

How Synthetic Data Generation Expands AI Training Datasets
MAR 17, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Synthetic Data Generation Background and AI Training Goals
Synthetic data generation has emerged as a transformative technology in artificial intelligence, fundamentally addressing the persistent challenge of data scarcity that has long constrained machine learning model development. This innovative approach involves creating artificial datasets that statistically mirror real-world data distributions while maintaining privacy and reducing dependency on costly data collection processes. The technology has evolved from simple statistical sampling methods to sophisticated generative models capable of producing highly realistic synthetic samples across various domains including computer vision, natural language processing, and structured data applications.
The historical development of synthetic data generation can be traced back to early statistical simulation techniques in the 1960s, but gained significant momentum with the advent of deep learning architectures. The introduction of Generative Adversarial Networks (GANs) in 2014 marked a pivotal breakthrough, enabling the creation of remarkably realistic synthetic images and subsequently expanding to other data modalities. Variational Autoencoders (VAEs) and more recently, diffusion models have further advanced the field, each contributing unique capabilities for generating high-quality synthetic data with improved controllability and diversity.
The evolution has progressed through distinct phases: from rule-based data augmentation techniques to probabilistic generative models, and now toward foundation models capable of generating multimodal synthetic data. Recent developments in large language models and vision transformers have opened new possibilities for creating contextually aware synthetic datasets that can capture complex relationships and semantic structures present in real-world data.
The primary technological objectives driving synthetic data generation research focus on achieving statistical fidelity, privacy preservation, and scalability. Statistical fidelity ensures that synthetic data maintains the essential characteristics and distributions of original datasets while introducing sufficient variation to enhance model generalization. Privacy preservation addresses critical concerns regarding sensitive data usage, enabling organizations to share and utilize datasets without compromising individual privacy or violating regulatory requirements.
Scalability objectives aim to generate large-scale synthetic datasets efficiently, reducing the computational overhead and time requirements associated with traditional data collection and annotation processes. Additionally, controllability has become a crucial goal, allowing researchers to generate targeted synthetic samples that address specific data imbalances or rare scenarios that are difficult to capture in natural datasets, ultimately enabling more robust and comprehensive AI model training.
The historical development of synthetic data generation can be traced back to early statistical simulation techniques in the 1960s, but gained significant momentum with the advent of deep learning architectures. The introduction of Generative Adversarial Networks (GANs) in 2014 marked a pivotal breakthrough, enabling the creation of remarkably realistic synthetic images and subsequently expanding to other data modalities. Variational Autoencoders (VAEs) and more recently, diffusion models have further advanced the field, each contributing unique capabilities for generating high-quality synthetic data with improved controllability and diversity.
The evolution has progressed through distinct phases: from rule-based data augmentation techniques to probabilistic generative models, and now toward foundation models capable of generating multimodal synthetic data. Recent developments in large language models and vision transformers have opened new possibilities for creating contextually aware synthetic datasets that can capture complex relationships and semantic structures present in real-world data.
The primary technological objectives driving synthetic data generation research focus on achieving statistical fidelity, privacy preservation, and scalability. Statistical fidelity ensures that synthetic data maintains the essential characteristics and distributions of original datasets while introducing sufficient variation to enhance model generalization. Privacy preservation addresses critical concerns regarding sensitive data usage, enabling organizations to share and utilize datasets without compromising individual privacy or violating regulatory requirements.
Scalability objectives aim to generate large-scale synthetic datasets efficiently, reducing the computational overhead and time requirements associated with traditional data collection and annotation processes. Additionally, controllability has become a crucial goal, allowing researchers to generate targeted synthetic samples that address specific data imbalances or rare scenarios that are difficult to capture in natural datasets, ultimately enabling more robust and comprehensive AI model training.
Market Demand for Enhanced AI Training Datasets
The global artificial intelligence industry faces an unprecedented demand for high-quality training datasets as machine learning models become increasingly sophisticated and data-hungry. Traditional data collection methods struggle to meet the exponential growth in data requirements, particularly as organizations deploy larger language models, computer vision systems, and multimodal AI applications across diverse sectors.
Enterprise adoption of AI technologies has accelerated dramatically, with organizations across healthcare, automotive, financial services, and manufacturing sectors requiring specialized datasets that reflect their unique operational contexts. The challenge intensifies when considering privacy regulations, data scarcity in niche domains, and the prohibitive costs associated with manual data annotation and collection processes.
