Federated Learning Challenges: Dealing with Non-IID Network Data
JUL 14, 2025 |
Understanding Federated Learning and Its Appeal
Federated learning has emerged as a promising approach in the field of machine learning, primarily due to its capability to train models across multiple decentralized devices without needing to transfer local data to a central server. This approach not only enhances privacy but also reduces bandwidth usage, making it an attractive solution for organizations that handle sensitive data. However, despite its advantages, federated learning also comes with a set of unique challenges, especially when dealing with non-Independently and Identically Distributed (non-IID) network data.
The Nature of Non-IID Data in Federated Learning
In traditional machine learning, the assumption is often that data is IID, meaning that each data point is generated independently from the same probability distribution. However, this assumption rarely holds in federated learning environments. Devices in a federated network tend to collect data that is inherently different due to varying factors such as geographical location, user preferences, and device-specific usage patterns. This results in non-IID data distributions, which can significantly impact the performance and convergence of federated learning models.
Challenges Posed by Non-IID Data
Non-IID data presents several challenges in federated learning, making it a complex task to ensure model accuracy and reliability.
1. Model Convergence Issues
One of the primary challenges with non-IID data is achieving model convergence. In federated learning, the model's global aggregation heavily relies on averaging updates from local models trained on different devices. When data is non-IID, these local updates can be highly diverse, leading to slower convergence or even divergence of the global model.
2. Fairness and Bias
Non-IID data can also introduce fairness and bias issues in federated learning models. If certain demographic groups are overrepresented or underrepresented in the data collected by different devices, it can lead to biased model predictions. Ensuring fairness across diverse populations becomes a daunting task, requiring careful calibration and adjustment of model parameters.
3. Communication Overhead
The presence of non-IID data often necessitates additional rounds of communication between devices and the central server to achieve acceptable model performance. This not only increases the communication overhead but also extends training time, which can be particularly challenging in environments with limited connectivity.
Approaches to Mitigate Non-IID Challenges
To address the challenges posed by non-IID data, researchers and practitioners have proposed several strategies that aim to enhance the robustness of federated learning systems.
1. Personalization Techniques
One approach to tackling non-IID data is through personalization techniques. By customizing models to better fit the unique data distributions present on individual devices, it is possible to improve overall model performance and user satisfaction. This can be achieved through approaches like multi-task learning or meta-learning, which allow for more adaptive models.
2. Data Augmentation and Regularization
Employing data augmentation and regularization techniques can also help mitigate the effects of non-IID data. By artificially increasing the diversity of data through augmentation or introducing regularization terms that penalize large discrepancies in model updates, it is possible to enhance model generalization across diverse data sources.
3. Federated Averaging Algorithms
Advanced federated averaging algorithms have been developed to address non-IID data issues. These algorithms incorporate techniques such as weighted averaging, where more importance is given to updates from devices with more representative data, or introducing momentum terms to stabilize convergence.
