How to Optimize NLP for Document Similarity Detection
MAR 18, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
NLP Document Similarity Background and Objectives
Natural Language Processing (NLP) for document similarity detection has emerged as a critical technology in the digital information age, where organizations face exponential growth in textual data volumes. The field originated from early computational linguistics research in the 1950s and has evolved through multiple paradigm shifts, from rule-based systems to statistical methods, and most recently to deep learning approaches. This evolution reflects the continuous pursuit of more accurate and efficient methods to quantify semantic relationships between documents.
The fundamental challenge in document similarity detection lies in capturing both syntactic and semantic relationships between texts while maintaining computational efficiency. Traditional approaches relied heavily on lexical matching and statistical measures such as TF-IDF and cosine similarity. However, these methods often failed to capture deeper semantic meanings and contextual nuances that human readers naturally understand.
The advent of word embeddings marked a significant milestone in this domain, with techniques like Word2Vec and GloVe enabling vector representations of words that capture semantic relationships. This breakthrough paved the way for more sophisticated document-level representations, leading to the development of document embeddings and transformer-based models that have revolutionized the field.
Current technological objectives focus on achieving several key goals simultaneously. First, improving semantic understanding beyond surface-level text matching to capture contextual meanings, synonyms, and conceptual relationships. Second, enhancing scalability to handle large-scale document collections efficiently while maintaining real-time processing capabilities for dynamic applications.
Third, developing domain-adaptive solutions that can perform effectively across different industries and document types, from legal contracts to scientific publications. Fourth, ensuring multilingual compatibility to support global applications and cross-language document comparison.
The ultimate technical goal involves creating robust, interpretable systems that can provide not only similarity scores but also explanations for their decisions, enabling users to understand why certain documents are considered similar. This transparency is crucial for applications in legal discovery, academic research, and content management systems where decision rationale is as important as accuracy.
The fundamental challenge in document similarity detection lies in capturing both syntactic and semantic relationships between texts while maintaining computational efficiency. Traditional approaches relied heavily on lexical matching and statistical measures such as TF-IDF and cosine similarity. However, these methods often failed to capture deeper semantic meanings and contextual nuances that human readers naturally understand.
The advent of word embeddings marked a significant milestone in this domain, with techniques like Word2Vec and GloVe enabling vector representations of words that capture semantic relationships. This breakthrough paved the way for more sophisticated document-level representations, leading to the development of document embeddings and transformer-based models that have revolutionized the field.
Current technological objectives focus on achieving several key goals simultaneously. First, improving semantic understanding beyond surface-level text matching to capture contextual meanings, synonyms, and conceptual relationships. Second, enhancing scalability to handle large-scale document collections efficiently while maintaining real-time processing capabilities for dynamic applications.
Third, developing domain-adaptive solutions that can perform effectively across different industries and document types, from legal contracts to scientific publications. Fourth, ensuring multilingual compatibility to support global applications and cross-language document comparison.
The ultimate technical goal involves creating robust, interpretable systems that can provide not only similarity scores but also explanations for their decisions, enabling users to understand why certain documents are considered similar. This transparency is crucial for applications in legal discovery, academic research, and content management systems where decision rationale is as important as accuracy.
Market Demand for Document Similarity Solutions
The global market for document similarity detection solutions has experienced substantial growth driven by the exponential increase in digital content creation and the critical need for intellectual property protection. Organizations across industries are generating vast amounts of textual data daily, creating unprecedented demand for automated systems capable of identifying duplicate, plagiarized, or closely related content with high accuracy and efficiency.
Educational institutions represent one of the largest market segments, where academic integrity enforcement has become paramount. Universities and schools worldwide require sophisticated plagiarism detection systems to maintain educational standards and ensure original student work. The shift toward online learning and digital submission platforms has further amplified this demand, as traditional manual verification methods prove inadequate for handling large volumes of academic content.
Legal and compliance sectors demonstrate equally strong market demand, particularly for contract analysis, patent research, and regulatory document management. Law firms and corporate legal departments need advanced similarity detection capabilities to identify potential conflicts, ensure compliance with existing agreements, and conduct thorough due diligence processes. The complexity of legal language and the high stakes involved in legal documentation drive requirements for highly precise and contextually aware similarity detection systems.
Publishing and media industries face mounting pressure to combat content plagiarism and protect intellectual property rights. News organizations, book publishers, and digital content creators require robust solutions to detect unauthorized content reproduction and maintain editorial integrity. The rise of digital publishing platforms and user-generated content has created new challenges in content authenticity verification.
