How to Optimize NLP for Chatbot Efficiency
MAR 18, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
NLP Chatbot Optimization Background and Objectives
Natural Language Processing (NLP) has undergone remarkable evolution since its inception in the 1950s, transitioning from rule-based systems to sophisticated machine learning and deep learning architectures. The journey began with simple pattern matching and syntactic analysis, progressed through statistical methods in the 1990s, and reached new heights with transformer-based models like BERT and GPT in recent years. This technological progression has fundamentally transformed how machines understand and generate human language.
The integration of NLP into chatbot systems represents a critical convergence of computational linguistics, artificial intelligence, and user experience design. Early chatbots relied on predetermined response trees and keyword matching, but modern conversational AI leverages advanced NLP techniques including intent recognition, entity extraction, context understanding, and natural language generation. This evolution has enabled chatbots to handle increasingly complex interactions while maintaining conversational flow and contextual awareness.
Current market demands for chatbot efficiency stem from exponential growth in digital customer service, e-commerce automation, and enterprise productivity tools. Organizations require chatbots that can process queries rapidly, understand nuanced language patterns, maintain conversation context across multiple turns, and provide accurate responses while minimizing computational overhead. The challenge lies in balancing sophisticated language understanding capabilities with real-time performance requirements.
The primary objective of NLP optimization for chatbot efficiency centers on achieving superior response accuracy while maintaining sub-second latency. This involves streamlining model architectures, implementing efficient tokenization strategies, optimizing memory usage, and developing intelligent caching mechanisms. Additionally, the goal encompasses enhancing multilingual support, improving handling of ambiguous queries, and reducing false positive rates in intent classification.
Technical objectives include developing lightweight yet powerful language models that can operate effectively in resource-constrained environments, implementing dynamic model compression techniques, and creating adaptive learning systems that improve performance based on user interactions. The optimization framework must also address scalability concerns, ensuring consistent performance across varying user loads while maintaining cost-effectiveness in deployment scenarios.
Strategic goals encompass establishing robust evaluation metrics for measuring both linguistic accuracy and computational efficiency, developing standardized benchmarking protocols, and creating modular architectures that allow for continuous improvement without complete system overhauls. The ultimate aim is to create NLP-powered chatbots that deliver human-like conversational experiences while operating within practical computational and economic constraints.
The integration of NLP into chatbot systems represents a critical convergence of computational linguistics, artificial intelligence, and user experience design. Early chatbots relied on predetermined response trees and keyword matching, but modern conversational AI leverages advanced NLP techniques including intent recognition, entity extraction, context understanding, and natural language generation. This evolution has enabled chatbots to handle increasingly complex interactions while maintaining conversational flow and contextual awareness.
Current market demands for chatbot efficiency stem from exponential growth in digital customer service, e-commerce automation, and enterprise productivity tools. Organizations require chatbots that can process queries rapidly, understand nuanced language patterns, maintain conversation context across multiple turns, and provide accurate responses while minimizing computational overhead. The challenge lies in balancing sophisticated language understanding capabilities with real-time performance requirements.
The primary objective of NLP optimization for chatbot efficiency centers on achieving superior response accuracy while maintaining sub-second latency. This involves streamlining model architectures, implementing efficient tokenization strategies, optimizing memory usage, and developing intelligent caching mechanisms. Additionally, the goal encompasses enhancing multilingual support, improving handling of ambiguous queries, and reducing false positive rates in intent classification.
Technical objectives include developing lightweight yet powerful language models that can operate effectively in resource-constrained environments, implementing dynamic model compression techniques, and creating adaptive learning systems that improve performance based on user interactions. The optimization framework must also address scalability concerns, ensuring consistent performance across varying user loads while maintaining cost-effectiveness in deployment scenarios.
Strategic goals encompass establishing robust evaluation metrics for measuring both linguistic accuracy and computational efficiency, developing standardized benchmarking protocols, and creating modular architectures that allow for continuous improvement without complete system overhauls. The ultimate aim is to create NLP-powered chatbots that deliver human-like conversational experiences while operating within practical computational and economic constraints.
