

Optimizing Hardware-Software Co-Design in AI Inference Accelerators
JUN 5, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
AI Accelerator Co-Design Background and Objectives
The evolution of artificial intelligence has fundamentally transformed computational paradigms, driving unprecedented demand for specialized processing architectures capable of handling complex neural network workloads. Traditional computing systems, originally designed for general-purpose applications, have proven inadequate for the intensive matrix operations and parallel processing requirements inherent in AI inference tasks. This technological gap has catalyzed the emergence of dedicated AI inference accelerators, representing a critical shift toward domain-specific computing solutions.
Hardware-software co-design has emerged as a pivotal methodology for addressing the performance bottlenecks and efficiency challenges in AI inference systems. Unlike conventional approaches that treat hardware and software as separate entities, co-design methodology integrates both domains from the earliest development stages, enabling optimized system-level solutions that maximize computational efficiency while minimizing power consumption and latency.
The historical development of AI accelerators reveals a progression from repurposed graphics processing units to purpose-built inference engines. Early implementations relied heavily on existing GPU architectures, which, while offering parallel processing capabilities, suffered from inefficiencies due to their graphics-centric design. The recognition of these limitations spurred the development of specialized neural processing units, tensor processing units, and field-programmable gate arrays specifically optimized for AI workloads.
Contemporary AI inference accelerators face multifaceted challenges spanning computational efficiency, memory bandwidth limitations, power constraints, and the need for flexible architectures capable of supporting diverse neural network topologies. The exponential growth in model complexity, exemplified by large language models and computer vision networks, has intensified these challenges, demanding innovative approaches to hardware-software integration.
The primary objective of optimizing hardware-software co-design in AI inference accelerators centers on achieving superior performance-per-watt ratios while maintaining flexibility across various AI workloads. This encompasses developing adaptive architectures that can dynamically reconfigure based on specific neural network requirements, implementing efficient memory hierarchies that minimize data movement overhead, and creating software stacks that fully exploit underlying hardware capabilities. Additionally, the objective includes establishing design methodologies that accelerate time-to-market while ensuring scalability across different application domains and deployment scenarios.
Hardware-software co-design has emerged as a pivotal methodology for addressing the performance bottlenecks and efficiency challenges in AI inference systems. Unlike conventional approaches that treat hardware and software as separate entities, co-design methodology integrates both domains from the earliest development stages, enabling optimized system-level solutions that maximize computational efficiency while minimizing power consumption and latency.
The historical development of AI accelerators reveals a progression from repurposed graphics processing units to purpose-built inference engines. Early implementations relied heavily on existing GPU architectures, which, while offering parallel processing capabilities, suffered from inefficiencies due to their graphics-centric design. The recognition of these limitations spurred the development of specialized neural processing units, tensor processing units, and field-programmable gate arrays specifically optimized for AI workloads.
Contemporary AI inference accelerators face multifaceted challenges spanning computational efficiency, memory bandwidth limitations, power constraints, and the need for flexible architectures capable of supporting diverse neural network topologies. The exponential growth in model complexity, exemplified by large language models and computer vision networks, has intensified these challenges, demanding innovative approaches to hardware-software integration.
The primary objective of optimizing hardware-software co-design in AI inference accelerators centers on achieving superior performance-per-watt ratios while maintaining flexibility across various AI workloads. This encompasses developing adaptive architectures that can dynamically reconfigure based on specific neural network requirements, implementing efficient memory hierarchies that minimize data movement overhead, and creating software stacks that fully exploit underlying hardware capabilities. Additionally, the objective includes establishing design methodologies that accelerate time-to-market while ensuring scalability across different application domains and deployment scenarios.
Market Demand for Efficient AI Inference Solutions
The global artificial intelligence market is experiencing unprecedented growth, driven by the increasing adoption of AI applications across diverse industries including autonomous vehicles, healthcare diagnostics, smart manufacturing, and edge computing devices. This surge in AI deployment has created substantial demand for efficient inference solutions that can deliver real-time processing capabilities while maintaining optimal power consumption and cost-effectiveness.
Enterprise applications represent a significant portion of this demand, particularly in data centers where large-scale AI workloads require accelerated inference processing. Cloud service providers are actively seeking hardware-software co-designed solutions that can handle massive concurrent inference requests while minimizing latency and energy consumption. The need for specialized inference accelerators has become critical as traditional general-purpose processors struggle to meet the performance requirements of modern AI applications.
