

How to Scale Seamless Rate in Distributed Cloud Services
MAR 2, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Distributed Cloud Services Scaling Background and Objectives
Distributed cloud services have emerged as a critical infrastructure paradigm in the modern digital landscape, fundamentally transforming how organizations deploy, manage, and scale their applications across geographically dispersed environments. This architectural approach extends traditional cloud computing beyond centralized data centers, distributing computing resources closer to end users and data sources to minimize latency and improve performance.
The evolution of distributed cloud services stems from the increasing demand for real-time applications, edge computing requirements, and the need to comply with data sovereignty regulations. Organizations are migrating from monolithic architectures to microservices-based distributed systems that can dynamically scale across multiple cloud regions and edge locations. This transition has introduced complex challenges in maintaining seamless performance scaling while ensuring consistent user experiences.
Seamless rate scaling represents a fundamental capability that determines the success of distributed cloud deployments. It encompasses the system's ability to automatically adjust resource allocation, request routing, and service capacity in response to varying workload demands without causing service disruptions or performance degradation. The challenge lies in coordinating scaling decisions across distributed nodes while maintaining data consistency and minimizing cross-region communication overhead.
Current market drivers include the exponential growth of IoT devices, real-time analytics requirements, and the proliferation of mobile applications demanding low-latency responses. Organizations are seeking solutions that can handle traffic spikes ranging from 10x to 100x normal loads while maintaining sub-second response times across global user bases.
The primary technical objectives focus on achieving horizontal scalability that can seamlessly distribute workloads across multiple cloud providers and regions. This includes developing intelligent load balancing mechanisms, implementing predictive scaling algorithms, and establishing efficient resource orchestration frameworks. Additionally, the goal encompasses maintaining service quality metrics including 99.99% availability, consistent response times under varying loads, and cost-effective resource utilization.
Advanced objectives target the implementation of autonomous scaling systems that can predict demand patterns, pre-provision resources, and execute scaling operations without human intervention. These systems must integrate machine learning capabilities to optimize scaling decisions based on historical patterns, real-time metrics, and business requirements while ensuring compliance with regulatory constraints across different geographical regions.
The evolution of distributed cloud services stems from the increasing demand for real-time applications, edge computing requirements, and the need to comply with data sovereignty regulations. Organizations are migrating from monolithic architectures to microservices-based distributed systems that can dynamically scale across multiple cloud regions and edge locations. This transition has introduced complex challenges in maintaining seamless performance scaling while ensuring consistent user experiences.
Seamless rate scaling represents a fundamental capability that determines the success of distributed cloud deployments. It encompasses the system's ability to automatically adjust resource allocation, request routing, and service capacity in response to varying workload demands without causing service disruptions or performance degradation. The challenge lies in coordinating scaling decisions across distributed nodes while maintaining data consistency and minimizing cross-region communication overhead.
Current market drivers include the exponential growth of IoT devices, real-time analytics requirements, and the proliferation of mobile applications demanding low-latency responses. Organizations are seeking solutions that can handle traffic spikes ranging from 10x to 100x normal loads while maintaining sub-second response times across global user bases.
The primary technical objectives focus on achieving horizontal scalability that can seamlessly distribute workloads across multiple cloud providers and regions. This includes developing intelligent load balancing mechanisms, implementing predictive scaling algorithms, and establishing efficient resource orchestration frameworks. Additionally, the goal encompasses maintaining service quality metrics including 99.99% availability, consistent response times under varying loads, and cost-effective resource utilization.
Advanced objectives target the implementation of autonomous scaling systems that can predict demand patterns, pre-provision resources, and execute scaling operations without human intervention. These systems must integrate machine learning capabilities to optimize scaling decisions based on historical patterns, real-time metrics, and business requirements while ensuring compliance with regulatory constraints across different geographical regions.
Market Demand for Seamless Cloud Service Scaling
The global cloud services market continues to experience unprecedented growth, driven by digital transformation initiatives across industries and the accelerating shift toward distributed computing architectures. Organizations worldwide are increasingly adopting multi-cloud and hybrid cloud strategies, creating substantial demand for seamless scaling capabilities that can maintain consistent performance across diverse cloud environments.
Enterprise customers represent the primary demand driver, particularly those operating mission-critical applications requiring high availability and dynamic resource allocation. Financial services institutions, e-commerce platforms, streaming media companies, and software-as-a-service providers constitute the most demanding segments, where service interruptions or performance degradation directly impact revenue and customer satisfaction. These organizations require scaling solutions that can handle traffic spikes, seasonal variations, and unexpected load increases without compromising user experience.
