Optimizing DSP for Fast Fourier Transform Calculations
FEB 26, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
DSP-FFT Background and Performance Goals
Digital Signal Processing (DSP) has evolved significantly since its inception in the 1960s, transforming from theoretical concepts into practical implementations that power modern communication, audio, and imaging systems. The Fast Fourier Transform, developed by Cooley and Tukey in 1965, revolutionized signal processing by reducing computational complexity from O(N²) to O(N log N), making real-time frequency domain analysis feasible for practical applications.
The evolution of DSP-FFT optimization has progressed through distinct phases, beginning with software implementations on general-purpose processors, advancing to dedicated DSP chips in the 1980s, and culminating in today's specialized hardware accelerators and parallel processing architectures. Modern applications demand increasingly sophisticated FFT processing capabilities, driven by emerging technologies such as 5G communications, high-resolution radar systems, and real-time audio processing.
Contemporary DSP systems face mounting pressure to achieve higher throughput while maintaining energy efficiency. The proliferation of Internet of Things devices and edge computing applications has intensified the need for low-power FFT implementations without compromising computational accuracy. Additionally, the growing complexity of multi-channel systems requires parallel FFT processing capabilities that can handle multiple data streams simultaneously.
Current performance benchmarks indicate that state-of-the-art DSP implementations target sub-microsecond FFT computation times for 1024-point transforms, with power consumption constraints often limiting achievable performance in mobile and embedded applications. The industry standard seeks to achieve at least 1000 MOPS (Million Operations Per Second) per watt for FFT operations while maintaining numerical precision within acceptable bounds.
Future optimization goals focus on achieving real-time processing for increasingly large transform sizes, with 8K and 16K point FFTs becoming standard requirements. The integration of machine learning techniques for adaptive optimization and the development of quantum-inspired algorithms represent emerging frontiers in DSP-FFT advancement, promising unprecedented performance improvements for next-generation signal processing applications.
The evolution of DSP-FFT optimization has progressed through distinct phases, beginning with software implementations on general-purpose processors, advancing to dedicated DSP chips in the 1980s, and culminating in today's specialized hardware accelerators and parallel processing architectures. Modern applications demand increasingly sophisticated FFT processing capabilities, driven by emerging technologies such as 5G communications, high-resolution radar systems, and real-time audio processing.
Contemporary DSP systems face mounting pressure to achieve higher throughput while maintaining energy efficiency. The proliferation of Internet of Things devices and edge computing applications has intensified the need for low-power FFT implementations without compromising computational accuracy. Additionally, the growing complexity of multi-channel systems requires parallel FFT processing capabilities that can handle multiple data streams simultaneously.
Current performance benchmarks indicate that state-of-the-art DSP implementations target sub-microsecond FFT computation times for 1024-point transforms, with power consumption constraints often limiting achievable performance in mobile and embedded applications. The industry standard seeks to achieve at least 1000 MOPS (Million Operations Per Second) per watt for FFT operations while maintaining numerical precision within acceptable bounds.
Future optimization goals focus on achieving real-time processing for increasingly large transform sizes, with 8K and 16K point FFTs becoming standard requirements. The integration of machine learning techniques for adaptive optimization and the development of quantum-inspired algorithms represent emerging frontiers in DSP-FFT advancement, promising unprecedented performance improvements for next-generation signal processing applications.
Market Demand for High-Speed FFT Processing
The global demand for high-speed FFT processing has experienced unprecedented growth across multiple industries, driven by the exponential increase in data-intensive applications and real-time processing requirements. Telecommunications infrastructure represents one of the largest market segments, where 5G networks and beyond require sophisticated signal processing capabilities for beamforming, channel estimation, and OFDM modulation schemes. The deployment of massive MIMO systems and millimeter-wave communications has intensified the need for optimized DSP solutions capable of handling complex FFT computations with minimal latency.
Digital signal processing applications in radar and defense systems constitute another significant market driver. Modern phased array radars, synthetic aperture radar systems, and electronic warfare platforms demand real-time spectral analysis capabilities that can process vast amounts of data while maintaining strict timing constraints. The increasing complexity of threat detection algorithms and the need for higher resolution imaging have pushed the boundaries of traditional FFT processing capabilities.
The audio and multimedia processing industry has witnessed substantial growth in demand for high-performance FFT implementations. Professional audio equipment, noise cancellation systems, and immersive audio technologies require sophisticated frequency domain processing. The rise of spatial audio, virtual reality applications, and high-resolution audio formats has created new performance benchmarks for FFT processing efficiency.
