

How to Predict Network Failures in Spiking Models
APR 24, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Spiking Neural Network Failure Prediction Background and Goals
Spiking Neural Networks (SNNs) represent a third-generation neural network paradigm that mimics the temporal dynamics of biological neurons through discrete spike-based communication. Unlike traditional artificial neural networks that process continuous values, SNNs encode information in the precise timing and frequency of spikes, making them inherently more biologically plausible and energy-efficient. This temporal processing capability has positioned SNNs as promising candidates for neuromorphic computing applications, real-time signal processing, and edge computing scenarios where power consumption is critical.
The evolution of SNNs traces back to the pioneering work of Hodgkin and Huxley in the 1950s, which established the mathematical foundation for understanding neural spike generation. The field gained momentum in the 1990s with the development of practical spiking neuron models like the Integrate-and-Fire and Leaky Integrate-and-Fire models. Recent advances in neuromorphic hardware platforms such as Intel's Loihi and IBM's TrueNorth have accelerated the practical deployment of SNNs, creating new opportunities and challenges in network reliability and failure prediction.
Network failure prediction in spiking models has emerged as a critical research area driven by the increasing deployment of SNNs in safety-critical applications including autonomous vehicles, medical devices, and industrial control systems. The unique temporal dynamics and sparse activation patterns of SNNs introduce novel failure modes that differ significantly from conventional neural networks, necessitating specialized prediction methodologies.
The primary technical objective is to develop robust predictive frameworks capable of identifying potential network failures before they manifest in SNN systems. This encompasses detecting degradation in spike timing precision, synaptic weight drift, neuron membrane potential instabilities, and network synchronization failures. The goal extends to creating early warning systems that can trigger preventive measures or graceful degradation protocols.
From a practical standpoint, the research aims to establish reliability standards for neuromorphic computing systems and enable the safe deployment of SNNs in mission-critical applications. This includes developing real-time monitoring capabilities, fault-tolerant architectures, and adaptive recovery mechanisms that can maintain network functionality under various failure conditions while preserving the energy efficiency advantages that make SNNs attractive for edge computing applications.
The evolution of SNNs traces back to the pioneering work of Hodgkin and Huxley in the 1950s, which established the mathematical foundation for understanding neural spike generation. The field gained momentum in the 1990s with the development of practical spiking neuron models like the Integrate-and-Fire and Leaky Integrate-and-Fire models. Recent advances in neuromorphic hardware platforms such as Intel's Loihi and IBM's TrueNorth have accelerated the practical deployment of SNNs, creating new opportunities and challenges in network reliability and failure prediction.
Network failure prediction in spiking models has emerged as a critical research area driven by the increasing deployment of SNNs in safety-critical applications including autonomous vehicles, medical devices, and industrial control systems. The unique temporal dynamics and sparse activation patterns of SNNs introduce novel failure modes that differ significantly from conventional neural networks, necessitating specialized prediction methodologies.
The primary technical objective is to develop robust predictive frameworks capable of identifying potential network failures before they manifest in SNN systems. This encompasses detecting degradation in spike timing precision, synaptic weight drift, neuron membrane potential instabilities, and network synchronization failures. The goal extends to creating early warning systems that can trigger preventive measures or graceful degradation protocols.
From a practical standpoint, the research aims to establish reliability standards for neuromorphic computing systems and enable the safe deployment of SNNs in mission-critical applications. This includes developing real-time monitoring capabilities, fault-tolerant architectures, and adaptive recovery mechanisms that can maintain network functionality under various failure conditions while preserving the energy efficiency advantages that make SNNs attractive for edge computing applications.
Market Demand for Reliable Spiking Network Systems
The market demand for reliable spiking network systems is experiencing unprecedented growth driven by the convergence of neuromorphic computing advancements and the increasing need for energy-efficient artificial intelligence solutions. Traditional computing architectures face significant limitations in handling real-time processing tasks while maintaining low power consumption, creating substantial market opportunities for spiking neural network technologies that can address these challenges.
Healthcare and medical device sectors represent one of the most promising markets for reliable spiking network systems. Brain-computer interfaces, neural prosthetics, and real-time patient monitoring systems require robust network architectures that can process neural signals with minimal latency while ensuring system reliability. The aging global population and rising prevalence of neurological disorders are driving substantial investments in these applications, where network failure prediction capabilities are critical for patient safety and treatment efficacy.
