Digital Signal Processing for Speech Enhancement: Reducing Distortion
FEB 26, 20268 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Speech Enhancement DSP Background and Objectives
Digital signal processing for speech enhancement has emerged as a critical technology domain driven by the exponential growth of voice-based applications and communication systems. The evolution of this field traces back to the early developments in digital filtering and spectral analysis in the 1960s, progressing through adaptive filtering techniques in the 1980s, to modern machine learning-based approaches. This technological progression reflects the continuous pursuit of higher speech quality and intelligibility in increasingly challenging acoustic environments.
The fundamental challenge in speech enhancement lies in the inherent trade-off between noise reduction and speech distortion. Traditional approaches often achieve noise suppression at the expense of introducing artifacts or attenuating important speech components, leading to degraded perceptual quality. This limitation has driven decades of research focused on developing more sophisticated algorithms that can selectively preserve speech characteristics while effectively suppressing unwanted interference.
Current technological trends indicate a paradigm shift toward hybrid approaches that combine classical signal processing techniques with advanced machine learning methodologies. Deep neural networks, particularly recurrent and convolutional architectures, have demonstrated remarkable capabilities in learning complex noise patterns and speech representations. However, these approaches still face challenges in computational complexity, real-time processing requirements, and generalization across diverse acoustic conditions.
The primary technical objectives center on achieving optimal balance between noise reduction effectiveness and speech quality preservation. Key performance metrics include signal-to-noise ratio improvement, perceptual evaluation of speech quality scores, and short-time objective intelligibility measures. Advanced objectives encompass maintaining natural speech prosody, preserving speaker characteristics, and ensuring robust performance across various noise types and signal-to-noise ratio conditions.
Contemporary research directions emphasize the development of perceptually-motivated enhancement algorithms that align with human auditory processing mechanisms. This includes incorporating psychoacoustic principles, exploiting temporal and spectral masking properties, and developing context-aware processing strategies. The integration of multi-modal information and the exploration of end-to-end optimization frameworks represent promising avenues for achieving superior enhancement performance while minimizing distortion artifacts.
The fundamental challenge in speech enhancement lies in the inherent trade-off between noise reduction and speech distortion. Traditional approaches often achieve noise suppression at the expense of introducing artifacts or attenuating important speech components, leading to degraded perceptual quality. This limitation has driven decades of research focused on developing more sophisticated algorithms that can selectively preserve speech characteristics while effectively suppressing unwanted interference.
Current technological trends indicate a paradigm shift toward hybrid approaches that combine classical signal processing techniques with advanced machine learning methodologies. Deep neural networks, particularly recurrent and convolutional architectures, have demonstrated remarkable capabilities in learning complex noise patterns and speech representations. However, these approaches still face challenges in computational complexity, real-time processing requirements, and generalization across diverse acoustic conditions.
The primary technical objectives center on achieving optimal balance between noise reduction effectiveness and speech quality preservation. Key performance metrics include signal-to-noise ratio improvement, perceptual evaluation of speech quality scores, and short-time objective intelligibility measures. Advanced objectives encompass maintaining natural speech prosody, preserving speaker characteristics, and ensuring robust performance across various noise types and signal-to-noise ratio conditions.
Contemporary research directions emphasize the development of perceptually-motivated enhancement algorithms that align with human auditory processing mechanisms. This includes incorporating psychoacoustic principles, exploiting temporal and spectral masking properties, and developing context-aware processing strategies. The integration of multi-modal information and the exploration of end-to-end optimization frameworks represent promising avenues for achieving superior enhancement performance while minimizing distortion artifacts.
Market Demand for Clear Audio Communication Systems
The global demand for clear audio communication systems has experienced unprecedented growth across multiple sectors, driven by the fundamental shift toward digital communication platforms and remote collaboration technologies. Enterprise communications represent the largest market segment, where organizations increasingly rely on high-quality audio solutions for video conferencing, unified communications, and collaborative platforms. The proliferation of hybrid work models has intensified requirements for crystal-clear audio transmission, making speech enhancement technologies essential rather than optional.
Consumer electronics markets demonstrate robust demand for enhanced audio processing capabilities, particularly in smartphones, tablets, and wireless audio devices. Users expect seamless communication experiences regardless of environmental conditions, driving manufacturers to integrate sophisticated digital signal processing solutions. The automotive industry has emerged as a significant growth driver, with voice-controlled infotainment systems and hands-free communication requiring advanced noise reduction and speech clarity technologies.
