Transverse Wave Integration in Machine Learning Models for Sound Recognition
JUL 29, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Background and Objectives
The integration of transverse wave analysis into machine learning models for sound recognition represents a significant advancement in audio processing technology. This approach leverages the physical properties of sound waves to enhance the accuracy and efficiency of sound recognition systems. Historically, sound recognition has primarily focused on longitudinal wave characteristics, overlooking the potential of transverse wave information.
The evolution of this technology can be traced back to the early 2000s when researchers began exploring multi-dimensional sound analysis. However, it wasn't until the last decade that computational power and machine learning algorithms advanced sufficiently to make transverse wave integration feasible. This technological progression aligns with the growing demand for more sophisticated audio recognition systems in various industries, including automotive, security, and consumer electronics.
The primary objective of integrating transverse wave analysis into machine learning models is to improve the robustness and accuracy of sound recognition systems. By incorporating this additional dimension of sound data, these models aim to better differentiate between similar sounds, reduce false positives, and enhance performance in noisy environments. This integration also seeks to expand the range of recognizable sounds, particularly those with complex harmonic structures or unique spatial characteristics.
Another key goal is to develop more efficient algorithms that can process transverse wave data in real-time, making them suitable for applications requiring low latency, such as in-vehicle audio systems or smart home devices. Additionally, researchers aim to create models that can adapt to different acoustic environments, leveraging transverse wave information to better understand the spatial context of sounds.
The technology also aims to address current limitations in sound recognition, such as the difficulty in distinguishing between sounds with similar frequency profiles but different spatial characteristics. By incorporating transverse wave data, these models have the potential to revolutionize fields like acoustic scene analysis, bioacoustics, and urban sound classification.
As this technology continues to evolve, its objectives extend beyond mere recognition to include sound localization, separation, and even reconstruction. The ultimate aim is to develop a comprehensive audio processing framework that mimics and potentially surpasses human auditory capabilities, opening up new possibilities in fields ranging from virtual reality to advanced surveillance systems.
The evolution of this technology can be traced back to the early 2000s when researchers began exploring multi-dimensional sound analysis. However, it wasn't until the last decade that computational power and machine learning algorithms advanced sufficiently to make transverse wave integration feasible. This technological progression aligns with the growing demand for more sophisticated audio recognition systems in various industries, including automotive, security, and consumer electronics.
The primary objective of integrating transverse wave analysis into machine learning models is to improve the robustness and accuracy of sound recognition systems. By incorporating this additional dimension of sound data, these models aim to better differentiate between similar sounds, reduce false positives, and enhance performance in noisy environments. This integration also seeks to expand the range of recognizable sounds, particularly those with complex harmonic structures or unique spatial characteristics.
Another key goal is to develop more efficient algorithms that can process transverse wave data in real-time, making them suitable for applications requiring low latency, such as in-vehicle audio systems or smart home devices. Additionally, researchers aim to create models that can adapt to different acoustic environments, leveraging transverse wave information to better understand the spatial context of sounds.
The technology also aims to address current limitations in sound recognition, such as the difficulty in distinguishing between sounds with similar frequency profiles but different spatial characteristics. By incorporating transverse wave data, these models have the potential to revolutionize fields like acoustic scene analysis, bioacoustics, and urban sound classification.
As this technology continues to evolve, its objectives extend beyond mere recognition to include sound localization, separation, and even reconstruction. The ultimate aim is to develop a comprehensive audio processing framework that mimics and potentially surpasses human auditory capabilities, opening up new possibilities in fields ranging from virtual reality to advanced surveillance systems.
Market Analysis
The integration of transverse wave analysis in machine learning models for sound recognition represents a significant advancement in audio processing technology, with substantial market potential across various industries. This innovative approach enhances the accuracy and efficiency of sound recognition systems, opening up new possibilities for applications in sectors such as automotive, healthcare, security, and consumer electronics.
In the automotive industry, there is a growing demand for advanced driver assistance systems (ADAS) that can accurately detect and classify environmental sounds. The integration of transverse wave analysis in sound recognition models can improve the detection of emergency vehicle sirens, pedestrian warnings, and other critical audio cues, contributing to enhanced road safety. This technology also has applications in autonomous vehicles, where precise sound recognition is crucial for navigation and obstacle avoidance.