Autonomous vehicle manufacturers constitute another major market segment demanding highly reliable spiking network systems. These systems must process sensory data in real-time while maintaining operational integrity under various environmental conditions. The automotive industry's stringent safety requirements necessitate advanced failure prediction mechanisms to prevent catastrophic system failures that could endanger human lives.
Industrial automation and robotics sectors are increasingly adopting spiking neural networks for real-time control and decision-making applications. Manufacturing environments require systems that can operate continuously with minimal downtime, making network failure prediction essential for maintaining production efficiency and preventing costly equipment damage. The growing trend toward smart manufacturing and Industry 4.0 initiatives is accelerating demand for these reliable neuromorphic solutions.
Edge computing applications across various industries are driving demand for energy-efficient spiking network systems that can operate reliably in resource-constrained environments. Internet of Things deployments, smart city infrastructure, and distributed sensor networks require robust systems capable of predicting and preventing network failures to ensure continuous operation and data integrity.
The defense and aerospace sectors present significant market opportunities for reliable spiking network systems, particularly in applications requiring real-time threat detection, autonomous navigation, and mission-critical decision-making. These applications demand the highest levels of system reliability and failure prediction capabilities to ensure operational success and personnel safety.
Healthcare and medical device sectors represent one of the most promising markets for reliable spiking network systems. Brain-computer interfaces, neural prosthetics, and real-time patient monitoring systems require robust network architectures that can process neural signals with minimal latency while ensuring system reliability. The aging global population and rising prevalence of neurological disorders are driving substantial investments in these applications, where network failure prediction capabilities are critical for patient safety and treatment efficacy.
Autonomous vehicle manufacturers constitute another major market segment demanding highly reliable spiking network systems. These systems must process sensory data in real-time while maintaining operational integrity under various environmental conditions. The automotive industry's stringent safety requirements necessitate advanced failure prediction mechanisms to prevent catastrophic system failures that could endanger human lives.
Industrial automation and robotics sectors are increasingly adopting spiking neural networks for real-time control and decision-making applications. Manufacturing environments require systems that can operate continuously with minimal downtime, making network failure prediction essential for maintaining production efficiency and preventing costly equipment damage. The growing trend toward smart manufacturing and Industry 4.0 initiatives is accelerating demand for these reliable neuromorphic solutions.
Edge computing applications across various industries are driving demand for energy-efficient spiking network systems that can operate reliably in resource-constrained environments. Internet of Things deployments, smart city infrastructure, and distributed sensor networks require robust systems capable of predicting and preventing network failures to ensure continuous operation and data integrity.
The defense and aerospace sectors present significant market opportunities for reliable spiking network systems, particularly in applications requiring real-time threat detection, autonomous navigation, and mission-critical decision-making. These applications demand the highest levels of system reliability and failure prediction capabilities to ensure operational success and personnel safety.
Current Challenges in Spiking Model Network Failure Detection
Spiking neural networks face fundamental challenges in failure detection due to their inherently stochastic and temporal nature. Unlike traditional artificial neural networks that process static inputs, spiking models operate through discrete spike events distributed across time, making it extremely difficult to distinguish between normal network dynamics and actual failure states. The temporal dependencies and complex spike patterns create ambiguity in determining whether irregular behavior represents natural network variability or genuine malfunction.
The sparse and asynchronous communication patterns in spiking networks present significant detection difficulties. Neurons fire sporadically, and the absence of spikes does not necessarily indicate failure, as silent periods are natural components of network operation. This sparsity makes it challenging to establish baseline performance metrics and identify anomalous patterns that truly represent network degradation or component failures.
Current detection methodologies struggle with the multi-scale temporal dynamics inherent in spiking models. Network failures can manifest across different timescales, from microsecond-level synaptic failures to longer-term connectivity degradation. Existing monitoring approaches often focus on single temporal resolutions, missing critical failure signatures that emerge at different time horizons or through cross-scale interactions.
The heterogeneous nature of spiking network components compounds detection complexity. Different neuron types, synaptic mechanisms, and plasticity rules create diverse failure modes that require specialized detection strategies. Traditional one-size-fits-all monitoring approaches prove inadequate when dealing with the varied behavioral signatures of different network elements and their potential failure mechanisms.
Real-time processing constraints pose additional challenges for practical failure detection systems. Spiking networks often operate under strict timing requirements, leaving limited computational resources for continuous monitoring and analysis. The need for immediate failure detection conflicts with the computational overhead required for comprehensive network state assessment and pattern recognition.
Limited ground truth data for training detection algorithms represents a critical bottleneck. Unlike software systems where failure modes are well-documented, spiking network failures are poorly characterized, making it difficult to develop robust detection models. The lack of standardized failure taxonomies and benchmark datasets hinders the development of reliable detection frameworks across different spiking network implementations and applications.