Healthcare communications present specialized market opportunities, where clear audio transmission can impact patient safety and diagnostic accuracy. Telemedicine platforms, medical device communications, and emergency response systems require exceptionally reliable speech enhancement capabilities. Similarly, public safety and defense sectors demand robust audio communication systems that perform effectively in challenging acoustic environments.
The telecommunications infrastructure sector continues expanding its requirements for speech enhancement technologies as network operators upgrade to advanced voice services. Voice over Internet Protocol implementations and next-generation mobile networks necessitate sophisticated digital signal processing to maintain communication quality across diverse network conditions.
Market growth drivers include increasing consumer expectations for audio quality, regulatory requirements for accessibility in communication systems, and the expanding Internet of Things ecosystem requiring voice interfaces. The integration of artificial intelligence and machine learning capabilities into speech enhancement systems has created new market segments focused on adaptive and intelligent audio processing solutions.
Emerging applications in virtual and augmented reality environments represent significant future market potential, where spatial audio and real-time speech processing become critical for immersive experiences. The convergence of communication technologies with emerging platforms continues expanding the addressable market for advanced speech enhancement solutions.
Consumer electronics markets demonstrate robust demand for enhanced audio processing capabilities, particularly in smartphones, tablets, and wireless audio devices. Users expect seamless communication experiences regardless of environmental conditions, driving manufacturers to integrate sophisticated digital signal processing solutions. The automotive industry has emerged as a significant growth driver, with voice-controlled infotainment systems and hands-free communication requiring advanced noise reduction and speech clarity technologies.
Healthcare communications present specialized market opportunities, where clear audio transmission can impact patient safety and diagnostic accuracy. Telemedicine platforms, medical device communications, and emergency response systems require exceptionally reliable speech enhancement capabilities. Similarly, public safety and defense sectors demand robust audio communication systems that perform effectively in challenging acoustic environments.
The telecommunications infrastructure sector continues expanding its requirements for speech enhancement technologies as network operators upgrade to advanced voice services. Voice over Internet Protocol implementations and next-generation mobile networks necessitate sophisticated digital signal processing to maintain communication quality across diverse network conditions.
Market growth drivers include increasing consumer expectations for audio quality, regulatory requirements for accessibility in communication systems, and the expanding Internet of Things ecosystem requiring voice interfaces. The integration of artificial intelligence and machine learning capabilities into speech enhancement systems has created new market segments focused on adaptive and intelligent audio processing solutions.
Emerging applications in virtual and augmented reality environments represent significant future market potential, where spatial audio and real-time speech processing become critical for immersive experiences. The convergence of communication technologies with emerging platforms continues expanding the addressable market for advanced speech enhancement solutions.
Current DSP Challenges in Speech Distortion Reduction
Digital signal processing for speech enhancement faces numerous technical obstacles that significantly impact the effectiveness of distortion reduction systems. The primary challenge lies in the inherent trade-off between noise suppression and speech quality preservation. Aggressive noise reduction algorithms often introduce artifacts such as musical noise, spectral distortion, and temporal discontinuities that can severely degrade the naturalness and intelligibility of enhanced speech signals.
Real-time processing constraints present another critical challenge in modern DSP implementations. Speech enhancement systems must operate within strict latency requirements, typically under 20-30 milliseconds for telecommunications applications. This temporal limitation restricts the complexity of algorithms that can be deployed, forcing engineers to balance computational efficiency with enhancement quality. The challenge becomes more pronounced in resource-constrained environments such as hearing aids and mobile devices.
Spectral leakage and frequency domain artifacts constitute significant technical hurdles in current DSP approaches. Traditional windowing techniques and frame-based processing methods introduce boundary effects that manifest as spectral smearing and temporal aliasing. These artifacts are particularly problematic in non-stationary noise environments where rapid spectral changes occur, leading to suboptimal noise estimation and subsequent distortion in the enhanced speech output.
The complexity of multi-speaker scenarios and overlapping speech presents substantial algorithmic challenges. Current DSP methods struggle to effectively separate and enhance individual speakers while maintaining spatial audio characteristics. This limitation is exacerbated by reverberation effects and acoustic coupling in real-world environments, where traditional single-channel enhancement techniques prove inadequate.