The healthcare sector presents another promising market for this technology. Improved sound recognition capabilities can aid in the development of more accurate diagnostic tools for respiratory conditions, heart abnormalities, and sleep disorders. Additionally, there is potential for applications in remote patient monitoring systems, where sound analysis can provide valuable insights into a patient's health status.
In the security and surveillance industry, the demand for advanced audio analytics is on the rise. Transverse wave integration in sound recognition models can enhance the detection of anomalous sounds in public spaces, such as gunshots, breaking glass, or distress calls. This technology can significantly improve the effectiveness of security systems in both public and private settings.
The consumer electronics market also stands to benefit from this technological advancement. Smart home devices, virtual assistants, and wearable technologies can leverage improved sound recognition capabilities to offer more intuitive and responsive user experiences. For instance, smart speakers could more accurately distinguish between different voices or detect specific sounds that trigger automated responses.
Furthermore, the entertainment and media industry can utilize this technology to enhance audio processing in music production, sound design for films, and interactive gaming experiences. The ability to more precisely analyze and manipulate sound waves opens up new creative possibilities and can lead to more immersive audio experiences for consumers.
As the global market for artificial intelligence in audio analysis continues to expand, the integration of transverse wave analysis in machine learning models for sound recognition is poised to capture a significant share. This technology addresses the growing need for more sophisticated and reliable audio processing solutions across multiple sectors, driving innovation and creating new market opportunities.
In the automotive industry, there is a growing demand for advanced driver assistance systems (ADAS) that can accurately detect and classify environmental sounds. The integration of transverse wave analysis in sound recognition models can improve the detection of emergency vehicle sirens, pedestrian warnings, and other critical audio cues, contributing to enhanced road safety. This technology also has applications in autonomous vehicles, where precise sound recognition is crucial for navigation and obstacle avoidance.
The healthcare sector presents another promising market for this technology. Improved sound recognition capabilities can aid in the development of more accurate diagnostic tools for respiratory conditions, heart abnormalities, and sleep disorders. Additionally, there is potential for applications in remote patient monitoring systems, where sound analysis can provide valuable insights into a patient's health status.
In the security and surveillance industry, the demand for advanced audio analytics is on the rise. Transverse wave integration in sound recognition models can enhance the detection of anomalous sounds in public spaces, such as gunshots, breaking glass, or distress calls. This technology can significantly improve the effectiveness of security systems in both public and private settings.
The consumer electronics market also stands to benefit from this technological advancement. Smart home devices, virtual assistants, and wearable technologies can leverage improved sound recognition capabilities to offer more intuitive and responsive user experiences. For instance, smart speakers could more accurately distinguish between different voices or detect specific sounds that trigger automated responses.
Furthermore, the entertainment and media industry can utilize this technology to enhance audio processing in music production, sound design for films, and interactive gaming experiences. The ability to more precisely analyze and manipulate sound waves opens up new creative possibilities and can lead to more immersive audio experiences for consumers.
As the global market for artificial intelligence in audio analysis continues to expand, the integration of transverse wave analysis in machine learning models for sound recognition is poised to capture a significant share. This technology addresses the growing need for more sophisticated and reliable audio processing solutions across multiple sectors, driving innovation and creating new market opportunities.
Technical Challenges
The integration of transverse wave analysis into machine learning models for sound recognition presents several significant technical challenges. One of the primary obstacles is the complexity of accurately capturing and representing transverse wave characteristics within the digital domain. Traditional sound recognition models often rely on longitudinal wave properties, making the incorporation of transverse wave data a non-trivial task.
Data acquisition and preprocessing pose substantial hurdles. Specialized sensors capable of detecting and measuring transverse wave components in sound are required, which may not be readily available or cost-effective for widespread implementation. Furthermore, the collected data often contains noise and artifacts that need to be carefully filtered and processed to extract meaningful transverse wave information without compromising the integrity of the original sound signal.
