

How to Map Multi-Dimensional Data for Hyperdimensional Model Training
JUN 4, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Hyperdimensional Computing Background and Training Objectives
Hyperdimensional Computing (HDC) represents a paradigm shift in computational approaches, drawing inspiration from the high-dimensional nature of neural processing in biological systems. This computing methodology operates on the principle that information can be encoded and processed in extremely high-dimensional spaces, typically ranging from 1,000 to 10,000 dimensions, where mathematical operations become more robust and fault-tolerant due to the statistical properties of high-dimensional vectors.
The foundational concept of HDC emerged from neuroscience research demonstrating that the human brain processes information through distributed representations across vast neural networks. Unlike traditional computing architectures that rely on precise numerical calculations, HDC leverages the holographic properties of high-dimensional spaces where information is distributed across all dimensions, making the system inherently resilient to noise and component failures.
HDC systems utilize hypervectors as the fundamental data structure, which are high-dimensional binary or bipolar vectors with specific mathematical properties. These hypervectors can represent complex data structures, relationships, and patterns through simple vector operations such as bundling, binding, and permutation. The bundling operation combines multiple hypervectors to create superposition representations, while binding creates associative memories between different concepts.
The evolution of HDC has been driven by the increasing demand for energy-efficient computing solutions capable of handling complex pattern recognition tasks. Traditional machine learning approaches often require extensive computational resources and are vulnerable to adversarial attacks, whereas HDC offers inherent robustness and can operate effectively with minimal training data.
Current research objectives in HDC focus on developing efficient mapping techniques that can transform multi-dimensional real-world data into hyperdimensional representations while preserving essential structural relationships and semantic meanings. The challenge lies in creating encoding schemes that maintain the discriminative power of original data while leveraging the computational advantages of hyperdimensional spaces.
The primary technical goal involves establishing systematic methodologies for data transformation that can handle various data types including temporal sequences, spatial patterns, and categorical information. This requires developing novel algorithms that can automatically determine optimal encoding parameters and dimension allocation strategies based on the specific characteristics of input data and target applications.
The foundational concept of HDC emerged from neuroscience research demonstrating that the human brain processes information through distributed representations across vast neural networks. Unlike traditional computing architectures that rely on precise numerical calculations, HDC leverages the holographic properties of high-dimensional spaces where information is distributed across all dimensions, making the system inherently resilient to noise and component failures.
HDC systems utilize hypervectors as the fundamental data structure, which are high-dimensional binary or bipolar vectors with specific mathematical properties. These hypervectors can represent complex data structures, relationships, and patterns through simple vector operations such as bundling, binding, and permutation. The bundling operation combines multiple hypervectors to create superposition representations, while binding creates associative memories between different concepts.
The evolution of HDC has been driven by the increasing demand for energy-efficient computing solutions capable of handling complex pattern recognition tasks. Traditional machine learning approaches often require extensive computational resources and are vulnerable to adversarial attacks, whereas HDC offers inherent robustness and can operate effectively with minimal training data.
Current research objectives in HDC focus on developing efficient mapping techniques that can transform multi-dimensional real-world data into hyperdimensional representations while preserving essential structural relationships and semantic meanings. The challenge lies in creating encoding schemes that maintain the discriminative power of original data while leveraging the computational advantages of hyperdimensional spaces.
The primary technical goal involves establishing systematic methodologies for data transformation that can handle various data types including temporal sequences, spatial patterns, and categorical information. This requires developing novel algorithms that can automatically determine optimal encoding parameters and dimension allocation strategies based on the specific characteristics of input data and target applications.
Market Demand for Multi-Dimensional Data Processing Solutions
The global demand for multi-dimensional data processing solutions has experienced unprecedented growth driven by the exponential increase in data complexity across industries. Organizations worldwide are grappling with datasets that span multiple dimensions, requiring sophisticated mapping techniques to extract meaningful insights and enable effective machine learning model training. This surge in demand stems from the proliferation of IoT devices, sensor networks, and digital transformation initiatives that generate vast amounts of heterogeneous data.
