

Synthetic Data in Large-Scale Recommendation Systems
MAR 17, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Synthetic Data in Recommendation Systems Background and Objectives
The evolution of recommendation systems has been fundamentally shaped by the exponential growth of digital platforms and user-generated content over the past two decades. From early collaborative filtering approaches in the 1990s to sophisticated deep learning architectures today, recommendation systems have become critical infrastructure for digital commerce, content platforms, and social networks. The integration of synthetic data represents a paradigm shift in addressing longstanding challenges related to data scarcity, privacy constraints, and system scalability.
Traditional recommendation systems have relied heavily on historical user interaction data, which often suffers from inherent limitations including cold start problems, data sparsity, and privacy concerns. The emergence of synthetic data generation techniques, particularly those leveraging generative adversarial networks and variational autoencoders, has opened new possibilities for augmenting training datasets while preserving user privacy and enabling more robust model training.
The primary technical objective of incorporating synthetic data in large-scale recommendation systems centers on enhancing model performance through data augmentation while maintaining recommendation quality and relevance. This involves developing sophisticated generation mechanisms that can capture complex user behavior patterns, item relationships, and temporal dynamics present in real-world interaction data. The synthetic data must preserve statistical properties of original datasets while introducing beneficial variations that improve model generalization.
A critical objective involves addressing the cold start problem that plagues recommendation systems when dealing with new users or items with limited interaction history. Synthetic data generation can create plausible interaction patterns based on learned user archetypes and item characteristics, enabling systems to provide meaningful recommendations from the initial user engagement. This capability is particularly valuable for rapidly scaling platforms and seasonal content scenarios.
Privacy preservation represents another fundamental objective, as synthetic data can serve as a privacy-preserving alternative to sharing sensitive user interaction data across different system components or external partners. The goal is to generate synthetic datasets that maintain utility for model training while providing formal privacy guarantees through techniques such as differential privacy.
The scalability objective focuses on reducing computational overhead and storage requirements associated with processing massive real-world datasets. Synthetic data can be generated on-demand with specific characteristics tailored to particular training scenarios, potentially reducing the need for extensive data preprocessing and storage infrastructure while maintaining model training effectiveness.
Traditional recommendation systems have relied heavily on historical user interaction data, which often suffers from inherent limitations including cold start problems, data sparsity, and privacy concerns. The emergence of synthetic data generation techniques, particularly those leveraging generative adversarial networks and variational autoencoders, has opened new possibilities for augmenting training datasets while preserving user privacy and enabling more robust model training.
The primary technical objective of incorporating synthetic data in large-scale recommendation systems centers on enhancing model performance through data augmentation while maintaining recommendation quality and relevance. This involves developing sophisticated generation mechanisms that can capture complex user behavior patterns, item relationships, and temporal dynamics present in real-world interaction data. The synthetic data must preserve statistical properties of original datasets while introducing beneficial variations that improve model generalization.
A critical objective involves addressing the cold start problem that plagues recommendation systems when dealing with new users or items with limited interaction history. Synthetic data generation can create plausible interaction patterns based on learned user archetypes and item characteristics, enabling systems to provide meaningful recommendations from the initial user engagement. This capability is particularly valuable for rapidly scaling platforms and seasonal content scenarios.
Privacy preservation represents another fundamental objective, as synthetic data can serve as a privacy-preserving alternative to sharing sensitive user interaction data across different system components or external partners. The goal is to generate synthetic datasets that maintain utility for model training while providing formal privacy guarantees through techniques such as differential privacy.
The scalability objective focuses on reducing computational overhead and storage requirements associated with processing massive real-world datasets. Synthetic data can be generated on-demand with specific characteristics tailored to particular training scenarios, potentially reducing the need for extensive data preprocessing and storage infrastructure while maintaining model training effectiveness.
Market Demand for Large-Scale Personalized Recommendation Solutions
The global market for large-scale personalized recommendation solutions has experienced unprecedented growth driven by the exponential increase in digital content consumption and e-commerce activities. Organizations across industries are recognizing that personalized experiences directly correlate with customer engagement, retention rates, and revenue generation. This demand surge has created a substantial market opportunity for advanced recommendation technologies that can process massive datasets while delivering real-time, contextually relevant suggestions.
E-commerce platforms represent the largest segment of market demand, where recommendation systems directly impact conversion rates and average order values. Major online retailers have demonstrated that sophisticated recommendation engines can increase sales significantly by presenting customers with products aligned to their preferences and browsing behaviors. The streaming media industry follows closely, with content platforms requiring recommendation systems capable of handling millions of users and vast content libraries simultaneously.
