

Improving Resiliency via Array Configuration Adjustments
MAR 5, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Array Resiliency Technology Background and Objectives
Array resiliency technology has emerged as a critical component in modern data storage systems, driven by the exponential growth of digital data and the increasing demand for high-availability computing infrastructure. The evolution of storage arrays began with simple RAID configurations in the 1980s, where redundancy was achieved through basic mirroring and parity schemes. Over the decades, this field has witnessed significant advancements, transitioning from hardware-based RAID controllers to software-defined storage solutions that offer greater flexibility and scalability.
The technological landscape has progressively shifted toward more sophisticated approaches that dynamically adjust array configurations based on real-time system conditions, workload patterns, and failure scenarios. Traditional static configurations have proven inadequate for handling the complexity of modern enterprise environments, where storage systems must maintain optimal performance while ensuring data integrity across diverse operational conditions.
Current market demands emphasize the need for self-healing storage systems capable of automatically reconfiguring themselves to maintain service continuity during component failures or performance degradation. The proliferation of cloud computing, big data analytics, and mission-critical applications has intensified the requirement for storage solutions that can adapt their resilience strategies without human intervention.
The primary objective of improving resiliency via array configuration adjustments centers on developing intelligent algorithms that can dynamically modify storage array parameters to optimize both data protection and system performance. This involves creating adaptive mechanisms that can assess current system health, predict potential failure scenarios, and proactively adjust redundancy levels, data distribution patterns, and recovery strategies.
Key technical goals include minimizing recovery time objectives while maximizing data availability, implementing predictive failure analysis to enable preemptive configuration changes, and developing cost-effective redundancy schemes that balance storage efficiency with protection levels. The technology aims to achieve seamless transitions between different resilience modes without service interruption, ensuring that storage arrays can maintain optimal performance characteristics while adapting to changing operational requirements and emerging threat vectors in real-time scenarios.
The technological landscape has progressively shifted toward more sophisticated approaches that dynamically adjust array configurations based on real-time system conditions, workload patterns, and failure scenarios. Traditional static configurations have proven inadequate for handling the complexity of modern enterprise environments, where storage systems must maintain optimal performance while ensuring data integrity across diverse operational conditions.
Current market demands emphasize the need for self-healing storage systems capable of automatically reconfiguring themselves to maintain service continuity during component failures or performance degradation. The proliferation of cloud computing, big data analytics, and mission-critical applications has intensified the requirement for storage solutions that can adapt their resilience strategies without human intervention.
The primary objective of improving resiliency via array configuration adjustments centers on developing intelligent algorithms that can dynamically modify storage array parameters to optimize both data protection and system performance. This involves creating adaptive mechanisms that can assess current system health, predict potential failure scenarios, and proactively adjust redundancy levels, data distribution patterns, and recovery strategies.
Key technical goals include minimizing recovery time objectives while maximizing data availability, implementing predictive failure analysis to enable preemptive configuration changes, and developing cost-effective redundancy schemes that balance storage efficiency with protection levels. The technology aims to achieve seamless transitions between different resilience modes without service interruption, ensuring that storage arrays can maintain optimal performance characteristics while adapting to changing operational requirements and emerging threat vectors in real-time scenarios.
Market Demand for Resilient Array Systems
The global demand for resilient array systems has experienced substantial growth across multiple sectors, driven by the exponential increase in data generation and the critical need for uninterrupted system availability. Enterprise data centers, cloud service providers, and high-performance computing facilities represent the primary market segments seeking advanced array resilience solutions. These organizations face mounting pressure to maintain continuous operations while managing increasingly complex data workloads.
Financial services, healthcare, telecommunications, and government sectors demonstrate particularly strong demand for resilient array configurations. These industries require systems capable of withstanding hardware failures, network disruptions, and unexpected load variations without compromising data integrity or service availability. The regulatory compliance requirements in these sectors further amplify the need for robust array resilience mechanisms.
The emergence of edge computing and distributed architectures has created new market opportunities for adaptive array configuration technologies. Organizations deploying applications across geographically dispersed locations require array systems that can dynamically adjust their resilience parameters based on local conditions and connectivity constraints. This trend has expanded the addressable market beyond traditional data center environments.
Market research indicates strong growth potential in the storage array segment, particularly for solutions that can automatically optimize resilience configurations based on workload characteristics and failure patterns. Enterprises are increasingly seeking intelligent systems that can balance performance, cost, and reliability through dynamic configuration adjustments rather than static, over-provisioned approaches.
The rise of artificial intelligence and machine learning workloads has introduced new resilience requirements, as these applications often involve long-running computations that cannot tolerate interruptions. This has created demand for array systems capable of predictive failure detection and proactive configuration adjustments to prevent service disruptions.