Financial services represent one of the most significant market segments driving demand for advanced multi-dimensional data processing capabilities. Banks and investment firms require real-time processing of market data, customer behavior patterns, and risk assessment metrics across multiple temporal and categorical dimensions. The need to map complex financial instruments and their interdependencies for hyperdimensional model training has become critical for algorithmic trading and fraud detection systems.
Healthcare and life sciences sectors demonstrate substantial market appetite for multi-dimensional data mapping solutions. Medical imaging, genomics research, and patient monitoring systems generate complex datasets requiring sophisticated dimensional reduction and mapping techniques. The integration of electronic health records with real-time monitoring data creates multi-dimensional challenges that traditional processing methods cannot adequately address.
Manufacturing industries increasingly demand solutions for processing multi-dimensional sensor data from smart factories and Industry 4.0 implementations. Production optimization, predictive maintenance, and quality control systems require mapping of temporal, spatial, and operational parameters into formats suitable for hyperdimensional model training. The complexity of modern manufacturing processes necessitates advanced data processing capabilities to maintain competitive advantages.
Autonomous vehicle development and smart city initiatives represent emerging high-growth market segments. These applications require real-time processing of multi-dimensional sensor fusion data, including lidar, camera, radar, and GPS information. The challenge of mapping this heterogeneous data for training autonomous navigation models drives significant investment in advanced processing solutions.
The market demand is further amplified by the limitations of traditional dimensionality reduction techniques when dealing with hyperdimensional model requirements. Organizations seek solutions that preserve critical information while enabling efficient model training, creating opportunities for innovative mapping approaches that can handle the scale and complexity of modern multi-dimensional datasets.
Financial services represent one of the most significant market segments driving demand for advanced multi-dimensional data processing capabilities. Banks and investment firms require real-time processing of market data, customer behavior patterns, and risk assessment metrics across multiple temporal and categorical dimensions. The need to map complex financial instruments and their interdependencies for hyperdimensional model training has become critical for algorithmic trading and fraud detection systems.
Healthcare and life sciences sectors demonstrate substantial market appetite for multi-dimensional data mapping solutions. Medical imaging, genomics research, and patient monitoring systems generate complex datasets requiring sophisticated dimensional reduction and mapping techniques. The integration of electronic health records with real-time monitoring data creates multi-dimensional challenges that traditional processing methods cannot adequately address.
Manufacturing industries increasingly demand solutions for processing multi-dimensional sensor data from smart factories and Industry 4.0 implementations. Production optimization, predictive maintenance, and quality control systems require mapping of temporal, spatial, and operational parameters into formats suitable for hyperdimensional model training. The complexity of modern manufacturing processes necessitates advanced data processing capabilities to maintain competitive advantages.
Autonomous vehicle development and smart city initiatives represent emerging high-growth market segments. These applications require real-time processing of multi-dimensional sensor fusion data, including lidar, camera, radar, and GPS information. The challenge of mapping this heterogeneous data for training autonomous navigation models drives significant investment in advanced processing solutions.
The market demand is further amplified by the limitations of traditional dimensionality reduction techniques when dealing with hyperdimensional model requirements. Organizations seek solutions that preserve critical information while enabling efficient model training, creating opportunities for innovative mapping approaches that can handle the scale and complexity of modern multi-dimensional datasets.
Current State of Hyperdimensional Model Training Challenges
Hyperdimensional computing (HDC) has emerged as a promising paradigm for machine learning, offering advantages in energy efficiency and fault tolerance. However, the field currently faces significant challenges in effectively mapping multi-dimensional data to hyperdimensional representations. The primary obstacle lies in the fundamental mismatch between traditional data structures and the requirements of hyperdimensional vector spaces, which typically operate with dimensions ranging from 1,000 to 10,000 or higher.
The encoding bottleneck represents one of the most pressing issues in current HDC implementations. Traditional encoding methods struggle to preserve semantic relationships and spatial correlations present in multi-dimensional datasets when transforming them into hyperdimensional vectors. This challenge is particularly acute when dealing with heterogeneous data types, where different modalities require distinct encoding strategies that must remain compatible within the unified hyperdimensional framework.