Financial services institutions are increasingly adopting personalized recommendation solutions for product suggestions, investment advice, and risk management applications. The healthcare sector shows growing interest in recommendation systems for treatment protocols, drug interactions, and personalized care pathways. Social media platforms continue to drive demand for content recommendation technologies that can manage billions of user interactions and content pieces in real-time.
The market demand extends beyond traditional sectors into emerging areas such as autonomous vehicles, smart cities, and Internet of Things applications. These domains require recommendation systems that can process diverse data types including sensor data, behavioral patterns, and environmental factors. The integration of artificial intelligence and machine learning capabilities has become a fundamental requirement rather than a competitive advantage.
Enterprise adoption patterns indicate strong preference for solutions that can scale horizontally while maintaining low latency performance. Organizations demand recommendation systems that can handle peak traffic loads without degradation in recommendation quality or response times. Privacy compliance and data governance capabilities have become critical selection criteria, particularly in regulated industries where data handling requirements are stringent.
The market shows increasing sophistication in evaluation criteria, with organizations seeking solutions that provide explainable recommendations, support multi-objective optimization, and enable real-time model updates. Cross-platform compatibility and API-first architectures have become standard expectations as businesses operate across multiple digital touchpoints and require seamless integration capabilities.
E-commerce platforms represent the largest segment of market demand, where recommendation systems directly impact conversion rates and average order values. Major online retailers have demonstrated that sophisticated recommendation engines can increase sales significantly by presenting customers with products aligned to their preferences and browsing behaviors. The streaming media industry follows closely, with content platforms requiring recommendation systems capable of handling millions of users and vast content libraries simultaneously.
Financial services institutions are increasingly adopting personalized recommendation solutions for product suggestions, investment advice, and risk management applications. The healthcare sector shows growing interest in recommendation systems for treatment protocols, drug interactions, and personalized care pathways. Social media platforms continue to drive demand for content recommendation technologies that can manage billions of user interactions and content pieces in real-time.
The market demand extends beyond traditional sectors into emerging areas such as autonomous vehicles, smart cities, and Internet of Things applications. These domains require recommendation systems that can process diverse data types including sensor data, behavioral patterns, and environmental factors. The integration of artificial intelligence and machine learning capabilities has become a fundamental requirement rather than a competitive advantage.
Enterprise adoption patterns indicate strong preference for solutions that can scale horizontally while maintaining low latency performance. Organizations demand recommendation systems that can handle peak traffic loads without degradation in recommendation quality or response times. Privacy compliance and data governance capabilities have become critical selection criteria, particularly in regulated industries where data handling requirements are stringent.
The market shows increasing sophistication in evaluation criteria, with organizations seeking solutions that provide explainable recommendations, support multi-objective optimization, and enable real-time model updates. Cross-platform compatibility and API-first architectures have become standard expectations as businesses operate across multiple digital touchpoints and require seamless integration capabilities.
Current State and Challenges of Synthetic Data Generation
The current landscape of synthetic data generation for large-scale recommendation systems presents a complex ecosystem of evolving methodologies and persistent technical barriers. Traditional approaches primarily rely on statistical sampling techniques and rule-based generation methods, which often struggle to capture the intricate behavioral patterns and temporal dynamics inherent in user-item interactions. These conventional methods typically produce data that lacks the nuanced correlations found in real-world recommendation scenarios.
Generative Adversarial Networks (GANs) have emerged as a prominent solution, with specialized architectures like RecGAN and CFGAN designed specifically for recommendation data synthesis. However, these models face significant challenges in maintaining data utility while ensuring privacy preservation. The adversarial training process often suffers from mode collapse issues, resulting in synthetic datasets that inadequately represent minority user behaviors or long-tail item preferences.
Variational Autoencoders (VAEs) represent another mainstream approach, offering more stable training dynamics compared to GANs. Recent developments include Multinomial VAE and β-VAE variants that attempt to disentangle latent factors in user preferences. Despite these advances, VAEs frequently produce overly smoothed synthetic data that fails to capture the discrete nature of user-item interactions and the sparsity characteristics typical of recommendation datasets.
The integration of large language models and transformer architectures has introduced new possibilities for sequential recommendation data synthesis. These models excel at capturing temporal dependencies and contextual relationships but require substantial computational resources and often generate data with limited diversity in user behavior patterns.
