

Optimizing Fault Tolerance Capabilities in Complex Data Interconnect Fabrics
MAY 19, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Data Fabric Fault Tolerance Background and Objectives
Data interconnect fabrics have evolved from simple point-to-point connections to sophisticated multi-dimensional networks that form the backbone of modern computing infrastructure. The emergence of high-performance computing, cloud computing, and artificial intelligence applications has driven unprecedented demands for reliable, high-bandwidth data transmission across complex network topologies. Traditional fault tolerance mechanisms, originally designed for simpler network architectures, are increasingly inadequate for addressing the multifaceted challenges present in contemporary data fabric environments.
The historical development of data fabric fault tolerance can be traced through several distinct phases. Early implementations relied primarily on basic redundancy and error detection mechanisms, such as parity checking and simple retry protocols. As network complexity increased, more sophisticated approaches emerged, including adaptive routing algorithms, distributed error correction, and hierarchical fault management systems. The transition from centralized to distributed fault tolerance architectures marked a significant milestone, enabling more scalable and resilient network designs.
Current data fabric environments face unprecedented complexity challenges that traditional fault tolerance approaches struggle to address effectively. Modern interconnect fabrics must simultaneously handle diverse traffic patterns, varying quality of service requirements, and dynamic workload distributions while maintaining sub-microsecond latency constraints. The proliferation of heterogeneous computing elements, including CPUs, GPUs, FPGAs, and specialized accelerators, further complicates fault tolerance design by introducing diverse failure modes and recovery requirements.
The primary objective of optimizing fault tolerance capabilities centers on developing adaptive, intelligent systems capable of predicting, detecting, and recovering from failures with minimal performance impact. This involves creating self-healing network architectures that can dynamically reconfigure routing paths, redistribute traffic loads, and maintain service continuity even under multiple concurrent failure scenarios. Advanced machine learning techniques are increasingly being integrated to enable predictive fault detection and proactive mitigation strategies.
Secondary objectives include achieving fault tolerance optimization while preserving energy efficiency and cost-effectiveness. The challenge lies in balancing redundancy requirements with resource utilization, ensuring that fault tolerance mechanisms do not introduce prohibitive overhead in terms of power consumption, silicon area, or network bandwidth. Additionally, maintaining backward compatibility with existing protocols and standards remains crucial for practical deployment in enterprise environments.
The historical development of data fabric fault tolerance can be traced through several distinct phases. Early implementations relied primarily on basic redundancy and error detection mechanisms, such as parity checking and simple retry protocols. As network complexity increased, more sophisticated approaches emerged, including adaptive routing algorithms, distributed error correction, and hierarchical fault management systems. The transition from centralized to distributed fault tolerance architectures marked a significant milestone, enabling more scalable and resilient network designs.
Current data fabric environments face unprecedented complexity challenges that traditional fault tolerance approaches struggle to address effectively. Modern interconnect fabrics must simultaneously handle diverse traffic patterns, varying quality of service requirements, and dynamic workload distributions while maintaining sub-microsecond latency constraints. The proliferation of heterogeneous computing elements, including CPUs, GPUs, FPGAs, and specialized accelerators, further complicates fault tolerance design by introducing diverse failure modes and recovery requirements.
The primary objective of optimizing fault tolerance capabilities centers on developing adaptive, intelligent systems capable of predicting, detecting, and recovering from failures with minimal performance impact. This involves creating self-healing network architectures that can dynamically reconfigure routing paths, redistribute traffic loads, and maintain service continuity even under multiple concurrent failure scenarios. Advanced machine learning techniques are increasingly being integrated to enable predictive fault detection and proactive mitigation strategies.
Secondary objectives include achieving fault tolerance optimization while preserving energy efficiency and cost-effectiveness. The challenge lies in balancing redundancy requirements with resource utilization, ensuring that fault tolerance mechanisms do not introduce prohibitive overhead in terms of power consumption, silicon area, or network bandwidth. Additionally, maintaining backward compatibility with existing protocols and standards remains crucial for practical deployment in enterprise environments.
Market Demand for Resilient Data Interconnect Solutions
The global demand for resilient data interconnect solutions has experienced unprecedented growth driven by the exponential expansion of data-intensive applications and the increasing complexity of modern computing infrastructures. Cloud computing, artificial intelligence, machine learning, and big data analytics have fundamentally transformed how organizations process and transmit information, creating an urgent need for robust interconnect fabrics that can maintain operational continuity under adverse conditions.