Medical imaging and diagnostic equipment represent an emerging high-growth segment where FFT optimization directly impacts patient care quality. MRI systems, ultrasound imaging, and digital X-ray processing rely heavily on frequency domain transformations for image reconstruction and enhancement. The trend toward portable diagnostic devices and real-time imaging applications has intensified the demand for power-efficient, high-speed FFT processing solutions.
Industrial automation and IoT applications have created new market opportunities for optimized FFT processing. Vibration analysis, predictive maintenance systems, and condition monitoring equipment require continuous spectral analysis capabilities. The integration of edge computing with industrial sensors has driven demand for compact, energy-efficient DSP solutions that can perform complex FFT calculations locally without relying on cloud connectivity.
The automotive industry's transition toward autonomous vehicles has generated substantial demand for real-time signal processing capabilities. Advanced driver assistance systems, radar-based collision avoidance, and sensor fusion algorithms require high-throughput FFT processing for environmental perception and object detection. The stringent safety requirements and real-time constraints in automotive applications have established new performance standards for DSP optimization.
Market analysts project continued expansion in FFT processing demand, particularly in emerging applications such as quantum computing simulation, cryptocurrency mining acceleration, and advanced scientific computing. The convergence of artificial intelligence with traditional signal processing has created hybrid workloads that benefit significantly from optimized FFT implementations, further expanding the addressable market for high-performance DSP solutions.
Digital signal processing applications in radar and defense systems constitute another significant market driver. Modern phased array radars, synthetic aperture radar systems, and electronic warfare platforms demand real-time spectral analysis capabilities that can process vast amounts of data while maintaining strict timing constraints. The increasing complexity of threat detection algorithms and the need for higher resolution imaging have pushed the boundaries of traditional FFT processing capabilities.
The audio and multimedia processing industry has witnessed substantial growth in demand for high-performance FFT implementations. Professional audio equipment, noise cancellation systems, and immersive audio technologies require sophisticated frequency domain processing. The rise of spatial audio, virtual reality applications, and high-resolution audio formats has created new performance benchmarks for FFT processing efficiency.
Medical imaging and diagnostic equipment represent an emerging high-growth segment where FFT optimization directly impacts patient care quality. MRI systems, ultrasound imaging, and digital X-ray processing rely heavily on frequency domain transformations for image reconstruction and enhancement. The trend toward portable diagnostic devices and real-time imaging applications has intensified the demand for power-efficient, high-speed FFT processing solutions.
Industrial automation and IoT applications have created new market opportunities for optimized FFT processing. Vibration analysis, predictive maintenance systems, and condition monitoring equipment require continuous spectral analysis capabilities. The integration of edge computing with industrial sensors has driven demand for compact, energy-efficient DSP solutions that can perform complex FFT calculations locally without relying on cloud connectivity.
The automotive industry's transition toward autonomous vehicles has generated substantial demand for real-time signal processing capabilities. Advanced driver assistance systems, radar-based collision avoidance, and sensor fusion algorithms require high-throughput FFT processing for environmental perception and object detection. The stringent safety requirements and real-time constraints in automotive applications have established new performance standards for DSP optimization.
Market analysts project continued expansion in FFT processing demand, particularly in emerging applications such as quantum computing simulation, cryptocurrency mining acceleration, and advanced scientific computing. The convergence of artificial intelligence with traditional signal processing has created hybrid workloads that benefit significantly from optimized FFT implementations, further expanding the addressable market for high-performance DSP solutions.
Current DSP-FFT Implementation Challenges
Current DSP implementations for Fast Fourier Transform calculations face significant computational bottlenecks that limit their effectiveness in real-time applications. The primary challenge stems from the inherent complexity of FFT algorithms, which require intensive multiply-accumulate operations and complex memory access patterns. Traditional DSP architectures struggle with the bit-reversed addressing schemes and butterfly computations that are fundamental to efficient FFT processing.
Memory bandwidth constraints represent another critical limitation in contemporary DSP-FFT implementations. The frequent data shuffling required between FFT stages creates substantial overhead, particularly when dealing with large transform sizes. Cache misses and memory latency issues become increasingly problematic as FFT lengths exceed the available on-chip memory capacity, forcing processors to rely on slower external memory systems.
Precision and numerical stability concerns pose additional challenges for DSP-based FFT calculations. Fixed-point arithmetic implementations, while computationally efficient, suffer from quantization errors and potential overflow conditions during intermediate calculations. The accumulation of rounding errors across multiple FFT stages can significantly degrade signal quality, particularly in applications requiring high dynamic range or extended processing chains.
Power consumption optimization remains a persistent challenge in mobile and embedded DSP applications. The computational intensity of FFT operations, combined with frequent memory accesses, results in substantial energy consumption that limits battery life in portable devices. Balancing processing speed with power efficiency requires careful consideration of clock frequencies, voltage scaling, and architectural trade-offs.
