Improve Data Parallelism with Near-Memory Solutions
APR 24, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Near-Memory Computing Background and Objectives
Near-memory computing represents a paradigm shift in computer architecture that addresses the growing disparity between processor performance and memory bandwidth, commonly known as the "memory wall" problem. This architectural approach emerged from the recognition that traditional von Neumann architectures, where processing units and memory are physically separated, create significant bottlenecks in data-intensive applications. The concept gained momentum in the early 2000s as semiconductor scaling continued while memory latency improvements stagnated, leading to increasingly inefficient data movement patterns.
The evolution of near-memory computing has been driven by several technological convergences. The advent of 3D memory technologies, such as High Bandwidth Memory (HBM) and 3D NAND, provided the physical foundation for integrating processing elements closer to storage. Simultaneously, the emergence of specialized workloads in artificial intelligence, big data analytics, and scientific computing created unprecedented demands for memory bandwidth that traditional architectures could not satisfy efficiently.
The primary objective of near-memory computing solutions is to minimize data movement by bringing computation closer to where data resides. This approach fundamentally challenges the conventional separation between processing and storage, instead advocating for a more integrated architecture where simple processing elements are embedded within or adjacent to memory arrays. By reducing the physical distance data must travel, these solutions aim to achieve significant improvements in both performance and energy efficiency.
Key technical goals include maximizing memory bandwidth utilization, reducing energy consumption associated with data transfers, and enabling new forms of parallelism that were previously impractical. The technology seeks to transform memory from a passive storage medium into an active participant in computation, capable of performing operations on data in-situ rather than requiring data to be moved to distant processing units.
Contemporary near-memory computing initiatives focus on developing hybrid architectures that maintain compatibility with existing software ecosystems while introducing new computational capabilities at the memory level. These solutions target applications with high memory bandwidth requirements, irregular access patterns, and opportunities for fine-grained parallelism, positioning near-memory computing as a critical enabler for next-generation data-intensive computing systems.
The evolution of near-memory computing has been driven by several technological convergences. The advent of 3D memory technologies, such as High Bandwidth Memory (HBM) and 3D NAND, provided the physical foundation for integrating processing elements closer to storage. Simultaneously, the emergence of specialized workloads in artificial intelligence, big data analytics, and scientific computing created unprecedented demands for memory bandwidth that traditional architectures could not satisfy efficiently.
The primary objective of near-memory computing solutions is to minimize data movement by bringing computation closer to where data resides. This approach fundamentally challenges the conventional separation between processing and storage, instead advocating for a more integrated architecture where simple processing elements are embedded within or adjacent to memory arrays. By reducing the physical distance data must travel, these solutions aim to achieve significant improvements in both performance and energy efficiency.
Key technical goals include maximizing memory bandwidth utilization, reducing energy consumption associated with data transfers, and enabling new forms of parallelism that were previously impractical. The technology seeks to transform memory from a passive storage medium into an active participant in computation, capable of performing operations on data in-situ rather than requiring data to be moved to distant processing units.
Contemporary near-memory computing initiatives focus on developing hybrid architectures that maintain compatibility with existing software ecosystems while introducing new computational capabilities at the memory level. These solutions target applications with high memory bandwidth requirements, irregular access patterns, and opportunities for fine-grained parallelism, positioning near-memory computing as a critical enabler for next-generation data-intensive computing systems.
Market Demand for Enhanced Data Parallelism Solutions
The global computing landscape is experiencing unprecedented demand for enhanced data parallelism solutions, driven by the exponential growth of data-intensive applications across multiple sectors. High-performance computing, artificial intelligence, machine learning, and big data analytics are creating substantial pressure on traditional computing architectures to deliver faster processing capabilities while maintaining energy efficiency.
Enterprise data centers are facing significant challenges in meeting the computational requirements of modern workloads. Traditional von Neumann architectures struggle with the memory wall problem, where data movement between processors and memory becomes the primary bottleneck. This limitation has created urgent market demand for innovative solutions that can process data closer to where it resides, reducing latency and improving overall system performance.