Adaptive filter convergence issues represent another fundamental challenge in speech enhancement systems. The non-stationary nature of both speech and noise signals creates difficulties in achieving optimal filter coefficients, particularly during rapid transitions between speech and silence periods. Slow convergence rates can result in transient distortions and reduced enhancement performance during the initial adaptation phase.
Finally, the lack of robust perceptual quality metrics poses a significant challenge for DSP algorithm development and evaluation. Traditional objective measures such as SNR improvement often fail to correlate with subjective speech quality assessments, making it difficult to optimize algorithms for human perception. This disconnect between technical performance metrics and actual user experience continues to hinder the development of more effective speech enhancement solutions.
Real-time processing constraints present another critical challenge in modern DSP implementations. Speech enhancement systems must operate within strict latency requirements, typically under 20-30 milliseconds for telecommunications applications. This temporal limitation restricts the complexity of algorithms that can be deployed, forcing engineers to balance computational efficiency with enhancement quality. The challenge becomes more pronounced in resource-constrained environments such as hearing aids and mobile devices.
Spectral leakage and frequency domain artifacts constitute significant technical hurdles in current DSP approaches. Traditional windowing techniques and frame-based processing methods introduce boundary effects that manifest as spectral smearing and temporal aliasing. These artifacts are particularly problematic in non-stationary noise environments where rapid spectral changes occur, leading to suboptimal noise estimation and subsequent distortion in the enhanced speech output.
The complexity of multi-speaker scenarios and overlapping speech presents substantial algorithmic challenges. Current DSP methods struggle to effectively separate and enhance individual speakers while maintaining spatial audio characteristics. This limitation is exacerbated by reverberation effects and acoustic coupling in real-world environments, where traditional single-channel enhancement techniques prove inadequate.
Adaptive filter convergence issues represent another fundamental challenge in speech enhancement systems. The non-stationary nature of both speech and noise signals creates difficulties in achieving optimal filter coefficients, particularly during rapid transitions between speech and silence periods. Slow convergence rates can result in transient distortions and reduced enhancement performance during the initial adaptation phase.
Finally, the lack of robust perceptual quality metrics poses a significant challenge for DSP algorithm development and evaluation. Traditional objective measures such as SNR improvement often fail to correlate with subjective speech quality assessments, making it difficult to optimize algorithms for human perception. This disconnect between technical performance metrics and actual user experience continues to hinder the development of more effective speech enhancement solutions.
Existing DSP Solutions for Speech Distortion Mitigation
01 Predistortion techniques for distortion compensation
Digital predistortion methods are employed to compensate for nonlinear distortion in signal processing systems. These techniques involve analyzing the characteristics of the distortion and applying inverse distortion functions before signal amplification or transmission. Adaptive algorithms can be used to continuously update predistortion parameters based on feedback signals, ensuring optimal distortion correction across varying operating conditions.- Predistortion techniques for distortion compensation: Digital predistortion methods are employed to compensate for nonlinear distortion in signal processing systems. These techniques involve analyzing the characteristics of the distortion and applying inverse distortion functions before signal amplification or transmission. Adaptive algorithms can be used to continuously update predistortion parameters based on feedback signals, ensuring optimal distortion correction across varying operating conditions.
- Linearization of power amplifiers: Power amplifier linearization techniques address distortion caused by nonlinear amplification characteristics. Methods include feedforward correction, feedback loops, and digital signal processing algorithms that monitor output signals and adjust input signals accordingly. These approaches help maintain signal integrity while maximizing amplifier efficiency and reducing harmonic distortion and intermodulation products.
- Distortion measurement and analysis systems: Systems and methods for measuring and analyzing distortion in digital signal processing involve specialized test equipment and algorithms. These systems can detect various types of distortion including harmonic distortion, intermodulation distortion, and phase distortion. Real-time monitoring capabilities enable continuous assessment of signal quality and provide metrics for system optimization and calibration.
- Adaptive filtering for distortion reduction: Adaptive filtering techniques dynamically adjust filter coefficients to minimize distortion in digital signal processing applications. These methods utilize algorithms that learn from signal characteristics and environmental conditions to optimize filter performance. Applications include echo cancellation, noise reduction, and equalization where distortion varies over time or across different signal conditions.
