

How to Improve Model Compression Efficiency on Embedded AI Accelerators
MAY 19, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Embedded AI Model Compression Background and Objectives
The evolution of artificial intelligence has witnessed a remarkable shift from cloud-centric computing to edge-based deployment, driven by the increasing demand for real-time processing, privacy preservation, and reduced latency in AI applications. This paradigm shift has brought embedded AI accelerators to the forefront of technological innovation, enabling intelligent processing capabilities in resource-constrained environments such as mobile devices, IoT sensors, automotive systems, and industrial automation equipment.
Embedded AI accelerators represent specialized hardware architectures designed to execute machine learning inference tasks efficiently within strict power, memory, and computational constraints. These devices typically feature optimized processing units, dedicated memory hierarchies, and specialized instruction sets tailored for neural network operations. However, the deployment of sophisticated AI models on such platforms presents significant challenges due to the inherent mismatch between model complexity and hardware limitations.
Model compression has emerged as a critical enabling technology to bridge this gap, encompassing various techniques including quantization, pruning, knowledge distillation, and architectural optimization. The historical development of compression methods has progressed from simple weight reduction strategies to sophisticated neural architecture search approaches, each addressing specific aspects of the size-performance trade-off inherent in embedded deployment scenarios.
The primary objective of improving model compression efficiency on embedded AI accelerators centers on achieving optimal balance between model accuracy retention and resource utilization optimization. This involves developing compression algorithms that can maximize inference speed while minimizing memory footprint and power consumption, without significantly degrading model performance. The challenge extends beyond mere size reduction to encompass hardware-aware optimization strategies that leverage specific architectural features of target accelerators.
Contemporary research efforts focus on co-design methodologies that simultaneously consider model architecture, compression techniques, and hardware characteristics. This holistic approach aims to unlock synergistic benefits by aligning algorithmic innovations with hardware capabilities, ultimately enabling deployment of increasingly sophisticated AI models on resource-constrained embedded platforms while maintaining acceptable performance standards for real-world applications.
Embedded AI accelerators represent specialized hardware architectures designed to execute machine learning inference tasks efficiently within strict power, memory, and computational constraints. These devices typically feature optimized processing units, dedicated memory hierarchies, and specialized instruction sets tailored for neural network operations. However, the deployment of sophisticated AI models on such platforms presents significant challenges due to the inherent mismatch between model complexity and hardware limitations.
Model compression has emerged as a critical enabling technology to bridge this gap, encompassing various techniques including quantization, pruning, knowledge distillation, and architectural optimization. The historical development of compression methods has progressed from simple weight reduction strategies to sophisticated neural architecture search approaches, each addressing specific aspects of the size-performance trade-off inherent in embedded deployment scenarios.
The primary objective of improving model compression efficiency on embedded AI accelerators centers on achieving optimal balance between model accuracy retention and resource utilization optimization. This involves developing compression algorithms that can maximize inference speed while minimizing memory footprint and power consumption, without significantly degrading model performance. The challenge extends beyond mere size reduction to encompass hardware-aware optimization strategies that leverage specific architectural features of target accelerators.
Contemporary research efforts focus on co-design methodologies that simultaneously consider model architecture, compression techniques, and hardware characteristics. This holistic approach aims to unlock synergistic benefits by aligning algorithmic innovations with hardware capabilities, ultimately enabling deployment of increasingly sophisticated AI models on resource-constrained embedded platforms while maintaining acceptable performance standards for real-world applications.
Market Demand for Efficient Edge AI Solutions
The global edge AI market is experiencing unprecedented growth driven by the proliferation of IoT devices, autonomous systems, and real-time processing requirements across multiple industries. Organizations are increasingly seeking to deploy AI capabilities directly on edge devices rather than relying on cloud-based processing, creating substantial demand for efficient embedded AI solutions that can operate within strict power, latency, and computational constraints.
Smart manufacturing represents a significant market segment where efficient edge AI solutions are critical for predictive maintenance, quality control, and process optimization. Industrial equipment requires real-time decision-making capabilities without the latency associated with cloud connectivity, driving demand for compressed AI models that can operate on resource-constrained industrial controllers and embedded processors.