The rise of microservices architectures and containerized applications has fundamentally altered scaling requirements. Modern applications consist of numerous interconnected services that must scale independently while maintaining seamless communication and data consistency. This architectural evolution has created demand for sophisticated orchestration capabilities that can coordinate scaling decisions across multiple service components and cloud regions simultaneously.
Geographic distribution of workloads presents another critical demand factor. Organizations serving global customer bases require scaling solutions that can dynamically allocate resources across different regions while maintaining low latency and regulatory compliance. Edge computing adoption further amplifies this need, as applications must seamlessly scale between centralized cloud resources and distributed edge locations based on real-time demand patterns.
Cost optimization pressures significantly influence market demand for seamless scaling solutions. Organizations seek technologies that can automatically scale resources up during peak periods and scale down during low-demand intervals, minimizing unnecessary infrastructure costs while ensuring performance requirements are met. The ability to predict scaling needs and proactively adjust resources has become a key differentiator in vendor selection processes.
Regulatory compliance requirements, particularly in healthcare, finance, and government sectors, create additional demand complexity. Scaling solutions must maintain data sovereignty, security controls, and audit trails across all scaling operations, driving need for specialized compliance-aware scaling technologies that can operate within strict regulatory frameworks while delivering seamless performance.
Enterprise customers represent the primary demand driver, particularly those operating mission-critical applications requiring high availability and dynamic resource allocation. Financial services institutions, e-commerce platforms, streaming media companies, and software-as-a-service providers constitute the most demanding segments, where service interruptions or performance degradation directly impact revenue and customer satisfaction. These organizations require scaling solutions that can handle traffic spikes, seasonal variations, and unexpected load increases without compromising user experience.
The rise of microservices architectures and containerized applications has fundamentally altered scaling requirements. Modern applications consist of numerous interconnected services that must scale independently while maintaining seamless communication and data consistency. This architectural evolution has created demand for sophisticated orchestration capabilities that can coordinate scaling decisions across multiple service components and cloud regions simultaneously.
Geographic distribution of workloads presents another critical demand factor. Organizations serving global customer bases require scaling solutions that can dynamically allocate resources across different regions while maintaining low latency and regulatory compliance. Edge computing adoption further amplifies this need, as applications must seamlessly scale between centralized cloud resources and distributed edge locations based on real-time demand patterns.
Cost optimization pressures significantly influence market demand for seamless scaling solutions. Organizations seek technologies that can automatically scale resources up during peak periods and scale down during low-demand intervals, minimizing unnecessary infrastructure costs while ensuring performance requirements are met. The ability to predict scaling needs and proactively adjust resources has become a key differentiator in vendor selection processes.
Regulatory compliance requirements, particularly in healthcare, finance, and government sectors, create additional demand complexity. Scaling solutions must maintain data sovereignty, security controls, and audit trails across all scaling operations, driving need for specialized compliance-aware scaling technologies that can operate within strict regulatory frameworks while delivering seamless performance.
Current Challenges in Distributed Cloud Scaling
Distributed cloud services face significant architectural complexity when attempting to achieve seamless scaling rates. The heterogeneous nature of distributed environments creates fundamental challenges in maintaining consistent performance across multiple nodes, data centers, and geographic regions. Traditional scaling approaches often struggle with the inherent latency variations, network partitions, and resource heterogeneity that characterize modern distributed systems.
Resource allocation inefficiencies represent a critical bottleneck in achieving optimal scaling rates. Current distributed systems frequently suffer from suboptimal resource utilization due to inadequate load prediction algorithms and reactive scaling mechanisms. The time lag between demand detection and resource provisioning creates performance degradation periods that compromise the seamless scaling experience. Additionally, the granularity of scaling units often mismatches actual workload requirements, leading to either resource waste or performance bottlenecks.
State management and data consistency pose substantial technical hurdles for seamless scaling operations. Distributed cloud services must maintain data coherence across scaling events while minimizing service disruption. The CAP theorem constraints force systems to make trade-offs between consistency, availability, and partition tolerance, often resulting in temporary performance degradation during scaling operations. Stateful services particularly struggle with seamless scaling due to the complexity of migrating or replicating state information across nodes.
Network-related constraints significantly impact scaling seamlessness in distributed environments. Bandwidth limitations, network congestion, and inter-node communication overhead create scaling bottlenecks that are difficult to predict and mitigate. The geographic distribution of cloud resources introduces variable latency patterns that complicate load balancing and request routing decisions during scaling events.
Monitoring and observability limitations hinder effective scaling decision-making processes. Current distributed systems often lack comprehensive real-time visibility into system performance metrics, resource utilization patterns, and user experience indicators. This observability gap results in delayed or inappropriate scaling decisions, preventing truly seamless scaling experiences. The complexity of correlating metrics across distributed components further complicates the development of effective scaling strategies.