Market Demand for Efficient Conversational AI Systems
The global conversational AI market has experienced unprecedented growth, driven by enterprises' urgent need to enhance customer service efficiency while reducing operational costs. Organizations across industries are increasingly recognizing that traditional rule-based chatbots fail to meet modern customer expectations for natural, contextual interactions. This shift has created substantial demand for NLP-optimized chatbot solutions that can deliver human-like conversational experiences at scale.
Enterprise adoption patterns reveal strong demand across multiple sectors, with customer service, e-commerce, healthcare, and financial services leading implementation efforts. Companies are particularly seeking solutions that can handle complex, multi-turn conversations while maintaining response accuracy and speed. The growing volume of customer inquiries, especially following digital transformation acceleration, has intensified the need for chatbots capable of processing natural language efficiently without compromising service quality.
Market drivers extend beyond cost reduction to include competitive differentiation and customer experience enhancement. Organizations recognize that poorly performing chatbots can damage brand reputation and customer satisfaction. Consequently, there is increasing willingness to invest in advanced NLP optimization technologies that ensure chatbots understand context, maintain conversation flow, and provide relevant responses consistently.
The demand landscape shows particular strength in multilingual support capabilities, as global enterprises require chatbots that can efficiently process diverse languages and cultural contexts. Real-time processing requirements have also intensified, with customers expecting immediate responses regardless of query complexity. This has created specific market demand for NLP optimization techniques that can reduce latency while maintaining accuracy.
Emerging market segments include voice-enabled conversational interfaces and industry-specific chatbot applications requiring specialized domain knowledge. Healthcare chatbots need medical terminology processing, while financial services demand compliance-aware conversation handling. These specialized requirements are driving demand for targeted NLP optimization approaches that can efficiently handle domain-specific language patterns and regulatory constraints.
The market also demonstrates growing interest in conversational AI systems that can seamlessly integrate with existing enterprise infrastructure while scaling efficiently during peak usage periods. Organizations are actively seeking solutions that optimize computational resources without sacrificing conversational quality, indicating strong commercial viability for advanced NLP optimization technologies.
Enterprise adoption patterns reveal strong demand across multiple sectors, with customer service, e-commerce, healthcare, and financial services leading implementation efforts. Companies are particularly seeking solutions that can handle complex, multi-turn conversations while maintaining response accuracy and speed. The growing volume of customer inquiries, especially following digital transformation acceleration, has intensified the need for chatbots capable of processing natural language efficiently without compromising service quality.
Market drivers extend beyond cost reduction to include competitive differentiation and customer experience enhancement. Organizations recognize that poorly performing chatbots can damage brand reputation and customer satisfaction. Consequently, there is increasing willingness to invest in advanced NLP optimization technologies that ensure chatbots understand context, maintain conversation flow, and provide relevant responses consistently.
The demand landscape shows particular strength in multilingual support capabilities, as global enterprises require chatbots that can efficiently process diverse languages and cultural contexts. Real-time processing requirements have also intensified, with customers expecting immediate responses regardless of query complexity. This has created specific market demand for NLP optimization techniques that can reduce latency while maintaining accuracy.
Emerging market segments include voice-enabled conversational interfaces and industry-specific chatbot applications requiring specialized domain knowledge. Healthcare chatbots need medical terminology processing, while financial services demand compliance-aware conversation handling. These specialized requirements are driving demand for targeted NLP optimization approaches that can efficiently handle domain-specific language patterns and regulatory constraints.
The market also demonstrates growing interest in conversational AI systems that can seamlessly integrate with existing enterprise infrastructure while scaling efficiently during peak usage periods. Organizations are actively seeking solutions that optimize computational resources without sacrificing conversational quality, indicating strong commercial viability for advanced NLP optimization technologies.
Current NLP Chatbot Performance Bottlenecks and Challenges
Natural Language Processing chatbots face significant performance bottlenecks that directly impact user experience and operational efficiency. The most prominent challenge lies in computational complexity, where large language models require substantial processing power for real-time inference. Modern transformer-based architectures, while delivering superior accuracy, demand extensive GPU resources and memory allocation, creating latency issues that can exceed acceptable response times for interactive applications.
