

Multilayer Perceptron vs Logistic Regression: Binary Classification
APR 2, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
MLP vs LR Binary Classification Background and Objectives
Binary classification represents one of the fundamental challenges in machine learning, where algorithms must categorize data points into one of two distinct classes. This classification paradigm has evolved significantly since the early days of statistical learning, with logistic regression emerging as a cornerstone technique in the 1940s and multilayer perceptrons gaining prominence during the neural network renaissance of the 1980s and beyond.
The historical development of these approaches reflects broader trends in computational statistics and artificial intelligence. Logistic regression, rooted in statistical theory, provided researchers with an interpretable and mathematically elegant solution for binary classification problems. Its foundation in maximum likelihood estimation and linear decision boundaries made it particularly attractive for applications requiring transparency and statistical rigor.
Multilayer perceptrons emerged from the connectionist movement, representing a paradigm shift toward biologically-inspired computing models. The development of backpropagation algorithms in the 1980s transformed MLPs from theoretical constructs into practical tools capable of learning complex, non-linear decision boundaries. This evolution marked a significant departure from linear models, opening new possibilities for handling intricate data relationships.
The contemporary landscape presents practitioners with a critical decision point between these two approaches. While both techniques address binary classification, they embody fundamentally different philosophies regarding model complexity, interpretability, and computational requirements. This technological divergence has created distinct application domains and use cases for each method.
The primary objective of comparing these methodologies centers on understanding their respective strengths and limitations in modern binary classification scenarios. Key evaluation criteria include predictive accuracy across different data distributions, computational efficiency during training and inference phases, model interpretability requirements, and scalability considerations for large-scale applications.
Furthermore, the comparison aims to establish clear guidelines for practitioners regarding optimal technique selection based on specific problem characteristics. This includes analyzing performance trade-offs between linear and non-linear modeling approaches, examining robustness to different data quality conditions, and evaluating the practical implications of model complexity choices.
The ultimate goal involves developing a comprehensive framework for understanding when each approach delivers superior results, considering factors such as dataset size, feature dimensionality, noise levels, and business requirements for model transparency versus predictive performance.
The historical development of these approaches reflects broader trends in computational statistics and artificial intelligence. Logistic regression, rooted in statistical theory, provided researchers with an interpretable and mathematically elegant solution for binary classification problems. Its foundation in maximum likelihood estimation and linear decision boundaries made it particularly attractive for applications requiring transparency and statistical rigor.
Multilayer perceptrons emerged from the connectionist movement, representing a paradigm shift toward biologically-inspired computing models. The development of backpropagation algorithms in the 1980s transformed MLPs from theoretical constructs into practical tools capable of learning complex, non-linear decision boundaries. This evolution marked a significant departure from linear models, opening new possibilities for handling intricate data relationships.
The contemporary landscape presents practitioners with a critical decision point between these two approaches. While both techniques address binary classification, they embody fundamentally different philosophies regarding model complexity, interpretability, and computational requirements. This technological divergence has created distinct application domains and use cases for each method.
The primary objective of comparing these methodologies centers on understanding their respective strengths and limitations in modern binary classification scenarios. Key evaluation criteria include predictive accuracy across different data distributions, computational efficiency during training and inference phases, model interpretability requirements, and scalability considerations for large-scale applications.
Furthermore, the comparison aims to establish clear guidelines for practitioners regarding optimal technique selection based on specific problem characteristics. This includes analyzing performance trade-offs between linear and non-linear modeling approaches, examining robustness to different data quality conditions, and evaluating the practical implications of model complexity choices.
The ultimate goal involves developing a comprehensive framework for understanding when each approach delivers superior results, considering factors such as dataset size, feature dimensionality, noise levels, and business requirements for model transparency versus predictive performance.
Market Demand for Advanced Binary Classification Solutions
The global binary classification market represents a substantial segment within the broader machine learning and artificial intelligence ecosystem, driven by the exponential growth of data-driven decision-making across industries. Organizations increasingly require sophisticated algorithms to categorize data into two distinct classes, whether for fraud detection, medical diagnosis, customer segmentation, or risk assessment applications.
Financial services sector demonstrates particularly strong demand for advanced binary classification solutions, where institutions need to distinguish between legitimate and fraudulent transactions, assess credit worthiness, and evaluate investment risks. The healthcare industry similarly relies on binary classification for diagnostic imaging, disease prediction, and treatment outcome forecasting, where accuracy improvements can directly impact patient outcomes and operational efficiency.