Scalability issues emerge when attempting to implement variable-length FFTs or support multiple concurrent FFT operations. Many existing DSP architectures are optimized for specific transform sizes, making them inefficient for applications requiring flexible FFT lengths. The lack of dynamic reconfiguration capabilities forces developers to implement multiple specialized processing paths, increasing both hardware complexity and software overhead.
Parallel processing coordination presents additional complexity in multi-core DSP systems. Efficiently distributing FFT computations across multiple processing elements while maintaining data coherency and minimizing inter-processor communication overhead requires sophisticated scheduling algorithms and careful memory management strategies that current implementations often handle suboptimally.
Memory bandwidth constraints represent another critical limitation in contemporary DSP-FFT implementations. The frequent data shuffling required between FFT stages creates substantial overhead, particularly when dealing with large transform sizes. Cache misses and memory latency issues become increasingly problematic as FFT lengths exceed the available on-chip memory capacity, forcing processors to rely on slower external memory systems.
Precision and numerical stability concerns pose additional challenges for DSP-based FFT calculations. Fixed-point arithmetic implementations, while computationally efficient, suffer from quantization errors and potential overflow conditions during intermediate calculations. The accumulation of rounding errors across multiple FFT stages can significantly degrade signal quality, particularly in applications requiring high dynamic range or extended processing chains.
Power consumption optimization remains a persistent challenge in mobile and embedded DSP applications. The computational intensity of FFT operations, combined with frequent memory accesses, results in substantial energy consumption that limits battery life in portable devices. Balancing processing speed with power efficiency requires careful consideration of clock frequencies, voltage scaling, and architectural trade-offs.
Scalability issues emerge when attempting to implement variable-length FFTs or support multiple concurrent FFT operations. Many existing DSP architectures are optimized for specific transform sizes, making them inefficient for applications requiring flexible FFT lengths. The lack of dynamic reconfiguration capabilities forces developers to implement multiple specialized processing paths, increasing both hardware complexity and software overhead.
Parallel processing coordination presents additional complexity in multi-core DSP systems. Efficiently distributing FFT computations across multiple processing elements while maintaining data coherency and minimizing inter-processor communication overhead requires sophisticated scheduling algorithms and careful memory management strategies that current implementations often handle suboptimally.
Existing DSP-FFT Optimization Solutions
01 Hardware architecture optimization for FFT computation
Digital signal processors can be optimized through specialized hardware architectures designed specifically for Fast Fourier Transform calculations. These architectures include dedicated butterfly computation units, parallel processing elements, and optimized memory access patterns that reduce computational complexity. The hardware implementations focus on minimizing clock cycles and power consumption while maximizing throughput for FFT operations of various sizes.- Hardware architecture optimization for FFT computation: Digital signal processors can be optimized through specialized hardware architectures designed specifically for Fast Fourier Transform calculations. These architectures include dedicated butterfly computation units, parallel processing elements, and optimized memory access patterns that reduce computational complexity. The hardware implementations focus on minimizing clock cycles and power consumption while maximizing throughput for FFT operations of various sizes.
- Pipeline and parallel processing techniques for FFT: Advanced pipeline architectures enable efficient FFT computation by breaking down the transform into multiple stages that can be processed simultaneously. Parallel processing methods distribute FFT calculations across multiple processing units, allowing for higher data throughput and reduced latency. These techniques include multi-core implementations and SIMD operations that exploit data-level parallelism inherent in FFT algorithms.
- Memory management and data addressing schemes: Efficient memory organization is critical for FFT performance in DSP systems. Specialized addressing schemes enable conflict-free memory access during butterfly operations, while optimized buffer management reduces memory bandwidth requirements. Techniques include bit-reversal addressing, bank-switching methods, and cache optimization strategies that minimize data movement overhead during transform computation.
- Algorithm optimization and computational complexity reduction: Various algorithmic improvements reduce the computational burden of FFT calculations through mathematical optimizations. These include radix-based decomposition methods, pruning techniques for sparse data, and hybrid algorithms that combine different FFT approaches. The optimizations focus on reducing multiplication operations, exploiting symmetry properties, and adapting the algorithm based on input data characteristics.
- Precision control and numerical accuracy enhancement: Managing numerical precision in FFT computations involves techniques to minimize quantization errors and prevent overflow conditions in fixed-point arithmetic implementations. Methods include dynamic scaling, block floating-point representations, and error compensation algorithms. These approaches balance computational accuracy with hardware resource constraints, ensuring reliable results across different signal processing applications.