- Digital correction circuits for signal integrity: Specialized digital correction circuits are designed to detect and correct various forms of signal distortion in real-time processing applications. These circuits employ error detection algorithms, compensation networks, and calibration mechanisms to maintain signal fidelity. Implementation may include dedicated hardware blocks or software-based solutions that process signals to remove unwanted distortion components while preserving the original signal information.
02 Linearization of power amplifiers
Power amplifier linearization techniques address distortion caused by nonlinear amplification characteristics. Methods include feedforward correction, feedback loops, and digital signal processing algorithms that monitor output signals and adjust input signals accordingly. These approaches help maintain signal integrity while maximizing amplifier efficiency and reducing harmonic distortion and intermodulation products.Expand Specific Solutions03 Distortion measurement and analysis systems
Systems and methods for measuring and analyzing distortion in digital signal processing involve specialized test equipment and algorithms. These systems can detect various types of distortion including harmonic distortion, intermodulation distortion, and phase distortion. Real-time monitoring capabilities enable continuous assessment of signal quality and provide metrics for system optimization and calibration.Expand Specific Solutions04 Adaptive filtering for distortion reduction
Adaptive filtering techniques dynamically adjust filter coefficients to minimize distortion in digital signal processing applications. These methods utilize algorithms that learn from signal characteristics and environmental conditions to optimize filter performance. Applications include echo cancellation, noise reduction, and equalization where distortion varies over time or across different signal conditions.Expand Specific Solutions05 Digital correction circuits for signal integrity