Privacy preservation remains a critical constraint across all synthetic data generation approaches. Differential privacy mechanisms, while providing theoretical guarantees, often significantly degrade data utility. The trade-off between privacy protection and maintaining recommendation performance continues to challenge researchers and practitioners.
Scalability issues persist as a major bottleneck, particularly when dealing with millions of users and items. Most existing methods struggle to efficiently generate synthetic data that preserves both local user preferences and global system-wide patterns. The computational complexity of maintaining realistic user-item interaction distributions while scaling to industrial-level datasets represents a fundamental challenge that current technologies have yet to fully address.
Generative Adversarial Networks (GANs) have emerged as a prominent solution, with specialized architectures like RecGAN and CFGAN designed specifically for recommendation data synthesis. However, these models face significant challenges in maintaining data utility while ensuring privacy preservation. The adversarial training process often suffers from mode collapse issues, resulting in synthetic datasets that inadequately represent minority user behaviors or long-tail item preferences.
Variational Autoencoders (VAEs) represent another mainstream approach, offering more stable training dynamics compared to GANs. Recent developments include Multinomial VAE and β-VAE variants that attempt to disentangle latent factors in user preferences. Despite these advances, VAEs frequently produce overly smoothed synthetic data that fails to capture the discrete nature of user-item interactions and the sparsity characteristics typical of recommendation datasets.
The integration of large language models and transformer architectures has introduced new possibilities for sequential recommendation data synthesis. These models excel at capturing temporal dependencies and contextual relationships but require substantial computational resources and often generate data with limited diversity in user behavior patterns.
Privacy preservation remains a critical constraint across all synthetic data generation approaches. Differential privacy mechanisms, while providing theoretical guarantees, often significantly degrade data utility. The trade-off between privacy protection and maintaining recommendation performance continues to challenge researchers and practitioners.
Scalability issues persist as a major bottleneck, particularly when dealing with millions of users and items. Most existing methods struggle to efficiently generate synthetic data that preserves both local user preferences and global system-wide patterns. The computational complexity of maintaining realistic user-item interaction distributions while scaling to industrial-level datasets represents a fundamental challenge that current technologies have yet to fully address.
Existing Synthetic Data Generation Solutions for RecSys
01 Synthetic data generation for machine learning model training
Methods and systems for generating synthetic data to train machine learning models, particularly when real-world data is limited, expensive, or sensitive. The synthetic data is created using various algorithms and techniques to mimic the statistical properties and patterns of real data, enabling effective model training while preserving privacy and reducing data collection costs. This approach is especially useful in domains where obtaining large amounts of labeled training data is challenging.- Synthetic data generation for machine learning model training: Methods and systems for generating synthetic data to train machine learning models, particularly when real-world data is limited, expensive, or sensitive. The synthetic data is created using various algorithms and techniques to mimic the statistical properties and patterns of real data, enabling effective model training while preserving privacy and reducing data collection costs. This approach is especially useful in domains where obtaining large amounts of labeled training data is challenging.
- Privacy-preserving synthetic data generation: Techniques for generating synthetic datasets that maintain the utility of original data while protecting individual privacy. These methods employ differential privacy, anonymization, and other privacy-preserving mechanisms to ensure that synthetic data cannot be traced back to specific individuals. The generated data can be safely shared and used for analysis, testing, and research purposes without compromising sensitive information or violating privacy regulations.
- Synthetic data for testing and validation: Systems and methods for creating synthetic datasets specifically designed for software testing, system validation, and quality assurance purposes. The synthetic data can simulate various edge cases, rare scenarios, and stress conditions that may be difficult to capture in real-world data. This enables comprehensive testing of applications, databases, and systems without relying on production data, thereby reducing risks and improving software reliability.
- Generative models for synthetic data creation: Application of generative models, including generative adversarial networks and variational autoencoders, to produce high-quality synthetic data. These models learn the underlying distribution of real data and generate new samples that are statistically similar but not identical to the original dataset. The approach is applicable across various data types including images, text, time series, and structured data, providing flexible solutions for data augmentation and simulation.
- Synthetic data quality assessment and validation: Methods and metrics for evaluating the quality, fidelity, and utility of synthetically generated data. These techniques assess how well synthetic data preserves the statistical properties, correlations, and distributions of original data while measuring its effectiveness for intended applications. Quality assessment includes comparing synthetic and real data distributions, evaluating model performance trained on synthetic versus real data, and detecting potential biases or artifacts introduced during the generation process.