E-commerce and digital marketing platforms constitute another major demand driver, utilizing binary classification for recommendation systems, spam detection, and customer behavior prediction. These applications require real-time processing capabilities and high accuracy rates to maintain user experience and business performance standards.
The manufacturing sector increasingly adopts binary classification for predictive maintenance, quality control, and supply chain optimization. Industrial IoT deployments generate massive datasets requiring efficient classification algorithms to identify equipment failures, defective products, or operational anomalies before they impact production schedules.
Market demand patterns reveal a clear preference for solutions that balance interpretability with performance. While complex models like multilayer perceptrons offer superior accuracy for intricate datasets, many organizations still value the transparency and regulatory compliance advantages provided by logistic regression approaches, particularly in heavily regulated industries.
Emerging requirements include edge computing compatibility, automated model selection capabilities, and hybrid approaches that combine multiple classification techniques. Organizations seek solutions that can automatically determine optimal algorithms based on dataset characteristics, computational constraints, and accuracy requirements.
The growing emphasis on explainable AI further influences market demand, as stakeholders require clear understanding of classification decisions for regulatory compliance, ethical considerations, and business justification purposes.
Financial services sector demonstrates particularly strong demand for advanced binary classification solutions, where institutions need to distinguish between legitimate and fraudulent transactions, assess credit worthiness, and evaluate investment risks. The healthcare industry similarly relies on binary classification for diagnostic imaging, disease prediction, and treatment outcome forecasting, where accuracy improvements can directly impact patient outcomes and operational efficiency.
E-commerce and digital marketing platforms constitute another major demand driver, utilizing binary classification for recommendation systems, spam detection, and customer behavior prediction. These applications require real-time processing capabilities and high accuracy rates to maintain user experience and business performance standards.
The manufacturing sector increasingly adopts binary classification for predictive maintenance, quality control, and supply chain optimization. Industrial IoT deployments generate massive datasets requiring efficient classification algorithms to identify equipment failures, defective products, or operational anomalies before they impact production schedules.
Market demand patterns reveal a clear preference for solutions that balance interpretability with performance. While complex models like multilayer perceptrons offer superior accuracy for intricate datasets, many organizations still value the transparency and regulatory compliance advantages provided by logistic regression approaches, particularly in heavily regulated industries.
Emerging requirements include edge computing compatibility, automated model selection capabilities, and hybrid approaches that combine multiple classification techniques. Organizations seek solutions that can automatically determine optimal algorithms based on dataset characteristics, computational constraints, and accuracy requirements.
The growing emphasis on explainable AI further influences market demand, as stakeholders require clear understanding of classification decisions for regulatory compliance, ethical considerations, and business justification purposes.
Current State and Challenges in MLP and LR Implementation
The current implementation landscape of Multilayer Perceptrons and Logistic Regression for binary classification presents a complex array of technical achievements alongside persistent challenges. Both algorithms have reached significant maturity levels, yet face distinct implementation hurdles that continue to shape their practical deployment across various domains.
Logistic Regression maintains its position as a foundational algorithm with well-established implementation frameworks across major machine learning libraries including scikit-learn, TensorFlow, and PyTorch. The algorithm benefits from decades of optimization research, resulting in highly efficient solvers such as L-BFGS, Newton-CG, and stochastic gradient descent variants. However, implementation challenges persist in handling high-dimensional sparse data, managing numerical stability during optimization, and addressing convergence issues in ill-conditioned datasets.
Multilayer Perceptrons have experienced remarkable advancement through deep learning frameworks, enabling sophisticated architectures with automated differentiation and GPU acceleration. Modern implementations leverage advanced optimization techniques including Adam, RMSprop, and adaptive learning rate schedules. Despite these improvements, MLPs face significant challenges in hyperparameter tuning complexity, requiring careful selection of network depth, width, activation functions, and regularization parameters.
Computational efficiency remains a critical differentiator between the two approaches. Logistic Regression implementations typically achieve faster training times and lower memory consumption, making them suitable for resource-constrained environments and real-time applications. Conversely, MLP implementations demand substantial computational resources, particularly for large networks, though hardware acceleration through GPUs and specialized chips has partially mitigated these limitations.
Scalability challenges affect both algorithms differently. Logistic Regression implementations struggle with feature engineering requirements and limited representational capacity for complex non-linear relationships. MLP implementations face scalability issues related to gradient vanishing, overfitting in small datasets, and the need for extensive data preprocessing and augmentation strategies.
