

How to Improve Neural Network Performance with Transfer Learning
FEB 27, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Transfer Learning Background and Neural Network Goals
Transfer learning emerged as a paradigmatic shift in machine learning during the early 2000s, fundamentally challenging the traditional assumption that models must be trained from scratch for each new task. The concept draws inspiration from human cognitive processes, where knowledge acquired from previous experiences accelerates learning in new but related domains. This approach gained significant momentum with the proliferation of deep neural networks, where the computational cost and data requirements of training large models from initialization became increasingly prohibitive.
The historical evolution of transfer learning can be traced through several key phases. Initially, researchers focused on domain adaptation techniques in the 1990s, primarily addressing statistical distribution differences between training and target datasets. The breakthrough came with the advent of deep learning architectures, particularly convolutional neural networks, where researchers discovered that lower-layer features often captured universal patterns applicable across diverse tasks. This revelation transformed transfer learning from a niche technique into a mainstream methodology.
Contemporary neural network architectures have been specifically designed to facilitate knowledge transfer. Pre-trained models such as ResNet, VGG, and more recently, transformer-based architectures like BERT and GPT, serve as foundational building blocks for transfer learning applications. These models, trained on massive datasets, encapsulate hierarchical feature representations that can be effectively adapted to downstream tasks with limited data availability.
The primary technical objectives of implementing transfer learning in neural networks encompass several critical dimensions. Performance enhancement represents the most immediate goal, where transfer learning aims to achieve superior accuracy, precision, and recall metrics compared to models trained from scratch. This improvement is particularly pronounced in scenarios with limited training data, where traditional approaches often suffer from overfitting and poor generalization capabilities.
Computational efficiency constitutes another fundamental objective. Transfer learning significantly reduces training time and resource requirements by leveraging pre-existing learned representations. This efficiency gain enables organizations to deploy sophisticated neural network solutions without extensive computational infrastructure, democratizing access to advanced machine learning capabilities across various industry sectors.
Data efficiency represents a crucial technical target, especially in domains where labeled data acquisition is expensive or challenging. Transfer learning enables effective model performance with substantially smaller datasets by utilizing knowledge encoded in pre-trained models. This capability is particularly valuable in specialized applications such as medical imaging, where expert annotations are scarce and costly.
The overarching goal extends beyond immediate performance gains to establish robust, generalizable neural network systems capable of rapid adaptation to emerging challenges and evolving requirements in dynamic technological landscapes.
The historical evolution of transfer learning can be traced through several key phases. Initially, researchers focused on domain adaptation techniques in the 1990s, primarily addressing statistical distribution differences between training and target datasets. The breakthrough came with the advent of deep learning architectures, particularly convolutional neural networks, where researchers discovered that lower-layer features often captured universal patterns applicable across diverse tasks. This revelation transformed transfer learning from a niche technique into a mainstream methodology.
Contemporary neural network architectures have been specifically designed to facilitate knowledge transfer. Pre-trained models such as ResNet, VGG, and more recently, transformer-based architectures like BERT and GPT, serve as foundational building blocks for transfer learning applications. These models, trained on massive datasets, encapsulate hierarchical feature representations that can be effectively adapted to downstream tasks with limited data availability.
The primary technical objectives of implementing transfer learning in neural networks encompass several critical dimensions. Performance enhancement represents the most immediate goal, where transfer learning aims to achieve superior accuracy, precision, and recall metrics compared to models trained from scratch. This improvement is particularly pronounced in scenarios with limited training data, where traditional approaches often suffer from overfitting and poor generalization capabilities.
Computational efficiency constitutes another fundamental objective. Transfer learning significantly reduces training time and resource requirements by leveraging pre-existing learned representations. This efficiency gain enables organizations to deploy sophisticated neural network solutions without extensive computational infrastructure, democratizing access to advanced machine learning capabilities across various industry sectors.
Data efficiency represents a crucial technical target, especially in domains where labeled data acquisition is expensive or challenging. Transfer learning enables effective model performance with substantially smaller datasets by utilizing knowledge encoded in pre-trained models. This capability is particularly valuable in specialized applications such as medical imaging, where expert annotations are scarce and costly.
The overarching goal extends beyond immediate performance gains to establish robust, generalizable neural network systems capable of rapid adaptation to emerging challenges and evolving requirements in dynamic technological landscapes.