Digital correction circuits implement hardware and software solutions to maintain signal integrity by correcting various forms of distortion. These circuits may include digital-to-analog converter correction, timing jitter compensation, and quantization error reduction. Integration of correction algorithms at the circuit level enables real-time distortion mitigation with minimal latency impact on signal processing chains.Expand Specific Solutions
Core DSP Algorithms for Speech Quality Improvement
Noise suppression
PatentInactiveUS20060184363A1
Innovation
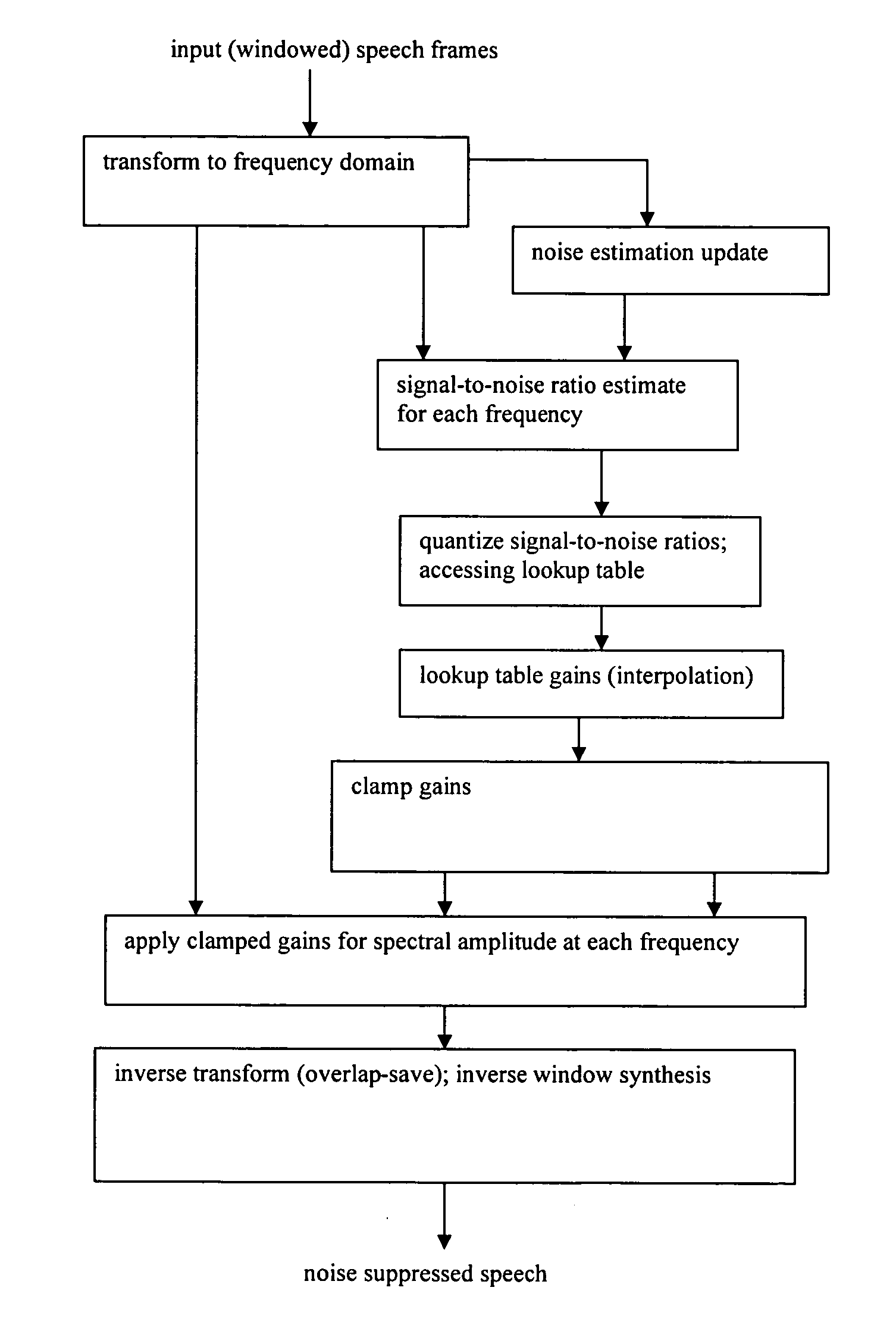
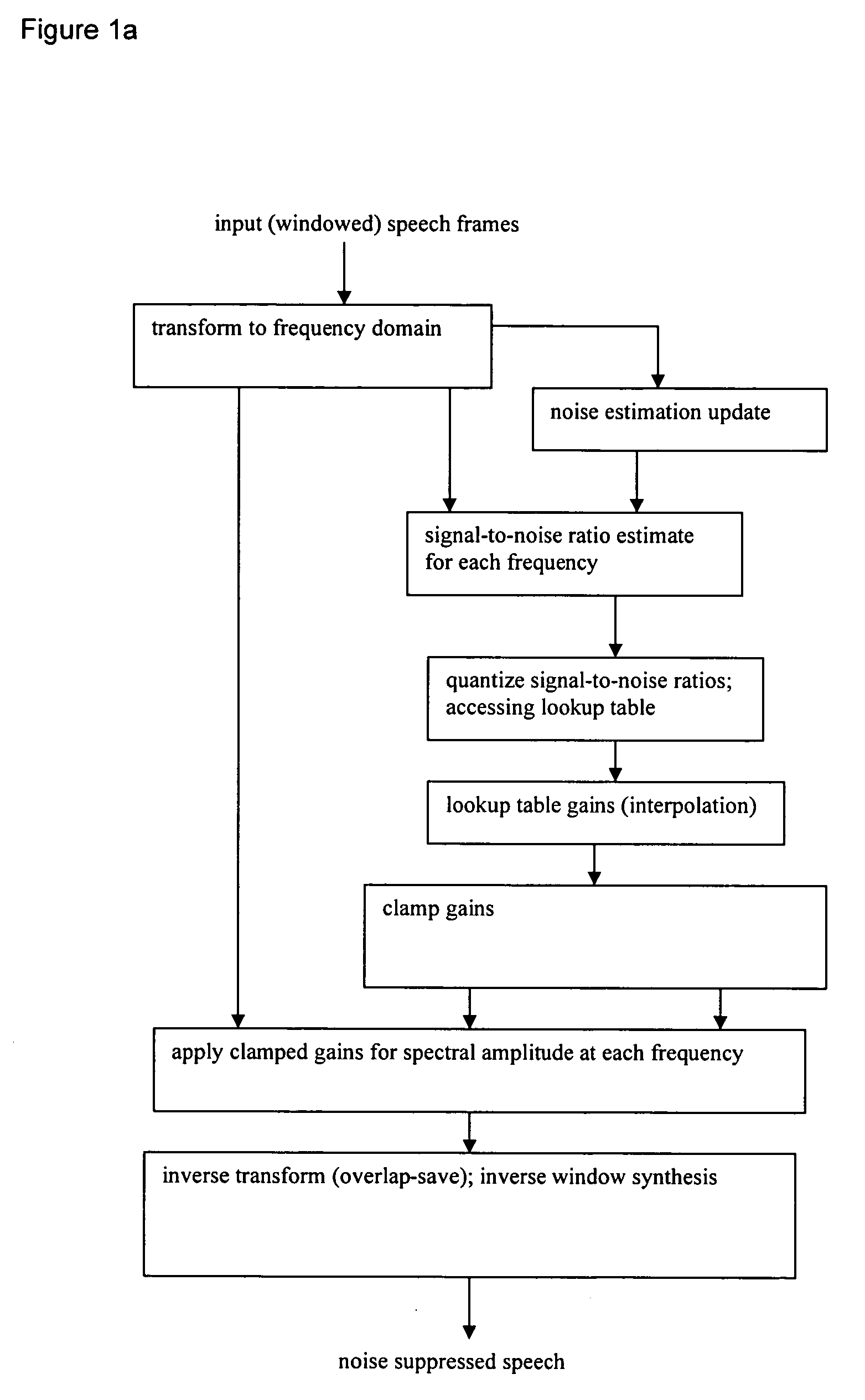
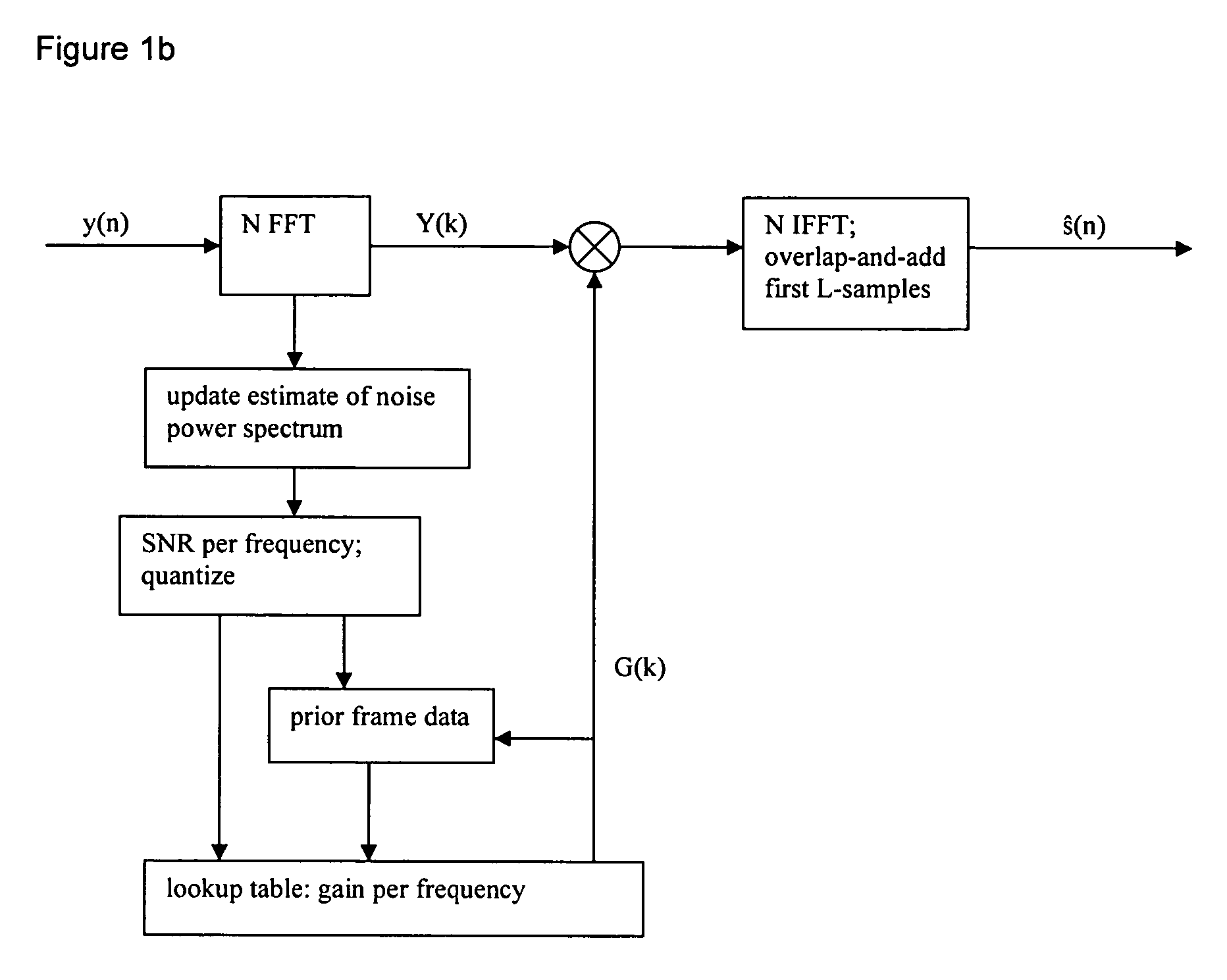
- The method employs a frequency-dependent gain based on signal-to-noise ratio (SNR) using codebook mapping, which involves windowing noisy speech, transforming it into the frequency domain, estimating SNR, and applying a frequency-dependent gain through a lookup table constructed from training data, with options for gain smoothing and clamping to enhance noise suppression.