Memory management represents another critical bottleneck, particularly in multi-turn conversations where context retention becomes computationally expensive. Chatbots must maintain conversation history while processing new inputs, leading to exponential memory consumption as dialogue length increases. This challenge is amplified in enterprise environments where thousands of concurrent users generate simultaneous requests, straining system resources and degrading response quality.
Intent recognition accuracy remains inconsistent across diverse user inputs and domain-specific terminology. Current NLP models struggle with ambiguous queries, colloquial expressions, and context-dependent meanings, resulting in misinterpretation rates that can reach 15-20% in complex scenarios. This accuracy degradation is particularly pronounced when handling multilingual inputs or specialized industry jargon, where training data may be insufficient.
Scalability constraints emerge when deploying chatbots across multiple channels and languages simultaneously. Traditional architectures face difficulties in load balancing and resource allocation, especially during peak usage periods. The challenge intensifies with real-time learning requirements, where models must adapt to new patterns while maintaining consistent performance across existing functionalities.
Integration complexity with existing enterprise systems creates additional performance overhead. Chatbots must interface with databases, APIs, and legacy systems, introducing network latency and data processing delays. Security protocols and authentication mechanisms further compound these delays, particularly in regulated industries where compliance requirements mandate additional verification steps.
Training data quality and bias present ongoing challenges that affect both accuracy and fairness. Insufficient or skewed training datasets lead to performance degradation in underrepresented scenarios, while bias amplification can result in discriminatory responses. The continuous need for model retraining to address these issues creates additional computational overhead and operational complexity.
Response generation speed varies significantly based on query complexity and required reasoning depth. Simple factual queries may process efficiently, but complex analytical requests or creative tasks can experience substantial delays. This inconsistency in processing time creates unpredictable user experiences and complicates system resource planning for optimal performance delivery.
Memory management represents another critical bottleneck, particularly in multi-turn conversations where context retention becomes computationally expensive. Chatbots must maintain conversation history while processing new inputs, leading to exponential memory consumption as dialogue length increases. This challenge is amplified in enterprise environments where thousands of concurrent users generate simultaneous requests, straining system resources and degrading response quality.
Intent recognition accuracy remains inconsistent across diverse user inputs and domain-specific terminology. Current NLP models struggle with ambiguous queries, colloquial expressions, and context-dependent meanings, resulting in misinterpretation rates that can reach 15-20% in complex scenarios. This accuracy degradation is particularly pronounced when handling multilingual inputs or specialized industry jargon, where training data may be insufficient.
Scalability constraints emerge when deploying chatbots across multiple channels and languages simultaneously. Traditional architectures face difficulties in load balancing and resource allocation, especially during peak usage periods. The challenge intensifies with real-time learning requirements, where models must adapt to new patterns while maintaining consistent performance across existing functionalities.
Integration complexity with existing enterprise systems creates additional performance overhead. Chatbots must interface with databases, APIs, and legacy systems, introducing network latency and data processing delays. Security protocols and authentication mechanisms further compound these delays, particularly in regulated industries where compliance requirements mandate additional verification steps.
Training data quality and bias present ongoing challenges that affect both accuracy and fairness. Insufficient or skewed training datasets lead to performance degradation in underrepresented scenarios, while bias amplification can result in discriminatory responses. The continuous need for model retraining to address these issues creates additional computational overhead and operational complexity.
Response generation speed varies significantly based on query complexity and required reasoning depth. Simple factual queries may process efficiently, but complex analytical requests or creative tasks can experience substantial delays. This inconsistency in processing time creates unpredictable user experiences and complicates system resource planning for optimal performance delivery.
Existing NLP Optimization Techniques for Chatbots
01 Model compression and optimization techniques
Various techniques can be employed to reduce the computational complexity and memory footprint of NLP models while maintaining performance. These include pruning unnecessary parameters, quantization of model weights, knowledge distillation from larger models to smaller ones, and neural architecture search to find efficient model structures. Such approaches enable faster inference times and reduced resource consumption in natural language processing applications.- Model compression and optimization techniques: Various techniques are employed to reduce the computational complexity and memory footprint of NLP models. These include pruning redundant parameters, quantization of model weights, knowledge distillation from larger models to smaller ones, and neural architecture search to find efficient model structures. These methods enable faster inference times and reduced resource consumption while maintaining acceptable performance levels.