Computational complexity poses another significant barrier to widespread adoption. Current mapping algorithms often exhibit quadratic or higher time complexity with respect to input dimensionality, making them impractical for large-scale applications. Memory requirements for storing and manipulating hyperdimensional vectors create additional constraints, especially in resource-limited environments where HDC's energy efficiency advantages would be most beneficial.
The lack of standardized benchmarking protocols hampers progress in addressing these challenges. Researchers currently employ diverse evaluation metrics and datasets, making it difficult to compare different mapping approaches objectively. This fragmentation has led to inconsistent performance claims and limited reproducibility across different implementations and hardware platforms.
Training stability issues further complicate the landscape. Many existing hyperdimensional models exhibit sensitivity to initialization parameters and encoding choices, resulting in unpredictable convergence behavior. The absence of robust theoretical frameworks for understanding these dynamics limits the development of reliable training methodologies.
Hardware-software co-design challenges also persist, as current mapping algorithms are often not optimized for emerging neuromorphic and in-memory computing architectures that could maximize HDC's potential benefits. This misalignment between algorithmic design and hardware capabilities represents a critical gap that must be addressed for practical deployment.
The encoding bottleneck represents one of the most pressing issues in current HDC implementations. Traditional encoding methods struggle to preserve semantic relationships and spatial correlations present in multi-dimensional datasets when transforming them into hyperdimensional vectors. This challenge is particularly acute when dealing with heterogeneous data types, where different modalities require distinct encoding strategies that must remain compatible within the unified hyperdimensional framework.
Computational complexity poses another significant barrier to widespread adoption. Current mapping algorithms often exhibit quadratic or higher time complexity with respect to input dimensionality, making them impractical for large-scale applications. Memory requirements for storing and manipulating hyperdimensional vectors create additional constraints, especially in resource-limited environments where HDC's energy efficiency advantages would be most beneficial.
The lack of standardized benchmarking protocols hampers progress in addressing these challenges. Researchers currently employ diverse evaluation metrics and datasets, making it difficult to compare different mapping approaches objectively. This fragmentation has led to inconsistent performance claims and limited reproducibility across different implementations and hardware platforms.
Training stability issues further complicate the landscape. Many existing hyperdimensional models exhibit sensitivity to initialization parameters and encoding choices, resulting in unpredictable convergence behavior. The absence of robust theoretical frameworks for understanding these dynamics limits the development of reliable training methodologies.
Hardware-software co-design challenges also persist, as current mapping algorithms are often not optimized for emerging neuromorphic and in-memory computing architectures that could maximize HDC's potential benefits. This misalignment between algorithmic design and hardware capabilities represents a critical gap that must be addressed for practical deployment.
Existing Multi-Dimensional Data Mapping Solutions
01 Parallel processing algorithms for multi-dimensional data mapping
Implementation of parallel processing techniques to enhance the efficiency of multi-dimensional data mapping operations. These algorithms distribute computational tasks across multiple processors or cores to reduce processing time and improve overall system performance. The approach includes load balancing mechanisms and optimized thread management for handling large-scale multi-dimensional datasets.- Parallel processing algorithms for multi-dimensional data mapping: Implementation of parallel processing techniques to enhance the efficiency of multi-dimensional data mapping operations. These algorithms distribute computational tasks across multiple processors or cores to reduce processing time and improve overall system performance. The approach includes load balancing mechanisms and optimized thread management for handling large-scale multi-dimensional datasets.
- Optimized indexing structures for dimensional data access: Advanced indexing methodologies designed to accelerate data retrieval and mapping operations in multi-dimensional spaces. These structures utilize hierarchical organization, spatial partitioning, and hash-based techniques to minimize search time and improve query performance. The indexing systems are specifically tailored for high-dimensional data environments.
- Memory management optimization for large-scale data mapping: Techniques for efficient memory allocation and management during multi-dimensional data mapping processes. These methods include cache optimization, memory pooling, and dynamic allocation strategies to handle memory-intensive operations while maintaining system stability and performance. The approaches focus on reducing memory fragmentation and improving data locality.