Apparatuses for providing a processed audio signal, apparatuses for providing neural network parameters, methods and computer program
PatentWO2023186934A1
Innovation
- The use of an apparatus that processes audio signals using flow blocks with affine scaling and a neural network, combined with an All-Pole Gammatone Filterbank adapted to human auditory resolutions, to enhance speech signals by conditioning noise processing on input audio signals, thereby improving audio quality and reducing computational complexity.




Audio Quality Standards and Compliance Requirements
Audio quality standards and compliance requirements form the foundation for evaluating speech enhancement systems in digital signal processing applications. These standards establish measurable criteria for assessing the effectiveness of distortion reduction algorithms and ensure consistent performance across different implementation environments. The telecommunications industry relies heavily on standardized metrics to guarantee interoperability between systems and maintain acceptable user experience levels.
The International Telecommunication Union (ITU) has established several critical standards for speech quality assessment, including ITU-T P.862 (PESQ - Perceptual Evaluation of Speech Quality) and ITU-T P.863 (POLQA - Perceptual Objective Listening Quality Assessment). These standards provide objective measurement frameworks that correlate strongly with subjective human perception of speech quality. PESQ operates in the frequency range of 300-3400 Hz for narrowband applications, while POLQA extends coverage to wideband and super-wideband scenarios up to 14 kHz.
Compliance with IEEE standards, particularly IEEE 269-2010 for measuring transmission performance, ensures that speech enhancement systems meet rigorous technical specifications. These requirements encompass signal-to-noise ratio improvements, total harmonic distortion limits, and frequency response characteristics. Modern speech enhancement systems must demonstrate measurable improvements in these parameters while maintaining computational efficiency within specified processing latency constraints.
Regulatory compliance extends beyond technical performance to include safety and electromagnetic compatibility requirements. FCC Part 68 regulations in North America and CE marking requirements in Europe mandate specific performance thresholds for telecommunications equipment. Speech enhancement systems must demonstrate compliance with these standards through comprehensive testing protocols that validate both standalone performance and integration capabilities with existing infrastructure.
Industry-specific compliance requirements vary significantly across applications. Medical device implementations must adhere to FDA regulations and ISO 14155 clinical investigation standards, while automotive applications require compliance with ISO 26262 functional safety standards. Consumer electronics applications typically follow IEC 62368-1 safety standards and regional electromagnetic compatibility directives, ensuring that speech enhancement technologies can be safely deployed across diverse market segments while maintaining consistent quality performance.
The International Telecommunication Union (ITU) has established several critical standards for speech quality assessment, including ITU-T P.862 (PESQ - Perceptual Evaluation of Speech Quality) and ITU-T P.863 (POLQA - Perceptual Objective Listening Quality Assessment). These standards provide objective measurement frameworks that correlate strongly with subjective human perception of speech quality. PESQ operates in the frequency range of 300-3400 Hz for narrowband applications, while POLQA extends coverage to wideband and super-wideband scenarios up to 14 kHz.