The sparse and asynchronous communication patterns in spiking networks present significant detection difficulties. Neurons fire sporadically, and the absence of spikes does not necessarily indicate failure, as silent periods are natural components of network operation. This sparsity makes it challenging to establish baseline performance metrics and identify anomalous patterns that truly represent network degradation or component failures.
Current detection methodologies struggle with the multi-scale temporal dynamics inherent in spiking models. Network failures can manifest across different timescales, from microsecond-level synaptic failures to longer-term connectivity degradation. Existing monitoring approaches often focus on single temporal resolutions, missing critical failure signatures that emerge at different time horizons or through cross-scale interactions.
The heterogeneous nature of spiking network components compounds detection complexity. Different neuron types, synaptic mechanisms, and plasticity rules create diverse failure modes that require specialized detection strategies. Traditional one-size-fits-all monitoring approaches prove inadequate when dealing with the varied behavioral signatures of different network elements and their potential failure mechanisms.
Real-time processing constraints pose additional challenges for practical failure detection systems. Spiking networks often operate under strict timing requirements, leaving limited computational resources for continuous monitoring and analysis. The need for immediate failure detection conflicts with the computational overhead required for comprehensive network state assessment and pattern recognition.
Limited ground truth data for training detection algorithms represents a critical bottleneck. Unlike software systems where failure modes are well-documented, spiking network failures are poorly characterized, making it difficult to develop robust detection models. The lack of standardized failure taxonomies and benchmark datasets hinders the development of reliable detection frameworks across different spiking network implementations and applications.
Existing Failure Prediction Solutions for Spiking Models
01 Spiking neural network architecture for fault tolerance
Implementation of specialized spiking neural network architectures designed to handle network failures through redundant pathways and adaptive routing mechanisms. These architectures incorporate neuromorphic computing principles to maintain functionality during component failures by dynamically reconfiguring spike transmission paths and utilizing backup processing units.- Spiking neural network architecture for fault tolerance: Implementation of specialized spiking neural network architectures designed to handle network failures through redundant pathways and adaptive routing mechanisms. These architectures incorporate neuromorphic computing principles to maintain functionality during component failures by dynamically reconfiguring spike transmission paths and utilizing distributed processing capabilities.
- Failure detection and prediction using spiking models: Methods for detecting and predicting network failures through spiking neural network models that analyze temporal patterns and anomalies in network behavior. These systems utilize spike-timing-dependent plasticity and event-driven processing to identify early warning signs of potential failures and trigger preventive measures before critical breakdowns occur.
- Self-healing mechanisms in spiking networks: Autonomous recovery systems that employ spiking neural networks to automatically restore network functionality after failures. These mechanisms use bio-inspired learning algorithms and adaptive synaptic weights to reroute information flow, isolate faulty components, and maintain service continuity without manual intervention.
- Distributed spike processing for network resilience: Distributed computing frameworks utilizing spiking neural networks across multiple nodes to enhance system resilience against localized failures. These approaches implement decentralized spike processing, load balancing, and redundant computation to ensure that network operations continue even when individual nodes or connections fail.
- Training and optimization of failure-resistant spiking models: Training methodologies and optimization techniques specifically designed to develop spiking neural networks with enhanced robustness against network failures. These methods incorporate failure scenarios during training, utilize reinforcement learning approaches, and implement regularization techniques to ensure models maintain performance under degraded network conditions.