Market Demand for Efficient Deep Learning Solutions
The global deep learning market is experiencing unprecedented growth driven by the increasing complexity of AI applications across industries. Organizations are facing mounting pressure to deploy sophisticated neural networks while managing computational costs and development timelines. Transfer learning has emerged as a critical solution to address these challenges, enabling companies to leverage pre-trained models and achieve superior performance with reduced resource requirements.
Enterprise demand for efficient deep learning solutions spans multiple sectors, with technology companies, healthcare organizations, financial institutions, and manufacturing enterprises leading adoption efforts. These organizations require neural network solutions that can deliver high accuracy while minimizing training time and computational overhead. The ability to adapt existing models to new domains through transfer learning has become essential for maintaining competitive advantage in rapidly evolving markets.
Cloud service providers are witnessing substantial increases in demand for transfer learning capabilities within their machine learning platforms. Major cloud vendors report significant growth in usage of pre-trained model repositories and transfer learning frameworks. This trend reflects the broader industry shift toward democratizing AI development, making advanced neural network capabilities accessible to organizations with limited machine learning expertise or computational resources.
The automotive industry represents a particularly compelling use case, where companies must rapidly develop computer vision models for autonomous driving applications. Transfer learning enables these organizations to build upon established image recognition models, significantly reducing the time and data requirements for developing specialized automotive AI systems. Similar patterns emerge in healthcare, where medical imaging applications benefit from models initially trained on general image datasets.
Startup ecosystems are increasingly dependent on transfer learning approaches to compete with larger organizations possessing extensive datasets and computational resources. These companies leverage pre-trained models as foundational building blocks, focusing their limited resources on domain-specific fine-tuning rather than training models from scratch. This democratization effect is expanding the total addressable market for deep learning solutions.
Research institutions and academic organizations constitute another significant demand segment, requiring efficient methods to explore novel applications without extensive infrastructure investments. Transfer learning enables rapid prototyping and experimentation, accelerating research cycles and facilitating breakthrough discoveries across diverse scientific domains.
The convergence of edge computing requirements and transfer learning capabilities is creating new market opportunities. Organizations seek neural network solutions that can be efficiently deployed on resource-constrained devices while maintaining acceptable performance levels. Transfer learning techniques that enable model compression and optimization are becoming increasingly valuable for mobile and IoT applications.
Enterprise demand for efficient deep learning solutions spans multiple sectors, with technology companies, healthcare organizations, financial institutions, and manufacturing enterprises leading adoption efforts. These organizations require neural network solutions that can deliver high accuracy while minimizing training time and computational overhead. The ability to adapt existing models to new domains through transfer learning has become essential for maintaining competitive advantage in rapidly evolving markets.
Cloud service providers are witnessing substantial increases in demand for transfer learning capabilities within their machine learning platforms. Major cloud vendors report significant growth in usage of pre-trained model repositories and transfer learning frameworks. This trend reflects the broader industry shift toward democratizing AI development, making advanced neural network capabilities accessible to organizations with limited machine learning expertise or computational resources.
The automotive industry represents a particularly compelling use case, where companies must rapidly develop computer vision models for autonomous driving applications. Transfer learning enables these organizations to build upon established image recognition models, significantly reducing the time and data requirements for developing specialized automotive AI systems. Similar patterns emerge in healthcare, where medical imaging applications benefit from models initially trained on general image datasets.
Startup ecosystems are increasingly dependent on transfer learning approaches to compete with larger organizations possessing extensive datasets and computational resources. These companies leverage pre-trained models as foundational building blocks, focusing their limited resources on domain-specific fine-tuning rather than training models from scratch. This democratization effect is expanding the total addressable market for deep learning solutions.
Research institutions and academic organizations constitute another significant demand segment, requiring efficient methods to explore novel applications without extensive infrastructure investments. Transfer learning enables rapid prototyping and experimentation, accelerating research cycles and facilitating breakthrough discoveries across diverse scientific domains.
The convergence of edge computing requirements and transfer learning capabilities is creating new market opportunities. Organizations seek neural network solutions that can be efficiently deployed on resource-constrained devices while maintaining acceptable performance levels. Transfer learning techniques that enable model compression and optimization are becoming increasingly valuable for mobile and IoT applications.
