions require systems that can provide detailed visual information while operating within the bandwidth constraints of hospital networks and telemedicine infrastructure.
The education sector is increasingly adopting immersive learning platforms that rely on remote rendering capabilities. Educational institutions need solutions that can deliver engaging visual content to students across diverse network conditions, from high-speed campus connections to limited home broadband services.
Manufacturing and industrial design sectors are embracing remote collaboration tools that enable distributed teams to work with complex three-dimensional models and simulations. These applications require efficient rendering solutions that can maintain visual fidelity while accommodating the bandwidth limitations of industrial networks and remote work environments.
The growing emphasis on edge computing and distributed processing architectures is creating new market opportunities for bandwidth-efficient neural rendering technologies. Organizations are seeking solutions that can optimize the balance between local processing capabilities and remote rendering services, minimizing bandwidth usage while maximizing performance and user experience quality.
Current Bandwidth Limitations in Remote Neural Rendering
Remote neural rendering systems face significant bandwidth constraints that fundamentally limit their practical deployment and performance scalability. Current implementations typically require transmitting substantial amounts of data between client devices and remote servers, creating bottlenecks that directly impact user experience and system viability.
The primary bandwidth challenge stems from the need to transmit high-resolution neural network parameters, intermediate feature maps, and rendering outputs across network connections. Modern neural rendering models often contain millions of parameters, with state-of-the-art NeRF implementations requiring hundreds of megabytes for model weights alone. When combined with the continuous data exchange needed for real-time rendering, bandwidth requirements can easily exceed 100 Mbps for high-quality applications.
Network latency compounds these bandwidth limitations, particularly in mobile and edge computing scenarios. Even with sufficient theoretical bandwidth, the round-trip time for data transmission introduces delays that make interactive applications impractical. Current systems struggle to maintain acceptable frame rates when network latency exceeds 50 milliseconds, severely limiting deployment in geographically distributed environments.
Existing compression techniques provide only partial solutions to these bandwidth constraints. Traditional video compression algorithms are poorly suited for neural rendering data, as they cannot effectively compress the unique data structures and parameter distributions inherent in neural networks. Lossy compression methods often degrade rendering quality significantly, while lossless approaches fail to achieve sufficient compression ratios for practical bandwidth reduction.
The heterogeneous nature of client devices further exacerbates bandwidth limitations. Mobile devices with limited processing capabilities require more server-side computation and data transmission, while high-end systems could potentially handle local processing but lack optimized distribution mechanisms. This creates a complex optimization problem where bandwidth usage must be balanced against computational load distribution.
Current research indicates that bandwidth requirements scale poorly with rendering quality and scene complexity. High-resolution outputs and complex 3D scenes can increase bandwidth demands by orders of magnitude, making current approaches unsuitable for demanding applications such as virtual reality or professional visualization tools.
The primary bandwidth challenge stems from the need to transmit high-resolution neural network parameters, intermediate feature maps, and rendering outputs across network connections. Modern neural rendering models often contain millions of parameters, with state-of-the-art NeRF implementations requiring hundreds of megabytes for model weights alone. When combined with the continuous data exchange needed for real-time rendering, bandwidth requirements can easily exceed 100 Mbps for high-quality applications.
Network latency compounds these bandwidth limitations, particularly in mobile and edge computing scenarios. Even with sufficient theoretical bandwidth, the round-trip time for data transmission introduces delays that make interactive applications impractical. Current systems struggle to maintain acceptable frame rates when network latency exceeds 50 milliseconds, severely limiting deployment in geographically distributed environments.
Existing compression techniques provide only partial solutions to these bandwidth constraints. Traditional video compression algorithms are poorly suited for neural rendering data, as they cannot effectively compress the unique data structures and parameter distributions inherent in neural networks. Lossy compression methods often degrade rendering quality significantly, while lossless approaches fail to achieve sufficient compression ratios for practical bandwidth reduction.
The heterogeneous nature of client devices further exacerbates bandwidth limitations. Mobile devices with limited processing capabilities require more server-side computation and data transmission, while high-end systems could potentially handle local processing but lack optimized distribution mechanisms. This creates a complex optimization problem where bandwidth usage must be balanced against computational load distribution.
Current research indicates that bandwidth requirements scale poorly with rendering quality and scene complexity. High-resolution outputs and complex 3D scenes can increase bandwidth demands by orders of magnitude, making current approaches unsuitable for demanding applications such as virtual reality or professional visualization tools.
