

Multilayer Perceptron vs Generative Adversarial Networks: Data Synthesis Analysis
APR 2, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
MLP vs GAN Data Synthesis Background and Objectives
Data synthesis has emerged as a critical technological domain driven by the exponential growth of data-dependent applications and the increasing scarcity of high-quality labeled datasets. The evolution of artificial intelligence and machine learning systems has created an unprecedented demand for diverse, representative training data that can effectively capture the complexity of real-world scenarios while addressing privacy, cost, and accessibility constraints.
The historical development of data synthesis techniques can be traced back to early statistical modeling approaches in the 1960s, progressing through rule-based systems in the 1980s, to the emergence of neural network-based solutions in the 1990s. Multilayer Perceptrons represented one of the foundational approaches, leveraging their universal approximation capabilities to model complex data distributions through supervised learning paradigms.
The introduction of Generative Adversarial Networks in 2014 marked a revolutionary shift in data synthesis methodology, establishing an adversarial training framework that fundamentally transformed the landscape of synthetic data generation. This innovation sparked a new era of unsupervised learning approaches that could generate highly realistic synthetic samples across various data modalities.
Current technological objectives in this domain focus on achieving several critical milestones. Primary goals include developing synthesis methods that can generate data with statistical fidelity matching original distributions while maintaining semantic coherence and structural integrity. The pursuit of scalable solutions capable of handling high-dimensional data spaces represents another fundamental objective.
Quality preservation remains a paramount concern, with emphasis on maintaining the utility of synthetic data for downstream machine learning tasks while ensuring privacy protection through effective anonymization. The development of robust evaluation frameworks for assessing synthesis quality across different metrics constitutes an essential technical target.
Efficiency optimization represents a crucial objective, particularly in terms of computational resource utilization and training time requirements. The ability to generate diverse synthetic samples that capture rare events and edge cases while avoiding mode collapse scenarios forms another key technical goal.
The convergence of these technological trajectories aims to establish comprehensive data synthesis frameworks that can democratize access to high-quality training data across industries, enabling more robust and generalizable machine learning applications while addressing ethical and regulatory requirements surrounding data usage and privacy protection.
The historical development of data synthesis techniques can be traced back to early statistical modeling approaches in the 1960s, progressing through rule-based systems in the 1980s, to the emergence of neural network-based solutions in the 1990s. Multilayer Perceptrons represented one of the foundational approaches, leveraging their universal approximation capabilities to model complex data distributions through supervised learning paradigms.
The introduction of Generative Adversarial Networks in 2014 marked a revolutionary shift in data synthesis methodology, establishing an adversarial training framework that fundamentally transformed the landscape of synthetic data generation. This innovation sparked a new era of unsupervised learning approaches that could generate highly realistic synthetic samples across various data modalities.
Current technological objectives in this domain focus on achieving several critical milestones. Primary goals include developing synthesis methods that can generate data with statistical fidelity matching original distributions while maintaining semantic coherence and structural integrity. The pursuit of scalable solutions capable of handling high-dimensional data spaces represents another fundamental objective.
Quality preservation remains a paramount concern, with emphasis on maintaining the utility of synthetic data for downstream machine learning tasks while ensuring privacy protection through effective anonymization. The development of robust evaluation frameworks for assessing synthesis quality across different metrics constitutes an essential technical target.
Efficiency optimization represents a crucial objective, particularly in terms of computational resource utilization and training time requirements. The ability to generate diverse synthetic samples that capture rare events and edge cases while avoiding mode collapse scenarios forms another key technical goal.
The convergence of these technological trajectories aims to establish comprehensive data synthesis frameworks that can democratize access to high-quality training data across industries, enabling more robust and generalizable machine learning applications while addressing ethical and regulatory requirements surrounding data usage and privacy protection.
Market Demand for AI-Generated Synthetic Data Solutions
The global synthetic data market has experienced unprecedented growth driven by increasing data privacy regulations, limited access to real-world datasets, and the rising demand for machine learning model training data. Organizations across industries face mounting pressure to develop AI solutions while navigating stringent data protection requirements such as GDPR and CCPA, creating substantial demand for artificially generated datasets that preserve statistical properties without compromising individual privacy.