02 Failure detection and prediction using spiking models
Methods for detecting and predicting network failures through spiking neural network models that monitor network behavior patterns and anomalies. These systems utilize temporal spike patterns to identify early warning signs of potential failures, enabling proactive maintenance and failure prevention through real-time analysis of network traffic and component health.Expand Specific Solutions03 Self-healing mechanisms in spiking networks
Autonomous recovery systems that employ spiking neural networks to automatically detect, isolate, and recover from network failures without human intervention. These mechanisms use spike-timing-dependent plasticity and learning algorithms to adapt network configurations in response to failures, redistributing workloads and rerouting data through alternative pathways.Expand Specific Solutions04 Resilient communication protocols for spiking networks
Communication protocols specifically designed for spiking neural networks that maintain data integrity and connectivity during partial network failures. These protocols implement error correction, packet retransmission strategies, and adaptive synchronization methods that account for the temporal dynamics of spike-based communication while ensuring reliable information transfer under degraded conditions.Expand Specific Solutions05 Hardware implementation for failure-resistant spiking systems
Physical hardware designs and neuromorphic chip architectures that provide inherent resistance to failures in spiking neural network implementations. These designs incorporate redundant circuitry, error-correcting memory systems, and distributed processing elements that continue operating even when individual components fail, ensuring system-level reliability through hardware-level fault tolerance.Expand Specific Solutions
Key Players in Spiking Neural Network Infrastructure
The network failure prediction in spiking models field represents an emerging technological domain at the intersection of neuromorphic computing and network reliability engineering. The industry is in its early developmental stage, with significant research activity concentrated in academic institutions and established technology corporations. Market size remains nascent as commercial applications are still being explored, primarily within telecommunications and power grid sectors. Technology maturity varies considerably across key players: telecommunications giants like China Mobile Communications Group and Cisco Technology possess advanced network