Enterprise data centers and hyperscale cloud providers represent the primary market segments driving demand for fault-tolerant interconnect solutions. These organizations require interconnect fabrics capable of handling massive data volumes while ensuring zero-tolerance for service interruptions. The proliferation of distributed computing architectures, including microservices and containerized applications, has further amplified the need for reliable data transmission pathways that can adapt to dynamic workload requirements.
High-performance computing environments, particularly in scientific research, financial modeling, and simulation applications, constitute another significant market driver. These sectors demand interconnect solutions that can maintain consistent performance levels even when individual components fail, as computational delays can result in substantial financial losses or research setbacks.
The telecommunications industry's transition toward software-defined networking and network function virtualization has created substantial market opportunities for advanced fault-tolerant interconnect technologies. Service providers require interconnect fabrics that can guarantee service level agreements while managing increasingly complex network topologies and traffic patterns.
Edge computing deployment represents an emerging market segment with unique resilience requirements. As computing resources move closer to end users, the need for autonomous fault detection and recovery mechanisms becomes critical, particularly in environments where immediate human intervention may not be feasible.
Market growth is further accelerated by regulatory compliance requirements across various industries, including healthcare, finance, and government sectors, where data availability and integrity are mandated by law. Organizations in these sectors actively seek interconnect solutions that can demonstrate measurable improvements in system reliability and fault recovery capabilities.
The increasing adoption of artificial intelligence and machine learning workloads has created demand for interconnect fabrics optimized for parallel processing and distributed training scenarios, where fault tolerance directly impacts computational efficiency and resource utilization costs.
Enterprise data centers and hyperscale cloud providers represent the primary market segments driving demand for fault-tolerant interconnect solutions. These organizations require interconnect fabrics capable of handling massive data volumes while ensuring zero-tolerance for service interruptions. The proliferation of distributed computing architectures, including microservices and containerized applications, has further amplified the need for reliable data transmission pathways that can adapt to dynamic workload requirements.
High-performance computing environments, particularly in scientific research, financial modeling, and simulation applications, constitute another significant market driver. These sectors demand interconnect solutions that can maintain consistent performance levels even when individual components fail, as computational delays can result in substantial financial losses or research setbacks.
The telecommunications industry's transition toward software-defined networking and network function virtualization has created substantial market opportunities for advanced fault-tolerant interconnect technologies. Service providers require interconnect fabrics that can guarantee service level agreements while managing increasingly complex network topologies and traffic patterns.
Edge computing deployment represents an emerging market segment with unique resilience requirements. As computing resources move closer to end users, the need for autonomous fault detection and recovery mechanisms becomes critical, particularly in environments where immediate human intervention may not be feasible.
Market growth is further accelerated by regulatory compliance requirements across various industries, including healthcare, finance, and government sectors, where data availability and integrity are mandated by law. Organizations in these sectors actively seek interconnect solutions that can demonstrate measurable improvements in system reliability and fault recovery capabilities.
The increasing adoption of artificial intelligence and machine learning workloads has created demand for interconnect fabrics optimized for parallel processing and distributed training scenarios, where fault tolerance directly impacts computational efficiency and resource utilization costs.
Current Fault Tolerance Limitations in Complex Data Fabrics
Complex data interconnect fabrics face significant fault tolerance limitations that constrain their reliability and performance in mission-critical applications. Traditional error detection and correction mechanisms often operate at individual component levels, lacking comprehensive system-wide coordination. This fragmented approach creates vulnerability gaps where cascading failures can propagate through multiple fabric layers before detection occurs.
Current fabric architectures predominantly rely on reactive fault handling strategies rather than proactive prevention mechanisms. When link failures or node degradation occurs, existing systems typically respond through basic retry mechanisms or simple path rerouting. However, these approaches introduce substantial latency penalties and may not adequately address correlated failures that affect multiple interconnect paths simultaneously.
Bandwidth utilization presents another critical limitation in fault-tolerant fabric designs. Most current implementations reserve significant portions of available bandwidth for redundancy and error recovery operations, reducing overall system efficiency. The static allocation of these resources prevents dynamic adaptation to varying fault conditions and traffic patterns, leading to suboptimal performance during both normal operations and fault scenarios.