Existing Bandwidth Reduction Solutions for Neural Rendering
01 Adaptive bitrate control and compression techniques for neural rendering
Methods for dynamically adjusting compression levels and bitrate allocation based on network conditions and rendering complexity. These techniques optimize bandwidth usage by selectively compressing neural network outputs, feature maps, or intermediate representations while maintaining visual quality. Adaptive algorithms monitor available bandwidth and adjust encoding parameters in real-time to prevent congestion and ensure smooth rendering performance.- Compression techniques for neural rendering data transmission: Various compression methods can be applied to reduce the bandwidth requirements for transmitting neural rendering data between remote servers and client devices. These techniques include lossy and lossless compression algorithms specifically designed for neural network parameters, feature maps, and rendered output. By compressing the data before transmission, the amount of bandwidth consumed can be significantly reduced while maintaining acceptable visual quality.
- Adaptive quality adjustment based on network conditions: Systems can dynamically adjust the quality and resolution of remotely rendered content based on available bandwidth and network conditions. This approach monitors real-time network performance metrics and automatically scales rendering parameters to optimize the balance between visual fidelity and data transmission requirements. The adaptive mechanism ensures smooth streaming experience even under varying network conditions.
- Predictive rendering and caching strategies: Predictive algorithms can anticipate user interactions and pre-render likely scenes or viewpoints, storing them in local cache to reduce real-time bandwidth demands. This approach combines machine learning models with user behavior analysis to predict future rendering needs. By intelligently caching predicted content, the system minimizes the amount of data that needs to be transmitted during actual user interactions.
- Distributed rendering architecture with edge computing: Implementing distributed rendering systems that leverage edge computing nodes closer to end users can significantly reduce bandwidth usage and latency. This architecture distributes the neural rendering workload across multiple geographic locations, allowing partial rendering to occur at edge servers. The approach minimizes the distance data must travel and reduces the load on central servers.
- Selective transmission of neural network layers: Rather than transmitting complete neural rendering outputs, systems can selectively transmit only essential neural network layers or intermediate representations that require less bandwidth. The client device can then perform final rendering steps locally using lightweight neural networks. This hybrid approach balances computational load between server and client while optimizing bandwidth consumption.
02 Distributed rendering architecture with client-server processing division
Systems that partition neural rendering workloads between remote servers and local client devices to minimize data transmission requirements. The architecture determines which rendering stages execute remotely versus locally based on computational capabilities and network bandwidth. By strategically distributing processing tasks, these systems reduce the amount of data that must be transmitted over the network while leveraging server-side computational resources for complex neural network operations.Expand Specific Solutions03 Predictive caching and prefetching of neural rendering data
Techniques for anticipating future rendering requirements and preloading relevant neural network parameters, textures, or scene data to reduce real-time bandwidth demands. These methods use prediction algorithms to identify likely user interactions or viewpoint changes and proactively transfer necessary data during periods of lower network utilization. By caching frequently accessed rendering assets locally, the system minimizes redundant data transmission and improves responsiveness.Expand Specific Solutions04 Level-of-detail and progressive transmission for neural representations
Methods for transmitting neural rendering data in multiple resolution levels or progressive refinement stages to optimize bandwidth usage. Initial low-resolution or coarse representations are transmitted first to provide immediate visual feedback, followed by progressive enhancement with additional detail as bandwidth permits. These approaches allow users to interact with rendered content quickly while higher-quality data continues to stream in the background.Expand Specific Solutions05 Bandwidth-aware neural network architecture optimization
Techniques for designing or adapting neural rendering networks specifically to minimize data transmission requirements while maintaining rendering quality. These methods include network pruning, quantization, and architecture search strategies that prioritize compact representations and efficient encoding of neural network parameters. The optimized networks reduce the volume of data that must be transmitted between remote servers and client devices without significantly compromising visual fidelity.Expand Specific Solutions
Key Players in Neural Rendering and Edge Computing
The remote neural rendering field is experiencing rapid growth as an emerging technology sector, driven by increasing demand for real-time 3D graphics and immersive experiences across gaming, AR/VR, and digital content creation. The market shows significant expansion potential, particularly in cloud-based rendering services and edge computing applications. Technology maturity varies considerably among key players: established tech giants like Microsoft, Adobe, and Huawei demonstrate advanced capabilities in cloud infrastructure and graphics processing, while specialized companies such as Didimo and Shenzhen Rayvision focus on niche rendering solutions. Academic institutions including Fudan University, Xidian University, and Beihang University contribute foundational research in neural networks and bandwidth optimization. Chinese companies like Tencent, Baidu USA, and China Mobile are actively developing telecommunications infrastructure to support low-latency rendering applications, indicating strong regional competition and investment in this transformative technology space.