- Compression algorithms for dimensional data storage efficiency: Data compression methodologies specifically designed for multi-dimensional datasets to reduce storage requirements and improve transfer efficiency. These algorithms exploit dimensional correlations and redundancies to achieve optimal compression ratios while maintaining data integrity and enabling fast decompression for mapping operations.
- Adaptive mapping strategies for dynamic dimensional scaling: Dynamic adaptation mechanisms that adjust mapping strategies based on data characteristics and system resources. These approaches include real-time performance monitoring, automatic parameter tuning, and scalable architectures that can handle varying dimensional complexities and data volumes while maintaining optimal mapping efficiency.
02 Optimized indexing structures for dimensional data access
Advanced indexing methodologies designed to accelerate data retrieval and mapping operations in multi-dimensional spaces. These structures utilize hierarchical organization, spatial partitioning, and hash-based techniques to minimize search time and improve query performance. The indexing systems are specifically tailored for high-dimensional data environments.Expand Specific Solutions03 Memory management optimization for large-scale data mapping
Techniques for efficient memory allocation and management during multi-dimensional data mapping processes. These methods include cache optimization, memory pooling, and dynamic allocation strategies to handle memory-intensive operations while maintaining system stability and performance. The approaches focus on reducing memory fragmentation and improving data locality.Expand Specific Solutions04 Compression algorithms for dimensional data storage efficiency
Data compression methodologies specifically designed for multi-dimensional datasets to reduce storage requirements and improve transfer efficiency. These algorithms exploit dimensional correlations and redundancies to achieve optimal compression ratios while maintaining fast decompression capabilities for real-time mapping operations.Expand Specific Solutions05 Adaptive mapping algorithms with dynamic optimization
Self-adjusting algorithms that dynamically optimize mapping strategies based on data characteristics and system performance metrics. These adaptive systems monitor computational efficiency in real-time and automatically adjust parameters, data structures, and processing methods to maintain optimal performance across varying dimensional complexities and data volumes.Expand Specific Solutions
Key Players in Hyperdimensional Computing and AI Hardware
The multi-dimensional data mapping for hyperdimensional model training field represents an emerging technological frontier currently in its early-to-mid development stage. The market demonstrates significant growth potential driven by increasing demand for advanced AI and machine learning applications across industries. Technology giants like IBM, Google, NVIDIA, and Microsoft are leading the competitive landscape, leveraging their extensive R&D capabilities and cloud infrastructure to advance hyperdimensional computing solutions. Academic institutions including Fudan University and University of California contribute foundational research, while specialized companies like aiMotive focus on domain-specific applications such as autonomous driving. The technology maturity varies significantly among players, with established tech companies possessing more robust implementation capabilities compared to emerging startups, creating a multi-tiered competitive environment where collaboration between industry leaders and research institutions accelerates innovation.
International Business Machines Corp.
Technical Solution: IBM's approach to hyperdimensional computing leverages their neuromorphic chip technology and quantum-inspired algorithms for mapping multi-dimensional data. Their solution employs phase-change memory devices and memristive crossbar arrays to perform in-memory computing operations essential for hyperdimensional model training. The company has developed specialized encoding schemes that transform multi-dimensional sensor data into binary hypervectors using circular convolution and XOR operations. Their architecture supports real-time learning and adaptation through online training algorithms that can update hyperdimensional representations without requiring full model retraining. IBM's research emphasizes energy-efficient computing paradigms that mimic biological neural networks.
Strengths: Pioneer in neuromorphic computing hardware, strong expertise in quantum computing integration, energy-efficient processing capabilities. Weaknesses: Limited commercial availability of neuromorphic hardware, complex integration with existing AI infrastructure.
Google LLC
Technical Solution: Google has developed advanced tensor processing units (TPUs) and TensorFlow framework specifically designed for multi-dimensional data mapping in hyperdimensional computing. Their approach utilizes distributed computing architectures that can efficiently handle high-dimensional vector spaces through optimized matrix operations and parallel processing. The company's hyperdimensional computing research focuses on encoding multi-dimensional sensory data into hypervectors using binding and bundling operations, enabling robust pattern recognition and associative memory capabilities. Their technical solution incorporates neuromorphic computing principles with traditional deep learning architectures to create hybrid models that can process thousands of dimensions simultaneously while maintaining computational efficiency.