Synthetic data generation emerges as a critical solution to address these market pressures. Organizations increasingly recognize that relying solely on real-world data creates bottlenecks in AI development cycles, limits model performance in edge cases, and exposes companies to significant privacy and compliance risks. The technology enables rapid dataset expansion while maintaining statistical properties essential for effective model training.
The healthcare sector demonstrates particularly acute demand for synthetic data solutions, where patient privacy regulations severely restrict access to real medical records and imaging data. Similarly, autonomous vehicle development requires vast amounts of diverse driving scenarios that would be impractical or dangerous to collect through traditional means. Financial institutions seek synthetic transaction data to train fraud detection models without exposing sensitive customer information.
Market dynamics reveal growing investment in synthetic data platforms and tools, driven by the recognition that data availability often determines competitive advantage in AI-driven markets. Organizations that can rapidly generate diverse, high-quality training datasets can accelerate their AI development timelines and achieve superior model performance compared to competitors constrained by traditional data acquisition methods.
The convergence of stricter data privacy regulations, increasing AI model complexity, and competitive pressures for faster deployment cycles creates a substantial and expanding market opportunity for synthetic data generation technologies across multiple industry verticals.
Enterprise adoption of AI technologies has accelerated dramatically, with organizations across healthcare, automotive, financial services, and manufacturing sectors requiring specialized datasets that reflect their unique operational contexts. The challenge intensifies when considering privacy regulations, data scarcity in niche domains, and the prohibitive costs associated with manual data annotation and collection processes.
Synthetic data generation emerges as a critical solution to address these market pressures. Organizations increasingly recognize that relying solely on real-world data creates bottlenecks in AI development cycles, limits model performance in edge cases, and exposes companies to significant privacy and compliance risks. The technology enables rapid dataset expansion while maintaining statistical properties essential for effective model training.
The healthcare sector demonstrates particularly acute demand for synthetic data solutions, where patient privacy regulations severely restrict access to real medical records and imaging data. Similarly, autonomous vehicle development requires vast amounts of diverse driving scenarios that would be impractical or dangerous to collect through traditional means. Financial institutions seek synthetic transaction data to train fraud detection models without exposing sensitive customer information.
Market dynamics reveal growing investment in synthetic data platforms and tools, driven by the recognition that data availability often determines competitive advantage in AI-driven markets. Organizations that can rapidly generate diverse, high-quality training datasets can accelerate their AI development timelines and achieve superior model performance compared to competitors constrained by traditional data acquisition methods.
The convergence of stricter data privacy regulations, increasing AI model complexity, and competitive pressures for faster deployment cycles creates a substantial and expanding market opportunity for synthetic data generation technologies across multiple industry verticals.
Current State and Challenges of Synthetic Data Generation
Synthetic data generation has emerged as a transformative technology in the artificial intelligence landscape, addressing critical limitations in traditional data collection methods. The current state of this field demonstrates significant maturity in computer vision applications, where generative adversarial networks (GANs) and variational autoencoders (VAEs) have proven highly effective in creating realistic images for training purposes. Major technology companies including NVIDIA, Google, and Microsoft have developed sophisticated platforms that can generate millions of synthetic images with controllable attributes, enabling AI models to train on diverse scenarios without privacy concerns or data scarcity issues.
The natural language processing domain has witnessed remarkable progress with the advent of large language models capable of generating contextually relevant text data. Transformer-based architectures have revolutionized synthetic text generation, allowing researchers to create training datasets for sentiment analysis, machine translation, and conversational AI systems. However, the quality and coherence of generated text remain variable across different domains and languages.
Despite these advances, synthetic data generation faces substantial technical challenges that limit its widespread adoption. Data quality remains the most pressing concern, as synthetic datasets often exhibit distribution shifts compared to real-world data, potentially leading to model performance degradation when deployed in production environments. The phenomenon known as "synthetic data cascade" poses another significant challenge, where models trained on synthetic data generate increasingly degraded outputs when used to create subsequent synthetic datasets.
Computational requirements present another major obstacle, as generating high-quality synthetic data demands substantial processing power and specialized hardware. The training of generative models requires extensive computational resources, making it economically challenging for smaller organizations to implement comprehensive synthetic data generation pipelines.