Resource allocation inefficiencies represent a critical bottleneck in achieving optimal scaling rates. Current distributed systems frequently suffer from suboptimal resource utilization due to inadequate load prediction algorithms and reactive scaling mechanisms. The time lag between demand detection and resource provisioning creates performance degradation periods that compromise the seamless scaling experience. Additionally, the granularity of scaling units often mismatches actual workload requirements, leading to either resource waste or performance bottlenecks.
State management and data consistency pose substantial technical hurdles for seamless scaling operations. Distributed cloud services must maintain data coherence across scaling events while minimizing service disruption. The CAP theorem constraints force systems to make trade-offs between consistency, availability, and partition tolerance, often resulting in temporary performance degradation during scaling operations. Stateful services particularly struggle with seamless scaling due to the complexity of migrating or replicating state information across nodes.
Network-related constraints significantly impact scaling seamlessness in distributed environments. Bandwidth limitations, network congestion, and inter-node communication overhead create scaling bottlenecks that are difficult to predict and mitigate. The geographic distribution of cloud resources introduces variable latency patterns that complicate load balancing and request routing decisions during scaling events.
Monitoring and observability limitations hinder effective scaling decision-making processes. Current distributed systems often lack comprehensive real-time visibility into system performance metrics, resource utilization patterns, and user experience indicators. This observability gap results in delayed or inappropriate scaling decisions, preventing truly seamless scaling experiences. The complexity of correlating metrics across distributed components further complicates the development of effective scaling strategies.
Current Seamless Scaling Solutions and Approaches
01 Dynamic resource allocation and load balancing across distributed cloud nodes
Systems and methods for dynamically allocating computing resources across multiple distributed cloud service nodes to optimize performance and maintain seamless service delivery. This includes intelligent load balancing mechanisms that distribute workloads based on real-time capacity, network conditions, and geographic proximity to ensure consistent service rates across the distributed infrastructure.- Dynamic resource allocation and load balancing across distributed cloud nodes: Systems and methods for dynamically allocating computing resources across multiple distributed cloud service nodes to optimize performance and maintain seamless service delivery. This includes intelligent load balancing mechanisms that distribute workloads based on real-time capacity, network conditions, and geographic proximity to ensure consistent service rates across the distributed infrastructure.
- Seamless migration and failover mechanisms for continuous service availability: Technologies enabling transparent migration of services and workloads between distributed cloud nodes without service interruption. These mechanisms include automated failover protocols, state synchronization, and session persistence techniques that maintain consistent service rates during node transitions or failures, ensuring uninterrupted user experience across the distributed cloud environment.
- Rate limiting and quality of service management in distributed architectures: Methods for implementing consistent rate limiting policies and quality of service guarantees across distributed cloud services. This includes coordinated throttling mechanisms, bandwidth allocation strategies, and priority-based scheduling that ensure fair resource distribution and maintain predictable service rates regardless of the serving node location.
- Network optimization and latency reduction for distributed cloud communications: Techniques for optimizing network paths and reducing latency in distributed cloud service architectures. This encompasses intelligent routing algorithms, edge computing integration, content delivery optimization, and protocol enhancements that minimize communication overhead and maintain high-speed data transfer rates between distributed service components.
- Monitoring and analytics for distributed service performance optimization: Systems for real-time monitoring, measurement, and analysis of service performance metrics across distributed cloud infrastructure. These solutions provide visibility into service rates, resource utilization, and performance bottlenecks, enabling automated optimization decisions and proactive adjustments to maintain seamless service delivery across all distributed nodes.