Scalability constraints become increasingly problematic as fabric complexity grows. Existing fault tolerance mechanisms often exhibit exponential overhead increases with network size, making them impractical for large-scale deployments. The centralized nature of many current fault management systems creates bottlenecks and single points of failure, contradicting the distributed resilience goals of modern interconnect architectures.
Protocol-level limitations further compound these challenges. Many established interconnect protocols lack native support for advanced fault tolerance features, requiring costly overlay solutions that introduce additional complexity and performance overhead. The absence of standardized fault reporting and coordination mechanisms across different fabric components hampers the development of unified fault management strategies.
Timing synchronization issues represent another significant constraint in current fault tolerance implementations. Distributed fault detection and recovery operations often suffer from coordination delays that can exceed acceptable service level requirements. These timing challenges are particularly acute in high-frequency trading, real-time control systems, and other latency-sensitive applications where fault recovery must occur within microsecond timeframes.
Current fabric architectures predominantly rely on reactive fault handling strategies rather than proactive prevention mechanisms. When link failures or node degradation occurs, existing systems typically respond through basic retry mechanisms or simple path rerouting. However, these approaches introduce substantial latency penalties and may not adequately address correlated failures that affect multiple interconnect paths simultaneously.
Bandwidth utilization presents another critical limitation in fault-tolerant fabric designs. Most current implementations reserve significant portions of available bandwidth for redundancy and error recovery operations, reducing overall system efficiency. The static allocation of these resources prevents dynamic adaptation to varying fault conditions and traffic patterns, leading to suboptimal performance during both normal operations and fault scenarios.
Scalability constraints become increasingly problematic as fabric complexity grows. Existing fault tolerance mechanisms often exhibit exponential overhead increases with network size, making them impractical for large-scale deployments. The centralized nature of many current fault management systems creates bottlenecks and single points of failure, contradicting the distributed resilience goals of modern interconnect architectures.
Protocol-level limitations further compound these challenges. Many established interconnect protocols lack native support for advanced fault tolerance features, requiring costly overlay solutions that introduce additional complexity and performance overhead. The absence of standardized fault reporting and coordination mechanisms across different fabric components hampers the development of unified fault management strategies.
Timing synchronization issues represent another significant constraint in current fault tolerance implementations. Distributed fault detection and recovery operations often suffer from coordination delays that can exceed acceptable service level requirements. These timing challenges are particularly acute in high-frequency trading, real-time control systems, and other latency-sensitive applications where fault recovery must occur within microsecond timeframes.
Existing Fault Tolerance Solutions for Data Fabrics
01 Redundant path routing and failover mechanisms
Data interconnect fabrics implement redundant routing paths to ensure continuous data transmission when primary paths fail. These systems automatically detect path failures and redirect traffic through alternative routes, maintaining network connectivity and preventing data loss. The failover mechanisms include dynamic path selection algorithms and backup route establishment to ensure seamless operation during network disruptions.- Redundant path routing and failover mechanisms: Implementation of multiple redundant communication paths within data interconnect fabrics to ensure continuous operation when primary paths fail. These mechanisms automatically detect path failures and reroute traffic through alternative paths, maintaining system connectivity and data flow integrity during fault conditions.
- Error detection and correction protocols: Advanced error detection and correction techniques integrated into fabric communication protocols to identify and recover from data transmission errors. These protocols implement checksums, parity bits, and forward error correction algorithms to ensure data integrity across the interconnect fabric even in the presence of transient faults.
- Dynamic reconfiguration and self-healing capabilities: Adaptive fabric architectures that can dynamically reconfigure their topology and routing tables in response to detected faults. These systems feature self-healing capabilities that isolate faulty components and automatically restructure the network to maintain optimal performance and connectivity without manual intervention.
- Distributed fault monitoring and management systems: Comprehensive monitoring frameworks that continuously track the health and performance of fabric components across distributed nodes. These systems collect fault data, analyze failure patterns, and coordinate recovery actions across multiple fabric elements to prevent cascading failures and maintain system reliability.