Current implementation frameworks increasingly focus on automated machine learning capabilities, with tools like AutoML and neural architecture search attempting to address hyperparameter optimization challenges. However, the interpretability gap between Logistic Regression's transparent coefficient-based explanations and MLPs' black-box nature continues to influence implementation choices in regulated industries and applications requiring algorithmic transparency.
The integration of both algorithms within ensemble methods and hybrid architectures represents an emerging implementation trend, combining Logistic Regression's interpretability with MLPs' representational power to address complex binary classification scenarios.
Logistic Regression maintains its position as a foundational algorithm with well-established implementation frameworks across major machine learning libraries including scikit-learn, TensorFlow, and PyTorch. The algorithm benefits from decades of optimization research, resulting in highly efficient solvers such as L-BFGS, Newton-CG, and stochastic gradient descent variants. However, implementation challenges persist in handling high-dimensional sparse data, managing numerical stability during optimization, and addressing convergence issues in ill-conditioned datasets.
Multilayer Perceptrons have experienced remarkable advancement through deep learning frameworks, enabling sophisticated architectures with automated differentiation and GPU acceleration. Modern implementations leverage advanced optimization techniques including Adam, RMSprop, and adaptive learning rate schedules. Despite these improvements, MLPs face significant challenges in hyperparameter tuning complexity, requiring careful selection of network depth, width, activation functions, and regularization parameters.
Computational efficiency remains a critical differentiator between the two approaches. Logistic Regression implementations typically achieve faster training times and lower memory consumption, making them suitable for resource-constrained environments and real-time applications. Conversely, MLP implementations demand substantial computational resources, particularly for large networks, though hardware acceleration through GPUs and specialized chips has partially mitigated these limitations.
Scalability challenges affect both algorithms differently. Logistic Regression implementations struggle with feature engineering requirements and limited representational capacity for complex non-linear relationships. MLP implementations face scalability issues related to gradient vanishing, overfitting in small datasets, and the need for extensive data preprocessing and augmentation strategies.
Current implementation frameworks increasingly focus on automated machine learning capabilities, with tools like AutoML and neural architecture search attempting to address hyperparameter optimization challenges. However, the interpretability gap between Logistic Regression's transparent coefficient-based explanations and MLPs' black-box nature continues to influence implementation choices in regulated industries and applications requiring algorithmic transparency.
The integration of both algorithms within ensemble methods and hybrid architectures represents an emerging implementation trend, combining Logistic Regression's interpretability with MLPs' representational power to address complex binary classification scenarios.
Existing MLP and Logistic Regression Solutions
01 Multilayer Perceptron architecture for binary classification
Multilayer Perceptron (MLP) neural networks utilize multiple hidden layers with non-linear activation functions to learn complex decision boundaries for binary classification tasks. The architecture typically consists of an input layer, one or more hidden layers with neurons, and an output layer that produces binary predictions. MLPs can capture non-linear relationships in data through backpropagation training and gradient descent optimization, making them suitable for complex classification problems where linear separability is not achievable.- Multilayer Perceptron architecture for binary classification: Multilayer Perceptron (MLP) neural networks utilize multiple hidden layers with non-linear activation functions to learn complex decision boundaries for binary classification tasks. The architecture typically consists of an input layer, one or more hidden layers with neurons, and an output layer that produces binary predictions. MLPs can capture non-linear relationships in data through backpropagation training and gradient descent optimization, making them suitable for complex classification problems where linear separability is not achievable.
- Logistic regression implementation for binary classification: Logistic regression is a linear classification method that uses a sigmoid function to map input features to binary outcomes. It estimates the probability of class membership through a linear combination of input variables followed by a logistic transformation. This approach is computationally efficient and provides interpretable coefficients that indicate feature importance. Logistic regression works well for linearly separable data and serves as a baseline model for binary classification tasks.
- Hybrid models combining neural networks and logistic components: Hybrid approaches integrate neural network architectures with logistic regression elements to leverage advantages of both methods. These models may use neural networks for feature extraction and transformation, followed by logistic regression layers for final classification. The combination allows for learning complex feature representations while maintaining interpretability in the decision-making process. Such architectures can balance model complexity with computational efficiency for binary classification applications.