Current State and Challenges in Neural Network Training
Neural network training has reached a sophisticated level of maturity, with deep learning architectures achieving remarkable performance across diverse domains including computer vision, natural language processing, and speech recognition. Modern training methodologies incorporate advanced optimization algorithms such as Adam, RMSprop, and their variants, alongside sophisticated regularization techniques including dropout, batch normalization, and weight decay. The field has witnessed significant progress in architectural innovations, from convolutional neural networks to transformer-based models, each designed to address specific computational challenges and data characteristics.
Despite these advances, neural network training continues to face substantial computational and resource constraints. Training large-scale models from scratch requires enormous datasets, often millions or billions of samples, which are not readily available for many specialized domains. The computational cost associated with training deep networks presents a significant barrier, with state-of-the-art models requiring weeks or months of training on high-performance GPU clusters, making such approaches economically unfeasible for many organizations and research institutions.
Data scarcity represents another critical challenge, particularly in specialized domains such as medical imaging, rare language processing, or niche industrial applications. Traditional training approaches struggle when labeled data is limited, often resulting in overfitting and poor generalization performance. This limitation is compounded by the cold-start problem, where models must learn complex feature representations from scratch without leveraging previously acquired knowledge from related tasks or domains.
The convergence and stability issues in neural network training remain persistent challenges. Networks often exhibit sensitivity to hyperparameter selection, initialization strategies, and learning rate schedules. Training instability can manifest as gradient vanishing or exploding problems, particularly in very deep networks, leading to suboptimal performance or complete training failure. Additionally, the lack of theoretical guarantees regarding convergence to global optima creates uncertainty in training outcomes.
Geographical distribution of neural network training capabilities reveals significant disparities, with advanced training infrastructure concentrated primarily in North America, Europe, and East Asia. This concentration reflects the substantial investment required for high-performance computing resources and specialized expertise. Emerging markets face challenges in accessing cutting-edge training methodologies due to limited computational infrastructure and talent availability, creating a technological divide that impacts global innovation capacity in artificial intelligence applications.
Despite these advances, neural network training continues to face substantial computational and resource constraints. Training large-scale models from scratch requires enormous datasets, often millions or billions of samples, which are not readily available for many specialized domains. The computational cost associated with training deep networks presents a significant barrier, with state-of-the-art models requiring weeks or months of training on high-performance GPU clusters, making such approaches economically unfeasible for many organizations and research institutions.
Data scarcity represents another critical challenge, particularly in specialized domains such as medical imaging, rare language processing, or niche industrial applications. Traditional training approaches struggle when labeled data is limited, often resulting in overfitting and poor generalization performance. This limitation is compounded by the cold-start problem, where models must learn complex feature representations from scratch without leveraging previously acquired knowledge from related tasks or domains.
The convergence and stability issues in neural network training remain persistent challenges. Networks often exhibit sensitivity to hyperparameter selection, initialization strategies, and learning rate schedules. Training instability can manifest as gradient vanishing or exploding problems, particularly in very deep networks, leading to suboptimal performance or complete training failure. Additionally, the lack of theoretical guarantees regarding convergence to global optima creates uncertainty in training outcomes.
Geographical distribution of neural network training capabilities reveals significant disparities, with advanced training infrastructure concentrated primarily in North America, Europe, and East Asia. This concentration reflects the substantial investment required for high-performance computing resources and specialized expertise. Emerging markets face challenges in accessing cutting-edge training methodologies due to limited computational infrastructure and talent availability, creating a technological divide that impacts global innovation capacity in artificial intelligence applications.
Existing Transfer Learning Implementation Approaches
01 Neural network architecture optimization and configuration
Techniques for optimizing neural network architectures to enhance performance include configuring network layers, adjusting network depth and width, and selecting appropriate activation functions. Architecture search methods and automated design approaches can be employed to identify optimal network structures. These optimization strategies help improve computational efficiency, reduce latency, and enhance overall model performance for various applications.- Neural network architecture optimization and configuration: Techniques for optimizing neural network architectures to enhance performance include configuring network layers, adjusting network depth and width, and implementing specialized network structures. These methods focus on designing efficient network topologies that balance computational complexity with accuracy. Architecture search and automated design approaches can be employed to identify optimal configurations for specific applications.
