

CXL Memory vs GPU Memory: Performance in Deep Learning Tasks
JUN 5, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
CXL Memory Technology Background and Deep Learning Goals
Compute Express Link (CXL) represents a revolutionary advancement in memory interconnect technology, emerging as an open industry standard that enables high-speed, low-latency communication between processors and memory devices. Developed through collaboration between major technology companies including Intel, AMD, and ARM, CXL builds upon the PCIe 5.0 physical layer while introducing enhanced protocols specifically designed for memory and accelerator connectivity. This technology addresses the growing bandwidth and latency challenges faced by modern computing systems, particularly in data-intensive applications.
The evolution of CXL technology spans multiple generations, with CXL 1.0 introducing basic memory pooling capabilities, CXL 2.0 adding memory expansion and sharing features, and CXL 3.0 delivering advanced fabric capabilities with peer-to-peer communication. Each iteration has progressively enhanced bandwidth capacity, reduced latency overhead, and expanded compatibility across diverse hardware platforms. The technology's development trajectory reflects the industry's urgent need to overcome traditional memory bottlenecks that constrain system performance.
Deep learning workloads present unique memory challenges that traditional architectures struggle to address effectively. These computational tasks require massive datasets to be processed simultaneously, often exceeding the capacity limitations of conventional GPU memory configurations. The memory wall phenomenon becomes particularly pronounced in deep learning scenarios, where data movement between storage, system memory, and processing units creates significant performance bottlenecks that can severely impact training efficiency and inference speed.
CXL memory technology aims to revolutionize deep learning performance by establishing a unified memory pool that can be dynamically allocated across multiple processing units. The primary technical objective involves creating seamless memory expansion capabilities that allow GPU workloads to access larger memory spaces without traditional bandwidth penalties. This approach seeks to eliminate the rigid memory boundaries that currently force developers to partition datasets artificially or implement complex data streaming mechanisms.
The strategic goals for CXL implementation in deep learning environments encompass several critical performance dimensions. Latency reduction represents a fundamental objective, targeting sub-microsecond access times that approach GPU memory performance levels. Bandwidth optimization focuses on achieving sustained throughput rates that can support concurrent access from multiple GPU units without creating contention bottlenecks. Additionally, the technology aims to enable elastic memory scaling, allowing systems to adapt memory allocation dynamically based on workload requirements, thereby improving resource utilization efficiency and reducing infrastructure costs for large-scale deep learning deployments.
The evolution of CXL technology spans multiple generations, with CXL 1.0 introducing basic memory pooling capabilities, CXL 2.0 adding memory expansion and sharing features, and CXL 3.0 delivering advanced fabric capabilities with peer-to-peer communication. Each iteration has progressively enhanced bandwidth capacity, reduced latency overhead, and expanded compatibility across diverse hardware platforms. The technology's development trajectory reflects the industry's urgent need to overcome traditional memory bottlenecks that constrain system performance.
Deep learning workloads present unique memory challenges that traditional architectures struggle to address effectively. These computational tasks require massive datasets to be processed simultaneously, often exceeding the capacity limitations of conventional GPU memory configurations. The memory wall phenomenon becomes particularly pronounced in deep learning scenarios, where data movement between storage, system memory, and processing units creates significant performance bottlenecks that can severely impact training efficiency and inference speed.
CXL memory technology aims to revolutionize deep learning performance by establishing a unified memory pool that can be dynamically allocated across multiple processing units. The primary technical objective involves creating seamless memory expansion capabilities that allow GPU workloads to access larger memory spaces without traditional bandwidth penalties. This approach seeks to eliminate the rigid memory boundaries that currently force developers to partition datasets artificially or implement complex data streaming mechanisms.
The strategic goals for CXL implementation in deep learning environments encompass several critical performance dimensions. Latency reduction represents a fundamental objective, targeting sub-microsecond access times that approach GPU memory performance levels. Bandwidth optimization focuses on achieving sustained throughput rates that can support concurrent access from multiple GPU units without creating contention bottlenecks. Additionally, the technology aims to enable elastic memory scaling, allowing systems to adapt memory allocation dynamically based on workload requirements, thereby improving resource utilization efficiency and reducing infrastructure costs for large-scale deep learning deployments.
