

How to Leverage Data Lakes with SCADA Data
MAR 13, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
SCADA Data Lake Integration Background and Objectives
SCADA (Supervisory Control and Data Acquisition) systems have evolved from simple monitoring tools into sophisticated data generation platforms that produce vast amounts of operational intelligence across industrial sectors. Originally designed for real-time control and monitoring of industrial processes, SCADA systems now generate terabytes of time-series data, alarm logs, historical trends, and operational metrics that contain invaluable insights for business optimization and predictive maintenance strategies.
The exponential growth in SCADA data volume, driven by increased sensor deployment and higher sampling frequencies, has created significant challenges for traditional data storage and analysis approaches. Legacy SCADA historians and relational databases struggle with scalability limitations, rigid schema requirements, and prohibitive storage costs when handling multi-year datasets from complex industrial operations.
Data lakes have emerged as a transformative solution for managing this data explosion, offering virtually unlimited storage capacity, schema-on-read flexibility, and cost-effective archival capabilities. Unlike traditional data warehouses, data lakes can accommodate the diverse data formats typical in SCADA environments, including structured time-series data, semi-structured configuration files, and unstructured maintenance logs.
The primary objective of integrating SCADA data with data lake architectures is to unlock advanced analytics capabilities that were previously impossible due to data silos and storage constraints. This integration enables organizations to perform comprehensive historical analysis, implement machine learning algorithms for predictive maintenance, and correlate operational data with business metrics across extended timeframes.
Key technical objectives include establishing real-time data ingestion pipelines that can handle high-velocity SCADA streams while maintaining data integrity and chronological accuracy. The integration must preserve critical SCADA data characteristics such as timestamp precision, data quality indicators, and alarm context that are essential for operational decision-making.
Strategic business objectives encompass reducing total cost of ownership for data storage, enabling cross-functional analytics teams to access operational data, and creating a foundation for digital transformation initiatives. Organizations seek to leverage this integrated approach to improve operational efficiency, reduce unplanned downtime, and optimize asset performance through data-driven insights that span multiple operational domains and extended historical periods.
The exponential growth in SCADA data volume, driven by increased sensor deployment and higher sampling frequencies, has created significant challenges for traditional data storage and analysis approaches. Legacy SCADA historians and relational databases struggle with scalability limitations, rigid schema requirements, and prohibitive storage costs when handling multi-year datasets from complex industrial operations.
Data lakes have emerged as a transformative solution for managing this data explosion, offering virtually unlimited storage capacity, schema-on-read flexibility, and cost-effective archival capabilities. Unlike traditional data warehouses, data lakes can accommodate the diverse data formats typical in SCADA environments, including structured time-series data, semi-structured configuration files, and unstructured maintenance logs.
The primary objective of integrating SCADA data with data lake architectures is to unlock advanced analytics capabilities that were previously impossible due to data silos and storage constraints. This integration enables organizations to perform comprehensive historical analysis, implement machine learning algorithms for predictive maintenance, and correlate operational data with business metrics across extended timeframes.
Key technical objectives include establishing real-time data ingestion pipelines that can handle high-velocity SCADA streams while maintaining data integrity and chronological accuracy. The integration must preserve critical SCADA data characteristics such as timestamp precision, data quality indicators, and alarm context that are essential for operational decision-making.
Strategic business objectives encompass reducing total cost of ownership for data storage, enabling cross-functional analytics teams to access operational data, and creating a foundation for digital transformation initiatives. Organizations seek to leverage this integrated approach to improve operational efficiency, reduce unplanned downtime, and optimize asset performance through data-driven insights that span multiple operational domains and extended historical periods.
Industrial Data Analytics Market Demand Analysis
The industrial data analytics market is experiencing unprecedented growth driven by the convergence of digital transformation initiatives and the increasing complexity of industrial operations. Manufacturing enterprises across sectors are recognizing the critical importance of data-driven decision making to maintain competitive advantages in rapidly evolving markets. The proliferation of Industrial Internet of Things devices and smart manufacturing technologies has created an exponential increase in data generation, necessitating sophisticated analytics solutions to extract actionable insights.
SCADA systems generate massive volumes of real-time operational data that traditionally remained siloed within control systems. Organizations are now seeking comprehensive solutions to unlock the value of this historical and streaming data through advanced analytics platforms. The demand for integrating SCADA data with broader enterprise data ecosystems has intensified as companies pursue holistic operational intelligence strategies.
Key market drivers include the urgent need for predictive maintenance capabilities to minimize unplanned downtime and optimize asset performance. Industrial organizations are increasingly focused on reducing operational costs while improving safety standards and regulatory compliance. The growing emphasis on sustainability and energy efficiency has further amplified demand for sophisticated data analytics solutions that can identify optimization opportunities across complex industrial processes.