- Hot-swappable component support and graceful degradation: Design methodologies that enable replacement of faulty fabric components without system shutdown while maintaining service availability. These approaches implement graceful degradation strategies that allow the system to continue operating at reduced capacity when components fail, ensuring critical operations remain functional.
02 Error detection and correction protocols
Advanced error detection and correction mechanisms are integrated into data interconnect fabrics to identify and rectify transmission errors in real-time. These protocols monitor data integrity during transmission and employ various correction algorithms to recover corrupted data packets. The systems implement checksums, parity bits, and forward error correction techniques to maintain data accuracy and reliability across the network fabric.Expand Specific Solutions03 Load balancing and traffic distribution
Fault-tolerant data interconnect fabrics employ sophisticated load balancing techniques to distribute network traffic evenly across multiple paths and nodes. These systems prevent network congestion and single points of failure by dynamically adjusting traffic flow based on real-time network conditions. The load balancing mechanisms help maintain optimal performance while providing resilience against component failures.Expand Specific Solutions04 Network topology reconfiguration and self-healing
Self-healing capabilities enable data interconnect fabrics to automatically reconfigure network topology when failures occur. These systems can isolate faulty components and restructure connections to maintain network functionality without manual intervention. The reconfiguration process includes dynamic discovery of available resources and automatic establishment of new communication paths to bypass failed elements.Expand Specific Solutions05 Monitoring and diagnostic systems
Comprehensive monitoring and diagnostic capabilities provide real-time visibility into network health and performance metrics. These systems continuously track various parameters including link status, error rates, and traffic patterns to predict potential failures before they occur. The diagnostic tools enable proactive maintenance and rapid identification of fault conditions, supporting preventive measures and quick recovery procedures.Expand Specific Solutions
Key Players in Data Fabric and Interconnect Industry
The fault tolerance optimization in complex data interconnect fabrics represents a mature yet rapidly evolving market segment driven by increasing data center complexity and reliability demands. The industry has reached an advanced development stage, with established players like IBM, Intel, and Hewlett Packard Enterprise leading infrastructure solutions, while semiconductor specialists including AMD, Qualcomm, and Infineon contribute critical hardware components. Technology maturity varies significantly across the competitive landscape - traditional enterprise vendors demonstrate proven fault tolerance implementations, whereas emerging players like Google LLC and Mellanox Technologies push innovation boundaries with software-defined approaches and high-performance interconnect solutions. The market exhibits substantial growth potential, particularly in cloud computing and AI workloads, with academic institutions such as Fudan University and Xi'an Jiaotong University contributing foundational research that bridges theoretical advances with practical implementations across diverse industry applications.
International Business Machines Corp.
Technical Solution: IBM implements comprehensive fault tolerance in data interconnect fabrics through redundant pathway architecture and advanced error correction mechanisms. Their approach utilizes dynamic routing algorithms that automatically detect and isolate faulty components while redistributing traffic through alternative paths. The system incorporates real-time monitoring capabilities with predictive analytics to identify potential failure points before they impact network performance. IBM's solution features multi-level redundancy including link-level, switch-level, and fabric-level protection mechanisms. The technology employs sophisticated error detection and correction codes specifically designed for high-speed interconnects, ensuring data integrity even under adverse conditions.
Strengths: Mature enterprise-grade solutions with proven reliability in mission-critical environments. Comprehensive multi-layer fault tolerance approach. Weaknesses: Higher implementation costs and complexity compared to simpler solutions.
Intel Corp.
Technical Solution: Intel's fault tolerance strategy for data interconnect fabrics centers on their advanced silicon photonics technology combined with intelligent fabric management systems. Their approach integrates hardware-level error detection with software-defined networking principles to create self-healing network architectures. The solution employs machine learning algorithms to predict and prevent failures while maintaining optimal performance through adaptive load balancing. Intel's technology features built-in redundancy mechanisms at the physical layer, including backup optical paths and automatic failover capabilities. The system utilizes advanced signal processing techniques to maintain data integrity across high-bandwidth interconnects, with real-time error monitoring and correction capabilities that ensure continuous operation even during component failures.
Strengths: Leading-edge silicon photonics technology with high bandwidth capabilities. Strong integration of AI-driven predictive maintenance. Weaknesses: Relatively newer technology with limited long-term deployment history in complex enterprise environments.