- Hardware acceleration and computational efficiency: Improving neural network performance through hardware-based acceleration involves utilizing specialized processors, optimizing memory access patterns, and implementing parallel processing techniques. These approaches reduce inference time and power consumption while maintaining accuracy. Hardware-software co-design strategies enable efficient execution of neural network operations on various computing platforms.
- Training optimization and learning algorithms: Enhanced training methodologies improve neural network performance by implementing advanced optimization algorithms, adaptive learning rates, and regularization techniques. These methods accelerate convergence, prevent overfitting, and improve generalization capabilities. Training strategies may include batch normalization, gradient optimization, and loss function modifications to achieve better model performance.
- Model compression and pruning techniques: Reducing neural network size while maintaining performance involves compression methods such as weight pruning, quantization, and knowledge distillation. These techniques decrease model complexity, reduce memory requirements, and accelerate inference speed. Compression strategies enable deployment of neural networks on resource-constrained devices without significant accuracy loss.
- Performance monitoring and adaptive optimization: Real-time performance monitoring and dynamic optimization techniques adjust neural network operations based on runtime conditions and performance metrics. These approaches include adaptive resource allocation, dynamic precision adjustment, and performance-aware scheduling. Monitoring systems track accuracy, latency, and resource utilization to enable continuous performance improvement and efficient operation across varying workloads.
02 Hardware acceleration and computational efficiency
Hardware-based solutions for improving neural network performance involve specialized processors, accelerators, and computing architectures designed to execute neural network operations more efficiently. These implementations may include optimized memory access patterns, parallel processing capabilities, and dedicated computational units. Such hardware optimizations significantly reduce inference time and power consumption while maintaining or improving accuracy.Expand Specific Solutions03 Training optimization and learning algorithms
Methods for enhancing neural network performance through improved training processes include advanced optimization algorithms, learning rate scheduling, and regularization techniques. These approaches help networks converge faster, avoid overfitting, and achieve better generalization. Training strategies may also involve data augmentation, batch normalization, and adaptive learning methods to improve model accuracy and robustness.Expand Specific Solutions04 Model compression and pruning techniques
Techniques for reducing neural network size and complexity while maintaining performance include weight pruning, quantization, and knowledge distillation. These methods enable deployment on resource-constrained devices by reducing memory footprint and computational requirements. Compression strategies can significantly decrease model size and inference time without substantial accuracy loss, making neural networks more practical for edge computing and mobile applications.Expand Specific Solutions05 Performance monitoring and adaptive optimization
Systems and methods for monitoring neural network performance in real-time and dynamically adjusting network parameters to maintain optimal operation. These approaches include performance metrics tracking, adaptive resource allocation, and runtime optimization techniques. Monitoring frameworks can detect performance degradation and trigger corrective actions, ensuring consistent network performance across varying workloads and operating conditions.Expand Specific Solutions
Key Players in Deep Learning and Transfer Learning
The transfer learning landscape represents a mature and rapidly expanding market, driven by the technology's proven ability to reduce training time and computational costs while improving neural network performance across diverse applications. Major technology giants including Google LLC, NVIDIA Corp., Microsoft Technology Licensing LLC, and IBM Corp. have established dominant positions through comprehensive AI platforms and extensive research investments. Asian technology leaders such as Huawei Technologies, Samsung Electronics, Baidu, and QUALCOMM contribute significant innovations, particularly in mobile and edge computing applications. The competitive environment also features specialized AI companies like Soul Machines and telecommunications providers including Ericsson and NTT, alongside prominent research institutions such as Northwestern Polytechnical University and University of Southern California, indicating a collaborative ecosystem where academic research directly influences commercial implementations and market advancement.
Google LLC
Technical Solution: Google has developed comprehensive transfer learning frameworks through TensorFlow Hub and pre-trained models like BERT, Vision Transformer, and EfficientNet. Their approach focuses on feature extraction and fine-tuning methodologies that enable rapid adaptation of large-scale models to specific tasks with minimal data requirements. Google's transfer learning pipeline incorporates advanced techniques such as progressive resizing, mixup augmentation, and adaptive learning rate scheduling to optimize performance across diverse domains including natural language processing, computer vision, and speech recognition.