The market demonstrates strong demand for scalable data lake architectures capable of handling diverse industrial data formats and high-velocity streaming information. Organizations require solutions that can seamlessly integrate structured SCADA data with unstructured maintenance logs, sensor readings, and external market data sources. This integration capability is essential for developing comprehensive digital twin models and advanced process optimization algorithms.
Emerging market segments include small and medium-sized manufacturers who previously lacked access to enterprise-grade analytics capabilities. Cloud-based industrial data analytics platforms are democratizing access to sophisticated analytical tools, expanding the addressable market significantly. The increasing adoption of edge computing architectures is creating new demand patterns for distributed analytics solutions that can process SCADA data locally while maintaining centralized visibility and control.
Regional market dynamics show particularly strong growth in Asia-Pacific manufacturing hubs, where rapid industrialization and government digitization initiatives are driving substantial investments in industrial analytics infrastructure. North American and European markets demonstrate mature demand patterns focused on advanced analytics capabilities and regulatory compliance requirements.
SCADA systems generate massive volumes of real-time operational data that traditionally remained siloed within control systems. Organizations are now seeking comprehensive solutions to unlock the value of this historical and streaming data through advanced analytics platforms. The demand for integrating SCADA data with broader enterprise data ecosystems has intensified as companies pursue holistic operational intelligence strategies.
Key market drivers include the urgent need for predictive maintenance capabilities to minimize unplanned downtime and optimize asset performance. Industrial organizations are increasingly focused on reducing operational costs while improving safety standards and regulatory compliance. The growing emphasis on sustainability and energy efficiency has further amplified demand for sophisticated data analytics solutions that can identify optimization opportunities across complex industrial processes.
The market demonstrates strong demand for scalable data lake architectures capable of handling diverse industrial data formats and high-velocity streaming information. Organizations require solutions that can seamlessly integrate structured SCADA data with unstructured maintenance logs, sensor readings, and external market data sources. This integration capability is essential for developing comprehensive digital twin models and advanced process optimization algorithms.
Emerging market segments include small and medium-sized manufacturers who previously lacked access to enterprise-grade analytics capabilities. Cloud-based industrial data analytics platforms are democratizing access to sophisticated analytical tools, expanding the addressable market significantly. The increasing adoption of edge computing architectures is creating new demand patterns for distributed analytics solutions that can process SCADA data locally while maintaining centralized visibility and control.
Regional market dynamics show particularly strong growth in Asia-Pacific manufacturing hubs, where rapid industrialization and government digitization initiatives are driving substantial investments in industrial analytics infrastructure. North American and European markets demonstrate mature demand patterns focused on advanced analytics capabilities and regulatory compliance requirements.
Current SCADA Data Management Challenges and Limitations
Traditional SCADA systems face significant data management constraints that limit their ability to handle the growing volume and complexity of industrial data. Legacy SCADA architectures typically rely on centralized databases with rigid schemas, creating bottlenecks when processing high-frequency sensor data from multiple sources. These systems often struggle with scalability issues, particularly when industrial facilities expand their monitoring capabilities or integrate additional equipment into existing networks.
Data silos represent another critical challenge in current SCADA environments. Different operational units frequently maintain separate data repositories, preventing comprehensive cross-system analysis and hindering enterprise-wide visibility. This fragmentation makes it difficult to correlate events across multiple processes or identify system-wide patterns that could indicate emerging operational issues or optimization opportunities.
Storage limitations pose substantial constraints on data retention and historical analysis capabilities. Traditional SCADA databases are optimized for real-time operations rather than long-term data preservation, forcing organizations to make difficult decisions about which historical data to retain. This limitation significantly impacts predictive maintenance initiatives and long-term trend analysis, as insufficient historical context reduces the accuracy of analytical models.
Real-time processing requirements create additional complexity in SCADA data management. Industrial control systems demand immediate response to critical events, but traditional database architectures struggle to balance real-time performance with comprehensive data logging. This tension often results in simplified data models that sacrifice analytical depth for operational responsiveness.
Integration challenges emerge when attempting to combine SCADA data with other enterprise systems. Different data formats, communication protocols, and update frequencies create technical barriers that prevent seamless information flow between operational technology and information technology domains. These integration difficulties limit the potential for advanced analytics and comprehensive business intelligence initiatives.
Data quality and consistency issues further complicate SCADA data management. Sensor drift, communication errors, and system maintenance activities can introduce data anomalies that are difficult to detect and correct within traditional SCADA frameworks. Without robust data validation and cleansing mechanisms, these quality issues propagate through analytical processes, potentially leading to incorrect operational decisions.