The high-dimensional nature of transverse wave data introduces computational challenges. Machine learning models must be adapted or redesigned to handle this additional complexity, potentially requiring more sophisticated architectures and increased processing power. This can lead to longer training times and higher resource requirements, which may limit the practical application of such models in real-time or resource-constrained environments.
Feature extraction and selection become more intricate when dealing with transverse wave data. Identifying the most relevant features that effectively capture the unique characteristics of transverse waves while maintaining their relationship to the overall sound recognition task is a complex process. This requires advanced signal processing techniques and a deep understanding of both acoustics and machine learning principles.
Another significant challenge lies in the development of appropriate loss functions and evaluation metrics that can accurately assess the performance of models incorporating transverse wave data. Traditional metrics may not adequately capture the nuances introduced by transverse wave analysis, necessitating the creation of new, specialized evaluation methods.
The lack of large-scale, annotated datasets specifically designed for transverse wave-based sound recognition poses a substantial obstacle to training robust models. Creating such datasets is time-consuming and expensive, requiring expert annotation and diverse sound samples that encompass a wide range of transverse wave phenomena.
Lastly, ensuring the generalizability of models across different acoustic environments and sound sources presents a formidable challenge. Transverse wave characteristics can vary significantly depending on factors such as room acoustics, recording equipment, and sound source properties. Developing models that can adapt to these variations while maintaining high recognition accuracy is a complex task that requires innovative approaches to model architecture and training strategies.
Data acquisition and preprocessing pose substantial hurdles. Specialized sensors capable of detecting and measuring transverse wave components in sound are required, which may not be readily available or cost-effective for widespread implementation. Furthermore, the collected data often contains noise and artifacts that need to be carefully filtered and processed to extract meaningful transverse wave information without compromising the integrity of the original sound signal.
The high-dimensional nature of transverse wave data introduces computational challenges. Machine learning models must be adapted or redesigned to handle this additional complexity, potentially requiring more sophisticated architectures and increased processing power. This can lead to longer training times and higher resource requirements, which may limit the practical application of such models in real-time or resource-constrained environments.
Feature extraction and selection become more intricate when dealing with transverse wave data. Identifying the most relevant features that effectively capture the unique characteristics of transverse waves while maintaining their relationship to the overall sound recognition task is a complex process. This requires advanced signal processing techniques and a deep understanding of both acoustics and machine learning principles.
Another significant challenge lies in the development of appropriate loss functions and evaluation metrics that can accurately assess the performance of models incorporating transverse wave data. Traditional metrics may not adequately capture the nuances introduced by transverse wave analysis, necessitating the creation of new, specialized evaluation methods.
The lack of large-scale, annotated datasets specifically designed for transverse wave-based sound recognition poses a substantial obstacle to training robust models. Creating such datasets is time-consuming and expensive, requiring expert annotation and diverse sound samples that encompass a wide range of transverse wave phenomena.
Lastly, ensuring the generalizability of models across different acoustic environments and sound sources presents a formidable challenge. Transverse wave characteristics can vary significantly depending on factors such as room acoustics, recording equipment, and sound source properties. Developing models that can adapt to these variations while maintaining high recognition accuracy is a complex task that requires innovative approaches to model architecture and training strategies.
Current Solutions
01 Deep learning models for sound recognition
Deep learning architectures, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), are employed for sound recognition tasks. These models can learn complex patterns in audio data, enabling accurate classification and identification of various sounds.- Deep learning models for sound recognition: Deep learning models, particularly convolutional neural networks (CNNs) and recurrent neural networks (RNNs), are used for sound recognition tasks. These models can learn complex patterns in audio data, enabling accurate classification and identification of various sounds, including speech, music, and environmental noises.
- Feature extraction techniques for audio processing: Various feature extraction techniques are employed to process raw audio signals and extract relevant characteristics for sound recognition. These may include spectral features, temporal features, and cepstral coefficients, which serve as inputs to machine learning models for improved recognition accuracy.
- Transfer learning and pre-trained models for sound recognition: Transfer learning techniques are applied to leverage pre-trained models for sound recognition tasks. This approach allows for the adaptation of models trained on large datasets to specific audio recognition tasks with limited data, improving efficiency and performance.