infrastructure expertise but are adapting to spiking neural paradigms, while semiconductor leaders Samsung Electronics and Qualcomm bring neuromorphic hardware capabilities. Academic institutions including Shanghai Jiao Tong University, Beihang University, and Dalian University of Technology are driving fundamental research breakthroughs. Power sector entities such as State Grid companies are exploring practical applications for grid reliability. The competitive landscape shows a convergence of traditional networking expertise with emerging neuromorphic technologies, creating opportunities for hybrid solutions that leverage both conventional and bio-inspired approaches.
Cisco Technology, Inc.
Technical Solution: Cisco has developed advanced network failure prediction systems that integrate machine learning algorithms with real-time network monitoring. Their approach utilizes deep neural networks to analyze network traffic patterns, latency variations, and hardware performance metrics to predict potential failures before they occur. The system employs predictive analytics engines that process massive amounts of network telemetry data, enabling proactive maintenance and reducing network downtime by up to 40%. Their solution includes automated remediation capabilities and integrates with existing network management platforms to provide comprehensive failure prediction and prevention.
Strengths: Industry-leading network infrastructure expertise, comprehensive data analytics capabilities, proven scalability across enterprise networks. Weaknesses: High implementation costs, complexity in integration with non-Cisco equipment, requires extensive training for optimal utilization.
QUALCOMM, Inc.
Technical Solution: Qualcomm has developed edge AI solutions that incorporate spiking neural network models for wireless network failure prediction, particularly in 5G and IoT environments. Their technology utilizes neuromorphic processing units embedded in network infrastructure to analyze signal quality, interference patterns, and device connectivity metrics. The system processes temporal sequences of network events to predict potential failures in wireless communications, achieving prediction accuracy rates exceeding 90% while operating with minimal power consumption. Their approach focuses on distributed intelligence across network nodes to enable real-time failure prediction and automatic network optimization.