Baidu USA LLC
Technical Solution: Baidu has developed neural rendering solutions with emphasis on autonomous driving and AR applications, incorporating sophisticated bandwidth optimization techniques. Their approach utilizes hierarchical neural representations that transmit coarse scene geometry first, followed by progressive detail refinement based on bandwidth availability[13]. Baidu implements semantic compression where neural networks identify and prioritize important scene elements, achieving up to 65% bandwidth reduction in typical autonomous driving scenarios[14]. Their PaddlePaddle framework includes specialized modules for distributed neural rendering that can dynamically partition computation between edge devices and cloud servers. The company's Apollo platform demonstrates real-world application of bandwidth-efficient neural rendering for vehicle-to-cloud communication[15].
Strengths: Strong AI research foundation, real-world autonomous driving deployment experience, comprehensive deep learning framework. Weaknesses: Limited global market presence, primarily focused on Chinese market applications.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed a comprehensive neural rendering solution focusing on 5G-enabled remote rendering with bandwidth optimization. Their approach utilizes edge computing nodes to perform partial neural network inference, reducing data transmission by processing intermediate representations locally[4]. The company implements adaptive bitrate streaming combined with AI-driven compression algorithms that can achieve up to 70% bandwidth reduction while maintaining visual quality[5]. Huawei's solution includes motion prediction algorithms and foveated rendering techniques that prioritize high-quality rendering only in areas of user attention. Their HiSilicon chips are specifically optimized for neural rendering workloads with dedicated NPU units[6].
Strengths: Strong 5G infrastructure integration, dedicated hardware optimization, comprehensive edge computing capabilities. Weaknesses: Limited global market access, dependency on proprietary hardware ecosystem.
Core Compression Innovations in Remote Neural Rendering
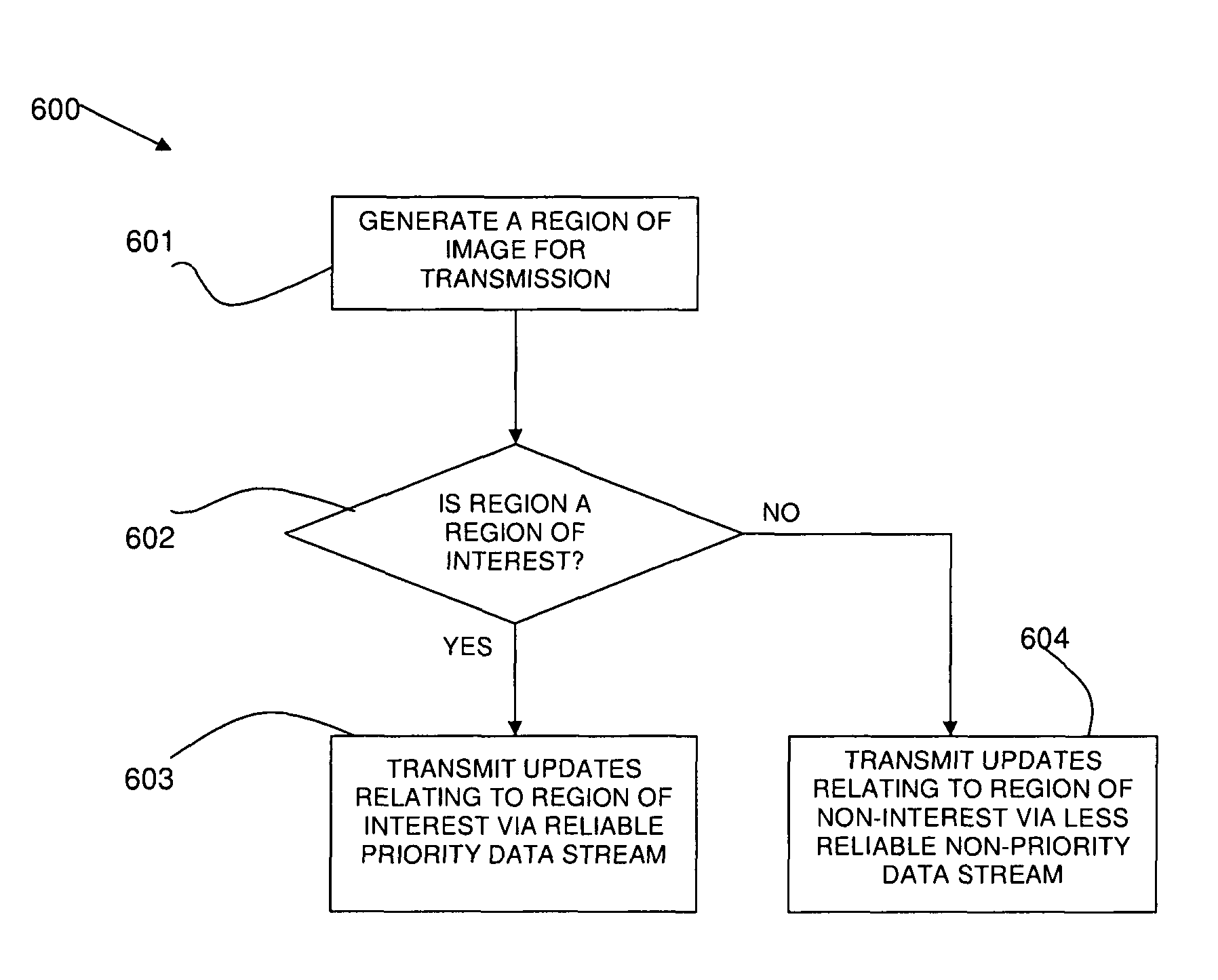
Method and system for optimizing bandwidth usage in remote visualization
PatentActiveUS8606952B2
Innovation
- The method involves determining regions of interest and non-interest in an image and sending high-quality data for regions of interest via a reliable transport protocol while sending lower-quality data for regions of non-interest via a less reliable protocol, optimizing bandwidth usage by prioritizing data transmission.