Healthcare and pharmaceutical sectors represent the largest consumer segments for synthetic data solutions, particularly for medical imaging, clinical trial simulation, and drug discovery applications. Financial services follow closely, utilizing synthetic datasets for fraud detection model training, risk assessment, and regulatory compliance testing. The autonomous vehicle industry has emerged as another significant market driver, requiring vast amounts of diverse driving scenarios and edge cases that are difficult or dangerous to collect in real-world conditions.
Enterprise adoption patterns reveal a clear preference for solutions that can generate high-fidelity tabular data, time-series data, and unstructured content including images and text. Organizations increasingly seek synthetic data platforms that can maintain complex relationships between variables while ensuring differential privacy guarantees. The demand extends beyond simple data augmentation to comprehensive dataset replacement strategies that enable secure data sharing between organizations and accelerated model development cycles.
Regulatory compliance requirements continue to fuel market expansion as organizations recognize synthetic data as a viable solution for maintaining analytical capabilities while adhering to data protection mandates. The growing sophistication of AI applications has created demand for more nuanced synthetic data generation techniques that can capture subtle patterns and correlations present in original datasets.
Market dynamics indicate strong growth potential in emerging applications including personalized medicine, smart city development, and edge computing scenarios where data collection faces significant logistical or privacy constraints. The convergence of synthetic data generation with federated learning and privacy-preserving machine learning techniques represents a particularly promising growth vector for enterprise adoption.
Healthcare and pharmaceutical sectors represent the largest consumer segments for synthetic data solutions, particularly for medical imaging, clinical trial simulation, and drug discovery applications. Financial services follow closely, utilizing synthetic datasets for fraud detection model training, risk assessment, and regulatory compliance testing. The autonomous vehicle industry has emerged as another significant market driver, requiring vast amounts of diverse driving scenarios and edge cases that are difficult or dangerous to collect in real-world conditions.
Enterprise adoption patterns reveal a clear preference for solutions that can generate high-fidelity tabular data, time-series data, and unstructured content including images and text. Organizations increasingly seek synthetic data platforms that can maintain complex relationships between variables while ensuring differential privacy guarantees. The demand extends beyond simple data augmentation to comprehensive dataset replacement strategies that enable secure data sharing between organizations and accelerated model development cycles.
Regulatory compliance requirements continue to fuel market expansion as organizations recognize synthetic data as a viable solution for maintaining analytical capabilities while adhering to data protection mandates. The growing sophistication of AI applications has created demand for more nuanced synthetic data generation techniques that can capture subtle patterns and correlations present in original datasets.
Market dynamics indicate strong growth potential in emerging applications including personalized medicine, smart city development, and edge computing scenarios where data collection faces significant logistical or privacy constraints. The convergence of synthetic data generation with federated learning and privacy-preserving machine learning techniques represents a particularly promising growth vector for enterprise adoption.
Current State of MLP and GAN Data Synthesis Capabilities
Multilayer Perceptrons have established themselves as fundamental building blocks in data synthesis applications, particularly excelling in structured data generation and feature transformation tasks. Current MLP implementations demonstrate robust performance in generating tabular datasets, time series data, and low-dimensional synthetic samples. Modern MLP architectures incorporate advanced activation functions, dropout mechanisms, and batch normalization techniques that significantly enhance their synthesis capabilities. However, MLPs face inherent limitations when dealing with high-dimensional data such as images or complex sequential patterns, often struggling to capture intricate spatial relationships and long-range dependencies.
Generative Adversarial Networks represent a paradigm shift in data synthesis technology, leveraging adversarial training mechanisms to produce highly realistic synthetic data across multiple domains. Contemporary GAN variants, including StyleGAN, BigGAN, and Progressive GANs, demonstrate exceptional capabilities in generating high-resolution images, realistic human faces, and complex visual content that often becomes indistinguishable from real data. The adversarial framework enables GANs to learn sophisticated data distributions and generate samples with remarkable fidelity and diversity.
The current technological landscape reveals distinct performance characteristics between these approaches. MLPs excel in computational efficiency and training stability, making them suitable for resource-constrained environments and applications requiring consistent, predictable outputs. Their deterministic nature and straightforward architecture facilitate easier debugging and interpretation of synthesis processes. Conversely, GANs demonstrate superior performance in capturing complex data distributions and generating high-quality samples, particularly in computer vision and creative applications.