Strengths: Leading wireless technology expertise, advanced AI chip design capabilities, strong focus on energy-efficient processing. Weaknesses: Primarily focused on wireless networks rather than wired infrastructure, limited experience in enterprise network management, dependency on proprietary hardware platforms.
Core Technologies in Spiking Network Anomaly Detection
Spiking dynamical neural network for parallel prediction of multiple temporal events
PatentInactiveUS20100179935A1
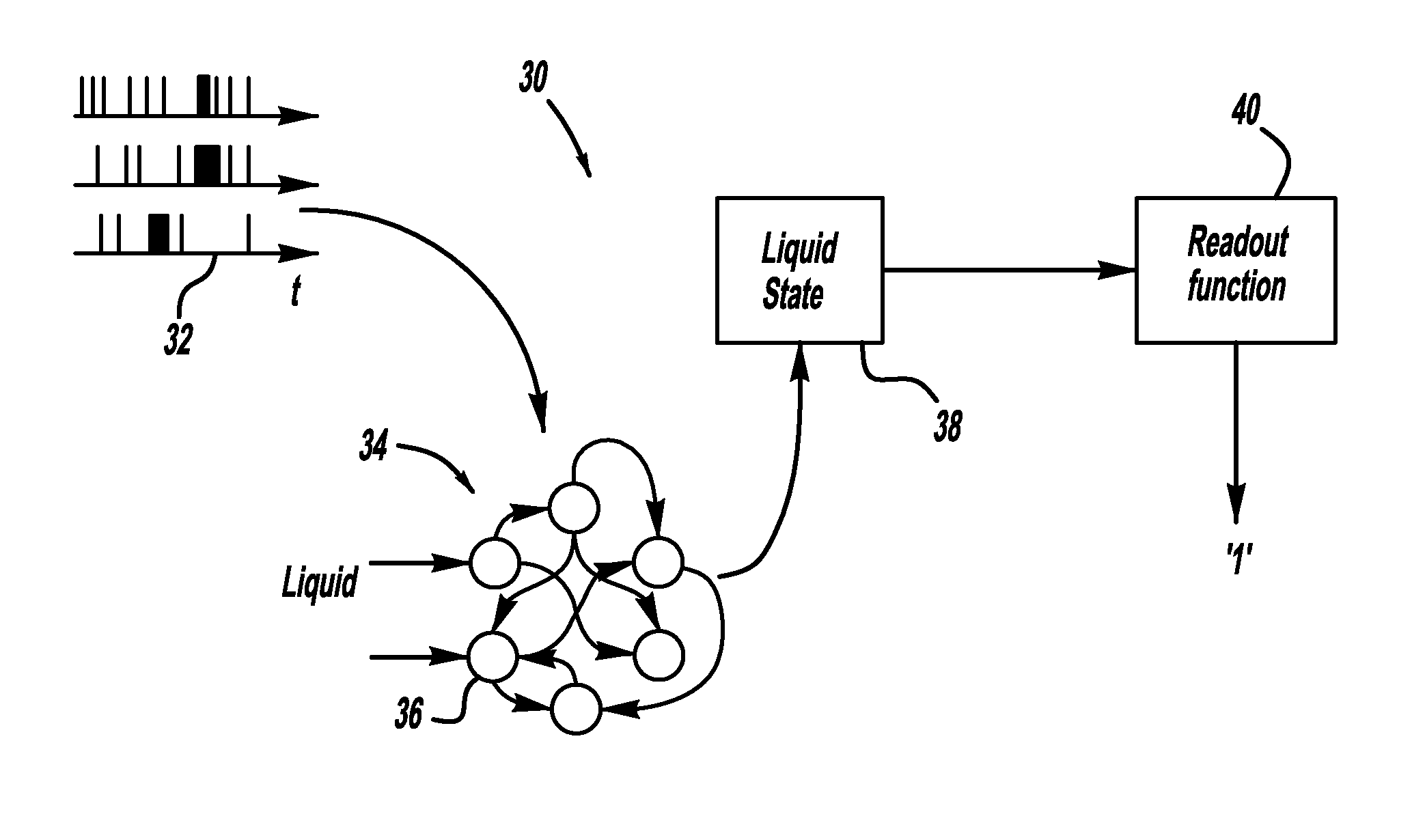
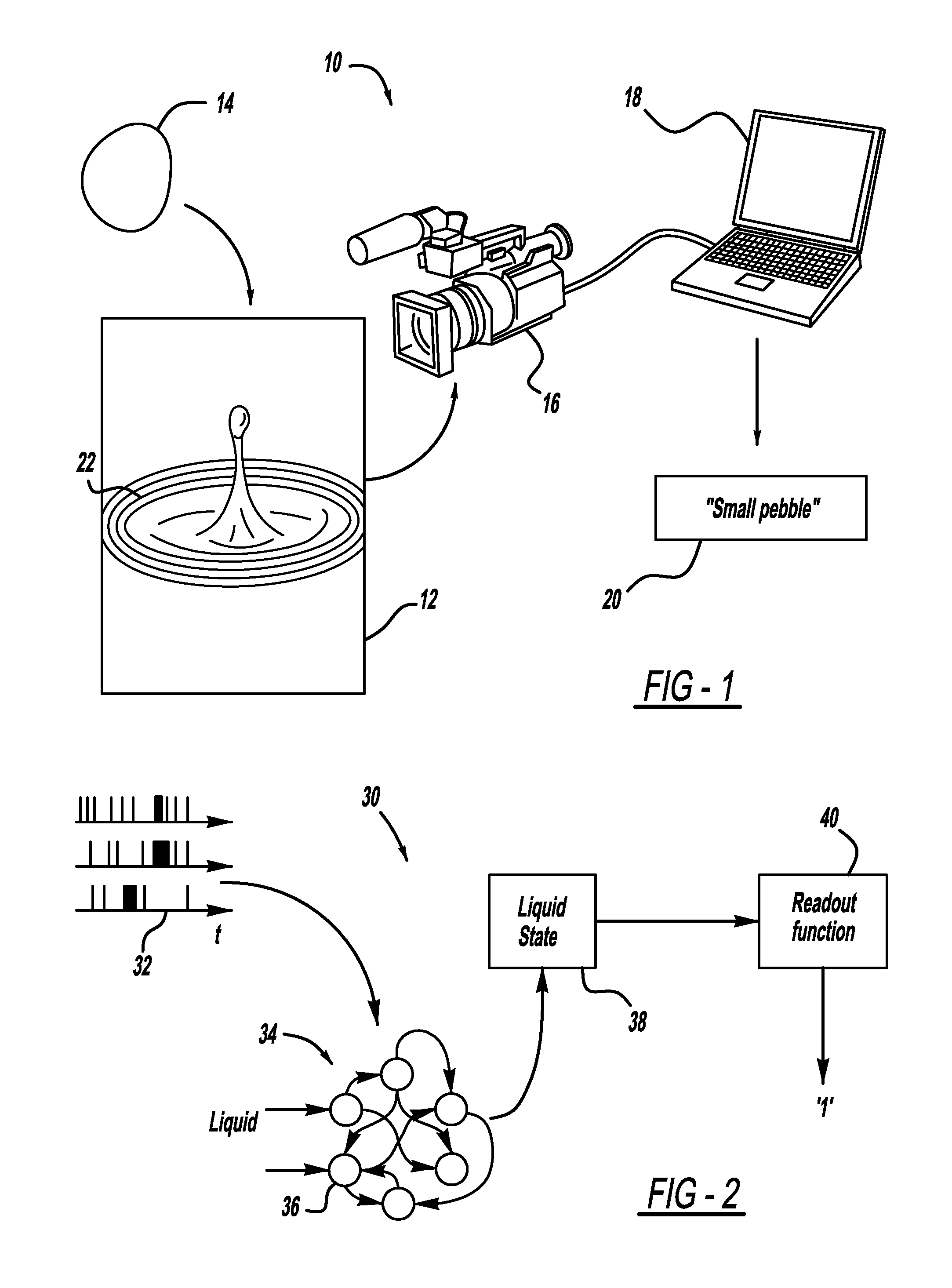
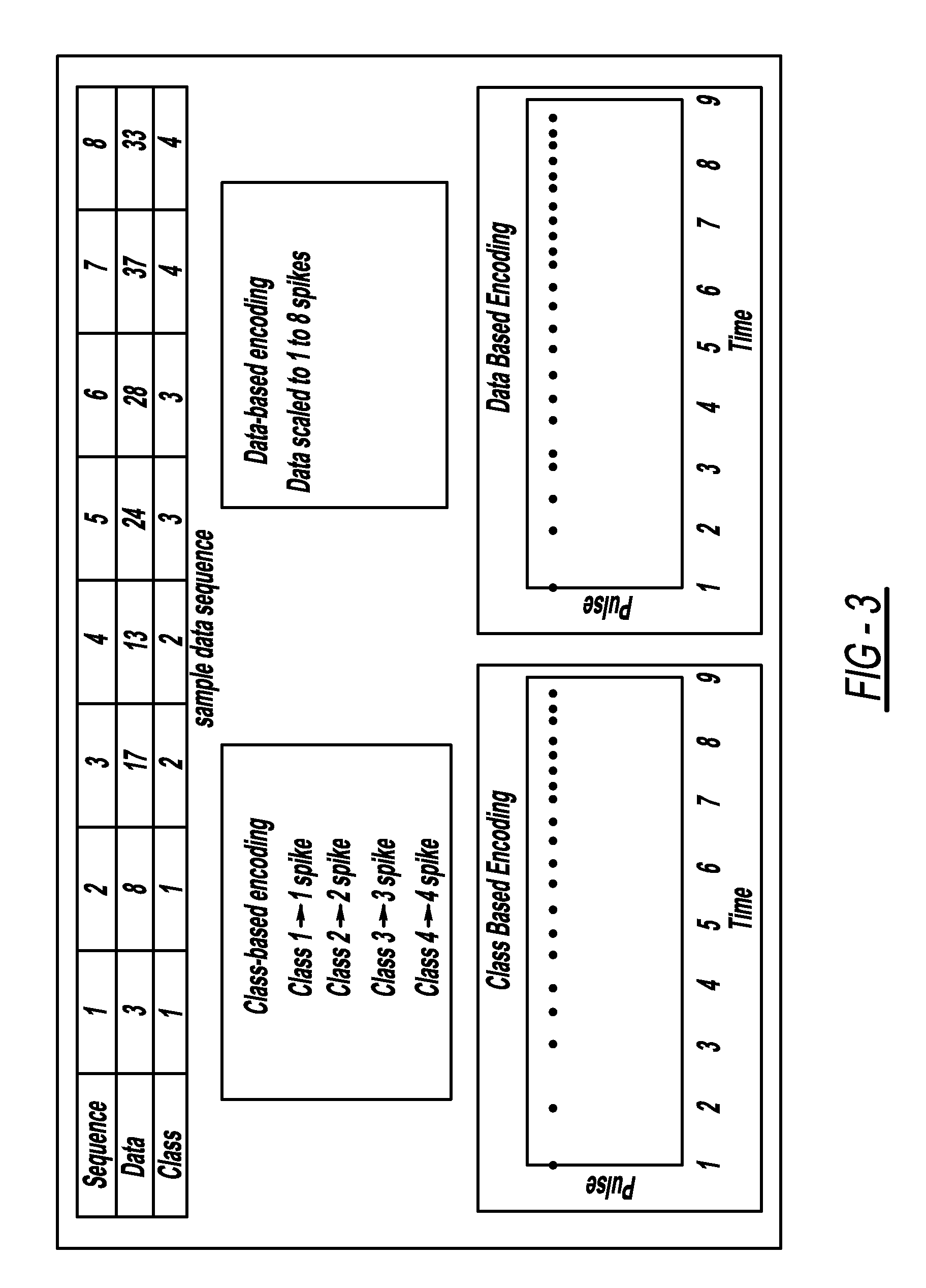
Innovation
- A system and method utilizing a dynamical neural network as a liquid state machine that processes temporal spike trains to analyze and predict multiple fault events, leveraging excitatory and inhibitory neurons for robust and efficient predictions, with semi-supervised learning and adjustable parameters to handle complex dynamics.

Method and apparatus for strategic synaptic failure and learning in spiking neural networks
PatentWO2013170036A2
Innovation
- A method and apparatus for determining synaptic failures based on characteristics such as weight, delay, and probability, allowing for probabilistic synaptic failure and adjustment of synaptic weights, which omits failed connections from post-synaptic neuron computations and adjusts weights for successful transmissions, enhancing learning and reducing computational requirements.




Safety Standards for Neural Network System Reliability
The establishment of comprehensive safety standards for neural network system reliability in spiking models represents a critical frontier in ensuring robust and dependable neuromorphic computing systems. Current safety frameworks primarily focus on traditional artificial neural networks, leaving a significant gap in addressing the unique characteristics and failure modes inherent to spiking neural networks.
Existing safety standards such as ISO 26262 for automotive systems and IEC 61508 for functional safety provide foundational principles but require substantial adaptation for spiking model architectures. The temporal dynamics, event-driven processing, and stochastic behavior of spiking neurons introduce novel reliability challenges that conventional safety metrics cannot adequately capture.
The development of specialized safety standards must address multiple reliability dimensions including temporal consistency, spike timing precision, and synaptic weight stability. These standards should establish quantitative metrics for acceptable failure rates, define testing protocols for various operational conditions, and specify validation procedures for safety-critical applications.