The artificial intelligence and machine learning sectors represent particularly strong demand drivers for near-memory computing solutions. Deep learning models require massive parallel processing capabilities for training and inference operations. Current GPU-based solutions, while powerful, still face memory bandwidth limitations that constrain their effectiveness. Organizations developing AI applications are actively seeking technologies that can accelerate matrix operations, neural network computations, and large-scale data processing tasks.
Cloud service providers constitute another major market segment demanding enhanced data parallelism solutions. As they scale their infrastructure to support growing customer workloads, energy efficiency and performance optimization become critical competitive factors. Near-memory computing technologies offer potential solutions for reducing power consumption while increasing computational throughput, making them attractive investments for hyperscale data center operators.
The scientific computing community also drives significant demand for these technologies. Research institutions conducting climate modeling, genomics analysis, and physics simulations require massive parallel processing capabilities. Traditional supercomputing approaches are reaching practical limits in terms of power consumption and cost-effectiveness, creating opportunities for near-memory solutions to address these computational challenges.
Financial services, telecommunications, and autonomous vehicle industries are emerging as additional demand sources. Real-time data processing requirements in these sectors necessitate low-latency, high-throughput computing solutions that can handle streaming data efficiently. Near-memory computing architectures offer promising approaches to meet these stringent performance requirements while managing operational costs effectively.
Enterprise data centers are facing significant challenges in meeting the computational requirements of modern workloads. Traditional von Neumann architectures struggle with the memory wall problem, where data movement between processors and memory becomes the primary bottleneck. This limitation has created urgent market demand for innovative solutions that can process data closer to where it resides, reducing latency and improving overall system performance.
The artificial intelligence and machine learning sectors represent particularly strong demand drivers for near-memory computing solutions. Deep learning models require massive parallel processing capabilities for training and inference operations. Current GPU-based solutions, while powerful, still face memory bandwidth limitations that constrain their effectiveness. Organizations developing AI applications are actively seeking technologies that can accelerate matrix operations, neural network computations, and large-scale data processing tasks.
Cloud service providers constitute another major market segment demanding enhanced data parallelism solutions. As they scale their infrastructure to support growing customer workloads, energy efficiency and performance optimization become critical competitive factors. Near-memory computing technologies offer potential solutions for reducing power consumption while increasing computational throughput, making them attractive investments for hyperscale data center operators.
The scientific computing community also drives significant demand for these technologies. Research institutions conducting climate modeling, genomics analysis, and physics simulations require massive parallel processing capabilities. Traditional supercomputing approaches are reaching practical limits in terms of power consumption and cost-effectiveness, creating opportunities for near-memory solutions to address these computational challenges.
Financial services, telecommunications, and autonomous vehicle industries are emerging as additional demand sources. Real-time data processing requirements in these sectors necessitate low-latency, high-throughput computing solutions that can handle streaming data efficiently. Near-memory computing architectures offer promising approaches to meet these stringent performance requirements while managing operational costs effectively.
Current State of Near-Memory Computing Technologies
Near-memory computing technologies have emerged as a critical solution to address the memory wall problem that has plagued traditional computing architectures for decades. The current landscape encompasses several distinct technological approaches, each targeting different aspects of data movement optimization and computational efficiency enhancement.
Processing-in-Memory (PIM) technologies represent the most mature segment of near-memory solutions. Leading implementations include Samsung's HBM-PIM and SK Hynix's GDDR6-AiM, which integrate arithmetic logic units directly into memory dies. These solutions demonstrate significant energy efficiency improvements, achieving up to 70% reduction in data movement overhead for specific workloads such as neural network inference and database operations.
Compute-near-Memory (CnM) architectures have gained substantial traction in enterprise applications. Intel's Data Streaming Accelerator and AMD's Infinity Cache exemplify this approach by positioning specialized processing units adjacent to memory controllers. These implementations show particular strength in bandwidth-intensive applications, delivering 2-3x performance improvements in memory-bound computational tasks.
Emerging resistive memory technologies, including ReRAM, PCM, and STT-MRAM, are reshaping the near-memory computing paradigm. Companies like Crossbar, Intel, and Everspin have developed commercial-grade solutions that enable in-situ computation within the memory array itself. These technologies demonstrate promising results for neuromorphic computing applications, achieving energy efficiencies comparable to biological neural networks.