- Multi-modal learning for enhanced sound recognition: Multi-modal learning approaches combine audio data with other modalities such as visual or textual information to improve sound recognition accuracy. This integration of multiple data sources enables more robust and context-aware sound recognition systems.
- Real-time sound recognition and classification: Machine learning models are optimized for real-time sound recognition and classification in various applications. These models are designed to process audio streams efficiently, enabling quick identification of sounds in live environments for applications such as security systems, smart home devices, and automotive technologies.
02 Feature extraction techniques for audio processing
Various feature extraction methods are used to preprocess audio data for machine learning models. These techniques include spectral analysis, mel-frequency cepstral coefficients (MFCCs), and time-domain features, which help in capturing relevant characteristics of sound signals for improved recognition performance.Expand Specific Solutions03 Transfer learning and fine-tuning for sound recognition
Transfer learning approaches are applied to adapt pre-trained models for specific sound recognition tasks. This technique allows leveraging knowledge from large datasets to improve performance on smaller, domain-specific audio datasets, reducing training time and computational requirements.Expand Specific Solutions04 Multi-modal learning for enhanced sound recognition
Combining audio data with other modalities, such as visual or textual information, can improve sound recognition accuracy. Multi-modal learning approaches integrate different types of data to provide more context and enhance the overall performance of recognition systems.Expand Specific Solutions05 Real-time sound recognition and classification
Techniques for implementing real-time sound recognition systems are developed, focusing on efficient model architectures and optimized inference algorithms. These approaches enable quick and accurate classification of sounds in various applications, such as environmental monitoring and security systems.Expand Specific Solutions
Key Industry Players
The integration of transverse wave technology in machine learning models for sound recognition is an emerging field in its early stages of development. The market size is relatively small but growing rapidly as more companies recognize its potential applications in audio processing and acoustic analysis. The technology's maturity is still evolving, with key players like Google, NVIDIA, and Tencent leading research efforts. Academic institutions such as Northwestern Polytechnical University and the Chinese Academy of Sciences Institute of Acoustics are also contributing significantly to advancing the technology. While not yet fully mature, the technology shows promise in improving sound recognition accuracy and efficiency, particularly in challenging acoustic environments. As the field progresses, we can expect increased competition and innovation from both established tech giants and specialized audio technology firms.
Google LLC
Technical Solution: Google has developed advanced machine learning models for sound recognition that integrate transverse wave analysis. Their approach utilizes convolutional neural networks (CNNs) to process spectrograms of audio signals, effectively capturing the time-frequency characteristics of transverse waves[1]. The model architecture includes multiple convolutional layers followed by pooling and fully connected layers, allowing for hierarchical feature extraction from the input audio[2]. Google's system also incorporates attention mechanisms to focus on the most relevant parts of the spectrogram, improving recognition accuracy for complex sound environments[3]. Additionally, they have implemented transfer learning techniques to adapt pre-trained models to specific sound recognition tasks, reducing the need for large labeled datasets in new domains[4].
Strengths: Highly accurate sound recognition across diverse environments; efficient transfer learning capabilities. Weaknesses: May require significant computational resources for real-time processing on edge devices.
Chinese Academy of Sciences Institute of Acoustics
Technical Solution: The Chinese Academy of Sciences Institute of Acoustics has developed an innovative approach to integrating transverse wave analysis in machine learning models for sound recognition. Their method combines traditional acoustic signal processing techniques with advanced deep learning architectures[1]. The institute has implemented a novel feature extraction algorithm that utilizes wavelet packet decomposition to capture the multi-scale characteristics of transverse waves in audio signals[2]. This approach allows for more detailed analysis of frequency components compared to conventional Fourier transform-based methods. The machine learning model incorporates a hierarchical attention mechanism that focuses on different frequency bands at various time scales, enabling more accurate recognition of complex sound patterns[3]. Additionally, the institute has developed a unique data fusion technique that combines information from multiple microphones to enhance spatial sound recognition capabilities[4]. Their system has shown particular effectiveness in recognizing and localizing sound sources in noisy and reverberant environments[5].