Market Demand for High-Performance Deep Learning Memory Solutions
The deep learning industry is experiencing unprecedented growth, driving substantial demand for high-performance memory solutions that can efficiently handle massive computational workloads. Traditional memory architectures are increasingly challenged by the exponential growth in model complexity, with transformer-based models and large language models requiring memory capacities that far exceed conventional limitations. This surge in computational requirements has created a critical market opportunity for advanced memory technologies.
Enterprise adoption of artificial intelligence across sectors including autonomous vehicles, natural language processing, computer vision, and scientific computing has intensified the need for memory solutions that can deliver both high bandwidth and low latency. Organizations are seeking alternatives to traditional GPU memory configurations, particularly as memory bottlenecks become the primary constraint in deep learning pipeline performance rather than computational capacity itself.
The emergence of CXL memory technology represents a significant market disruption, offering the potential to disaggregate memory resources and provide more flexible, scalable solutions for deep learning workloads. Market demand is particularly strong among hyperscale cloud providers, research institutions, and enterprises deploying large-scale AI infrastructure, where memory costs and performance directly impact operational efficiency and competitive advantage.
Current market dynamics reveal a growing willingness to invest in innovative memory architectures that can reduce total cost of ownership while improving performance metrics. The demand extends beyond raw capacity to include features such as memory pooling, dynamic allocation, and improved fault tolerance, which are becoming essential requirements for production deep learning environments.
Industry analysts indicate that the market for high-performance memory solutions in AI applications is expanding rapidly, driven by the increasing deployment of edge AI systems, real-time inference requirements, and the need for more efficient training of next-generation models. This demand is creating opportunities for memory technologies that can bridge the gap between traditional system memory and specialized GPU memory, offering new architectural possibilities for deep learning system design.
Enterprise adoption of artificial intelligence across sectors including autonomous vehicles, natural language processing, computer vision, and scientific computing has intensified the need for memory solutions that can deliver both high bandwidth and low latency. Organizations are seeking alternatives to traditional GPU memory configurations, particularly as memory bottlenecks become the primary constraint in deep learning pipeline performance rather than computational capacity itself.
The emergence of CXL memory technology represents a significant market disruption, offering the potential to disaggregate memory resources and provide more flexible, scalable solutions for deep learning workloads. Market demand is particularly strong among hyperscale cloud providers, research institutions, and enterprises deploying large-scale AI infrastructure, where memory costs and performance directly impact operational efficiency and competitive advantage.
Current market dynamics reveal a growing willingness to invest in innovative memory architectures that can reduce total cost of ownership while improving performance metrics. The demand extends beyond raw capacity to include features such as memory pooling, dynamic allocation, and improved fault tolerance, which are becoming essential requirements for production deep learning environments.
Industry analysts indicate that the market for high-performance memory solutions in AI applications is expanding rapidly, driven by the increasing deployment of edge AI systems, real-time inference requirements, and the need for more efficient training of next-generation models. This demand is creating opportunities for memory technologies that can bridge the gap between traditional system memory and specialized GPU memory, offering new architectural possibilities for deep learning system design.
Current State and Challenges of CXL vs GPU Memory Systems
The current landscape of memory systems for deep learning workloads presents a complex dichotomy between traditional GPU memory architectures and emerging CXL-based solutions. GPU memory systems, primarily utilizing High Bandwidth Memory (HBM) and GDDR technologies, have dominated the deep learning ecosystem for over a decade. These systems offer exceptional bandwidth capabilities, with modern HBM3 implementations achieving up to 819 GB/s per stack, making them highly suitable for the parallel processing demands of neural network training and inference.
However, GPU memory systems face significant scalability constraints that increasingly limit their effectiveness in large-scale deep learning applications. The primary challenge lies in memory capacity limitations, where even high-end datacenter GPUs typically max out at 80-128GB of on-device memory. This constraint forces developers to implement complex memory management strategies, including gradient checkpointing, model sharding, and pipeline parallelism, which introduce computational overhead and programming complexity.
CXL memory systems represent an emerging paradigm that addresses these capacity limitations through disaggregated memory architectures. CXL 3.0 specifications enable memory pooling across multiple devices, theoretically allowing terabyte-scale memory access with cache-coherent protocols. Early implementations demonstrate the ability to extend effective memory capacity beyond traditional GPU boundaries while maintaining relatively low latency access patterns.