Strengths: Extensive cloud infrastructure and advanced TPU hardware acceleration, strong research capabilities in distributed computing. Weaknesses: High computational costs for large-scale deployments, dependency on proprietary hardware ecosystem.
Core Innovations in Hyperdimensional Vector Encoding
Method, system and computer program product for non-linear mapping of multi-dimensional data
PatentInactiveUS7117187B2
Innovation
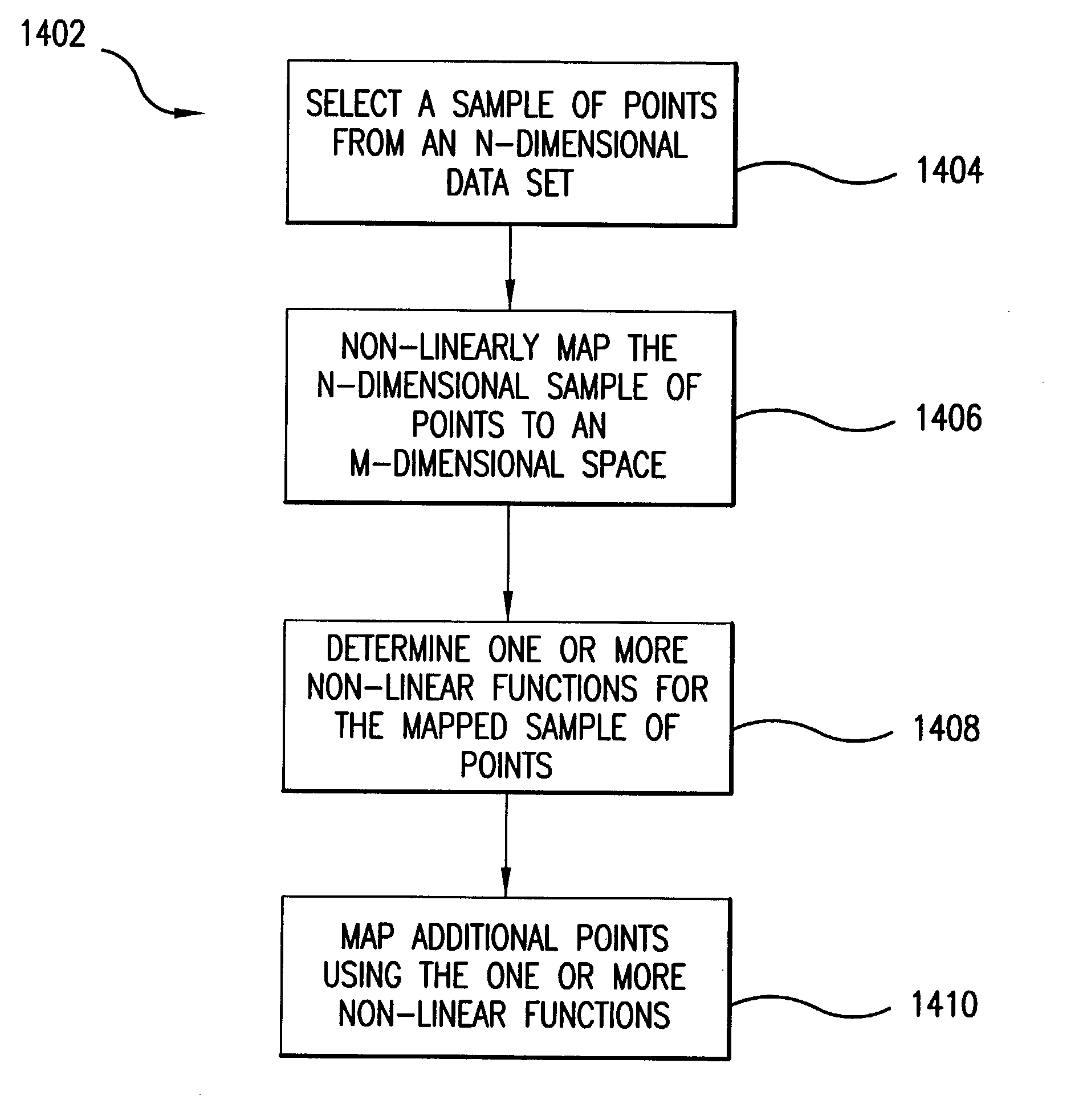
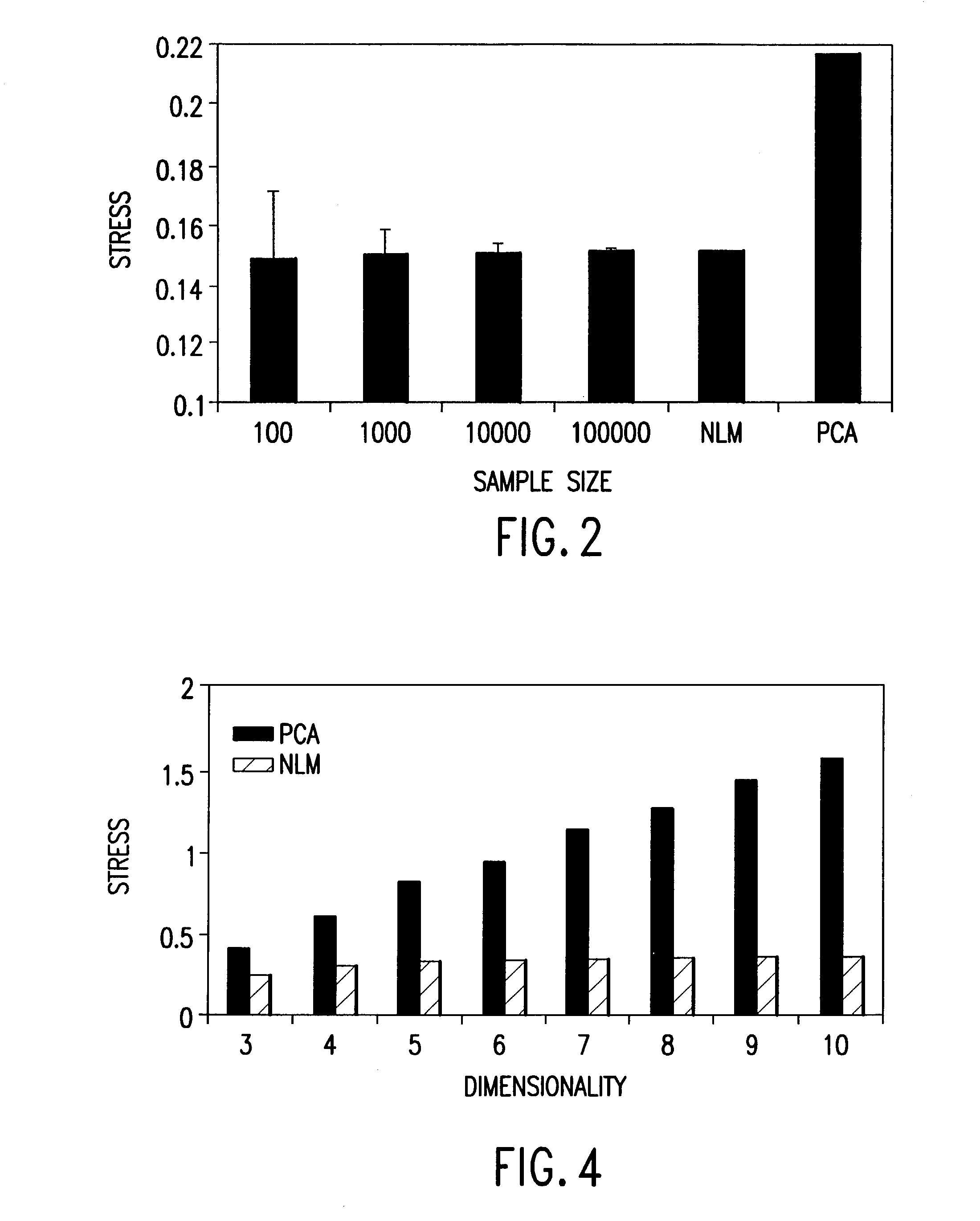
- A method that combines non-linear mapping techniques with feed-forward neural networks to scale multi-dimensional data sets by selecting a sample of points, determining non-linear functions, and using these functions to map additional points, allowing for efficient processing of large data sets.