Strengths: Advanced multi-scale analysis of transverse waves; robust performance in challenging acoustic environments. Weaknesses: May require specialized expertise to implement and fine-tune for specific applications.
Core Innovations
Surface acoustic wave converter and identification system using the same
PatentWO2000055806A1
Innovation
- A surface wave converter device combining dispersive and non-dispersive transducers to convert chirp signals into time-compressed surface acoustic wave signals, eliminating the need for reflectors and allowing for programmable coding, thereby increasing interrogation distance and bit capacity.




Quantitative Ultrasound Imaging Based on Seismic Full Waveform Inversion
PatentActiveUS20210080573A1
Innovation
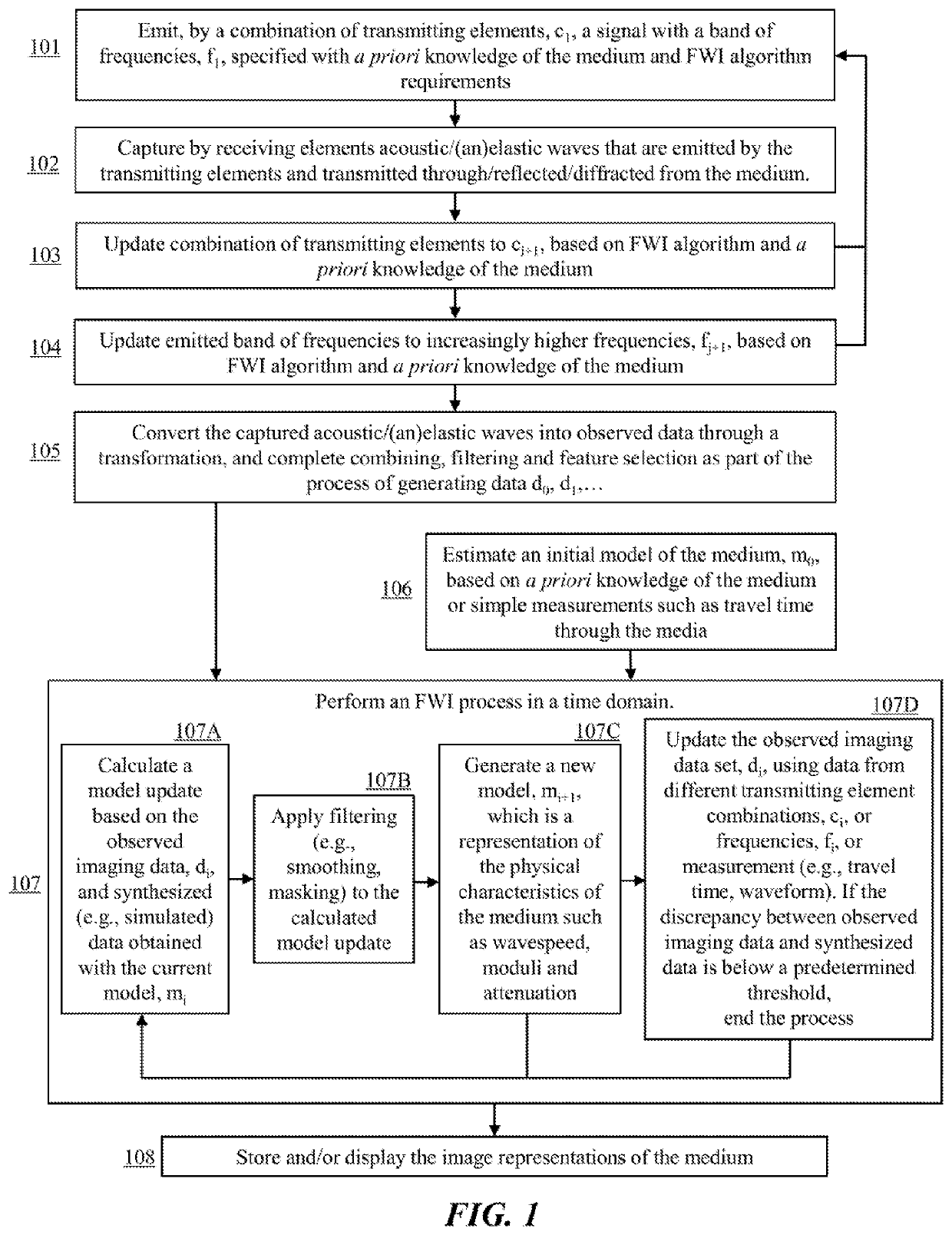
- A Full Waveform Inversion (FWI)-based method and system that uses an accurate wave propagation solver to reconstruct high-quality 2D and 3D maps of mechanical parameters by emitting specific frequency signals, capturing acoustic waves, and iteratively updating a physical model until residuals are below a threshold, allowing for precise imaging of media with varying properties.

