

How to Select the Best Interconnect for Disaggregated Memory Systems
MAY 12, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Disaggregated Memory Interconnect Background and Objectives
Disaggregated memory systems represent a fundamental shift from traditional server architectures where memory resources are tightly coupled with compute units. This architectural paradigm separates memory from processors, creating independent pools of memory resources that can be dynamically allocated and shared across multiple compute nodes through high-performance interconnects. The concept emerged from the growing mismatch between compute and memory scaling patterns in modern data centers, where different workloads exhibit varying memory-to-compute ratios.
The evolution of disaggregated memory architectures traces back to early distributed computing concepts but gained significant momentum with the advent of high-speed, low-latency interconnect technologies. Initial implementations focused on network-attached storage solutions, which gradually evolved toward more sophisticated memory disaggregation approaches. The development trajectory has been driven by increasing demands for resource utilization efficiency, elastic scaling capabilities, and the need to address memory wall challenges in contemporary computing systems.
Modern disaggregated memory systems aim to achieve several critical objectives that address fundamental limitations of traditional architectures. Resource utilization optimization stands as a primary goal, enabling memory resources to be shared dynamically across compute nodes based on real-time demand patterns. This approach significantly reduces memory stranding issues commonly observed in conventional server deployments where memory resources remain underutilized due to static allocation constraints.
Scalability enhancement represents another crucial objective, allowing independent scaling of memory and compute resources according to specific workload requirements. This flexibility enables organizations to optimize their infrastructure investments by provisioning resources more precisely aligned with application demands. The architecture also facilitates improved fault tolerance through memory resource redundancy and dynamic failover capabilities.
Performance optimization objectives focus on maintaining or improving memory access latencies while providing the benefits of resource disaggregation. This requires careful consideration of interconnect technologies, memory access patterns, and system-level optimizations to ensure that the disaggregated architecture does not introduce prohibitive performance penalties compared to traditional tightly-coupled systems.
The interconnect selection process becomes critical in achieving these objectives, as it directly impacts system performance, scalability, and cost-effectiveness. Different interconnect technologies offer varying trade-offs between latency, bandwidth, scalability, and implementation complexity, making the selection process a key determinant of overall system success.
The evolution of disaggregated memory architectures traces back to early distributed computing concepts but gained significant momentum with the advent of high-speed, low-latency interconnect technologies. Initial implementations focused on network-attached storage solutions, which gradually evolved toward more sophisticated memory disaggregation approaches. The development trajectory has been driven by increasing demands for resource utilization efficiency, elastic scaling capabilities, and the need to address memory wall challenges in contemporary computing systems.
Modern disaggregated memory systems aim to achieve several critical objectives that address fundamental limitations of traditional architectures. Resource utilization optimization stands as a primary goal, enabling memory resources to be shared dynamically across compute nodes based on real-time demand patterns. This approach significantly reduces memory stranding issues commonly observed in conventional server deployments where memory resources remain underutilized due to static allocation constraints.
Scalability enhancement represents another crucial objective, allowing independent scaling of memory and compute resources according to specific workload requirements. This flexibility enables organizations to optimize their infrastructure investments by provisioning resources more precisely aligned with application demands. The architecture also facilitates improved fault tolerance through memory resource redundancy and dynamic failover capabilities.
Performance optimization objectives focus on maintaining or improving memory access latencies while providing the benefits of resource disaggregation. This requires careful consideration of interconnect technologies, memory access patterns, and system-level optimizations to ensure that the disaggregated architecture does not introduce prohibitive performance penalties compared to traditional tightly-coupled systems.
The interconnect selection process becomes critical in achieving these objectives, as it directly impacts system performance, scalability, and cost-effectiveness. Different interconnect technologies offer varying trade-offs between latency, bandwidth, scalability, and implementation complexity, making the selection process a key determinant of overall system success.
Market Demand for Disaggregated Memory Solutions
The global data center infrastructure market is experiencing unprecedented growth driven by the exponential increase in data generation, cloud computing adoption, and artificial intelligence workloads. Traditional monolithic server architectures are increasingly unable to meet the diverse performance and efficiency requirements of modern applications, creating substantial market demand for disaggregated memory solutions.
Enterprise organizations are facing significant challenges with memory utilization inefficiencies in conventional systems. Studies indicate that memory resources in traditional servers often experience utilization rates below optimal levels, with some workloads requiring high memory capacity while others demand high bandwidth. This mismatch drives the need for flexible, scalable memory architectures that can be dynamically allocated based on application requirements.
Cloud service providers represent the primary market segment driving demand for disaggregated memory systems. These organizations operate massive data centers where memory optimization directly impacts operational costs and service delivery capabilities. The ability to independently scale compute and memory resources enables more efficient resource allocation and improved total cost of ownership.