Recent developments have introduced hybrid approaches that combine MLP components within GAN architectures, leveraging the stability of MLPs while maintaining the generative power of adversarial training. These innovations address traditional GAN challenges such as mode collapse and training instability while preserving synthesis quality. Additionally, emerging techniques like Variational Autoencoders with MLP encoders and GAN-based decoders represent promising directions for enhanced data synthesis capabilities.
Current limitations persist across both technologies. MLPs continue to struggle with generating diverse, high-dimensional outputs, while GANs face ongoing challenges related to training convergence, computational requirements, and evaluation metrics. The field increasingly focuses on developing more efficient training algorithms, improved loss functions, and better evaluation frameworks to assess synthesis quality objectively.
Generative Adversarial Networks represent a paradigm shift in data synthesis technology, leveraging adversarial training mechanisms to produce highly realistic synthetic data across multiple domains. Contemporary GAN variants, including StyleGAN, BigGAN, and Progressive GANs, demonstrate exceptional capabilities in generating high-resolution images, realistic human faces, and complex visual content that often becomes indistinguishable from real data. The adversarial framework enables GANs to learn sophisticated data distributions and generate samples with remarkable fidelity and diversity.
The current technological landscape reveals distinct performance characteristics between these approaches. MLPs excel in computational efficiency and training stability, making them suitable for resource-constrained environments and applications requiring consistent, predictable outputs. Their deterministic nature and straightforward architecture facilitate easier debugging and interpretation of synthesis processes. Conversely, GANs demonstrate superior performance in capturing complex data distributions and generating high-quality samples, particularly in computer vision and creative applications.
Recent developments have introduced hybrid approaches that combine MLP components within GAN architectures, leveraging the stability of MLPs while maintaining the generative power of adversarial training. These innovations address traditional GAN challenges such as mode collapse and training instability while preserving synthesis quality. Additionally, emerging techniques like Variational Autoencoders with MLP encoders and GAN-based decoders represent promising directions for enhanced data synthesis capabilities.
Current limitations persist across both technologies. MLPs continue to struggle with generating diverse, high-dimensional outputs, while GANs face ongoing challenges related to training convergence, computational requirements, and evaluation metrics. The field increasingly focuses on developing more efficient training algorithms, improved loss functions, and better evaluation frameworks to assess synthesis quality objectively.
Existing MLP and GAN Approaches for Data Synthesis
01 GAN-based synthetic data generation for training machine learning models
Generative Adversarial Networks are utilized to synthesize artificial training data that mimics real-world data distributions. This approach addresses data scarcity issues and enables the creation of diverse datasets for training machine learning models, particularly when real data is limited, sensitive, or expensive to obtain. The synthetic data generated can be used to augment existing datasets and improve model performance across various applications.- GAN-based synthetic data generation for training machine learning models: Generative Adversarial Networks are utilized to synthesize artificial training data that mimics real-world data distributions. This approach addresses data scarcity issues and enables the creation of diverse datasets for training machine learning models, particularly when real data is limited, sensitive, or expensive to obtain. The synthetic data generated can be used to augment existing datasets and improve model performance across various applications.
- Multilayer Perceptron architectures for discriminator and generator networks: Multilayer Perceptron networks serve as fundamental building blocks in GAN architectures, functioning as either discriminator or generator components. These neural network structures with multiple hidden layers enable complex feature learning and pattern recognition. The MLP-based approach facilitates the training process where the generator learns to create realistic synthetic data while the discriminator learns to distinguish between real and synthetic samples.
- Conditional GANs with MLP for controlled data synthesis: Conditional generation techniques incorporate additional input parameters or labels to guide the synthesis process, allowing for controlled generation of specific data types or categories. This methodology combines multilayer perceptron architectures with conditional inputs to produce targeted synthetic data that meets specific requirements or constraints, enhancing the utility and applicability of generated datasets for specialized tasks.
- Hybrid architectures combining MLPs with adversarial training: Advanced neural network designs integrate multilayer perceptron components with adversarial training frameworks to optimize data synthesis quality. These hybrid approaches leverage the strengths of both MLP architectures and GAN training dynamics to achieve improved convergence, stability, and output quality. The combination enables more efficient learning of complex data distributions and generation of high-fidelity synthetic samples.