02 Seamless migration and failover mechanisms for continuous service availability
Technologies enabling transparent migration of services and data between distributed cloud nodes without service interruption. These mechanisms include automated failover protocols, state synchronization, and session persistence techniques that maintain service continuity and consistent performance rates even during node failures or planned maintenance activities.Expand Specific Solutions03 Rate limiting and quality of service management in distributed environments
Methods for implementing consistent rate limiting policies and quality of service guarantees across geographically distributed cloud infrastructure. This includes coordinated throttling mechanisms, bandwidth allocation strategies, and priority-based scheduling that ensure fair resource distribution and predictable service rates for different user tiers and application types.Expand Specific Solutions04 Edge computing integration for reduced latency and improved service rates
Architectures that integrate edge computing nodes with centralized cloud services to minimize latency and improve overall service delivery rates. These solutions leverage proximity-based processing, intelligent caching, and content distribution strategies to provide faster response times and more consistent performance across distributed geographic locations.Expand Specific Solutions05 Network optimization and traffic management for distributed cloud services
Techniques for optimizing network paths and managing traffic flows between distributed cloud service endpoints. This includes software-defined networking approaches, intelligent routing algorithms, and bandwidth optimization methods that ensure efficient data transfer rates and minimize congestion across the distributed cloud infrastructure.Expand Specific Solutions
Major Players in Distributed Cloud Infrastructure
The distributed cloud services market for seamless rate scaling is experiencing rapid growth, driven by increasing demand for elastic computing resources and real-time performance optimization. The industry is in a mature development stage with significant market expansion, particularly in Asia-Pacific regions. Technology maturity varies considerably among key players. Established cloud giants like Microsoft Technology Licensing LLC, IBM, and VMware LLC demonstrate advanced scaling solutions with proven enterprise deployments. Chinese telecommunications leaders including Huawei Cloud Computing Technology, China Telecom Corp., and China Mobile Communications Group are rapidly advancing their distributed architectures. Emerging players such as Inspur Cloud Information Technology and Beijing ZetYun Technology are developing innovative approaches to seamless scaling. Academic institutions like Southeast University, Zhejiang University, and Central South University contribute foundational research in distributed systems optimization. The competitive landscape shows a mix of mature enterprise solutions and emerging technologies, with increasing focus on AI-driven auto-scaling and edge computing integration for enhanced performance delivery.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft implements Azure Service Fabric for seamless rate scaling in distributed cloud services. Their approach utilizes microservices architecture with automatic partitioning and replica management across cluster nodes. The system employs predictive scaling algorithms that analyze historical traffic patterns and real-time metrics to proactively adjust service instances. Azure's auto-scaling capabilities can scale from hundreds to thousands of instances within minutes, supporting both horizontal and vertical scaling strategies. The platform integrates machine learning models to optimize resource allocation and predict demand spikes, ensuring consistent performance during traffic fluctuations while minimizing resource waste through intelligent load distribution mechanisms.
Strengths: Mature enterprise-grade platform with proven scalability, comprehensive monitoring and analytics tools, seamless integration with existing Microsoft ecosystem. Weaknesses: Higher costs for large-scale deployments, vendor lock-in concerns, complex pricing structure that can be difficult to predict.
Huawei Cloud Computing Technology Co. Ltd.
Technical Solution: Huawei Cloud employs Container Cloud Native (CCN) architecture for seamless rate scaling, utilizing Kubernetes-based orchestration with proprietary Kunpeng processors for enhanced performance. Their solution implements elastic container instances that can scale from zero to thousands of containers within seconds. The system features intelligent traffic prediction using AI algorithms that analyze usage patterns and automatically adjust resource allocation. Huawei's distributed cloud services leverage edge-cloud collaboration, enabling seamless scaling across multiple geographic regions while maintaining low latency. The platform supports both reactive and proactive scaling strategies, with advanced load balancing mechanisms that distribute traffic efficiently across available resources to ensure optimal performance during peak demands.
Strengths: Strong presence in Asian markets, competitive pricing, advanced AI-driven scaling algorithms, excellent edge-cloud integration capabilities. Weaknesses: Limited global market penetration due to geopolitical concerns, smaller ecosystem compared to major competitors, regulatory restrictions in some regions.
Core Technologies for Distributed Service Rate Scaling
Control channel for modems
PatentInactiveUS5910959A
Innovation
- A novel methodology for multiplexing control information with user data using additional channels for V.34 modems, allowing rapid seamless rate changes by transmitting control information through a control channel, enabling immediate data rate adjustments and minimizing buffering delays.




Method for seamless bit rate adaptation for multicarrier DSL
PatentActiveUS7519124B2
Innovation
- The method involves interspersing dummy data with genuine data to form a combined data stream, which is processed through electronic subsystems like FEC encoders and interleavers, mitigating delay variations and impulse noise protection issues by adjusting the bit rate and power levels, while ensuring seamless rate adaptation without service disruption.
