

Quantum Computing Enhancements in Vision-Language-Action Models
APR 22, 20266 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Quantum VLA Model Background and Technical Objectives
Vision-Language-Action (VLA) models represent a convergence of computer vision, natural language processing, and robotic control systems, enabling machines to perceive visual environments, understand linguistic instructions, and execute appropriate physical actions. These multimodal AI systems have emerged as critical components in autonomous robotics, embodied AI, and human-robot interaction applications. The integration of quantum computing principles into VLA architectures presents unprecedented opportunities to overcome computational bottlenecks that have historically limited the scalability and real-time performance of these complex systems.
The evolution of VLA models traces back to early attempts at connecting perception with action in the 1980s, progressing through symbolic AI approaches, statistical learning methods, and contemporary deep learning frameworks. Traditional VLA implementations face significant computational challenges due to the exponential growth of parameter spaces when processing high-dimensional visual data, complex linguistic structures, and continuous action spaces simultaneously. Current state-of-the-art models require substantial computational resources, often limiting their deployment to cloud-based infrastructures rather than edge devices where real-time responsiveness is crucial.
Quantum computing introduces fundamentally different computational paradigms that could revolutionize VLA model architectures. Quantum superposition enables simultaneous exploration of multiple solution paths, while quantum entanglement facilitates novel approaches to feature correlation across modalities. Quantum parallelism offers exponential speedup potential for specific computational tasks inherent in multimodal processing, particularly in optimization problems related to attention mechanisms and cross-modal alignment.
The primary technical objective involves developing quantum-enhanced VLA architectures that leverage quantum algorithms for improved computational efficiency in multimodal feature extraction, representation learning, and action planning. Specific goals include implementing quantum attention mechanisms that can process visual-linguistic correlations more efficiently than classical approaches, developing quantum optimization algorithms for real-time action selection, and creating hybrid quantum-classical frameworks that maintain compatibility with existing robotic systems while providing quantum advantages where most beneficial.
Another critical objective focuses on addressing the scalability challenges in VLA models through quantum machine learning techniques. This includes exploring quantum neural networks for multimodal representation learning, investigating quantum reinforcement learning algorithms for action policy optimization, and developing quantum error correction methods specifically tailored for noisy intermediate-scale quantum devices operating in real-world robotic environments.
The integration aims to achieve significant improvements in processing speed, energy efficiency, and model capacity while maintaining or enhancing the accuracy and reliability of vision-language-action tasks across diverse application domains.
The evolution of VLA models traces back to early attempts at connecting perception with action in the 1980s, progressing through symbolic AI approaches, statistical learning methods, and contemporary deep learning frameworks. Traditional VLA implementations face significant computational challenges due to the exponential growth of parameter spaces when processing high-dimensional visual data, complex linguistic structures, and continuous action spaces simultaneously. Current state-of-the-art models require substantial computational resources, often limiting their deployment to cloud-based infrastructures rather than edge devices where real-time responsiveness is crucial.
Quantum computing introduces fundamentally different computational paradigms that could revolutionize VLA model architectures. Quantum superposition enables simultaneous exploration of multiple solution paths, while quantum entanglement facilitates novel approaches to feature correlation across modalities. Quantum parallelism offers exponential speedup potential for specific computational tasks inherent in multimodal processing, particularly in optimization problems related to attention mechanisms and cross-modal alignment.
The primary technical objective involves developing quantum-enhanced VLA architectures that leverage quantum algorithms for improved computational efficiency in multimodal feature extraction, representation learning, and action planning. Specific goals include implementing quantum attention mechanisms that can process visual-linguistic correlations more efficiently than classical approaches, developing quantum optimization algorithms for real-time action selection, and creating hybrid quantum-classical frameworks that maintain compatibility with existing robotic systems while providing quantum advantages where most beneficial.
Another critical objective focuses on addressing the scalability challenges in VLA models through quantum machine learning techniques. This includes exploring quantum neural networks for multimodal representation learning, investigating quantum reinforcement learning algorithms for action policy optimization, and developing quantum error correction methods specifically tailored for noisy intermediate-scale quantum devices operating in real-world robotic environments.