Financial services organizations increasingly rely on document similarity detection for fraud prevention, regulatory compliance, and risk management. Banks and insurance companies need to identify suspicious document patterns, detect fraudulent applications, and ensure compliance with evolving regulatory requirements across multiple jurisdictions.
The enterprise content management sector shows growing adoption of similarity detection technologies for knowledge management, document deduplication, and information retrieval optimization. Large corporations seek to eliminate redundant documentation, improve search capabilities, and enhance organizational knowledge sharing through advanced content analysis systems.
Market growth is further accelerated by regulatory requirements across industries, including data protection laws, financial regulations, and intellectual property enforcement mandates. Organizations must implement comprehensive content monitoring systems to meet compliance obligations and avoid substantial penalties associated with regulatory violations.
Educational institutions represent one of the largest market segments, where academic integrity enforcement has become paramount. Universities and schools worldwide require sophisticated plagiarism detection systems to maintain educational standards and ensure original student work. The shift toward online learning and digital submission platforms has further amplified this demand, as traditional manual verification methods prove inadequate for handling large volumes of academic content.
Legal and compliance sectors demonstrate equally strong market demand, particularly for contract analysis, patent research, and regulatory document management. Law firms and corporate legal departments need advanced similarity detection capabilities to identify potential conflicts, ensure compliance with existing agreements, and conduct thorough due diligence processes. The complexity of legal language and the high stakes involved in legal documentation drive requirements for highly precise and contextually aware similarity detection systems.
Publishing and media industries face mounting pressure to combat content plagiarism and protect intellectual property rights. News organizations, book publishers, and digital content creators require robust solutions to detect unauthorized content reproduction and maintain editorial integrity. The rise of digital publishing platforms and user-generated content has created new challenges in content authenticity verification.
Financial services organizations increasingly rely on document similarity detection for fraud prevention, regulatory compliance, and risk management. Banks and insurance companies need to identify suspicious document patterns, detect fraudulent applications, and ensure compliance with evolving regulatory requirements across multiple jurisdictions.
The enterprise content management sector shows growing adoption of similarity detection technologies for knowledge management, document deduplication, and information retrieval optimization. Large corporations seek to eliminate redundant documentation, improve search capabilities, and enhance organizational knowledge sharing through advanced content analysis systems.
Market growth is further accelerated by regulatory requirements across industries, including data protection laws, financial regulations, and intellectual property enforcement mandates. Organizations must implement comprehensive content monitoring systems to meet compliance obligations and avoid substantial penalties associated with regulatory violations.
Current NLP Similarity Detection Challenges
Document similarity detection in NLP faces significant computational complexity challenges when processing large-scale document collections. Traditional approaches like TF-IDF and cosine similarity struggle with scalability as document volumes increase exponentially. The quadratic time complexity of pairwise comparisons becomes prohibitive for enterprise-level applications handling millions of documents, creating bottlenecks that limit real-time processing capabilities.
Semantic understanding remains a fundamental obstacle in current NLP similarity detection systems. While syntactic matching can identify exact word overlaps, capturing deeper semantic relationships between documents with different vocabularies but similar meanings proves challenging. Documents discussing identical concepts using varied terminology often receive low similarity scores, leading to false negatives that undermine system effectiveness.
High-dimensional vector representations generated by modern embedding models introduce the curse of dimensionality problem. As feature spaces expand to thousands of dimensions, traditional distance metrics become less discriminative, making it difficult to distinguish between genuinely similar and dissimilar documents. This phenomenon particularly affects transformer-based models that produce dense embeddings with hundreds or thousands of dimensions.
Context-dependent similarity presents another critical challenge, as document relevance varies significantly across different domains and use cases. Legal documents require different similarity criteria compared to scientific papers or news articles. Current systems often lack the flexibility to adapt similarity thresholds and weighting schemes dynamically based on document types and user requirements.
Multilingual document similarity detection introduces additional complexity layers. Cross-language semantic alignment remains imperfect, with existing models showing bias toward high-resource languages. Documents in different languages expressing identical concepts may not be properly matched due to inadequate cross-lingual representation learning and cultural context variations.
Real-time processing demands conflict with accuracy requirements in many practical applications. Achieving millisecond response times while maintaining high precision and recall rates requires careful balance between model complexity and computational efficiency. Current approaches often sacrifice accuracy for speed or vice versa, limiting their applicability in time-sensitive scenarios.