The integration challenges remain significant across all near-memory approaches. Current solutions face limitations in programming model standardization, with each vendor implementing proprietary APIs and development frameworks. Memory coherency protocols require substantial modifications to accommodate near-memory processing units, leading to increased system complexity and potential performance bottlenecks.
Scalability constraints represent another critical challenge in contemporary implementations. Most existing near-memory solutions operate effectively at single-node levels but encounter significant difficulties in distributed computing environments. Network-attached memory solutions from companies like MemVerge and Kove are beginning to address these limitations through disaggregated memory architectures.
The current technological maturity varies significantly across different near-memory approaches. While PIM solutions have achieved commercial deployment in specific domains, broader adoption remains limited due to software ecosystem fragmentation and integration complexity with existing computing infrastructures.
Processing-in-Memory (PIM) technologies represent the most mature segment of near-memory solutions. Leading implementations include Samsung's HBM-PIM and SK Hynix's GDDR6-AiM, which integrate arithmetic logic units directly into memory dies. These solutions demonstrate significant energy efficiency improvements, achieving up to 70% reduction in data movement overhead for specific workloads such as neural network inference and database operations.
Compute-near-Memory (CnM) architectures have gained substantial traction in enterprise applications. Intel's Data Streaming Accelerator and AMD's Infinity Cache exemplify this approach by positioning specialized processing units adjacent to memory controllers. These implementations show particular strength in bandwidth-intensive applications, delivering 2-3x performance improvements in memory-bound computational tasks.
Emerging resistive memory technologies, including ReRAM, PCM, and STT-MRAM, are reshaping the near-memory computing paradigm. Companies like Crossbar, Intel, and Everspin have developed commercial-grade solutions that enable in-situ computation within the memory array itself. These technologies demonstrate promising results for neuromorphic computing applications, achieving energy efficiencies comparable to biological neural networks.
The integration challenges remain significant across all near-memory approaches. Current solutions face limitations in programming model standardization, with each vendor implementing proprietary APIs and development frameworks. Memory coherency protocols require substantial modifications to accommodate near-memory processing units, leading to increased system complexity and potential performance bottlenecks.
Scalability constraints represent another critical challenge in contemporary implementations. Most existing near-memory solutions operate effectively at single-node levels but encounter significant difficulties in distributed computing environments. Network-attached memory solutions from companies like MemVerge and Kove are beginning to address these limitations through disaggregated memory architectures.
The current technological maturity varies significantly across different near-memory approaches. While PIM solutions have achieved commercial deployment in specific domains, broader adoption remains limited due to software ecosystem fragmentation and integration complexity with existing computing infrastructures.
Existing Near-Memory Data Parallelism Solutions
01 Processing-in-Memory (PIM) architectures for parallel data operations
Near-memory computing architectures integrate processing units directly within or adjacent to memory arrays to enable parallel data processing. These solutions reduce data movement overhead by performing computations where data resides, utilizing memory banks as parallel processing elements. The architecture supports simultaneous operations across multiple memory units, enabling efficient execution of data-parallel workloads through distributed processing capabilities.- Processing-in-Memory (PIM) architectures for parallel data operations: Near-memory computing architectures integrate processing units directly within or adjacent to memory arrays to enable parallel data processing. These solutions reduce data movement overhead by performing computations where data resides, utilizing multiple processing elements that can operate simultaneously on different data segments. The architecture supports vector operations and SIMD-style parallelism, allowing multiple data elements to be processed concurrently within the memory subsystem.
- Memory-centric parallel computing with distributed processing elements: Distributed processing architectures place multiple computational units across memory banks or modules to achieve data-level parallelism. Each processing element can independently execute operations on local data partitions, enabling concurrent processing of multiple data streams. This approach leverages the inherent parallelism in memory organization, where different memory banks can be accessed simultaneously, allowing parallel execution of identical operations on different data sets.
- SIMD and vector processing in near-memory systems: Single Instruction Multiple Data architectures implemented in near-memory solutions enable parallel processing of multiple data elements with a single instruction. Vector processing units positioned close to memory can perform identical operations on arrays of data simultaneously, maximizing throughput for data-parallel workloads. These systems exploit regular data access patterns and uniform operations across data sets to achieve high computational efficiency.