The artificial intelligence and machine learning sector presents another significant demand driver. AI workloads often require substantial memory capacity for training large models and processing extensive datasets. Disaggregated memory architectures allow AI systems to access vast memory pools without being constrained by the memory limitations of individual compute nodes.
High-performance computing applications in scientific research, financial modeling, and simulation environments also contribute to market demand. These applications frequently require memory configurations that exceed what traditional server architectures can provide, making disaggregated memory solutions essential for performance optimization.
The telecommunications industry's transition to 5G networks and edge computing infrastructure creates additional market opportunities. Edge data centers require flexible, efficient architectures that can adapt to varying workload demands while maintaining low latency requirements.
Market research indicates strong growth projections for disaggregated infrastructure solutions, with memory disaggregation representing a critical component of this transformation. The increasing adoption of containerized applications and microservices architectures further amplifies the need for flexible memory allocation mechanisms that disaggregated systems provide.
Enterprise organizations are facing significant challenges with memory utilization inefficiencies in conventional systems. Studies indicate that memory resources in traditional servers often experience utilization rates below optimal levels, with some workloads requiring high memory capacity while others demand high bandwidth. This mismatch drives the need for flexible, scalable memory architectures that can be dynamically allocated based on application requirements.
Cloud service providers represent the primary market segment driving demand for disaggregated memory systems. These organizations operate massive data centers where memory optimization directly impacts operational costs and service delivery capabilities. The ability to independently scale compute and memory resources enables more efficient resource allocation and improved total cost of ownership.
The artificial intelligence and machine learning sector presents another significant demand driver. AI workloads often require substantial memory capacity for training large models and processing extensive datasets. Disaggregated memory architectures allow AI systems to access vast memory pools without being constrained by the memory limitations of individual compute nodes.
High-performance computing applications in scientific research, financial modeling, and simulation environments also contribute to market demand. These applications frequently require memory configurations that exceed what traditional server architectures can provide, making disaggregated memory solutions essential for performance optimization.
The telecommunications industry's transition to 5G networks and edge computing infrastructure creates additional market opportunities. Edge data centers require flexible, efficient architectures that can adapt to varying workload demands while maintaining low latency requirements.
Market research indicates strong growth projections for disaggregated infrastructure solutions, with memory disaggregation representing a critical component of this transformation. The increasing adoption of containerized applications and microservices architectures further amplifies the need for flexible memory allocation mechanisms that disaggregated systems provide.
Current Interconnect Technologies and Performance Bottlenecks
Disaggregated memory systems rely on various interconnect technologies to enable efficient communication between compute nodes and remote memory pools. The current landscape encompasses several mainstream approaches, each with distinct characteristics and performance implications.
InfiniBand remains the dominant high-performance interconnect technology, offering ultra-low latency typically ranging from 0.5 to 1.5 microseconds and bandwidth capabilities exceeding 200 Gbps with HDR specifications. Its RDMA capabilities enable direct memory access without CPU intervention, making it particularly suitable for memory disaggregation scenarios. However, InfiniBand's proprietary nature and high cost present significant barriers for widespread adoption.
Ethernet-based solutions have evolved substantially with the introduction of RDMA over Converged Ethernet (RoCE) and iWARP protocols. Modern 100GbE and emerging 400GbE implementations provide competitive bandwidth while leveraging existing network infrastructure. The latency performance, though higher than InfiniBand at 2-5 microseconds, remains acceptable for many disaggregated memory applications. The standardized nature and cost-effectiveness of Ethernet make it an attractive option for enterprise deployments.
Emerging technologies like Intel's Compute Express Link (CXL) represent a paradigm shift in memory interconnects. CXL provides cache-coherent connectivity with latencies approaching local memory access patterns, typically under 200 nanoseconds. This technology enables true memory pooling with transparent access semantics, though current implementations are limited to rack-scale deployments.
Performance bottlenecks in current interconnect technologies manifest across multiple dimensions. Latency remains the primary constraint, as even microsecond-level delays can significantly impact application performance compared to local DRAM access times of 50-100 nanoseconds. This latency gap creates challenges for latency-sensitive workloads and necessitates careful application design considerations.
Bandwidth limitations become apparent under high-throughput scenarios, where multiple compute nodes simultaneously access disaggregated memory pools. Network congestion and queuing delays can severely degrade performance, particularly in oversubscribed network topologies. Current interconnects struggle to match the aggregate bandwidth of local memory subsystems, creating potential bottlenecks for memory-intensive applications.
