

Cognitive Computing in Machine Vision: Integration Strategies
APR 3, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Cognitive Computing Vision Background and Objectives
Cognitive computing in machine vision represents a paradigm shift from traditional computer vision systems toward intelligent, adaptive visual processing capabilities that mimic human cognitive functions. This technological convergence emerged from the limitations of conventional rule-based vision systems, which struggled with complex real-world scenarios requiring contextual understanding, learning, and reasoning capabilities.
The evolution of machine vision has progressed through distinct phases, beginning with basic pattern recognition in the 1960s, advancing through statistical learning methods in the 1990s, and culminating in deep learning breakthroughs of the 2010s. However, current deep learning approaches, while powerful, still lack the cognitive flexibility and contextual reasoning that characterize human visual intelligence. This gap has driven the development of cognitive computing frameworks that integrate multiple AI disciplines including neural networks, symbolic reasoning, natural language processing, and knowledge representation.
The fundamental objective of cognitive computing integration in machine vision is to create systems capable of understanding, learning, and reasoning about visual information in ways that approach human-level performance. These systems must demonstrate several key capabilities: adaptive learning from limited examples, contextual interpretation of visual scenes, multi-modal information fusion, and explainable decision-making processes.
Primary technical goals include developing architectures that can seamlessly combine bottom-up feature extraction with top-down cognitive reasoning, enabling machines to not only detect objects but understand their relationships, purposes, and implications within broader contexts. This requires integration of perception with memory systems, attention mechanisms, and causal reasoning capabilities.
The strategic importance of this integration extends across numerous application domains, from autonomous vehicles requiring sophisticated scene understanding to medical imaging systems that must provide interpretable diagnostic insights. Industrial applications demand vision systems that can adapt to new products and environments without extensive retraining, while consumer applications require intuitive human-machine interfaces based on natural visual communication.
Current integration challenges center on bridging the gap between connectionist and symbolic AI approaches, managing computational complexity while maintaining real-time performance, and ensuring system reliability and interpretability. The ultimate objective is achieving artificial visual intelligence that combines the pattern recognition strengths of deep learning with the reasoning capabilities of symbolic AI systems.
The evolution of machine vision has progressed through distinct phases, beginning with basic pattern recognition in the 1960s, advancing through statistical learning methods in the 1990s, and culminating in deep learning breakthroughs of the 2010s. However, current deep learning approaches, while powerful, still lack the cognitive flexibility and contextual reasoning that characterize human visual intelligence. This gap has driven the development of cognitive computing frameworks that integrate multiple AI disciplines including neural networks, symbolic reasoning, natural language processing, and knowledge representation.
The fundamental objective of cognitive computing integration in machine vision is to create systems capable of understanding, learning, and reasoning about visual information in ways that approach human-level performance. These systems must demonstrate several key capabilities: adaptive learning from limited examples, contextual interpretation of visual scenes, multi-modal information fusion, and explainable decision-making processes.
Primary technical goals include developing architectures that can seamlessly combine bottom-up feature extraction with top-down cognitive reasoning, enabling machines to not only detect objects but understand their relationships, purposes, and implications within broader contexts. This requires integration of perception with memory systems, attention mechanisms, and causal reasoning capabilities.
The strategic importance of this integration extends across numerous application domains, from autonomous vehicles requiring sophisticated scene understanding to medical imaging systems that must provide interpretable diagnostic insights. Industrial applications demand vision systems that can adapt to new products and environments without extensive retraining, while consumer applications require intuitive human-machine interfaces based on natural visual communication.
Current integration challenges center on bridging the gap between connectionist and symbolic AI approaches, managing computational complexity while maintaining real-time performance, and ensuring system reliability and interpretability. The ultimate objective is achieving artificial visual intelligence that combines the pattern recognition strengths of deep learning with the reasoning capabilities of symbolic AI systems.
Market Demand for Intelligent Vision Systems
The global market for intelligent vision systems is experiencing unprecedented growth driven by the convergence of cognitive computing capabilities with traditional machine vision technologies. This transformation is fundamentally reshaping how industries approach visual data processing, moving beyond simple pattern recognition to sophisticated cognitive interpretation of visual information.
Manufacturing sectors represent the largest demand segment for intelligent vision systems, where cognitive computing integration enables predictive quality control, automated defect classification, and real-time production optimization. The automotive industry particularly drives significant demand through applications in autonomous vehicle development, advanced driver assistance systems, and intelligent manufacturing processes. These applications require vision systems capable of contextual understanding rather than mere object detection.
Healthcare markets demonstrate rapidly expanding adoption of cognitive vision technologies, particularly in medical imaging, diagnostic assistance, and surgical robotics. The integration of cognitive computing allows these systems to learn from vast datasets of medical images, improving diagnostic accuracy and enabling personalized treatment recommendations. Telemedicine expansion further accelerates demand for intelligent vision systems capable of remote patient monitoring and automated health assessment.