Small and medium enterprises represent an emerging market segment, as cloud-based resilient array services become more accessible and cost-effective. These organizations require simplified resilience solutions that can provide enterprise-grade reliability without the complexity of traditional high-availability systems.
The market trend toward sustainability and energy efficiency has also influenced demand patterns, with organizations seeking resilient array solutions that minimize power consumption and hardware redundancy while maintaining required availability levels. This has created opportunities for innovative configuration approaches that optimize resilience through software-defined methods rather than hardware over-provisioning.
Financial services, healthcare, telecommunications, and government sectors demonstrate particularly strong demand for resilient array configurations. These industries require systems capable of withstanding hardware failures, network disruptions, and unexpected load variations without compromising data integrity or service availability. The regulatory compliance requirements in these sectors further amplify the need for robust array resilience mechanisms.
The emergence of edge computing and distributed architectures has created new market opportunities for adaptive array configuration technologies. Organizations deploying applications across geographically dispersed locations require array systems that can dynamically adjust their resilience parameters based on local conditions and connectivity constraints. This trend has expanded the addressable market beyond traditional data center environments.
Market research indicates strong growth potential in the storage array segment, particularly for solutions that can automatically optimize resilience configurations based on workload characteristics and failure patterns. Enterprises are increasingly seeking intelligent systems that can balance performance, cost, and reliability through dynamic configuration adjustments rather than static, over-provisioned approaches.
The rise of artificial intelligence and machine learning workloads has introduced new resilience requirements, as these applications often involve long-running computations that cannot tolerate interruptions. This has created demand for array systems capable of predictive failure detection and proactive configuration adjustments to prevent service disruptions.
Small and medium enterprises represent an emerging market segment, as cloud-based resilient array services become more accessible and cost-effective. These organizations require simplified resilience solutions that can provide enterprise-grade reliability without the complexity of traditional high-availability systems.
The market trend toward sustainability and energy efficiency has also influenced demand patterns, with organizations seeking resilient array solutions that minimize power consumption and hardware redundancy while maintaining required availability levels. This has created opportunities for innovative configuration approaches that optimize resilience through software-defined methods rather than hardware over-provisioning.
Current Array Configuration Challenges and Limitations
Traditional array configurations in storage systems face significant scalability bottlenecks that limit their ability to adapt to changing workload demands. Most legacy RAID implementations rely on static stripe sizes and fixed parity distributions, which cannot dynamically adjust to varying I/O patterns or data access frequencies. This rigidity becomes particularly problematic in modern cloud environments where workloads can shift dramatically within short time periods, leading to suboptimal performance and resource utilization.
Current array management systems struggle with heterogeneous hardware integration, especially when combining different drive types, capacities, and performance characteristics within the same array. The lack of intelligent tiering mechanisms often results in hot spots where high-performance SSDs are underutilized while slower HDDs become bottlenecks. Additionally, most existing solutions cannot effectively balance load distribution across drives with varying specifications, leading to premature wear on certain components and reduced overall system lifespan.
Fault tolerance mechanisms in contemporary array configurations present another critical limitation. Traditional RAID levels offer limited flexibility in adjusting redundancy levels based on data criticality or changing reliability requirements. The inability to implement variable protection schemes within the same array forces organizations to over-provision storage capacity for less critical data while potentially under-protecting mission-critical information. This one-size-fits-all approach significantly impacts both cost efficiency and data protection effectiveness.
Performance optimization remains constrained by inflexible caching strategies and static data placement algorithms. Current array controllers typically employ fixed cache allocation policies that cannot adapt to evolving access patterns or application requirements. The lack of real-time reconfiguration capabilities means that arrays optimized for sequential workloads perform poorly when handling random I/O patterns, and vice versa. This limitation becomes increasingly problematic as organizations deploy diverse applications with conflicting storage requirements on shared infrastructure.
Maintenance and expansion operations continue to pose significant challenges due to the disruptive nature of configuration changes in existing array architectures. Most systems require complete rebuilds or extended downtime when adding capacity, changing RAID levels, or redistributing data across drives. The inability to perform non-disruptive reconfigurations limits operational flexibility and increases the total cost of ownership, particularly in environments requiring high availability and continuous operation.
Current array management systems struggle with heterogeneous hardware integration, especially when combining different drive types, capacities, and performance characteristics within the same array. The lack of intelligent tiering mechanisms often results in hot spots where high-performance SSDs are underutilized while slower HDDs become bottlenecks. Additionally, most existing solutions cannot effectively balance load distribution across drives with varying specifications, leading to premature wear on certain components and reduced overall system lifespan.