The technical challenges facing CXL adoption in deep learning contexts are multifaceted. Latency characteristics remain a critical concern, as CXL memory typically exhibits 2-3x higher access latencies compared to local GPU memory. This latency penalty particularly impacts memory-intensive operations such as attention mechanisms in transformer models and frequent parameter updates during training phases.
Bandwidth asymmetry presents another significant challenge in current CXL implementations. While GPU memory systems provide symmetric high-bandwidth access, CXL memory often exhibits directional bandwidth variations and potential bottlenecks at PCIe interface levels. This asymmetry can create performance unpredictability in workloads with irregular memory access patterns.
Software ecosystem maturity represents a substantial barrier to CXL adoption. Current deep learning frameworks, including PyTorch and TensorFlow, lack native optimization for CXL memory hierarchies. Memory allocation strategies, automatic placement policies, and performance profiling tools require significant development to effectively leverage CXL capabilities in production deep learning environments.
Interoperability challenges emerge when integrating CXL memory with existing GPU-centric workflows. Current implementations often require explicit memory management and data movement orchestration, contrasting with the relatively seamless unified memory models provided by modern GPU architectures. These integration complexities can offset potential capacity benefits in many practical deployment scenarios.
However, GPU memory systems face significant scalability constraints that increasingly limit their effectiveness in large-scale deep learning applications. The primary challenge lies in memory capacity limitations, where even high-end datacenter GPUs typically max out at 80-128GB of on-device memory. This constraint forces developers to implement complex memory management strategies, including gradient checkpointing, model sharding, and pipeline parallelism, which introduce computational overhead and programming complexity.
CXL memory systems represent an emerging paradigm that addresses these capacity limitations through disaggregated memory architectures. CXL 3.0 specifications enable memory pooling across multiple devices, theoretically allowing terabyte-scale memory access with cache-coherent protocols. Early implementations demonstrate the ability to extend effective memory capacity beyond traditional GPU boundaries while maintaining relatively low latency access patterns.
The technical challenges facing CXL adoption in deep learning contexts are multifaceted. Latency characteristics remain a critical concern, as CXL memory typically exhibits 2-3x higher access latencies compared to local GPU memory. This latency penalty particularly impacts memory-intensive operations such as attention mechanisms in transformer models and frequent parameter updates during training phases.
Bandwidth asymmetry presents another significant challenge in current CXL implementations. While GPU memory systems provide symmetric high-bandwidth access, CXL memory often exhibits directional bandwidth variations and potential bottlenecks at PCIe interface levels. This asymmetry can create performance unpredictability in workloads with irregular memory access patterns.
Software ecosystem maturity represents a substantial barrier to CXL adoption. Current deep learning frameworks, including PyTorch and TensorFlow, lack native optimization for CXL memory hierarchies. Memory allocation strategies, automatic placement policies, and performance profiling tools require significant development to effectively leverage CXL capabilities in production deep learning environments.
Interoperability challenges emerge when integrating CXL memory with existing GPU-centric workflows. Current implementations often require explicit memory management and data movement orchestration, contrasting with the relatively seamless unified memory models provided by modern GPU architectures. These integration complexities can offset potential capacity benefits in many practical deployment scenarios.
Existing Memory Solutions for Deep Learning Performance
01 CXL memory interface optimization and bandwidth enhancement
Technologies focused on optimizing the Compute Express Link interface to improve memory bandwidth and reduce latency between processors and memory devices. These innovations include advanced signaling protocols, enhanced data transfer mechanisms, and improved memory controller architectures that maximize throughput while maintaining compatibility with existing systems.- CXL memory interface optimization and bandwidth enhancement: Technologies focused on optimizing the Compute Express Link interface to improve memory bandwidth and reduce latency between processors and memory devices. These innovations include advanced signaling protocols, improved data transfer mechanisms, and enhanced memory controller architectures that maximize throughput while maintaining compatibility with existing systems.
- GPU memory allocation and management systems: Advanced memory management techniques specifically designed for graphics processing units, including dynamic memory allocation algorithms, memory pool optimization, and intelligent caching strategies. These systems aim to reduce memory fragmentation, improve memory utilization efficiency, and enhance overall GPU performance through better resource management.