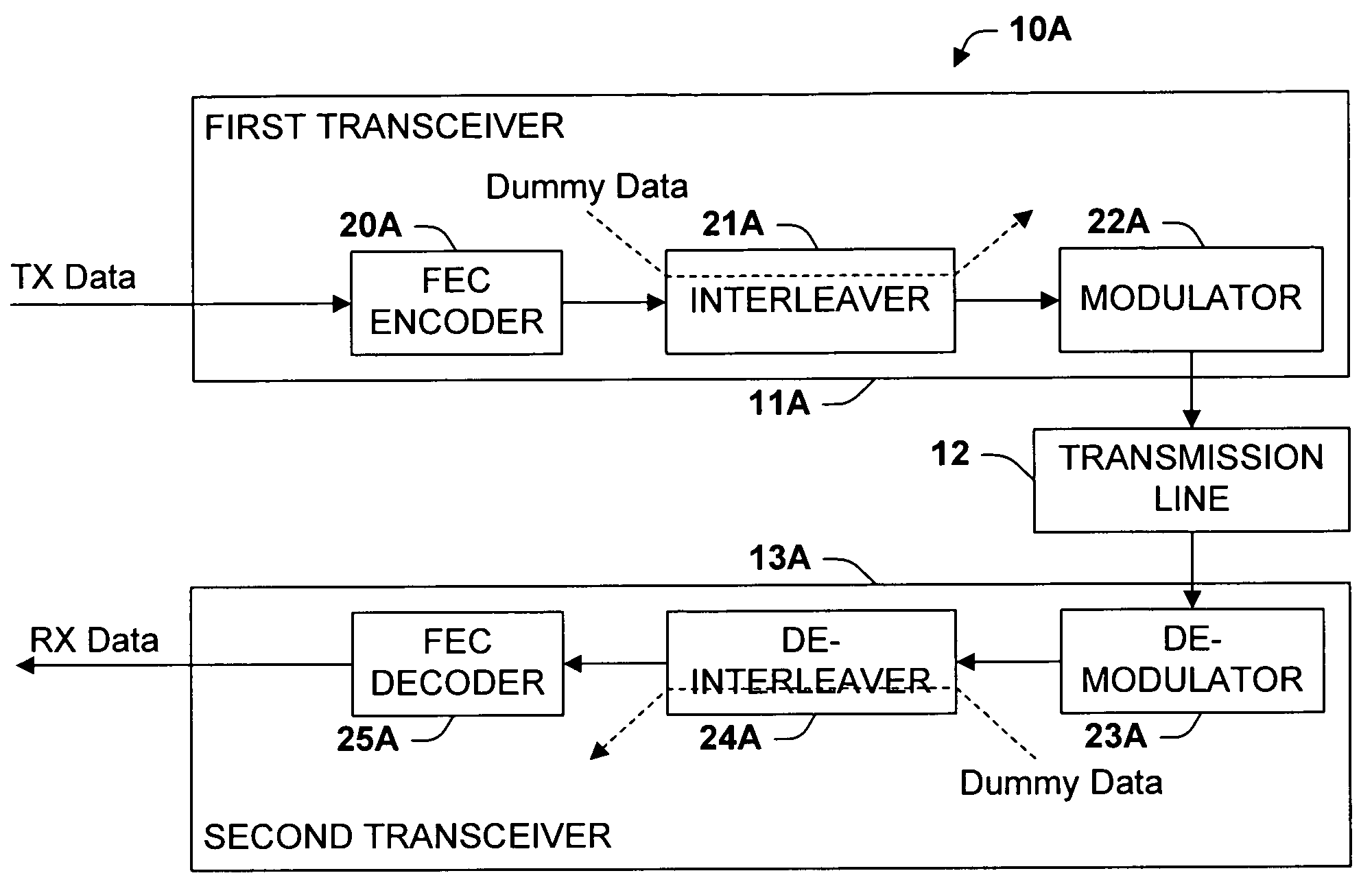
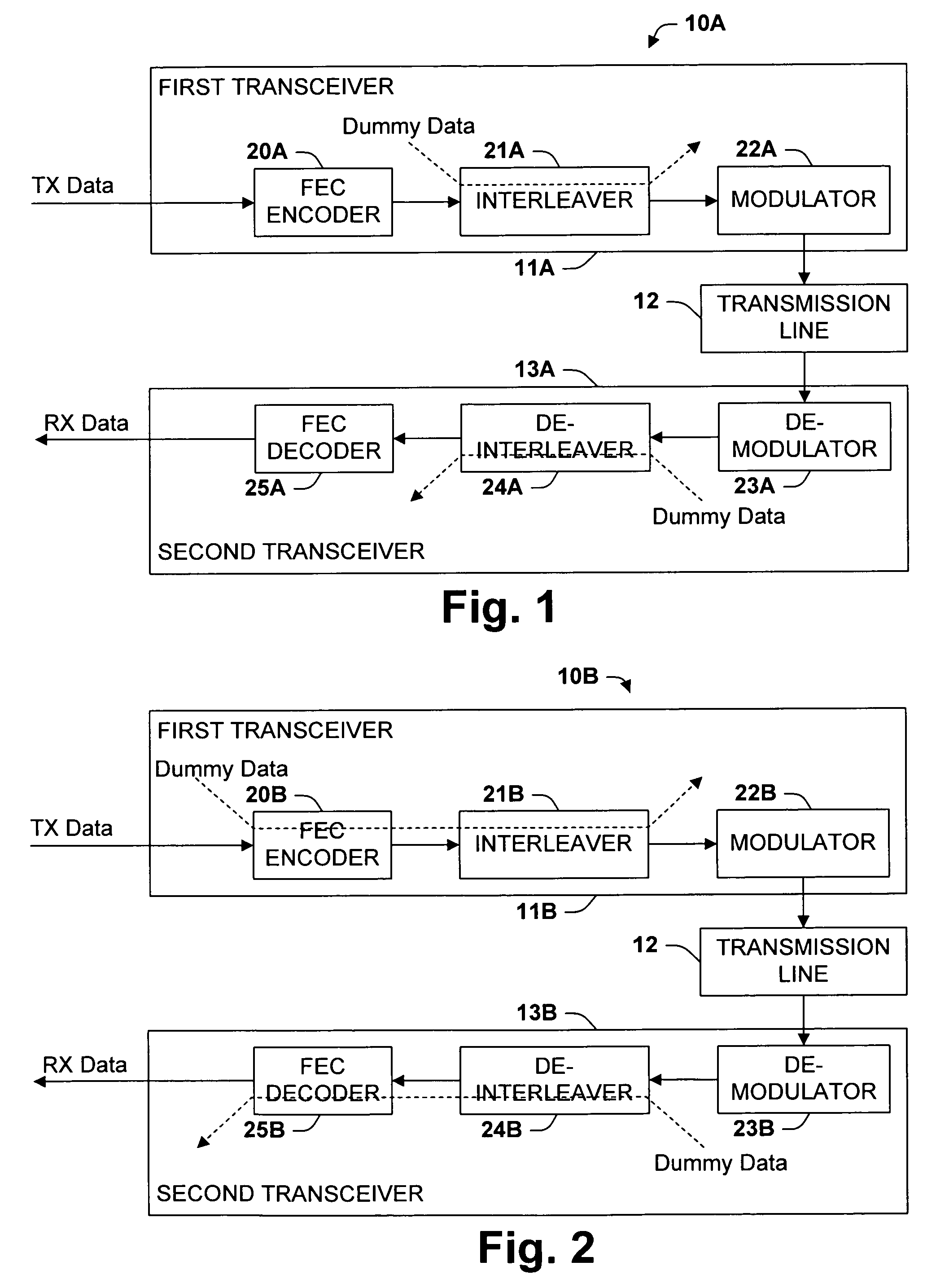
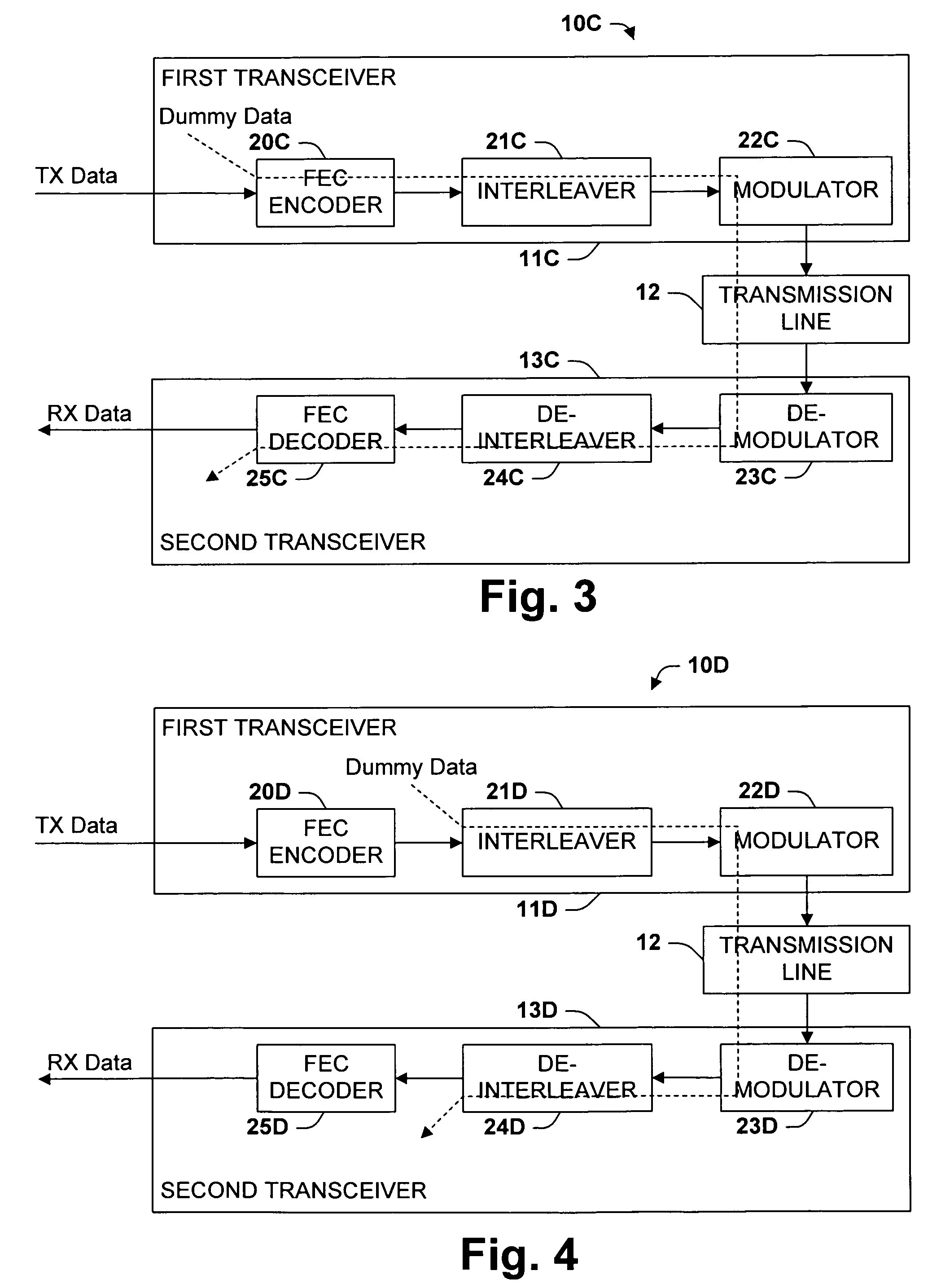
Cloud Service Governance and Compliance Framework
Cloud service governance and compliance frameworks have become critical enablers for achieving seamless rate scaling in distributed environments. These frameworks establish the foundational policies, procedures, and controls that ensure scalable operations remain within regulatory boundaries while maintaining service quality standards. The governance structure must accommodate dynamic resource allocation patterns inherent in seamless scaling while preserving audit trails and compliance evidence.
Regulatory compliance requirements significantly influence scaling architecture decisions in distributed cloud services. Data residency regulations, such as GDPR and various national data protection laws, constrain how services can distribute workloads across geographical regions during scaling events. Financial services regulations like PCI-DSS and SOX impose additional requirements for transaction processing and data handling that must be maintained even during rapid scaling operations.