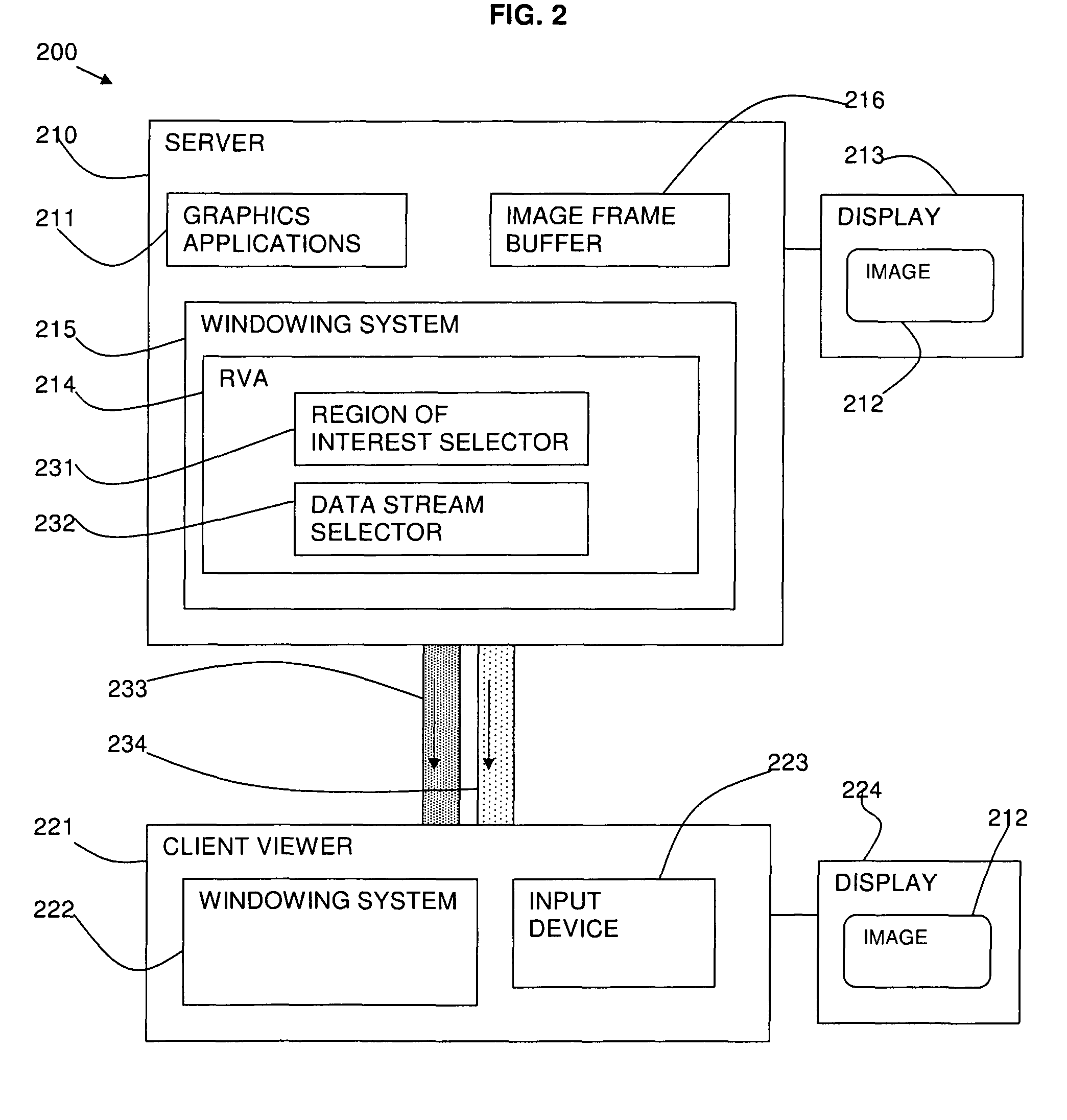

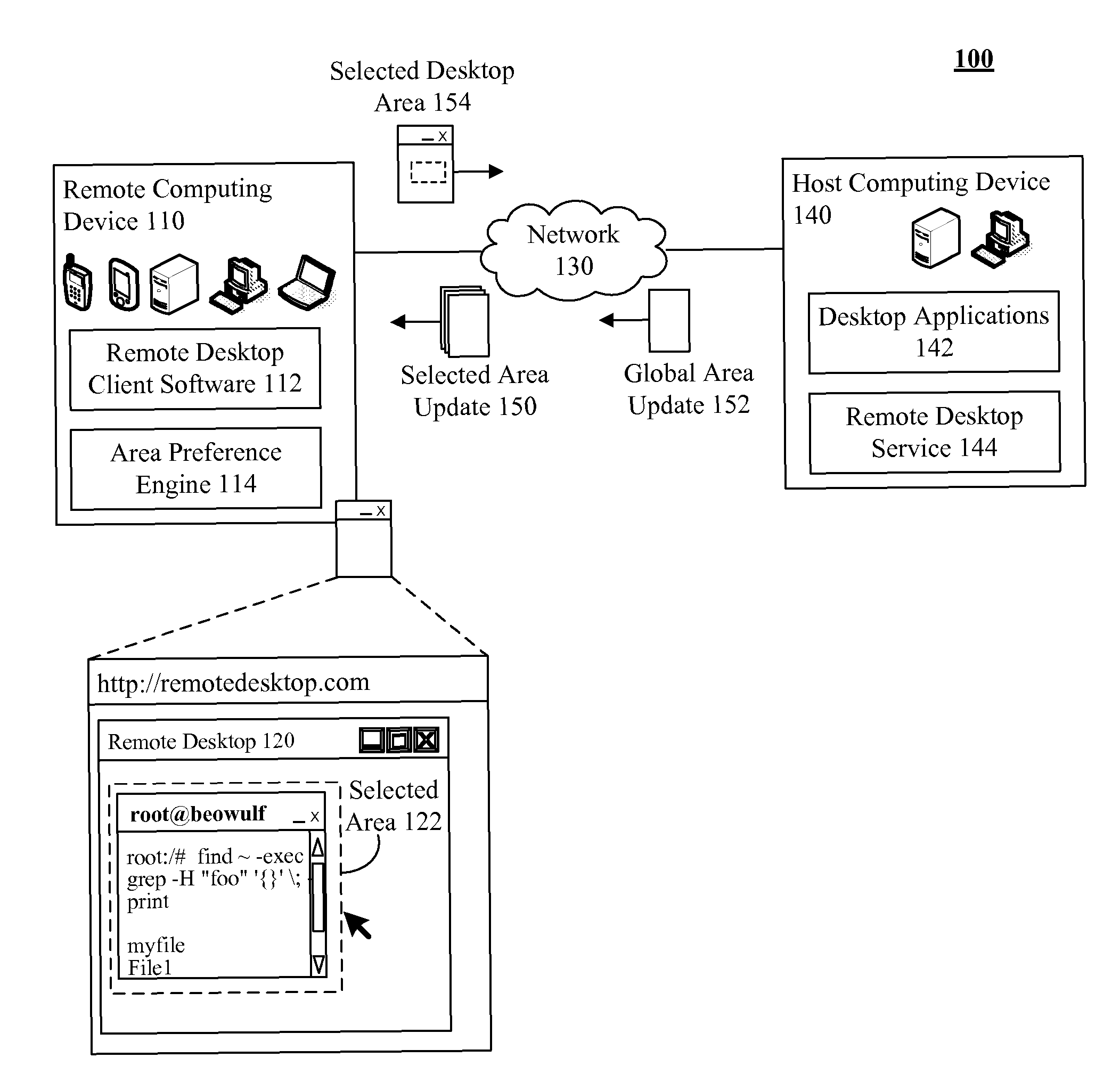
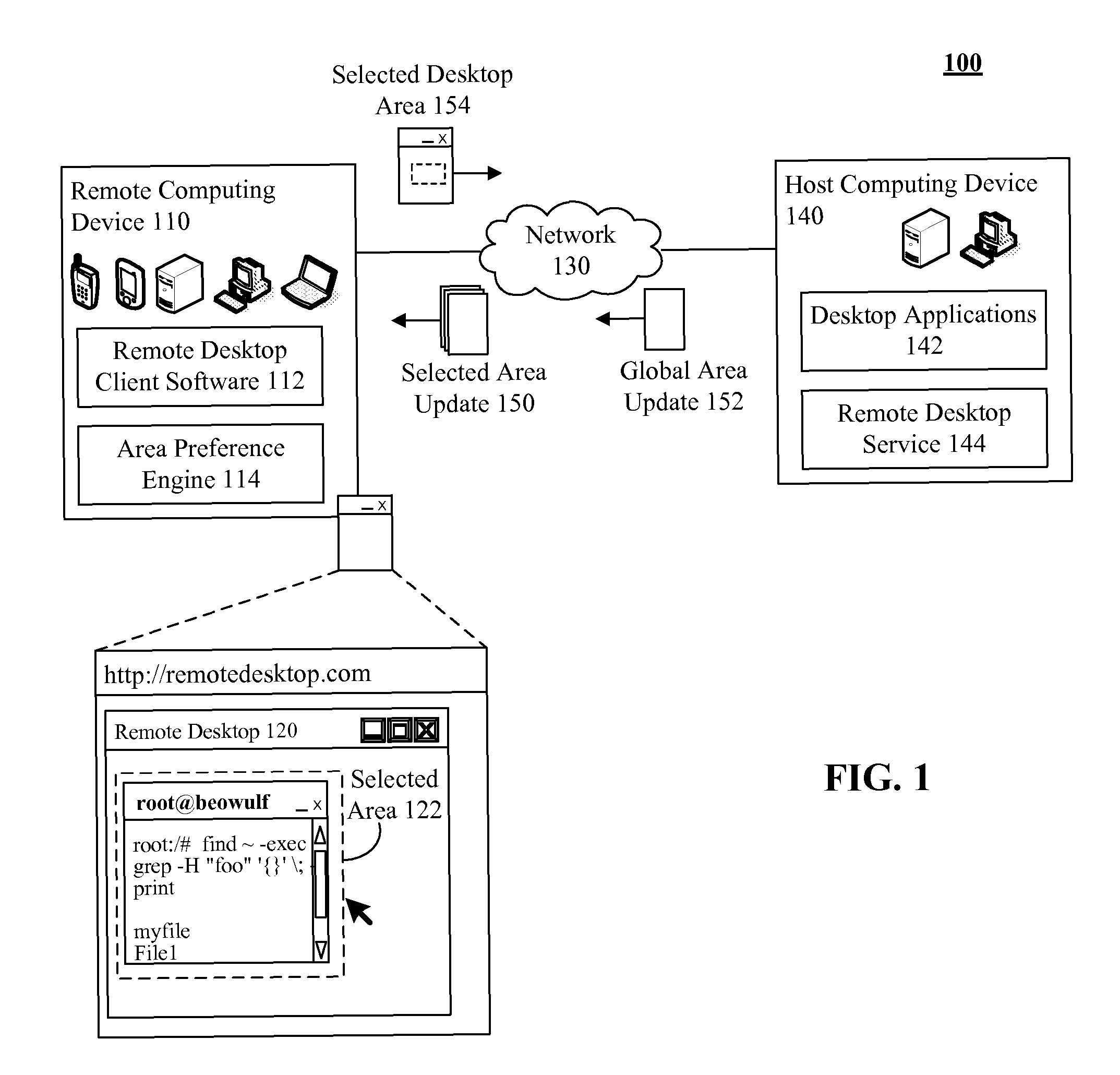
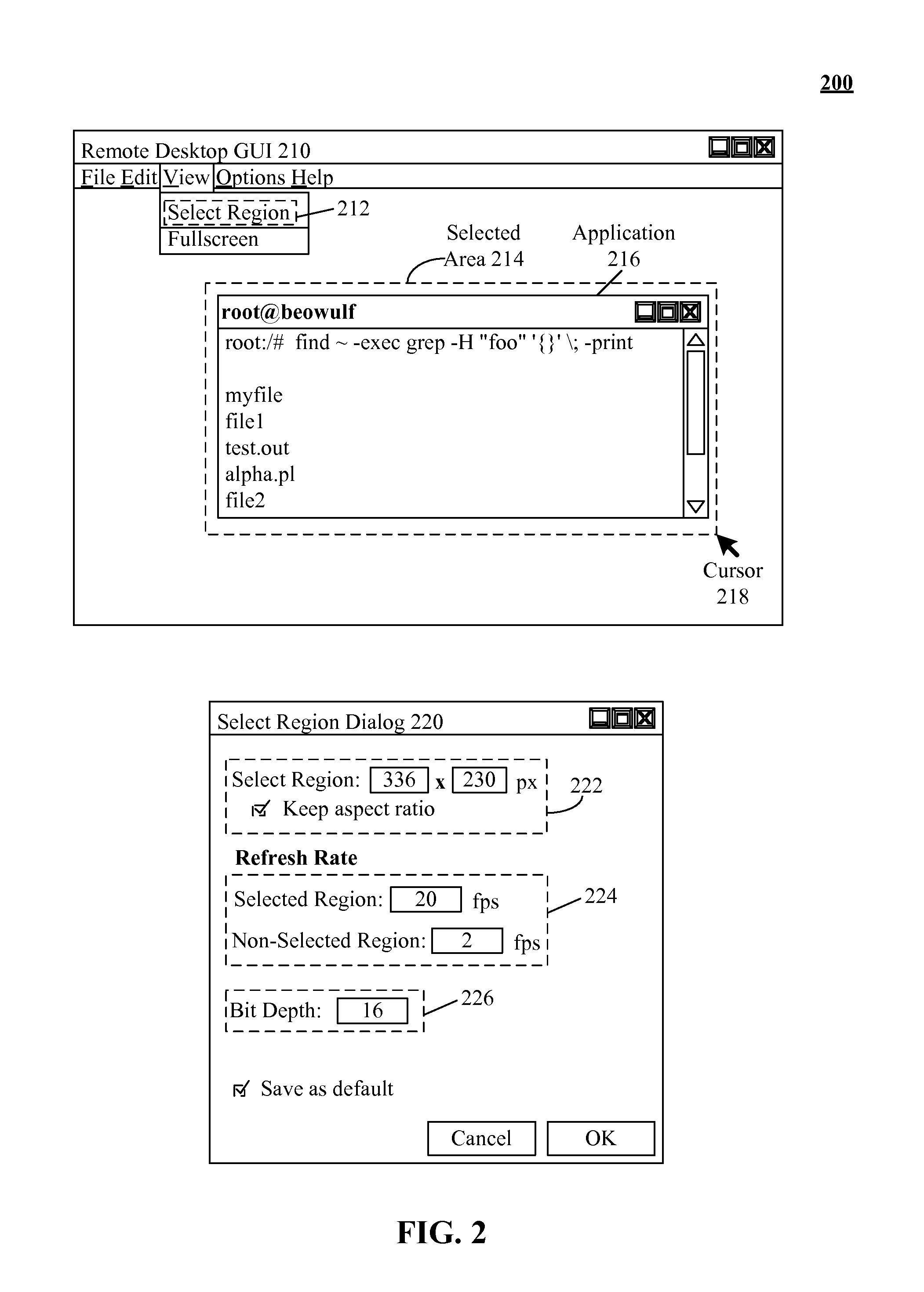
Bandwidth usage and latency reduction of remote desktop software based on preferred rendering of a user selected area
PatentActiveUS7895521B2
Innovation
- Implementing a preferred rendering region within remote desktop software, where users can select and configure specific areas for higher priority updates, differing in resolution, color depth, frame rate, and update frequency compared to non-selected regions, to optimize data transfer and reduce latency.

Network Infrastructure Requirements for Neural Rendering