Protocol overhead introduces additional performance penalties, especially for small memory transactions. The software stack complexity required for remote memory access, including network protocol processing and memory management, can consume significant CPU cycles and introduce unpredictable latencies. These overheads become more pronounced as the frequency of memory operations increases.
Scalability challenges emerge as system sizes grow, with current interconnect technologies facing limitations in maintaining consistent performance across large-scale deployments. Network diameter effects, switch fabric constraints, and protocol scalability issues can significantly impact system-wide memory access patterns and overall application performance.
InfiniBand remains the dominant high-performance interconnect technology, offering ultra-low latency typically ranging from 0.5 to 1.5 microseconds and bandwidth capabilities exceeding 200 Gbps with HDR specifications. Its RDMA capabilities enable direct memory access without CPU intervention, making it particularly suitable for memory disaggregation scenarios. However, InfiniBand's proprietary nature and high cost present significant barriers for widespread adoption.
Ethernet-based solutions have evolved substantially with the introduction of RDMA over Converged Ethernet (RoCE) and iWARP protocols. Modern 100GbE and emerging 400GbE implementations provide competitive bandwidth while leveraging existing network infrastructure. The latency performance, though higher than InfiniBand at 2-5 microseconds, remains acceptable for many disaggregated memory applications. The standardized nature and cost-effectiveness of Ethernet make it an attractive option for enterprise deployments.
Emerging technologies like Intel's Compute Express Link (CXL) represent a paradigm shift in memory interconnects. CXL provides cache-coherent connectivity with latencies approaching local memory access patterns, typically under 200 nanoseconds. This technology enables true memory pooling with transparent access semantics, though current implementations are limited to rack-scale deployments.
Performance bottlenecks in current interconnect technologies manifest across multiple dimensions. Latency remains the primary constraint, as even microsecond-level delays can significantly impact application performance compared to local DRAM access times of 50-100 nanoseconds. This latency gap creates challenges for latency-sensitive workloads and necessitates careful application design considerations.
Bandwidth limitations become apparent under high-throughput scenarios, where multiple compute nodes simultaneously access disaggregated memory pools. Network congestion and queuing delays can severely degrade performance, particularly in oversubscribed network topologies. Current interconnects struggle to match the aggregate bandwidth of local memory subsystems, creating potential bottlenecks for memory-intensive applications.
Protocol overhead introduces additional performance penalties, especially for small memory transactions. The software stack complexity required for remote memory access, including network protocol processing and memory management, can consume significant CPU cycles and introduce unpredictable latencies. These overheads become more pronounced as the frequency of memory operations increases.
Scalability challenges emerge as system sizes grow, with current interconnect technologies facing limitations in maintaining consistent performance across large-scale deployments. Network diameter effects, switch fabric constraints, and protocol scalability issues can significantly impact system-wide memory access patterns and overall application performance.
Existing Interconnect Solutions for Memory Disaggregation
01 Interconnect routing algorithms and path optimization
Advanced algorithms are employed to determine optimal routing paths for interconnects in integrated circuits and electronic systems. These methods focus on minimizing signal delay, reducing power consumption, and improving overall system performance through intelligent path selection and routing optimization techniques.- Routing algorithms and path optimization techniques: Advanced routing algorithms are employed to determine optimal paths for interconnect selection, considering factors such as signal delay, power consumption, and congestion. These techniques utilize mathematical models and heuristic approaches to evaluate multiple routing options and select the most efficient paths. The algorithms can dynamically adapt to changing network conditions and optimize for various performance metrics simultaneously.
- Machine learning and AI-based optimization methods: Artificial intelligence and machine learning techniques are integrated into interconnect selection systems to predict optimal routing decisions based on historical data and real-time network conditions. These methods can learn from past performance patterns and automatically adjust selection criteria to improve overall system efficiency. Neural networks and reinforcement learning algorithms are commonly used to enhance decision-making processes.
- Multi-objective optimization frameworks: Comprehensive optimization frameworks that simultaneously consider multiple objectives such as latency minimization, bandwidth maximization, power efficiency, and reliability. These systems use weighted scoring methods or Pareto optimization to balance competing requirements and find optimal trade-offs. The frameworks can be customized for different application requirements and performance priorities.
- Dynamic reconfiguration and adaptive selection: Systems that provide real-time reconfiguration capabilities to adapt interconnect selections based on changing network conditions, traffic patterns, and system requirements. These solutions monitor network performance continuously and can switch between different interconnect options to maintain optimal performance. The adaptive mechanisms help prevent bottlenecks and ensure consistent system operation under varying loads.