- Data augmentation and privacy preservation through synthetic data generation: Synthetic data generation techniques address privacy concerns and data augmentation needs by creating artificial datasets that preserve statistical properties while protecting sensitive information. This approach enables organizations to share and utilize data for research and development without compromising individual privacy or violating data protection regulations. The generated synthetic data maintains the utility of original datasets while eliminating direct links to real individuals or entities.
02 Multilayer Perceptron architectures for discriminator and generator networks
Multilayer Perceptron networks serve as fundamental building blocks in GAN architectures, functioning as either discriminator or generator components. These neural network structures with multiple hidden layers enable complex feature learning and pattern recognition. The MLP-based approach facilitates the training process where the generator learns to create realistic synthetic data while the discriminator learns to distinguish between real and synthetic samples.Expand Specific Solutions03 Conditional GANs for controlled synthetic data generation
Conditional generation techniques allow for controlled synthesis of data by incorporating additional information or constraints into the generation process. This enables the creation of synthetic data with specific characteristics or attributes, providing more targeted and useful training samples. The conditioning mechanism guides the generation process to produce data that meets particular requirements or belongs to specific categories.Expand Specific Solutions04 Hybrid architectures combining MLPs with advanced neural network components
Advanced implementations integrate Multilayer Perceptrons with other neural network architectures such as convolutional layers, recurrent units, or attention mechanisms to enhance the quality and diversity of synthesized data. These hybrid approaches leverage the strengths of different network types to improve feature extraction, temporal modeling, or spatial understanding in the data synthesis process.Expand Specific Solutions05 Training optimization and stability techniques for GAN-MLP systems
Various optimization methods and training strategies are employed to improve the stability and convergence of GAN systems utilizing Multilayer Perceptrons. These techniques address common challenges such as mode collapse, vanishing gradients, and training instability. Methods include specialized loss functions, regularization approaches, progressive training schemes, and architectural modifications that ensure more reliable and efficient synthetic data generation.Expand Specific Solutions
Key Players in AI Data Synthesis and Generation Industry
The competitive landscape for Multilayer Perceptron versus Generative Adversarial Networks in data synthesis represents a mature, rapidly evolving market segment within the broader AI/ML industry. The sector has reached significant scale, with established technology giants like NVIDIA Corp., IBM, and Google LLC driving hardware acceleration and cloud-based ML platforms, while Samsung Electronics and Sony Group Corp. integrate these technologies into consumer applications. Academic institutions including Zhejiang University and Hangzhou Dianzi University contribute foundational research, particularly in GAN architectures. The technology demonstrates high maturity levels, evidenced by widespread enterprise adoption across automotive (Ford Global Technologies, Continental Autonomous Mobility), telecommunications (Telefónica), and cybersecurity (Fortinet) sectors. Market consolidation is evident as major players like Amazon Technologies and NEC Corp. offer comprehensive AI-as-a-Service solutions, indicating the transition from experimental research to production-ready implementations for synthetic data generation applications.
International Business Machines Corp.
Technical Solution: IBM's approach to MLP vs GAN analysis focuses on enterprise-grade data synthesis solutions through their Watson AI platform. Their research demonstrates that MLPs excel in structured data synthesis tasks with 15-30% better performance in tabular data generation compared to GANs. However, for unstructured data synthesis, their GAN implementations show superior results in generating realistic synthetic datasets for privacy-preserving analytics. IBM's hybrid architecture combines MLP-based feature extractors with GAN generators, achieving balanced performance across different data types. Their federated learning framework enables distributed training of both architectures while maintaining data privacy, particularly valuable for healthcare and financial data synthesis applications.
Strengths: Enterprise focus, strong privacy protection, hybrid architecture flexibility. Weaknesses: Limited consumer market presence, complex implementation requirements.
NVIDIA Corp.
Technical Solution: NVIDIA has developed comprehensive frameworks for both MLPs and GANs in data synthesis applications. Their CUDA-accelerated deep learning libraries provide optimized implementations for multilayer perceptrons with tensor operations achieving up to 20x speedup over CPU implementations. For GANs, NVIDIA's StyleGAN architecture demonstrates superior performance in high-resolution image synthesis, generating photorealistic images at 1024x1024 resolution. Their unified approach combines MLP-based discriminators with convolutional generators, enabling efficient training on their GPU architecture. The company's cuDNN library provides highly optimized primitives for both network types, supporting mixed-precision training that reduces memory usage by 50% while maintaining model accuracy.
