

Comparing NLP Algorithms: Precision vs Recall
MAR 18, 20268 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
NLP Algorithm Evolution and Performance Goals
Natural Language Processing has undergone remarkable transformation since its inception in the 1950s, evolving from rule-based systems to sophisticated neural architectures. Early NLP systems relied heavily on handcrafted linguistic rules and statistical methods, achieving modest performance on limited tasks. The introduction of machine learning approaches in the 1990s marked a pivotal shift, enabling algorithms to learn patterns from data rather than relying solely on predefined rules.
The emergence of deep learning in the 2010s revolutionized NLP capabilities, with neural networks demonstrating unprecedented performance across various language tasks. Transformer architectures, introduced in 2017, fundamentally changed the landscape by enabling parallel processing and capturing long-range dependencies more effectively than previous sequential models. This breakthrough led to the development of large language models that exhibit human-like language understanding and generation capabilities.
Contemporary NLP development focuses on achieving optimal balance between precision and recall metrics, recognizing that different applications require distinct performance priorities. Search engines prioritize high precision to deliver relevant results, while information extraction systems often favor recall to ensure comprehensive data capture. The evolution toward contextual embeddings and attention mechanisms has enabled more nuanced approaches to this precision-recall trade-off.
Current technological objectives center on developing adaptive algorithms that can dynamically adjust their precision-recall balance based on specific use cases and user requirements. Advanced techniques such as multi-task learning and transfer learning are being leveraged to create more versatile models that maintain high performance across diverse domains while optimizing for specific evaluation metrics.
The trajectory toward explainable AI and interpretable NLP models represents another critical goal, as organizations seek algorithms that not only achieve superior precision and recall but also provide transparent decision-making processes. This evolution reflects the growing demand for trustworthy AI systems in mission-critical applications where understanding model behavior is essential for deployment and maintenance.
The emergence of deep learning in the 2010s revolutionized NLP capabilities, with neural networks demonstrating unprecedented performance across various language tasks. Transformer architectures, introduced in 2017, fundamentally changed the landscape by enabling parallel processing and capturing long-range dependencies more effectively than previous sequential models. This breakthrough led to the development of large language models that exhibit human-like language understanding and generation capabilities.
Contemporary NLP development focuses on achieving optimal balance between precision and recall metrics, recognizing that different applications require distinct performance priorities. Search engines prioritize high precision to deliver relevant results, while information extraction systems often favor recall to ensure comprehensive data capture. The evolution toward contextual embeddings and attention mechanisms has enabled more nuanced approaches to this precision-recall trade-off.
Current technological objectives center on developing adaptive algorithms that can dynamically adjust their precision-recall balance based on specific use cases and user requirements. Advanced techniques such as multi-task learning and transfer learning are being leveraged to create more versatile models that maintain high performance across diverse domains while optimizing for specific evaluation metrics.
The trajectory toward explainable AI and interpretable NLP models represents another critical goal, as organizations seek algorithms that not only achieve superior precision and recall but also provide transparent decision-making processes. This evolution reflects the growing demand for trustworthy AI systems in mission-critical applications where understanding model behavior is essential for deployment and maintenance.
Market Demand for High-Performance NLP Solutions
The global natural language processing market has experienced unprecedented growth driven by the increasing demand for intelligent automation and data-driven decision making across industries. Organizations are recognizing that the effectiveness of NLP applications heavily depends on the precision and recall performance of underlying algorithms, creating a substantial market opportunity for high-performance solutions.
Enterprise applications represent the largest segment of demand for precision-optimized NLP solutions. Financial institutions require highly accurate sentiment analysis and risk assessment tools where false positives can result in significant financial losses. Healthcare organizations demand precise clinical text processing systems for electronic health records and diagnostic support, where accuracy directly impacts patient safety and regulatory compliance.
The customer service and support sector drives substantial demand for recall-optimized NLP systems. Companies implementing chatbots and automated response systems prioritize comprehensive query understanding and intent recognition to minimize customer frustration from missed interactions. E-commerce platforms similarly require high-recall search and recommendation engines to capture diverse customer preferences and maximize conversion opportunities.