Semantic understanding remains a fundamental obstacle in current NLP similarity detection systems. While syntactic matching can identify exact word overlaps, capturing deeper semantic relationships between documents with different vocabularies but similar meanings proves challenging. Documents discussing identical concepts using varied terminology often receive low similarity scores, leading to false negatives that undermine system effectiveness.
High-dimensional vector representations generated by modern embedding models introduce the curse of dimensionality problem. As feature spaces expand to thousands of dimensions, traditional distance metrics become less discriminative, making it difficult to distinguish between genuinely similar and dissimilar documents. This phenomenon particularly affects transformer-based models that produce dense embeddings with hundreds or thousands of dimensions.
Context-dependent similarity presents another critical challenge, as document relevance varies significantly across different domains and use cases. Legal documents require different similarity criteria compared to scientific papers or news articles. Current systems often lack the flexibility to adapt similarity thresholds and weighting schemes dynamically based on document types and user requirements.
Multilingual document similarity detection introduces additional complexity layers. Cross-language semantic alignment remains imperfect, with existing models showing bias toward high-resource languages. Documents in different languages expressing identical concepts may not be properly matched due to inadequate cross-lingual representation learning and cultural context variations.
Real-time processing demands conflict with accuracy requirements in many practical applications. Achieving millisecond response times while maintaining high precision and recall rates requires careful balance between model complexity and computational efficiency. Current approaches often sacrifice accuracy for speed or vice versa, limiting their applicability in time-sensitive scenarios.
Existing NLP Document Similarity Approaches
01 Vector-based semantic similarity computation
Methods for detecting document similarity using vector representations and semantic embeddings. Documents are converted into high-dimensional vector spaces where similarity is measured through distance metrics such as cosine similarity or Euclidean distance. This approach captures semantic relationships beyond simple keyword matching, enabling more accurate similarity detection between documents with different wordings but similar meanings.- Vector-based semantic similarity computation: Methods for detecting document similarity using vector representations and semantic embeddings. Documents are converted into high-dimensional vector spaces where similarity is measured through distance metrics such as cosine similarity or Euclidean distance. This approach captures semantic relationships beyond simple keyword matching, enabling more accurate similarity detection between documents with different wordings but similar meanings.
- Machine learning-based similarity classification: Application of machine learning algorithms and neural networks to classify and detect document similarity. These methods train models on labeled datasets to learn patterns and features that indicate document similarity. The trained models can then automatically identify similar documents by analyzing textual features, structural patterns, and contextual information.
- Feature extraction and comparison techniques: Techniques for extracting distinctive features from documents and comparing them to determine similarity. This includes methods such as n-gram analysis, term frequency-inverse document frequency calculations, and linguistic feature extraction. The extracted features serve as fingerprints for documents, allowing efficient comparison and similarity scoring.
- Clustering and grouping of similar documents: Methods for automatically clustering and grouping documents based on similarity measures. These approaches organize large document collections into clusters where documents within each cluster share high similarity. Clustering algorithms process document features to identify natural groupings, facilitating document organization, retrieval, and duplicate detection.
- Cross-lingual and multilingual similarity detection: Systems and methods for detecting similarity across documents in different languages. These approaches employ translation mechanisms, cross-lingual embeddings, or language-independent representations to identify similar content regardless of the source language. This enables similarity detection in multilingual environments and supports applications such as cross-lingual plagiarism detection and content matching.
02 Machine learning-based similarity classification
Application of machine learning algorithms and neural networks to classify and detect document similarity. These systems are trained on labeled datasets to learn patterns and features that indicate similar content. The models can automatically extract relevant features and make similarity determinations with improved accuracy over rule-based approaches.Expand Specific Solutions03 Text fingerprinting and hashing techniques
Methods utilizing document fingerprinting and hashing algorithms to efficiently detect similar or duplicate documents. These techniques generate compact representations of documents that can be quickly compared. Hash-based approaches enable rapid similarity detection across large document collections while maintaining computational efficiency.Expand Specific Solutions04 Natural language processing with syntactic analysis
Techniques employing syntactic parsing and linguistic analysis to determine document similarity. These methods analyze grammatical structures, sentence patterns, and linguistic features to identify similar documents. The approach considers both surface-level text features and deeper linguistic relationships to improve similarity detection accuracy.Expand Specific Solutions05 Cross-lingual and multilingual similarity detection
Systems designed to detect similarity across documents in different languages or within multilingual contexts. These methods employ translation mechanisms, cross-lingual embeddings, or language-independent features to identify similar content regardless of the source language. This enables similarity detection in global and multilingual document repositories.Expand Specific Solutions
Key Players in NLP and Text Analytics Industry
The NLP document similarity detection market is experiencing rapid growth, driven by increasing demand for automated content analysis and document processing across industries. The competitive landscape reveals a mature technology sector with established players demonstrating varying levels of technological sophistication. Tech giants like Google LLC, Microsoft Technology Licensing LLC, IBM, and Meta Platforms lead with advanced AI capabilities and comprehensive NLP platforms. Cloud service providers including ServiceNow and Zscaler integrate similarity detection into broader enterprise solutions. Chinese companies such as Baidu Online Network Technology and Inspur Cloud Information Technology contribute significant regional innovation. Academic institutions like California Institute of Technology and Central South University drive fundamental research advancement. Traditional IT services companies like Wipro Ltd. and Fujitsu Ltd. offer implementation expertise, while specialized firms like Fair Isaac Corp. focus on domain-specific applications. The technology maturity spans from research-stage algorithms to production-ready enterprise solutions, indicating a healthy ecosystem with opportunities across different market segments and geographical regions.