Strengths: Industry-leading GPU acceleration, comprehensive deep learning ecosystem, proven scalability. Weaknesses: High hardware costs, vendor lock-in concerns.
Core Innovations in Neural Network Data Generation Methods
Synthetic data for neural network training using vectors
PatentActiveUS20210201003A1
Innovation
- The use of generative adversarial networks (GANs) to create synthetic vectors that mimic real vector representations of facial elements, which are then used to augment training datasets, enabling the neural network to better identify and classify facial expressions, cognitive states, and emotional states, and improve the training process by generating additional synthetic data that avoids discriminator detection.




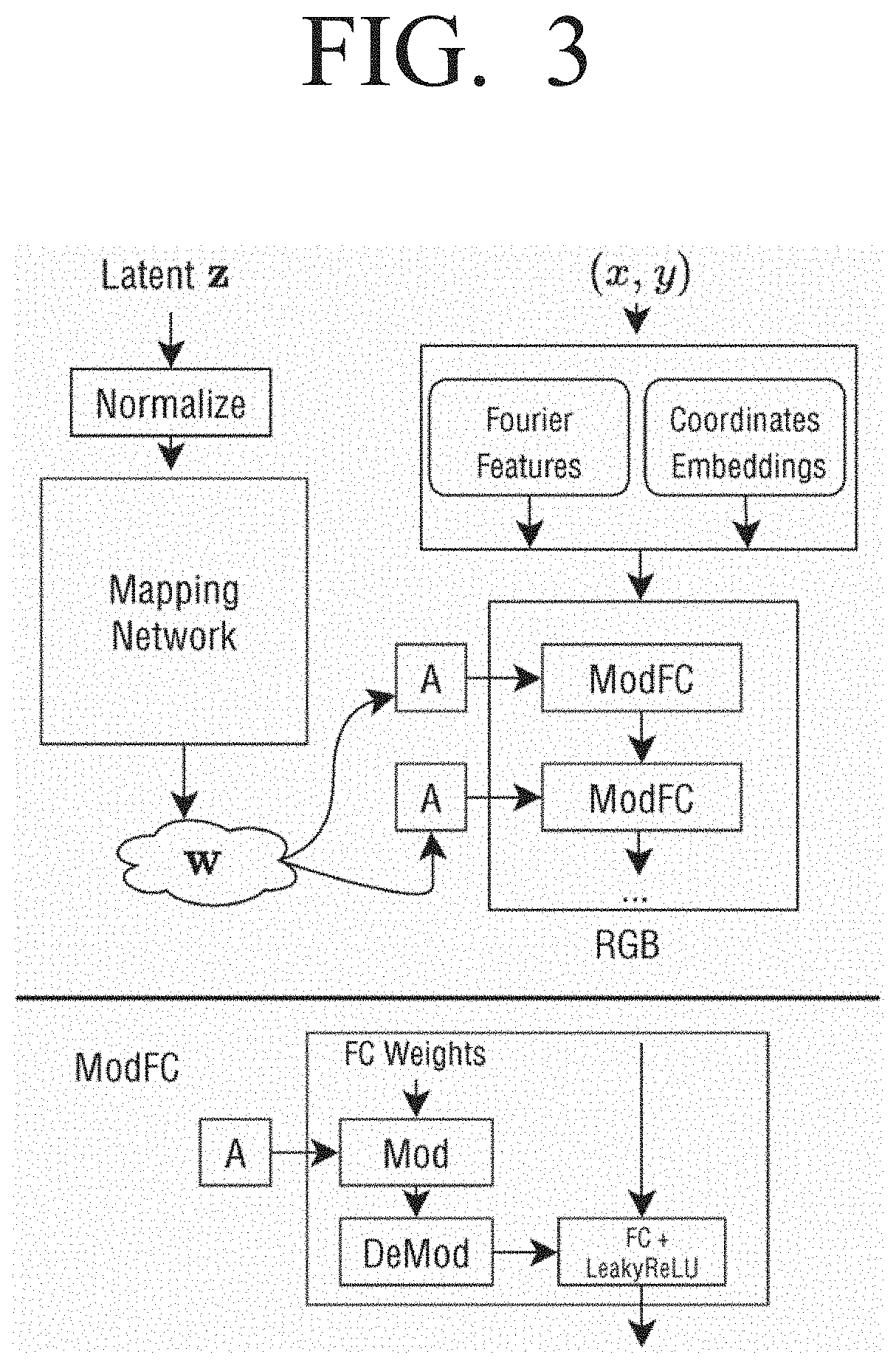
Image generators with conditionally-independent pixel synthesis
PatentActiveUS20220207646A1
Innovation
- The development of Conditionally-Independent Pixel Synthesis (CIPS) generators, which use coordinate encodings and sidewise multiplicative conditioning on random vectors to predict pixel colors independently, eliminating the need for spatial convolutions and self-attention, allowing for high-quality image generation without pixel interaction during inference.