- Efficient attention mechanisms and transformer architectures: Improvements to attention mechanisms in transformer-based models focus on reducing computational complexity from quadratic to linear or near-linear time. Techniques include sparse attention patterns, local attention windows, and approximation methods that maintain model effectiveness while significantly reducing processing time and memory requirements for long sequences.
- Hardware acceleration and parallel processing: Specialized hardware implementations and parallel processing strategies are utilized to accelerate NLP computations. This includes optimization for GPUs, TPUs, and custom accelerators, as well as distributed computing frameworks that enable efficient processing across multiple devices. These approaches leverage hardware-specific features to maximize throughput and minimize latency.
- Caching and pre-computation strategies: Efficiency gains are achieved through intelligent caching of intermediate results, pre-computation of frequently used embeddings, and reuse of computed representations across multiple queries. These strategies reduce redundant calculations and enable faster response times, particularly in production environments where similar queries are processed repeatedly.
- Dynamic computation and adaptive inference: Adaptive methods adjust computational resources based on input complexity and required accuracy. This includes early exit mechanisms that terminate processing when confidence thresholds are met, dynamic depth networks that adjust the number of layers processed, and input-dependent routing that allocates resources efficiently based on task difficulty.
02 Efficient attention mechanisms and transformer architectures
Improvements to attention mechanisms in transformer-based models can significantly enhance computational efficiency. This includes sparse attention patterns, linear attention approximations, and hierarchical attention structures that reduce the quadratic complexity of standard attention. These optimizations allow for processing longer sequences with reduced computational overhead while preserving model accuracy.Expand Specific Solutions03 Hardware acceleration and parallel processing
Leveraging specialized hardware and parallel computing architectures can dramatically improve NLP processing speed. This involves optimizing models for GPU, TPU, or custom accelerator execution, implementing efficient batching strategies, and utilizing distributed computing frameworks. Hardware-aware optimization techniques ensure that NLP models can take full advantage of available computational resources.Expand Specific Solutions04 Caching and pre-computation strategies
Efficiency can be improved through intelligent caching of intermediate results and pre-computation of frequently used representations. This includes storing embeddings, attention patterns, or model states that can be reused across multiple inference requests. Such strategies reduce redundant computations and enable faster response times in production NLP systems.Expand Specific Solutions05 Dynamic and adaptive inference methods
Adaptive approaches that adjust computational resources based on input complexity can optimize efficiency. This includes early exit mechanisms that allow simpler inputs to skip later layers, dynamic depth networks that vary processing depth, and conditional computation that activates only relevant model components. These methods enable variable computational budgets tailored to specific input requirements.Expand Specific Solutions
Leading Companies in NLP and Chatbot Development
The NLP chatbot optimization landscape is experiencing rapid growth as the industry transitions from experimental to mainstream adoption phases. Major technology corporations including IBM, Google, Oracle, Alibaba, and Tencent are driving significant market expansion through substantial investments in conversational AI infrastructure. The market demonstrates strong maturity indicators with established players like Salesforce and PayPal integrating sophisticated NLP solutions into their platforms. Technology maturity varies considerably across segments, with companies like IBM and Google showcasing advanced natural language processing capabilities, while emerging specialists such as Acurai focus on eliminating AI hallucinations. Financial services leaders including Truist Bank and PayPal are implementing production-ready chatbot systems, indicating robust enterprise adoption. The competitive landscape spans from established tech giants to specialized AI companies, with significant contributions from Chinese technology leaders Alibaba and Tencent, suggesting a globally distributed innovation ecosystem with varying levels of technological sophistication across different market segments.
International Business Machines Corp.
Technical Solution: IBM Watson Assistant employs a multi-layered NLP optimization strategy combining intent recognition, entity extraction, and contextual understanding. Their approach utilizes federated learning techniques to improve model performance while maintaining data privacy, and implements adaptive learning algorithms that continuously optimize based on user interactions. IBM focuses on enterprise-grade solutions with robust API management, implementing efficient caching strategies and load balancing for high-throughput scenarios. Their technology stack includes specialized hardware acceleration and optimized inference pipelines designed for business-critical applications.