Edge computing environments present another substantial market opportunity, where AI inference must operate under strict power and thermal constraints. Mobile devices, IoT sensors, autonomous vehicles, and industrial automation systems require inference accelerators that can deliver high performance within limited power budgets. The demand for efficient edge AI solutions continues to expand as more applications migrate from cloud-based processing to local inference execution.
The healthcare sector demonstrates particularly strong demand for optimized AI inference solutions, especially in medical imaging and diagnostic applications where real-time processing capabilities are essential. Similarly, the automotive industry's transition toward autonomous driving systems has created substantial requirements for low-latency, high-throughput inference processing that can operate reliably in safety-critical environments.
Financial services and retail industries are increasingly deploying AI inference solutions for fraud detection, algorithmic trading, and personalized recommendation systems. These applications demand inference accelerators capable of processing high-frequency data streams with minimal latency while maintaining consistent performance under varying workload conditions.
The growing emphasis on sustainability and energy efficiency has further intensified market demand for optimized inference solutions. Organizations are actively seeking hardware-software co-designed accelerators that can reduce operational costs through improved energy efficiency while meeting stringent performance requirements. This trend has created opportunities for innovative approaches that balance computational performance with power consumption optimization.
Enterprise applications represent a significant portion of this demand, particularly in data centers where large-scale AI workloads require accelerated inference processing. Cloud service providers are actively seeking hardware-software co-designed solutions that can handle massive concurrent inference requests while minimizing latency and energy consumption. The need for specialized inference accelerators has become critical as traditional general-purpose processors struggle to meet the performance requirements of modern AI applications.
Edge computing environments present another substantial market opportunity, where AI inference must operate under strict power and thermal constraints. Mobile devices, IoT sensors, autonomous vehicles, and industrial automation systems require inference accelerators that can deliver high performance within limited power budgets. The demand for efficient edge AI solutions continues to expand as more applications migrate from cloud-based processing to local inference execution.
The healthcare sector demonstrates particularly strong demand for optimized AI inference solutions, especially in medical imaging and diagnostic applications where real-time processing capabilities are essential. Similarly, the automotive industry's transition toward autonomous driving systems has created substantial requirements for low-latency, high-throughput inference processing that can operate reliably in safety-critical environments.
Financial services and retail industries are increasingly deploying AI inference solutions for fraud detection, algorithmic trading, and personalized recommendation systems. These applications demand inference accelerators capable of processing high-frequency data streams with minimal latency while maintaining consistent performance under varying workload conditions.
The growing emphasis on sustainability and energy efficiency has further intensified market demand for optimized inference solutions. Organizations are actively seeking hardware-software co-designed accelerators that can reduce operational costs through improved energy efficiency while meeting stringent performance requirements. This trend has created opportunities for innovative approaches that balance computational performance with power consumption optimization.
Current State of Hardware-Software Co-Design Challenges
The current landscape of hardware-software co-design in AI inference accelerators faces significant fragmentation across multiple dimensions. Traditional development approaches maintain rigid boundaries between hardware architecture teams and software optimization groups, resulting in suboptimal performance outcomes. This siloed methodology prevents comprehensive system-level optimization and creates substantial inefficiencies in the overall inference pipeline.
Memory hierarchy optimization represents one of the most pressing challenges in contemporary AI accelerator design. Current systems struggle with the complex interplay between on-chip memory constraints, external memory bandwidth limitations, and dynamic workload characteristics. The mismatch between software memory access patterns and hardware memory architecture often leads to substantial performance degradation, particularly in transformer-based models and convolutional neural networks with irregular sparsity patterns.
Compiler infrastructure limitations significantly constrain the effectiveness of hardware-software integration. Existing compilation frameworks frequently fail to fully exploit specialized hardware features such as mixed-precision arithmetic units, custom instruction sets, and advanced dataflow architectures. The gap between high-level model representations and low-level hardware capabilities creates optimization opportunities that remain largely untapped in current commercial solutions.