The automotive industry presents another major growth area, particularly with the advancement of autonomous driving technologies and advanced driver assistance systems. Vehicle manufacturers require AI models that can process sensor data in real-time while operating within the power and thermal limitations of automotive computing platforms. Model compression efficiency directly impacts the feasibility of deploying sophisticated AI capabilities in vehicles.
Consumer electronics manufacturers are integrating AI functionality into smartphones, smart home devices, wearables, and IoT sensors. These applications demand highly efficient AI models that preserve battery life while delivering responsive performance. The competitive pressure to offer AI-enhanced features in cost-sensitive consumer products creates strong market pull for advanced compression techniques.
Healthcare and medical device sectors are adopting edge AI for patient monitoring, diagnostic imaging, and portable medical equipment. Regulatory requirements and privacy concerns drive the need for on-device processing, while medical device constraints necessitate extremely efficient model implementations that maintain clinical accuracy.
The telecommunications industry is deploying edge AI solutions for network optimization, predictive maintenance, and enhanced services delivery. With the rollout of 5G networks and edge computing infrastructure, telecom operators require efficient AI models that can operate on distributed edge nodes with varying computational capabilities.
Market research indicates that organizations prioritize solutions offering significant model size reduction while maintaining accuracy, reduced inference latency, and lower power consumption. The convergence of these requirements creates substantial commercial opportunities for advanced model compression technologies specifically optimized for embedded AI accelerators.
Smart manufacturing represents a significant market segment where efficient edge AI solutions are critical for predictive maintenance, quality control, and process optimization. Industrial equipment requires real-time decision-making capabilities without the latency associated with cloud connectivity, driving demand for compressed AI models that can operate on resource-constrained industrial controllers and embedded processors.
The automotive industry presents another major growth area, particularly with the advancement of autonomous driving technologies and advanced driver assistance systems. Vehicle manufacturers require AI models that can process sensor data in real-time while operating within the power and thermal limitations of automotive computing platforms. Model compression efficiency directly impacts the feasibility of deploying sophisticated AI capabilities in vehicles.
Consumer electronics manufacturers are integrating AI functionality into smartphones, smart home devices, wearables, and IoT sensors. These applications demand highly efficient AI models that preserve battery life while delivering responsive performance. The competitive pressure to offer AI-enhanced features in cost-sensitive consumer products creates strong market pull for advanced compression techniques.
Healthcare and medical device sectors are adopting edge AI for patient monitoring, diagnostic imaging, and portable medical equipment. Regulatory requirements and privacy concerns drive the need for on-device processing, while medical device constraints necessitate extremely efficient model implementations that maintain clinical accuracy.
The telecommunications industry is deploying edge AI solutions for network optimization, predictive maintenance, and enhanced services delivery. With the rollout of 5G networks and edge computing infrastructure, telecom operators require efficient AI models that can operate on distributed edge nodes with varying computational capabilities.
Market research indicates that organizations prioritize solutions offering significant model size reduction while maintaining accuracy, reduced inference latency, and lower power consumption. The convergence of these requirements creates substantial commercial opportunities for advanced model compression technologies specifically optimized for embedded AI accelerators.
Current Compression Challenges on Embedded Accelerators
Embedded AI accelerators face significant computational and memory constraints that create unique challenges for model compression implementation. These specialized processors, designed for edge computing applications, typically operate with limited memory bandwidth, restricted storage capacity, and power consumption constraints that directly impact compression algorithm performance.
Memory bandwidth limitations represent one of the most critical bottlenecks in embedded compression workflows. Traditional compression techniques often require multiple data passes and intermediate storage of compressed representations, which can overwhelm the limited memory subsystems of embedded accelerators. The frequent data movement between different memory hierarchies introduces substantial latency overhead that negates potential compression benefits.
Hardware heterogeneity across different embedded accelerator architectures creates compatibility challenges for compression algorithms. Each accelerator family, whether based on ARM processors, dedicated neural processing units, or FPGA implementations, exhibits distinct instruction sets, memory architectures, and optimization requirements. This diversity makes it difficult to develop universally applicable compression solutions that maintain efficiency across platforms.
Real-time processing requirements impose strict timing constraints that conflict with compression overhead. Many embedded AI applications demand deterministic inference latency, but compression and decompression operations introduce variable processing delays. Dynamic compression techniques that adapt to input characteristics can cause unpredictable timing variations that violate real-time system requirements.