Data Privacy Regulations Impact on Synthetic Data
The emergence of synthetic data generation technologies, particularly Multilayer Perceptrons and Generative Adversarial Networks, has coincided with an increasingly complex global regulatory landscape governing data privacy and protection. The General Data Protection Regulation (GDPR) in Europe, California Consumer Privacy Act (CCPA) in the United States, and similar frameworks worldwide have fundamentally altered how organizations approach data collection, processing, and sharing.
These regulations have created both challenges and opportunities for synthetic data applications. GDPR's strict consent requirements and data minimization principles have made traditional data sharing practices more restrictive, driving organizations to explore synthetic alternatives. The regulation's concept of "pseudonymization" provides some legal basis for synthetic data usage, though the interpretation remains evolving across different jurisdictions.
The "right to be forgotten" provisions in GDPR present particular complexities for synthetic data systems. When individuals request data deletion, organizations must determine whether synthetic datasets derived from their information require modification or removal. This challenge is more pronounced with GANs, where the training process may inadvertently memorize specific data points, compared to MLPs which typically learn more generalized patterns.
Cross-border data transfer restrictions have significantly boosted synthetic data adoption. Organizations facing limitations on international data sharing are increasingly turning to synthetic alternatives to maintain global operations while ensuring compliance. The European Commission's adequacy decisions and Standard Contractual Clauses framework have created additional incentives for synthetic data deployment.
Regulatory uncertainty remains a significant factor influencing technology adoption decisions. While synthetic data offers potential compliance benefits, the lack of explicit regulatory guidance creates hesitation among organizations. Different privacy authorities have varying interpretations of synthetic data's legal status, with some viewing it as anonymized data while others maintain it carries residual privacy risks.
The healthcare and financial services sectors face particularly stringent requirements under regulations like HIPAA and PCI DSS, making synthetic data an attractive solution for research and development activities. However, these industries also demand higher standards of evidence regarding privacy preservation, influencing the choice between MLP and GAN-based approaches based on their respective privacy guarantees and auditability requirements.
These regulations have created both challenges and opportunities for synthetic data applications. GDPR's strict consent requirements and data minimization principles have made traditional data sharing practices more restrictive, driving organizations to explore synthetic alternatives. The regulation's concept of "pseudonymization" provides some legal basis for synthetic data usage, though the interpretation remains evolving across different jurisdictions.
The "right to be forgotten" provisions in GDPR present particular complexities for synthetic data systems. When individuals request data deletion, organizations must determine whether synthetic datasets derived from their information require modification or removal. This challenge is more pronounced with GANs, where the training process may inadvertently memorize specific data points, compared to MLPs which typically learn more generalized patterns.
Cross-border data transfer restrictions have significantly boosted synthetic data adoption. Organizations facing limitations on international data sharing are increasingly turning to synthetic alternatives to maintain global operations while ensuring compliance. The European Commission's adequacy decisions and Standard Contractual Clauses framework have created additional incentives for synthetic data deployment.
Regulatory uncertainty remains a significant factor influencing technology adoption decisions. While synthetic data offers potential compliance benefits, the lack of explicit regulatory guidance creates hesitation among organizations. Different privacy authorities have varying interpretations of synthetic data's legal status, with some viewing it as anonymized data while others maintain it carries residual privacy risks.
The healthcare and financial services sectors face particularly stringent requirements under regulations like HIPAA and PCI DSS, making synthetic data an attractive solution for research and development activities. However, these industries also demand higher standards of evidence regarding privacy preservation, influencing the choice between MLP and GAN-based approaches based on their respective privacy guarantees and auditability requirements.