Power efficiency optimization presents another critical challenge area. While hardware designers focus on architectural power reduction techniques, software developers often lack visibility into real-time power consumption patterns and thermal constraints. This disconnect results in inference solutions that may achieve peak performance but fail to maintain sustained throughput under realistic deployment conditions with strict power budgets.
Scalability issues emerge prominently when transitioning from single-accelerator prototypes to multi-device production systems. Current co-design methodologies inadequately address the complexities of workload distribution, inter-device communication overhead, and dynamic load balancing across heterogeneous accelerator configurations. The lack of unified programming models that seamlessly span hardware boundaries further complicates deployment scenarios.
Verification and validation processes remain fragmented, with hardware verification teams and software testing groups operating independently. This separation creates significant risks of integration failures that only surface during late-stage system testing, substantially increasing development costs and time-to-market delays for AI inference solutions.
Memory hierarchy optimization represents one of the most pressing challenges in contemporary AI accelerator design. Current systems struggle with the complex interplay between on-chip memory constraints, external memory bandwidth limitations, and dynamic workload characteristics. The mismatch between software memory access patterns and hardware memory architecture often leads to substantial performance degradation, particularly in transformer-based models and convolutional neural networks with irregular sparsity patterns.
Compiler infrastructure limitations significantly constrain the effectiveness of hardware-software integration. Existing compilation frameworks frequently fail to fully exploit specialized hardware features such as mixed-precision arithmetic units, custom instruction sets, and advanced dataflow architectures. The gap between high-level model representations and low-level hardware capabilities creates optimization opportunities that remain largely untapped in current commercial solutions.
Power efficiency optimization presents another critical challenge area. While hardware designers focus on architectural power reduction techniques, software developers often lack visibility into real-time power consumption patterns and thermal constraints. This disconnect results in inference solutions that may achieve peak performance but fail to maintain sustained throughput under realistic deployment conditions with strict power budgets.
Scalability issues emerge prominently when transitioning from single-accelerator prototypes to multi-device production systems. Current co-design methodologies inadequately address the complexities of workload distribution, inter-device communication overhead, and dynamic load balancing across heterogeneous accelerator configurations. The lack of unified programming models that seamlessly span hardware boundaries further complicates deployment scenarios.
Verification and validation processes remain fragmented, with hardware verification teams and software testing groups operating independently. This separation creates significant risks of integration failures that only surface during late-stage system testing, substantially increasing development costs and time-to-market delays for AI inference solutions.
Existing Co-Design Methodologies and Frameworks
01 Hardware architecture optimization for AI inference
Specialized hardware architectures designed to optimize AI inference operations through custom processing units, parallel computing structures, and dedicated inference engines. These architectures focus on reducing latency and improving throughput for neural network computations by implementing optimized data paths and computation units specifically tailored for inference workloads.- Hardware architecture optimization for AI inference: Specialized hardware architectures designed to optimize AI inference operations through dedicated processing units, custom silicon designs, and parallel processing capabilities. These architectures focus on reducing latency and improving throughput for neural network computations by implementing purpose-built computational elements and memory hierarchies tailored for inference workloads.
- Memory management and data flow optimization: Advanced memory management techniques and data flow optimization strategies to enhance AI inference performance. These approaches include efficient memory allocation schemes, data prefetching mechanisms, and optimized data movement patterns between different memory levels to minimize bottlenecks and maximize computational efficiency during inference operations.
- Neural network model compression and quantization: Techniques for compressing and quantizing neural network models to reduce computational requirements and memory footprint while maintaining inference accuracy. These methods include weight pruning, bit-width reduction, and model distillation approaches that enable efficient deployment of AI models on resource-constrained accelerator hardware.
- Power efficiency and thermal management: Power optimization strategies and thermal management solutions for AI inference accelerators to achieve energy-efficient operation. These approaches encompass dynamic voltage and frequency scaling, power gating techniques, and thermal-aware scheduling algorithms that balance performance requirements with power consumption constraints in inference hardware systems.
- Software frameworks and compiler optimizations: Software frameworks and compiler optimization techniques specifically designed for AI inference accelerators. These solutions include runtime optimization engines, graph compilation methods, and kernel fusion strategies that automatically optimize neural network execution for target hardware platforms, enabling seamless deployment and maximum utilization of accelerator capabilities.