International Business Machines Corp.
Technical Solution: IBM's Watson Natural Language Understanding platform employs a multi-faceted approach to document similarity optimization, combining semantic analysis with entity recognition and sentiment correlation. Their solution utilizes advanced feature extraction techniques including n-gram analysis, syntactic parsing, and concept mapping to create comprehensive document representations. IBM implements machine learning algorithms that continuously adapt to domain-specific vocabularies and writing styles, while their distributed architecture ensures scalability across enterprise environments. The system incorporates intelligent preprocessing that handles multiple languages and document formats, optimizing similarity calculations through dimensionality reduction and efficient indexing strategies.
Strengths: Strong enterprise focus, multi-language support, proven track record in business applications. Weaknesses: Complex implementation, higher costs compared to open-source alternatives.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft's approach to NLP document similarity optimization centers around their Azure Cognitive Services and the development of specialized embedding models. They utilize a hybrid architecture combining traditional TF-IDF methods with modern neural embeddings, implementing efficient caching mechanisms for frequently accessed documents. Microsoft's solution features adaptive model selection based on document types and lengths, incorporating domain-specific fine-tuning capabilities. Their system employs distributed computing frameworks to handle large-scale document collections and includes advanced preprocessing pipelines that normalize text while preserving semantic meaning for optimal similarity detection performance.
Strengths: Enterprise-grade scalability, strong integration with existing Microsoft ecosystem, robust security features. Weaknesses: Licensing costs can be high, dependency on Microsoft infrastructure.
Core NLP Optimization Techniques and Patents
A text processing method and related device
PatentActiveCN112395859B
Innovation
- The sentence vector generation model with a twin network structure is used to process the first text and the second text. After generating feature vectors, strong feature extraction and dimensionality reduction are performed to obtain an output vector to determine the similarity.




Natural language processing using joint topic-sentiment detection
PatentActiveUS20210064703A1
Innovation
- The use of non-negative matrix factorization (NMF) and non-negative matrix tri-factorization (3-factor NMF) models to generate term-topic and document-sentiment correlation data, enabling efficient and accurate detection of semantic properties in short NLP input data by integrating domain-specific data and reducing reliance on high-dimensional sparse term occurrence information.