Ethical AI and Bias Considerations in Data Synthesis
The deployment of Multilayer Perceptrons and Generative Adversarial Networks for data synthesis raises critical ethical considerations that extend beyond technical performance metrics. As these technologies generate increasingly realistic synthetic data, the potential for misuse and unintended societal consequences grows exponentially. The fundamental ethical challenge lies in ensuring that synthetic data generation serves beneficial purposes while preventing malicious applications such as deepfakes, identity theft, or misinformation campaigns.
Bias propagation represents one of the most significant ethical concerns in data synthesis. Both MLPs and GANs learn from training datasets that often contain historical biases, societal prejudices, and underrepresentation of minority groups. When these models generate synthetic data, they frequently amplify existing biases rather than mitigating them. For instance, facial generation models trained on datasets with demographic imbalances may produce synthetic faces that perpetuate racial or gender stereotypes, leading to discriminatory outcomes in downstream applications.
The concept of fairness in synthetic data generation requires careful consideration of multiple dimensions. Demographic parity demands that synthetic datasets represent all population groups proportionally, while equalized odds focuses on ensuring consistent performance across different demographic categories. However, achieving these fairness criteria simultaneously often proves mathematically impossible, necessitating trade-offs based on specific application contexts and stakeholder priorities.
Privacy preservation emerges as another crucial ethical dimension, particularly when synthetic data aims to replace sensitive real-world datasets. While synthetic data theoretically protects individual privacy by generating artificial samples, recent research demonstrates that both MLPs and GANs can inadvertently memorize and reproduce training data patterns, potentially enabling privacy attacks. The challenge intensifies when balancing data utility with privacy protection, as overly anonymized synthetic data may lose its analytical value.
Transparency and explainability concerns are particularly acute for GANs due to their adversarial training process and complex latent space representations. The black-box nature of these models makes it difficult to understand why certain synthetic samples are generated, hindering bias detection and mitigation efforts. This opacity challenges regulatory compliance requirements and undermines trust in AI systems, especially in high-stakes applications such as healthcare or criminal justice.
Establishing robust governance frameworks for ethical data synthesis requires interdisciplinary collaboration between technologists, ethicists, policymakers, and affected communities. These frameworks must address consent mechanisms for training data usage, audit procedures for bias detection, and accountability structures for synthetic data misuse. Regular ethical impact assessments and continuous monitoring systems become essential components of responsible AI deployment in data synthesis applications.
Bias propagation represents one of the most significant ethical concerns in data synthesis. Both MLPs and GANs learn from training datasets that often contain historical biases, societal prejudices, and underrepresentation of minority groups. When these models generate synthetic data, they frequently amplify existing biases rather than mitigating them. For instance, facial generation models trained on datasets with demographic imbalances may produce synthetic faces that perpetuate racial or gender stereotypes, leading to discriminatory outcomes in downstream applications.
The concept of fairness in synthetic data generation requires careful consideration of multiple dimensions. Demographic parity demands that synthetic datasets represent all population groups proportionally, while equalized odds focuses on ensuring consistent performance across different demographic categories. However, achieving these fairness criteria simultaneously often proves mathematically impossible, necessitating trade-offs based on specific application contexts and stakeholder priorities.
Privacy preservation emerges as another crucial ethical dimension, particularly when synthetic data aims to replace sensitive real-world datasets. While synthetic data theoretically protects individual privacy by generating artificial samples, recent research demonstrates that both MLPs and GANs can inadvertently memorize and reproduce training data patterns, potentially enabling privacy attacks. The challenge intensifies when balancing data utility with privacy protection, as overly anonymized synthetic data may lose its analytical value.
Transparency and explainability concerns are particularly acute for GANs due to their adversarial training process and complex latent space representations. The black-box nature of these models makes it difficult to understand why certain synthetic samples are generated, hindering bias detection and mitigation efforts. This opacity challenges regulatory compliance requirements and undermines trust in AI systems, especially in high-stakes applications such as healthcare or criminal justice.
Establishing robust governance frameworks for ethical data synthesis requires interdisciplinary collaboration between technologists, ethicists, policymakers, and affected communities. These frameworks must address consent mechanisms for training data usage, audit procedures for bias detection, and accountability structures for synthetic data misuse. Regular ethical impact assessments and continuous monitoring systems become essential components of responsible AI deployment in data synthesis applications.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!