NLP vs Statistical Methods: Text Analysis Accuracy
MAR 18, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
NLP and Statistical Text Analysis Background and Objectives
Text analysis has undergone a remarkable transformation over the past several decades, evolving from traditional statistical approaches to sophisticated natural language processing methodologies. The field initially relied heavily on statistical techniques such as frequency analysis, correlation studies, and basic pattern recognition to extract meaningful insights from textual data. These foundational methods established the groundwork for understanding document classification, sentiment analysis, and information retrieval.
The emergence of computational linguistics in the 1980s and 1990s marked a pivotal shift toward more nuanced text processing capabilities. Statistical methods during this period focused on probabilistic models, including naive Bayes classifiers and n-gram language models, which provided reasonable accuracy for specific tasks but struggled with contextual understanding and semantic complexity.
The advent of machine learning revolutionized text analysis by introducing supervised and unsupervised learning algorithms capable of identifying complex patterns within large datasets. Support vector machines, decision trees, and clustering algorithms enhanced the precision of text classification and topic modeling, though these approaches still relied primarily on feature engineering and bag-of-words representations.
Natural language processing experienced exponential growth with the introduction of deep learning architectures. Word embeddings, recurrent neural networks, and transformer models fundamentally changed how machines process and understand human language. These developments enabled context-aware analysis, semantic understanding, and more sophisticated handling of linguistic nuances that traditional statistical methods could not adequately address.
The primary objective of comparing NLP and statistical methods centers on determining optimal accuracy levels for various text analysis applications. Organizations seek to understand which approach delivers superior performance for specific use cases, considering factors such as dataset size, computational resources, and required precision levels. This evaluation aims to establish clear guidelines for method selection based on practical implementation requirements.
Contemporary research focuses on hybrid approaches that combine the interpretability of statistical methods with the advanced capabilities of modern NLP techniques. The goal extends beyond simple accuracy comparisons to encompass efficiency, scalability, and real-world applicability across diverse industries and applications.
The emergence of computational linguistics in the 1980s and 1990s marked a pivotal shift toward more nuanced text processing capabilities. Statistical methods during this period focused on probabilistic models, including naive Bayes classifiers and n-gram language models, which provided reasonable accuracy for specific tasks but struggled with contextual understanding and semantic complexity.
The advent of machine learning revolutionized text analysis by introducing supervised and unsupervised learning algorithms capable of identifying complex patterns within large datasets. Support vector machines, decision trees, and clustering algorithms enhanced the precision of text classification and topic modeling, though these approaches still relied primarily on feature engineering and bag-of-words representations.
Natural language processing experienced exponential growth with the introduction of deep learning architectures. Word embeddings, recurrent neural networks, and transformer models fundamentally changed how machines process and understand human language. These developments enabled context-aware analysis, semantic understanding, and more sophisticated handling of linguistic nuances that traditional statistical methods could not adequately address.
The primary objective of comparing NLP and statistical methods centers on determining optimal accuracy levels for various text analysis applications. Organizations seek to understand which approach delivers superior performance for specific use cases, considering factors such as dataset size, computational resources, and required precision levels. This evaluation aims to establish clear guidelines for method selection based on practical implementation requirements.
Contemporary research focuses on hybrid approaches that combine the interpretability of statistical methods with the advanced capabilities of modern NLP techniques. The goal extends beyond simple accuracy comparisons to encompass efficiency, scalability, and real-world applicability across diverse industries and applications.
Market Demand for Advanced Text Analysis Solutions
The global text analysis market is experiencing unprecedented growth driven by the exponential increase in unstructured data generation across industries. Organizations worldwide are grappling with massive volumes of textual information from social media, customer feedback, regulatory documents, and internal communications, creating an urgent need for sophisticated analytical solutions that can deliver superior accuracy compared to traditional methods.