- Multi-bank memory parallelism with concurrent access: Memory systems organized into multiple independent banks enable parallel data access and processing across different memory partitions. By structuring memory into separately addressable banks, multiple read and write operations can occur simultaneously, supporting parallel execution of data operations. This organization allows different processing elements to access distinct memory banks concurrently, eliminating access conflicts and maximizing data throughput for parallel workloads.
- Parallel data movement and interconnect architectures: Specialized interconnect fabrics and data movement mechanisms facilitate parallel transfer of data between memory and processing elements. Wide data buses and multiple parallel channels enable simultaneous data transfers across different paths, supporting high-bandwidth parallel operations. These architectures include crossbar switches, network-on-chip designs, and multi-channel interfaces that allow concurrent data movement to support parallel processing requirements in near-memory computing systems.
02 Memory-centric parallel computing with distributed execution units
Systems that distribute computational resources across memory hierarchies to achieve data parallelism through localized processing. Multiple execution units are positioned near memory modules to process data in parallel, minimizing latency and bandwidth bottlenecks. This approach enables concurrent operations on different data segments stored in separate memory regions, improving throughput for data-intensive applications.Expand Specific Solutions03 Vector and SIMD operations in near-memory processors
Implementation of single instruction multiple data processing capabilities within memory-adjacent computing units to exploit data parallelism. These solutions enable simultaneous execution of identical operations on multiple data elements stored in memory arrays. The architecture supports vector processing and parallel data transformations directly at the memory interface, reducing the need for data transfers to distant processing units.Expand Specific Solutions04 Multi-bank memory systems with parallel access mechanisms
Memory organizations that partition data across multiple independent banks to enable concurrent access and parallel processing. Each memory bank can be accessed simultaneously, allowing multiple data operations to proceed in parallel. This structure supports high-bandwidth data parallelism by eliminating sequential access constraints and enabling distributed workload execution across memory partitions.Expand Specific Solutions05 Data parallel accelerators with near-memory interconnects
Specialized acceleration units positioned close to memory with optimized interconnection networks for parallel data processing. These systems feature dedicated pathways between memory and processing elements designed to support high-throughput parallel operations. The architecture enables efficient distribution of data-parallel tasks across multiple accelerators while maintaining proximity to data storage, reducing communication overhead in parallel computing scenarios.Expand Specific Solutions
Key Players in Near-Memory and PIM Industry
The near-memory computing landscape for data parallelism is in a rapid growth phase, driven by increasing demand for high-performance computing and AI workloads. The market demonstrates significant scale with established semiconductor giants like Intel, Samsung Electronics, Micron Technology, and AMD leading traditional memory and processor development. Technology maturity varies considerably across players - while IBM, Huawei, and NEC represent mature enterprise solutions, emerging specialists like EdgeCortix and Graphcore focus on cutting-edge AI acceleration architectures. The competitive dynamics show convergence between memory manufacturers (Samsung, Micron), processor companies (Intel, AMD), and system integrators (Fujitsu, Hewlett-Packard) all pursuing near-memory processing capabilities. Academic institutions like Georgia Tech and University of Illinois contribute foundational research, while companies like Microsoft and Cisco drive software integration. This diverse ecosystem indicates the technology is transitioning from research to commercial deployment across multiple application domains.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has developed Processing-in-Memory (PIM) technology integrated into their GDDR6 and HBM memory solutions. Their approach includes specialized memory controllers that can perform computational operations directly within memory modules, reducing data movement overhead by up to 70%. The company's PIM-enabled memory supports parallel execution of multiple data streams simultaneously, with dedicated processing units embedded in memory banks. Samsung's solution particularly focuses on AI workloads and high-performance computing applications, offering bandwidth improvements of 2.5x compared to traditional memory architectures while maintaining compatibility with existing processor interfaces.