02 Privacy-preserving synthetic data generation
Techniques for creating synthetic datasets that maintain the utility of original data while protecting individual privacy. These methods employ differential privacy, anonymization, and other privacy-enhancing technologies to generate synthetic data that cannot be traced back to specific individuals. The generated data can be safely shared and used for analysis, testing, and research purposes without compromising sensitive information or violating privacy regulations.Expand Specific Solutions03 Synthetic data for testing and validation
Generation of synthetic datasets specifically designed for software testing, system validation, and quality assurance purposes. These synthetic datasets simulate various scenarios, edge cases, and data distributions that may be difficult or impossible to obtain from real-world sources. The approach enables comprehensive testing of systems, algorithms, and applications under controlled conditions, improving reliability and identifying potential issues before deployment.Expand Specific Solutions04 Generative models for synthetic data creation
Application of generative models, including generative adversarial networks and variational autoencoders, to produce high-quality synthetic data. These models learn the underlying distribution of real data and generate new samples that are statistically similar but not identical to the original data. The technology enables the creation of diverse and realistic synthetic datasets for various applications, including image generation, text synthesis, and structured data creation.Expand Specific Solutions05 Synthetic data augmentation and enhancement
Methods for augmenting existing datasets with synthetic data to improve model performance and robustness. This involves generating additional training examples that complement real data, addressing class imbalances, and creating variations that help models generalize better. The augmentation techniques can include transformations, interpolations, and generation of entirely new samples that expand the diversity and coverage of training datasets.Expand Specific Solutions
Key Players in Synthetic Data and Recommendation Industry
The synthetic data landscape in large-scale recommendation systems represents a rapidly evolving market driven by increasing privacy regulations and data scarcity challenges. The industry is in a growth phase, with market expansion fueled by enterprises seeking alternatives to traditional data collection methods. Technology maturity varies significantly across players, with established tech giants like NVIDIA Corp., Microsoft Technology Licensing LLC, and IBM leading in foundational AI infrastructure and synthetic data generation capabilities. Financial services companies including Capital One Services LLC and Fair Isaac Corp. are advancing domain-specific applications, while analytics specialists like SAS Institute demonstrate mature implementation frameworks. Chinese technology leaders such as Beijing Baidu Netcom and Alipay are developing region-specific solutions. The competitive landscape shows a mix of mature enterprise solutions and emerging specialized platforms, indicating a market transitioning from experimental to production-ready synthetic data technologies for recommendation systems.
International Business Machines Corp.
Technical Solution: IBM provides synthetic data generation capabilities for recommendation systems through their Watson AI platform and IBM Cloud services. Their approach emphasizes enterprise-grade privacy preservation and regulatory compliance, utilizing techniques such as differential privacy and federated learning combined with synthetic data generation. IBM's solution generates synthetic user profiles and interaction patterns that maintain statistical validity while ensuring GDPR and other privacy regulation compliance. The company's synthetic data toolkit supports various recommendation algorithms and provides comprehensive data quality assessment tools. Their enterprise focus includes robust governance frameworks and audit trails for synthetic data usage in production recommendation systems.
Strengths: Strong enterprise focus and compliance capabilities, comprehensive governance frameworks, extensive industry experience. Weaknesses: Higher costs compared to cloud-native solutions, complex implementation requirements.
NVIDIA Corp.
Technical Solution: NVIDIA develops comprehensive synthetic data generation platforms for recommendation systems, leveraging their Omniverse and AI simulation technologies. Their approach utilizes generative adversarial networks (GANs) and variational autoencoders (VAEs) to create realistic user behavior patterns and item interactions. The company's synthetic data solutions address privacy concerns while maintaining statistical properties of real user data, enabling better model training without exposing sensitive information. Their RAPIDS cuML library provides accelerated synthetic data generation capabilities, supporting large-scale recommendation workloads with GPU acceleration for faster processing and model iteration.
Strengths: Leading GPU acceleration technology, comprehensive AI platform ecosystem, strong performance in large-scale data processing. Weaknesses: High computational costs, dependency on specialized hardware infrastructure.
Core Innovations in Large-Scale Synthetic Data Patents
Synthetic data generation for service recommendation
PatentPendingUS20250124488A1
Innovation
- The system generates synthetic data that maintains statistical properties of real data while protecting sensitive information, using randomized and advanced machine learning techniques, and evaluates this synthetic data to ensure quality and privacy preservation.