Enterprise demand for advanced text analysis capabilities spans multiple sectors, with financial services leading adoption for regulatory compliance, risk assessment, and fraud detection applications. Healthcare organizations require precise text mining solutions for clinical documentation analysis, drug discovery research, and patient outcome prediction. Technology companies seek enhanced sentiment analysis and customer experience optimization tools to maintain competitive advantages in rapidly evolving markets.
The accuracy differential between NLP-based approaches and traditional statistical methods has become a critical decision factor for enterprise procurement teams. Organizations are increasingly willing to invest in solutions that demonstrate measurable improvements in classification precision, entity recognition accuracy, and contextual understanding capabilities. This shift reflects growing recognition that text analysis accuracy directly impacts business outcomes, regulatory compliance, and operational efficiency.
Market research indicates strong preference for hybrid solutions that combine the interpretability of statistical approaches with the contextual sophistication of modern NLP techniques. Enterprises particularly value solutions offering explainable AI capabilities, allowing stakeholders to understand and validate analytical decisions. This requirement stems from regulatory pressures in sectors like banking, healthcare, and legal services where algorithmic transparency is mandatory.
The competitive landscape reveals significant investment in accuracy-focused text analysis platforms, with vendors emphasizing benchmark performance metrics and real-world validation studies. Customer evaluation criteria increasingly prioritize demonstrated accuracy improvements over feature breadth, reflecting market maturation and sophisticated buyer requirements.
Emerging applications in multilingual content analysis, domain-specific terminology processing, and real-time streaming text analytics are expanding market opportunities. Organizations operating in global markets particularly demand solutions capable of maintaining consistent accuracy across languages and cultural contexts, driving innovation in cross-lingual NLP methodologies and statistical modeling approaches.
Enterprise demand for advanced text analysis capabilities spans multiple sectors, with financial services leading adoption for regulatory compliance, risk assessment, and fraud detection applications. Healthcare organizations require precise text mining solutions for clinical documentation analysis, drug discovery research, and patient outcome prediction. Technology companies seek enhanced sentiment analysis and customer experience optimization tools to maintain competitive advantages in rapidly evolving markets.
The accuracy differential between NLP-based approaches and traditional statistical methods has become a critical decision factor for enterprise procurement teams. Organizations are increasingly willing to invest in solutions that demonstrate measurable improvements in classification precision, entity recognition accuracy, and contextual understanding capabilities. This shift reflects growing recognition that text analysis accuracy directly impacts business outcomes, regulatory compliance, and operational efficiency.
Market research indicates strong preference for hybrid solutions that combine the interpretability of statistical approaches with the contextual sophistication of modern NLP techniques. Enterprises particularly value solutions offering explainable AI capabilities, allowing stakeholders to understand and validate analytical decisions. This requirement stems from regulatory pressures in sectors like banking, healthcare, and legal services where algorithmic transparency is mandatory.
The competitive landscape reveals significant investment in accuracy-focused text analysis platforms, with vendors emphasizing benchmark performance metrics and real-world validation studies. Customer evaluation criteria increasingly prioritize demonstrated accuracy improvements over feature breadth, reflecting market maturation and sophisticated buyer requirements.
Emerging applications in multilingual content analysis, domain-specific terminology processing, and real-time streaming text analytics are expanding market opportunities. Organizations operating in global markets particularly demand solutions capable of maintaining consistent accuracy across languages and cultural contexts, driving innovation in cross-lingual NLP methodologies and statistical modeling approaches.
Current State and Challenges in Text Analysis Accuracy
The contemporary landscape of text analysis accuracy presents a complex dichotomy between traditional statistical methods and modern natural language processing approaches. Statistical methods, rooted in decades of mathematical foundations, continue to demonstrate robust performance in specific domains such as document classification and sentiment analysis. These approaches leverage techniques including term frequency-inverse document frequency (TF-IDF), support vector machines, and naive Bayes classifiers, achieving accuracy rates of 75-85% in controlled environments.