- Hardware-software co-optimization approaches: Integrated optimization strategies that consider both hardware constraints and software requirements to achieve optimal interconnect selection. These approaches involve close coordination between physical layer design and higher-level protocol optimization. The methods account for manufacturing limitations, thermal considerations, and electrical characteristics while optimizing for software-defined performance metrics.
02 Multi-layer interconnect structure design
Optimization techniques for designing multi-layer interconnect architectures that maximize signal integrity while minimizing cross-talk and electromagnetic interference. These approaches involve strategic placement of interconnect layers and optimization of via structures to enhance overall circuit performance.Expand Specific Solutions03 Dynamic interconnect selection and switching
Methods for dynamically selecting and switching between different interconnect paths based on real-time system conditions, traffic load, and performance requirements. These techniques enable adaptive interconnect management to optimize bandwidth utilization and reduce latency.Expand Specific Solutions04 Interconnect topology optimization for network-on-chip
Specialized optimization approaches for network-on-chip architectures that focus on selecting optimal interconnect topologies and configurations. These methods consider factors such as scalability, fault tolerance, and energy efficiency to determine the best interconnect arrangements for chip-level communication networks.Expand Specific Solutions05 Machine learning-based interconnect optimization
Application of artificial intelligence and machine learning techniques to optimize interconnect selection and configuration. These approaches use predictive models and learning algorithms to automatically determine optimal interconnect parameters and adapt to changing system requirements for improved performance and efficiency.Expand Specific Solutions
Key Players in Disaggregated Memory and Interconnect Industry
The disaggregated memory systems interconnect market is in a rapidly evolving growth stage, driven by increasing demand for scalable data center architectures and AI workloads. The market represents a multi-billion dollar opportunity as enterprises seek to optimize memory utilization and reduce costs through memory pooling technologies. Technology maturity varies significantly across different interconnect approaches, with established players like Intel, Samsung Electronics, and Mellanox Technologies leading traditional high-speed electrical interconnects, while companies such as AvicenaTech are pioneering next-generation optical solutions. Memory specialists including Micron Technology and KIOXIA are developing memory-centric interconnect standards, and system integrators like Hewlett Packard Enterprise and IBM are creating comprehensive disaggregated memory platforms. The competitive landscape shows a convergence of semiconductor giants, networking specialists, and emerging startups, indicating the technology is transitioning from experimental to commercially viable solutions with varying degrees of market readiness.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung develops Compute Express Link (CXL) based memory expansion solutions for disaggregated architectures. Their CXL memory modules provide cache-coherent access to remote DRAM and emerging memory technologies like MRAM and Z-NAND. Samsung's Memory-Semantic SSD technology bridges storage and memory domains with microsecond-level access times. They offer tiered memory solutions combining high-bandwidth HBM, standard DDR, and persistent storage in unified address spaces. Samsung's SmartSSD computational storage drives reduce data movement by processing data closer to storage, optimizing disaggregated workloads through near-data computing capabilities.
Strengths: Leading memory technology portfolio, CXL expertise, computational storage innovation. Weaknesses: Limited networking hardware ecosystem, dependency on third-party interconnect providers.
Hewlett Packard Enterprise Development LP
Technical Solution: HPE implements The Machine architecture concept featuring photonic interconnects for memory-centric computing. Their Slingshot interconnect technology provides adaptive routing with congestion management specifically optimized for memory-intensive workloads. HPE's Memory-Driven Computing initiative includes fabric-attached memory pools accessible via high-speed optical connections. They develop composable infrastructure solutions where memory resources can be dynamically allocated across compute nodes through software-defined networking. HPE's approach emphasizes photonic switching matrices that enable massive memory bandwidth scaling with reduced power consumption compared to electrical interconnects.
Strengths: Innovative photonic interconnect technology, composable infrastructure expertise, memory-centric architecture vision. Weaknesses: Early-stage photonic technology maturity, limited commercial deployment scale.