Strengths: Extensive pre-trained model ecosystem, robust infrastructure, strong research foundation. Weaknesses: High computational requirements, potential vendor lock-in concerns.
International Business Machines Corp.
Technical Solution: IBM's transfer learning strategy focuses on Watson AI platform and IBM Research innovations in few-shot learning and meta-learning algorithms. Their approach incorporates federated transfer learning techniques that enable knowledge sharing across distributed environments while preserving data privacy. IBM's methodology includes advanced regularization techniques, adaptive batch normalization, and progressive knowledge distillation to enhance transfer learning effectiveness in enterprise applications, particularly in healthcare, finance, and manufacturing domains.
Strengths: Enterprise focus, strong privacy protection, industry-specific solutions. Weaknesses: Limited consumer market presence, complex implementation requirements.
Core Innovations in Neural Network Transfer Techniques
Automated fine-tuning of a pre-trained neural network for transfer learning
PatentActiveUS12437190B2
Innovation
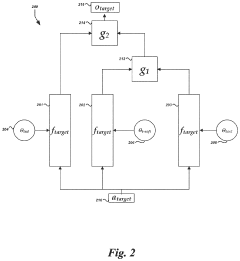
- An automated system calculates divergence values between source and target datasets to determine optimal learning rates for each layer of a pre-trained neural network, using symmetric Kullback-Leibler divergence to refine and repurpose the network for new tasks.




Dynamic transfer learning for neural network modeling
PatentActiveUS11093714B1
Innovation
- The implementation of dynamic transfer networks using gating mechanisms to combine various parameter sharing schemes, allowing for the determination of an optimal parameter sharing configuration without the need to train multiple models, thereby reducing training time and improving efficiency.



Computational Resource Optimization Strategies
Transfer learning implementations require strategic computational resource optimization to achieve maximum efficiency while maintaining model performance. The fundamental challenge lies in balancing computational overhead with the benefits gained from leveraging pre-trained models. Effective resource management becomes critical when deploying transfer learning solutions at scale, particularly in enterprise environments where computational costs directly impact operational budgets.
Memory optimization represents a primary concern in transfer learning workflows. Pre-trained models often consume substantial GPU memory, especially large-scale architectures like Vision Transformers or large language models. Gradient checkpointing techniques can reduce memory footprint by trading computation for memory, storing only subset of intermediate activations during forward passes. Additionally, mixed-precision training using FP16 or BF16 formats can halve memory requirements while maintaining numerical stability through careful loss scaling strategies.
Model architecture pruning and quantization offer significant computational savings without severely compromising transfer learning effectiveness. Structured pruning removes entire channels or layers from pre-trained networks, reducing both memory and computational requirements. Post-training quantization converts model weights from 32-bit to 8-bit or even 4-bit representations, dramatically reducing model size and inference latency. These techniques prove particularly valuable when deploying transfer learning models on edge devices or resource-constrained environments.
Dynamic batching and adaptive learning rate scheduling optimize training efficiency during fine-tuning phases. Gradient accumulation allows effective large batch training on limited hardware by accumulating gradients across multiple smaller batches before parameter updates. Learning rate warm-up strategies prevent catastrophic forgetting of pre-trained features while enabling efficient convergence to task-specific optima.
Distributed training frameworks enable horizontal scaling of transfer learning workloads across multiple GPUs or nodes. Data parallelism distributes training samples across devices, while model parallelism partitions large models across multiple accelerators. Pipeline parallelism further optimizes resource utilization by overlapping computation and communication phases, reducing idle time and maximizing throughput in multi-device configurations.
Memory optimization represents a primary concern in transfer learning workflows. Pre-trained models often consume substantial GPU memory, especially large-scale architectures like Vision Transformers or large language models. Gradient checkpointing techniques can reduce memory footprint by trading computation for memory, storing only subset of intermediate activations during forward passes. Additionally, mixed-precision training using FP16 or BF16 formats can halve memory requirements while maintaining numerical stability through careful loss scaling strategies.
Model architecture pruning and quantization offer significant computational savings without severely compromising transfer learning effectiveness. Structured pruning removes entire channels or layers from pre-trained networks, reducing both memory and computational requirements. Post-training quantization converts model weights from 32-bit to 8-bit or even 4-bit representations, dramatically reducing model size and inference latency. These techniques prove particularly valuable when deploying transfer learning models on edge devices or resource-constrained environments.