Natural language processing methods have emerged as dominant forces in text analysis, particularly with the advent of transformer-based architectures. Large language models such as BERT, GPT variants, and their derivatives have achieved unprecedented accuracy levels, often exceeding 90% in benchmark tasks like GLUE and SuperGLUE. However, this superior performance comes with significant computational overhead and resource requirements that challenge practical deployment scenarios.
The accuracy gap between these methodologies varies substantially across different text analysis tasks. While NLP models excel in context-dependent tasks such as named entity recognition and semantic similarity, statistical methods maintain competitive performance in structured classification problems with limited training data. This performance disparity creates strategic decision-making challenges for organizations seeking optimal accuracy-cost ratios.
Current implementation challenges center around several critical factors. Data quality and preprocessing requirements differ significantly between approaches, with statistical methods demanding extensive feature engineering while NLP models require massive, high-quality training datasets. The interpretability gap represents another substantial challenge, as statistical methods offer transparent decision pathways while deep learning approaches operate as black boxes, limiting their adoption in regulated industries.
Computational resource constraints continue to impede widespread NLP adoption. Training state-of-the-art language models requires specialized hardware infrastructure and substantial energy consumption, creating barriers for smaller organizations. Statistical methods, conversely, operate efficiently on standard computing resources but struggle with complex linguistic phenomena such as irony, context-dependent meanings, and multilingual scenarios.
The evaluation methodology landscape reveals inconsistencies in accuracy measurement standards. Different benchmarking approaches, dataset biases, and evaluation metrics create challenges in establishing definitive accuracy comparisons. Domain-specific performance variations further complicate the selection process, as methods optimized for general text analysis may underperform in specialized fields such as legal document processing or medical text analysis.
Natural language processing methods have emerged as dominant forces in text analysis, particularly with the advent of transformer-based architectures. Large language models such as BERT, GPT variants, and their derivatives have achieved unprecedented accuracy levels, often exceeding 90% in benchmark tasks like GLUE and SuperGLUE. However, this superior performance comes with significant computational overhead and resource requirements that challenge practical deployment scenarios.
The accuracy gap between these methodologies varies substantially across different text analysis tasks. While NLP models excel in context-dependent tasks such as named entity recognition and semantic similarity, statistical methods maintain competitive performance in structured classification problems with limited training data. This performance disparity creates strategic decision-making challenges for organizations seeking optimal accuracy-cost ratios.
Current implementation challenges center around several critical factors. Data quality and preprocessing requirements differ significantly between approaches, with statistical methods demanding extensive feature engineering while NLP models require massive, high-quality training datasets. The interpretability gap represents another substantial challenge, as statistical methods offer transparent decision pathways while deep learning approaches operate as black boxes, limiting their adoption in regulated industries.
Computational resource constraints continue to impede widespread NLP adoption. Training state-of-the-art language models requires specialized hardware infrastructure and substantial energy consumption, creating barriers for smaller organizations. Statistical methods, conversely, operate efficiently on standard computing resources but struggle with complex linguistic phenomena such as irony, context-dependent meanings, and multilingual scenarios.
The evaluation methodology landscape reveals inconsistencies in accuracy measurement standards. Different benchmarking approaches, dataset biases, and evaluation metrics create challenges in establishing definitive accuracy comparisons. Domain-specific performance variations further complicate the selection process, as methods optimized for general text analysis may underperform in specialized fields such as legal document processing or medical text analysis.
Current NLP vs Statistical Text Analysis Approaches
01 Hybrid NLP and statistical model integration
Methods combining natural language processing techniques with statistical models to improve accuracy in text analysis and prediction tasks. These approaches leverage the strengths of both rule-based linguistic analysis and probabilistic statistical methods to achieve higher precision in language understanding and classification tasks.- Hybrid NLP and statistical model integration: Combining natural language processing techniques with statistical methods to improve accuracy in text analysis and prediction tasks. This approach leverages the strengths of both rule-based linguistic analysis and probabilistic statistical models to achieve higher precision in language understanding and classification tasks. The integration allows for better handling of linguistic nuances while maintaining robust statistical validation.