Retail and consumer electronics sectors increasingly demand intelligent vision solutions for customer behavior analysis, inventory management, and augmented reality experiences. Smart city initiatives worldwide create substantial market opportunities for cognitive vision systems in traffic management, security surveillance, and urban planning applications. These deployments require systems capable of processing complex visual scenarios and making autonomous decisions based on contextual understanding.
The security and surveillance market segment shows strong growth momentum, driven by requirements for intelligent threat detection, behavioral analysis, and automated incident response. Traditional surveillance systems are being replaced by cognitive-enabled platforms that can distinguish between normal and suspicious activities, reducing false alarms while improving security effectiveness.
Agricultural technology adoption of intelligent vision systems addresses precision farming needs, crop monitoring, and automated harvesting applications. These systems leverage cognitive computing to interpret complex environmental conditions, plant health indicators, and optimal harvesting timing, supporting sustainable agricultural practices and improved yield optimization.
Market demand is further amplified by the increasing availability of edge computing platforms capable of supporting cognitive vision processing locally, reducing latency and improving system responsiveness. This technological advancement enables deployment in previously inaccessible applications where real-time processing is critical.
Manufacturing sectors represent the largest demand segment for intelligent vision systems, where cognitive computing integration enables predictive quality control, automated defect classification, and real-time production optimization. The automotive industry particularly drives significant demand through applications in autonomous vehicle development, advanced driver assistance systems, and intelligent manufacturing processes. These applications require vision systems capable of contextual understanding rather than mere object detection.
Healthcare markets demonstrate rapidly expanding adoption of cognitive vision technologies, particularly in medical imaging, diagnostic assistance, and surgical robotics. The integration of cognitive computing allows these systems to learn from vast datasets of medical images, improving diagnostic accuracy and enabling personalized treatment recommendations. Telemedicine expansion further accelerates demand for intelligent vision systems capable of remote patient monitoring and automated health assessment.
Retail and consumer electronics sectors increasingly demand intelligent vision solutions for customer behavior analysis, inventory management, and augmented reality experiences. Smart city initiatives worldwide create substantial market opportunities for cognitive vision systems in traffic management, security surveillance, and urban planning applications. These deployments require systems capable of processing complex visual scenarios and making autonomous decisions based on contextual understanding.
The security and surveillance market segment shows strong growth momentum, driven by requirements for intelligent threat detection, behavioral analysis, and automated incident response. Traditional surveillance systems are being replaced by cognitive-enabled platforms that can distinguish between normal and suspicious activities, reducing false alarms while improving security effectiveness.
Agricultural technology adoption of intelligent vision systems addresses precision farming needs, crop monitoring, and automated harvesting applications. These systems leverage cognitive computing to interpret complex environmental conditions, plant health indicators, and optimal harvesting timing, supporting sustainable agricultural practices and improved yield optimization.
Market demand is further amplified by the increasing availability of edge computing platforms capable of supporting cognitive vision processing locally, reducing latency and improving system responsiveness. This technological advancement enables deployment in previously inaccessible applications where real-time processing is critical.
Current State of Cognitive Vision Integration Challenges
The integration of cognitive computing capabilities into machine vision systems represents a paradigm shift from traditional rule-based image processing to intelligent, adaptive visual perception. Current implementations demonstrate varying degrees of success across different application domains, with notable achievements in autonomous vehicles, medical imaging, and industrial quality control. However, the field faces significant architectural challenges in creating seamless interfaces between symbolic reasoning engines and neural network-based vision modules.
Contemporary cognitive vision systems predominantly rely on hybrid architectures that combine convolutional neural networks for feature extraction with knowledge graphs for contextual reasoning. Major technology providers including NVIDIA, Intel, and IBM have developed specialized hardware platforms optimized for these workloads, yet standardization remains fragmented. The lack of unified frameworks creates interoperability issues between different vendor solutions, limiting scalability and increasing implementation complexity.
Performance bottlenecks emerge primarily at the data fusion layer, where real-time visual inputs must be reconciled with existing knowledge bases. Current systems struggle with latency requirements, particularly in applications demanding sub-millisecond response times. Memory bandwidth limitations further constrain the simultaneous processing of high-resolution imagery and complex reasoning operations, forcing developers to make trade-offs between accuracy and speed.
Integration challenges are compounded by the heterogeneous nature of cognitive computing frameworks. TensorFlow, PyTorch, and proprietary solutions each offer distinct advantages but require specialized expertise for effective implementation. The absence of standardized APIs creates vendor lock-in scenarios and increases development costs. Additionally, the computational overhead of maintaining coherent world models while processing continuous visual streams presents ongoing scalability concerns.