Legal technology markets show strong appetite for balanced precision-recall NLP solutions. Document review, contract analysis, and legal research applications require systems that can identify relevant information comprehensively while maintaining accuracy standards necessary for legal proceedings. This sector particularly values customizable performance tuning capabilities.
Content management and media industries increasingly seek high-performance NLP solutions for automated content categorization, moderation, and personalization. Social media platforms and news organizations require systems capable of processing massive content volumes while maintaining quality standards for user experience and brand safety.
The cybersecurity sector represents an emerging high-value market segment where NLP algorithm performance directly impacts threat detection effectiveness. Security information and event management systems require optimized precision-recall balance to identify genuine threats while minimizing false alarms that can overwhelm security teams.
Market research indicates growing demand for industry-specific NLP solutions that can be fine-tuned for particular precision-recall requirements rather than generic one-size-fits-all approaches. Organizations increasingly recognize that different use cases require different performance optimization strategies, driving demand for flexible, configurable NLP platforms.
Enterprise applications represent the largest segment of demand for precision-optimized NLP solutions. Financial institutions require highly accurate sentiment analysis and risk assessment tools where false positives can result in significant financial losses. Healthcare organizations demand precise clinical text processing systems for electronic health records and diagnostic support, where accuracy directly impacts patient safety and regulatory compliance.
The customer service and support sector drives substantial demand for recall-optimized NLP systems. Companies implementing chatbots and automated response systems prioritize comprehensive query understanding and intent recognition to minimize customer frustration from missed interactions. E-commerce platforms similarly require high-recall search and recommendation engines to capture diverse customer preferences and maximize conversion opportunities.
Legal technology markets show strong appetite for balanced precision-recall NLP solutions. Document review, contract analysis, and legal research applications require systems that can identify relevant information comprehensively while maintaining accuracy standards necessary for legal proceedings. This sector particularly values customizable performance tuning capabilities.
Content management and media industries increasingly seek high-performance NLP solutions for automated content categorization, moderation, and personalization. Social media platforms and news organizations require systems capable of processing massive content volumes while maintaining quality standards for user experience and brand safety.
The cybersecurity sector represents an emerging high-value market segment where NLP algorithm performance directly impacts threat detection effectiveness. Security information and event management systems require optimized precision-recall balance to identify genuine threats while minimizing false alarms that can overwhelm security teams.
Market research indicates growing demand for industry-specific NLP solutions that can be fine-tuned for particular precision-recall requirements rather than generic one-size-fits-all approaches. Organizations increasingly recognize that different use cases require different performance optimization strategies, driving demand for flexible, configurable NLP platforms.
Current NLP Algorithm Precision-Recall Trade-offs
The precision-recall trade-off represents a fundamental challenge in contemporary NLP algorithm design, where optimizing for one metric often comes at the expense of the other. This inherent tension manifests differently across various NLP tasks and algorithmic approaches, creating distinct performance profiles that must be carefully evaluated based on specific application requirements.
Traditional rule-based NLP systems typically exhibit high precision but suffer from limited recall capabilities. These systems excel at identifying patterns they are explicitly programmed to recognize, resulting in fewer false positives. However, their rigid structure prevents them from capturing the nuanced variations in natural language, leading to missed relevant instances and reduced recall scores.
Statistical machine learning approaches, including Support Vector Machines and Naive Bayes classifiers, demonstrate more balanced precision-recall characteristics. These algorithms can be tuned through threshold adjustment and feature engineering to favor either precision or recall depending on the use case. However, they often struggle with complex linguistic phenomena and require extensive feature engineering to achieve optimal performance.
Deep learning models, particularly transformer-based architectures like BERT and GPT variants, have revolutionized the precision-recall landscape in NLP. These models generally achieve superior overall performance but still face the fundamental trade-off. Fine-tuning strategies and architectural modifications can shift the balance, with some variants optimized for high-precision tasks like fact verification, while others prioritize recall for comprehensive information extraction.
Named Entity Recognition systems exemplify these trade-offs clearly. Conservative models achieve high precision by identifying only the most obvious entities but miss subtle or ambiguous cases. Aggressive models capture more entities, improving recall, but introduce more false positives, reducing precision.
Sentiment analysis algorithms face similar challenges, where strict classification boundaries yield high precision but may miss nuanced emotional expressions. Relaxed thresholds improve recall but increase misclassification rates, particularly for neutral or mixed sentiments.