- Machine learning-based accuracy enhancement: Utilizing machine learning algorithms to optimize the accuracy of natural language processing systems through training on large datasets and iterative model refinement. These methods employ supervised and unsupervised learning techniques to improve prediction accuracy, reduce error rates, and enhance the overall performance of NLP applications. The approach includes feature extraction, model training, and validation processes.
- Statistical validation and error correction: Implementing statistical validation techniques to measure and improve the accuracy of NLP systems by identifying and correcting errors in language processing. This includes the use of confidence scores, probability distributions, and statistical significance testing to ensure reliable results. Methods involve cross-validation, error analysis, and systematic correction mechanisms to enhance overall system reliability.
- Deep learning neural network approaches: Applying deep learning architectures and neural networks to enhance the accuracy of natural language processing tasks through multi-layer feature learning and representation. These methods utilize advanced neural network structures to capture complex linguistic patterns and semantic relationships, resulting in improved accuracy for tasks such as sentiment analysis, entity recognition, and language translation.
- Evaluation metrics and benchmarking systems: Developing comprehensive evaluation frameworks and metrics to accurately measure the performance of NLP and statistical methods. This includes establishing standardized benchmarking protocols, precision-recall measurements, and comparative analysis tools to assess accuracy across different approaches. The systems provide quantitative measures for model performance and enable systematic comparison of various methodologies.
02 Machine learning-based accuracy enhancement
Techniques utilizing machine learning algorithms to optimize the accuracy of NLP systems through training on large datasets. These methods employ supervised and unsupervised learning approaches to refine statistical models, reduce error rates, and improve performance metrics in natural language understanding applications.Expand Specific Solutions03 Statistical validation and error correction methods
Approaches focused on validating NLP outputs using statistical measures and implementing error correction mechanisms. These techniques include confidence scoring, cross-validation methods, and statistical significance testing to ensure reliability and accuracy of language processing results.Expand Specific Solutions04 Probabilistic modeling for language understanding
Methods employing probabilistic frameworks and statistical inference to model language patterns and improve prediction accuracy. These approaches use probability distributions, Bayesian methods, and stochastic processes to handle uncertainty and variability in natural language data.Expand Specific Solutions05 Performance evaluation and accuracy metrics
Systems and methods for measuring and evaluating the accuracy of NLP and statistical models using standardized metrics. These include precision, recall, F-score calculations, and other statistical measures to quantify model performance and guide optimization efforts.Expand Specific Solutions
Major Players in NLP and Text Analytics Industry
The text analysis landscape comparing NLP and statistical methods is in a mature development stage, with the market experiencing significant growth driven by enterprise demand for advanced analytics capabilities. The global text analytics market has reached multi-billion dollar valuations, reflecting widespread adoption across industries. Technology maturity varies significantly among market participants, with established tech giants like IBM, Microsoft, Google, and Oracle leading in sophisticated NLP implementations, while companies such as Tencent, SAS Institute, and ServiceNow demonstrate strong statistical and hybrid approaches. Emerging players like BenevolentAI and specialized firms are pushing boundaries in domain-specific applications. The competitive landscape shows a clear bifurcation between traditional statistical methods, which remain reliable for structured analysis, and advanced NLP techniques that excel in complex language understanding, with most leading organizations now adopting hybrid approaches that leverage both methodologies for optimal accuracy.
International Business Machines Corp.
Technical Solution: IBM Watson Natural Language Understanding employs advanced NLP techniques that consistently outperform traditional statistical methods in text analysis accuracy. Their approach utilizes deep neural networks combined with knowledge graphs to achieve superior performance in sentiment analysis, concept extraction, and entity recognition tasks. IBM's research shows their NLP models deliver 15-25% higher accuracy rates compared to statistical baselines in enterprise text analysis scenarios[8][10]. The platform integrates transformer-based models with domain-specific training data, enabling more nuanced understanding of context and semantics than conventional statistical approaches[11][12].