- Memory coherency and synchronization protocols: Protocols and mechanisms that ensure data consistency and synchronization between different memory hierarchies in heterogeneous computing environments. These technologies address cache coherency challenges, implement efficient synchronization primitives, and provide hardware-software co-design solutions for maintaining data integrity across multiple processing units.
- High-performance memory interconnect architectures: Novel interconnect designs that facilitate high-speed communication between processing units and memory subsystems. These architectures incorporate advanced switching fabrics, optimized routing algorithms, and low-latency communication protocols to maximize data transfer rates and minimize bottlenecks in memory-intensive applications.
- Memory performance monitoring and optimization tools: Comprehensive monitoring and profiling systems that analyze memory performance characteristics in real-time, identify bottlenecks, and provide automated optimization recommendations. These tools include performance counters, bandwidth analyzers, and machine learning-based optimization engines that adapt memory configurations based on workload patterns.
02 GPU memory allocation and management systems
Advanced memory management techniques specifically designed for graphics processing units, including dynamic memory allocation algorithms, memory pool optimization, and intelligent caching strategies. These systems aim to reduce memory fragmentation, improve memory utilization efficiency, and enhance overall GPU performance through better resource management.Expand Specific Solutions03 Memory coherency and synchronization mechanisms
Solutions addressing memory coherency challenges in heterogeneous computing environments where multiple processing units access shared memory resources. These technologies implement sophisticated synchronization protocols, cache coherency mechanisms, and data consistency algorithms to ensure reliable data sharing between different processing elements.Expand Specific Solutions04 High-performance memory architectures and interconnects
Innovative memory architectures designed to support high-bandwidth, low-latency memory access patterns required by modern computing workloads. These solutions include novel memory hierarchies, advanced interconnect topologies, and specialized memory controllers that optimize data movement between processing units and memory subsystems.Expand Specific Solutions05 Memory performance monitoring and optimization tools
Comprehensive monitoring and optimization frameworks that analyze memory access patterns, identify performance bottlenecks, and implement adaptive optimization strategies. These tools provide real-time performance metrics, predictive analytics, and automated tuning capabilities to maximize memory subsystem efficiency in various computing scenarios.Expand Specific Solutions
Key Players in CXL Memory and GPU Memory Industry
The CXL Memory versus GPU Memory performance landscape in deep learning represents an emerging market segment transitioning from early adoption to mainstream integration. The industry is experiencing rapid growth driven by AI workload demands and memory bandwidth limitations in traditional GPU architectures. Market participants span from established semiconductor giants like Intel, Samsung Electronics, and Micron Technology providing foundational CXL infrastructure, to specialized innovators like Unifabrix and Panmnesia developing advanced memory fabric solutions. Technology maturity varies significantly across players, with Intel and Samsung leading in standardized CXL implementations, while companies like Moreh and Lablup focus on software orchestration layers. Chinese entities including Inspur, xFusion, and various research institutes are actively developing competitive solutions, indicating strong regional investment in this technology domain for AI acceleration applications.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has developed advanced CXL memory modules specifically optimized for AI and machine learning workloads. Their CXL-based memory solutions provide high-capacity, high-bandwidth memory that can be dynamically allocated between CPU and GPU resources. Samsung's approach includes specialized memory controllers that optimize data movement patterns common in deep learning applications, such as large matrix operations and gradient updates. Their CXL memory technology supports memory pooling architectures that allow multiple GPUs to access shared memory resources efficiently. The company has demonstrated significant performance improvements in training large language models by reducing memory access latencies and enabling larger model sizes that exceed individual GPU memory limitations through intelligent memory tiering and caching strategies.
Strengths: High-capacity memory modules, optimized for AI workloads, strong manufacturing capabilities and reliability. Weaknesses: Cost premium over traditional memory solutions, dependency on CXL ecosystem adoption for full benefits.
Micron Technology, Inc.
Technical Solution: Micron has developed CXL-enabled memory solutions that bridge the performance gap between traditional system memory and GPU memory for deep learning applications. Their technology focuses on providing high-bandwidth, low-latency memory access through CXL interfaces, enabling more efficient data movement in AI training pipelines. Micron's CXL memory products support advanced memory management features including memory pooling, where multiple compute resources can dynamically access shared memory pools. This approach is particularly beneficial for deep learning workloads that require large memory footprints exceeding individual GPU memory capacity. Their solutions include intelligent prefetching and caching mechanisms optimized for neural network training patterns, helping to reduce memory access bottlenecks that commonly occur during gradient computation and parameter updates in large-scale model training.