The emergence of ensemble methods and multi-task learning approaches has provided new avenues for managing these trade-offs. By combining multiple models or training on related tasks simultaneously, these techniques can achieve more favorable precision-recall curves, though computational complexity increases significantly.
Traditional rule-based NLP systems typically exhibit high precision but suffer from limited recall capabilities. These systems excel at identifying patterns they are explicitly programmed to recognize, resulting in fewer false positives. However, their rigid structure prevents them from capturing the nuanced variations in natural language, leading to missed relevant instances and reduced recall scores.
Statistical machine learning approaches, including Support Vector Machines and Naive Bayes classifiers, demonstrate more balanced precision-recall characteristics. These algorithms can be tuned through threshold adjustment and feature engineering to favor either precision or recall depending on the use case. However, they often struggle with complex linguistic phenomena and require extensive feature engineering to achieve optimal performance.
Deep learning models, particularly transformer-based architectures like BERT and GPT variants, have revolutionized the precision-recall landscape in NLP. These models generally achieve superior overall performance but still face the fundamental trade-off. Fine-tuning strategies and architectural modifications can shift the balance, with some variants optimized for high-precision tasks like fact verification, while others prioritize recall for comprehensive information extraction.
Named Entity Recognition systems exemplify these trade-offs clearly. Conservative models achieve high precision by identifying only the most obvious entities but miss subtle or ambiguous cases. Aggressive models capture more entities, improving recall, but introduce more false positives, reducing precision.
Sentiment analysis algorithms face similar challenges, where strict classification boundaries yield high precision but may miss nuanced emotional expressions. Relaxed thresholds improve recall but increase misclassification rates, particularly for neutral or mixed sentiments.
The emergence of ensemble methods and multi-task learning approaches has provided new avenues for managing these trade-offs. By combining multiple models or training on related tasks simultaneously, these techniques can achieve more favorable precision-recall curves, though computational complexity increases significantly.
Existing Precision-Recall Optimization Approaches
01 Machine learning model evaluation metrics optimization
Methods and systems for optimizing precision and recall metrics in natural language processing models through advanced evaluation techniques. These approaches focus on balancing the trade-off between precision and recall by implementing dynamic threshold adjustments and multi-metric optimization strategies. The techniques enable improved model performance assessment and fine-tuning capabilities for various NLP tasks.- Machine learning model evaluation metrics optimization: Methods and systems for optimizing precision and recall metrics in machine learning models through advanced evaluation techniques. These approaches involve calculating and balancing precision-recall tradeoffs to improve model performance. Techniques include threshold adjustment, cross-validation methods, and multi-metric optimization strategies to achieve optimal balance between false positives and false negatives in classification tasks.
- Natural language processing performance measurement: Systems for measuring and improving the accuracy of natural language processing algorithms using precision and recall as key performance indicators. These methods involve evaluating text classification, entity recognition, and information extraction tasks. The approaches include automated testing frameworks, benchmark dataset evaluation, and statistical analysis of algorithm outputs to quantify performance improvements.
- Deep learning model accuracy enhancement: Techniques for enhancing precision and recall in deep learning-based NLP models through architectural improvements and training optimization. These methods incorporate attention mechanisms, loss function modifications, and ensemble learning approaches. The systems focus on reducing prediction errors and improving the reliability of neural network outputs in language understanding tasks.
- Information retrieval and search optimization: Methods for improving precision and recall in information retrieval systems and search engines using advanced NLP algorithms. These approaches involve query understanding, document ranking, and relevance scoring mechanisms. Techniques include semantic matching, context-aware retrieval, and user feedback integration to enhance search result quality and relevance.
- Automated text classification and labeling systems: Systems and methods for automated text classification with optimized precision and recall through intelligent labeling and categorization algorithms. These solutions employ supervised and unsupervised learning techniques to classify documents, emails, and other textual content. The approaches include active learning strategies, confidence scoring, and hierarchical classification methods to improve accuracy while minimizing manual intervention.