Security considerations add another layer of complexity to SCADA data management. Industrial control systems require stringent access controls and data protection measures, but traditional security approaches often conflict with the need for data accessibility and analytical flexibility. Balancing operational security requirements with data utilization needs remains a persistent challenge for industrial organizations.
Data silos represent another critical challenge in current SCADA environments. Different operational units frequently maintain separate data repositories, preventing comprehensive cross-system analysis and hindering enterprise-wide visibility. This fragmentation makes it difficult to correlate events across multiple processes or identify system-wide patterns that could indicate emerging operational issues or optimization opportunities.
Storage limitations pose substantial constraints on data retention and historical analysis capabilities. Traditional SCADA databases are optimized for real-time operations rather than long-term data preservation, forcing organizations to make difficult decisions about which historical data to retain. This limitation significantly impacts predictive maintenance initiatives and long-term trend analysis, as insufficient historical context reduces the accuracy of analytical models.
Real-time processing requirements create additional complexity in SCADA data management. Industrial control systems demand immediate response to critical events, but traditional database architectures struggle to balance real-time performance with comprehensive data logging. This tension often results in simplified data models that sacrifice analytical depth for operational responsiveness.
Integration challenges emerge when attempting to combine SCADA data with other enterprise systems. Different data formats, communication protocols, and update frequencies create technical barriers that prevent seamless information flow between operational technology and information technology domains. These integration difficulties limit the potential for advanced analytics and comprehensive business intelligence initiatives.
Data quality and consistency issues further complicate SCADA data management. Sensor drift, communication errors, and system maintenance activities can introduce data anomalies that are difficult to detect and correct within traditional SCADA frameworks. Without robust data validation and cleansing mechanisms, these quality issues propagate through analytical processes, potentially leading to incorrect operational decisions.
Security considerations add another layer of complexity to SCADA data management. Industrial control systems require stringent access controls and data protection measures, but traditional security approaches often conflict with the need for data accessibility and analytical flexibility. Balancing operational security requirements with data utilization needs remains a persistent challenge for industrial organizations.
Existing SCADA Data Lake Implementation Approaches
01 SCADA data integration and storage architecture in data lakes
Systems and methods for integrating SCADA data into data lake architectures, enabling centralized storage of industrial control system data. These approaches focus on establishing data pipelines and storage frameworks that can handle the volume and velocity of SCADA data streams while maintaining data integrity and accessibility for downstream analytics applications.- SCADA data integration and storage architecture in data lakes: Systems and methods for integrating SCADA data into data lake architectures, enabling centralized storage of industrial control system data. These approaches focus on establishing data pipelines and storage frameworks that can handle the high-volume, time-series nature of SCADA data while maintaining data integrity and accessibility for downstream analytics applications.
- Real-time data processing and streaming for SCADA systems: Technologies for processing and streaming SCADA data in real-time within data lake environments. These solutions address the challenges of handling continuous data streams from supervisory control and data acquisition systems, enabling immediate data availability for monitoring, alerting, and operational decision-making while preserving historical data for long-term analysis.
- Data quality and validation mechanisms for industrial data: Methods for ensuring data quality, validation, and cleansing of SCADA data within data lake environments. These techniques include anomaly detection, data consistency checks, and automated validation processes that ensure the reliability and accuracy of industrial control data before it is used for analytics or operational purposes.
- Security and access control for SCADA data repositories: Security frameworks and access control mechanisms designed specifically for protecting SCADA data stored in data lakes. These solutions address the critical need for securing industrial control system data against unauthorized access while enabling appropriate data sharing and collaboration among authorized users and systems.
- Analytics and visualization platforms for SCADA data lakes: Analytical tools and visualization platforms that leverage SCADA data stored in data lakes for operational intelligence and predictive maintenance. These systems enable users to perform complex queries, generate insights from historical trends, and create dashboards that combine SCADA data with other enterprise data sources for comprehensive operational visibility.