Fault tolerance mechanisms in contemporary array configurations present another critical limitation. Traditional RAID levels offer limited flexibility in adjusting redundancy levels based on data criticality or changing reliability requirements. The inability to implement variable protection schemes within the same array forces organizations to over-provision storage capacity for less critical data while potentially under-protecting mission-critical information. This one-size-fits-all approach significantly impacts both cost efficiency and data protection effectiveness.
Performance optimization remains constrained by inflexible caching strategies and static data placement algorithms. Current array controllers typically employ fixed cache allocation policies that cannot adapt to evolving access patterns or application requirements. The lack of real-time reconfiguration capabilities means that arrays optimized for sequential workloads perform poorly when handling random I/O patterns, and vice versa. This limitation becomes increasingly problematic as organizations deploy diverse applications with conflicting storage requirements on shared infrastructure.
Maintenance and expansion operations continue to pose significant challenges due to the disruptive nature of configuration changes in existing array architectures. Most systems require complete rebuilds or extended downtime when adding capacity, changing RAID levels, or redistributing data across drives. The inability to perform non-disruptive reconfigurations limits operational flexibility and increases the total cost of ownership, particularly in environments requiring high availability and continuous operation.
Existing Array Configuration Adjustment Methods
01 RAID configuration and data protection mechanisms
Array configuration resiliency can be enhanced through RAID (Redundant Array of Independent Disks) implementations that provide data redundancy and protection against disk failures. These mechanisms include various RAID levels that distribute data across multiple storage devices, enabling continued operation even when one or more disks fail. The system can automatically rebuild data from parity information or mirrored copies to maintain data integrity and availability.- RAID configuration and data protection mechanisms: Storage systems implement various RAID levels and data protection schemes to ensure array resiliency. These mechanisms include parity-based protection, mirroring, and striping techniques that distribute data across multiple drives. When a drive fails, the system can reconstruct lost data using redundant information stored across the remaining drives. Advanced implementations support hot-swapping of failed drives and automatic rebuilding processes to maintain data integrity and availability.
- Distributed storage architecture with fault tolerance: Modern storage arrays employ distributed architectures where data is replicated across multiple nodes or storage devices. This approach enhances resiliency by eliminating single points of failure. The system maintains multiple copies of data across different physical locations or storage units, enabling continued operation even when individual components fail. Load balancing and automatic failover mechanisms ensure seamless transitions during component failures.
- Dynamic array reconfiguration and self-healing capabilities: Storage systems incorporate intelligent monitoring and self-healing features that detect degraded components and automatically reconfigure the array to maintain optimal performance. These systems can dynamically adjust data placement, initiate background scrubbing operations, and proactively migrate data away from failing drives. The reconfiguration process occurs transparently without service interruption, ensuring continuous data availability.
- Snapshot and backup integration for data recovery: Array resiliency is enhanced through integrated snapshot and backup capabilities that create point-in-time copies of data. These features enable rapid recovery from logical errors, corruption, or accidental deletion. The system maintains multiple generations of snapshots with minimal storage overhead using copy-on-write or redirect-on-write techniques. Recovery operations can restore data to any previous state without affecting ongoing operations.
- Multi-path I/O and redundant controller architecture: Enterprise storage arrays implement redundant data paths and controller architectures to eliminate single points of failure in the I/O subsystem. Multiple independent paths connect hosts to storage devices, with automatic path failover ensuring continuous access during component failures. Redundant controllers operate in active-active or active-passive configurations, providing seamless failover capabilities and maintaining consistent data access throughout failure scenarios.