Core Innovations in Data Fabric Resilience Technologies
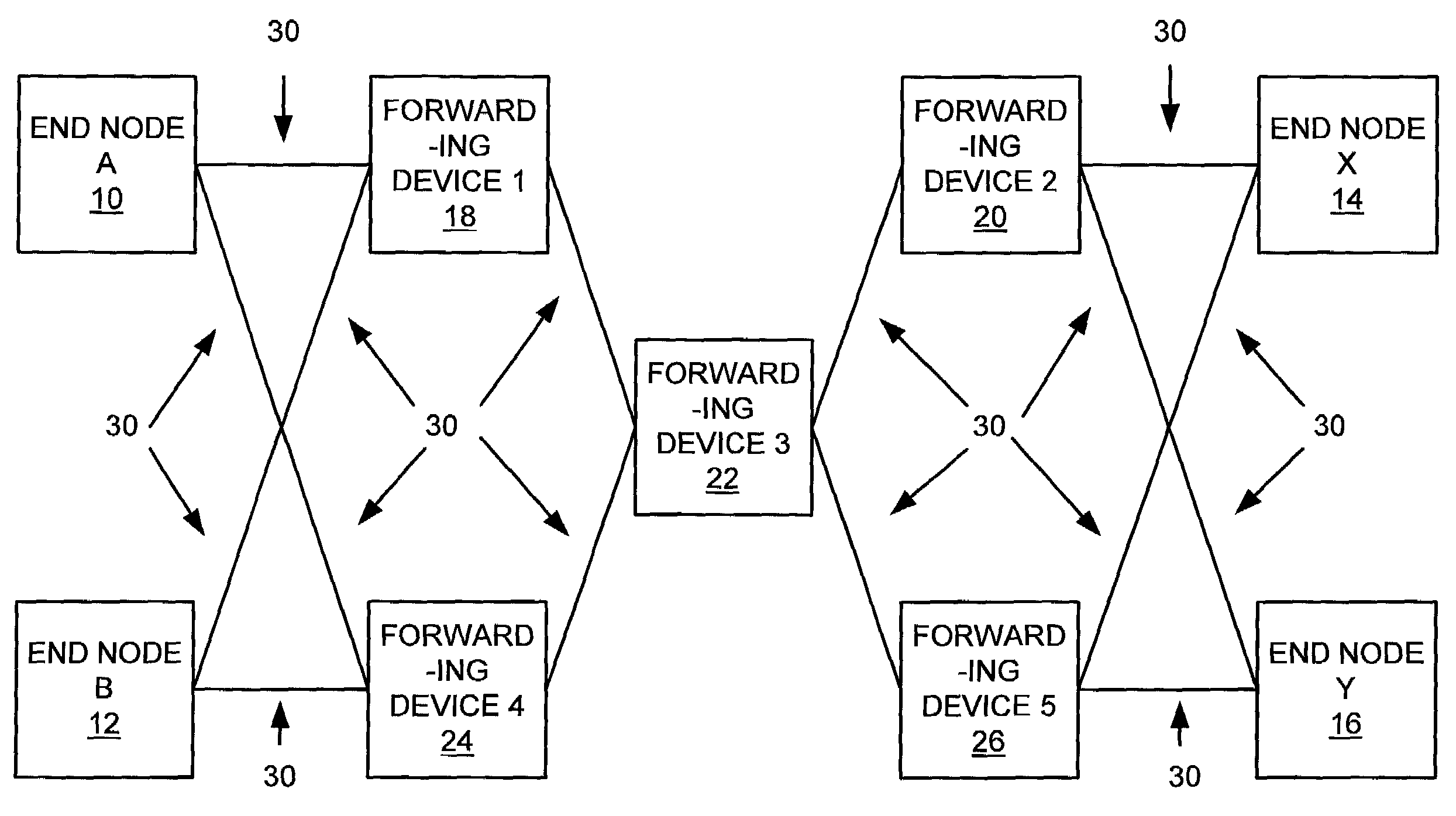
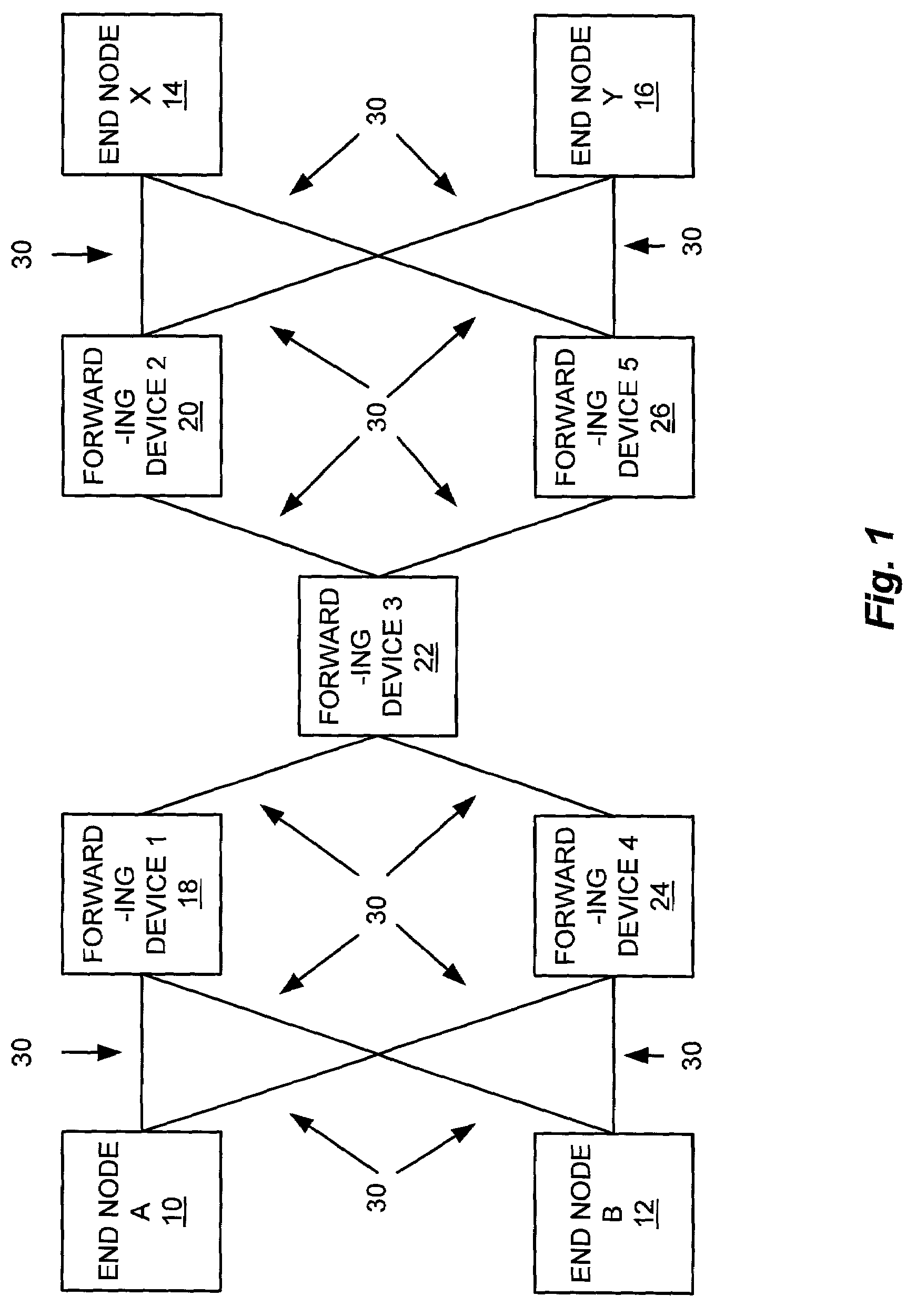
Method and apparatus for cluster interconnection using multi-port nodes and multiple routing fabrics
PatentActiveUS7468982B2
Innovation
- A multi-fabric interconnection system where each node interfaces with more than two fabrics, with each fabric being incomplete, ensuring every pair of nodes connects through at least one common fabric, using balanced incomplete block designs to determine optimal fabric sizes and numbers, allowing for scalable, high-performance, and fault-tolerant connections.