- Performance comparison and model selection criteria: Comparative analysis between multilayer perceptrons and logistic regression involves evaluating metrics such as accuracy, precision, recall, and computational cost. The selection depends on data characteristics including dimensionality, sample size, and feature relationships. Methods for comparing these approaches include cross-validation, ROC curve analysis, and statistical significance testing. Decision frameworks consider trade-offs between model complexity, training time, interpretability, and generalization performance to determine the optimal classifier for specific binary classification scenarios.
- Optimization and training techniques for binary classifiers: Advanced optimization methods improve the training and performance of both multilayer perceptrons and logistic regression models. Techniques include regularization methods to prevent overfitting, adaptive learning rate algorithms, batch normalization, and ensemble approaches. Feature engineering and selection methods enhance model input quality. Hyperparameter tuning through grid search or automated methods optimizes model configuration. These optimization strategies aim to improve convergence speed, classification accuracy, and model robustness across different binary classification tasks.
02 Logistic regression for binary classification
Logistic regression is a statistical method that uses a logistic function to model binary dependent variables. It applies a linear combination of input features followed by a sigmoid activation function to produce probability outputs between 0 and 1. This approach is computationally efficient and provides interpretable results with clear feature weights. Logistic regression works well for linearly separable data and serves as a baseline model for binary classification tasks.Expand Specific Solutions03 Hybrid approaches combining neural networks and logistic methods
Hybrid classification systems integrate neural network architectures with logistic regression components to leverage advantages of both approaches. These methods may use neural networks for feature extraction and transformation, followed by logistic regression for final classification. Such combinations can improve model interpretability while maintaining the ability to capture complex patterns. The hybrid approach balances computational complexity with prediction accuracy.Expand Specific Solutions04 Performance comparison and model selection strategies
Comparative analysis frameworks evaluate multilayer perceptrons against logistic regression based on metrics such as accuracy, precision, recall, and computational efficiency. Model selection strategies consider factors including dataset size, feature dimensionality, training time, and interpretability requirements. Evaluation methods incorporate cross-validation techniques and statistical testing to determine which approach is more suitable for specific binary classification scenarios. Performance benchmarking helps identify optimal algorithms for different application domains.Expand Specific Solutions05 Optimization and regularization techniques for binary classifiers
Advanced optimization methods improve the training and generalization of both multilayer perceptrons and logistic regression models. Regularization techniques such as L1 and L2 penalties prevent overfitting and improve model robustness. Optimization algorithms including stochastic gradient descent, adaptive learning rates, and momentum-based methods enhance convergence speed and classification performance. Feature selection and dimensionality reduction techniques are applied to improve computational efficiency and model accuracy for binary classification tasks.Expand Specific Solutions
Key Players in Machine Learning and Classification Technology
The binary classification landscape comparing Multilayer Perceptrons versus Logistic Regression represents a mature technological domain within the broader machine learning ecosystem. The industry has progressed beyond early-stage development, with widespread commercial adoption across diverse sectors including healthcare, finance, and technology services. Market penetration is substantial, driven by increasing demand for predictive analytics and automated decision-making systems. Technology maturity varies significantly among key players: established technology giants like Google LLC, IBM, and Oracle demonstrate advanced implementation capabilities with sophisticated deep learning frameworks, while companies such as Illumina and LG Electronics focus on domain-specific applications. Academic institutions including Rice University and Technische Universität München contribute foundational research, bridging theoretical advances with practical implementations. The competitive landscape reflects a consolidation phase where traditional statistical methods coexist with neural network approaches, creating opportunities for specialized solutions across different complexity requirements and computational constraints.
International Business Machines Corp.
Technical Solution: IBM Watson provides enterprise-grade binary classification solutions utilizing both traditional logistic regression and advanced MLP architectures. Their AutoAI platform automatically selects between logistic regression and neural network approaches based on dataset characteristics, feature complexity, and performance requirements. IBM's implementation includes automated hyperparameter tuning, feature selection algorithms, and model interpretability tools specifically designed for business applications. Their binary classification models are optimized for structured data processing with built-in bias detection and fairness metrics, making them suitable for regulated industries like finance and healthcare where model transparency is crucial.
Strengths: Enterprise focus, strong interpretability features, regulatory compliance capabilities. Weaknesses: Higher licensing costs, may lack cutting-edge research innovations compared to tech giants.
Honeywell International Technologies Ltd.
