How Reinforcement Learning Algorithms Adapt to Unseen Formation Changes
JUN 20, 2025 |
Reinforcement learning (RL) is a fascinating domain within machine learning where agents learn to make decisions by interacting with an environment to maximize cumulative rewards. Unlike supervised learning, where models learn from a set of labeled data, RL algorithms learn through trial and error, receiving feedback from their actions in the form of rewards or penalties. This makes RL particularly suited to dynamic and complex situations, where the optimal course of action is not immediately clear. One of the critical challenges in RL is adapting to changes in the environment, especially when those changes are entirely unseen or unexpected.
Understanding Formation Changes
In many real-world applications, RL agents operate within environments that undergo formation changes. These changes might occur due to external factors, such as shifts in market conditions for finance-related algorithms, changes in opponent strategies for gaming applications, or variations in environmental conditions for robotics or autonomous vehicles. Formation changes can be thought of as any alteration in the underlying structure or dynamics of the environment that the agent must adapt to. The ability to handle such changes is crucial for the robustness and reliability of RL systems.
Adaptive Mechanisms in RL
Adapting to unseen formation changes requires RL algorithms to have mechanisms that allow for flexibility and resilience. Several strategies and techniques can be employed to enhance the adaptability of RL algorithms:
1. Transfer Learning in RL
Transfer learning involves leveraging knowledge gained in one task to improve learning in another, related task. In the context of RL, transfer learning can help agents adapt to formation changes by utilizing the knowledge from previous experiences. Techniques like model-based transfer, where agents use a model of the environment to predict outcomes, can be highly effective in adapting to new situations quickly.
2. Meta-Learning Approaches
Meta-learning, or "learning to learn," focuses on creating models that can adapt rapidly to new tasks by optimizing their learning process. This approach is particularly beneficial in environments with frequent or drastic formation changes. Meta-learning enables RL agents to adjust their learning strategies based on the new information, allowing them to quickly recalibrate their actions.
3. Environment Modeling
For RL algorithms to adapt effectively, they must have a robust understanding of their environment. Techniques such as environment modeling allow agents to construct internal representations of the environment, which can be updated as new information becomes available. This helps the agent anticipate changes and adjust its strategy accordingly.
4. Exploration Strategies
Effective exploration strategies are essential for RL agents to adapt to unseen changes. By employing techniques such as curiosity-driven learning or adaptive exploration, agents can continuously seek out new information, ensuring they remain well-informed about any alterations in the environment. This proactive approach allows agents to anticipate changes rather than merely react to them.
Challenges in Adapting to Formation Changes
Despite the advancements in adaptive mechanisms, several challenges remain in making RL algorithms resilient to unseen formation changes. One of the main challenges is the balance between exploration and exploitation. Over-exploration can lead to inefficiencies, while under-exploration can result in missing critical information about environmental changes. Additionally, managing the trade-off between stability and adaptability is crucial; while agents must be flexible enough to handle new situations, they also need to maintain stability to avoid erratic behaviors.
Applications in Real-World Scenarios
The ability of RL algorithms to adapt to formation changes has significant implications for various industries. In finance, RL models can adjust to market fluctuations, making them valuable for trading strategies. In autonomous systems, such as self-driving cars, RL algorithms can adapt to changing road conditions and traffic patterns. In healthcare, RL can assist in personalized treatment plans by adjusting to patient responses and new medical insights.
Conclusion
Reinforcement learning offers a powerful framework for developing intelligent systems that can operate effectively in dynamic environments. By incorporating adaptive mechanisms, RL algorithms can handle unseen formation changes more effectively, ensuring their reliability and robustness in real-world applications. As research continues, the development of increasingly sophisticated adaptation strategies will undoubtedly enhance the capabilities of RL systems, opening new possibilities across various fields.