02 Hot spare and automatic failover systems
Resiliency in storage arrays can be achieved through hot spare disk mechanisms that automatically replace failed drives without manual intervention. These systems monitor the health status of array components and trigger automatic failover processes when failures are detected. The hot spare drives remain on standby and are immediately activated to rebuild the array configuration, minimizing downtime and maintaining data accessibility throughout the recovery process.Expand Specific Solutions03 Distributed data storage and replication
Array resiliency can be improved through distributed storage architectures that replicate data across multiple nodes or storage locations. This approach ensures that data remains accessible even if individual storage components or entire nodes fail. The system maintains multiple copies of data in different physical or logical locations, with synchronization mechanisms to keep replicas consistent and enable seamless failover to alternative data sources.Expand Specific Solutions04 Error detection and correction techniques
Storage array configurations incorporate advanced error detection and correction mechanisms to maintain data integrity and system resilience. These techniques include checksums, error-correcting codes, and parity calculations that identify and repair corrupted data blocks. The system continuously monitors data integrity and can reconstruct damaged information using redundant data stored across the array, preventing data loss and maintaining operational continuity.Expand Specific Solutions05 Dynamic reconfiguration and load balancing
Resilient array configurations support dynamic reconfiguration capabilities that allow the system to adapt to changing conditions and component failures. These systems can automatically redistribute data and workloads across available storage resources to optimize performance and maintain availability. Load balancing algorithms ensure even distribution of I/O operations, while reconfiguration mechanisms enable the array to continue operating with reduced capacity during component failures or maintenance activities.Expand Specific Solutions
Key Players in Array Configuration and Resiliency Solutions
The array configuration adjustment technology for improving resiliency is in a mature development stage, driven by the exponential growth of data storage demands and increasing system reliability requirements. The market demonstrates significant scale with established enterprise storage solutions reaching billions in revenue annually. Technology maturity varies considerably across the competitive landscape, with industry leaders like IBM, Pure Storage, and NetApp advancing sophisticated software-defined storage architectures, while semiconductor companies including Samsung Electronics, Western Digital Technologies, and Advanced Micro Devices focus on hardware-level resilience innovations. Traditional infrastructure providers such as Hewlett Packard Enterprise Development LP and Dell Products LP integrate comprehensive array management solutions, while emerging cloud-native companies like Huawei Cloud Computing Technology and Beijing Kingsoft Cloud Network Technology emphasize distributed resilience mechanisms. The convergence of AI-driven predictive maintenance, real-time configuration optimization, and hybrid cloud architectures indicates a rapidly evolving technological ecosystem where established storage vendors compete alongside semiconductor manufacturers and cloud service providers.
International Business Machines Corp.
Technical Solution: IBM implements advanced RAID array configuration technologies with dynamic array reconstruction capabilities. Their solution features intelligent data placement algorithms that automatically adjust array configurations based on workload patterns and failure predictions. The system utilizes machine learning models to predict potential disk failures and proactively redistributes data across healthy drives. IBM's approach includes hot-spare management, where spare drives are dynamically allocated based on array health metrics. The technology supports multi-tier storage architectures with automatic data migration between different performance tiers. Their FlashSystem arrays incorporate real-time monitoring and adaptive configuration adjustments to maintain optimal performance during component failures. The solution also features advanced error correction codes and distributed parity schemes that enhance data protection while minimizing performance impact during reconstruction operations.
Strengths: Enterprise-grade reliability with proven track record in mission-critical environments, comprehensive AI-driven predictive analytics for failure prevention. Weaknesses: High implementation costs and complexity requiring specialized expertise for deployment and maintenance.
Pure Storage, Inc.
Technical Solution: Pure Storage employs DirectFlash technology with dynamic array optimization that continuously adjusts storage configurations for maximum resiliency. Their Purity operating system features automated data reduction and intelligent data placement across flash modules. The system implements erasure coding with variable protection levels that can be adjusted in real-time based on data criticality and available capacity. Pure Storage's solution includes predictive analytics that monitor array health and automatically trigger configuration changes before failures occur. The technology supports non-disruptive upgrades and maintenance through intelligent workload migration and redundancy management. Their arrays utilize distributed metadata architecture that eliminates single points of failure and enables rapid recovery from component failures. The system also incorporates advanced wear leveling algorithms that extend flash memory lifespan while maintaining consistent performance across all storage elements.
Strengths: All-flash architecture provides superior performance and reliability, simplified management through automation reduces operational overhead. Weaknesses: Limited to flash storage technology, premium pricing compared to hybrid storage solutions.
Core Innovations in Dynamic Array Reconfiguration
Autonomic parity exchange
PatentInactiveUS20050015694A1
Innovation
- The method involves an autonomic parity exchange (APX) that globally couples arrays, allowing local redundancy to be utilized across the system, increasing failure tolerance by selecting donor and recipient arrays based on minimum Hamming distance and performance impact, and rebuilding lost information to maintain system reliability and defer maintenance.