02 Named entity recognition with precision-recall enhancement
Techniques for improving named entity recognition accuracy by enhancing both precision and recall through sophisticated algorithms. These methods employ contextual analysis, semantic understanding, and pattern matching to identify entities more accurately while minimizing false positives and false negatives. The approaches integrate multiple linguistic features and knowledge bases to achieve better entity extraction performance.Expand Specific Solutions03 Text classification with balanced performance metrics
Systems and methods for text classification that optimize both precision and recall simultaneously. These solutions implement ensemble learning techniques, feature engineering, and adaptive algorithms to achieve balanced classification performance. The approaches address the challenge of maintaining high accuracy across different text categories while controlling both types of classification errors.Expand Specific Solutions04 Information retrieval with relevance scoring
Advanced information retrieval systems that utilize precision and recall metrics for relevance scoring and ranking. These methods incorporate semantic search capabilities, query understanding, and document relevance assessment to improve search result quality. The techniques employ statistical models and machine learning algorithms to optimize retrieval performance based on user intent and content relevance.Expand Specific Solutions05 Natural language understanding with performance monitoring
Frameworks for monitoring and improving natural language understanding systems using precision and recall as key performance indicators. These solutions provide real-time performance tracking, automated quality assessment, and continuous model improvement mechanisms. The approaches enable systematic evaluation of language understanding capabilities across different linguistic phenomena and application domains.Expand Specific Solutions
Leading NLP Technology Companies and Frameworks
The NLP algorithms precision vs recall optimization represents a mature technology domain experiencing rapid commercialization across diverse market segments. The industry has evolved from research-focused development to widespread enterprise deployment, with market size reaching billions annually driven by AI automation demands. Technology maturity varies significantly among key players, with established tech giants like Microsoft, IBM, and Tencent demonstrating advanced production-ready solutions through their cloud platforms and enterprise services. Companies such as Cisco, NEC, and Bosch integrate NLP capabilities into specialized industry applications, while emerging players like Ping An Technology and Veracode focus on domain-specific implementations. Academic institutions including Beijing Institute of Technology, Nanjing University of Science & Technology, and Capital Normal University contribute foundational research advancing algorithmic precision-recall trade-offs. The competitive landscape shows consolidation around platform providers offering comprehensive NLP toolkits, with differentiation occurring through specialized vertical applications and performance optimization techniques.
Tencent Technology (Shenzhen) Co., Ltd.
Technical Solution: Tencent has developed advanced NLP evaluation systems through their AI Lab, focusing on multi-dimensional algorithm comparison including precision-recall analysis. Their technical approach leverages deep learning frameworks with custom loss functions that can be adjusted to prioritize either precision or recall optimization. The platform incorporates ensemble learning methods that combine multiple NLP algorithms to achieve optimal precision-recall balance for specific applications. Tencent's solution includes real-time performance monitoring and adaptive algorithm selection based on incoming data characteristics. Their system utilizes cross-lingual evaluation capabilities and supports comparison across different language models, making it particularly effective for global applications requiring consistent precision-recall performance across multiple languages and cultural contexts.
Strengths: Strong performance in multilingual environments and extensive experience with large-scale consumer applications. Weaknesses: Limited availability outside of Chinese markets and potential data privacy concerns for international users.
Cisco Technology, Inc.
Technical Solution: Cisco's NLP algorithm comparison solutions are primarily integrated within their network security and collaboration platforms. Their approach focuses on real-time text analysis for threat detection and communication optimization, where precision-recall balance is critical for minimizing false positives while maintaining comprehensive threat coverage. The system employs federated learning techniques that allow algorithm comparison across distributed network environments without centralizing sensitive data. Cisco's platform includes specialized evaluation metrics for network-specific NLP applications, such as anomaly detection in network logs and automated incident response. Their solution incorporates edge computing capabilities that enable local NLP algorithm evaluation and comparison, reducing latency and improving privacy for enterprise customers requiring on-premises deployment of precision-recall optimization systems.
Strengths: Strong integration with existing network infrastructure and robust security features for enterprise environments. Weaknesses: Limited focus on general-purpose NLP applications and higher complexity for non-network related use cases.