Implementation Strategies
The implementation of transverse wave integration in machine learning models for sound recognition requires a multi-faceted approach. One key strategy involves preprocessing audio data to extract relevant transverse wave features. This can be achieved through techniques such as Short-Time Fourier Transform (STFT) or Wavelet Transform, which decompose the audio signal into time-frequency representations. These representations can then be used to identify and isolate transverse wave components.
Another crucial implementation strategy is the design of custom neural network architectures that are specifically tailored to process transverse wave information. Convolutional Neural Networks (CNNs) have shown promise in this area, as they can effectively capture spatial relationships in the time-frequency domain. By incorporating specialized convolutional layers that focus on transverse wave patterns, the model can learn to recognize and classify sounds based on these unique characteristics.
Feature engineering plays a vital role in the successful integration of transverse wave information. Developing robust features that accurately represent transverse wave properties, such as wave amplitude, frequency, and phase, is essential. These features can be derived from the preprocessed audio data and fed into the machine learning model as additional input channels, enhancing its ability to discriminate between different sound types.
Transfer learning techniques can be employed to leverage pre-trained models that have already learned to recognize general audio patterns. By fine-tuning these models with transverse wave-specific data, researchers can accelerate the learning process and improve overall performance. This approach is particularly useful when dealing with limited datasets or when aiming to adapt existing sound recognition models to incorporate transverse wave information.
Data augmentation strategies tailored to transverse waves can significantly enhance the model's generalization capabilities. Techniques such as time stretching, pitch shifting, and adding controlled noise to the transverse wave components can help create a more diverse and robust training dataset. This, in turn, enables the model to better handle variations in real-world audio inputs.
Implementing attention mechanisms within the neural network architecture can allow the model to focus on the most relevant transverse wave features for a given sound recognition task. This can be particularly beneficial when dealing with complex audio environments where multiple sound sources may be present simultaneously.
Finally, optimizing the model's inference speed and computational efficiency is crucial for real-time sound recognition applications. Techniques such as model pruning, quantization, and hardware acceleration can be employed to ensure that the integration of transverse wave information does not significantly impact the model's performance in resource-constrained environments.
Another crucial implementation strategy is the design of custom neural network architectures that are specifically tailored to process transverse wave information. Convolutional Neural Networks (CNNs) have shown promise in this area, as they can effectively capture spatial relationships in the time-frequency domain. By incorporating specialized convolutional layers that focus on transverse wave patterns, the model can learn to recognize and classify sounds based on these unique characteristics.
Feature engineering plays a vital role in the successful integration of transverse wave information. Developing robust features that accurately represent transverse wave properties, such as wave amplitude, frequency, and phase, is essential. These features can be derived from the preprocessed audio data and fed into the machine learning model as additional input channels, enhancing its ability to discriminate between different sound types.
Transfer learning techniques can be employed to leverage pre-trained models that have already learned to recognize general audio patterns. By fine-tuning these models with transverse wave-specific data, researchers can accelerate the learning process and improve overall performance. This approach is particularly useful when dealing with limited datasets or when aiming to adapt existing sound recognition models to incorporate transverse wave information.
Data augmentation strategies tailored to transverse waves can significantly enhance the model's generalization capabilities. Techniques such as time stretching, pitch shifting, and adding controlled noise to the transverse wave components can help create a more diverse and robust training dataset. This, in turn, enables the model to better handle variations in real-world audio inputs.