Strengths: Market-leading memory manufacturing capabilities, proven PIM technology integration, strong performance improvements. Weaknesses: Limited to specific memory types, requires specialized software optimization for maximum benefit.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed near-memory computing solutions through their Ascend AI processors and DaVinci architecture, which integrates specialized memory subsystems designed for parallel AI workloads. Their approach includes high-bandwidth memory (HBM) integration with AI processing units, supporting parallel data flows across multiple compute engines simultaneously. Huawei's solution features intelligent memory management that can dynamically allocate memory resources based on workload characteristics, achieving up to 320GB/s memory bandwidth per processor. The company's near-memory architecture includes specialized data movement engines that optimize parallel data access patterns for neural network training and inference, reducing memory access latency by up to 50% compared to traditional architectures.
Strengths: AI-optimized memory architecture, high bandwidth capabilities, integrated hardware-software co-design. Weaknesses: Limited market availability due to trade restrictions, primarily focused on AI applications rather than general-purpose computing.
Core Innovations in Processing-in-Memory Technologies
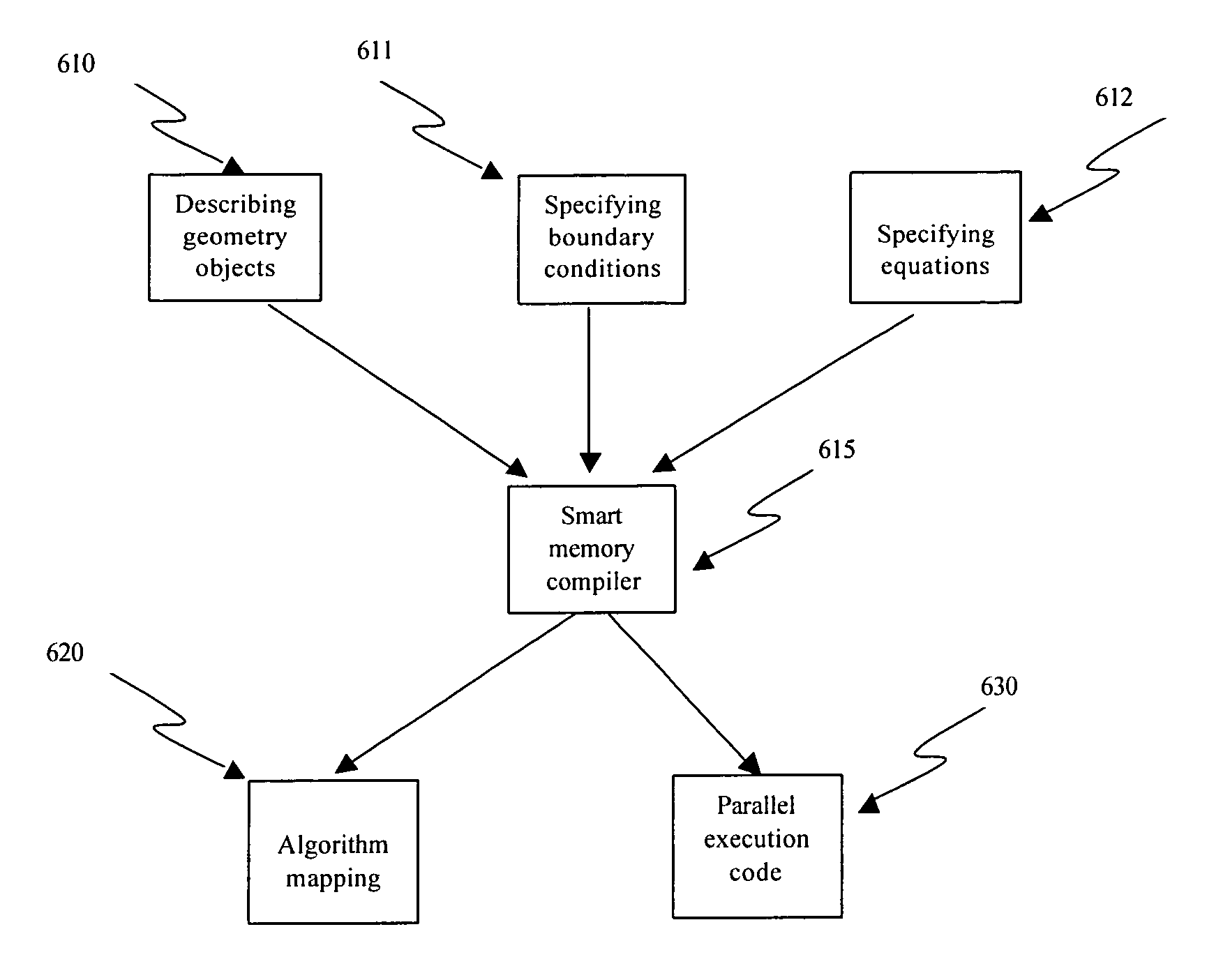
Algorithm mapping, specialized instructions and architecture features for smart memory computing
PatentInactiveUS7546438B2
Innovation
- A smart memory computing system that integrates data storage with processing capabilities, utilizing algorithm mapping, compiler techniques, and specialized instruction sets to enable massive data-level parallelism, allowing for in-situ data processing and reduced hardware requirements.