Core Innovations in NLP Performance Enhancement
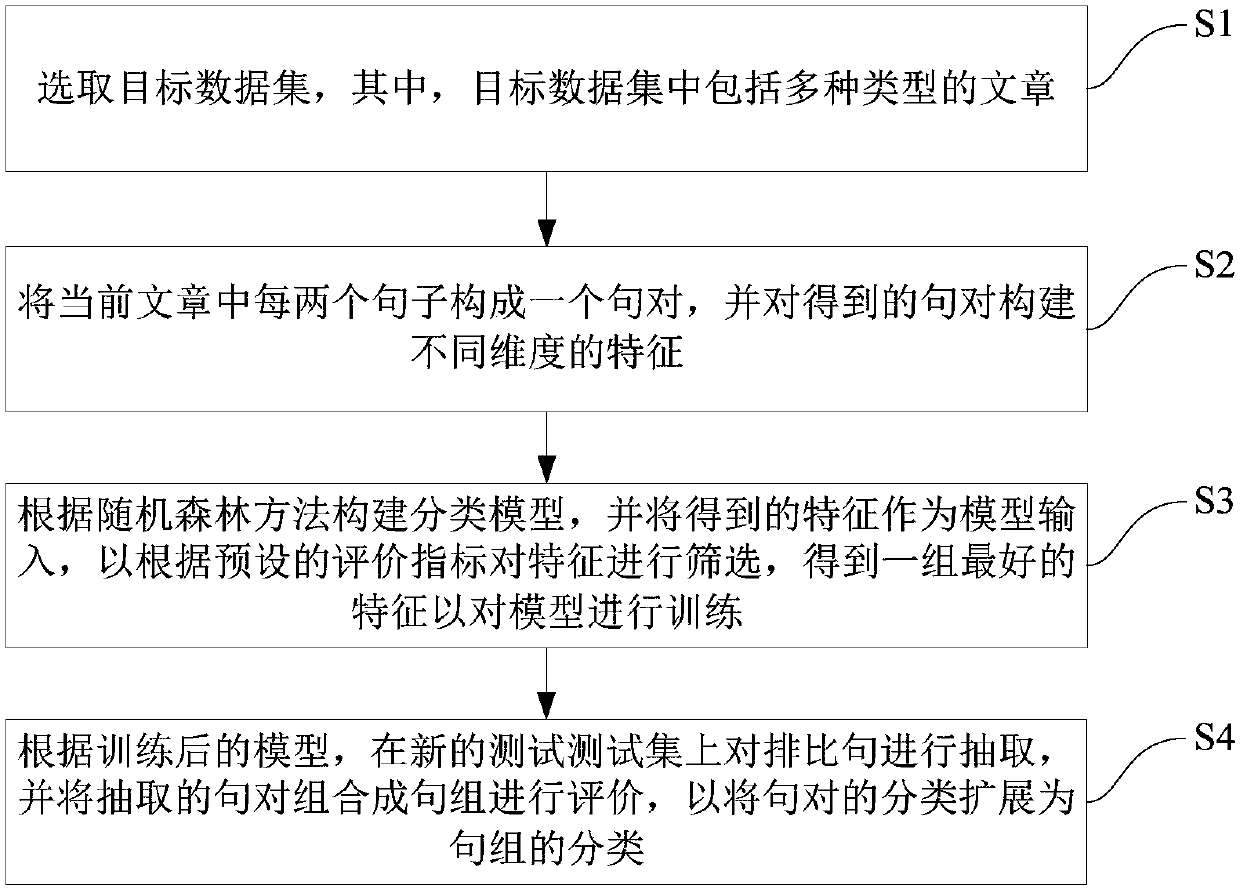
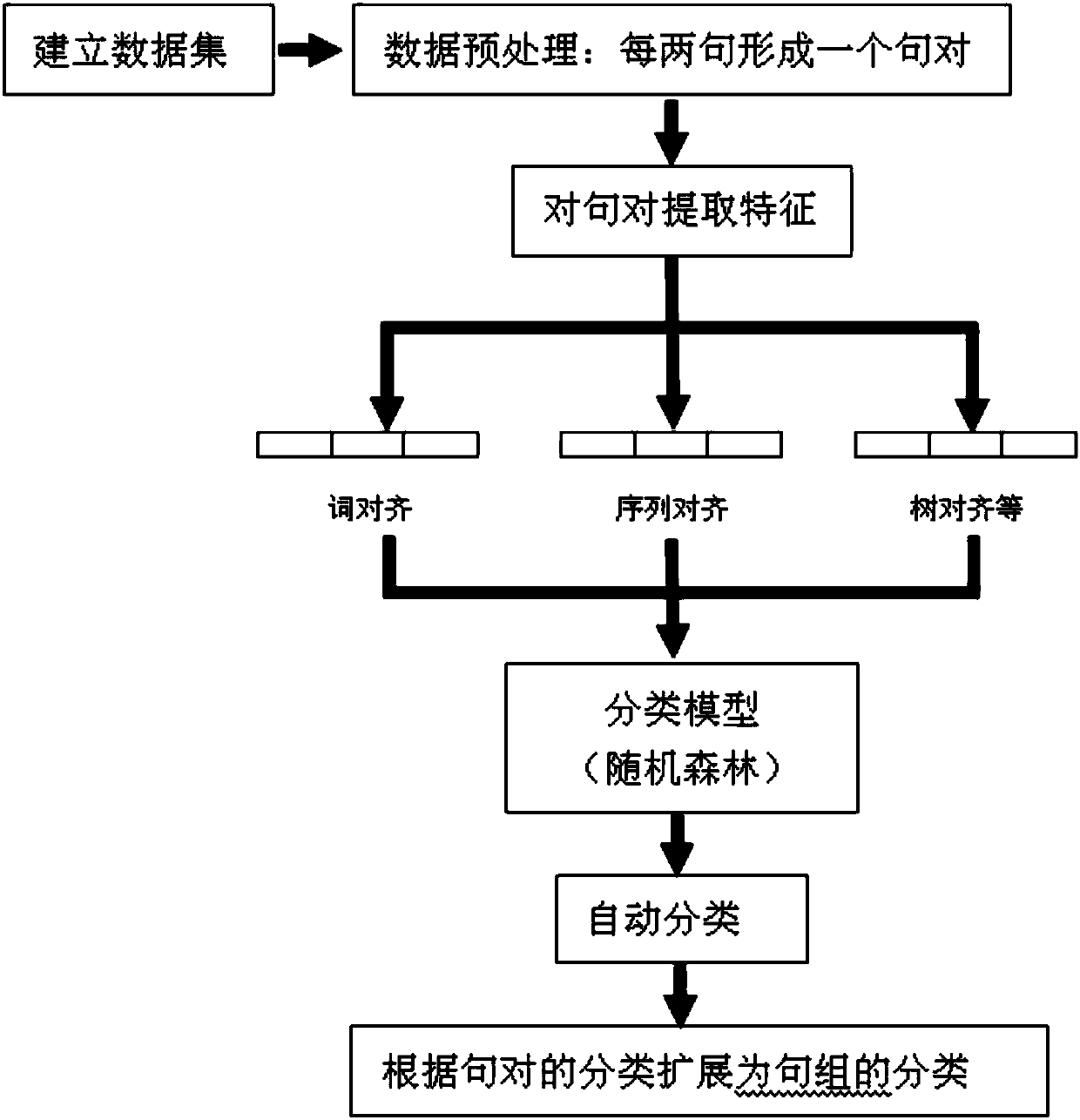
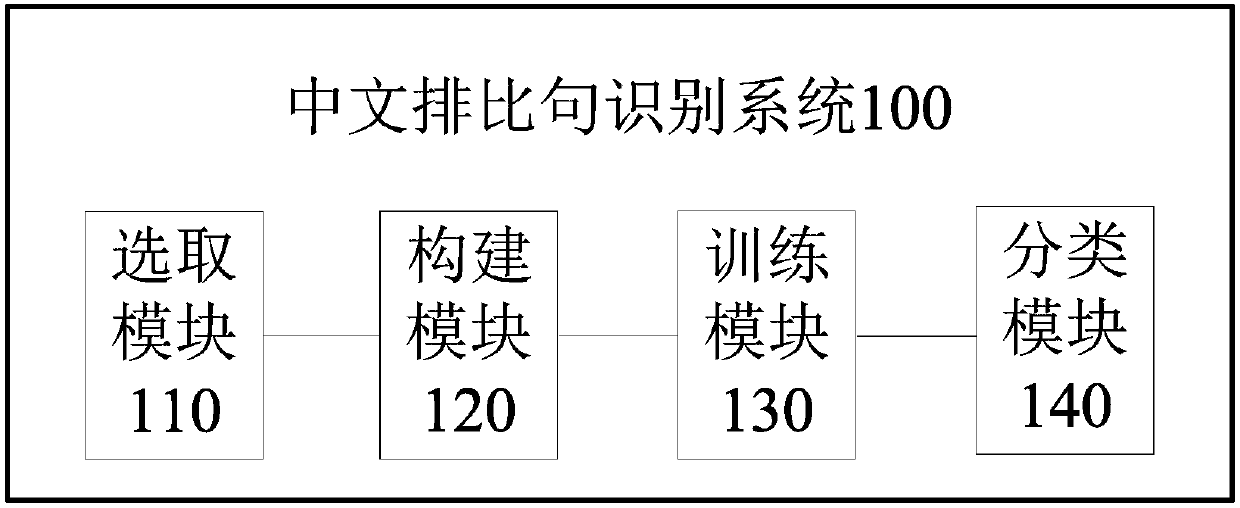
Chinese parallelism sentence recognition method and system
PatentActiveCN107943852A
Innovation
- The random forest method is used to build a classification model. By constructing features of different dimensions, such as word alignment strategy, sequence alignment strategy, tree alignment strategy and position length features, Chinese parallel sentences are identified and classified, using accuracy, recall and F-value. Filter features as evaluation indicators.

Tutorial recommendation using discourse-level consistency and ontology-based filtering
PatentActiveUS12105748B2
Innovation
- A machine learning-based recommendation apparatus that generates a summary of a source document using a summarization network, filters candidate documents based on domain-specific knowledge and string similarity, and computes ranking scores for relevant document retrieval.




Data Privacy Regulations in NLP Applications
The implementation of NLP algorithms with varying precision and recall characteristics must navigate an increasingly complex landscape of data privacy regulations worldwide. The General Data Protection Regulation (GDPR) in Europe establishes stringent requirements for processing personal data, including