02 Memory and data management systems for AI acceleration
Advanced memory hierarchies and data management techniques that enhance AI inference performance through optimized data flow, caching strategies, and bandwidth utilization. These systems implement intelligent memory allocation, data prefetching, and storage optimization to minimize memory bottlenecks during inference operations.Expand Specific Solutions03 Software frameworks and compilation techniques
Software optimization methods including compiler technologies, runtime optimization, and framework integration that enhance AI inference efficiency. These approaches focus on code generation, model optimization, and execution scheduling to maximize hardware utilization and minimize computational overhead.Expand Specific Solutions04 Neural network model compression and quantization
Techniques for reducing model size and computational complexity while maintaining inference accuracy through quantization, pruning, and knowledge distillation methods. These approaches enable efficient deployment of AI models on resource-constrained hardware by optimizing model parameters and reducing precision requirements.Expand Specific Solutions05 Edge computing and distributed inference systems
Distributed computing architectures that enable AI inference across edge devices and cloud systems, focusing on load balancing, task distribution, and communication optimization. These systems provide scalable inference solutions by coordinating multiple processing units and managing workload distribution across different computing nodes.Expand Specific Solutions
Key Players in AI Chip and Software Ecosystem
The AI inference accelerator market is experiencing rapid growth driven by increasing demand for edge computing and real-time AI applications across industries. The competitive landscape features established semiconductor giants like Intel, Qualcomm, Samsung Electronics, and IBM competing alongside specialized players such as Tenstorrent and SoyNet. Technology maturity varies significantly across the ecosystem, with Intel and Qualcomm leveraging decades of processor expertise, while companies like Xilinx (now AMD) and Altera pioneered FPGA-based acceleration solutions. Emerging players like Tenstorrent focus on next-generation AI-specific architectures, and Chinese companies including Huawei Cloud and Allwinner Technology are developing regional capabilities. Academic institutions like Princeton University and Peking University contribute foundational research, while the market shows clear segmentation between general-purpose accelerators and domain-specific solutions for automotive and edge applications.
Intel Corp.
Technical Solution: Intel develops comprehensive hardware-software co-design solutions for AI inference through their Intel AI acceleration stack, featuring optimized neural network libraries, compiler optimizations, and custom silicon designs. Their approach integrates Intel Distribution of OpenVINO toolkit with specialized hardware including Neural Processing Units (NPUs) and AI accelerators built into their processors. The co-design methodology focuses on workload-aware optimization, where software algorithms are specifically tuned for underlying hardware architectures, enabling significant performance improvements in inference tasks across edge and datacenter deployments.
Strengths: Mature ecosystem integration, extensive software optimization tools, broad hardware portfolio. Weaknesses: Higher power consumption compared to specialized AI chips, complex optimization requirements.
Xilinx, Inc.
Technical Solution: Xilinx (now part of AMD) pioneered adaptive hardware-software co-design through their FPGA-based AI acceleration platforms, featuring the Versal ACAP (Adaptive Compute Acceleration Platform) with integrated AI Engines. Their co-design methodology enables runtime reconfiguration of hardware accelerators optimized for specific neural network topologies. The Vitis AI development environment provides comprehensive tools for model optimization, quantization, and hardware mapping, allowing developers to achieve optimal performance through hardware-software co-optimization. Their approach supports dynamic adaptation where hardware configurations can be modified based on changing workload requirements during inference.
Strengths: Flexible and reconfigurable architecture, excellent for diverse AI workloads, strong development tools. Weaknesses: Higher complexity in programming, longer development cycles compared to fixed-function accelerators.
Core Innovations in Hardware-Software Optimization
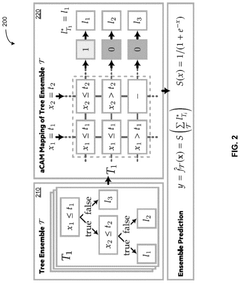
Hardware-software co-design for efficient transformer training and inference
PatentPendingUS20250037028A1
Innovation
- A hardware-software co-design method that generates a computational graph and transformer model using a transformer embedding, simulates training and inference tasks with an accelerator embedding, and optimizes hardware performance and model accuracy using a co-design optimizer to produce a transformer-accelerator or transformer-edge-device pair.