Quantization precision limitations on embedded hardware restrict the effectiveness of certain compression approaches. While aggressive quantization can significantly reduce model size, embedded accelerators often lack sufficient precision control or specialized arithmetic units to handle mixed-precision operations efficiently. This constraint forces developers to choose between compression ratio and computational accuracy.
Power consumption considerations add another layer of complexity to compression implementation. The energy cost of compression and decompression operations must be weighed against the benefits of reduced memory access and computation. In battery-powered devices, compression algorithms that consume excessive power during execution may actually decrease overall system efficiency despite reducing model size.
Integration challenges arise when attempting to incorporate compression techniques into existing embedded software stacks and development toolchains. Many compression methods require specialized libraries or runtime support that may not be available or optimized for target embedded platforms, creating deployment barriers for practical applications.
Memory bandwidth limitations represent one of the most critical bottlenecks in embedded compression workflows. Traditional compression techniques often require multiple data passes and intermediate storage of compressed representations, which can overwhelm the limited memory subsystems of embedded accelerators. The frequent data movement between different memory hierarchies introduces substantial latency overhead that negates potential compression benefits.
Hardware heterogeneity across different embedded accelerator architectures creates compatibility challenges for compression algorithms. Each accelerator family, whether based on ARM processors, dedicated neural processing units, or FPGA implementations, exhibits distinct instruction sets, memory architectures, and optimization requirements. This diversity makes it difficult to develop universally applicable compression solutions that maintain efficiency across platforms.
Real-time processing requirements impose strict timing constraints that conflict with compression overhead. Many embedded AI applications demand deterministic inference latency, but compression and decompression operations introduce variable processing delays. Dynamic compression techniques that adapt to input characteristics can cause unpredictable timing variations that violate real-time system requirements.
Quantization precision limitations on embedded hardware restrict the effectiveness of certain compression approaches. While aggressive quantization can significantly reduce model size, embedded accelerators often lack sufficient precision control or specialized arithmetic units to handle mixed-precision operations efficiently. This constraint forces developers to choose between compression ratio and computational accuracy.
Power consumption considerations add another layer of complexity to compression implementation. The energy cost of compression and decompression operations must be weighed against the benefits of reduced memory access and computation. In battery-powered devices, compression algorithms that consume excessive power during execution may actually decrease overall system efficiency despite reducing model size.
Integration challenges arise when attempting to incorporate compression techniques into existing embedded software stacks and development toolchains. Many compression methods require specialized libraries or runtime support that may not be available or optimized for target embedded platforms, creating deployment barriers for practical applications.
Existing Model Compression Solutions for Edge Devices
01 Neural network pruning and sparsity techniques
Techniques for reducing model size by removing redundant or less important connections, weights, or neurons from neural networks. These methods identify and eliminate parameters that contribute minimally to model performance, resulting in sparse network architectures that maintain accuracy while significantly reducing computational requirements and memory footprint.- Neural network pruning and sparsity optimization: Techniques for removing redundant connections and parameters from neural networks to reduce model size while maintaining performance. This includes structured and unstructured pruning methods that eliminate unnecessary weights and neurons, creating sparse network architectures that require less memory and computational resources during inference.
- Quantization and bit-width reduction methods: Approaches to reduce the precision of model parameters and activations from floating-point to lower bit representations. These methods compress models by converting weights and activations to reduced precision formats while implementing compensation techniques to minimize accuracy degradation during the quantization process.
- Knowledge distillation and model compression: Techniques that transfer knowledge from large teacher models to smaller student models, enabling the creation of compact networks that retain much of the original model's performance. This approach involves training lightweight models to mimic the behavior and outputs of more complex networks through specialized loss functions and training procedures.
- Efficient encoding and data compression algorithms: Advanced compression algorithms specifically designed for model parameters and network architectures. These methods utilize entropy coding, dictionary-based compression, and specialized encoding schemes to achieve high compression ratios while enabling fast decompression during model deployment and inference operations.
- Hardware-aware optimization and acceleration: Compression techniques that consider specific hardware constraints and capabilities to optimize model deployment on target devices. These methods adapt compression strategies based on memory bandwidth, processing capabilities, and power consumption requirements of different hardware platforms including mobile devices and embedded systems.