Key safety requirements should encompass fault detection mechanisms capable of identifying anomalous spiking patterns, redundancy strategies that leverage the distributed nature of spiking networks, and graceful degradation protocols that maintain essential functionality during partial system failures. The standards must also define acceptable bounds for network parameter drift and establish monitoring frameworks for real-time reliability assessment.
Implementation guidelines should specify design practices that enhance inherent reliability, including robust training methodologies that improve fault tolerance, architectural patterns that minimize single points of failure, and verification techniques tailored to the probabilistic nature of spiking computations. These standards must balance safety requirements with the energy efficiency and computational advantages that make spiking models attractive for edge computing applications.
The certification process should incorporate domain-specific considerations, recognizing that safety requirements for autonomous vehicles differ significantly from those for medical devices or industrial control systems. Regular updates to these standards will be essential as spiking neural network technology continues to evolve and new failure modes are discovered through practical deployment experience.
Existing safety standards such as ISO 26262 for automotive systems and IEC 61508 for functional safety provide foundational principles but require substantial adaptation for spiking model architectures. The temporal dynamics, event-driven processing, and stochastic behavior of spiking neurons introduce novel reliability challenges that conventional safety metrics cannot adequately capture.
The development of specialized safety standards must address multiple reliability dimensions including temporal consistency, spike timing precision, and synaptic weight stability. These standards should establish quantitative metrics for acceptable failure rates, define testing protocols for various operational conditions, and specify validation procedures for safety-critical applications.
Key safety requirements should encompass fault detection mechanisms capable of identifying anomalous spiking patterns, redundancy strategies that leverage the distributed nature of spiking networks, and graceful degradation protocols that maintain essential functionality during partial system failures. The standards must also define acceptable bounds for network parameter drift and establish monitoring frameworks for real-time reliability assessment.