Strengths: Enterprise-focused solutions, strong privacy and security features, proven reliability in business environments. Weaknesses: Higher costs, potentially slower adoption of cutting-edge research compared to tech giants.
Alibaba Group Holding Ltd.
Technical Solution: Alibaba's chatbot optimization strategy centers around their AliMe platform, which integrates advanced NLP techniques with e-commerce specific optimizations. They implement multi-modal learning approaches combining text, voice, and visual inputs for enhanced user experience. Their technology stack includes efficient model serving architectures, automated hyperparameter tuning, and real-time A/B testing frameworks for continuous optimization. Alibaba utilizes cloud-native solutions with auto-scaling capabilities and implements specialized algorithms for handling high-concurrency scenarios during peak shopping periods like Singles' Day.
Strengths: Proven performance under extreme load conditions, strong e-commerce domain expertise, comprehensive cloud infrastructure. Weaknesses: Primarily focused on Chinese market, limited presence in Western enterprise solutions.
Core Innovations in Efficient NLP Model Architecture
System and method for chatbot conversation construction and management
PatentInactiveUS20190311036A1
Innovation
- A chatbot system and method that is not tied to a particular NLP engine, enabling continuous self-improvement and efficient task allocation between chatbots and live agents, using an AI Manager with NLP core and Application Connectors for protocol translation and machine learning-driven conversation management.
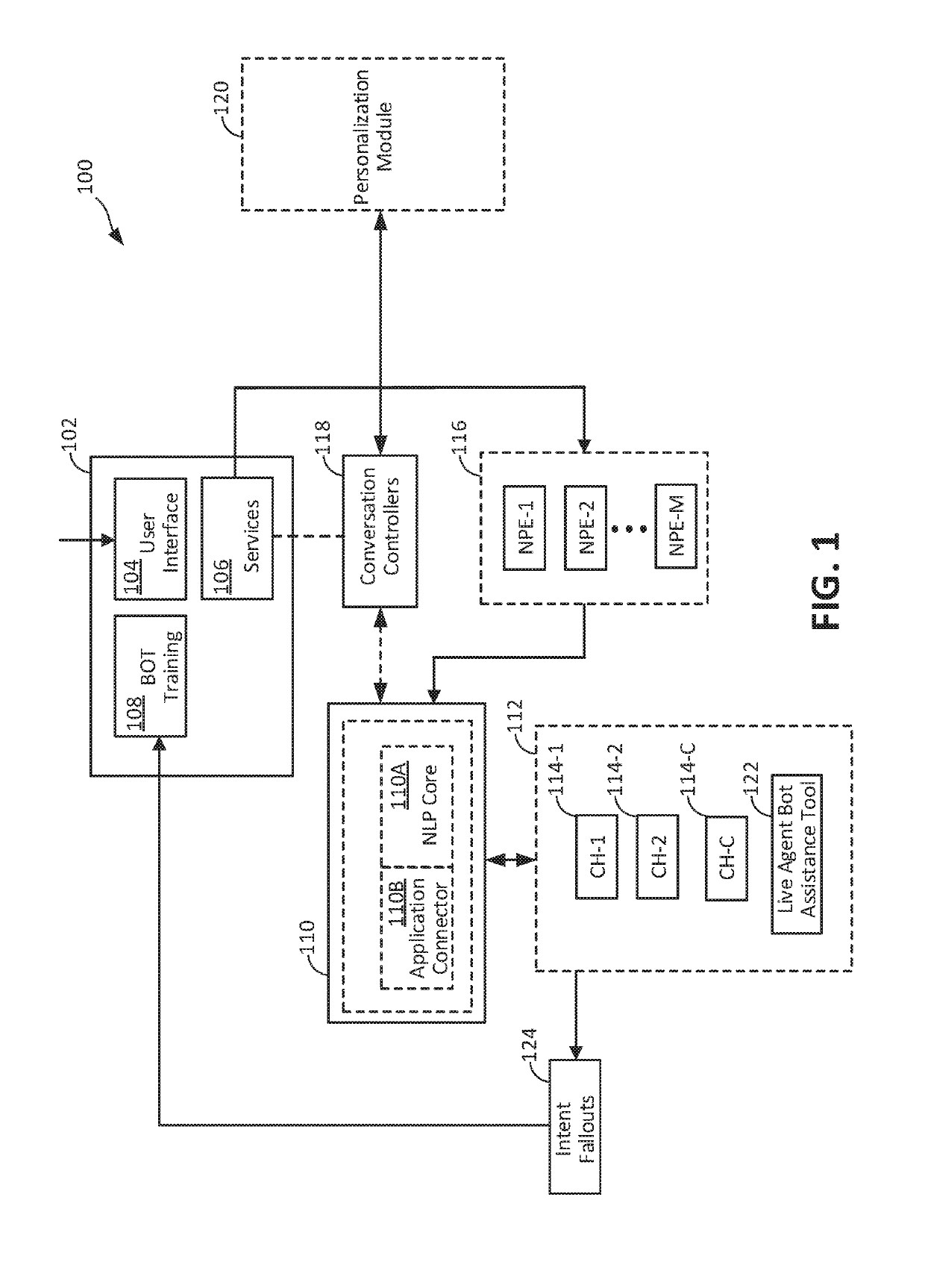


Automatic detection of intention of natural language input text
PatentInactiveSG10202103337TA
Innovation
- A platform that processes natural language input text by parsing it into constituent components, categorizing them, identifying activity-related and noun components, and validating hypotheses to determine the intention and target of the input, using semantic and syntactic rules to automatically extract the underlying objective without extensive user input.




Data Privacy Regulations Impact on NLP Chatbot Design
The implementation of stringent data privacy regulations such as GDPR, CCPA, and emerging regional privacy laws has fundamentally transformed the architectural requirements for NLP-powered chatbots. These regulatory frameworks mandate explicit user consent mechanisms, data minimization principles, and the right to erasure, compelling organizations to redesign their chatbot systems from the ground up. Traditional NLP models that relied on extensive data collection and persistent storage now face significant compliance challenges.
Privacy-by-design principles have become mandatory rather than optional in chatbot development. This regulatory shift requires implementing differential privacy techniques, federated learning approaches, and on-device processing capabilities to minimize data exposure risks. Organizations must now balance the tension between model performance and privacy compliance, often resulting in trade-offs that impact chatbot efficiency and accuracy.