Synthetic data generation for machine learning models
PatentActiveUS20240112045A1
Innovation
- A system and method for generating synthetic data by determining archetype probability distributions, clustering data points into transactional behavior patterns, removing non-representative data points, and generating updated archetype probability distributions to create representative transaction data, which is used to train machine learning models.
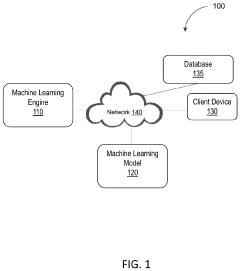
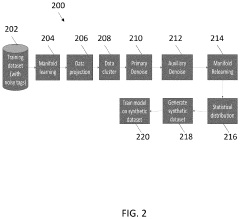
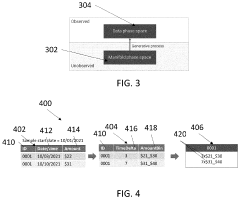
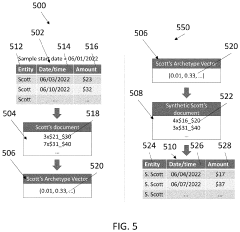
Privacy Regulations Impact on Synthetic Data Usage
The implementation of synthetic data in large-scale recommendation systems faces significant challenges from evolving privacy regulations worldwide. The General Data Protection Regulation (GDPR) in Europe has established stringent requirements for data processing, including synthetic data generation, particularly when it involves personal information or can be traced back to individual users. Under GDPR Article 4, synthetic data derived from personal data may still be considered personal data if it allows for re-identification of individuals, creating compliance complexities for recommendation system operators.
The California Consumer Privacy Act (CCPA) and its amendment, the California Privacy Rights Act (CPRA), have introduced additional layers of regulatory scrutiny in the United States. These regulations require organizations to demonstrate that synthetic data generation processes do not compromise user privacy rights, including the right to deletion and data portability. Recommendation systems must ensure that synthetic datasets cannot be reverse-engineered to reveal original user preferences or behaviors, necessitating advanced anonymization techniques and differential privacy mechanisms.
Emerging privacy frameworks in Asia-Pacific regions, including China's Personal Information Protection Law (PIPL) and India's proposed Data Protection Bill, are reshaping how synthetic data can be utilized in recommendation systems. These regulations emphasize data minimization principles and purpose limitation, requiring organizations to justify the necessity of synthetic data generation and ensure it serves legitimate business interests without excessive privacy intrusion.
The regulatory landscape has accelerated the adoption of privacy-preserving synthetic data generation techniques such as federated learning, homomorphic encryption, and secure multi-party computation. Organizations are increasingly investing in privacy-by-design approaches that embed regulatory compliance into the synthetic data pipeline from inception rather than as an afterthought.
Compliance costs and technical complexity have become significant factors in synthetic data strategy decisions. Organizations must balance the utility of synthetic data for improving recommendation accuracy against the risk of regulatory penalties and reputational damage. This has led to the development of privacy impact assessment frameworks specifically tailored for synthetic data applications in recommendation systems, ensuring that privacy considerations are systematically evaluated throughout the data lifecycle.
The California Consumer Privacy Act (CCPA) and its amendment, the California Privacy Rights Act (CPRA), have introduced additional layers of regulatory scrutiny in the United States. These regulations require organizations to demonstrate that synthetic data generation processes do not compromise user privacy rights, including the right to deletion and data portability. Recommendation systems must ensure that synthetic datasets cannot be reverse-engineered to reveal original user preferences or behaviors, necessitating advanced anonymization techniques and differential privacy mechanisms.
Emerging privacy frameworks in Asia-Pacific regions, including China's Personal Information Protection Law (PIPL) and India's proposed Data Protection Bill, are reshaping how synthetic data can be utilized in recommendation systems. These regulations emphasize data minimization principles and purpose limitation, requiring organizations to justify the necessity of synthetic data generation and ensure it serves legitimate business interests without excessive privacy intrusion.
The regulatory landscape has accelerated the adoption of privacy-preserving synthetic data generation techniques such as federated learning, homomorphic encryption, and secure multi-party computation. Organizations are increasingly investing in privacy-by-design approaches that embed regulatory compliance into the synthetic data pipeline from inception rather than as an afterthought.
Compliance costs and technical complexity have become significant factors in synthetic data strategy decisions. Organizations must balance the utility of synthetic data for improving recommendation accuracy against the risk of regulatory penalties and reputational damage. This has led to the development of privacy impact assessment frameworks specifically tailored for synthetic data applications in recommendation systems, ensuring that privacy considerations are systematically evaluated throughout the data lifecycle.