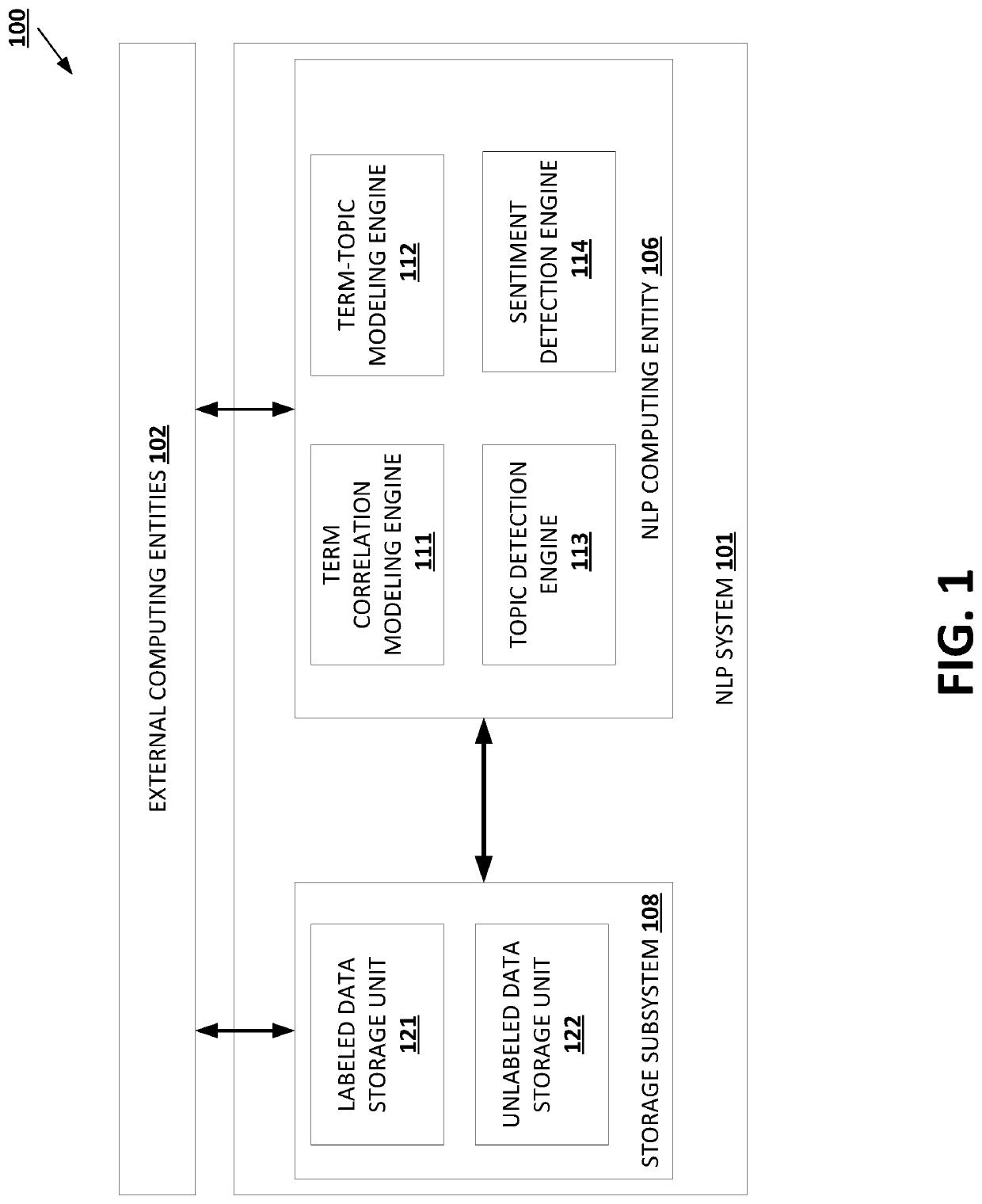
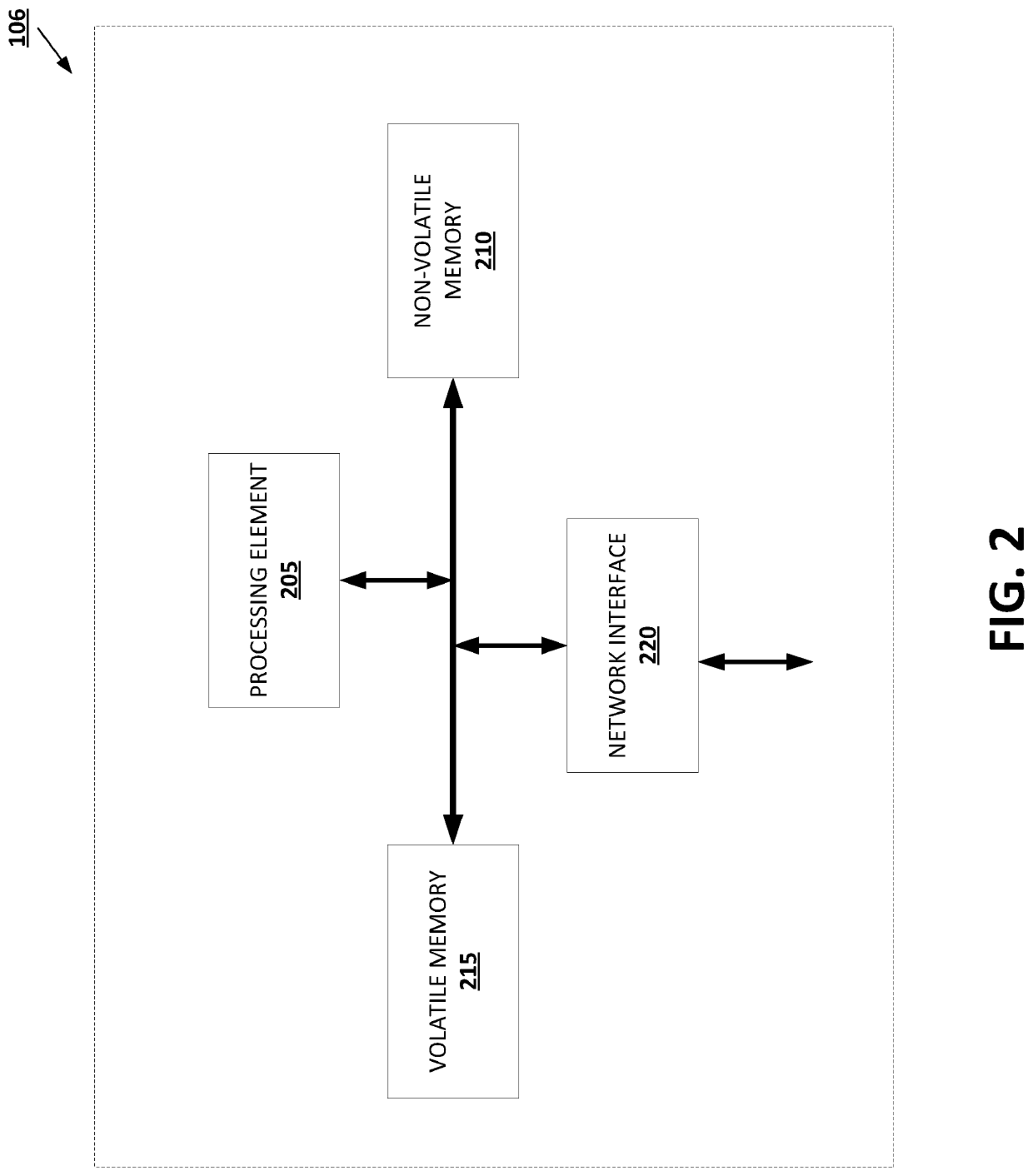
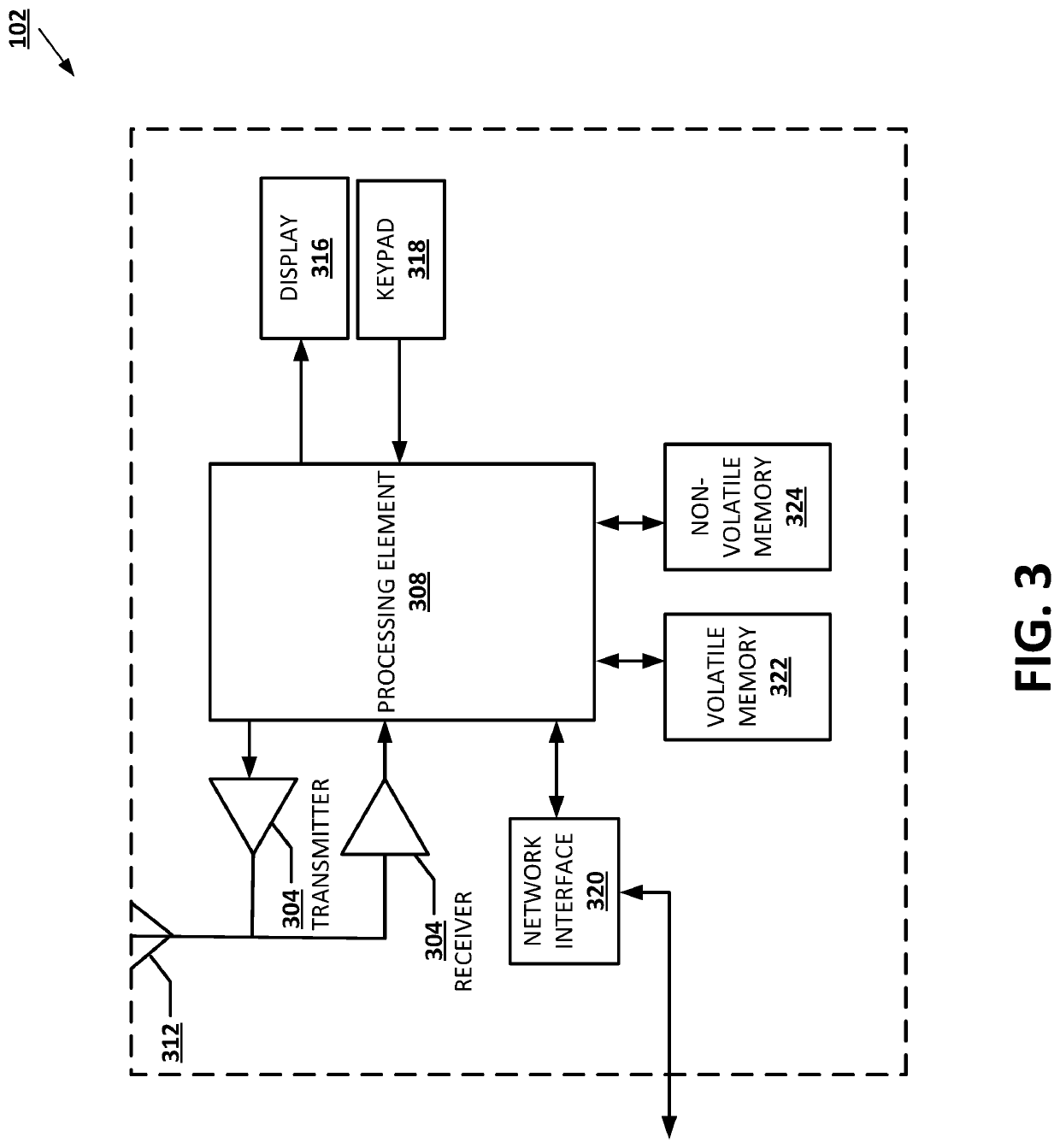

Data Privacy Regulations for Document Processing
The implementation of NLP systems for document similarity detection operates within an increasingly complex regulatory landscape that demands careful consideration of data privacy requirements. Organizations deploying these technologies must navigate a web of international, national, and sector-specific regulations that govern how personal and sensitive information is processed, stored, and analyzed.
The General Data Protection Regulation (GDPR) in the European Union establishes fundamental principles that significantly impact document processing workflows. Under GDPR, organizations must ensure lawful basis for processing, implement data minimization practices, and maintain transparency about algorithmic decision-making processes. When NLP systems analyze documents containing personal data, companies must demonstrate compliance with purpose limitation requirements and provide clear opt-out mechanisms for data subjects.
In the United States, sector-specific regulations create additional compliance layers. The Health Insurance Portability and Accountability Act (HIPAA) imposes strict requirements on healthcare document processing, mandating encryption, access controls, and audit trails for any system handling protected health information. Financial institutions must comply with regulations such as the Gramm-Leach-Bliley Act and state-level privacy laws like the California Consumer Privacy Act (CCPA), which require explicit consent mechanisms and data subject rights management.