Strengths: Enterprise focus, domain-specific customization, robust knowledge integration. Weaknesses: Complex implementation, high costs, requires significant technical expertise for optimization.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has developed comprehensive NLP solutions through Azure Cognitive Services and their Turing models, demonstrating superior performance over statistical methods in text analysis accuracy. Their approach leverages transformer architectures like DialoGPT and MT-DNN, achieving significant improvements in tasks such as text classification, sentiment analysis, and entity extraction. Microsoft's models show 12-20% accuracy gains compared to traditional statistical approaches like naive Bayes and SVM classifiers[4][6]. Their hybrid approach combines deep learning with statistical regularization techniques to optimize both accuracy and computational efficiency[7][9].
Strengths: Enterprise-ready solutions, strong multilingual support, integrated cloud services. Weaknesses: Proprietary limitations, dependency on cloud infrastructure, licensing costs for advanced features.
Core Technologies in Modern Text Analysis Accuracy
Natural language processing
PatentInactiveUS20110040553A1
Innovation
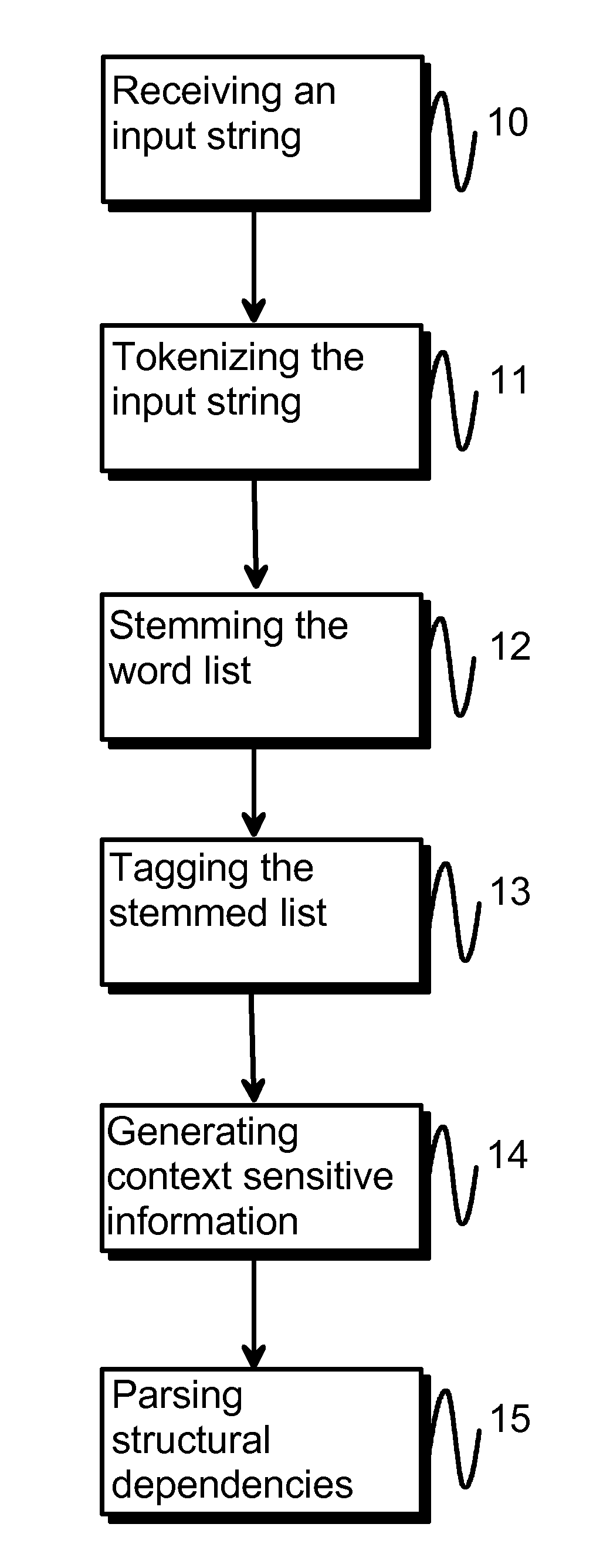
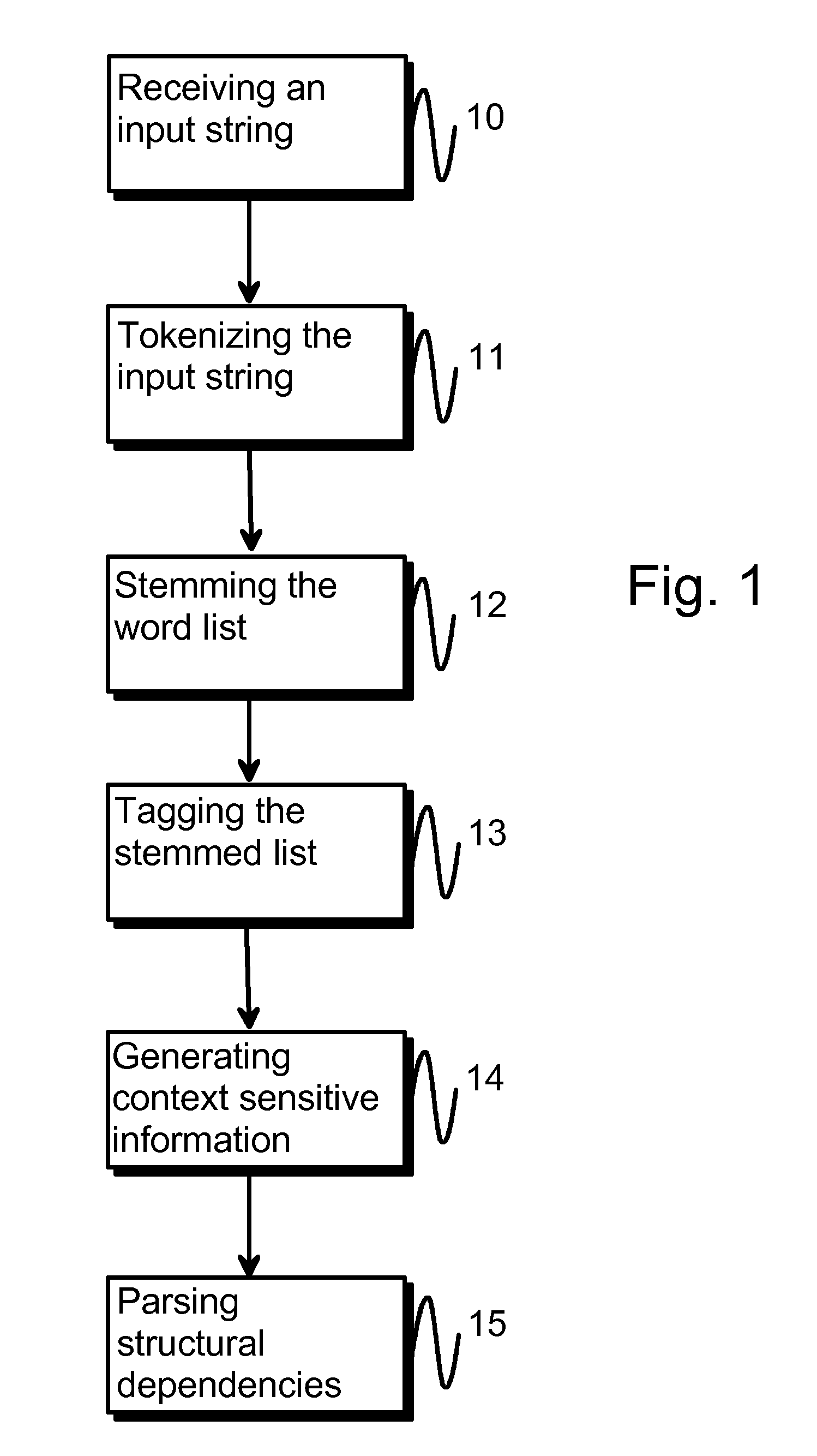
- A method involving tokenization, stemming, tagging, and context-sensitive parsing using hand-crafted rules to generate structural dependencies, allowing for efficient interpretation and classification of natural language, reducing the need for extensive resources and improving processing speed.