Data quality and annotation requirements pose another significant barrier to widespread adoption. Cognitive vision systems demand extensive training datasets that capture not only visual patterns but also semantic relationships and contextual dependencies. The cost and complexity of generating such comprehensive datasets often exceed the capabilities of smaller organizations, creating market concentration among well-resourced technology leaders.
Security and reliability concerns further complicate integration efforts, particularly in safety-critical applications. The black-box nature of deep learning components makes it difficult to ensure predictable behavior under edge cases, while the complexity of cognitive reasoning modules introduces additional failure modes that are challenging to anticipate and mitigate through traditional testing methodologies.
Contemporary cognitive vision systems predominantly rely on hybrid architectures that combine convolutional neural networks for feature extraction with knowledge graphs for contextual reasoning. Major technology providers including NVIDIA, Intel, and IBM have developed specialized hardware platforms optimized for these workloads, yet standardization remains fragmented. The lack of unified frameworks creates interoperability issues between different vendor solutions, limiting scalability and increasing implementation complexity.
Performance bottlenecks emerge primarily at the data fusion layer, where real-time visual inputs must be reconciled with existing knowledge bases. Current systems struggle with latency requirements, particularly in applications demanding sub-millisecond response times. Memory bandwidth limitations further constrain the simultaneous processing of high-resolution imagery and complex reasoning operations, forcing developers to make trade-offs between accuracy and speed.
Integration challenges are compounded by the heterogeneous nature of cognitive computing frameworks. TensorFlow, PyTorch, and proprietary solutions each offer distinct advantages but require specialized expertise for effective implementation. The absence of standardized APIs creates vendor lock-in scenarios and increases development costs. Additionally, the computational overhead of maintaining coherent world models while processing continuous visual streams presents ongoing scalability concerns.
Data quality and annotation requirements pose another significant barrier to widespread adoption. Cognitive vision systems demand extensive training datasets that capture not only visual patterns but also semantic relationships and contextual dependencies. The cost and complexity of generating such comprehensive datasets often exceed the capabilities of smaller organizations, creating market concentration among well-resourced technology leaders.
Security and reliability concerns further complicate integration efforts, particularly in safety-critical applications. The black-box nature of deep learning components makes it difficult to ensure predictable behavior under edge cases, while the complexity of cognitive reasoning modules introduces additional failure modes that are challenging to anticipate and mitigate through traditional testing methodologies.
Existing Cognitive-Vision Integration Solutions
01 Deep learning and neural network architectures for image recognition
Cognitive computing systems utilize deep learning algorithms and neural network architectures to process and analyze visual data. These systems employ convolutional neural networks, recurrent neural networks, and other advanced architectures to extract features, recognize patterns, and classify objects in images. The neural networks are trained on large datasets to improve accuracy in object detection, image segmentation, and scene understanding tasks.- Deep learning and neural network architectures for image recognition: Cognitive computing systems utilize deep learning algorithms and neural network architectures to process and analyze visual data. These systems employ convolutional neural networks, recurrent neural networks, and other advanced architectures to extract features, recognize patterns, and classify objects in images. The integration of multiple neural network layers enables hierarchical feature learning, improving accuracy in object detection, image segmentation, and scene understanding tasks.
- Real-time image processing and edge computing integration: Machine vision systems incorporate real-time processing capabilities through edge computing architectures that enable immediate analysis of visual data. These systems process images locally at the edge devices, reducing latency and bandwidth requirements while maintaining high processing speeds. The integration of specialized hardware accelerators and optimized algorithms allows for instantaneous decision-making in applications requiring immediate visual feedback and response.
- Multi-modal sensor fusion and data integration: Cognitive vision systems combine data from multiple sensor types including cameras, depth sensors, and other imaging devices to create comprehensive visual understanding. The fusion of different data modalities enhances the robustness and accuracy of visual perception by leveraging complementary information from various sources. Advanced algorithms process and integrate heterogeneous sensor data to generate unified representations for improved object recognition and scene interpretation.
- Adaptive learning and continuous model improvement: Machine vision systems employ adaptive learning mechanisms that enable continuous improvement of recognition models through feedback loops and incremental learning. These systems can update their knowledge base and refine their performance based on new data and user interactions without requiring complete retraining. The implementation of transfer learning and few-shot learning techniques allows the systems to adapt to new visual tasks and domains with minimal additional training data.
- Semantic understanding and contextual analysis: Advanced cognitive computing approaches enable semantic interpretation of visual content by understanding the relationships between objects, scenes, and contextual information. These systems go beyond simple object detection to comprehend the meaning and context of visual scenes, enabling higher-level reasoning and decision-making. The integration of knowledge graphs, natural language processing, and visual reasoning capabilities allows for comprehensive scene understanding and intelligent interpretation of complex visual environments.