02 Real-time data acquisition and streaming from SCADA systems
Technologies for capturing and streaming real-time data from SCADA systems into data lakes. These solutions address the challenges of continuous data ingestion, handling time-series data, and ensuring low-latency data transfer from operational technology environments to data lake platforms while preserving temporal relationships and data quality.Expand Specific Solutions03 Data transformation and preprocessing for SCADA data lakes
Methods for transforming and preprocessing raw SCADA data before storage in data lakes. These techniques include data normalization, format conversion, metadata enrichment, and quality validation to ensure that SCADA data is properly structured and tagged for efficient querying and analysis within the data lake environment.Expand Specific Solutions04 Security and access control for SCADA data in data lakes
Security frameworks and access control mechanisms specifically designed for protecting sensitive SCADA data stored in data lakes. These solutions implement authentication, authorization, encryption, and audit logging capabilities to ensure that industrial control data remains secure while enabling authorized access for analytics and monitoring purposes.Expand Specific Solutions05 Analytics and visualization of SCADA data from data lakes
Analytical tools and visualization platforms that leverage SCADA data stored in data lakes for operational intelligence and decision support. These systems enable advanced analytics, pattern recognition, anomaly detection, and interactive dashboards that help operators and engineers gain insights from historical and real-time SCADA data.Expand Specific Solutions
Key Players in SCADA and Data Lake Solutions
The competitive landscape for leveraging data lakes with SCADA data reflects a rapidly evolving market driven by industrial digital transformation initiatives. The industry is transitioning from traditional SCADA systems to cloud-integrated architectures, with market growth accelerated by IoT adoption and Industry 4.0 requirements. Technology maturity varies significantly across players, with established cloud giants like Amazon Technologies, Google LLC, and Microsoft Technology Licensing leading in scalable data lake platforms, while IBM and SAP SE offer comprehensive enterprise integration solutions. Specialized players like Starburst Data and MongoDB provide targeted analytics and database capabilities, whereas industrial-focused companies including Hitachi, Cisco Technology, and Fortinet contribute domain-specific expertise in operational technology integration and cybersecurity. The convergence of IT and OT systems is creating opportunities for both traditional enterprise software vendors and emerging data platform specialists.
International Business Machines Corp.
Technical Solution: IBM's approach to SCADA data lakes centers on IBM Cloud Pak for Data, providing a unified platform that combines data collection, storage, and analytics capabilities specifically designed for industrial IoT environments. The solution leverages IBM Watson IoT Platform for secure SCADA data ingestion and IBM Db2 Event Store for high-performance time-series data storage and retrieval. IBM's Maximo Application Suite integrates directly with the data lake architecture to provide asset performance management and predictive maintenance capabilities. The platform includes advanced AI and machine learning tools through Watson Studio, enabling sophisticated analytics on historical and real-time SCADA data to optimize industrial operations and predict equipment failures.
Strengths: Deep industrial domain expertise and strong AI/ML capabilities for predictive analytics. Robust security and governance features. Weaknesses: Higher implementation costs and complexity compared to cloud-native solutions. Limited market presence in modern data lake technologies.
Amazon Technologies, Inc.
Technical Solution: Amazon Web Services (AWS) provides comprehensive data lake solutions through Amazon S3 as the foundational storage layer, integrated with AWS Lake Formation for automated data cataloging and governance. Their architecture supports real-time SCADA data ingestion via Amazon Kinesis Data Streams and AWS IoT Core, enabling seamless collection from industrial sensors and control systems. The platform offers native integration with Amazon EMR, Redshift Spectrum, and SageMaker for advanced analytics and machine learning on SCADA datasets. AWS Glue provides automated ETL capabilities to transform raw SCADA data into analytics-ready formats, while Amazon QuickSight delivers real-time dashboards for operational intelligence.
Strengths: Market-leading cloud infrastructure with proven scalability and reliability for industrial IoT workloads. Comprehensive security and compliance certifications. Weaknesses: Can become expensive at scale and requires significant cloud expertise for optimal implementation.
Core Technologies for SCADA Data Lake Architecture
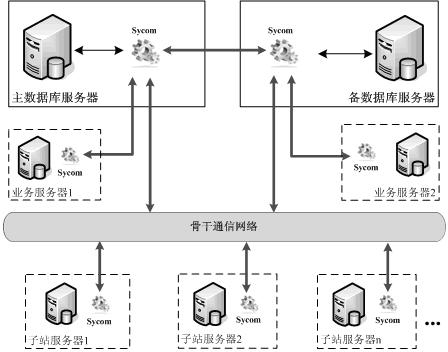
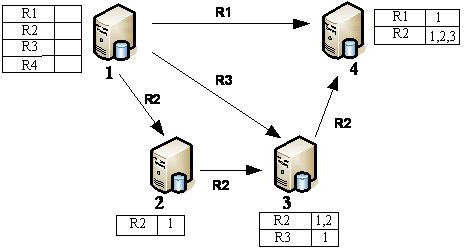
Data synchronization component of network relation database nodes of SCADA (Supervisory Control and Data Acquisition) system
PatentActiveCN102360357A
Innovation
- Designed a new synchronization component Sycom to support data synchronization across relational database platforms. It uses interface configuration to set data sources, data endpoints and filtering conditions to achieve network data interaction between multiple nodes and reduce the coupling between the system and components. , simplifying the configuration process.