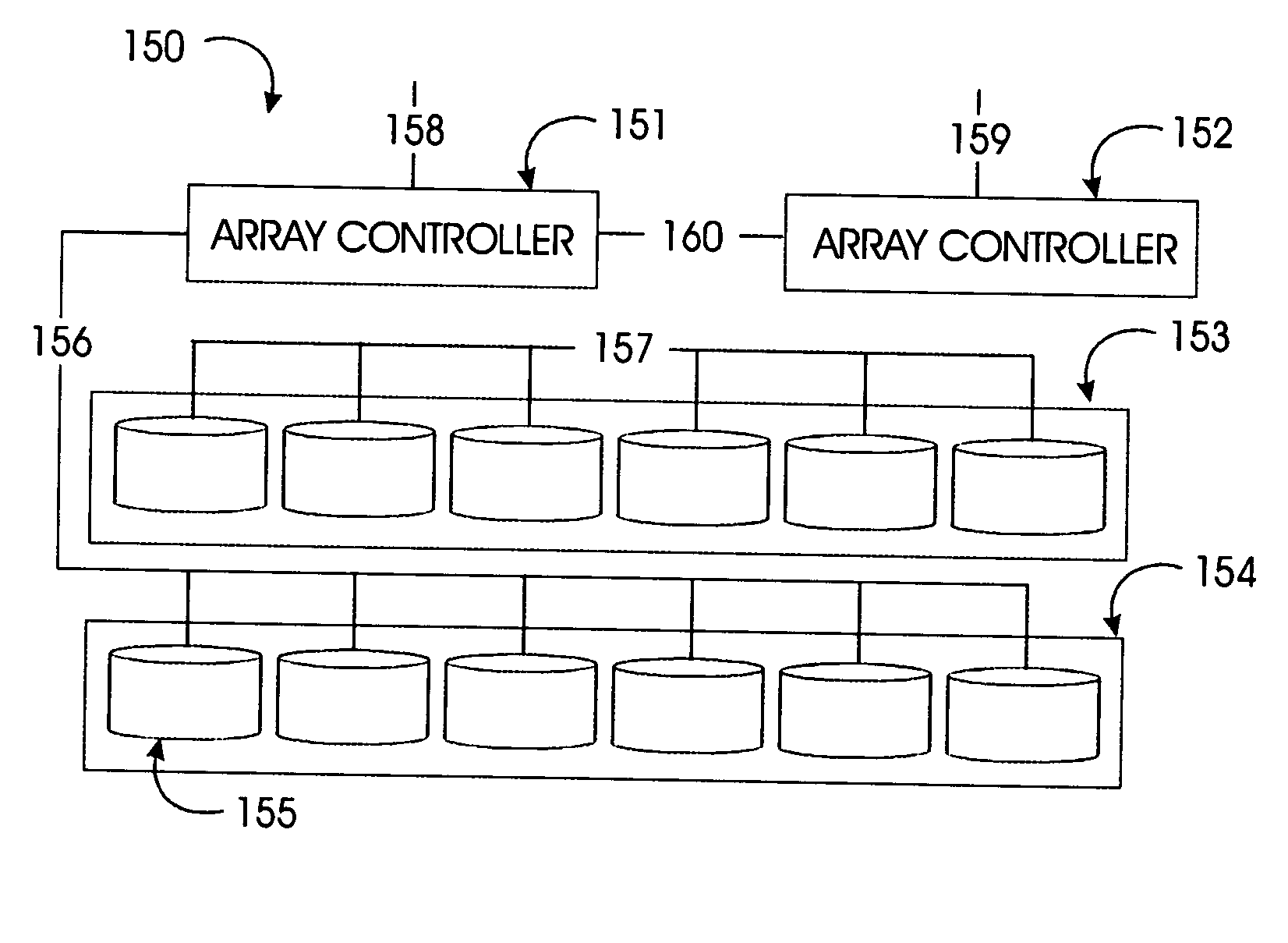
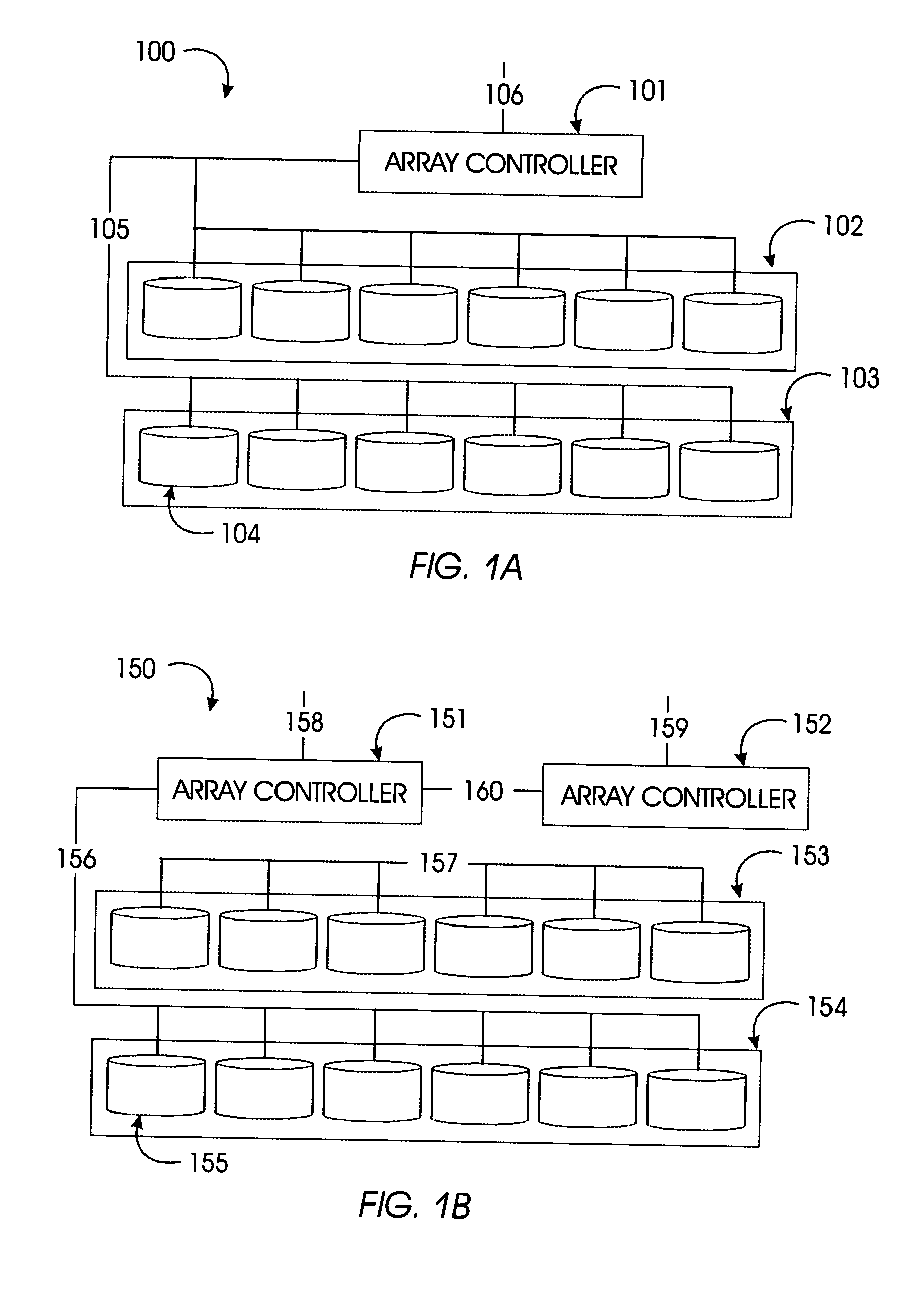
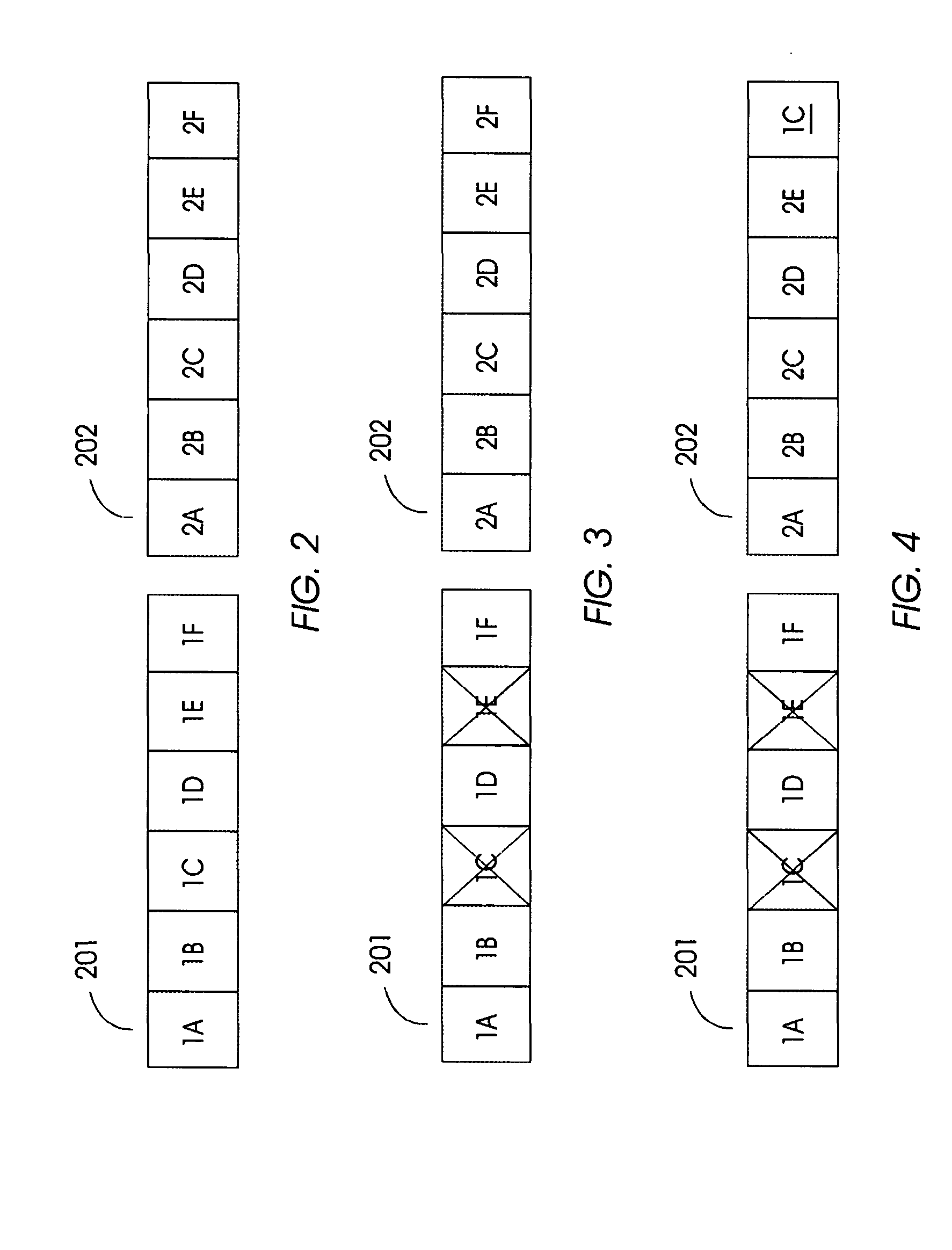

Mapping storage extents into resiliency groups
PatentActiveUS20210109664A1
Innovation
- The technique involves forming an additional resiliency group with one or more new storage drives and reallocating existing drives to satisfy the RAID configuration requirements, while minimizing data movement operations to reallocate data slices across the groups.




Fault Tolerance Standards and Compliance Requirements
The implementation of fault-tolerant array configurations must adhere to a comprehensive framework of industry standards and regulatory compliance requirements. These standards establish the foundation for ensuring system reliability, data integrity, and operational continuity across various deployment environments. Organizations must navigate multiple layers of compliance frameworks that govern different aspects of array resilience and fault tolerance mechanisms.
International standards such as ISO/IEC 27001 for information security management and ISO 22301 for business continuity management provide overarching guidelines for implementing resilient storage systems. These frameworks mandate specific requirements for risk assessment, incident response procedures, and recovery time objectives that directly influence array configuration