Core Innovations in High-Performance Memory Interconnects
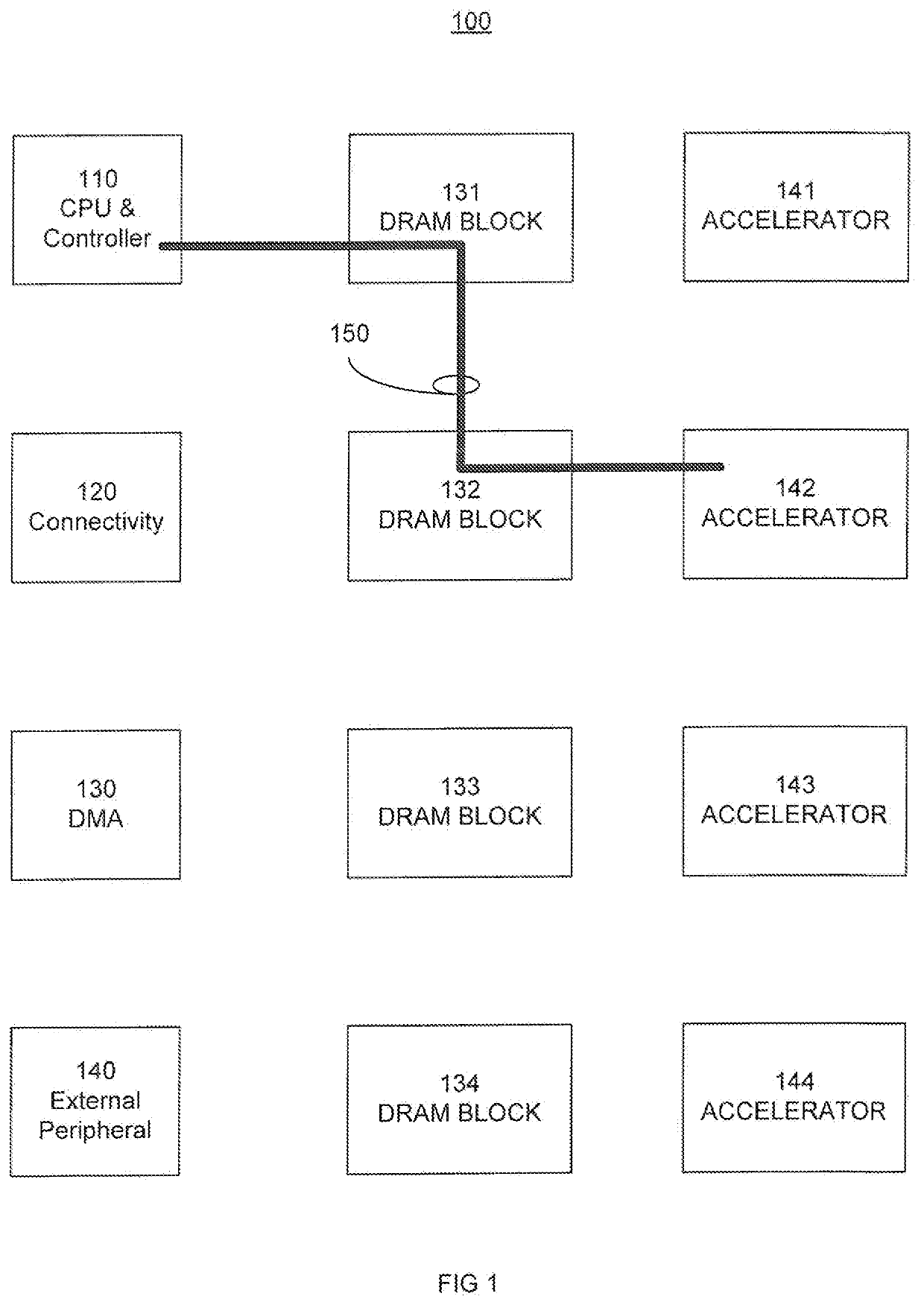
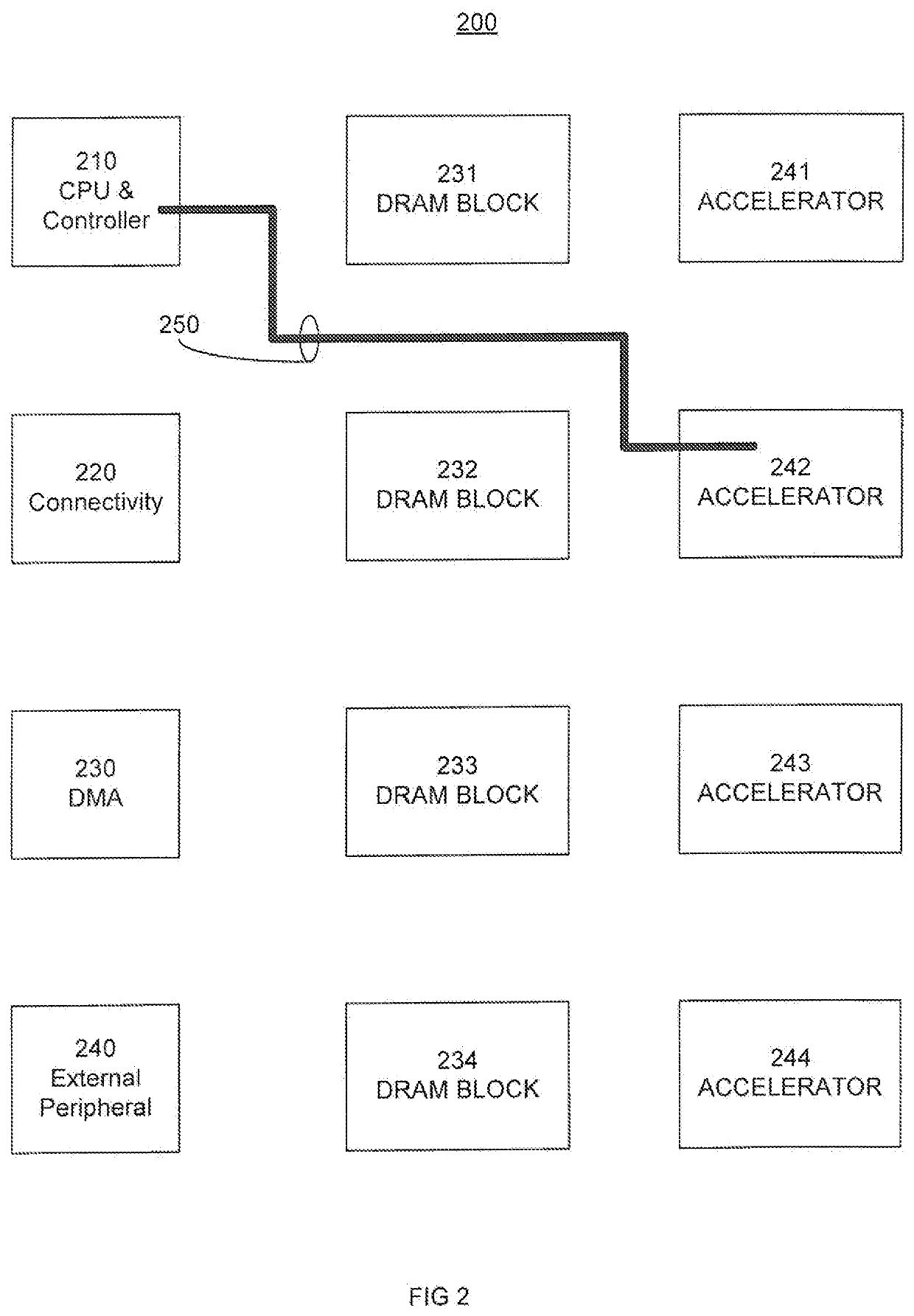
Computer architecture with disaggregated memory and high-bandwidth communication interconnects
PatentActiveUS12117930B2
Innovation
- A computer system utilizing photonic interconnects to create a unified contiguous memory address space disaggregated from processing units, enabling low-power, high-bandwidth-density communication through memory aggregation devices, computational devices, and switching systems that allow simultaneous data transfers across multiple memory modules.




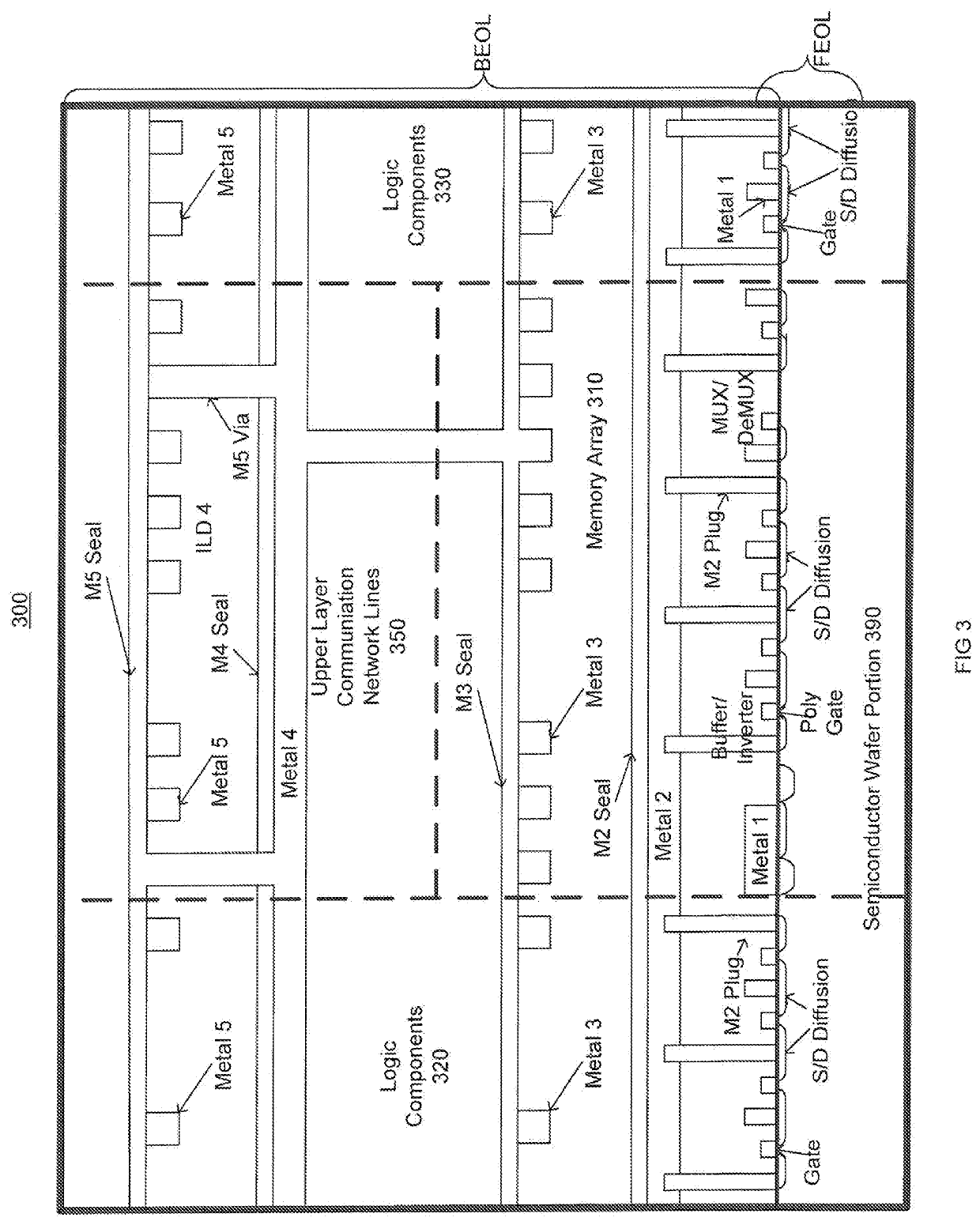
Memory interconnection architecture systems and methods
PatentActiveUS20220101887A1
Innovation
- The implementation of a Processing-in-Memory (PIM) chip with a memory array, logic components, and an interconnection network that includes switches and interconnect wires, where the interconnection network is configured to communicatively couple logic components and storage cells, utilizing upper metal layers for improved routing and scalability.

Standardization Efforts in Memory Interconnect Protocols
The standardization of memory interconnect protocols represents a critical foundation for the widespread adoption of disaggregated memory systems. Industry-wide efforts have emerged to establish common frameworks that ensure interoperability, reduce development costs, and accelerate market adoption across diverse computing environments.