Validation and evaluation methodologies for synthetic data quality remain underdeveloped, creating uncertainty about the reliability and effectiveness of generated datasets. Current metrics often fail to capture subtle but important characteristics of real data, leading to potential blind spots in model training. Additionally, ensuring that synthetic data maintains the statistical properties and edge cases present in real-world scenarios continues to challenge researchers and practitioners across various domains.
The natural language processing domain has witnessed remarkable progress with the advent of large language models capable of generating contextually relevant text data. Transformer-based architectures have revolutionized synthetic text generation, allowing researchers to create training datasets for sentiment analysis, machine translation, and conversational AI systems. However, the quality and coherence of generated text remain variable across different domains and languages.
Despite these advances, synthetic data generation faces substantial technical challenges that limit its widespread adoption. Data quality remains the most pressing concern, as synthetic datasets often exhibit distribution shifts compared to real-world data, potentially leading to model performance degradation when deployed in production environments. The phenomenon known as "synthetic data cascade" poses another significant challenge, where models trained on synthetic data generate increasingly degraded outputs when used to create subsequent synthetic datasets.
Computational requirements present another major obstacle, as generating high-quality synthetic data demands substantial processing power and specialized hardware. The training of generative models requires extensive computational resources, making it economically challenging for smaller organizations to implement comprehensive synthetic data generation pipelines.
Validation and evaluation methodologies for synthetic data quality remain underdeveloped, creating uncertainty about the reliability and effectiveness of generated datasets. Current metrics often fail to capture subtle but important characteristics of real data, leading to potential blind spots in model training. Additionally, ensuring that synthetic data maintains the statistical properties and edge cases present in real-world scenarios continues to challenge researchers and practitioners across various domains.
Existing Synthetic Data Generation Solutions
01 Generative adversarial networks (GANs) for synthetic data generation
Generative adversarial networks can be employed to create synthetic data that mimics real-world data distributions. This approach involves training generator and discriminator networks in tandem to produce high-quality synthetic samples that can augment existing datasets. The generated data maintains statistical properties similar to original data while providing additional training examples for machine learning models.- Generative adversarial networks (GANs) for synthetic data generation: Generative adversarial networks can be employed to create synthetic data that mimics real-world data distributions. This approach involves training generator and discriminator networks in tandem to produce high-quality synthetic samples that can augment existing datasets. The generated data maintains statistical properties similar to original data while providing additional training examples for machine learning models.
- Data augmentation through transformation and perturbation techniques: Dataset expansion can be achieved by applying various transformation operations to existing data samples, including rotation, scaling, cropping, and noise injection. These techniques create variations of original data points while preserving essential characteristics and labels. Advanced perturbation methods can generate diverse synthetic samples that improve model robustness and generalization capabilities.
- Synthetic data generation using variational autoencoders and latent space manipulation: Variational autoencoders and latent space techniques enable the generation of synthetic data by learning compressed representations of input data and sampling from learned distributions. This methodology allows for controlled generation of new data points by manipulating latent variables, facilitating dataset expansion with diverse yet realistic samples that capture underlying data patterns.
- Domain-specific synthetic data generation for specialized applications: Specialized techniques can generate synthetic data tailored to specific domains such as medical imaging, autonomous driving, or natural language processing. These methods incorporate domain knowledge and constraints to produce realistic synthetic samples that address data scarcity issues in specialized fields. The generated data maintains domain-specific characteristics while expanding available training datasets.
- Privacy-preserving synthetic data generation and differential privacy techniques: Synthetic data generation methods can incorporate privacy-preserving mechanisms to create datasets that maintain utility while protecting sensitive information. These approaches use differential privacy, federated learning, or anonymization techniques to generate synthetic samples that cannot be traced back to individual records. Such methods enable dataset expansion while complying with data protection regulations and privacy requirements.