Methods for mapping data into lower dimensions
PatentActiveUS20140337258A1
Innovation
- The method involves generating supervised and unsupervised hypersurfaces in high-dimensional feature spaces, projecting data onto lower-dimensional subspaces, and using these subspaces for data discovery, visualization, and database access, allowing for the incorporation of user domain expertise and hypothetical patterns into data models.




Hardware Acceleration for Hyperdimensional Computing
Hardware acceleration has emerged as a critical enabler for hyperdimensional computing, addressing the computational bottlenecks inherent in processing high-dimensional vector operations. Traditional von Neumann architectures struggle with the massive parallelism required for hyperdimensional operations, creating a compelling case for specialized hardware solutions that can efficiently handle the unique computational patterns of HD computing.
Field-Programmable Gate Arrays (FPGAs) represent the most mature hardware acceleration approach for hyperdimensional computing. These reconfigurable platforms excel at implementing custom arithmetic units optimized for binary and bipolar hypervector operations. FPGA implementations typically achieve 10-100x speedup over CPU implementations while maintaining energy efficiency. The reconfigurable nature allows for algorithm-specific optimizations and supports various encoding schemes without hardware redesign.
Graphics Processing Units (GPUs) offer another viable acceleration path, leveraging their inherent parallel architecture for hypervector computations. Modern GPUs can process thousands of hyperdimensional operations simultaneously, making them particularly effective for training phases that require extensive similarity computations. However, GPU acceleration faces challenges with memory bandwidth limitations and the overhead of data transfer between host and device memory.
Application-Specific Integrated Circuits (ASICs) represent the frontier of hardware acceleration for hyperdimensional computing. Several research initiatives have demonstrated ASIC designs that integrate memory and computation units specifically for HD operations. These designs achieve remarkable energy efficiency, often consuming orders of magnitude less power than general-purpose processors while delivering superior performance for hyperdimensional workloads.
Emerging neuromorphic computing platforms present intriguing opportunities for hyperdimensional acceleration. The inherent compatibility between hyperdimensional computing's distributed representations and neuromorphic architectures' sparse, event-driven processing creates synergistic effects. Early prototypes demonstrate promising results in terms of both energy efficiency and real-time processing capabilities.
The development of specialized memory architectures, including processing-in-memory and near-data computing solutions, addresses the memory wall problem that traditionally limits hyperdimensional computing performance. These approaches minimize data movement costs and enable more efficient utilization of available memory bandwidth, crucial for large-scale hyperdimensional applications.
Field-Programmable Gate Arrays (FPGAs) represent the most mature hardware acceleration approach for hyperdimensional computing. These reconfigurable platforms excel at implementing custom arithmetic units optimized for binary and bipolar hypervector operations. FPGA implementations typically achieve 10-100x speedup over CPU implementations while maintaining energy efficiency. The reconfigurable nature allows for algorithm-specific optimizations and supports various encoding schemes without hardware redesign.
Graphics Processing Units (GPUs) offer another viable acceleration path, leveraging their inherent parallel architecture for hypervector computations. Modern GPUs can process thousands of hyperdimensional operations simultaneously, making them particularly effective for training phases that require extensive similarity computations. However, GPU acceleration faces challenges with memory bandwidth limitations and the overhead of data transfer between host and device memory.
Application-Specific Integrated Circuits (ASICs) represent the frontier of hardware acceleration for hyperdimensional computing. Several research initiatives have demonstrated ASIC designs that integrate memory and computation units specifically for HD operations. These designs achieve remarkable energy efficiency, often consuming orders of magnitude less power than general-purpose processors while delivering superior performance for hyperdimensional workloads.