The integration aims to achieve significant improvements in processing speed, energy efficiency, and model capacity while maintaining or enhancing the accuracy and reliability of vision-language-action tasks across diverse application domains.
Market Demand for Quantum-Enhanced Multimodal AI Systems
The convergence of quantum computing and multimodal AI systems represents a transformative opportunity across multiple industry sectors. Enterprise demand for quantum-enhanced vision-language-action models is primarily driven by the exponential growth in data complexity and the limitations of classical computing architectures in processing multimodal information streams simultaneously.
Financial services institutions demonstrate significant interest in quantum-enhanced multimodal AI for real-time fraud detection and risk assessment. These systems can process visual transaction patterns, natural language communications, and behavioral data concurrently, offering unprecedented analytical capabilities that traditional systems cannot match. The ability to handle quantum superposition states enables parallel processing of multiple decision pathways simultaneously.
Healthcare organizations represent another critical market segment, particularly in medical imaging and diagnostic applications. Quantum-enhanced vision-language-action models can simultaneously analyze medical images, interpret clinical notes, and recommend treatment actions with quantum-accelerated pattern recognition capabilities. The potential for quantum algorithms to identify subtle correlations across multimodal medical data creates substantial value propositions for healthcare providers.
Autonomous systems development, including robotics and self-driving vehicles, constitutes a rapidly expanding market for quantum-enhanced multimodal AI. These applications require real-time integration of visual perception, natural language understanding, and action planning. Quantum computing's inherent parallelism offers significant advantages in processing the massive data streams required for autonomous decision-making in complex environments.
Manufacturing and industrial automation sectors show increasing demand for quantum-enhanced systems capable of integrating visual quality control, natural language maintenance reports, and automated corrective actions. The quantum advantage becomes particularly evident in optimization problems involving multiple variables and constraints across different data modalities.
The enterprise software market increasingly seeks quantum-enhanced solutions for customer service applications, where systems must simultaneously process visual inputs, understand natural language queries, and execute appropriate responses. Early adopters recognize the competitive advantages of quantum-accelerated multimodal processing capabilities.
Market barriers include the current limited availability of quantum hardware and the specialized expertise required for implementation. However, cloud-based quantum computing services are gradually reducing these barriers, making quantum-enhanced multimodal AI more accessible to enterprises across various sectors.
Financial services institutions demonstrate significant interest in quantum-enhanced multimodal AI for real-time fraud detection and risk assessment. These systems can process visual transaction patterns, natural language communications, and behavioral data concurrently, offering unprecedented analytical capabilities that traditional systems cannot match. The ability to handle quantum superposition states enables parallel processing of multiple decision pathways simultaneously.
Healthcare organizations represent another critical market segment, particularly in medical imaging and diagnostic applications. Quantum-enhanced vision-language-action models can simultaneously analyze medical images, interpret clinical notes, and recommend treatment actions with quantum-accelerated pattern recognition capabilities. The potential for quantum algorithms to identify subtle correlations across multimodal medical data creates substantial value propositions for healthcare providers.
Autonomous systems development, including robotics and self-driving vehicles, constitutes a rapidly expanding market for quantum-enhanced multimodal AI. These applications require real-time integration of visual perception, natural language understanding, and action planning. Quantum computing's inherent parallelism offers significant advantages in processing the massive data streams required for autonomous decision-making in complex environments.
Manufacturing and industrial automation sectors show increasing demand for quantum-enhanced systems capable of integrating visual quality control, natural language maintenance reports, and automated corrective actions. The quantum advantage becomes particularly evident in optimization problems involving multiple variables and constraints across different data modalities.
The enterprise software market increasingly seeks quantum-enhanced solutions for customer service applications, where systems must simultaneously process visual inputs, understand natural language queries, and execute appropriate responses. Early adopters recognize the competitive advantages of quantum-accelerated multimodal processing capabilities.
Market barriers include the current limited availability of quantum hardware and the specialized expertise required for implementation. However, cloud-based quantum computing services are gradually reducing these barriers, making quantum-enhanced multimodal AI more accessible to enterprises across various sectors.