The right to data portability and deletion has introduced complex technical requirements for NLP systems. Chatbots must now incorporate mechanisms to selectively remove individual user data from training datasets without compromising overall model integrity. This has led to the development of machine unlearning techniques and modular training architectures that can accommodate dynamic data removal requests while maintaining conversational quality.
Cross-border data transfer restrictions have significantly impacted global chatbot deployments. Organizations operating in multiple jurisdictions must implement data localization strategies, requiring distributed NLP processing capabilities and region-specific model training. This regulatory fragmentation has increased infrastructure complexity and operational costs while potentially reducing the effectiveness of globally trained language models.
Consent management integration has become a critical design consideration, requiring chatbots to dynamically adjust their processing capabilities based on user permission levels. This includes implementing tiered functionality where basic conversational features operate with minimal data collection, while advanced personalization requires explicit user consent. Such regulatory compliance measures directly influence the optimization strategies available for enhancing chatbot efficiency, as developers must prioritize privacy-preserving techniques over traditional performance enhancement methods.
Privacy-by-design principles have become mandatory rather than optional in chatbot development. This regulatory shift requires implementing differential privacy techniques, federated learning approaches, and on-device processing capabilities to minimize data exposure risks. Organizations must now balance the tension between model performance and privacy compliance, often resulting in trade-offs that impact chatbot efficiency and accuracy.
The right to data portability and deletion has introduced complex technical requirements for NLP systems. Chatbots must now incorporate mechanisms to selectively remove individual user data from training datasets without compromising overall model integrity. This has led to the development of machine unlearning techniques and modular training architectures that can accommodate dynamic data removal requests while maintaining conversational quality.
Cross-border data transfer restrictions have significantly impacted global chatbot deployments. Organizations operating in multiple jurisdictions must implement data localization strategies, requiring distributed NLP processing capabilities and region-specific model training. This regulatory fragmentation has increased infrastructure complexity and operational costs while potentially reducing the effectiveness of globally trained language models.