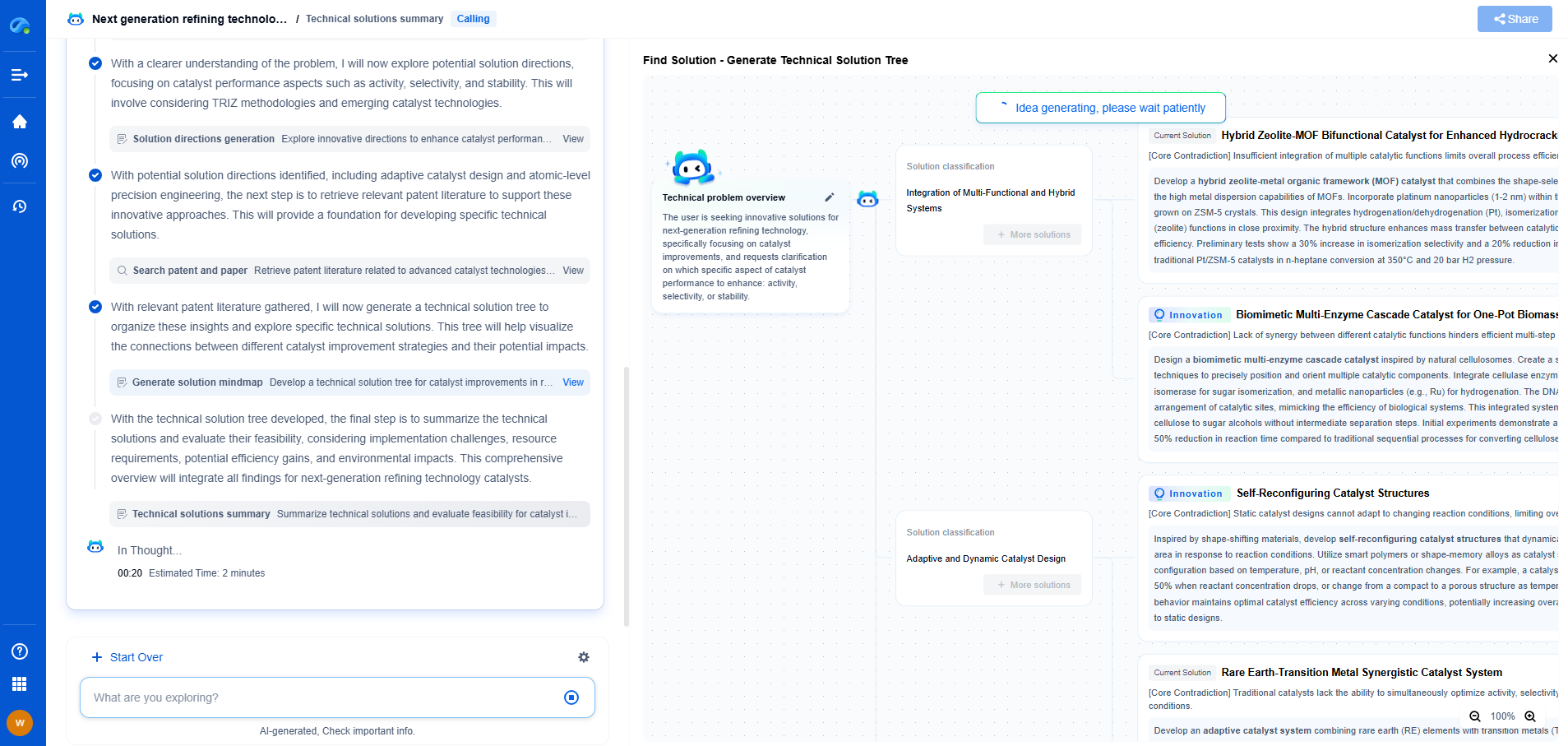
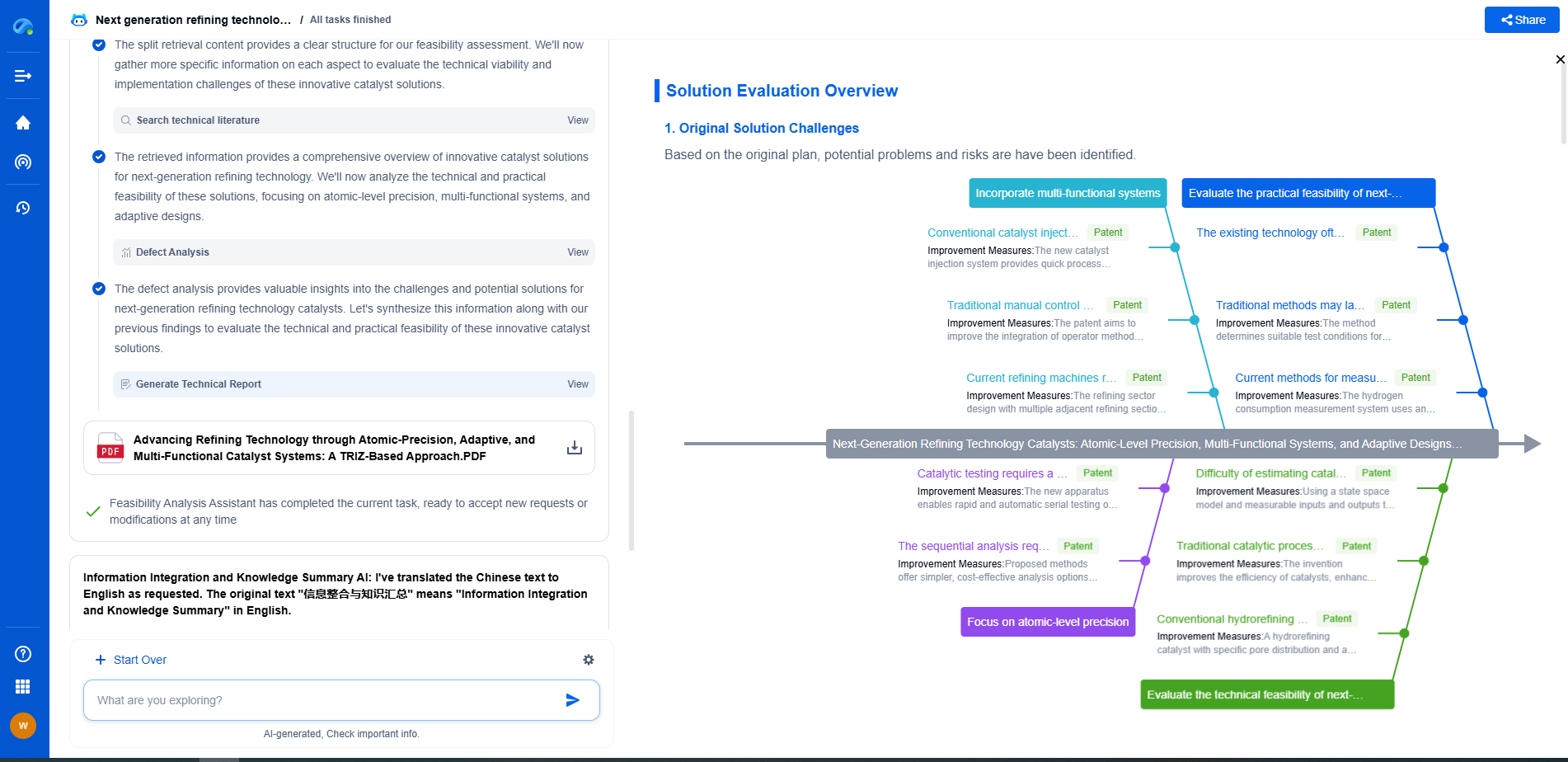
Navigating the Complexities of Drilling Innovation? Let AI Do the Heavy Lifting
In an industry where subsurface conditions, materials science, and drilling dynamics evolve rapidly, staying ahead of technical innovation and protecting your intellectual property can be overwhelming.
Patsnap Eureka, our cutting-edge AI assistant, is built for R&D and IP professionals in high-tech industries like drilling technologies. Whether you're optimizing rotary steerable systems, evaluating high-temperature materials, or exploring next-gen automation in directional drilling, Eureka enables real-time analysis of the latest patents, technology landscapes, and competitive movements—all from one intelligent, intuitive platform.
Ready to accelerate your development cycle and make strategic decisions with confidence? Explore Patsnap Eureka today—where smart drilling starts with smarter insights.
Features
- R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
Why Patsnap Eureka
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Social media
Patsnap Eureka Blog
Learn More Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com