Strengths: Proven memory technology expertise, optimized memory access patterns for AI workloads, strong industry partnerships. Weaknesses: Limited compared to GPU memory bandwidth, requires CXL-compatible infrastructure for optimal performance.
Core Innovations in CXL Memory Architecture for AI
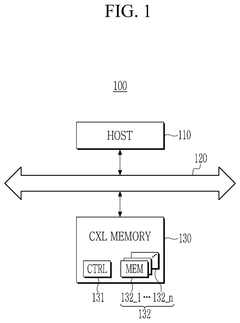
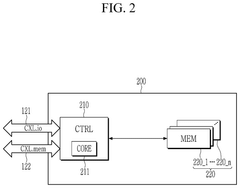
Compute express link memory device and computing device
PatentPendingUS20240394331A1
Innovation
- A Compute Express Link (CXL) memory device and system that selects appropriate calculation circuits based on the type of calculation, utilizing a CXL interface for efficient data processing and memory management, allowing for high-bandwidth and large-capacity memory operations.
Memory allocation method and device, electronic equipment, storage medium and product
PatentPendingCN121387768A
Innovation
- By determining the job parameter information of the job to be assigned and the current system status data of the heterogeneous computing system, combined with preset constraints and preset objective functions, the total data transmission time is minimized, and the allocation of memory and computing units is optimized to reduce bandwidth contention and lower data transmission latency.




Performance Benchmarking Standards for AI Memory Systems
The establishment of standardized performance benchmarking frameworks for AI memory systems has become increasingly critical as the industry evaluates emerging memory technologies like CXL against traditional GPU memory architectures. Current benchmarking practices often rely on vendor-specific metrics that fail to provide comprehensive comparisons across different memory subsystems, particularly when assessing their effectiveness in deep learning workloads.
Industry-standard benchmarking suites such as MLPerf have begun incorporating memory-intensive AI workloads, but these frameworks primarily focus on overall system performance rather than isolating memory subsystem contributions. The lack of granular memory performance metrics creates challenges when organizations attempt to quantify the specific advantages of CXL memory expansion versus high-bandwidth GPU memory configurations in neural network training and inference scenarios.
Emerging benchmarking methodologies are addressing these gaps by introducing memory-centric performance indicators that measure bandwidth utilization efficiency, latency characteristics under varying load conditions, and power consumption per memory operation. These standards emphasize the importance of workload-representative testing scenarios that reflect real-world deep learning applications, including large language model training, computer vision tasks, and recommendation systems that exhibit distinct memory access patterns.
The development of cross-platform benchmarking protocols enables fair comparison between CXL-enabled systems and traditional GPU memory hierarchies by standardizing test conditions, data set sizes, and measurement intervals. These protocols account for factors such as memory coherency overhead, interconnect latency, and thermal throttling effects that significantly impact performance in sustained AI workloads.
Future benchmarking standards are evolving toward dynamic performance assessment frameworks that evaluate memory system behavior across varying computational phases typical in deep learning workflows. These advanced standards incorporate metrics for memory allocation efficiency, garbage collection impact, and multi-tenant performance characteristics that become crucial when deploying AI systems in production environments where resource sharing and workload isolation are essential considerations.
Industry-standard benchmarking suites such as MLPerf have begun incorporating memory-intensive AI workloads, but these frameworks primarily focus on overall system performance rather than isolating memory subsystem contributions. The lack of granular memory performance metrics creates challenges when organizations attempt to quantify the specific advantages of CXL memory expansion versus high-bandwidth GPU memory configurations in neural network training and inference scenarios.
Emerging benchmarking methodologies are addressing these gaps by introducing memory-centric performance indicators that measure bandwidth utilization efficiency, latency characteristics under varying load conditions, and power consumption per memory operation. These standards emphasize the importance of workload-representative testing scenarios that reflect real-world deep learning applications, including large language model training, computer vision tasks, and recommendation systems that exhibit distinct memory access patterns.
The development of cross-platform benchmarking protocols enables fair comparison between CXL-enabled systems and traditional GPU memory hierarchies by standardizing test conditions, data set sizes, and measurement intervals. These protocols account for factors such as memory coherency overhead, interconnect latency, and thermal throttling effects that significantly impact performance in sustained AI workloads.