Technical Solution: Honeywell applies binary classification techniques using both logistic regression and MLPs in industrial IoT and process control systems. Their implementation focuses on real-time anomaly detection and predictive maintenance applications where binary decisions (normal/abnormal, pass/fail) are critical. They utilize lightweight MLP architectures optimized for edge computing devices with limited computational resources, while employing logistic regression for simpler threshold-based classifications. Honeywell's binary classification systems incorporate domain-specific feature engineering for industrial sensors, time-series data processing, and integration with SCADA systems, enabling automated decision-making in manufacturing and building automation environments.
Strengths: Industrial domain expertise, edge computing optimization, real-time processing capabilities. Weaknesses: Limited to industrial applications, less general-purpose ML capabilities compared to pure software companies.
Core Innovations in Deep Learning vs Statistical Approaches
Rare variant polygenic risk scores
PatentPendingUS20230207052A1
Innovation
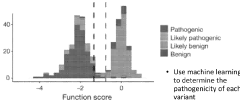
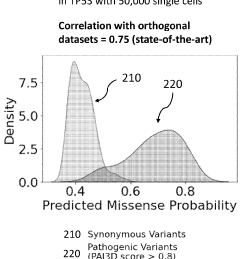
- A novel weighted sum model for rare variant polygenic risk scores is developed, using a convolutional neural network pathogenicity classifier to determine the pathogenicity of variants and aggregating risk across genes based on the presence of rare deleterious variants, with optimization techniques such as grid searches for allele counts and pathogenicity score thresholds to maximize burden test significance.




Systems and methods for evaluation of expression patterns
PatentWO2024130230A2
Innovation
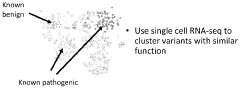
- The method involves generating mutant expression vectors for genetic variants, expressing them in single cells, and using high-throughput sequencing and machine learning to evaluate single-cell RNA sequencing data to determine pathogenicity, enabling the classification of variants as pathogenic, likely pathogenic, or benign.

Data Privacy Regulations Impact on Classification Models
The implementation of data privacy regulations has fundamentally transformed how binary classification models, particularly Multilayer Perceptrons and Logistic Regression, are developed, deployed, and maintained in production environments. The General Data Protection Regulation (GDPR) in Europe, California Consumer Privacy Act (CCPA), and similar frameworks worldwide have established stringent requirements for algorithmic transparency, data minimization, and user consent management that directly affect model architecture decisions.
Privacy-preserving techniques have become essential components of classification pipelines. Differential privacy mechanisms are increasingly integrated into both MLP and Logistic Regression training processes, adding calibrated noise to gradients or model parameters to prevent individual data point identification. This approach particularly impacts MLPs due to their complex parameter spaces, requiring careful balance between privacy guarantees and model performance. Logistic Regression models, with their simpler structure, often demonstrate better resilience to differential privacy noise injection.
Federated learning frameworks have emerged as a critical solution for regulatory compliance, enabling distributed training of classification models without centralizing sensitive data. MLPs benefit significantly from federated approaches, as their capacity for learning complex patterns can be preserved across decentralized datasets. Logistic Regression models in federated settings face challenges with feature standardization and convergence stability across heterogeneous data distributions.
The right to explanation mandated by various regulations has created distinct advantages for Logistic Regression models, whose linear decision boundaries and coefficient interpretability align naturally with explainability requirements. MLPs require additional architectural considerations, such as attention mechanisms or post-hoc explanation methods, to meet regulatory transparency standards.
Data retention and deletion requirements pose operational challenges for both model types. Logistic Regression models can more easily accommodate data removal through incremental updates, while MLPs often require complete retraining to ensure proper data deletion compliance, significantly impacting computational costs and model versioning strategies in regulated environments.
Privacy-preserving techniques have become essential components of classification pipelines. Differential privacy mechanisms are increasingly integrated into both MLP and Logistic Regression training processes, adding calibrated noise to gradients or model parameters to prevent individual data point identification. This approach particularly impacts MLPs due to their complex parameter spaces, requiring careful balance between privacy guarantees and model performance. Logistic Regression models, with their simpler structure, often demonstrate better resilience to differential privacy noise injection.
Federated learning frameworks have emerged as a critical solution for regulatory compliance, enabling distributed training of classification models without centralizing sensitive data. MLPs benefit significantly from federated approaches, as their capacity for learning complex patterns can be preserved across decentralized datasets. Logistic Regression models in federated settings face challenges with feature standardization and convergence stability across heterogeneous data distributions.
The right to explanation mandated by various regulations has created distinct advantages for Logistic Regression models, whose linear decision boundaries and coefficient interpretability align naturally with explainability requirements. MLPs require additional architectural considerations, such as attention mechanisms or post-hoc explanation methods, to meet regulatory transparency standards.