Ethical AI and Bias Mitigation in Synthetic Recommendations
The deployment of synthetic data in large-scale recommendation systems raises critical ethical considerations that demand systematic attention to bias mitigation and fairness preservation. As these systems increasingly influence user behavior and access to information, products, and services, the synthetic data generation process must incorporate robust ethical frameworks to prevent the amplification of existing societal biases and discrimination patterns.
Bias propagation represents one of the most significant ethical challenges in synthetic recommendation data. Traditional synthetic data generation methods often inherit and amplify biases present in the original training datasets, potentially leading to discriminatory outcomes across protected demographic groups. These biases can manifest in various forms, including demographic bias where certain user groups receive systematically different recommendation quality, popularity bias that over-represents mainstream content while marginalizing niche interests, and temporal bias that fails to account for evolving user preferences and societal changes.
The implementation of bias detection mechanisms requires comprehensive auditing frameworks that can identify unfair patterns across multiple dimensions simultaneously. Advanced statistical parity measures, equalized odds assessments, and individual fairness metrics must be integrated into the synthetic data validation pipeline. These mechanisms should evaluate not only direct demographic disparities but also intersectional biases that affect users belonging to multiple protected categories.
Fairness-aware synthetic data generation techniques have emerged as promising solutions to address these ethical concerns. Adversarial debiasing approaches utilize generative adversarial networks where discriminator components are specifically trained to detect and eliminate biased patterns during the synthetic data creation process. Constraint-based generation methods incorporate fairness objectives directly into the optimization function, ensuring that synthetic datasets maintain statistical parity across different user groups while preserving utility for recommendation tasks.
Privacy preservation intersects significantly with ethical considerations in synthetic recommendation systems. Differential privacy techniques must be carefully calibrated to protect individual user information while maintaining the statistical properties necessary for fair recommendations. The privacy-utility-fairness trade-off requires sophisticated balancing mechanisms that prevent the privacy protection process from inadvertently introducing or exacerbating bias against minority groups.
Transparency and explainability constitute essential components of ethical synthetic data deployment. Stakeholders must understand how synthetic data influences recommendation outcomes, particularly regarding potential bias sources and mitigation strategies. This includes developing interpretable models that can articulate why certain recommendations are generated and how synthetic data contributes to these decisions, enabling users to make informed choices about their engagement with recommendation systems.
Bias propagation represents one of the most significant ethical challenges in synthetic recommendation data. Traditional synthetic data generation methods often inherit and amplify biases present in the original training datasets, potentially leading to discriminatory outcomes across protected demographic groups. These biases can manifest in various forms, including demographic bias where certain user groups receive systematically different recommendation quality, popularity bias that over-represents mainstream content while marginalizing niche interests, and temporal bias that fails to account for evolving user preferences and societal changes.
The implementation of bias detection mechanisms requires comprehensive auditing frameworks that can identify unfair patterns across multiple dimensions simultaneously. Advanced statistical parity measures, equalized odds assessments, and individual fairness metrics must be integrated into the synthetic data validation pipeline. These mechanisms should evaluate not only direct demographic disparities but also intersectional biases that affect users belonging to multiple protected categories.
Fairness-aware synthetic data generation techniques have emerged as promising solutions to address these ethical concerns. Adversarial debiasing approaches utilize generative adversarial networks where discriminator components are specifically trained to detect and eliminate biased patterns during the synthetic data creation process. Constraint-based generation methods incorporate fairness objectives directly into the optimization function, ensuring that synthetic datasets maintain statistical parity across different user groups while preserving utility for recommendation tasks.
Privacy preservation intersects significantly with ethical considerations in synthetic recommendation systems. Differential privacy techniques must be carefully calibrated to protect individual user information while maintaining the statistical properties necessary for fair recommendations. The privacy-utility-fairness trade-off requires sophisticated balancing mechanisms that prevent the privacy protection process from inadvertently introducing or exacerbating bias against minority groups.
Transparency and explainability constitute essential components of ethical synthetic data deployment. Stakeholders must understand how synthetic data influences recommendation outcomes, particularly regarding potential bias sources and mitigation strategies. This includes developing interpretable models that can articulate why certain recommendations are generated and how synthetic data contributes to these decisions, enabling users to make informed choices about their engagement with recommendation systems.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!