02 Data augmentation through transformation and perturbation techniques
Dataset expansion can be achieved by applying various transformation operations to existing data samples, including rotation, scaling, cropping, and noise injection. These techniques create variations of original data points while preserving essential characteristics and labels. Advanced perturbation methods can generate diverse synthetic samples that improve model robustness and generalization capabilities.Expand Specific Solutions03 Synthetic data generation using variational autoencoders and latent space manipulation
Variational autoencoders and latent space techniques enable the generation of synthetic data by learning compressed representations of input data and sampling from learned distributions. This methodology allows for controlled generation of new samples by manipulating latent variables, producing diverse synthetic data that expands training datasets while maintaining semantic consistency with original data.Expand Specific Solutions04 Domain-specific synthetic data generation for specialized applications
Specialized techniques can generate synthetic data tailored to specific domains such as medical imaging, autonomous driving, or natural language processing. These methods incorporate domain knowledge and constraints to produce realistic synthetic samples that address data scarcity issues in specialized fields. The generated data can supplement limited real-world datasets while maintaining domain-specific characteristics and requirements.Expand Specific Solutions05 Privacy-preserving synthetic data generation and differential privacy techniques
Synthetic data generation methods can incorporate privacy-preserving mechanisms to create datasets that maintain utility while protecting sensitive information. These approaches use differential privacy, anonymization, and other techniques to generate synthetic samples that preserve statistical properties without exposing individual data points. This enables dataset expansion while complying with privacy regulations and protecting confidential information.Expand Specific Solutions
Key Players in Synthetic Data and AI Training Industry
The synthetic data generation market is experiencing rapid growth as organizations seek to overcome data scarcity and privacy constraints in AI training. Currently in an expansion phase, the market spans multiple sectors from automotive to healthcare, with significant investment from both established tech giants and specialized startups. Major technology companies like NVIDIA, Google, Samsung Electronics, and Huawei are leveraging their computational infrastructure and AI expertise to develop sophisticated synthetic data solutions. Traditional automotive manufacturers including Hyundai, Kia, DENSO, and ZF Friedrichshafen are integrating synthetic data for autonomous vehicle training, while specialized companies like CUBIG, DataGen Technologies, and AGRISYNTH focus on domain-specific synthetic data generation. The technology maturity varies significantly across applications, with computer vision and autonomous driving showing advanced implementations, while emerging areas like healthcare and agriculture are still developing. Financial institutions such as Capital One and JP Morgan Chase are exploring synthetic data for regulatory compliance and model training, indicating growing enterprise adoption across regulated industries.
NVIDIA Corp.
Technical Solution: NVIDIA has developed comprehensive synthetic data generation solutions through their Omniverse platform and AI frameworks. Their approach leverages advanced GPU computing to create photorealistic synthetic datasets for computer vision, autonomous vehicles, and robotics applications. The company utilizes generative adversarial networks (GANs) and neural rendering techniques to produce high-fidelity synthetic images, 3D scenes, and sensor data that closely mimic real-world conditions. NVIDIA's synthetic data pipeline includes domain randomization, procedural generation, and physics-based simulation to ensure dataset diversity and quality for robust AI model training.
Strengths: Industry-leading GPU infrastructure, comprehensive toolchain, strong ecosystem partnerships. Weaknesses: High computational costs, requires specialized hardware expertise.
Tencent Technology (Shenzhen) Co., Ltd.
Technical Solution: Tencent has developed synthetic data generation technologies primarily for gaming, social media, and digital content applications. Their approach utilizes deep learning models trained on their vast gaming and social platform data to generate synthetic user interactions, game scenarios, and multimedia content. The company employs variational autoencoders and transformer-based models to create synthetic datasets for recommendation systems, content moderation, and user experience optimization. Tencent's synthetic data pipeline includes advanced techniques for generating realistic user behavior patterns, social network structures, and gaming environments that can be used to train AI models without exposing actual user data, supporting their privacy-first approach to AI development.
Strengths: Massive user data insights, strong gaming and social media domain knowledge, advanced deep learning capabilities. Weaknesses: Primarily focused on consumer applications, limited enterprise solutions.
Core Innovations in AI Dataset Expansion Technologies
Synthetic data generation for machine learning models
PatentActiveUS20240112045A1
Innovation
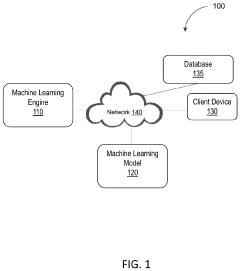
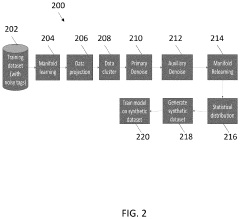
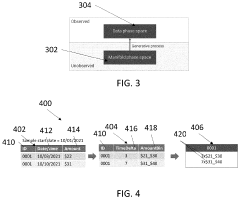
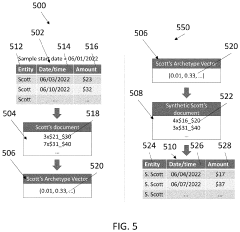
- A system and method for generating synthetic data by determining archetype probability distributions, clustering data points into transactional behavior patterns, removing non-representative data points, and generating updated archetype probability distributions to create representative transaction data, which is used to train machine learning models.