Method of optimizing network capacity and fault tolerance in deadlock-free routing
PatentInactiveUS7200117B2
Innovation
- A system that generates and distributes routing information to optimize for network-wide performance metrics by selecting routes that minimize standard deviation of link utilization for capacity and maximize link dissimilarity for fault tolerance, allowing for dynamic load balancing and failover capabilities.

Performance Impact Assessment of Fault Tolerance Mechanisms
The implementation of fault tolerance mechanisms in complex data interconnect fabrics inevitably introduces performance overhead that must be carefully evaluated and quantified. This performance impact manifests across multiple dimensions, including latency penalties, throughput degradation, and resource utilization increases. Understanding these trade-offs is essential for optimizing system design and ensuring that reliability improvements do not compromise overall system efficiency.
Latency overhead represents one of the most critical performance impacts of fault tolerance mechanisms. Error detection and correction processes introduce additional processing delays at each network hop, with the magnitude varying significantly based on the chosen approach. Forward Error Correction (FEC) schemes typically add 10-50 nanoseconds per hop, while more sophisticated adaptive routing algorithms can introduce variable delays ranging from 20-200 nanoseconds depending on network congestion and fault conditions.
Throughput degradation occurs through multiple pathways in fault-tolerant interconnect designs. Redundant data transmission for reliability purposes directly reduces effective bandwidth utilization, with typical overhead ranging from 12.5% for simple parity schemes to 50% for full duplication approaches. Additionally, the computational overhead of error correction algorithms can create bottlenecks in high-speed data paths, particularly when implemented in software rather than dedicated hardware.
Resource consumption increases substantially with fault tolerance implementation, affecting both hardware costs and power efficiency. Memory requirements for buffering and error correction can increase by 25-40% compared to non-fault-tolerant designs. Processing overhead for real-time error detection and recovery operations typically consumes 5-15% of available computational resources, with peaks reaching 30% during active fault recovery scenarios.
The performance impact varies significantly across different fault tolerance strategies. Proactive approaches like path diversity and predictive rerouting generally exhibit lower steady-state overhead but may experience performance spikes during fault prediction and prevention activities. Reactive mechanisms tend to maintain consistent baseline performance until fault events occur, at which point recovery operations can temporarily degrade system performance by 20-60% depending on fault severity and recovery complexity.
Scalability considerations reveal that performance overhead often increases non-linearly with system size and complexity. Large-scale interconnect fabrics with thousands of nodes may experience amplified latency effects due to the cumulative impact of per-hop processing delays. Network diameter growth in fault-tolerant topologies can increase average path lengths by 15-25%, directly impacting end-to-end communication latency.
Modern optimization techniques are emerging to mitigate these performance impacts while maintaining robust fault tolerance capabilities. Hardware acceleration of error correction algorithms, intelligent traffic prioritization during fault recovery, and adaptive overhead adjustment based on real-time reliability requirements represent promising approaches for minimizing the performance penalty associated with fault tolerance mechanisms in next-generation interconnect fabrics.
Latency overhead represents one of the most critical performance impacts of fault tolerance mechanisms. Error detection and correction processes introduce additional processing delays at each network hop, with the magnitude varying significantly based on the chosen approach. Forward Error Correction (FEC) schemes typically add 10-50 nanoseconds per hop, while more sophisticated adaptive routing algorithms can introduce variable delays ranging from 20-200 nanoseconds depending on network congestion and fault conditions.
Throughput degradation occurs through multiple pathways in fault-tolerant interconnect designs. Redundant data transmission for reliability purposes directly reduces effective bandwidth utilization, with typical overhead ranging from 12.5% for simple parity schemes to 50% for full duplication approaches. Additionally, the computational overhead of error correction algorithms can create bottlenecks in high-speed data paths, particularly when implemented in software rather than dedicated hardware.
Resource consumption increases substantially with fault tolerance implementation, affecting both hardware costs and power efficiency. Memory requirements for buffering and error correction can increase by 25-40% compared to non-fault-tolerant designs. Processing overhead for real-time error detection and recovery operations typically consumes 5-15% of available computational resources, with peaks reaching 30% during active fault recovery scenarios.
The performance impact varies significantly across different fault tolerance strategies. Proactive approaches like path diversity and predictive rerouting generally exhibit lower steady-state overhead but may experience performance spikes during fault prediction and prevention activities. Reactive mechanisms tend to maintain consistent baseline performance until fault events occur, at which point recovery operations can temporarily degrade system performance by 20-60% depending on fault severity and recovery complexity.