Near memory computing accelerator, dual in-line memory module and computing device
PatentWO2023041002A1
Innovation
- Design a near-memory computing accelerator that uses multiple controllers to acquire data from multiple memory blocks in parallel and perform computations concurrently. Employ a proprietary instruction set to support addition, multiplication, division, lookup, and non-linear calculations. Combined with a cache unit, it reduces memory access frequency and improves data processing speed.




Hardware-Software Co-design Considerations
The successful implementation of near-memory solutions for enhanced data parallelism requires careful orchestration between hardware architecture and software optimization strategies. This co-design approach ensures that the computational capabilities of near-memory processing units are fully utilized while maintaining system coherence and programmability.
Hardware considerations center on the integration of processing elements within or adjacent to memory hierarchies. Memory controllers must be enhanced with computational capabilities, requiring specialized arithmetic logic units that can perform operations directly on data streams without traditional CPU involvement. The memory interface design becomes critical, as it must support both conventional read/write operations and computational instructions while maintaining bandwidth efficiency.
Cache coherence protocols require fundamental redesign to accommodate distributed processing near memory banks. Traditional coherence mechanisms assume centralized processing units, but near-memory computing introduces multiple processing points that must coordinate data consistency. New coherence protocols must balance performance with correctness, potentially employing relaxed consistency models for specific parallel workloads.
Software stack modifications are equally crucial for realizing the benefits of near-memory parallelism. Compilers must be enhanced to recognize data access patterns suitable for near-memory execution and automatically partition computations between traditional processors and near-memory units. This requires sophisticated analysis of data locality, computational intensity, and dependency chains within parallel algorithms.
Runtime systems need dynamic load balancing mechanisms that can distribute work across heterogeneous processing elements. The scheduler must consider not only computational load but also data placement and movement costs. Memory allocation strategies become more complex, requiring awareness of which memory banks have computational capabilities and optimizing data placement accordingly.
Programming models must evolve to expose near-memory parallelism to developers while maintaining ease of use. This involves extending existing parallel programming frameworks with abstractions that allow explicit control over near-memory execution when needed, while providing automatic optimization for common patterns. The challenge lies in balancing programmer control with system automation to achieve optimal performance across diverse applications.
Hardware considerations center on the integration of processing elements within or adjacent to memory hierarchies. Memory controllers must be enhanced with computational capabilities, requiring specialized arithmetic logic units that can perform operations directly on data streams without traditional CPU involvement. The memory interface design becomes critical, as it must support both conventional read/write operations and computational instructions while maintaining bandwidth efficiency.
Cache coherence protocols require fundamental redesign to accommodate distributed processing near memory banks. Traditional coherence mechanisms assume centralized processing units, but near-memory computing introduces multiple processing points that must coordinate data consistency. New coherence protocols must balance performance with correctness, potentially employing relaxed consistency models for specific parallel workloads.
Software stack modifications are equally crucial for realizing the benefits of near-memory parallelism. Compilers must be enhanced to recognize data access patterns suitable for near-memory execution and automatically partition computations between traditional processors and near-memory units. This requires sophisticated analysis of data locality, computational intensity, and dependency chains within parallel algorithms.
Runtime systems need dynamic load balancing mechanisms that can distribute work across heterogeneous processing elements. The scheduler must consider not only computational load but also data placement and movement costs. Memory allocation strategies become more complex, requiring awareness of which memory banks have computational capabilities and optimizing data placement accordingly.