02 Quantization and bit-width reduction methods
Approaches that reduce the precision of model parameters and activations from higher bit representations to lower bit formats. These techniques compress models by representing weights and computations using fewer bits while preserving model functionality, enabling deployment on resource-constrained devices with reduced memory and computational overhead.Expand Specific Solutions03 Knowledge distillation and teacher-student frameworks
Methods that transfer knowledge from large, complex models to smaller, more efficient ones through training processes where compact student networks learn to mimic the behavior of larger teacher networks. This approach enables the creation of lightweight models that retain much of the original model's performance while being significantly more efficient.Expand Specific Solutions04 Matrix decomposition and low-rank approximation
Techniques that decompose weight matrices into smaller, lower-rank representations to reduce parameter count and computational complexity. These methods exploit redundancy in model parameters by approximating large matrices with combinations of smaller matrices, achieving compression while maintaining model expressiveness and performance.Expand Specific Solutions05 Hardware-aware compression and optimization
Compression strategies specifically designed to optimize models for particular hardware architectures and deployment constraints. These approaches consider target device capabilities, memory limitations, and computational resources to achieve optimal compression ratios while ensuring efficient execution on specific platforms such as mobile devices, embedded systems, or specialized accelerators.Expand Specific Solutions
Key Players in Embedded AI and Compression Technology
The model compression efficiency landscape for embedded AI accelerators represents a rapidly evolving competitive arena currently in its growth phase, driven by increasing demand for edge AI deployment across mobile devices, IoT systems, and autonomous vehicles. The market demonstrates significant expansion potential as enterprises seek to balance computational performance with power constraints. Technology maturity varies considerably among key players, with established semiconductor giants like NVIDIA, Intel, and Samsung leading through comprehensive hardware-software ecosystems, while specialized firms such as Nota and SAPEON focus on targeted compression solutions. Chinese companies including Huawei, Baidu, and Suiyuan Technology are advancing rapidly with proprietary architectures, and major device manufacturers like Apple and Vivo integrate custom silicon solutions. Academic institutions like Carnegie Mellon University contribute foundational research, creating a diverse ecosystem where traditional chip makers compete alongside AI-focused startups and vertically integrated technology companies.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei's model compression approach leverages their Ascend AI processors and MindSpore framework to optimize neural networks for embedded deployment. Their solution incorporates adaptive quantization algorithms that automatically select optimal bit-widths for different layers, achieving 8x compression ratios while maintaining 95% of original model accuracy. The MindSpore framework supports dynamic pruning during training, enabling real-time model optimization that reduces computational complexity by 60-80%. Huawei's compression pipeline includes tensor decomposition techniques and efficient convolution algorithms optimized for their NPU architecture. Their Ascend 310 AI processor delivers 22 TOPS INT8 performance at 8W power consumption, specifically designed for edge inference scenarios with compressed models.
Strengths: Integrated hardware-software optimization, advanced NPU architecture, comprehensive AI development ecosystem. Weaknesses: Limited global availability due to trade restrictions, smaller third-party developer community compared to competitors.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung develops model compression solutions through their Exynos Neural Processing Unit (NPU) and optimization frameworks for mobile and embedded AI applications. Their approach includes hardware-aware quantization that adapts compression levels based on NPU capabilities, achieving 6x model size reduction with minimal accuracy degradation. Samsung's compression toolkit supports channel pruning and weight sharing techniques that reduce memory bandwidth requirements by 70%, crucial for mobile AI accelerators. Their solution incorporates efficient batch normalization folding and activation function optimization specifically designed for their NPU architecture. The Exynos 2200 with AMD RDNA2 GPU and dedicated NPU delivers 26 TOPS AI performance while maintaining power efficiency for mobile devices, supporting real-time inference of compressed deep learning models.
Strengths: Mobile-optimized AI acceleration, integrated SoC design expertise, strong manufacturing capabilities. Weaknesses: Limited presence in dedicated AI accelerator market, focus primarily on consumer electronics applications.