Current State of Quantum Computing in VLA Applications
The integration of quantum computing principles into Vision-Language-Action (VLA) models represents an emerging frontier that remains largely in the experimental and theoretical exploration phase. Current quantum computing applications in VLA systems are primarily concentrated in research laboratories and academic institutions, with limited practical deployments due to the nascent state of quantum hardware and the complexity of quantum-classical hybrid architectures.
Quantum-enhanced computer vision components have shown the most promising early developments within VLA frameworks. Several research groups have demonstrated quantum convolutional neural networks (QCNNs) that leverage quantum superposition and entanglement to process visual information with potentially exponential speedups for specific pattern recognition tasks. These quantum vision modules have been tested on small-scale image classification problems, achieving comparable accuracy to classical counterparts while theoretically offering advantages in processing high-dimensional visual data.
Natural language processing components in VLA models have seen limited quantum integration, primarily focusing on quantum-inspired algorithms rather than true quantum implementations. Quantum natural language processing research has explored quantum word embeddings and quantum attention mechanisms, but these approaches remain computationally constrained by current quantum hardware limitations. The quantum advantage in language processing is still largely theoretical, with most implementations running on quantum simulators rather than actual quantum devices.
Action planning and decision-making modules represent the most challenging area for quantum integration in VLA systems. Current quantum reinforcement learning algorithms show promise for optimization problems inherent in action selection, but scalability issues persist. Quantum approximate optimization algorithms (QAOA) have been applied to simple robotic path planning scenarios, demonstrating potential advantages in exploring solution spaces more efficiently than classical methods.
The primary technical constraints limiting widespread quantum VLA adoption include quantum decoherence, limited qubit counts in current quantum processors, and the significant overhead required for quantum error correction. Most current implementations operate on noisy intermediate-scale quantum (NISQ) devices with fewer than 100 qubits, severely restricting the complexity of VLA tasks that can be addressed. Additionally, the quantum-classical interface introduces latency issues that complicate real-time VLA applications.
Despite these limitations, hybrid quantum-classical approaches are gaining traction, where quantum processors handle specific computational bottlenecks while classical systems manage the overall VLA pipeline. This hybrid paradigm represents the most viable near-term path for quantum-enhanced VLA systems, allowing researchers to explore quantum advantages in targeted components while maintaining system practicality and performance requirements.
Quantum-enhanced computer vision components have shown the most promising early developments within VLA frameworks. Several research groups have demonstrated quantum convolutional neural networks (QCNNs) that leverage quantum superposition and entanglement to process visual information with potentially exponential speedups for specific pattern recognition tasks. These quantum vision modules have been tested on small-scale image classification problems, achieving comparable accuracy to classical counterparts while theoretically offering advantages in processing high-dimensional visual data.
Natural language processing components in VLA models have seen limited quantum integration, primarily focusing on quantum-inspired algorithms rather than true quantum implementations. Quantum natural language processing research has explored quantum word embeddings and quantum attention mechanisms, but these approaches remain computationally constrained by current quantum hardware limitations. The quantum advantage in language processing is still largely theoretical, with most implementations running on quantum simulators rather than actual quantum devices.
Action planning and decision-making modules represent the most challenging area for quantum integration in VLA systems. Current quantum reinforcement learning algorithms show promise for optimization problems inherent in action selection, but scalability issues persist. Quantum approximate optimization algorithms (QAOA) have been applied to simple robotic path planning scenarios, demonstrating potential advantages in exploring solution spaces more efficiently than classical methods.
The primary technical constraints limiting widespread quantum VLA adoption include quantum decoherence, limited qubit counts in current quantum processors, and the significant overhead required for quantum error correction. Most current implementations operate on noisy intermediate-scale quantum (NISQ) devices with fewer than 100 qubits, severely restricting the complexity of VLA tasks that can be addressed. Additionally, the quantum-classical interface introduces latency issues that complicate real-time VLA applications.
Despite these limitations, hybrid quantum-classical approaches are gaining traction, where quantum processors handle specific computational bottlenecks while classical systems manage the overall VLA pipeline. This hybrid paradigm represents the most viable near-term path for quantum-enhanced VLA systems, allowing researchers to explore quantum advantages in targeted components while maintaining system practicality and performance requirements.