02 Pipeline and parallel processing techniques for FFT
Advanced pipeline architectures enable concurrent execution of multiple FFT stages, significantly improving processing speed. Parallel processing methods distribute FFT computations across multiple processing units, allowing simultaneous calculation of different frequency components. These techniques include multi-core implementations, SIMD operations, and distributed computing approaches that enhance real-time processing capabilities.Expand Specific Solutions03 Memory management and data flow optimization
Efficient memory organization is critical for FFT performance, involving optimized addressing schemes, reduced memory access conflicts, and intelligent buffer management. Techniques include in-place computation methods that minimize memory requirements, cache-friendly data arrangements, and specialized memory architectures that support high-bandwidth data transfers required for large-scale FFT operations.Expand Specific Solutions04 Algorithm modifications for computational efficiency
Various algorithmic improvements enhance FFT computation efficiency through modified calculation sequences, reduced multiplication operations, and optimized twiddle factor handling. These modifications include radix-based algorithms, split-radix approaches, and hybrid methods that adapt to different input sizes and precision requirements while maintaining accuracy and reducing computational overhead.Expand Specific Solutions05 Precision control and error reduction methods
Maintaining numerical accuracy in FFT calculations requires careful management of fixed-point and floating-point arithmetic, rounding errors, and overflow prevention. Techniques include dynamic range scaling, adaptive precision adjustment, and error compensation algorithms that ensure reliable results across different signal characteristics and transform sizes while optimizing resource utilization.Expand Specific Solutions
Key Players in DSP and FFT Technology
The DSP optimization for FFT calculations market represents a mature yet rapidly evolving sector driven by increasing demand for real-time signal processing across telecommunications, defense, and consumer electronics. The industry has reached a consolidation phase where established semiconductor giants like Intel, Qualcomm, Texas Instruments, and Analog Devices dominate through comprehensive DSP portfolios and advanced fabrication capabilities. Technology maturity varies significantly across market segments, with companies like Altera (now Intel) and ARM providing highly optimized FPGA and processor architectures for FFT acceleration, while emerging players such as Zhongke Ehiway focus on specialized programmable logic solutions. Defense contractors including Lockheed Martin and Northrop Grumman drive high-performance requirements, while academic institutions like UESTC and Beijing Institute of Technology contribute fundamental algorithmic innovations. The competitive landscape shows strong vertical integration among leaders, with newer entrants targeting niche applications through specialized IP cores and custom silicon solutions.
Altera Corp.
Technical Solution: Altera (now part of Intel) developed FPGA-based FFT IP cores that provide highly configurable and parallel FFT implementations. Their approach utilizes reconfigurable hardware architectures that can be optimized for specific FFT sizes and throughput requirements. The FFT IP cores support streaming architectures with pipelined butterfly operations, enabling continuous data processing with minimal latency. Altera's solution includes parameterizable designs supporting various radix configurations and precision levels, with dedicated DSP blocks optimized for complex multiplication operations. Their architecture can achieve processing rates exceeding 1 GSPS for certain FFT configurations while maintaining flexibility for custom implementations.
Strengths: High flexibility and customization capabilities with excellent parallel processing performance for specific applications. Weaknesses: Requires FPGA programming expertise and higher development complexity compared to fixed-function DSP solutions.
Analog Devices, Inc.
Technical Solution: ADI's SHARC and Blackfin DSP families feature dedicated FFT engines with hardware-accelerated complex arithmetic units and specialized memory architectures optimized for FFT data flow patterns. Their processors implement parallel radix-2 and radix-4 FFT algorithms with dedicated bit-reversal units and twiddle factor generators. The architecture includes dual-ported memory systems that enable simultaneous read/write operations during butterfly computations, significantly reducing memory access bottlenecks. ADI's implementation supports both fixed-point and floating-point FFT operations with configurable precision levels, achieving real-time processing capabilities for applications requiring up to 2048-point FFTs at sampling rates exceeding 100 MHz.
Strengths: Specialized DSP architecture with excellent real-time performance and comprehensive development tools for signal processing applications. Weaknesses: Higher cost compared to general-purpose solutions and limited scalability for very large FFT sizes.