Core Innovations in Hardware-Aware Compression Methods
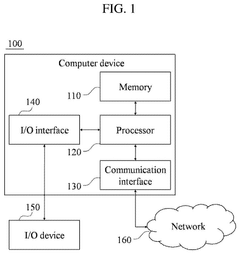
Apparatus and method for optimizing artificial intelligence model loading in embedded environment
PatentPendingUS20240330683A1
Innovation
- A loading optimization method that partitions deep learning models into multiple blocks using reinforcement learning-based techniques, specifically employing the DDPG algorithm to determine optimal partition scenarios that satisfy memory constraints and minimize computational requirements, allowing for efficient loading and execution in embedded devices.




Method and system for lightening model for optimizing to equipment- friendly model
PatentPendingUS20250029002A1
Innovation
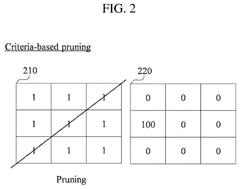
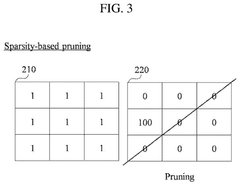
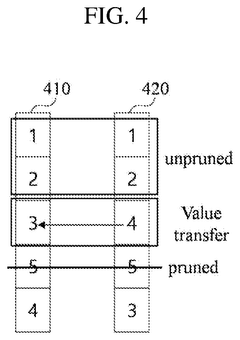
- A model compression method that combines unstructured pruning with structured pruning, using criteria and sparsity to determine filters for pruning, thereby generating a compressed AI model that can be optimized for equipment-friendly performance.
Power Efficiency Standards for Embedded AI Systems
Power efficiency standards for embedded AI systems have become increasingly critical as the demand for edge computing applications continues to surge across industries. The proliferation of IoT devices, autonomous vehicles, and smart sensors has necessitated the development of comprehensive frameworks that govern energy consumption while maintaining computational performance. Current industry standards primarily focus on establishing baseline metrics for power consumption per operation, thermal management protocols, and battery life optimization strategies.
The IEEE 2857 standard represents one of the most significant developments in this domain, providing guidelines for energy-efficient AI hardware design and implementation. This standard emphasizes the importance of dynamic voltage and frequency scaling (DVFS) techniques, which allow processors to adjust their operating parameters based on workload requirements. Additionally, the standard mandates specific power measurement methodologies that ensure consistent evaluation across different hardware platforms and AI accelerator architectures.
Regulatory bodies have established tiered classification systems that categorize embedded AI devices based on their power consumption profiles. Class A devices, typically consuming less than 1 watt, are designed for ultra-low-power applications such as wearable sensors and environmental monitoring systems. Class B devices operate within the 1-10 watt range and are commonly found in smart home appliances and industrial automation equipment. Class C devices, consuming 10-50 watts, are utilized in more computationally intensive applications like real-time video processing and autonomous navigation systems.
Compliance with these power efficiency standards requires manufacturers to implement sophisticated power management units (PMUs) that can monitor and control energy distribution across different system components. Modern embedded AI accelerators must incorporate features such as clock gating, power islands, and adaptive voltage scaling to meet stringent efficiency requirements. Furthermore, thermal design power (TDP) specifications have become mandatory reporting metrics, ensuring that devices operate within safe temperature ranges while maximizing computational throughput.
The emergence of specialized benchmarking suites, including MLPerf Tiny and EEMBC EnergyBench, has standardized the evaluation process for power-efficient AI systems. These benchmarks provide standardized workloads and measurement protocols that enable fair comparison between different hardware solutions and ensure adherence to established power efficiency criteria across the embedded AI ecosystem.
The IEEE 2857 standard represents one of the most significant developments in this domain, providing guidelines for energy-efficient AI hardware design and implementation. This standard emphasizes the importance of dynamic voltage and frequency scaling (DVFS) techniques, which allow processors to adjust their operating parameters based on workload requirements. Additionally, the standard mandates specific power measurement methodologies that ensure consistent evaluation across different hardware platforms and AI accelerator architectures.
Regulatory bodies have established tiered classification systems that categorize embedded AI devices based on their power consumption profiles. Class A devices, typically consuming less than 1 watt, are designed for ultra-low-power applications such as wearable sensors and environmental monitoring systems. Class B devices operate within the 1-10 watt range and are commonly found in smart home appliances and industrial automation equipment. Class C devices, consuming 10-50 watts, are utilized in more computationally intensive applications like real-time video processing and autonomous navigation systems.