Existing Quantum Enhancement Solutions for VLA Models
01 Multi-modal data fusion and integration techniques
Vision-Language-Action models can be enhanced through advanced multi-modal data fusion techniques that effectively integrate visual, linguistic, and action-related information. These approaches employ sophisticated neural network architectures to align and combine different modalities, enabling better understanding of complex relationships between visual scenes, language descriptions, and corresponding actions. The fusion mechanisms utilize attention mechanisms and cross-modal learning strategies to improve the model's ability to process and interpret multi-modal inputs simultaneously.- Multi-modal fusion architectures for vision-language-action integration: Advanced neural network architectures that integrate visual, linguistic, and action modalities through attention mechanisms and cross-modal fusion layers. These architectures enable better alignment between visual observations, language instructions, and robotic actions by learning joint representations across modalities. The fusion approaches include transformer-based encoders, cross-attention modules, and hierarchical feature extraction to capture complex relationships between vision, language, and action spaces.
- Pre-training strategies using large-scale multi-modal datasets: Methods for pre-training vision-language-action models on extensive datasets containing paired visual observations, natural language descriptions, and action sequences. These strategies leverage self-supervised learning, contrastive learning, and masked prediction tasks to learn generalizable representations. The pre-training phase enables models to acquire foundational knowledge about visual-linguistic-action correlations before fine-tuning on specific downstream tasks, significantly improving performance and sample efficiency.
- Action prediction and planning with language-conditioned policies: Techniques for generating and executing action sequences conditioned on natural language instructions and visual inputs. These methods employ policy networks that decode language embeddings and visual features into executable action primitives. The approaches include hierarchical planning, goal-conditioned reinforcement learning, and temporal action segmentation to enable robots to perform complex tasks specified through natural language while adapting to dynamic visual environments.
- Attention mechanisms for visual grounding and action localization: Specialized attention modules that establish precise correspondences between language tokens, visual regions, and action parameters. These mechanisms enable models to ground linguistic references in visual observations and identify relevant spatial locations for action execution. The techniques include spatial attention maps, object-centric attention, and temporal attention for tracking action-relevant features across video frames, improving the accuracy of vision-language-action alignment.
- Transfer learning and domain adaptation for robotic manipulation: Methods for adapting pre-trained vision-language-action models to new robotic platforms, environments, and task domains. These approaches address distribution shifts between training and deployment scenarios through techniques such as domain randomization, adversarial adaptation, and meta-learning. The transfer learning strategies enable models to generalize across different robot morphologies, object categories, and environmental conditions while maintaining high performance with minimal additional training data.
02 Transformer-based architecture optimization
Performance enhancement can be achieved through optimized transformer architectures specifically designed for vision-language-action tasks. These architectures incorporate specialized attention mechanisms, efficient token processing methods, and improved positional encoding schemes. The optimization focuses on reducing computational complexity while maintaining or improving accuracy, enabling faster inference times and better scalability for real-world applications.Expand Specific Solutions03 Pre-training and transfer learning strategies
Enhanced performance is obtained through sophisticated pre-training methodologies and transfer learning approaches that leverage large-scale datasets across multiple domains. These strategies involve self-supervised learning techniques, contrastive learning methods, and domain adaptation mechanisms that enable models to learn robust representations. The pre-training phase helps models develop generalizable features that can be fine-tuned for specific downstream tasks with improved efficiency and accuracy.Expand Specific Solutions04 Action prediction and planning mechanisms
Vision-Language-Action models benefit from advanced action prediction and planning mechanisms that bridge the gap between perception and execution. These mechanisms incorporate temporal reasoning, sequential decision-making frameworks, and reinforcement learning techniques to generate appropriate actions based on visual and linguistic inputs. The systems utilize policy networks and value functions to optimize action selection and improve task completion rates in dynamic environments.Expand Specific Solutions05 Computational efficiency and model compression
Performance enhancement includes techniques for improving computational efficiency through model compression, quantization, and pruning methods. These approaches reduce model size and inference time while preserving accuracy, making deployment feasible on resource-constrained devices. The optimization strategies include knowledge distillation, neural architecture search, and efficient parameter sharing schemes that balance performance with computational requirements.Expand Specific Solutions
Key Players in Quantum AI and VLA Model Development
The quantum computing enhancements in vision-language-action models represent an emerging technological frontier currently in its nascent stage. The market remains relatively small but shows significant growth potential as quantum computing capabilities mature. Technology maturity varies considerably across the competitive landscape, with established tech giants like Google LLC, IBM, Microsoft, and NVIDIA leading quantum hardware and software development, while specialized quantum companies such as Zapata Computing, Quantinuum, and Kipu Quantum focus on application-specific solutions. Academic institutions including MIT, Xiamen University, and Tongji University contribute foundational research, while traditional hardware manufacturers like Samsung Electronics and Qualcomm explore quantum integration opportunities. The convergence of quantum computing with multimodal AI represents a highly experimental phase, with most practical applications still years away from commercial viability, though the competitive positioning is intensifying rapidly.