strategies. Additionally, sector-specific regulations like HIPAA for healthcare, SOX for financial services, and GDPR for data protection impose stringent requirements on data availability and recovery capabilities.
The IEEE 1413 standard specifically addresses software reliability engineering practices, establishing metrics and methodologies for measuring fault tolerance effectiveness in storage arrays. This standard defines acceptable failure rates, mean time between failures (MTBF), and recovery point objectives (RPO) that must be incorporated into array design specifications. Compliance with these metrics requires careful consideration of redundancy levels, hot-spare allocation, and automated failover mechanisms.
Military and aerospace applications must conform to MIL-STD-882 for system safety and DO-178C for software considerations in airborne systems. These standards impose rigorous testing protocols and documentation requirements for fault-tolerant configurations, including formal verification of failure modes and recovery procedures. The standards mandate comprehensive hazard analysis and risk mitigation strategies that influence array topology decisions and component selection criteria.
Financial industry regulations such as Basel III and PCI DSS establish specific requirements for operational risk management and data protection that directly impact array configuration choices. These regulations require demonstrable resilience against various failure scenarios, including natural disasters, cyber attacks, and hardware malfunctions. Compliance necessitates implementation of geographically distributed arrays with real-time synchronization capabilities and automated disaster recovery protocols.
Emerging regulations around cloud computing and edge deployments, including the EU Cybersecurity Act and NIST Cybersecurity Framework, introduce new compliance dimensions for distributed array configurations. These frameworks emphasize the importance of supply chain security, third-party risk management, and continuous monitoring capabilities that must be integrated into fault-tolerant array designs to ensure ongoing compliance and operational resilience.
International standards such as ISO/IEC 27001 for information security management and ISO 22301 for business continuity management provide overarching guidelines for implementing resilient storage systems. These frameworks mandate specific requirements for risk assessment, incident response procedures, and recovery time objectives that directly influence array configuration strategies. Additionally, sector-specific regulations like HIPAA for healthcare, SOX for financial services, and GDPR for data protection impose stringent requirements on data availability and recovery capabilities.