Synthetic data generation utilizing generative artifical intelligence and scalable data generation tools
PatentPendingUS20250238340A1
Innovation
- A combined approach using generative AI models to generate data parameters and scalable data generation tools (SDGTs) to produce synthetic data, with a lightweight model for generating coherent sentences, tailored to specific domains, reducing resource consumption and time.




Data Privacy Regulations Impact on Synthetic Data
The emergence of comprehensive data privacy regulations worldwide has fundamentally transformed the landscape for synthetic data generation and utilization. The European Union's General Data Protection Regulation (GDPR), implemented in 2018, established stringent requirements for personal data processing, including explicit consent mechanisms and the right to data erasure. Similarly, the California Consumer Privacy Act (CCPA) and its amendment, the California Privacy Rights Act (CPRA), have introduced comparable protections in the United States. These regulatory frameworks have created both challenges and opportunities for organizations seeking to leverage synthetic data for AI training purposes.
Under GDPR Article 4, personal data encompasses any information relating to an identified or identifiable natural person. This broad definition has prompted organizations to reconsider their data utilization strategies, as traditional datasets often contain personally identifiable information that requires careful handling. The regulation's emphasis on data minimization and purpose limitation has made synthetic data generation an attractive alternative, as properly generated synthetic datasets can preserve statistical properties while eliminating direct personal identifiers.
The concept of pseudonymization, as defined in GDPR Article 4(5), has particular relevance to synthetic data applications. While pseudonymized data still falls under regulatory scope, synthetic data that cannot be traced back to original individuals may offer greater operational flexibility. However, regulatory authorities have emphasized that the mere application of synthetic data generation techniques does not automatically exempt organizations from compliance obligations, particularly when the synthetic data retains characteristics that could enable re-identification.
Recent regulatory guidance from data protection authorities has clarified expectations for synthetic data usage. The UK Information Commissioner's Office has acknowledged that synthetic data can support privacy-preserving analytics while noting that organizations must demonstrate that re-identification risks have been adequately mitigated. Similarly, the French Commission Nationale de l'Informatique et des Libertés has provided frameworks for assessing whether synthetic datasets constitute personal data based on re-identification potential.
The regulatory emphasis on privacy-by-design principles has accelerated adoption of advanced synthetic data generation techniques that incorporate differential privacy mechanisms and other mathematical privacy guarantees. Organizations are increasingly required to conduct privacy impact assessments that evaluate the effectiveness of their synthetic data generation processes in protecting individual privacy while maintaining data utility for AI training applications.
Under GDPR Article 4, personal data encompasses any information relating to an identified or identifiable natural person. This broad definition has prompted organizations to reconsider their data utilization strategies, as traditional datasets often contain personally identifiable information that requires careful handling. The regulation's emphasis on data minimization and purpose limitation has made synthetic data generation an attractive alternative, as properly generated synthetic datasets can preserve statistical properties while eliminating direct personal identifiers.
The concept of pseudonymization, as defined in GDPR Article 4(5), has particular relevance to synthetic data applications. While pseudonymized data still falls under regulatory scope, synthetic data that cannot be traced back to original individuals may offer greater operational flexibility. However, regulatory authorities have emphasized that the mere application of synthetic data generation techniques does not automatically exempt organizations from compliance obligations, particularly when the synthetic data retains characteristics that could enable re-identification.
Recent regulatory guidance from data protection authorities has clarified expectations for synthetic data usage. The UK Information Commissioner's Office has acknowledged that synthetic data can support privacy-preserving analytics while noting that organizations must demonstrate that re-identification risks have been adequately mitigated. Similarly, the French Commission Nationale de l'Informatique et des Libertés has provided frameworks for assessing whether synthetic datasets constitute personal data based on re-identification potential.