Google LLC
Technical Solution: Google has developed quantum-enhanced vision-language-action models through their Quantum AI division, integrating quantum computing principles with multimodal AI systems. Their approach leverages quantum superposition and entanglement to process visual, textual, and action data simultaneously, enabling more efficient representation learning across modalities. The company utilizes quantum neural networks (QNNs) to enhance feature extraction from visual inputs while maintaining semantic understanding through quantum-classical hybrid architectures. Their quantum advantage becomes apparent in handling high-dimensional state spaces common in robotics applications, where traditional classical methods face exponential scaling challenges. Google's implementation focuses on quantum variational circuits that can adapt to different action spaces while preserving the contextual relationships between vision and language components.
Strengths: Leading quantum hardware infrastructure, extensive research resources, strong integration capabilities across AI modalities. Weaknesses: High computational overhead, limited scalability on current quantum hardware, requires specialized quantum programming expertise.
International Business Machines Corp.
Technical Solution: IBM's quantum computing approach to vision-language-action models centers on their Qiskit framework and quantum processors. They have developed quantum machine learning algorithms that enhance the representational capacity of multimodal models by exploiting quantum parallelism for simultaneous processing of visual features, natural language tokens, and action embeddings. Their quantum advantage lies in the ability to encode exponentially large feature spaces in polynomial quantum resources, particularly beneficial for complex robotic tasks requiring real-time decision making. IBM's implementation uses quantum variational algorithms combined with classical neural networks, creating hybrid systems that can learn more efficient mappings between visual observations, language instructions, and appropriate actions. The company focuses on near-term quantum applications using their NISQ (Noisy Intermediate-Scale Quantum) devices to demonstrate practical advantages in specific vision-language-action scenarios.
Strengths: Mature quantum hardware platform, comprehensive quantum software ecosystem, strong enterprise partnerships. Weaknesses: Current quantum processors have limited qubit counts, noise interference affects model performance, requires significant classical preprocessing.
Core Quantum Algorithms for Vision-Language-Action Integration
Accelerated learning in neural networks incorporating quantum unitary noise and quantum stochastic rounding using silicon based quantum dot arrays
PatentWO2022101813A1
Innovation
- The introduction of unitary quantum noise generated by silicon-based quantum dot arrays to accelerate neural network learning, enabling faster training and inference through quantum stochastic rounding, which reduces the computational intensity and energy requirements while improving training accuracy.
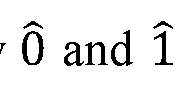
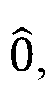
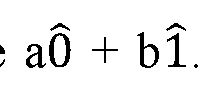
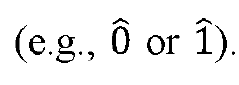
System and method for improving the efficiency of inputs to quantum computational devices
PatentPendingUS20240104412A1
Innovation
- Development of quantum foundation models, pretrained on general quantum computational tasks and calibration data from a family of quantum devices using classical processes and simulators, allowing for increased model parameters and training data, and fine-tuning for specific tasks to generate efficient inputs like quantum circuits or microwave pulses.



Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!