Future benchmarking standards are evolving toward dynamic performance assessment frameworks that evaluate memory system behavior across varying computational phases typical in deep learning workflows. These advanced standards incorporate metrics for memory allocation efficiency, garbage collection impact, and multi-tenant performance characteristics that become crucial when deploying AI systems in production environments where resource sharing and workload isolation are essential considerations.
Energy Efficiency Considerations in Deep Learning Memory
Energy efficiency has emerged as a critical consideration in deep learning memory architectures, particularly when comparing CXL memory and GPU memory systems. The exponential growth in model complexity and training dataset sizes has led to substantial increases in power consumption, making energy optimization a paramount concern for both operational costs and environmental sustainability.
CXL memory demonstrates superior energy efficiency characteristics compared to traditional GPU memory configurations in several key aspects. The disaggregated memory architecture inherent in CXL systems allows for more granular power management, enabling selective activation of memory modules based on actual workload requirements. This dynamic scaling capability significantly reduces idle power consumption during periods of lower memory utilization, which is particularly beneficial in training scenarios with variable memory access patterns.
The energy profile of GPU memory, particularly High Bandwidth Memory (HBM), presents distinct challenges in deep learning applications. While HBM provides exceptional bandwidth performance, it maintains relatively high static power consumption regardless of utilization levels. The tightly coupled nature of GPU memory to processing units often results in over-provisioning scenarios where memory modules remain active even when not fully utilized, leading to suboptimal energy efficiency ratios.
Power density considerations further differentiate these memory architectures. CXL memory systems distribute power consumption across multiple discrete components, allowing for better thermal management and reduced cooling requirements. This distributed approach contrasts with GPU memory's concentrated power density, which necessitates sophisticated cooling solutions that contribute additional energy overhead to the overall system.
Memory access patterns in deep learning workloads significantly impact energy consumption profiles. CXL memory's ability to maintain data persistence across compute cycles reduces the energy overhead associated with frequent data transfers between storage and active memory. GPU memory systems, while offering lower latency access, often require more frequent data movement operations that contribute to higher overall energy consumption, particularly in large-scale training scenarios where memory capacity exceeds individual GPU limitations.
The scalability implications of energy efficiency become increasingly important in distributed deep learning environments. CXL memory architectures enable more efficient resource allocation across multiple compute nodes, reducing redundant memory provisioning and associated energy waste. This efficiency advantage becomes more pronounced as training clusters scale beyond traditional GPU-centric configurations.
CXL memory demonstrates superior energy efficiency characteristics compared to traditional GPU memory configurations in several key aspects. The disaggregated memory architecture inherent in CXL systems allows for more granular power management, enabling selective activation of memory modules based on actual workload requirements. This dynamic scaling capability significantly reduces idle power consumption during periods of lower memory utilization, which is particularly beneficial in training scenarios with variable memory access patterns.
The energy profile of GPU memory, particularly High Bandwidth Memory (HBM), presents distinct challenges in deep learning applications. While HBM provides exceptional bandwidth performance, it maintains relatively high static power consumption regardless of utilization levels. The tightly coupled nature of GPU memory to processing units often results in over-provisioning scenarios where memory modules remain active even when not fully utilized, leading to suboptimal energy efficiency ratios.
Power density considerations further differentiate these memory architectures. CXL memory systems distribute power consumption across multiple discrete components, allowing for better thermal management and reduced cooling requirements. This distributed approach contrasts with GPU memory's concentrated power density, which necessitates sophisticated cooling solutions that contribute additional energy overhead to the overall system.
Memory access patterns in deep learning workloads significantly impact energy consumption profiles. CXL memory's ability to maintain data persistence across compute cycles reduces the energy overhead associated with frequent data transfers between storage and active memory. GPU memory systems, while offering lower latency access, often require more frequent data movement operations that contribute to higher overall energy consumption, particularly in large-scale training scenarios where memory capacity exceeds individual GPU limitations.
The scalability implications of energy efficiency become increasingly important in distributed deep learning environments. CXL memory architectures enable more efficient resource allocation across multiple compute nodes, reducing redundant memory provisioning and associated energy waste. This efficiency advantage becomes more pronounced as training clusters scale beyond traditional GPU-centric configurations.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!