The regulatory emphasis on privacy-by-design principles has accelerated adoption of advanced synthetic data generation techniques that incorporate differential privacy mechanisms and other mathematical privacy guarantees. Organizations are increasingly required to conduct privacy impact assessments that evaluate the effectiveness of their synthetic data generation processes in protecting individual privacy while maintaining data utility for AI training applications.
Quality Validation Methods for Synthetic Training Data
Quality validation of synthetic training data represents a critical bottleneck in the deployment of artificial intelligence systems, as the effectiveness of AI models fundamentally depends on the integrity and representativeness of their training datasets. The challenge lies in establishing robust methodologies that can systematically assess whether synthetically generated data maintains the statistical properties, diversity, and quality characteristics necessary for effective model training.
Statistical fidelity assessment forms the foundation of synthetic data validation, employing distribution comparison techniques such as Kolmogorov-Smirnov tests, Jensen-Shannon divergence, and Wasserstein distance metrics to quantify the similarity between synthetic and real data distributions. These methods evaluate whether synthetic datasets preserve the underlying statistical patterns of original data across multiple dimensions and feature spaces.
Privacy preservation validation ensures that synthetic data generation processes do not inadvertently leak sensitive information from original datasets. Membership inference attacks and attribute inference tests are employed to verify that individual records from the original dataset cannot be reconstructed or identified through the synthetic data, maintaining the privacy guarantees that synthetic data generation promises to deliver.
Downstream task performance evaluation provides the most practical validation approach by training machine learning models on synthetic datasets and comparing their performance against models trained on real data. This methodology assesses whether synthetic data maintains the predictive relationships and feature interactions necessary for successful model deployment across various application domains.
Cross-validation frameworks incorporate multiple validation dimensions simultaneously, combining statistical measures, privacy assessments, and performance evaluations into comprehensive quality scores. These frameworks often employ automated pipelines that can systematically evaluate synthetic datasets across predefined quality thresholds, enabling scalable validation processes for large-scale synthetic data generation initiatives.
Adversarial validation techniques utilize discriminator networks trained to distinguish between real and synthetic data samples, providing insights into the detectability and authenticity of generated datasets. When discriminators struggle to differentiate between real and synthetic samples, this indicates high-quality synthetic data generation that closely mimics the characteristics of original datasets.
Human expert evaluation remains essential for domain-specific validation, particularly in specialized fields where automated metrics may not capture nuanced quality requirements. Expert assessment protocols incorporate domain knowledge to evaluate whether synthetic data maintains the semantic coherence and contextual accuracy required for specific applications.
Statistical fidelity assessment forms the foundation of synthetic data validation, employing distribution comparison techniques such as Kolmogorov-Smirnov tests, Jensen-Shannon divergence, and Wasserstein distance metrics to quantify the similarity between synthetic and real data distributions. These methods evaluate whether synthetic datasets preserve the underlying statistical patterns of original data across multiple dimensions and feature spaces.
Privacy preservation validation ensures that synthetic data generation processes do not inadvertently leak sensitive information from original datasets. Membership inference attacks and attribute inference tests are employed to verify that individual records from the original dataset cannot be reconstructed or identified through the synthetic data, maintaining the privacy guarantees that synthetic data generation promises to deliver.
Downstream task performance evaluation provides the most practical validation approach by training machine learning models on synthetic datasets and comparing their performance against models trained on real data. This methodology assesses whether synthetic data maintains the predictive relationships and feature interactions necessary for successful model deployment across various application domains.
Cross-validation frameworks incorporate multiple validation dimensions simultaneously, combining statistical measures, privacy assessments, and performance evaluations into comprehensive quality scores. These frameworks often employ automated pipelines that can systematically evaluate synthetic datasets across predefined quality thresholds, enabling scalable validation processes for large-scale synthetic data generation initiatives.
Adversarial validation techniques utilize discriminator networks trained to distinguish between real and synthetic data samples, providing insights into the detectability and authenticity of generated datasets. When discriminators struggle to differentiate between real and synthetic samples, this indicates high-quality synthetic data generation that closely mimics the characteristics of original datasets.
Human expert evaluation remains essential for domain-specific validation, particularly in specialized fields where automated metrics may not capture nuanced quality requirements. Expert assessment protocols incorporate domain knowledge to evaluate whether synthetic data maintains the semantic coherence and contextual accuracy required for specific applications.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!