The IEEE 1413 standard specifically addresses software reliability engineering practices, establishing metrics and methodologies for measuring fault tolerance effectiveness in storage arrays. This standard defines acceptable failure rates, mean time between failures (MTBF), and recovery point objectives (RPO) that must be incorporated into array design specifications. Compliance with these metrics requires careful consideration of redundancy levels, hot-spare allocation, and automated failover mechanisms.
Military and aerospace applications must conform to MIL-STD-882 for system safety and DO-178C for software considerations in airborne systems. These standards impose rigorous testing protocols and documentation requirements for fault-tolerant configurations, including formal verification of failure modes and recovery procedures. The standards mandate comprehensive hazard analysis and risk mitigation strategies that influence array topology decisions and component selection criteria.
Financial industry regulations such as Basel III and PCI DSS establish specific requirements for operational risk management and data protection that directly impact array configuration choices. These regulations require demonstrable resilience against various failure scenarios, including natural disasters, cyber attacks, and hardware malfunctions. Compliance necessitates implementation of geographically distributed arrays with real-time synchronization capabilities and automated disaster recovery protocols.
Emerging regulations around cloud computing and edge deployments, including the EU Cybersecurity Act and NIST Cybersecurity Framework, introduce new compliance dimensions for distributed array configurations. These frameworks emphasize the importance of supply chain security, third-party risk management, and continuous monitoring capabilities that must be integrated into fault-tolerant array designs to ensure ongoing compliance and operational resilience.
Performance Impact Assessment of Configuration Changes
Performance impact assessment represents a critical evaluation framework for understanding how array configuration adjustments affect system operations while enhancing resiliency. This assessment methodology encompasses comprehensive monitoring of key performance indicators before, during, and after configuration modifications to ensure that resiliency improvements do not compromise operational efficiency.
The primary performance metrics evaluated include throughput variations, latency changes, and resource utilization patterns. Throughput assessment focuses on measuring data processing rates across different array configurations, particularly examining how redundancy implementations and load distribution strategies affect overall system capacity. Latency evaluation encompasses both read and write operation response times, with special attention to how configuration changes impact real-time processing requirements and user experience.
Resource utilization analysis examines CPU overhead, memory consumption, and network bandwidth requirements associated with various resiliency configurations. This includes evaluating the computational costs of implementing error correction mechanisms, data replication processes, and failover procedures. The assessment also considers storage efficiency metrics, analyzing how different redundancy schemes affect available capacity and data organization strategies.
Dynamic performance evaluation involves stress testing under various operational scenarios, including normal load conditions, peak usage periods, and simulated failure events. This testing reveals how configuration adjustments perform under different operational stresses and helps identify potential bottlenecks or performance degradation points that may emerge during resiliency operations.
The assessment framework incorporates predictive modeling to forecast long-term performance implications of configuration changes. This includes analyzing scalability characteristics, evaluating how performance metrics evolve as system load increases, and determining optimal configuration parameters for different operational requirements. Performance benchmarking against baseline configurations provides quantitative measures of improvement or degradation, enabling data-driven decision making for resiliency enhancement strategies.
Cost-benefit analysis forms an integral component of performance impact assessment, weighing the operational overhead of enhanced resiliency against the potential benefits of improved system reliability and reduced downtime risks.
The primary performance metrics evaluated include throughput variations, latency changes, and resource utilization patterns. Throughput assessment focuses on measuring data processing rates across different array configurations, particularly examining how redundancy implementations and load distribution strategies affect overall system capacity. Latency evaluation encompasses both read and write operation response times, with special attention to how configuration changes impact real-time processing requirements and user experience.
Resource utilization analysis examines CPU overhead, memory consumption, and network bandwidth requirements associated with various resiliency configurations. This includes evaluating the computational costs of implementing error correction mechanisms, data replication processes, and failover procedures. The assessment also considers storage efficiency metrics, analyzing how different redundancy schemes affect available capacity and data organization strategies.
Dynamic performance evaluation involves stress testing under various operational scenarios, including normal load conditions, peak usage periods, and simulated failure events. This testing reveals how configuration adjustments perform under different operational stresses and helps identify potential bottlenecks or performance degradation points that may emerge during resiliency operations.
The assessment framework incorporates predictive modeling to forecast long-term performance implications of configuration changes. This includes analyzing scalability characteristics, evaluating how performance metrics evolve as system load increases, and determining optimal configuration parameters for different operational requirements. Performance benchmarking against baseline configurations provides quantitative measures of improvement or degradation, enabling data-driven decision making for resiliency enhancement strategies.
Cost-benefit analysis forms an integral component of performance impact assessment, weighing the operational overhead of enhanced resiliency against the potential benefits of improved system reliability and reduced downtime risks.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!