Remote neural rendering demands robust network infrastructure capable of handling intensive computational workloads and real-time data transmission. The foundation requires high-bandwidth connections with minimum 10 Gbps capacity for enterprise deployments, while consumer applications typically need at least 100 Mbps for acceptable performance. Network latency becomes critical, with round-trip times ideally below 20 milliseconds to maintain responsive user experiences.
Edge computing infrastructure plays a pivotal role in neural rendering systems. Distributed edge nodes positioned strategically near end users reduce transmission distances and minimize latency bottlenecks. These nodes require substantial computational resources, including GPU clusters optimized for neural network inference, alongside high-speed interconnects to central rendering servers.
Content delivery networks must be specifically architected for neural rendering workloads. Traditional CDN approaches prove insufficient due to the dynamic nature of neural-generated content. Specialized CDN solutions incorporate intelligent caching mechanisms that can store intermediate neural network states and frequently accessed rendering parameters, reducing redundant computations across the network.
Network redundancy and failover mechanisms ensure service continuity during infrastructure disruptions. Multi-path routing protocols distribute rendering tasks across available network channels, while automatic load balancing prevents bottlenecks at individual network nodes. Quality of service protocols prioritize time-sensitive rendering data over less critical background traffic.
Storage infrastructure requirements extend beyond traditional approaches, necessitating high-speed distributed storage systems capable of handling massive neural model parameters and training datasets. Network-attached storage solutions must provide consistent low-latency access to model weights and intermediate computational results across distributed rendering nodes.
Security considerations demand encrypted data transmission protocols and secure authentication mechanisms for accessing distributed rendering resources. Network segmentation isolates rendering workloads from other enterprise traffic, while intrusion detection systems monitor for potential security threats targeting valuable neural network intellectual property.