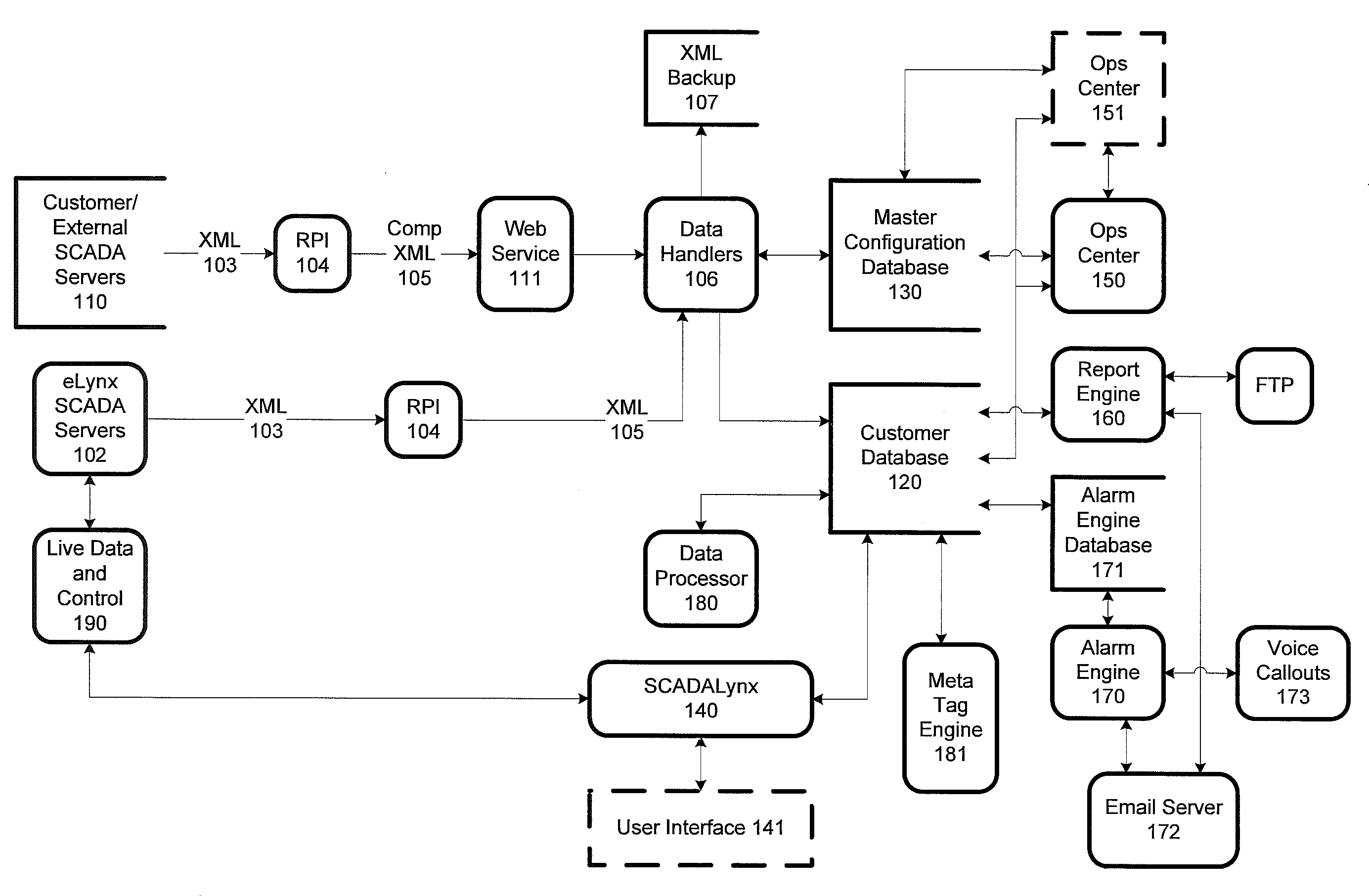
Classification and web-based presentation of oil and gas SCADA data
PatentInactiveUS8301386B1
Innovation
- A system that utilizes SCADA servers to gather and store data from field devices, with remote polling interfaces providing secure data transport and normalization across heterogeneous sources, consolidating data into unified databases for device-agnostic presentation, enabling real-time surveillance and control.