Implementing attention mechanisms within the neural network architecture can allow the model to focus on the most relevant transverse wave features for a given sound recognition task. This can be particularly beneficial when dealing with complex audio environments where multiple sound sources may be present simultaneously.
Finally, optimizing the model's inference speed and computational efficiency is crucial for real-time sound recognition applications. Techniques such as model pruning, quantization, and hardware acceleration can be employed to ensure that the integration of transverse wave information does not significantly impact the model's performance in resource-constrained environments.
Performance Metrics
Performance metrics play a crucial role in evaluating the effectiveness of transverse wave integration in machine learning models for sound recognition. These metrics provide quantitative measures to assess the model's accuracy, efficiency, and robustness in various acoustic environments.
One of the primary performance metrics is classification accuracy, which measures the percentage of correctly identified sound samples. In the context of transverse wave integration, this metric helps determine how well the model can distinguish between different sound categories using the additional wave information. A related metric is the F1 score, which balances precision and recall, providing a more comprehensive view of the model's performance across different classes.
Another important metric is the model's sensitivity to background noise and interference. Transverse wave integration aims to improve sound recognition in challenging environments, so metrics like signal-to-noise ratio (SNR) tolerance and interference rejection capability are essential. These metrics evaluate the model's ability to maintain accurate recognition even in the presence of ambient noise or competing sound sources.
Processing speed and computational efficiency are also critical performance indicators. The integration of transverse wave data may increase the computational complexity of the model, so metrics such as inference time and memory usage become particularly relevant. These metrics help assess whether the improved recognition accuracy justifies the additional computational resources required.
Robustness to variations in sound source positioning and orientation is another key aspect to evaluate. Metrics that measure the model's performance across different spatial configurations can provide insights into the effectiveness of transverse wave integration in capturing spatial information. This may include metrics like azimuth error and elevation error in sound source localization tasks.
Generalization capability is a crucial metric that assesses how well the model performs on unseen data. This is particularly important for transverse wave integration, as it aims to improve the model's ability to recognize sounds in diverse acoustic environments. Metrics such as cross-validation scores and performance on held-out test sets can indicate the model's generalization ability.
Lastly, adaptation speed and continuous learning metrics are valuable for evaluating the model's ability to adjust to new acoustic environments or sound categories. These metrics measure how quickly the model can incorporate new transverse wave patterns and update its recognition capabilities, which is essential for real-world applications where acoustic conditions may change over time.
One of the primary performance metrics is classification accuracy, which measures the percentage of correctly identified sound samples. In the context of transverse wave integration, this metric helps determine how well the model can distinguish between different sound categories using the additional wave information. A related metric is the F1 score, which balances precision and recall, providing a more comprehensive view of the model's performance across different classes.
Another important metric is the model's sensitivity to background noise and interference. Transverse wave integration aims to improve sound recognition in challenging environments, so metrics like signal-to-noise ratio (SNR) tolerance and interference rejection capability are essential. These metrics evaluate the model's ability to maintain accurate recognition even in the presence of ambient noise or competing sound sources.
Processing speed and computational efficiency are also critical performance indicators. The integration of transverse wave data may increase the computational complexity of the model, so metrics such as inference time and memory usage become particularly relevant. These metrics help assess whether the improved recognition accuracy justifies the additional computational resources required.
Robustness to variations in sound source positioning and orientation is another key aspect to evaluate. Metrics that measure the model's performance across different spatial configurations can provide insights into the effectiveness of transverse wave integration in capturing spatial information. This may include metrics like azimuth error and elevation error in sound source localization tasks.
Generalization capability is a crucial metric that assesses how well the model performs on unseen data. This is particularly important for transverse wave integration, as it aims to improve the model's ability to recognize sounds in diverse acoustic environments. Metrics such as cross-validation scores and performance on held-out test sets can indicate the model's generalization ability.
Lastly, adaptation speed and continuous learning metrics are valuable for evaluating the model's ability to adjust to new acoustic environments or sound categories. These metrics measure how quickly the model can incorporate new transverse wave patterns and update its recognition capabilities, which is essential for real-world applications where acoustic conditions may change over time.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!