Edge computing infrastructure plays a pivotal role in neural rendering systems. Distributed edge nodes positioned strategically near end users reduce transmission distances and minimize latency bottlenecks. These nodes require substantial computational resources, including GPU clusters optimized for neural network inference, alongside high-speed interconnects to central rendering servers.
Content delivery networks must be specifically architected for neural rendering workloads. Traditional CDN approaches prove insufficient due to the dynamic nature of neural-generated content. Specialized CDN solutions incorporate intelligent caching mechanisms that can store intermediate neural network states and frequently accessed rendering parameters, reducing redundant computations across the network.
Network redundancy and failover mechanisms ensure service continuity during infrastructure disruptions. Multi-path routing protocols distribute rendering tasks across available network channels, while automatic load balancing prevents bottlenecks at individual network nodes. Quality of service protocols prioritize time-sensitive rendering data over less critical background traffic.
Storage infrastructure requirements extend beyond traditional approaches, necessitating high-speed distributed storage systems capable of handling massive neural model parameters and training datasets. Network-attached storage solutions must provide consistent low-latency access to model weights and intermediate computational results across distributed rendering nodes.
Security considerations demand encrypted data transmission protocols and secure authentication mechanisms for accessing distributed rendering resources. Network segmentation isolates rendering workloads from other enterprise traffic, while intrusion detection systems monitor for potential security threats targeting valuable neural network intellectual property.
Edge Computing Integration for Neural Rendering Systems
Edge computing integration represents a paradigm shift in neural rendering architectures, fundamentally transforming how computational workloads are distributed between centralized cloud servers and distributed edge nodes. This approach strategically positions processing capabilities closer to end users, creating a hierarchical computing framework that addresses the inherent bandwidth limitations of traditional remote neural rendering systems.
The integration leverages geographically distributed edge infrastructure to perform preliminary neural rendering computations, including feature extraction, initial neural network inference, and data preprocessing. By executing these computationally intensive operations at edge locations, the system significantly reduces the volume of raw data that must be transmitted to central rendering servers, thereby minimizing bandwidth consumption while maintaining rendering quality.
Modern edge computing frameworks for neural rendering employ intelligent workload partitioning algorithms that dynamically allocate rendering tasks based on available computational resources, network conditions, and latency requirements. These systems utilize lightweight neural network models optimized for edge hardware constraints, enabling real-time processing of rendering primitives and scene geometry at distributed nodes.
The architectural design incorporates adaptive load balancing mechanisms that monitor network congestion and computational capacity across edge nodes. When bandwidth limitations are detected, the system automatically shifts more rendering responsibilities to edge locations, reducing data transmission requirements while ensuring consistent performance. This dynamic resource allocation prevents bottlenecks and optimizes overall system efficiency.
Edge-cloud hybrid rendering pipelines implement sophisticated caching strategies that store frequently accessed neural rendering models and scene data at edge locations. This distributed caching approach eliminates redundant data transfers and enables rapid response to rendering requests without requiring constant communication with centralized servers.
The integration also enables progressive rendering techniques where edge nodes generate low-resolution or simplified renderings that are subsequently refined by cloud-based systems. This multi-tier approach ensures immediate visual feedback while higher-quality renderings are processed and delivered incrementally, optimizing both bandwidth usage and user experience in remote neural rendering applications.
The integration leverages geographically distributed edge infrastructure to perform preliminary neural rendering computations, including feature extraction, initial neural network inference, and data preprocessing. By executing these computationally intensive operations at edge locations, the system significantly reduces the volume of raw data that must be transmitted to central rendering servers, thereby minimizing bandwidth consumption while maintaining rendering quality.
Modern edge computing frameworks for neural rendering employ intelligent workload partitioning algorithms that dynamically allocate rendering tasks based on available computational resources, network conditions, and latency requirements. These systems utilize lightweight neural network models optimized for edge hardware constraints, enabling real-time processing of rendering primitives and scene geometry at distributed nodes.
The architectural design incorporates adaptive load balancing mechanisms that monitor network congestion and computational capacity across edge nodes. When bandwidth limitations are detected, the system automatically shifts more rendering responsibilities to edge locations, reducing data transmission requirements while ensuring consistent performance. This dynamic resource allocation prevents bottlenecks and optimizes overall system efficiency.
Edge-cloud hybrid rendering pipelines implement sophisticated caching strategies that store frequently accessed neural rendering models and scene data at edge locations. This distributed caching approach eliminates redundant data transfers and enables rapid response to rendering requests without requiring constant communication with centralized servers.
The integration also enables progressive rendering techniques where edge nodes generate low-resolution or simplified renderings that are subsequently refined by cloud-based systems. This multi-tier approach ensures immediate visual feedback while higher-quality renderings are processed and delivered incrementally, optimizing both bandwidth usage and user experience in remote neural rendering applications.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!