Compliance with these power efficiency standards requires manufacturers to implement sophisticated power management units (PMUs) that can monitor and control energy distribution across different system components. Modern embedded AI accelerators must incorporate features such as clock gating, power islands, and adaptive voltage scaling to meet stringent efficiency requirements. Furthermore, thermal design power (TDP) specifications have become mandatory reporting metrics, ensuring that devices operate within safe temperature ranges while maximizing computational throughput.
The emergence of specialized benchmarking suites, including MLPerf Tiny and EEMBC EnergyBench, has standardized the evaluation process for power-efficient AI systems. These benchmarks provide standardized workloads and measurement protocols that enable fair comparison between different hardware solutions and ensure adherence to established power efficiency criteria across the embedded AI ecosystem.
Hardware-Software Co-design for Compression Optimization
Hardware-software co-design represents a paradigm shift in optimizing model compression for embedded AI accelerators, where traditional sequential development approaches give way to integrated design methodologies. This approach recognizes that compression efficiency cannot be maximized through software algorithms or hardware architectures alone, but requires deep integration between both domains from the earliest design stages.
The co-design methodology begins with establishing unified optimization objectives that simultaneously consider compression ratio, inference latency, energy consumption, and hardware resource utilization. Unlike conventional approaches where software compression algorithms are developed independently and later mapped to hardware, co-design enables compression strategies to be tailored specifically to the target accelerator's architectural characteristics, including memory hierarchy, computational units, and data flow patterns.
Critical to this approach is the development of hardware-aware compression algorithms that leverage specific accelerator features. For instance, compression schemes can be designed to align with the accelerator's native data types, memory access patterns, and parallel processing capabilities. This includes optimizing quantization schemes to match hardware precision support, designing pruning patterns that maximize hardware utilization efficiency, and developing compression formats that minimize memory bandwidth requirements.
The co-design process also involves creating specialized hardware features that directly support compression operations. This includes dedicated decompression units, optimized memory controllers for compressed data formats, and reconfigurable processing elements that can adapt to different compression schemes. These hardware enhancements are designed concurrently with compression algorithms to ensure optimal synergy.
Compiler and runtime system optimization forms another crucial component, where the software stack is designed to automatically exploit hardware compression features. This includes developing compression-aware scheduling algorithms, optimizing data layout for compressed formats, and implementing dynamic compression adaptation based on runtime conditions and hardware resource availability.
The validation and optimization cycle in co-design involves iterative refinement of both hardware and software components based on comprehensive performance analysis. This holistic approach enables identification of bottlenecks that span hardware-software boundaries and facilitates system-level optimizations that would be impossible to achieve through isolated component optimization.
The co-design methodology begins with establishing unified optimization objectives that simultaneously consider compression ratio, inference latency, energy consumption, and hardware resource utilization. Unlike conventional approaches where software compression algorithms are developed independently and later mapped to hardware, co-design enables compression strategies to be tailored specifically to the target accelerator's architectural characteristics, including memory hierarchy, computational units, and data flow patterns.
Critical to this approach is the development of hardware-aware compression algorithms that leverage specific accelerator features. For instance, compression schemes can be designed to align with the accelerator's native data types, memory access patterns, and parallel processing capabilities. This includes optimizing quantization schemes to match hardware precision support, designing pruning patterns that maximize hardware utilization efficiency, and developing compression formats that minimize memory bandwidth requirements.
The co-design process also involves creating specialized hardware features that directly support compression operations. This includes dedicated decompression units, optimized memory controllers for compressed data formats, and reconfigurable processing elements that can adapt to different compression schemes. These hardware enhancements are designed concurrently with compression algorithms to ensure optimal synergy.
Compiler and runtime system optimization forms another crucial component, where the software stack is designed to automatically exploit hardware compression features. This includes developing compression-aware scheduling algorithms, optimizing data layout for compressed formats, and implementing dynamic compression adaptation based on runtime conditions and hardware resource availability.
The validation and optimization cycle in co-design involves iterative refinement of both hardware and software components based on comprehensive performance analysis. This holistic approach enables identification of bottlenecks that span hardware-software boundaries and facilitates system-level optimizations that would be impossible to achieve through isolated component optimization.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!