Programming models must evolve to expose near-memory parallelism to developers while maintaining ease of use. This involves extending existing parallel programming frameworks with abstractions that allow explicit control over near-memory execution when needed, while providing automatic optimization for common patterns. The challenge lies in balancing programmer control with system automation to achieve optimal performance across diverse applications.
Energy Efficiency and Thermal Management Challenges
Near-memory computing architectures face significant energy efficiency challenges that directly impact their viability for large-scale data parallel applications. The primary energy consumption stems from data movement between processing units and memory hierarchies, which can account for up to 70% of total system power consumption in traditional architectures. Near-memory solutions aim to reduce this overhead by placing computational resources closer to data storage, but this proximity introduces new energy optimization complexities.
Processing-in-memory (PIM) and near-data computing implementations must balance computational density with power dissipation constraints. Current DRAM-based near-memory solutions typically operate at lower frequencies compared to traditional processors to maintain acceptable power envelopes. This trade-off becomes particularly challenging when scaling to multiple parallel processing elements within the same memory module, as aggregate power consumption can quickly exceed thermal design limits.
Thermal management presents critical challenges for near-memory architectures due to the heat-sensitive nature of memory devices. DRAM cells require specific temperature ranges to maintain data integrity and refresh characteristics. Elevated temperatures can lead to increased error rates, reduced retention times, and potential data corruption. The integration of processing elements within or adjacent to memory arrays creates localized hot spots that can compromise memory reliability and system performance.
Advanced cooling solutions become essential for high-performance near-memory systems. Traditional air cooling may prove insufficient for dense processing-in-memory configurations, necessitating liquid cooling or specialized thermal interface materials. The thermal design must consider both steady-state heat dissipation and transient thermal spikes during intensive parallel computations.
Power management strategies for near-memory solutions require sophisticated dynamic voltage and frequency scaling (DVFS) mechanisms. These systems must rapidly adjust operating parameters based on workload characteristics and thermal feedback to prevent overheating while maintaining computational throughput. Fine-grained power gating of individual processing elements enables selective activation of computational resources based on data locality and parallelism requirements.
Emerging technologies such as resistive RAM (ReRAM) and phase-change memory (PCM) offer potential advantages for near-memory computing by providing inherent computational capabilities with lower power consumption. However, these technologies introduce their own thermal sensitivities and endurance limitations that must be carefully managed in parallel processing scenarios.
Processing-in-memory (PIM) and near-data computing implementations must balance computational density with power dissipation constraints. Current DRAM-based near-memory solutions typically operate at lower frequencies compared to traditional processors to maintain acceptable power envelopes. This trade-off becomes particularly challenging when scaling to multiple parallel processing elements within the same memory module, as aggregate power consumption can quickly exceed thermal design limits.
Thermal management presents critical challenges for near-memory architectures due to the heat-sensitive nature of memory devices. DRAM cells require specific temperature ranges to maintain data integrity and refresh characteristics. Elevated temperatures can lead to increased error rates, reduced retention times, and potential data corruption. The integration of processing elements within or adjacent to memory arrays creates localized hot spots that can compromise memory reliability and system performance.
Advanced cooling solutions become essential for high-performance near-memory systems. Traditional air cooling may prove insufficient for dense processing-in-memory configurations, necessitating liquid cooling or specialized thermal interface materials. The thermal design must consider both steady-state heat dissipation and transient thermal spikes during intensive parallel computations.
Power management strategies for near-memory solutions require sophisticated dynamic voltage and frequency scaling (DVFS) mechanisms. These systems must rapidly adjust operating parameters based on workload characteristics and thermal feedback to prevent overheating while maintaining computational throughput. Fine-grained power gating of individual processing elements enables selective activation of computational resources based on data locality and parallelism requirements.
Emerging technologies such as resistive RAM (ReRAM) and phase-change memory (PCM) offer potential advantages for near-memory computing by providing inherent computational capabilities with lower power consumption. However, these technologies introduce their own thermal sensitivities and endurance limitations that must be carefully managed in parallel processing scenarios.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!