Scalability considerations reveal that performance overhead often increases non-linearly with system size and complexity. Large-scale interconnect fabrics with thousands of nodes may experience amplified latency effects due to the cumulative impact of per-hop processing delays. Network diameter growth in fault-tolerant topologies can increase average path lengths by 15-25%, directly impacting end-to-end communication latency.
Modern optimization techniques are emerging to mitigate these performance impacts while maintaining robust fault tolerance capabilities. Hardware acceleration of error correction algorithms, intelligent traffic prioritization during fault recovery, and adaptive overhead adjustment based on real-time reliability requirements represent promising approaches for minimizing the performance penalty associated with fault tolerance mechanisms in next-generation interconnect fabrics.
Standardization and Interoperability in Data Fabric Design
The standardization landscape for data fabric design has emerged as a critical enabler for achieving robust fault tolerance in complex interconnect systems. Industry consortiums and standards bodies have recognized that without unified protocols and interfaces, fault tolerance mechanisms remain fragmented and vendor-specific, limiting their effectiveness across heterogeneous environments.
Current standardization efforts focus on establishing common fault detection and recovery protocols that can operate seamlessly across different hardware platforms and software stacks. The Open Compute Project and similar initiatives have developed baseline specifications for error reporting, fault isolation, and recovery coordination mechanisms. These standards define standardized APIs and communication protocols that enable different components within a data fabric to share fault information and coordinate recovery actions effectively.
Interoperability challenges arise primarily from the diverse nature of modern data fabric components, including switches, network interface cards, storage controllers, and compute nodes from multiple vendors. Each component traditionally implements proprietary fault handling mechanisms, creating integration complexities that can compromise overall system resilience. Standardized fault tolerance frameworks address these challenges by defining common data structures for error reporting, standardized messaging protocols for fault propagation, and unified interfaces for recovery orchestration.
The development of vendor-neutral fault tolerance standards has accelerated through collaborative efforts between major technology companies and research institutions. These standards encompass fault classification taxonomies, standardized metrics for measuring fault tolerance effectiveness, and common testing methodologies for validating interoperability. Such standardization enables organizations to deploy multi-vendor data fabric solutions while maintaining consistent fault tolerance capabilities across the entire infrastructure.
Emerging interoperability frameworks emphasize the importance of real-time fault information sharing between disparate system components. These frameworks define standardized telemetry formats and communication channels that enable rapid fault detection and coordinated response mechanisms. The adoption of these standards significantly reduces the complexity of implementing comprehensive fault tolerance solutions in heterogeneous data fabric environments, ultimately improving system reliability and reducing operational overhead.
Current standardization efforts focus on establishing common fault detection and recovery protocols that can operate seamlessly across different hardware platforms and software stacks. The Open Compute Project and similar initiatives have developed baseline specifications for error reporting, fault isolation, and recovery coordination mechanisms. These standards define standardized APIs and communication protocols that enable different components within a data fabric to share fault information and coordinate recovery actions effectively.
Interoperability challenges arise primarily from the diverse nature of modern data fabric components, including switches, network interface cards, storage controllers, and compute nodes from multiple vendors. Each component traditionally implements proprietary fault handling mechanisms, creating integration complexities that can compromise overall system resilience. Standardized fault tolerance frameworks address these challenges by defining common data structures for error reporting, standardized messaging protocols for fault propagation, and unified interfaces for recovery orchestration.
The development of vendor-neutral fault tolerance standards has accelerated through collaborative efforts between major technology companies and research institutions. These standards encompass fault classification taxonomies, standardized metrics for measuring fault tolerance effectiveness, and common testing methodologies for validating interoperability. Such standardization enables organizations to deploy multi-vendor data fabric solutions while maintaining consistent fault tolerance capabilities across the entire infrastructure.
Emerging interoperability frameworks emphasize the importance of real-time fault information sharing between disparate system components. These frameworks define standardized telemetry formats and communication channels that enable rapid fault detection and coordinated response mechanisms. The adoption of these standards significantly reduces the complexity of implementing comprehensive fault tolerance solutions in heterogeneous data fabric environments, ultimately improving system reliability and reducing operational overhead.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!