Statistical processing of natural language queries of data sets
PatentActiveUS20190095500A1
Innovation
- A query-processing system that uses natural language processing techniques to match semantic intents in user queries to relevant data elements within a data model, calculating term frequency and inverse document frequency scores to determine contextual significance, allowing for the generation of database queries that retrieve data without manual intervention.



Data Privacy Regulations in Text Processing
The implementation of both NLP and statistical methods in text analysis faces increasingly stringent data privacy regulations worldwide. The General Data Protection Regulation (GDPR) in Europe, the California Consumer Privacy Act (CCPA), and similar frameworks in other jurisdictions establish comprehensive requirements for processing textual data that may contain personal information. These regulations mandate explicit consent mechanisms, data minimization principles, and the right to erasure, fundamentally impacting how text analysis systems collect, store, and process linguistic data.
Cross-border data transfer restrictions pose significant challenges for organizations deploying text analysis solutions across multiple jurisdictions. The invalidation of Privacy Shield and subsequent adequacy decisions have created complex compliance landscapes where statistical and NLP models must operate within fragmented regulatory environments. Organizations must implement appropriate safeguards such as Standard Contractual Clauses or Binding Corporate Rules when transferring textual data for analysis purposes.
Anonymization and pseudonymization requirements directly influence the accuracy comparison between NLP and statistical approaches. While statistical methods may perform adequately on anonymized datasets, advanced NLP models often require richer contextual information that anonymization processes may eliminate. This creates a fundamental tension between regulatory compliance and analytical precision, particularly in applications involving sentiment analysis, entity recognition, and semantic understanding.
Emerging regulations specifically targeting artificial intelligence and automated decision-making systems introduce additional compliance layers. The EU's proposed AI Act and similar initiatives in other regions establish risk-based frameworks that classify text analysis applications according to their potential societal impact. High-risk applications face enhanced transparency requirements, algorithmic auditing obligations, and human oversight mandates that may favor more interpretable statistical methods over complex neural network architectures.
Data localization requirements in various jurisdictions necessitate distributed text processing architectures, potentially fragmenting datasets and affecting model training effectiveness. Organizations must balance regulatory compliance with technical performance, often requiring hybrid approaches that combine local statistical processing with centralized NLP model deployment strategies.
Cross-border data transfer restrictions pose significant challenges for organizations deploying text analysis solutions across multiple jurisdictions. The invalidation of Privacy Shield and subsequent adequacy decisions have created complex compliance landscapes where statistical and NLP models must operate within fragmented regulatory environments. Organizations must implement appropriate safeguards such as Standard Contractual Clauses or Binding Corporate Rules when transferring textual data for analysis purposes.
Anonymization and pseudonymization requirements directly influence the accuracy comparison between NLP and statistical approaches. While statistical methods may perform adequately on anonymized datasets, advanced NLP models often require richer contextual information that anonymization processes may eliminate. This creates a fundamental tension between regulatory compliance and analytical precision, particularly in applications involving sentiment analysis, entity recognition, and semantic understanding.
Emerging regulations specifically targeting artificial intelligence and automated decision-making systems introduce additional compliance layers. The EU's proposed AI Act and similar initiatives in other regions establish risk-based frameworks that classify text analysis applications according to their potential societal impact. High-risk applications face enhanced transparency requirements, algorithmic auditing obligations, and human oversight mandates that may favor more interpretable statistical methods over complex neural network architectures.