The Compute Express Link (CXL) consortium has emerged as the most prominent standardization body in this domain. CXL 2.0 and the upcoming CXL 3.0 specifications define comprehensive protocols for memory pooling, sharing, and disaggregation. These standards establish unified interfaces for cache-coherent memory access, enabling seamless integration between processors and memory resources across different vendors. The protocol stack includes transaction layer specifications, physical layer requirements, and memory semantic definitions that facilitate consistent implementation across the industry.
Gen-Z consortium, though now merged with CXL efforts, contributed significant groundwork for fabric-based memory architectures. The Gen-Z specification introduced concepts of memory-semantic fabrics and established protocols for direct memory access across distributed systems. These early standardization efforts laid the foundation for current disaggregated memory protocols and influenced the development of subsequent standards.
The JEDEC Solid State Technology Association has played a complementary role by standardizing memory device interfaces and electrical specifications. JEDEC's DDR5 and emerging DDR6 standards define the physical and electrical characteristics that memory interconnect protocols must accommodate. These device-level standards ensure compatibility between standardized interconnect protocols and actual memory hardware implementations.
OpenCAPI (Open Coherent Accelerator Processor Interface) represents another significant standardization effort, particularly focused on high-performance computing applications. The OpenCAPI specification defines coherent interfaces for memory and accelerator connectivity, providing an alternative approach to memory disaggregation that emphasizes low-latency access and cache coherence across distributed memory pools.
Industry collaboration through these standardization bodies has resulted in reference implementations, compliance testing frameworks, and certification programs. These initiatives reduce technical risks for organizations implementing disaggregated memory systems and provide clear guidance for interconnect selection decisions. The convergence toward common standards significantly influences the evaluation criteria for memory interconnect technologies in enterprise deployments.
The Compute Express Link (CXL) consortium has emerged as the most prominent standardization body in this domain. CXL 2.0 and the upcoming CXL 3.0 specifications define comprehensive protocols for memory pooling, sharing, and disaggregation. These standards establish unified interfaces for cache-coherent memory access, enabling seamless integration between processors and memory resources across different vendors. The protocol stack includes transaction layer specifications, physical layer requirements, and memory semantic definitions that facilitate consistent implementation across the industry.