02 Real-time image processing and analysis systems
Machine vision systems incorporate cognitive computing capabilities to perform real-time processing and analysis of visual information. These systems utilize parallel processing architectures, optimized algorithms, and hardware acceleration to achieve low-latency performance. The technology enables immediate decision-making based on visual inputs, supporting applications that require instant responses to changing visual conditions.Expand Specific Solutions03 Adaptive learning and self-improvement mechanisms
Cognitive machine vision systems implement adaptive learning mechanisms that allow continuous improvement through experience. These systems can update their models based on new data, adjust parameters automatically, and refine their performance over time without explicit reprogramming. The self-learning capabilities enable the systems to handle varying conditions, new object types, and evolving requirements in dynamic environments.Expand Specific Solutions04 Multi-modal data fusion and integration
Advanced cognitive computing approaches combine visual data with information from multiple sources and modalities to enhance understanding and decision-making. These systems integrate data from various sensors, contextual information, and prior knowledge to create comprehensive representations of scenes and objects. The fusion techniques improve robustness, accuracy, and the ability to handle complex scenarios that single-modality systems cannot address effectively.Expand Specific Solutions05 Semantic understanding and contextual reasoning
Cognitive machine vision systems incorporate semantic understanding capabilities that go beyond simple pattern recognition to comprehend the meaning and context of visual information. These systems utilize knowledge representation, reasoning engines, and natural language processing to interpret scenes, understand relationships between objects, and make inferences based on visual context. The technology enables higher-level cognitive functions such as scene description, activity recognition, and predictive analysis.Expand Specific Solutions
Key Players in Cognitive Vision Computing Industry
The cognitive computing in machine vision field represents a rapidly evolving technological landscape currently in its growth phase, with significant market expansion driven by AI and deep learning advancements. The market demonstrates substantial scale potential across automotive, healthcare, industrial automation, and consumer electronics sectors. Technology maturity varies considerably among key players: tech giants like Google LLC, Microsoft Technology Licensing LLC, and Sony Group Corp. lead with advanced AI frameworks and extensive R&D capabilities, while semiconductor leaders including QUALCOMM Inc. and NXP Semiconductors provide essential hardware foundations. Industrial specialists such as Robert Bosch GmbH, Zebra Technologies Corp., and Banner Engineering Corp. focus on practical implementation solutions. Academic institutions like Tsinghua University and Harbin Institute of Technology contribute fundamental research, while emerging companies like Chengdu ESWIN SYSTEM IC Co. represent specialized innovation. The competitive landscape shows a convergence of established technology leaders, hardware manufacturers, and specialized solution providers, indicating a maturing ecosystem with diverse integration approaches and accelerating commercial deployment across multiple industries.
Google LLC
Technical Solution: Google has developed comprehensive cognitive computing solutions for machine vision through its TensorFlow framework and Cloud Vision API. Their approach integrates deep learning models with real-time processing capabilities, enabling automatic image recognition, object detection, and scene understanding. The company leverages distributed computing architecture to process large-scale visual data, incorporating natural language processing to bridge the gap between visual perception and semantic understanding. Google's cognitive vision systems utilize transfer learning techniques to adapt pre-trained models for specific applications, while their AutoML Vision platform allows automated model optimization for various industrial use cases.
Strengths: Extensive cloud infrastructure, advanced AI research capabilities, comprehensive developer ecosystem. Weaknesses: High dependency on internet connectivity, potential privacy concerns with cloud-based processing.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft's cognitive computing approach in machine vision centers around Azure Cognitive Services and Computer Vision API, which provides pre-built AI models for image analysis, optical character recognition, and facial recognition. Their integration strategy combines edge computing with cloud services through Azure IoT Edge, enabling real-time processing while maintaining connection to cloud-based learning systems. Microsoft emphasizes hybrid deployment models where cognitive processing can occur both locally and in the cloud, supporting various industries from manufacturing to healthcare. Their platform integrates seamlessly with existing enterprise systems through REST APIs and SDKs.
Strengths: Strong enterprise integration capabilities, hybrid cloud-edge architecture, comprehensive development tools. Weaknesses: Complex pricing structure, requires technical expertise for optimal implementation.
Core Patents in Cognitive Machine Vision Integration
Information processing device, information processing method, program, and learning method
PatentWO2021241261A1
Innovation
- A cross-fusion CNN architecture that combines a Human Vision CNN (HVC) and a Machine Vision CNN (MVC) through cross-connections, allowing information transfer between arbitrary layers, enabling efficient fusion of human and machine visual processing in real-time.