Cross-border data transfer regulations present particular challenges for cloud-based NLP solutions. Organizations must implement appropriate safeguards such as Standard Contractual Clauses or adequacy decisions when transferring documents across jurisdictions. The invalidation of Privacy Shield and ongoing scrutiny of international data flows necessitate robust data localization strategies and careful vendor selection processes.
Emerging regulations in Asia-Pacific regions, including China's Personal Information Protection Law and India's proposed Data Protection Bill, introduce additional compliance requirements. These regulations often emphasize data localization, algorithmic transparency, and enhanced consent mechanisms that directly impact how NLP systems can be architected and deployed.
Technical implementation of privacy-compliant document similarity detection requires integration of privacy-by-design principles, including differential privacy techniques, federated learning approaches, and advanced anonymization methods. Organizations must also establish comprehensive data governance frameworks that address retention policies, deletion procedures, and regular compliance auditing to ensure ongoing regulatory adherence while maintaining system effectiveness.
The General Data Protection Regulation (GDPR) in the European Union establishes fundamental principles that significantly impact document processing workflows. Under GDPR, organizations must ensure lawful basis for processing, implement data minimization practices, and maintain transparency about algorithmic decision-making processes. When NLP systems analyze documents containing personal data, companies must demonstrate compliance with purpose limitation requirements and provide clear opt-out mechanisms for data subjects.
In the United States, sector-specific regulations create additional compliance layers. The Health Insurance Portability and Accountability Act (HIPAA) imposes strict requirements on healthcare document processing, mandating encryption, access controls, and audit trails for any system handling protected health information. Financial institutions must comply with regulations such as the Gramm-Leach-Bliley Act and state-level privacy laws like the California Consumer Privacy Act (CCPA), which require explicit consent mechanisms and data subject rights management.
Cross-border data transfer regulations present particular challenges for cloud-based NLP solutions. Organizations must implement appropriate safeguards such as Standard Contractual Clauses or adequacy decisions when transferring documents across jurisdictions. The invalidation of Privacy Shield and ongoing scrutiny of international data flows necessitate robust data localization strategies and careful vendor selection processes.