The governance framework must address multi-tenancy compliance challenges that emerge during scaling operations. When services scale across shared infrastructure, tenant isolation requirements become more complex, requiring sophisticated policy enforcement mechanisms. Service level agreement compliance monitoring becomes particularly challenging when scaling involves dynamic resource reallocation across multiple cloud providers or regions with varying compliance postures.
Risk management frameworks within cloud governance directly impact scaling strategies and implementation approaches. Compliance frameworks must define acceptable risk thresholds for scaling operations, including data exposure risks during migration, service availability risks during scaling transitions, and security risks associated with rapid infrastructure provisioning. These risk parameters often constrain the speed and scope of scaling operations.
Automated compliance monitoring and enforcement mechanisms are essential for supporting seamless scaling operations. Traditional manual compliance processes cannot keep pace with the dynamic nature of distributed scaling, necessitating policy-as-code implementations and real-time compliance validation systems. These automated systems must integrate with scaling orchestration platforms to ensure compliance checks occur before, during, and after scaling events.
The framework must also establish clear accountability models for compliance during scaling operations, defining roles and responsibilities across development, operations, and compliance teams. This includes establishing approval workflows for scaling operations that may impact compliance posture and defining escalation procedures for compliance violations detected during scaling events.
Regulatory compliance requirements significantly influence scaling architecture decisions in distributed cloud services. Data residency regulations, such as GDPR and various national data protection laws, constrain how services can distribute workloads across geographical regions during scaling events. Financial services regulations like PCI-DSS and SOX impose additional requirements for transaction processing and data handling that must be maintained even during rapid scaling operations.
The governance framework must address multi-tenancy compliance challenges that emerge during scaling operations. When services scale across shared infrastructure, tenant isolation requirements become more complex, requiring sophisticated policy enforcement mechanisms. Service level agreement compliance monitoring becomes particularly challenging when scaling involves dynamic resource reallocation across multiple cloud providers or regions with varying compliance postures.