Dynamic batching and adaptive learning rate scheduling optimize training efficiency during fine-tuning phases. Gradient accumulation allows effective large batch training on limited hardware by accumulating gradients across multiple smaller batches before parameter updates. Learning rate warm-up strategies prevent catastrophic forgetting of pre-trained features while enabling efficient convergence to task-specific optima.
Distributed training frameworks enable horizontal scaling of transfer learning workloads across multiple GPUs or nodes. Data parallelism distributes training samples across devices, while model parallelism partitions large models across multiple accelerators. Pipeline parallelism further optimizes resource utilization by overlapping computation and communication phases, reducing idle time and maximizing throughput in multi-device configurations.
Data Privacy and Model Security Considerations
Transfer learning in neural networks introduces significant data privacy challenges that organizations must carefully address. When leveraging pre-trained models, sensitive information from the original training datasets may inadvertently leak into the transferred knowledge representations. This phenomenon, known as model inversion or membership inference attacks, poses substantial risks to individual privacy and organizational confidentiality.
The primary privacy concern stems from the fact that pre-trained models retain statistical patterns and feature representations from their original training data. When these models are fine-tuned on proprietary datasets, there exists potential for cross-contamination of sensitive information. Adversarial actors may exploit gradient information or model parameters to reconstruct portions of the training data, potentially exposing personal identifiable information or trade secrets.
Model security vulnerabilities in transfer learning scenarios extend beyond traditional privacy concerns. Backdoor attacks represent a critical threat where malicious actors embed hidden triggers in pre-trained models. These compromised models may perform normally during standard operations but exhibit predetermined malicious behaviors when specific input patterns are encountered. The widespread adoption of publicly available pre-trained models amplifies this risk significantly.
Differential privacy mechanisms offer promising solutions for mitigating privacy risks in transfer learning applications. By introducing carefully calibrated noise during the fine-tuning process, organizations can limit the amount of sensitive information that becomes embedded in model parameters. However, implementing differential privacy requires careful balance between privacy protection and model performance preservation.
Federated transfer learning emerges as another viable approach for addressing privacy concerns while maintaining collaborative model development. This methodology enables multiple parties to benefit from shared pre-trained representations without directly exposing their proprietary datasets. Secure aggregation protocols and homomorphic encryption techniques further enhance privacy protection in federated scenarios.
Organizations implementing transfer learning must establish comprehensive security frameworks that include model provenance tracking, adversarial robustness testing, and continuous monitoring for potential privacy breaches. Regular security audits and penetration testing specifically designed for machine learning systems become essential components of responsible AI deployment strategies.
The primary privacy concern stems from the fact that pre-trained models retain statistical patterns and feature representations from their original training data. When these models are fine-tuned on proprietary datasets, there exists potential for cross-contamination of sensitive information. Adversarial actors may exploit gradient information or model parameters to reconstruct portions of the training data, potentially exposing personal identifiable information or trade secrets.
Model security vulnerabilities in transfer learning scenarios extend beyond traditional privacy concerns. Backdoor attacks represent a critical threat where malicious actors embed hidden triggers in pre-trained models. These compromised models may perform normally during standard operations but exhibit predetermined malicious behaviors when specific input patterns are encountered. The widespread adoption of publicly available pre-trained models amplifies this risk significantly.
Differential privacy mechanisms offer promising solutions for mitigating privacy risks in transfer learning applications. By introducing carefully calibrated noise during the fine-tuning process, organizations can limit the amount of sensitive information that becomes embedded in model parameters. However, implementing differential privacy requires careful balance between privacy protection and model performance preservation.
Federated transfer learning emerges as another viable approach for addressing privacy concerns while maintaining collaborative model development. This methodology enables multiple parties to benefit from shared pre-trained representations without directly exposing their proprietary datasets. Secure aggregation protocols and homomorphic encryption techniques further enhance privacy protection in federated scenarios.
Organizations implementing transfer learning must establish comprehensive security frameworks that include model provenance tracking, adversarial robustness testing, and continuous monitoring for potential privacy breaches. Regular security audits and penetration testing specifically designed for machine learning systems become essential components of responsible AI deployment strategies.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!