textual information that may contain personally identifiable information. Under GDPR, organizations must demonstrate lawful basis for data processing, implement privacy by design principles, and ensure data subjects' rights are protected throughout the algorithmic decision-making process.
In the United States, sector-specific regulations such as HIPAA for healthcare and CCPA for consumer data create additional compliance layers. These regulations directly impact how NLP algorithms handle sensitive textual data, requiring careful consideration of precision-recall trade-offs when processing protected information. High-precision algorithms may reduce false positives in sensitive data identification but could miss critical privacy violations, while high-recall systems might over-classify benign text as sensitive, leading to unnecessary processing restrictions.
The emerging AI governance frameworks, including the EU AI Act and various national AI strategies, introduce algorithmic accountability requirements that affect NLP system design. These regulations mandate transparency in algorithmic decision-making, requiring organizations to explain how precision and recall parameters influence outcomes, particularly in high-risk applications such as automated content moderation or sentiment analysis for hiring decisions.
Cross-border data transfer restrictions under regulations like GDPR's adequacy decisions and China's Cybersecurity Law create additional complexity for NLP applications operating globally. Organizations must ensure that algorithm training data, model parameters, and inference results comply with data localization requirements while maintaining optimal precision-recall performance across different jurisdictions.
Compliance frameworks increasingly require algorithmic impact assessments that evaluate how precision-recall optimization affects individual privacy rights. This includes demonstrating that algorithm tuning processes do not inadvertently create discriminatory outcomes or compromise data subject rights, necessitating careful documentation of model performance metrics and their privacy implications throughout the development lifecycle.
In the United States, sector-specific regulations such as HIPAA for healthcare and CCPA for consumer data create additional compliance layers. These regulations directly impact how NLP algorithms handle sensitive textual data, requiring careful consideration of precision-recall trade-offs when processing protected information. High-precision algorithms may reduce false positives in sensitive data identification but could miss critical privacy violations, while high-recall systems might over-classify benign text as sensitive, leading to unnecessary processing restrictions.