Emerging regulations in Asia-Pacific regions, including China's Personal Information Protection Law and India's proposed Data Protection Bill, introduce additional compliance requirements. These regulations often emphasize data localization, algorithmic transparency, and enhanced consent mechanisms that directly impact how NLP systems can be architected and deployed.
Technical implementation of privacy-compliant document similarity detection requires integration of privacy-by-design principles, including differential privacy techniques, federated learning approaches, and advanced anonymization methods. Organizations must also establish comprehensive data governance frameworks that address retention policies, deletion procedures, and regular compliance auditing to ensure ongoing regulatory adherence while maintaining system effectiveness.
Performance Evaluation Metrics for NLP Systems
Performance evaluation metrics serve as the cornerstone for assessing NLP systems designed for document similarity detection, providing quantitative measures to gauge system effectiveness and guide optimization efforts. These metrics enable researchers and practitioners to make informed decisions about model selection, parameter tuning, and architectural improvements.
Precision, recall, and F1-score constitute the fundamental evaluation framework for document similarity detection tasks. Precision measures the proportion of correctly identified similar document pairs among all pairs classified as similar, while recall quantifies the system's ability to identify all truly similar pairs within the dataset. The F1-score provides a harmonic mean of precision and recall, offering a balanced assessment particularly valuable when dealing with imbalanced datasets common in similarity detection scenarios.
Mean Average Precision (MAP) and Normalized Discounted Cumulative Gain (NDCG) represent sophisticated ranking-based metrics essential for evaluating retrieval-oriented similarity systems. MAP calculates the average precision across multiple queries at different recall levels, providing insights into system performance across varying similarity thresholds. NDCG accounts for the graded relevance of documents and their ranking positions, making it particularly suitable for scenarios where similarity exists on a continuous scale rather than binary classification.
Cosine similarity and Euclidean distance metrics offer direct mathematical approaches to quantify document relationships in vector space representations. These metrics provide interpretable similarity scores that can be calibrated against human judgment benchmarks, enabling fine-tuned threshold optimization for specific application domains.
Area Under the Curve (AUC) for Receiver Operating Characteristic (ROC) curves delivers threshold-independent performance assessment, crucial for understanding system behavior across different operating points. This metric proves particularly valuable when deploying systems in environments with varying similarity detection requirements.
Computational efficiency metrics including processing time per document pair, memory consumption, and scalability measurements complement accuracy-based evaluations. These performance indicators become critical when optimizing NLP systems for real-world deployment scenarios involving large document corpora and real-time processing requirements.
Human evaluation metrics through inter-annotator agreement scores and correlation with expert judgments provide essential validation for automated similarity detection systems, ensuring alignment between computational assessments and human perception of document similarity.
Precision, recall, and F1-score constitute the fundamental evaluation framework for document similarity detection tasks. Precision measures the proportion of correctly identified similar document pairs among all pairs classified as similar, while recall quantifies the system's ability to identify all truly similar pairs within the dataset. The F1-score provides a harmonic mean of precision and recall, offering a balanced assessment particularly valuable when dealing with imbalanced datasets common in similarity detection scenarios.
Mean Average Precision (MAP) and Normalized Discounted Cumulative Gain (NDCG) represent sophisticated ranking-based metrics essential for evaluating retrieval-oriented similarity systems. MAP calculates the average precision across multiple queries at different recall levels, providing insights into system performance across varying similarity thresholds. NDCG accounts for the graded relevance of documents and their ranking positions, making it particularly suitable for scenarios where similarity exists on a continuous scale rather than binary classification.
Cosine similarity and Euclidean distance metrics offer direct mathematical approaches to quantify document relationships in vector space representations. These metrics provide interpretable similarity scores that can be calibrated against human judgment benchmarks, enabling fine-tuned threshold optimization for specific application domains.
Area Under the Curve (AUC) for Receiver Operating Characteristic (ROC) curves delivers threshold-independent performance assessment, crucial for understanding system behavior across different operating points. This metric proves particularly valuable when deploying systems in environments with varying similarity detection requirements.
Computational efficiency metrics including processing time per document pair, memory consumption, and scalability measurements complement accuracy-based evaluations. These performance indicators become critical when optimizing NLP systems for real-world deployment scenarios involving large document corpora and real-time processing requirements.
Human evaluation metrics through inter-annotator agreement scores and correlation with expert judgments provide essential validation for automated similarity detection systems, ensuring alignment between computational assessments and human perception of document similarity.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!