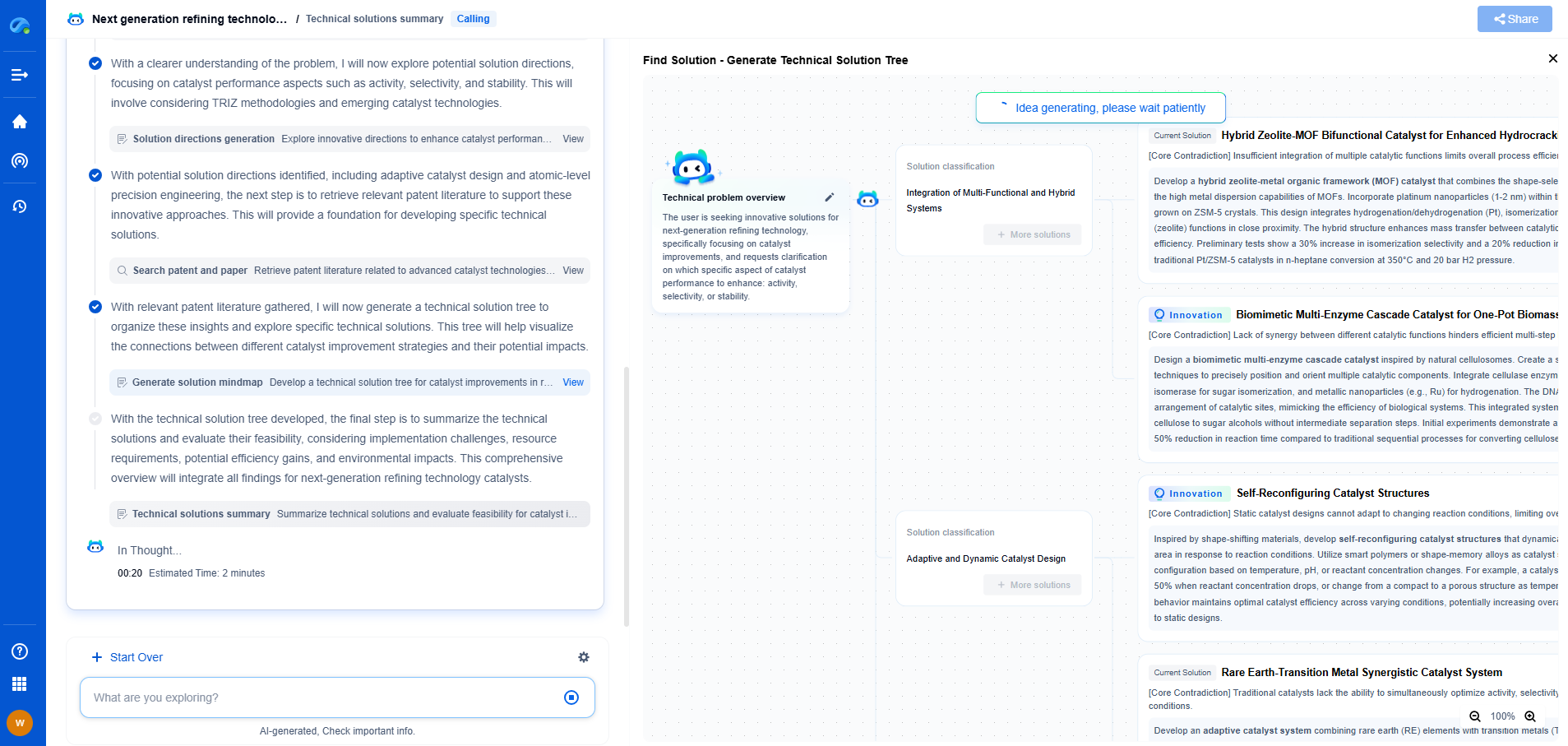
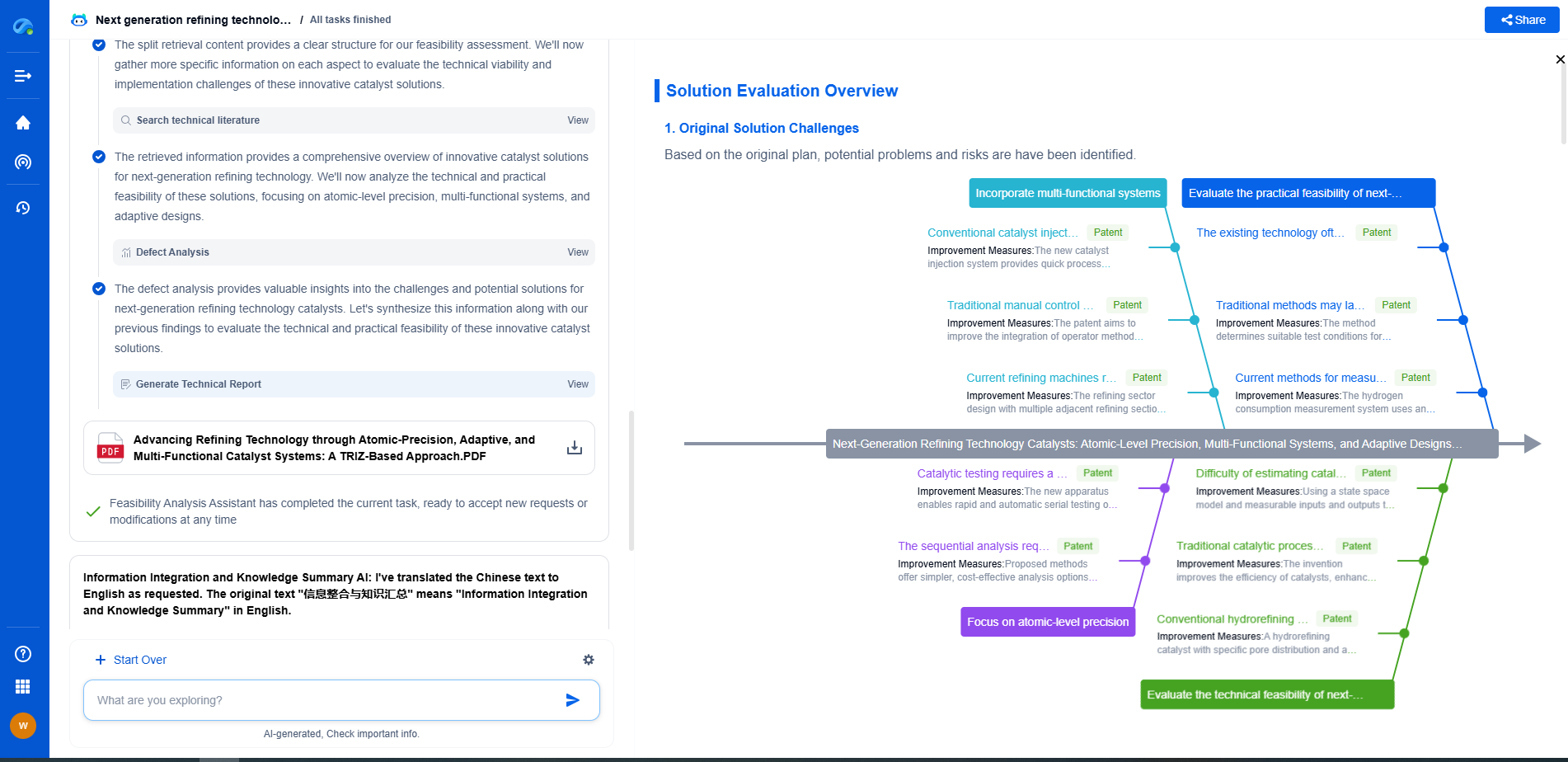
Conclusion: A Path Forward
Dealing with non-IID data in federated learning is undoubtedly challenging, but it is not insurmountable. By adopting a combination of personalized models, data augmentation techniques, and advanced aggregation algorithms, it is possible to navigate the complexities of non-IID data. As federated learning continues to evolve, ongoing research and innovation are essential to fully harness its potential while ensuring fairness, efficiency, and privacy. The path forward involves a concerted effort from the machine learning community to refine these strategies and develop new solutions that can handle the diverse realities of real-world data.
From 5G NR to SDN and quantum-safe encryption, the digital communication landscape is evolving faster than ever. For R&D teams and IP professionals, tracking protocol shifts, understanding standards like 3GPP and IEEE 802, and monitoring the global patent race are now mission-critical.
Patsnap Eureka, our intelligent AI assistant built for R&D professionals in high-tech sectors, empowers you with real-time expert-level analysis, technology roadmap exploration, and strategic mapping of core patents—all within a seamless, user-friendly interface.
📡 Experience Patsnap Eureka today and unlock next-gen insights into digital communication infrastructure, before your competitors do.