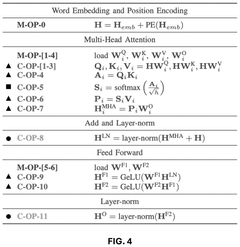
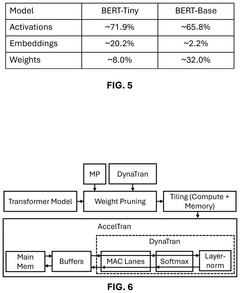
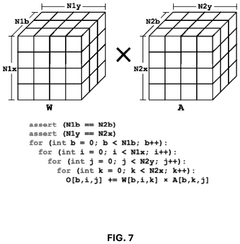
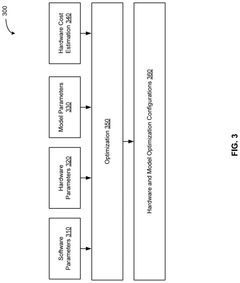
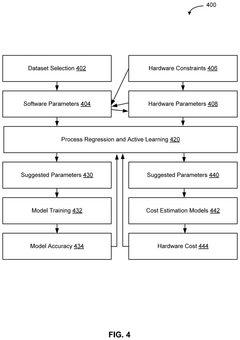
Artificial intelligence (AI) for hardware/software co-design of accelerators and machine learning models
PatentPendingUS20250173604A1
Innovation
- The system employs a hardware and software co-design approach that iteratively determines optimized configurations by co-designing hardware and software elements, using machine learning regression processes with active learning to simulate and evaluate various device configurations, thereby maximizing model accuracy and minimizing hardware costs.
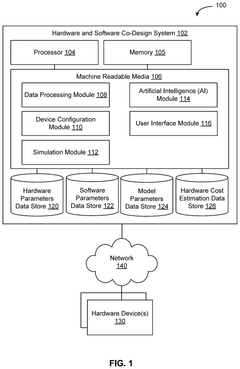
Energy Efficiency Standards for AI Computing Systems
The establishment of comprehensive energy efficiency standards for AI computing systems has become increasingly critical as artificial intelligence workloads continue to proliferate across data centers and edge devices. Current industry initiatives are converging around standardized metrics that can accurately measure and compare energy consumption across different AI inference accelerator architectures, with particular emphasis on performance-per-watt ratios and thermal design power optimization.
Leading standardization bodies including IEEE, ISO, and industry consortiums such as MLPerf have begun developing unified benchmarking frameworks that incorporate energy efficiency as a primary evaluation criterion. These standards focus on establishing baseline measurements for common AI workloads, including computer vision, natural language processing, and recommendation systems, while accounting for varying precision requirements and model complexity factors.
The emerging standards framework emphasizes dynamic power management capabilities, requiring AI accelerators to demonstrate adaptive voltage and frequency scaling based on real-time workload demands. This includes mandatory support for fine-grained power gating, clock domain isolation, and intelligent thermal throttling mechanisms that maintain performance while minimizing energy waste during periods of reduced computational intensity.
Compliance requirements are being structured around tiered certification levels, with basic standards focusing on static power consumption measurements and advanced tiers incorporating sophisticated metrics such as energy proportionality, idle power efficiency, and workload-specific optimization capabilities. These standards mandate comprehensive reporting of power consumption across different operational modes, including inference latency variations and batch processing scenarios.
Future regulatory developments are expected to introduce mandatory energy efficiency disclosures for AI computing systems deployed in enterprise environments, similar to existing requirements for traditional server hardware. This regulatory push is driving accelerator manufacturers to prioritize energy-aware design methodologies and implement hardware-level power monitoring capabilities that enable real-time energy optimization and compliance verification across diverse deployment scenarios.
Leading standardization bodies including IEEE, ISO, and industry consortiums such as MLPerf have begun developing unified benchmarking frameworks that incorporate energy efficiency as a primary evaluation criterion. These standards focus on establishing baseline measurements for common AI workloads, including computer vision, natural language processing, and recommendation systems, while accounting for varying precision requirements and model complexity factors.
The emerging standards framework emphasizes dynamic power management capabilities, requiring AI accelerators to demonstrate adaptive voltage and frequency scaling based on real-time workload demands. This includes mandatory support for fine-grained power gating, clock domain isolation, and intelligent thermal throttling mechanisms that maintain performance while minimizing energy waste during periods of reduced computational intensity.