Data localization requirements in various jurisdictions necessitate distributed text processing architectures, potentially fragmenting datasets and affecting model training effectiveness. Organizations must balance regulatory compliance with technical performance, often requiring hybrid approaches that combine local statistical processing with centralized NLP model deployment strategies.
Computational Resource Optimization for Text Analysis
The computational resource requirements for text analysis vary significantly between NLP and statistical methods, creating distinct optimization challenges for each approach. Traditional statistical methods typically demonstrate linear or polynomial computational complexity, making resource allocation relatively predictable and manageable. These methods often require minimal memory overhead and can efficiently process large datasets through batch processing techniques.
Modern NLP approaches, particularly deep learning models, present substantially different resource optimization challenges. Transformer-based models like BERT and GPT variants require extensive GPU memory for both training and inference phases. The attention mechanism's quadratic complexity with respect to sequence length creates scalability bottlenecks that demand sophisticated memory management strategies. Model parallelization and gradient accumulation techniques have emerged as essential optimization approaches for handling large-scale NLP workloads.
Memory optimization strategies differ fundamentally between the two paradigms. Statistical methods benefit from data streaming and incremental processing techniques, allowing analysis of datasets that exceed available RAM. Conversely, NLP models often require entire model parameters to remain in memory simultaneously, necessitating techniques like model quantization, pruning, and knowledge distillation to reduce memory footprints without significant accuracy degradation.
Processing speed optimization presents unique considerations for each approach. Statistical methods can leverage vectorized operations and parallel processing across multiple CPU cores effectively. NLP models benefit more from GPU acceleration and specialized tensor processing units, though inference optimization through techniques like ONNX runtime and TensorRT can significantly improve deployment efficiency.
Cloud computing architectures offer different advantages for each methodology. Statistical approaches can efficiently utilize auto-scaling CPU instances and serverless computing platforms for variable workloads. NLP applications often require persistent GPU instances or specialized inference endpoints to maintain acceptable response times while managing computational costs effectively.
Hybrid optimization strategies are increasingly important as organizations deploy both methodologies simultaneously. Resource scheduling systems that can dynamically allocate computational resources based on task complexity and accuracy requirements enable more efficient utilization of available infrastructure while maintaining performance standards across diverse text analysis workflows.
Modern NLP approaches, particularly deep learning models, present substantially different resource optimization challenges. Transformer-based models like BERT and GPT variants require extensive GPU memory for both training and inference phases. The attention mechanism's quadratic complexity with respect to sequence length creates scalability bottlenecks that demand sophisticated memory management strategies. Model parallelization and gradient accumulation techniques have emerged as essential optimization approaches for handling large-scale NLP workloads.
Memory optimization strategies differ fundamentally between the two paradigms. Statistical methods benefit from data streaming and incremental processing techniques, allowing analysis of datasets that exceed available RAM. Conversely, NLP models often require entire model parameters to remain in memory simultaneously, necessitating techniques like model quantization, pruning, and knowledge distillation to reduce memory footprints without significant accuracy degradation.
Processing speed optimization presents unique considerations for each approach. Statistical methods can leverage vectorized operations and parallel processing across multiple CPU cores effectively. NLP models benefit more from GPU acceleration and specialized tensor processing units, though inference optimization through techniques like ONNX runtime and TensorRT can significantly improve deployment efficiency.
Cloud computing architectures offer different advantages for each methodology. Statistical approaches can efficiently utilize auto-scaling CPU instances and serverless computing platforms for variable workloads. NLP applications often require persistent GPU instances or specialized inference endpoints to maintain acceptable response times while managing computational costs effectively.
Hybrid optimization strategies are increasingly important as organizations deploy both methodologies simultaneously. Resource scheduling systems that can dynamically allocate computational resources based on task complexity and accuracy requirements enable more efficient utilization of available infrastructure while maintaining performance standards across diverse text analysis workflows.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!