Compliance with IEEE standards, particularly IEEE 269-2010 for measuring transmission performance, ensures that speech enhancement systems meet rigorous technical specifications. These requirements encompass signal-to-noise ratio improvements, total harmonic distortion limits, and frequency response characteristics. Modern speech enhancement systems must demonstrate measurable improvements in these parameters while maintaining computational efficiency within specified processing latency constraints.
Regulatory compliance extends beyond technical performance to include safety and electromagnetic compatibility requirements. FCC Part 68 regulations in North America and CE marking requirements in Europe mandate specific performance thresholds for telecommunications equipment. Speech enhancement systems must demonstrate compliance with these standards through comprehensive testing protocols that validate both standalone performance and integration capabilities with existing infrastructure.
Industry-specific compliance requirements vary significantly across applications. Medical device implementations must adhere to FDA regulations and ISO 14155 clinical investigation standards, while automotive applications require compliance with ISO 26262 functional safety standards. Consumer electronics applications typically follow IEC 62368-1 safety standards and regional electromagnetic compatibility directives, ensuring that speech enhancement technologies can be safely deployed across diverse market segments while maintaining consistent quality performance.
Real-time Processing Constraints in Speech DSP Systems
Real-time processing constraints represent one of the most critical challenges in speech DSP systems designed for distortion reduction. These systems must operate within strict latency boundaries while maintaining computational efficiency and audio quality standards. The fundamental constraint lies in achieving processing delays below 20-30 milliseconds to ensure natural conversational flow, particularly in applications such as hearing aids, telecommunications, and live audio processing systems.
Computational complexity poses significant limitations on algorithm selection and implementation strategies. Traditional speech enhancement algorithms often require extensive spectral analysis, adaptive filtering, and noise estimation processes that can exceed real-time processing capabilities. Modern DSP processors must balance between sophisticated enhancement techniques and available computational resources, typically operating at clock speeds ranging from 100MHz to 1GHz with limited memory bandwidth.
Memory constraints further complicate real-time implementation, as speech enhancement algorithms frequently require substantial buffer storage for frame-based processing and historical data retention. Systems must optimize memory allocation between input buffering, intermediate processing stages, and output queuing while maintaining minimal latency. Typical implementations utilize circular buffers and overlap-add techniques to manage memory efficiently within constraints of 64KB to 2MB available RAM.
Power consumption limitations significantly impact algorithm complexity, particularly in battery-powered devices like hearing aids and mobile communication systems. Real-time speech DSP systems must achieve enhancement performance while operating within power budgets of 1-10 milliwatts, necessitating careful selection of processing techniques and hardware acceleration strategies.
Adaptive processing requirements introduce additional real-time constraints, as speech enhancement systems must continuously adjust to changing acoustic environments and noise conditions. These adaptations must occur seamlessly without introducing audible artifacts or processing interruptions, requiring sophisticated control mechanisms and predictive algorithms that operate within the established latency boundaries while maintaining consistent enhancement quality across diverse operating conditions.
Computational complexity poses significant limitations on algorithm selection and implementation strategies. Traditional speech enhancement algorithms often require extensive spectral analysis, adaptive filtering, and noise estimation processes that can exceed real-time processing capabilities. Modern DSP processors must balance between sophisticated enhancement techniques and available computational resources, typically operating at clock speeds ranging from 100MHz to 1GHz with limited memory bandwidth.
Memory constraints further complicate real-time implementation, as speech enhancement algorithms frequently require substantial buffer storage for frame-based processing and historical data retention. Systems must optimize memory allocation between input buffering, intermediate processing stages, and output queuing while maintaining minimal latency. Typical implementations utilize circular buffers and overlap-add techniques to manage memory efficiently within constraints of 64KB to 2MB available RAM.
Power consumption limitations significantly impact algorithm complexity, particularly in battery-powered devices like hearing aids and mobile communication systems. Real-time speech DSP systems must achieve enhancement performance while operating within power budgets of 1-10 milliwatts, necessitating careful selection of processing techniques and hardware acceleration strategies.
Adaptive processing requirements introduce additional real-time constraints, as speech enhancement systems must continuously adjust to changing acoustic environments and noise conditions. These adaptations must occur seamlessly without introducing audible artifacts or processing interruptions, requiring sophisticated control mechanisms and predictive algorithms that operate within the established latency boundaries while maintaining consistent enhancement quality across diverse operating conditions.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!