Compliance requirements are being structured around tiered certification levels, with basic standards focusing on static power consumption measurements and advanced tiers incorporating sophisticated metrics such as energy proportionality, idle power efficiency, and workload-specific optimization capabilities. These standards mandate comprehensive reporting of power consumption across different operational modes, including inference latency variations and batch processing scenarios.
Future regulatory developments are expected to introduce mandatory energy efficiency disclosures for AI computing systems deployed in enterprise environments, similar to existing requirements for traditional server hardware. This regulatory push is driving accelerator manufacturers to prioritize energy-aware design methodologies and implement hardware-level power monitoring capabilities that enable real-time energy optimization and compliance verification across diverse deployment scenarios.
Performance Benchmarking for AI Inference Platforms
Performance benchmarking for AI inference platforms represents a critical evaluation framework that enables systematic assessment of hardware-software co-design effectiveness in accelerator systems. The benchmarking process encompasses multiple dimensions including computational throughput, latency characteristics, energy efficiency, and resource utilization patterns across diverse neural network architectures and deployment scenarios.
Standardized benchmarking suites such as MLPerf Inference have emerged as industry-accepted evaluation protocols, providing consistent metrics for comparing different accelerator platforms. These frameworks evaluate performance across representative workloads including image classification, object detection, natural language processing, and recommendation systems, ensuring comprehensive coverage of real-world AI applications.
Latency measurement constitutes a fundamental aspect of inference benchmarking, particularly for edge computing applications where real-time response requirements are stringent. Single-inference latency, batch processing throughput, and tail latency distributions provide insights into system responsiveness under varying load conditions. Advanced benchmarking methodologies incorporate dynamic workload patterns that simulate production environments with fluctuating inference demands.
Energy efficiency metrics have gained prominence as sustainability concerns and operational costs drive optimization priorities. Performance-per-watt measurements enable evaluation of accelerator designs across different power envelopes, from ultra-low-power edge devices to high-performance datacenter deployments. Thermal characteristics and power scaling behaviors under sustained workloads provide additional dimensions for comprehensive platform assessment.
Memory subsystem performance evaluation reveals critical bottlenecks in AI inference pipelines. Benchmarking frameworks assess memory bandwidth utilization, cache efficiency, and data movement patterns that significantly impact overall system performance. These metrics illuminate the effectiveness of hardware-software co-design decisions regarding memory hierarchy optimization and data flow management.
Precision and accuracy preservation during inference acceleration represents another crucial benchmarking dimension. Quantization effects, numerical precision impacts, and model accuracy degradation under various optimization strategies require systematic evaluation to ensure deployment viability while maintaining acceptable performance standards.
Standardized benchmarking suites such as MLPerf Inference have emerged as industry-accepted evaluation protocols, providing consistent metrics for comparing different accelerator platforms. These frameworks evaluate performance across representative workloads including image classification, object detection, natural language processing, and recommendation systems, ensuring comprehensive coverage of real-world AI applications.
Latency measurement constitutes a fundamental aspect of inference benchmarking, particularly for edge computing applications where real-time response requirements are stringent. Single-inference latency, batch processing throughput, and tail latency distributions provide insights into system responsiveness under varying load conditions. Advanced benchmarking methodologies incorporate dynamic workload patterns that simulate production environments with fluctuating inference demands.
Energy efficiency metrics have gained prominence as sustainability concerns and operational costs drive optimization priorities. Performance-per-watt measurements enable evaluation of accelerator designs across different power envelopes, from ultra-low-power edge devices to high-performance datacenter deployments. Thermal characteristics and power scaling behaviors under sustained workloads provide additional dimensions for comprehensive platform assessment.
Memory subsystem performance evaluation reveals critical bottlenecks in AI inference pipelines. Benchmarking frameworks assess memory bandwidth utilization, cache efficiency, and data movement patterns that significantly impact overall system performance. These metrics illuminate the effectiveness of hardware-software co-design decisions regarding memory hierarchy optimization and data flow management.
Precision and accuracy preservation during inference acceleration represents another crucial benchmarking dimension. Quantization effects, numerical precision impacts, and model accuracy degradation under various optimization strategies require systematic evaluation to ensure deployment viability while maintaining acceptable performance standards.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!