Implementation guidelines should specify design practices that enhance inherent reliability, including robust training methodologies that improve fault tolerance, architectural patterns that minimize single points of failure, and verification techniques tailored to the probabilistic nature of spiking computations. These standards must balance safety requirements with the energy efficiency and computational advantages that make spiking models attractive for edge computing applications.
The certification process should incorporate domain-specific considerations, recognizing that safety requirements for autonomous vehicles differ significantly from those for medical devices or industrial control systems. Regular updates to these standards will be essential as spiking neural network technology continues to evolve and new failure modes are discovered through practical deployment experience.
Energy Efficiency Considerations in Spiking Network Monitoring
Energy efficiency represents a critical design consideration in spiking network monitoring systems, particularly when implementing failure prediction mechanisms. The inherent event-driven nature of spiking neural networks offers significant advantages over traditional continuous monitoring approaches, as computational resources are only activated when spikes occur rather than maintaining constant surveillance operations.
The sparse firing patterns characteristic of biological neural networks translate directly into reduced power consumption in hardware implementations. When monitoring network failures, this sparsity becomes particularly valuable as failure events typically represent anomalous patterns that deviate from normal operational baselines. By leveraging the natural efficiency of spike-based computation, monitoring systems can achieve substantial energy savings compared to conventional deep learning approaches that require continuous matrix operations.
Neuromorphic hardware platforms specifically designed for spiking networks demonstrate remarkable energy efficiency improvements. These specialized processors, such as Intel's Loihi and IBM's TrueNorth architectures, consume orders of magnitude less power than traditional GPU-based systems when processing temporal spike patterns. The asynchronous processing capabilities eliminate the need for synchronized clock cycles, further reducing energy overhead in failure prediction tasks.
Dynamic voltage and frequency scaling techniques can be integrated with spiking network monitoring to optimize energy consumption based on network activity levels. During periods of normal operation with minimal failure indicators, the system can operate at reduced power states. When spike patterns suggest potential failure conditions, computational resources can be dynamically allocated to ensure accurate prediction without compromising system responsiveness.
Edge deployment scenarios particularly benefit from energy-efficient spiking network implementations. Distributed monitoring nodes with limited power budgets can maintain continuous surveillance capabilities while extending operational lifetimes. The reduced computational complexity of spike-based processing enables real-time failure prediction on resource-constrained devices without requiring constant connectivity to centralized processing centers.
Adaptive learning mechanisms within spiking networks contribute to long-term energy efficiency by refining prediction accuracy over time. As the system learns to distinguish between normal variations and genuine failure precursors, unnecessary computational overhead from false alarms decreases, resulting in more efficient resource utilization and improved overall system sustainability.
The sparse firing patterns characteristic of biological neural networks translate directly into reduced power consumption in hardware implementations. When monitoring network failures, this sparsity becomes particularly valuable as failure events typically represent anomalous patterns that deviate from normal operational baselines. By leveraging the natural efficiency of spike-based computation, monitoring systems can achieve substantial energy savings compared to conventional deep learning approaches that require continuous matrix operations.
Neuromorphic hardware platforms specifically designed for spiking networks demonstrate remarkable energy efficiency improvements. These specialized processors, such as Intel's Loihi and IBM's TrueNorth architectures, consume orders of magnitude less power than traditional GPU-based systems when processing temporal spike patterns. The asynchronous processing capabilities eliminate the need for synchronized clock cycles, further reducing energy overhead in failure prediction tasks.
Dynamic voltage and frequency scaling techniques can be integrated with spiking network monitoring to optimize energy consumption based on network activity levels. During periods of normal operation with minimal failure indicators, the system can operate at reduced power states. When spike patterns suggest potential failure conditions, computational resources can be dynamically allocated to ensure accurate prediction without compromising system responsiveness.
Edge deployment scenarios particularly benefit from energy-efficient spiking network implementations. Distributed monitoring nodes with limited power budgets can maintain continuous surveillance capabilities while extending operational lifetimes. The reduced computational complexity of spike-based processing enables real-time failure prediction on resource-constrained devices without requiring constant connectivity to centralized processing centers.
Adaptive learning mechanisms within spiking networks contribute to long-term energy efficiency by refining prediction accuracy over time. As the system learns to distinguish between normal variations and genuine failure precursors, unnecessary computational overhead from false alarms decreases, resulting in more efficient resource utilization and improved overall system sustainability.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!