The emerging AI governance frameworks, including the EU AI Act and various national AI strategies, introduce algorithmic accountability requirements that affect NLP system design. These regulations mandate transparency in algorithmic decision-making, requiring organizations to explain how precision and recall parameters influence outcomes, particularly in high-risk applications such as automated content moderation or sentiment analysis for hiring decisions.
Cross-border data transfer restrictions under regulations like GDPR's adequacy decisions and China's Cybersecurity Law create additional complexity for NLP applications operating globally. Organizations must ensure that algorithm training data, model parameters, and inference results comply with data localization requirements while maintaining optimal precision-recall performance across different jurisdictions.
Compliance frameworks increasingly require algorithmic impact assessments that evaluate how precision-recall optimization affects individual privacy rights. This includes demonstrating that algorithm tuning processes do not inadvertently create discriminatory outcomes or compromise data subject rights, necessitating careful documentation of model performance metrics and their privacy implications throughout the development lifecycle.
Evaluation Standards for NLP Algorithm Comparison
The establishment of robust evaluation standards for NLP algorithm comparison requires a comprehensive framework that addresses the inherent trade-offs between precision and recall metrics. Current evaluation methodologies often rely on isolated metric assessments, which fail to capture the nuanced performance characteristics essential for algorithm selection in production environments.
Precision-focused evaluation standards emphasize the accuracy of positive predictions, making them particularly suitable for applications where false positives carry significant consequences. These standards typically incorporate threshold optimization techniques and cost-sensitive learning approaches to minimize incorrect classifications. The evaluation framework must account for class imbalance scenarios where precision metrics may provide misleading performance indicators.
Recall-oriented evaluation criteria prioritize the identification of all relevant instances within the dataset, proving crucial for information retrieval and content discovery applications. These standards require comprehensive coverage analysis and sensitivity measurements to ensure algorithms capture the maximum number of true positive cases. The evaluation process must consider the computational overhead associated with achieving high recall rates.
Balanced evaluation frameworks integrate F1-scores, F-beta measures, and area under the precision-recall curve metrics to provide holistic performance assessments. These composite standards enable fair comparison across algorithms with different optimization objectives and operational constraints. The framework should incorporate statistical significance testing and cross-validation protocols to ensure reproducible results.
Domain-specific evaluation standards must address unique requirements of different NLP applications, including named entity recognition, sentiment analysis, and machine translation tasks. These specialized criteria consider contextual accuracy, semantic coherence, and task-specific quality measures beyond traditional precision-recall metrics.
Standardized benchmarking protocols require consistent dataset preparation, feature engineering approaches, and hyperparameter optimization procedures to ensure fair algorithm comparison. The evaluation framework must establish clear guidelines for training-validation-test splits, data preprocessing steps, and performance reporting formats to maintain scientific rigor and reproducibility across comparative studies.
Precision-focused evaluation standards emphasize the accuracy of positive predictions, making them particularly suitable for applications where false positives carry significant consequences. These standards typically incorporate threshold optimization techniques and cost-sensitive learning approaches to minimize incorrect classifications. The evaluation framework must account for class imbalance scenarios where precision metrics may provide misleading performance indicators.
Recall-oriented evaluation criteria prioritize the identification of all relevant instances within the dataset, proving crucial for information retrieval and content discovery applications. These standards require comprehensive coverage analysis and sensitivity measurements to ensure algorithms capture the maximum number of true positive cases. The evaluation process must consider the computational overhead associated with achieving high recall rates.
Balanced evaluation frameworks integrate F1-scores, F-beta measures, and area under the precision-recall curve metrics to provide holistic performance assessments. These composite standards enable fair comparison across algorithms with different optimization objectives and operational constraints. The framework should incorporate statistical significance testing and cross-validation protocols to ensure reproducible results.
Domain-specific evaluation standards must address unique requirements of different NLP applications, including named entity recognition, sentiment analysis, and machine translation tasks. These specialized criteria consider contextual accuracy, semantic coherence, and task-specific quality measures beyond traditional precision-recall metrics.
Standardized benchmarking protocols require consistent dataset preparation, feature engineering approaches, and hyperparameter optimization procedures to ensure fair algorithm comparison. The evaluation framework must establish clear guidelines for training-validation-test splits, data preprocessing steps, and performance reporting formats to maintain scientific rigor and reproducibility across comparative studies.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!