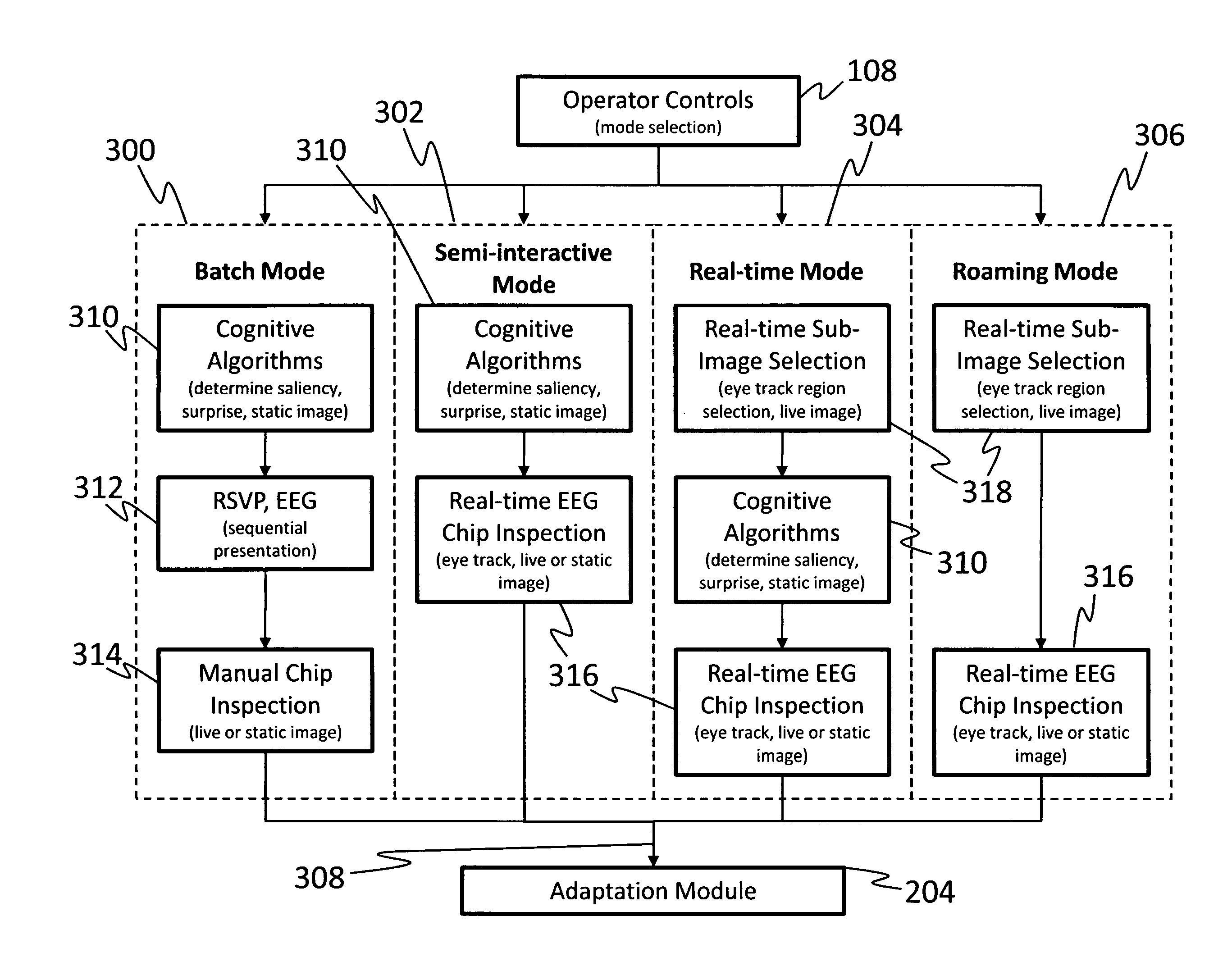
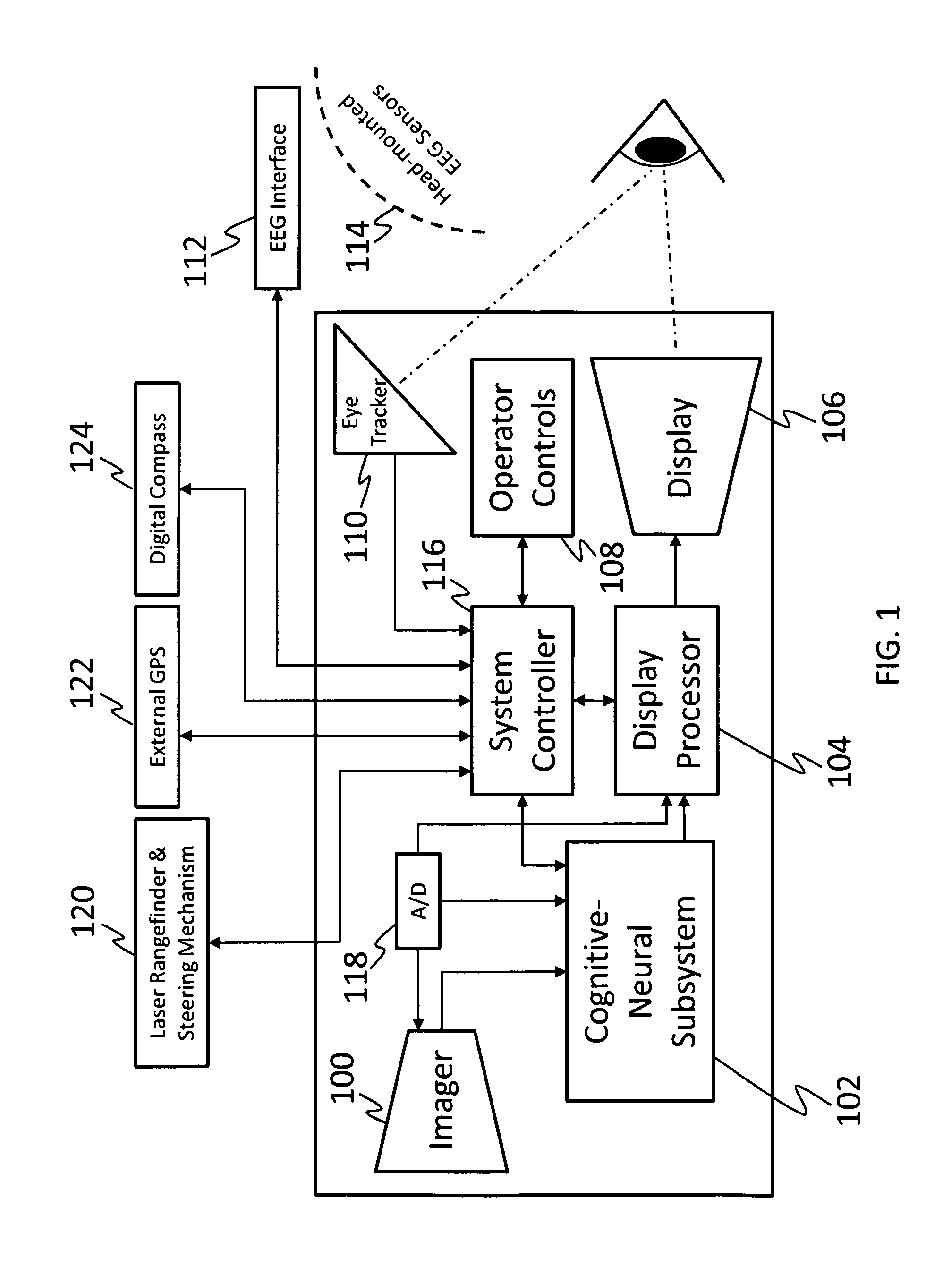
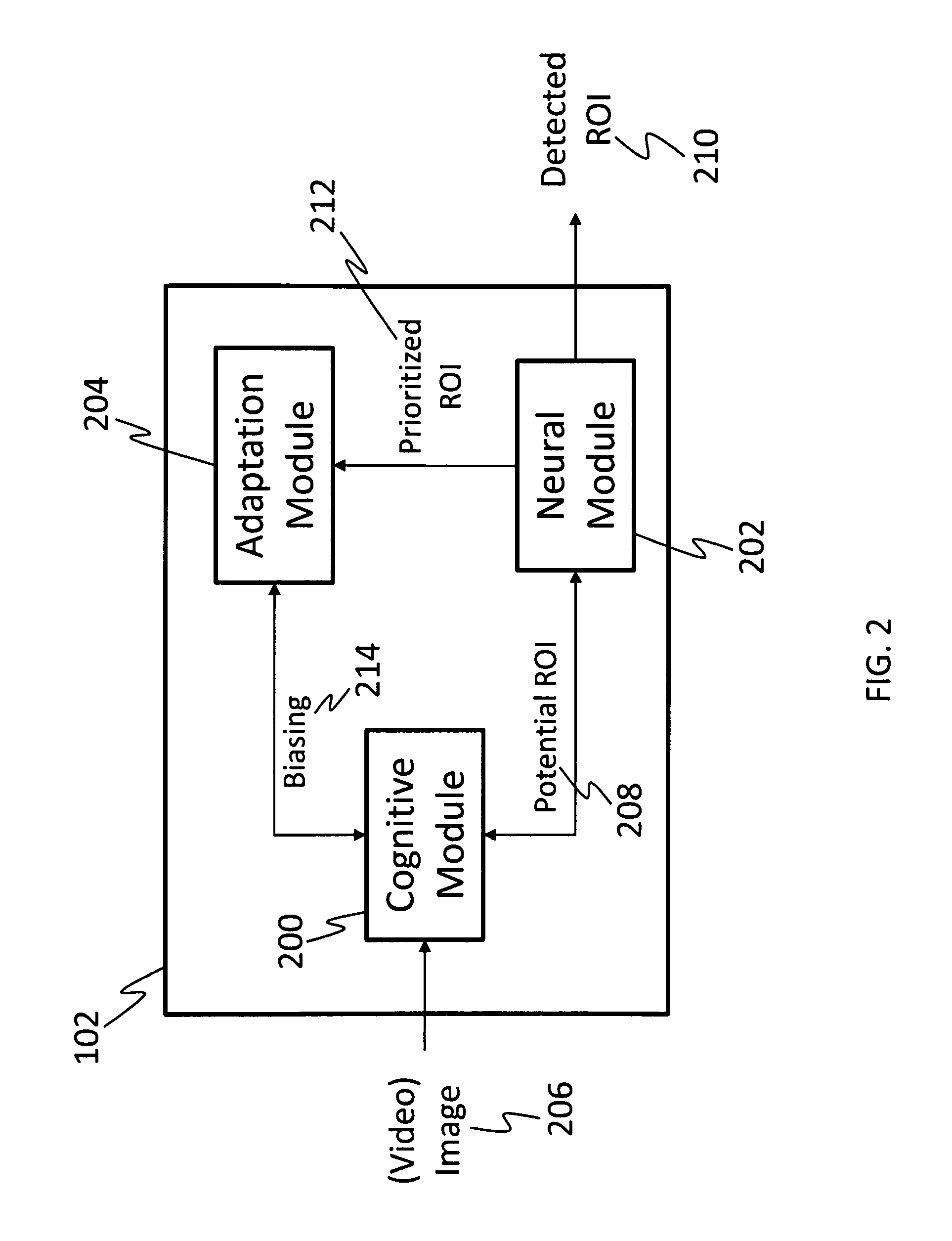
System for intelligent goal-directed search in large volume imagery and video using a cognitive-neural subsystem
PatentInactiveUS8335751B1
Innovation
- A cognitive-neural subsystem that combines cognitive and neural modules to automatically detect regions of interest in live and stored imagery using EEG responses and eye-tracking, allowing for real-time, semi-interactive, and batch modes of operation, with adaptive algorithms for improved performance.

AI Ethics and Privacy in Cognitive Vision Systems
The integration of cognitive computing technologies in machine vision systems raises significant ethical and privacy concerns that require comprehensive consideration throughout the development and deployment lifecycle. As these systems become increasingly sophisticated in their ability to process, analyze, and interpret visual data, the potential for privacy violations and ethical breaches grows exponentially.
Privacy protection represents one of the most critical challenges in cognitive vision systems. These technologies often process sensitive visual information including biometric data, behavioral patterns, and personal identifiers that can be extracted from images and video streams. The collection, storage, and processing of such data must comply with evolving privacy regulations such as GDPR, CCPA, and emerging AI-specific legislation. Organizations must implement privacy-by-design principles, ensuring that data minimization, purpose limitation, and user consent mechanisms are embedded within the system architecture.