Consent management integration has become a critical design consideration, requiring chatbots to dynamically adjust their processing capabilities based on user permission levels. This includes implementing tiered functionality where basic conversational features operate with minimal data collection, while advanced personalization requires explicit user consent. Such regulatory compliance measures directly influence the optimization strategies available for enhancing chatbot efficiency, as developers must prioritize privacy-preserving techniques over traditional performance enhancement methods.
Energy Efficiency Considerations in Large Language Models
Energy efficiency has emerged as a critical consideration in the deployment of large language models for chatbot applications, particularly as model sizes continue to grow exponentially. The computational demands of transformer-based architectures, which form the backbone of modern conversational AI systems, present significant challenges in terms of power consumption and operational costs. These concerns become especially pronounced in production environments where chatbots must handle millions of concurrent conversations while maintaining acceptable response times and service quality.
The energy footprint of large language models stems primarily from two phases: training and inference. While training represents a one-time energy investment, inference operations occur continuously throughout the model's operational lifetime, making inference efficiency crucial for sustainable chatbot deployment. Current state-of-the-art models like GPT-4 and Claude require substantial computational resources for each query, translating directly into energy consumption that scales with user demand.
Several architectural approaches have been developed to address energy efficiency without compromising conversational quality. Model distillation techniques enable the creation of smaller, more efficient models that retain much of the performance of their larger counterparts. Knowledge distillation allows organizations to deploy lightweight versions of complex models, reducing energy consumption by up to 80% while maintaining acceptable accuracy levels for most chatbot applications.
Dynamic inference strategies represent another promising avenue for energy optimization. Techniques such as early exit mechanisms allow models to terminate processing when confidence thresholds are met, avoiding unnecessary computation for simpler queries. Adaptive layer selection and conditional computation further enhance efficiency by activating only the neural network components required for specific types of conversational tasks.
Hardware-software co-optimization has become increasingly important in achieving energy-efficient chatbot operations. Specialized inference accelerators, optimized memory hierarchies, and custom silicon designs specifically tailored for transformer architectures can deliver significant energy savings compared to general-purpose computing platforms. These solutions often incorporate techniques like quantization, pruning, and sparsity optimization to reduce computational overhead.
The integration of edge computing paradigms offers additional opportunities for energy efficiency improvements. By deploying smaller, specialized models at edge locations closer to users, organizations can reduce both latency and the energy costs associated with data center operations. This distributed approach enables more sustainable chatbot architectures while potentially improving user experience through reduced response times.
The energy footprint of large language models stems primarily from two phases: training and inference. While training represents a one-time energy investment, inference operations occur continuously throughout the model's operational lifetime, making inference efficiency crucial for sustainable chatbot deployment. Current state-of-the-art models like GPT-4 and Claude require substantial computational resources for each query, translating directly into energy consumption that scales with user demand.
Several architectural approaches have been developed to address energy efficiency without compromising conversational quality. Model distillation techniques enable the creation of smaller, more efficient models that retain much of the performance of their larger counterparts. Knowledge distillation allows organizations to deploy lightweight versions of complex models, reducing energy consumption by up to 80% while maintaining acceptable accuracy levels for most chatbot applications.
Dynamic inference strategies represent another promising avenue for energy optimization. Techniques such as early exit mechanisms allow models to terminate processing when confidence thresholds are met, avoiding unnecessary computation for simpler queries. Adaptive layer selection and conditional computation further enhance efficiency by activating only the neural network components required for specific types of conversational tasks.
Hardware-software co-optimization has become increasingly important in achieving energy-efficient chatbot operations. Specialized inference accelerators, optimized memory hierarchies, and custom silicon designs specifically tailored for transformer architectures can deliver significant energy savings compared to general-purpose computing platforms. These solutions often incorporate techniques like quantization, pruning, and sparsity optimization to reduce computational overhead.
The integration of edge computing paradigms offers additional opportunities for energy efficiency improvements. By deploying smaller, specialized models at edge locations closer to users, organizations can reduce both latency and the energy costs associated with data center operations. This distributed approach enables more sustainable chatbot architectures while potentially improving user experience through reduced response times.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!