Risk management frameworks within cloud governance directly impact scaling strategies and implementation approaches. Compliance frameworks must define acceptable risk thresholds for scaling operations, including data exposure risks during migration, service availability risks during scaling transitions, and security risks associated with rapid infrastructure provisioning. These risk parameters often constrain the speed and scope of scaling operations.
Automated compliance monitoring and enforcement mechanisms are essential for supporting seamless scaling operations. Traditional manual compliance processes cannot keep pace with the dynamic nature of distributed scaling, necessitating policy-as-code implementations and real-time compliance validation systems. These automated systems must integrate with scaling orchestration platforms to ensure compliance checks occur before, during, and after scaling events.
The framework must also establish clear accountability models for compliance during scaling operations, defining roles and responsibilities across development, operations, and compliance teams. This includes establishing approval workflows for scaling operations that may impact compliance posture and defining escalation procedures for compliance violations detected during scaling events.
Cost Optimization Strategies for Distributed Scaling
Cost optimization in distributed cloud services requires a multi-faceted approach that balances performance requirements with economic efficiency. The primary challenge lies in maintaining seamless scaling capabilities while minimizing operational expenditures across distributed infrastructure components.
Dynamic resource allocation represents the cornerstone of cost-effective scaling strategies. Implementing intelligent auto-scaling mechanisms that respond to real-time demand patterns can significantly reduce unnecessary resource consumption. These systems should incorporate predictive analytics to anticipate traffic spikes and scale resources proactively, avoiding both over-provisioning and performance degradation scenarios.
Container orchestration platforms offer substantial cost advantages through improved resource utilization density. By leveraging containerization technologies, organizations can achieve higher workload consolidation ratios, reducing the overall infrastructure footprint required for distributed services. This approach enables more granular resource allocation and faster scaling responses compared to traditional virtual machine-based deployments.
Geographic distribution strategies play a crucial role in cost optimization by leveraging regional pricing variations and proximity advantages. Deploying services across multiple cloud regions allows organizations to capitalize on lower-cost availability zones while maintaining service quality through edge computing principles. This strategy also reduces data transfer costs by serving users from geographically closer locations.
Hybrid cloud architectures present opportunities for significant cost reductions through workload optimization across public and private infrastructure. Organizations can maintain baseline capacity on cost-effective private infrastructure while utilizing public cloud resources for peak demand periods. This approach requires sophisticated workload management systems capable of seamless resource migration between environments.
Reserved capacity planning and spot instance utilization can achieve substantial cost savings for predictable workloads. By committing to long-term resource reservations for baseline capacity and leveraging spot instances for fault-tolerant batch processing, organizations can reduce compute costs by up to sixty percent while maintaining service reliability standards.
Monitoring and analytics frameworks are essential for continuous cost optimization, providing visibility into resource utilization patterns and identifying optimization opportunities. These systems should track cost per transaction metrics and correlate performance indicators with resource consumption to enable data-driven scaling decisions.
Dynamic resource allocation represents the cornerstone of cost-effective scaling strategies. Implementing intelligent auto-scaling mechanisms that respond to real-time demand patterns can significantly reduce unnecessary resource consumption. These systems should incorporate predictive analytics to anticipate traffic spikes and scale resources proactively, avoiding both over-provisioning and performance degradation scenarios.
Container orchestration platforms offer substantial cost advantages through improved resource utilization density. By leveraging containerization technologies, organizations can achieve higher workload consolidation ratios, reducing the overall infrastructure footprint required for distributed services. This approach enables more granular resource allocation and faster scaling responses compared to traditional virtual machine-based deployments.
Geographic distribution strategies play a crucial role in cost optimization by leveraging regional pricing variations and proximity advantages. Deploying services across multiple cloud regions allows organizations to capitalize on lower-cost availability zones while maintaining service quality through edge computing principles. This strategy also reduces data transfer costs by serving users from geographically closer locations.
Hybrid cloud architectures present opportunities for significant cost reductions through workload optimization across public and private infrastructure. Organizations can maintain baseline capacity on cost-effective private infrastructure while utilizing public cloud resources for peak demand periods. This approach requires sophisticated workload management systems capable of seamless resource migration between environments.
Reserved capacity planning and spot instance utilization can achieve substantial cost savings for predictable workloads. By committing to long-term resource reservations for baseline capacity and leveraging spot instances for fault-tolerant batch processing, organizations can reduce compute costs by up to sixty percent while maintaining service reliability standards.
Monitoring and analytics frameworks are essential for continuous cost optimization, providing visibility into resource utilization patterns and identifying optimization opportunities. These systems should track cost per transaction metrics and correlate performance indicators with resource consumption to enable data-driven scaling decisions.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!