Algorithmic bias and fairness constitute another fundamental ethical concern. Cognitive vision systems trained on biased datasets may perpetuate or amplify existing societal inequalities, particularly affecting marginalized communities. This is especially problematic in applications such as facial recognition, surveillance systems, and automated decision-making processes where biased outcomes can have severe real-world consequences.
Transparency and explainability challenges emerge as cognitive vision systems become more complex. The black-box nature of deep learning models makes it difficult to understand how decisions are made, creating accountability gaps when systems make errors or produce unexpected results. This lack of interpretability poses significant risks in high-stakes applications such as medical diagnosis, autonomous vehicles, and security systems.
Data governance frameworks must address the entire data lifecycle, from collection through disposal. This includes establishing clear protocols for data access, sharing, and retention, as well as implementing robust security measures to prevent unauthorized access or data breaches. Cross-border data transfers add additional complexity, requiring compliance with multiple jurisdictional requirements.
The development of ethical AI frameworks specifically tailored to cognitive vision systems is essential. These frameworks should encompass principles of human oversight, accountability, and the right to explanation, ensuring that human judgment remains central to critical decision-making processes while leveraging the capabilities of cognitive computing technologies.
Privacy protection represents one of the most critical challenges in cognitive vision systems. These technologies often process sensitive visual information including biometric data, behavioral patterns, and personal identifiers that can be extracted from images and video streams. The collection, storage, and processing of such data must comply with evolving privacy regulations such as GDPR, CCPA, and emerging AI-specific legislation. Organizations must implement privacy-by-design principles, ensuring that data minimization, purpose limitation, and user consent mechanisms are embedded within the system architecture.
Algorithmic bias and fairness constitute another fundamental ethical concern. Cognitive vision systems trained on biased datasets may perpetuate or amplify existing societal inequalities, particularly affecting marginalized communities. This is especially problematic in applications such as facial recognition, surveillance systems, and automated decision-making processes where biased outcomes can have severe real-world consequences.