Core Innovations in Fast FFT Algorithms
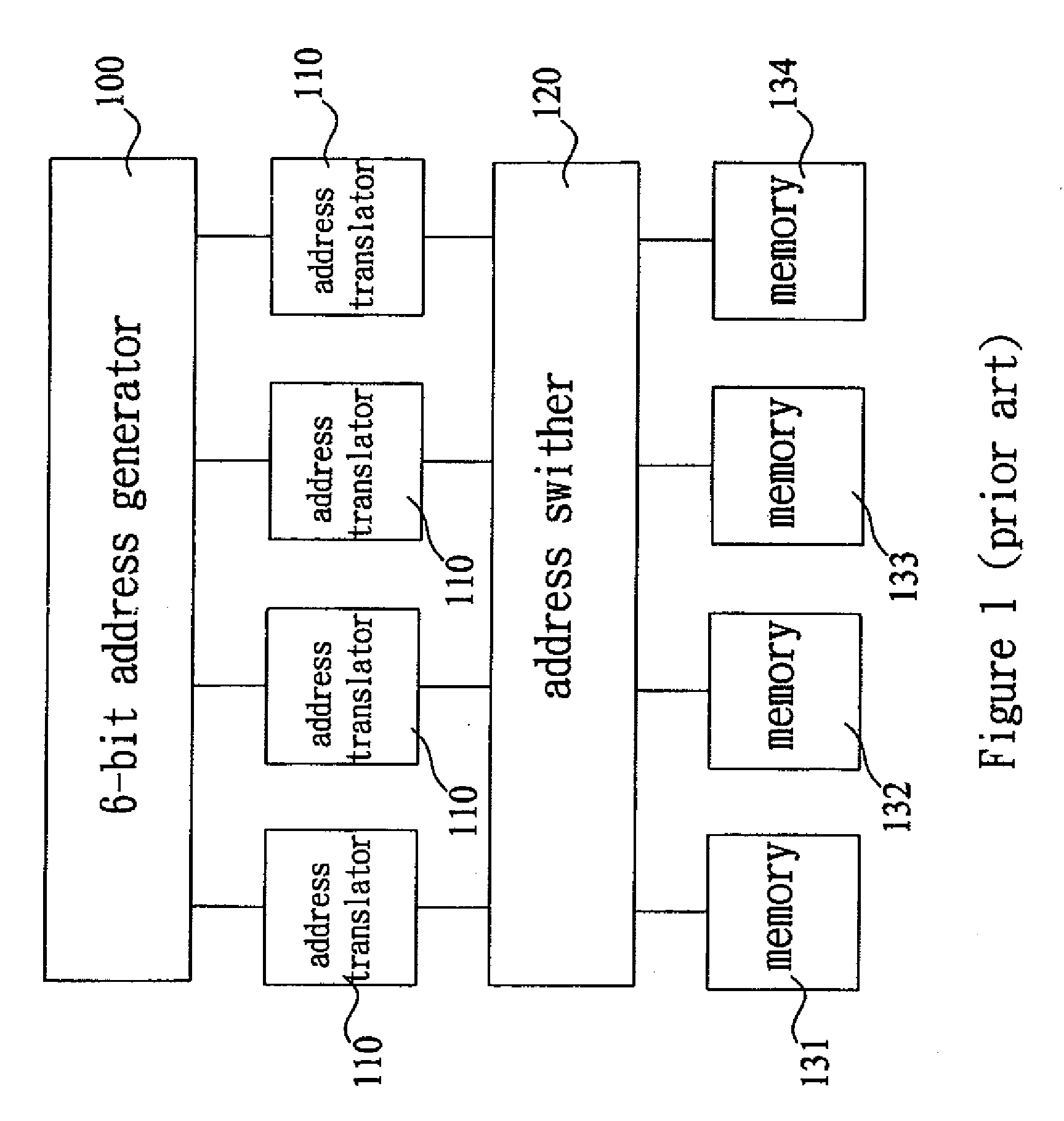
Digital signal processor architecture optimized for performing fast fourier transforms
PatentInactiveEP0889416A3
Innovation
- A general-purpose digital processor architecture with two parallel multiply and accumulate (MAC) units connected in a crossover configuration, allowing the butterfly operation of the FFT algorithm to be performed in a single instruction cycle, significantly reducing computational load and instruction cycles.