Emerging neuromorphic computing platforms present intriguing opportunities for hyperdimensional acceleration. The inherent compatibility between hyperdimensional computing's distributed representations and neuromorphic architectures' sparse, event-driven processing creates synergistic effects. Early prototypes demonstrate promising results in terms of both energy efficiency and real-time processing capabilities.
The development of specialized memory architectures, including processing-in-memory and near-data computing solutions, addresses the memory wall problem that traditionally limits hyperdimensional computing performance. These approaches minimize data movement costs and enable more efficient utilization of available memory bandwidth, crucial for large-scale hyperdimensional applications.
Energy Efficiency in Large-Scale HD Model Deployment
Energy efficiency represents a critical bottleneck in the widespread deployment of large-scale hyperdimensional computing systems. As HD models scale to handle increasingly complex multi-dimensional data mappings, their computational demands grow exponentially, creating substantial energy consumption challenges that threaten both operational sustainability and economic viability.
The primary energy consumption drivers in HD model deployment stem from the massive parallel processing requirements during vector encoding and similarity computations. Traditional implementations often rely on dense matrix operations that activate entire processing units even for sparse data patterns, leading to significant energy waste. Memory bandwidth limitations further exacerbate this issue, as frequent data transfers between processing cores and memory hierarchies consume substantial power resources.
Current energy optimization approaches focus on several key strategies. Hardware-specific optimizations leverage specialized neuromorphic chips and in-memory computing architectures that reduce data movement overhead. Software-level techniques include adaptive precision scaling, where computational accuracy is dynamically adjusted based on task requirements, and selective activation patterns that minimize unnecessary vector operations during training and inference phases.
Emerging solutions demonstrate promising energy reduction potential through novel architectural designs. Approximate computing techniques allow controlled precision trade-offs, reducing computational complexity while maintaining acceptable model performance. Distributed processing frameworks enable workload partitioning across heterogeneous computing resources, optimizing energy consumption based on specific hardware capabilities and power profiles.
Advanced power management strategies incorporate dynamic voltage and frequency scaling synchronized with HD model computational phases. These approaches recognize that different stages of hyperdimensional processing exhibit varying computational intensities, enabling targeted energy optimization without compromising model accuracy or training convergence rates.
The integration of quantum-inspired computing elements and photonic processing units presents revolutionary opportunities for energy-efficient HD model deployment. These technologies promise orders-of-magnitude improvements in energy efficiency while maintaining the parallel processing capabilities essential for large-scale hyperdimensional computations, potentially transforming the economic feasibility of enterprise-scale HD model implementations.
The primary energy consumption drivers in HD model deployment stem from the massive parallel processing requirements during vector encoding and similarity computations. Traditional implementations often rely on dense matrix operations that activate entire processing units even for sparse data patterns, leading to significant energy waste. Memory bandwidth limitations further exacerbate this issue, as frequent data transfers between processing cores and memory hierarchies consume substantial power resources.
Current energy optimization approaches focus on several key strategies. Hardware-specific optimizations leverage specialized neuromorphic chips and in-memory computing architectures that reduce data movement overhead. Software-level techniques include adaptive precision scaling, where computational accuracy is dynamically adjusted based on task requirements, and selective activation patterns that minimize unnecessary vector operations during training and inference phases.
Emerging solutions demonstrate promising energy reduction potential through novel architectural designs. Approximate computing techniques allow controlled precision trade-offs, reducing computational complexity while maintaining acceptable model performance. Distributed processing frameworks enable workload partitioning across heterogeneous computing resources, optimizing energy consumption based on specific hardware capabilities and power profiles.
Advanced power management strategies incorporate dynamic voltage and frequency scaling synchronized with HD model computational phases. These approaches recognize that different stages of hyperdimensional processing exhibit varying computational intensities, enabling targeted energy optimization without compromising model accuracy or training convergence rates.
The integration of quantum-inspired computing elements and photonic processing units presents revolutionary opportunities for energy-efficient HD model deployment. These technologies promise orders-of-magnitude improvements in energy efficiency while maintaining the parallel processing capabilities essential for large-scale hyperdimensional computations, potentially transforming the economic feasibility of enterprise-scale HD model implementations.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!