Transparency and explainability challenges emerge as cognitive vision systems become more complex. The black-box nature of deep learning models makes it difficult to understand how decisions are made, creating accountability gaps when systems make errors or produce unexpected results. This lack of interpretability poses significant risks in high-stakes applications such as medical diagnosis, autonomous vehicles, and security systems.
Data governance frameworks must address the entire data lifecycle, from collection through disposal. This includes establishing clear protocols for data access, sharing, and retention, as well as implementing robust security measures to prevent unauthorized access or data breaches. Cross-border data transfers add additional complexity, requiring compliance with multiple jurisdictional requirements.
The development of ethical AI frameworks specifically tailored to cognitive vision systems is essential. These frameworks should encompass principles of human oversight, accountability, and the right to explanation, ensuring that human judgment remains central to critical decision-making processes while leveraging the capabilities of cognitive computing technologies.
Hardware-Software Co-design for Cognitive Vision
Hardware-software co-design represents a paradigm shift in cognitive vision systems, where computational architectures and algorithmic implementations are developed synergistically to optimize performance, power efficiency, and real-time processing capabilities. This integrated approach addresses the fundamental challenge of bridging the gap between cognitive computing requirements and physical hardware constraints in machine vision applications.
The co-design methodology begins with understanding the computational characteristics of cognitive vision algorithms, including neural network architectures, attention mechanisms, and memory access patterns. Modern cognitive vision systems demand specialized processing units that can handle parallel computations, dynamic memory allocation, and adaptive inference pipelines. This necessitates custom silicon solutions such as neuromorphic processors, vision processing units (VPUs), and application-specific integrated circuits (ASICs) designed specifically for cognitive workloads.
Memory hierarchy optimization forms a critical component of hardware-software co-design in cognitive vision systems. The integration strategy involves designing memory subsystems that can efficiently handle the diverse data types and access patterns characteristic of cognitive algorithms, including feature maps, weight matrices, and intermediate computational results. Advanced techniques such as near-memory computing and processing-in-memory architectures are being explored to minimize data movement overhead.
Software optimization techniques are equally crucial in the co-design process, involving algorithm-aware compilation, dynamic resource allocation, and adaptive execution scheduling. These software innovations must be tightly coupled with hardware capabilities to achieve optimal system performance. Techniques such as quantization-aware training, pruning strategies, and dynamic precision scaling are implemented at both hardware and software levels.
The integration of edge computing capabilities with cloud-based cognitive processing represents another dimension of hardware-software co-design. This hybrid approach enables real-time local processing for time-critical vision tasks while leveraging cloud resources for complex cognitive reasoning and model updates. The co-design framework must accommodate seamless data flow and computational load balancing between edge devices and cloud infrastructure.
Emerging technologies such as photonic computing, quantum-inspired algorithms, and bio-inspired architectures are driving new co-design opportunities in cognitive vision systems. These innovations require fundamental rethinking of traditional hardware-software boundaries and demand novel integration strategies that can harness their unique computational advantages while maintaining compatibility with existing vision processing pipelines.
The co-design methodology begins with understanding the computational characteristics of cognitive vision algorithms, including neural network architectures, attention mechanisms, and memory access patterns. Modern cognitive vision systems demand specialized processing units that can handle parallel computations, dynamic memory allocation, and adaptive inference pipelines. This necessitates custom silicon solutions such as neuromorphic processors, vision processing units (VPUs), and application-specific integrated circuits (ASICs) designed specifically for cognitive workloads.
Memory hierarchy optimization forms a critical component of hardware-software co-design in cognitive vision systems. The integration strategy involves designing memory subsystems that can efficiently handle the diverse data types and access patterns characteristic of cognitive algorithms, including feature maps, weight matrices, and intermediate computational results. Advanced techniques such as near-memory computing and processing-in-memory architectures are being explored to minimize data movement overhead.
Software optimization techniques are equally crucial in the co-design process, involving algorithm-aware compilation, dynamic resource allocation, and adaptive execution scheduling. These software innovations must be tightly coupled with hardware capabilities to achieve optimal system performance. Techniques such as quantization-aware training, pruning strategies, and dynamic precision scaling are implemented at both hardware and software levels.
The integration of edge computing capabilities with cloud-based cognitive processing represents another dimension of hardware-software co-design. This hybrid approach enables real-time local processing for time-critical vision tasks while leveraging cloud resources for complex cognitive reasoning and model updates. The co-design framework must accommodate seamless data flow and computational load balancing between edge devices and cloud infrastructure.
Emerging technologies such as photonic computing, quantum-inspired algorithms, and bio-inspired architectures are driving new co-design opportunities in cognitive vision systems. These innovations require fundamental rethinking of traditional hardware-software boundaries and demand novel integration strategies that can harness their unique computational advantages while maintaining compatibility with existing vision processing pipelines.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!