Digital signal processor structure for performing length-scalable fast fourier transformation
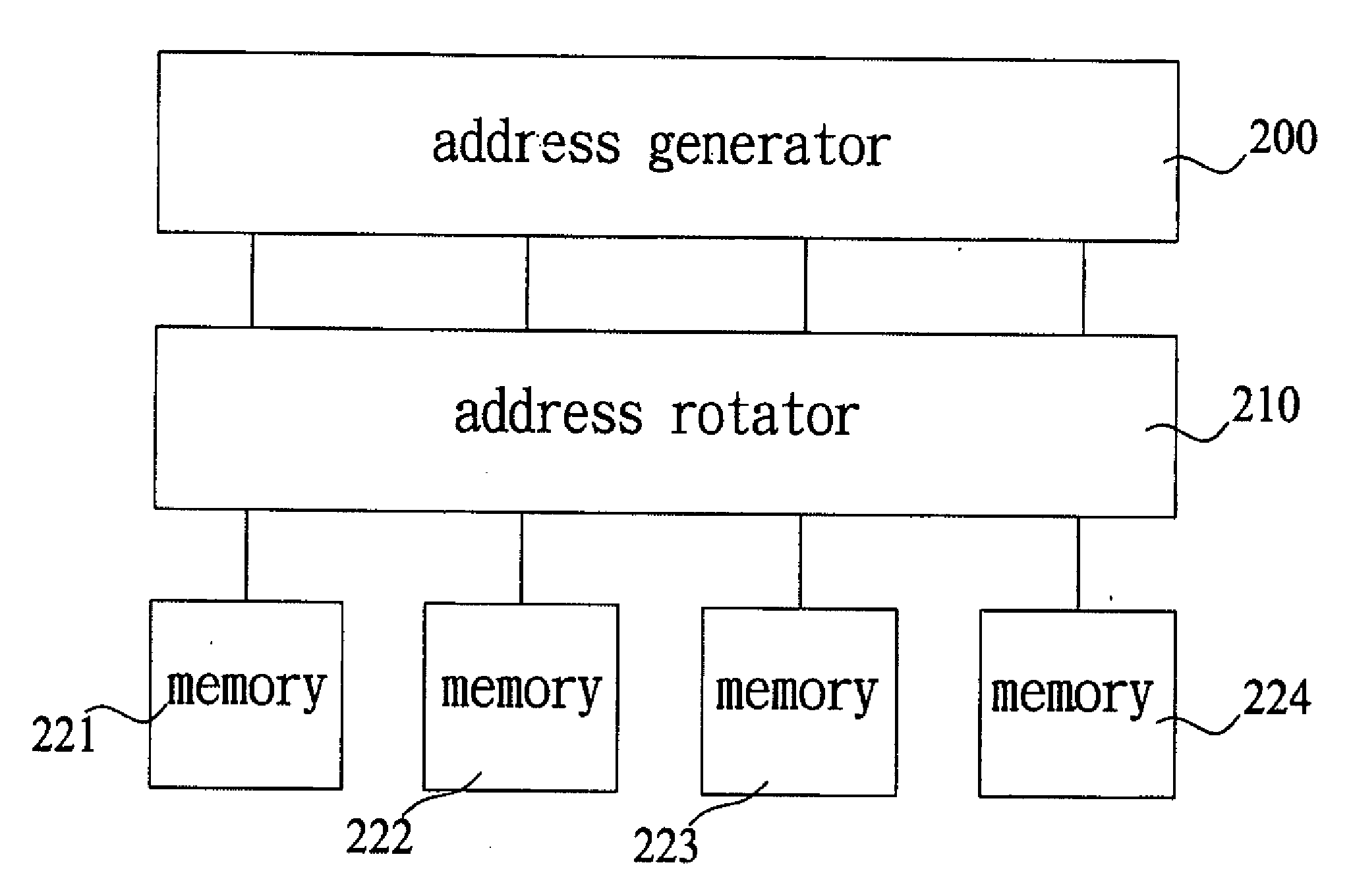
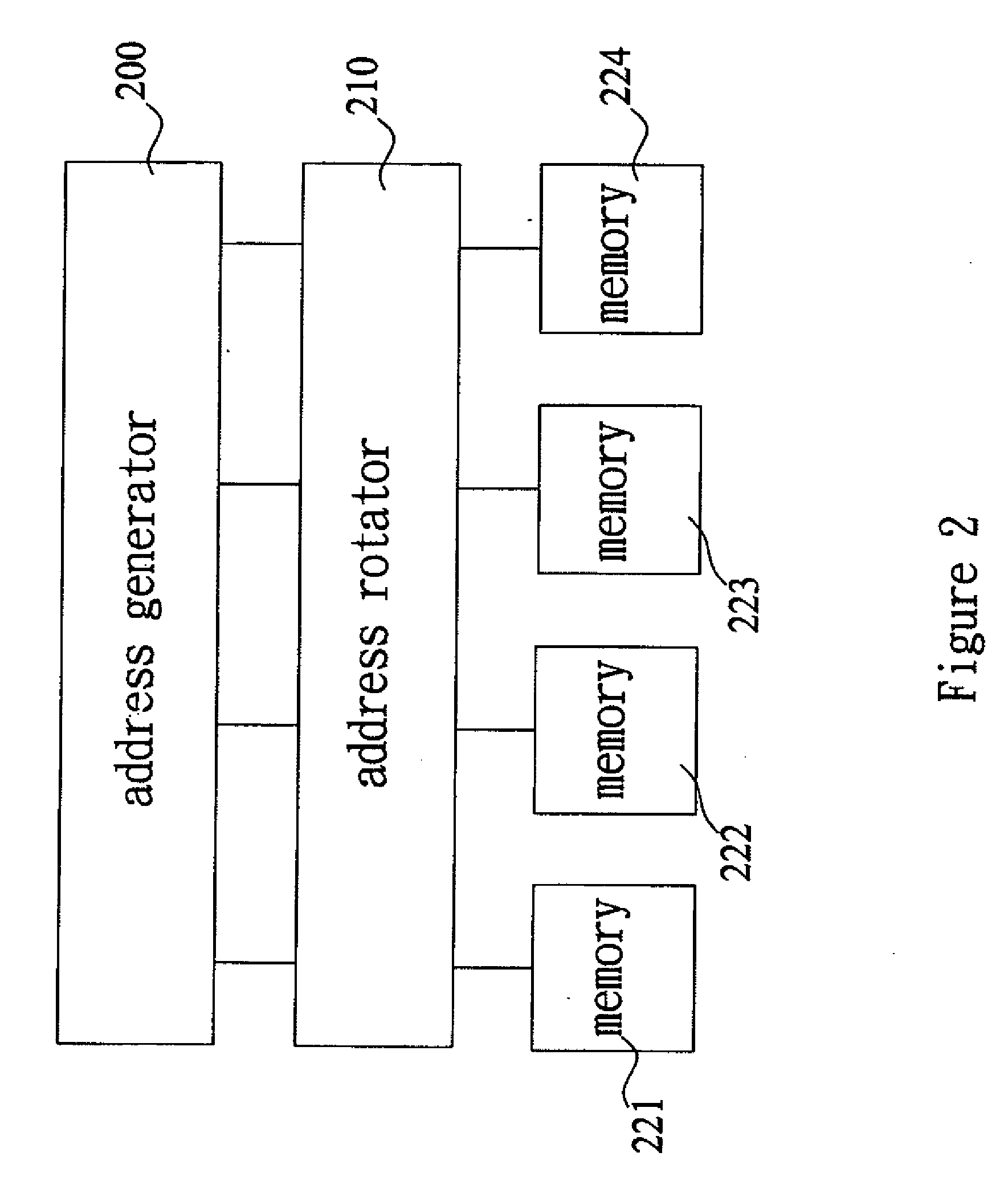
PatentInactiveUS20080208944A1
Innovation
- A digital signal processor structure utilizing a single processor element and a simple address generator, employing in-place computation and multiple single-port memory banks to achieve length-scalable, high-performance, and low-power consumption, with a dynamic prediction method for twiddle factor complex multiplications and a look-up table to reduce storage needs.

Hardware-Software Co-design for FFT
Hardware-software co-design represents a paradigm shift in FFT optimization, moving beyond traditional approaches that treat hardware and software as separate entities. This methodology enables simultaneous optimization of both domains, creating synergistic effects that significantly enhance DSP performance for FFT calculations. The co-design approach allows for fine-tuned alignment between algorithmic implementations and underlying hardware architectures, resulting in superior computational efficiency compared to conventional sequential design methodologies.
Modern FFT co-design strategies leverage reconfigurable computing platforms, particularly FPGAs, which offer the flexibility to implement custom hardware accelerators while maintaining software programmability. These platforms enable dynamic resource allocation, where computational resources can be redistributed based on real-time FFT requirements. The integration of dedicated multiply-accumulate units, specialized memory hierarchies, and optimized data path configurations creates highly efficient FFT processing engines tailored to specific application demands.
Software optimization within the co-design framework focuses on algorithm-hardware mapping strategies that maximize parallelism and minimize memory access latencies. Advanced compiler techniques automatically generate hardware-optimized code that exploits architectural features such as vector processing units, parallel execution pipelines, and specialized instruction sets. These software adaptations work in conjunction with hardware modifications to achieve optimal resource utilization and computational throughput.
The co-design methodology addresses critical bottlenecks in FFT processing through coordinated hardware-software optimizations. Memory bandwidth limitations are mitigated through intelligent data prefetching algorithms combined with custom memory controllers and optimized cache hierarchies. Computational complexity is reduced via algorithmic refinements that leverage specific hardware capabilities, such as dedicated butterfly operation units and parallel radix processing elements.
Emerging co-design approaches incorporate machine learning techniques to dynamically optimize FFT implementations based on workload characteristics and performance metrics. These adaptive systems continuously monitor computational patterns and automatically adjust both hardware configurations and software parameters to maintain optimal performance across varying operational conditions, representing the next evolution in FFT optimization strategies.