Data retention and deletion requirements pose operational challenges for both model types. Logistic Regression models can more easily accommodate data removal through incremental updates, while MLPs often require complete retraining to ensure proper data deletion compliance, significantly impacting computational costs and model versioning strategies in regulated environments.
Computational Efficiency and Scalability Considerations
Computational efficiency represents a critical differentiator between Multilayer Perceptrons and Logistic Regression in binary classification tasks. Logistic Regression demonstrates superior computational performance during both training and inference phases, requiring only matrix operations for parameter updates through gradient descent. The algorithm's linear nature enables rapid convergence, typically achieving optimal solutions within dozens of iterations.
Multilayer Perceptrons exhibit significantly higher computational complexity due to their multi-layered architecture and non-linear activation functions. Forward propagation requires multiple matrix multiplications across hidden layers, while backpropagation involves computing gradients through the entire network structure. Training time increases exponentially with network depth and width, often requiring hundreds or thousands of iterations to converge.
Memory consumption patterns differ substantially between these approaches. Logistic Regression maintains minimal memory footprint, storing only feature weights and bias terms. MLPs demand considerably more memory for storing weights across multiple layers, intermediate activations during forward passes, and gradient information during backpropagation. GPU memory limitations frequently constrain MLP architecture choices in resource-constrained environments.
Scalability characteristics vary dramatically across different dimensions. For feature scalability, Logistic Regression scales linearly with input dimensionality, making it suitable for high-dimensional sparse datasets common in text classification and genomics. MLPs can theoretically handle high-dimensional inputs but suffer from the curse of dimensionality, requiring careful regularization and architecture design.
Sample size scalability presents contrasting behaviors. Logistic Regression performs well with limited training data, often achieving stable performance with hundreds of samples. MLPs typically require substantially larger datasets to avoid overfitting, with deep networks demanding thousands or millions of training examples for optimal performance.
Distributed computing capabilities favor Logistic Regression for large-scale deployment. Its convex optimization landscape enables efficient parallelization across multiple machines using techniques like parameter servers or federated learning. MLPs face challenges in distributed training due to complex gradient synchronization requirements and non-convex optimization landscapes, though recent advances in distributed deep learning frameworks have improved scalability.
Real-time inference requirements often dictate algorithm selection. Logistic Regression enables microsecond-level predictions suitable for high-frequency trading or real-time recommendation systems. MLPs introduce latency through multiple layer computations, making them less suitable for ultra-low latency applications despite their superior modeling capacity.
Multilayer Perceptrons exhibit significantly higher computational complexity due to their multi-layered architecture and non-linear activation functions. Forward propagation requires multiple matrix multiplications across hidden layers, while backpropagation involves computing gradients through the entire network structure. Training time increases exponentially with network depth and width, often requiring hundreds or thousands of iterations to converge.
Memory consumption patterns differ substantially between these approaches. Logistic Regression maintains minimal memory footprint, storing only feature weights and bias terms. MLPs demand considerably more memory for storing weights across multiple layers, intermediate activations during forward passes, and gradient information during backpropagation. GPU memory limitations frequently constrain MLP architecture choices in resource-constrained environments.
Scalability characteristics vary dramatically across different dimensions. For feature scalability, Logistic Regression scales linearly with input dimensionality, making it suitable for high-dimensional sparse datasets common in text classification and genomics. MLPs can theoretically handle high-dimensional inputs but suffer from the curse of dimensionality, requiring careful regularization and architecture design.
Sample size scalability presents contrasting behaviors. Logistic Regression performs well with limited training data, often achieving stable performance with hundreds of samples. MLPs typically require substantially larger datasets to avoid overfitting, with deep networks demanding thousands or millions of training examples for optimal performance.
Distributed computing capabilities favor Logistic Regression for large-scale deployment. Its convex optimization landscape enables efficient parallelization across multiple machines using techniques like parameter servers or federated learning. MLPs face challenges in distributed training due to complex gradient synchronization requirements and non-convex optimization landscapes, though recent advances in distributed deep learning frameworks have improved scalability.
Real-time inference requirements often dictate algorithm selection. Logistic Regression enables microsecond-level predictions suitable for high-frequency trading or real-time recommendation systems. MLPs introduce latency through multiple layer computations, making them less suitable for ultra-low latency applications despite their superior modeling capacity.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!