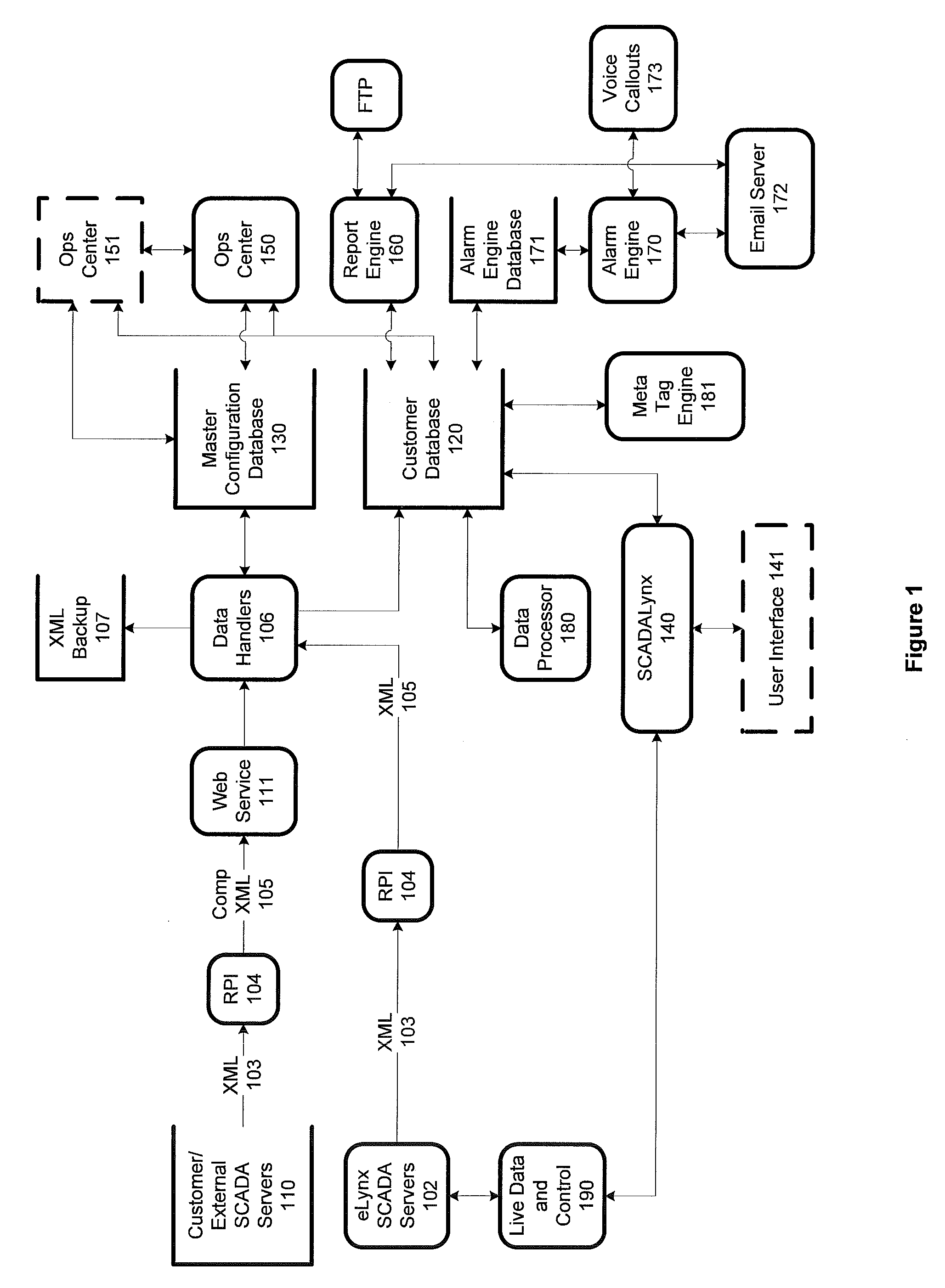
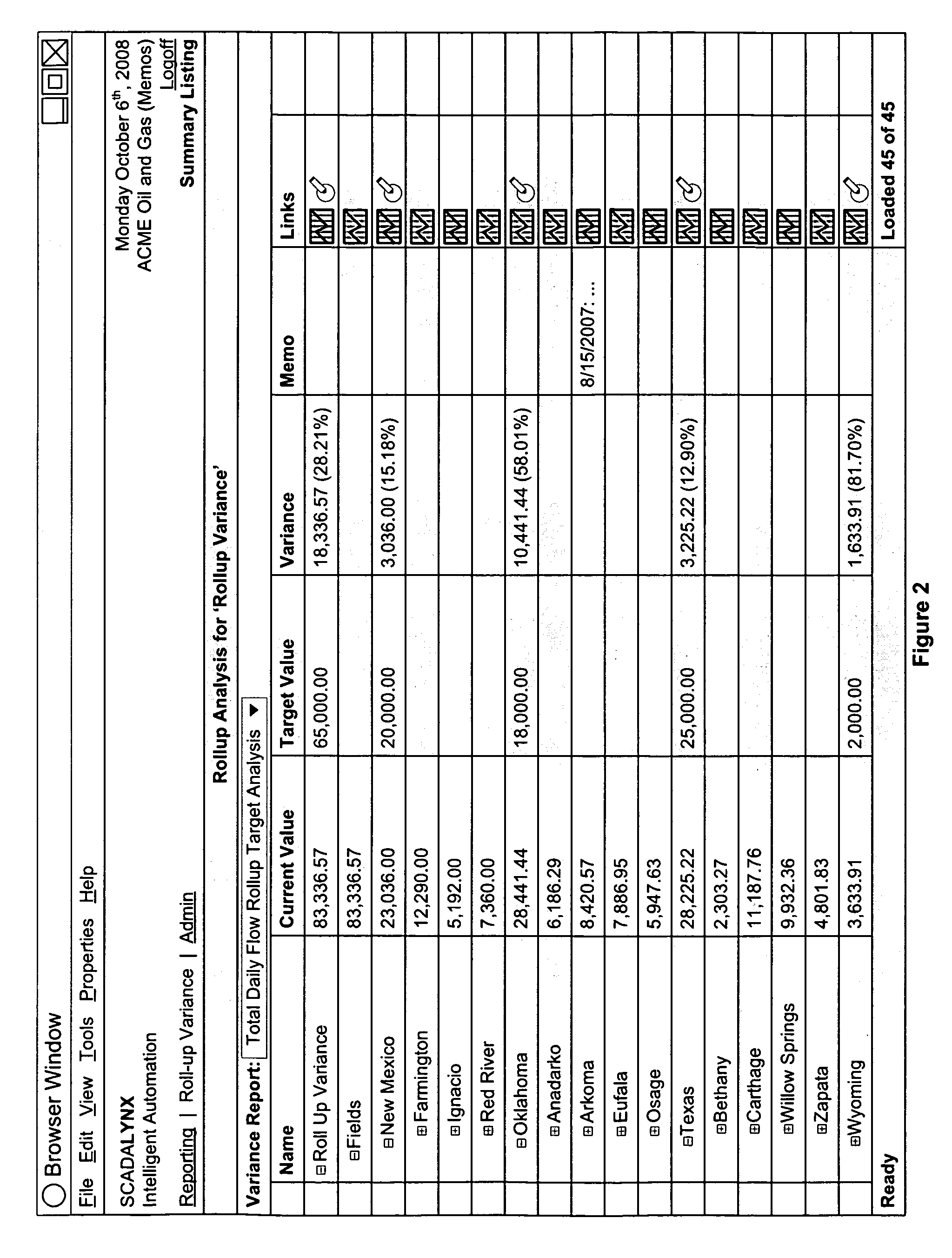

Data Governance and Security Frameworks for Industrial Systems
The integration of SCADA data into data lakes presents unique governance and security challenges that require specialized frameworks tailored to industrial environments. Traditional IT governance models often fall short when applied to operational technology systems, necessitating hybrid approaches that address both cybersecurity and operational continuity requirements.
Data governance frameworks for SCADA-enabled data lakes must establish clear data ownership hierarchies that span both operational and information technology domains. This includes defining roles for plant operators, process engineers, IT administrators, and data scientists, each with distinct access privileges and responsibilities. The framework should incorporate data lineage tracking to maintain visibility into how critical process data flows from field devices through historians into analytical platforms.
Security frameworks must address the unique threat landscape of industrial systems, where availability often takes precedence over confidentiality. Multi-layered security architectures should implement network segmentation between operational and analytical networks, ensuring that data lake operations cannot compromise real-time control systems. This includes establishing secure data transfer protocols, such as one-way data diodes or encrypted tunneling, to maintain operational integrity while enabling analytics.
Identity and access management becomes particularly complex when integrating SCADA data, as it must accommodate both human users and automated systems. Role-based access controls should align with operational hierarchies while supporting fine-grained permissions for specific data sets, time ranges, and analytical functions. This includes implementing time-based access controls that reflect shift patterns and operational schedules common in industrial environments.
Data classification schemes must account for the criticality and sensitivity of industrial process data, incorporating factors such as safety implications, competitive value, and regulatory requirements. This classification drives retention policies, backup strategies, and incident response procedures that align with both business continuity and compliance obligations.
Audit and compliance frameworks should provide comprehensive logging of data access, modification, and usage patterns while maintaining performance standards required for near real-time analytics. These frameworks must support regulatory requirements specific to industrial sectors, such as FDA validation for pharmaceutical manufacturing or NERC CIP standards for electrical utilities, ensuring that data lake implementations enhance rather than complicate compliance efforts.
Data governance frameworks for SCADA-enabled data lakes must establish clear data ownership hierarchies that span both operational and information technology domains. This includes defining roles for plant operators, process engineers, IT administrators, and data scientists, each with distinct access privileges and responsibilities. The framework should incorporate data lineage tracking to maintain visibility into how critical process data flows from field devices through historians into analytical platforms.