Modern FFT co-design strategies leverage reconfigurable computing platforms, particularly FPGAs, which offer the flexibility to implement custom hardware accelerators while maintaining software programmability. These platforms enable dynamic resource allocation, where computational resources can be redistributed based on real-time FFT requirements. The integration of dedicated multiply-accumulate units, specialized memory hierarchies, and optimized data path configurations creates highly efficient FFT processing engines tailored to specific application demands.
Software optimization within the co-design framework focuses on algorithm-hardware mapping strategies that maximize parallelism and minimize memory access latencies. Advanced compiler techniques automatically generate hardware-optimized code that exploits architectural features such as vector processing units, parallel execution pipelines, and specialized instruction sets. These software adaptations work in conjunction with hardware modifications to achieve optimal resource utilization and computational throughput.
The co-design methodology addresses critical bottlenecks in FFT processing through coordinated hardware-software optimizations. Memory bandwidth limitations are mitigated through intelligent data prefetching algorithms combined with custom memory controllers and optimized cache hierarchies. Computational complexity is reduced via algorithmic refinements that leverage specific hardware capabilities, such as dedicated butterfly operation units and parallel radix processing elements.
Emerging co-design approaches incorporate machine learning techniques to dynamically optimize FFT implementations based on workload characteristics and performance metrics. These adaptive systems continuously monitor computational patterns and automatically adjust both hardware configurations and software parameters to maintain optimal performance across varying operational conditions, representing the next evolution in FFT optimization strategies.
Power Efficiency in DSP-FFT Systems
Power efficiency has emerged as a critical design consideration in DSP-FFT systems, driven by the proliferation of battery-powered devices and stringent thermal constraints in high-performance computing applications. Modern FFT implementations face the dual challenge of maintaining computational accuracy while minimizing energy consumption, particularly in mobile communications, IoT sensors, and edge computing platforms where power budgets are severely constrained.
The energy consumption profile of FFT operations is fundamentally influenced by the algorithm's computational complexity and memory access patterns. Traditional radix-2 and radix-4 FFT algorithms exhibit different power characteristics, with higher radix implementations generally offering better computational efficiency but requiring more complex hardware architectures. The butterfly operations, which form the core computational units, contribute significantly to overall power consumption through arithmetic operations and data movement between processing elements.
Memory hierarchy optimization plays a pivotal role in achieving power-efficient FFT implementations. Cache-friendly algorithms that maximize data locality can reduce energy-intensive off-chip memory accesses by up to 60% compared to naive implementations. Techniques such as in-place computation and optimized data scheduling minimize memory bandwidth requirements, directly translating to reduced power consumption in memory subsystems.
Voltage and frequency scaling strategies have proven effective in balancing performance and power requirements. Dynamic voltage and frequency scaling (DVFS) allows FFT processors to adapt their operating points based on real-time computational demands and quality-of-service requirements. Near-threshold computing approaches can achieve significant energy savings for applications tolerating moderate performance degradation, particularly in sensor processing and low-power signal analysis scenarios.
Specialized hardware architectures, including dedicated FFT accelerators and approximate computing units, offer substantial power advantages over general-purpose processors. These implementations can achieve energy efficiency improvements of 10-100x through optimized datapath designs, reduced precision arithmetic, and elimination of unnecessary computational overhead inherent in programmable processors.
The energy consumption profile of FFT operations is fundamentally influenced by the algorithm's computational complexity and memory access patterns. Traditional radix-2 and radix-4 FFT algorithms exhibit different power characteristics, with higher radix implementations generally offering better computational efficiency but requiring more complex hardware architectures. The butterfly operations, which form the core computational units, contribute significantly to overall power consumption through arithmetic operations and data movement between processing elements.
Memory hierarchy optimization plays a pivotal role in achieving power-efficient FFT implementations. Cache-friendly algorithms that maximize data locality can reduce energy-intensive off-chip memory accesses by up to 60% compared to naive implementations. Techniques such as in-place computation and optimized data scheduling minimize memory bandwidth requirements, directly translating to reduced power consumption in memory subsystems.
Voltage and frequency scaling strategies have proven effective in balancing performance and power requirements. Dynamic voltage and frequency scaling (DVFS) allows FFT processors to adapt their operating points based on real-time computational demands and quality-of-service requirements. Near-threshold computing approaches can achieve significant energy savings for applications tolerating moderate performance degradation, particularly in sensor processing and low-power signal analysis scenarios.
Specialized hardware architectures, including dedicated FFT accelerators and approximate computing units, offer substantial power advantages over general-purpose processors. These implementations can achieve energy efficiency improvements of 10-100x through optimized datapath designs, reduced precision arithmetic, and elimination of unnecessary computational overhead inherent in programmable processors.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!