Gen-Z consortium, though now merged with CXL efforts, contributed significant groundwork for fabric-based memory architectures. The Gen-Z specification introduced concepts of memory-semantic fabrics and established protocols for direct memory access across distributed systems. These early standardization efforts laid the foundation for current disaggregated memory protocols and influenced the development of subsequent standards.
The JEDEC Solid State Technology Association has played a complementary role by standardizing memory device interfaces and electrical specifications. JEDEC's DDR5 and emerging DDR6 standards define the physical and electrical characteristics that memory interconnect protocols must accommodate. These device-level standards ensure compatibility between standardized interconnect protocols and actual memory hardware implementations.
OpenCAPI (Open Coherent Accelerator Processor Interface) represents another significant standardization effort, particularly focused on high-performance computing applications. The OpenCAPI specification defines coherent interfaces for memory and accelerator connectivity, providing an alternative approach to memory disaggregation that emphasizes low-latency access and cache coherence across distributed memory pools.
Industry collaboration through these standardization bodies has resulted in reference implementations, compliance testing frameworks, and certification programs. These initiatives reduce technical risks for organizations implementing disaggregated memory systems and provide clear guidance for interconnect selection decisions. The convergence toward common standards significantly influences the evaluation criteria for memory interconnect technologies in enterprise deployments.
Cost-Performance Trade-offs in Interconnect Selection
The selection of interconnects for disaggregated memory systems fundamentally revolves around balancing cost constraints with performance requirements. Organizations must carefully evaluate the total cost of ownership, which encompasses not only the initial hardware investment but also operational expenses including power consumption, cooling requirements, and maintenance overhead. High-performance interconnects such as InfiniBand EDR/HDR typically command premium pricing but deliver superior bandwidth and ultra-low latency characteristics essential for memory-intensive workloads.
Performance considerations extend beyond raw bandwidth metrics to include latency profiles, jitter characteristics, and scalability limitations. While Ethernet-based solutions offer attractive cost advantages and widespread compatibility, they may introduce higher latency variations that could impact application performance in latency-sensitive scenarios. The trade-off becomes particularly pronounced when considering CPU overhead, as some interconnect technologies require significant processing resources for protocol handling, potentially offsetting their cost benefits.
Power efficiency represents another critical dimension in the cost-performance equation. Modern interconnect technologies vary significantly in their power consumption profiles, with some high-speed solutions consuming substantial power per port while others optimize for energy efficiency. This consideration becomes amplified in large-scale deployments where power and cooling costs can exceed initial hardware investments over the system lifecycle.
Scalability economics further complicate the selection process. While certain interconnect solutions may appear cost-effective for smaller deployments, their cost structure may not scale linearly with system growth. Network topology requirements, switch fabric costs, and cabling complexity all contribute to the total economic impact as systems expand.
The emergence of specialized memory interconnects introduces additional complexity to the cost-performance analysis. These purpose-built solutions often provide optimized performance characteristics for memory disaggregation but may carry higher per-port costs and limited vendor ecosystems. Organizations must weigh these factors against the potential performance gains and future-proofing benefits when making selection decisions for their disaggregated memory infrastructure.
Performance considerations extend beyond raw bandwidth metrics to include latency profiles, jitter characteristics, and scalability limitations. While Ethernet-based solutions offer attractive cost advantages and widespread compatibility, they may introduce higher latency variations that could impact application performance in latency-sensitive scenarios. The trade-off becomes particularly pronounced when considering CPU overhead, as some interconnect technologies require significant processing resources for protocol handling, potentially offsetting their cost benefits.
Power efficiency represents another critical dimension in the cost-performance equation. Modern interconnect technologies vary significantly in their power consumption profiles, with some high-speed solutions consuming substantial power per port while others optimize for energy efficiency. This consideration becomes amplified in large-scale deployments where power and cooling costs can exceed initial hardware investments over the system lifecycle.
Scalability economics further complicate the selection process. While certain interconnect solutions may appear cost-effective for smaller deployments, their cost structure may not scale linearly with system growth. Network topology requirements, switch fabric costs, and cabling complexity all contribute to the total economic impact as systems expand.
The emergence of specialized memory interconnects introduces additional complexity to the cost-performance analysis. These purpose-built solutions often provide optimized performance characteristics for memory disaggregation but may carry higher per-port costs and limited vendor ecosystems. Organizations must weigh these factors against the potential performance gains and future-proofing benefits when making selection decisions for their disaggregated memory infrastructure.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!