Security frameworks must address the unique threat landscape of industrial systems, where availability often takes precedence over confidentiality. Multi-layered security architectures should implement network segmentation between operational and analytical networks, ensuring that data lake operations cannot compromise real-time control systems. This includes establishing secure data transfer protocols, such as one-way data diodes or encrypted tunneling, to maintain operational integrity while enabling analytics.
Identity and access management becomes particularly complex when integrating SCADA data, as it must accommodate both human users and automated systems. Role-based access controls should align with operational hierarchies while supporting fine-grained permissions for specific data sets, time ranges, and analytical functions. This includes implementing time-based access controls that reflect shift patterns and operational schedules common in industrial environments.
Data classification schemes must account for the criticality and sensitivity of industrial process data, incorporating factors such as safety implications, competitive value, and regulatory requirements. This classification drives retention policies, backup strategies, and incident response procedures that align with both business continuity and compliance obligations.
Audit and compliance frameworks should provide comprehensive logging of data access, modification, and usage patterns while maintaining performance standards required for near real-time analytics. These frameworks must support regulatory requirements specific to industrial sectors, such as FDA validation for pharmaceutical manufacturing or NERC CIP standards for electrical utilities, ensuring that data lake implementations enhance rather than complicate compliance efforts.
Edge Computing Integration with SCADA Data Lakes
Edge computing represents a paradigm shift in how SCADA data lakes process and analyze industrial information by bringing computational capabilities closer to data sources. This integration addresses the fundamental challenge of latency-sensitive industrial operations where real-time decision-making is critical for operational efficiency and safety. Traditional centralized data lake architectures often struggle with the bandwidth limitations and latency issues inherent in transmitting large volumes of SCADA data to remote processing centers.
The integration architecture typically employs a hierarchical approach where edge nodes serve as intelligent gateways between SCADA systems and centralized data lakes. These edge computing nodes perform initial data processing, filtering, and aggregation before transmitting refined datasets to the main data lake infrastructure. This distributed processing model significantly reduces network bandwidth requirements while enabling near-instantaneous responses to critical operational events.
Modern edge computing platforms designed for SCADA integration incorporate specialized hardware optimized for industrial environments, including ruggedized processors, enhanced security modules, and redundant communication interfaces. These systems must operate reliably in harsh industrial conditions while maintaining strict cybersecurity protocols to protect sensitive operational data. The edge nodes typically run containerized applications that can be remotely updated and managed, ensuring consistent performance across distributed industrial sites.
Data synchronization between edge nodes and centralized data lakes presents unique technical challenges requiring sophisticated conflict resolution algorithms and eventual consistency models. Advanced edge computing solutions implement intelligent caching mechanisms that prioritize critical data transmission while managing storage constraints at the edge level. Machine learning algorithms deployed at the edge can perform predictive maintenance analysis and anomaly detection, reducing the computational load on centralized systems.
The integration also enables hybrid analytics workflows where time-sensitive computations occur at the edge while complex historical analysis and machine learning model training happen in the centralized data lake. This distributed intelligence approach optimizes resource utilization and ensures that critical industrial processes maintain operational continuity even during network disruptions or connectivity issues with the central data lake infrastructure.
The integration architecture typically employs a hierarchical approach where edge nodes serve as intelligent gateways between SCADA systems and centralized data lakes. These edge computing nodes perform initial data processing, filtering, and aggregation before transmitting refined datasets to the main data lake infrastructure. This distributed processing model significantly reduces network bandwidth requirements while enabling near-instantaneous responses to critical operational events.
Modern edge computing platforms designed for SCADA integration incorporate specialized hardware optimized for industrial environments, including ruggedized processors, enhanced security modules, and redundant communication interfaces. These systems must operate reliably in harsh industrial conditions while maintaining strict cybersecurity protocols to protect sensitive operational data. The edge nodes typically run containerized applications that can be remotely updated and managed, ensuring consistent performance across distributed industrial sites.
Data synchronization between edge nodes and centralized data lakes presents unique technical challenges requiring sophisticated conflict resolution algorithms and eventual consistency models. Advanced edge computing solutions implement intelligent caching mechanisms that prioritize critical data transmission while managing storage constraints at the edge level. Machine learning algorithms deployed at the edge can perform predictive maintenance analysis and anomaly detection, reducing the computational load on centralized systems.
The integration also enables hybrid analytics workflows where time-sensitive computations occur at the edge while complex historical analysis and machine learning model training happen in the centralized data lake. This distributed intelligence approach optimizes resource utilization and ensures that critical industrial processes maintain operational continuity even during network disruptions or connectivity issues with the central data lake infrastructure.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!