

Optimizing Load Balancing in Multi-Core Data Center Fabric Environments
MAY 19, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Multi-Core Data Center Load Balancing Background and Objectives
The evolution of data center architectures has undergone a fundamental transformation over the past two decades, driven by the exponential growth in computational demands and the proliferation of cloud-based services. Traditional single-core processing systems have given way to sophisticated multi-core environments that leverage parallel processing capabilities to handle increasingly complex workloads. This architectural shift has necessitated a corresponding evolution in load balancing strategies, as conventional approaches designed for single-threaded environments prove inadequate for managing the intricate resource allocation requirements of modern multi-core data center fabrics.
Multi-core data center fabric environments represent a convergence of advanced networking topologies and parallel processing architectures. These systems integrate multiple processing cores within individual nodes while simultaneously orchestrating communication across distributed fabric networks. The fabric architecture enables high-bandwidth, low-latency interconnectivity between processing elements, creating a unified computational ecosystem that can dynamically allocate resources based on real-time demand patterns.
The primary technical objective centers on developing intelligent load distribution mechanisms that can effectively harness the parallel processing capabilities inherent in multi-core architectures. This involves creating algorithms that can simultaneously balance computational loads across individual cores within nodes while optimizing traffic distribution across the broader fabric network. The challenge extends beyond simple round-robin distribution to encompass sophisticated workload characterization, predictive resource allocation, and adaptive scheduling strategies.
Performance optimization objectives focus on minimizing latency variations, maximizing throughput utilization, and ensuring consistent quality of service across diverse application workloads. These goals require addressing the complex interdependencies between core-level processing efficiency and network-level traffic management. The optimization framework must account for varying computational intensities, memory access patterns, and communication requirements of different application types.
Scalability represents another critical objective, as modern data centers must accommodate dynamic scaling scenarios where computational demands can fluctuate dramatically within short timeframes. The load balancing solution must demonstrate resilience across different scales, from small cluster deployments to massive hyperscale environments containing thousands of multi-core nodes interconnected through sophisticated fabric topologies.
Energy efficiency considerations have become increasingly paramount, driving objectives toward developing load balancing strategies that optimize performance per watt metrics. This involves intelligent power management integration, where load distribution decisions consider both computational efficiency and energy consumption patterns across the multi-core fabric infrastructure.
Multi-core data center fabric environments represent a convergence of advanced networking topologies and parallel processing architectures. These systems integrate multiple processing cores within individual nodes while simultaneously orchestrating communication across distributed fabric networks. The fabric architecture enables high-bandwidth, low-latency interconnectivity between processing elements, creating a unified computational ecosystem that can dynamically allocate resources based on real-time demand patterns.
The primary technical objective centers on developing intelligent load distribution mechanisms that can effectively harness the parallel processing capabilities inherent in multi-core architectures. This involves creating algorithms that can simultaneously balance computational loads across individual cores within nodes while optimizing traffic distribution across the broader fabric network. The challenge extends beyond simple round-robin distribution to encompass sophisticated workload characterization, predictive resource allocation, and adaptive scheduling strategies.
Performance optimization objectives focus on minimizing latency variations, maximizing throughput utilization, and ensuring consistent quality of service across diverse application workloads. These goals require addressing the complex interdependencies between core-level processing efficiency and network-level traffic management. The optimization framework must account for varying computational intensities, memory access patterns, and communication requirements of different application types.
Scalability represents another critical objective, as modern data centers must accommodate dynamic scaling scenarios where computational demands can fluctuate dramatically within short timeframes. The load balancing solution must demonstrate resilience across different scales, from small cluster deployments to massive hyperscale environments containing thousands of multi-core nodes interconnected through sophisticated fabric topologies.
Energy efficiency considerations have become increasingly paramount, driving objectives toward developing load balancing strategies that optimize performance per watt metrics. This involves intelligent power management integration, where load distribution decisions consider both computational efficiency and energy consumption patterns across the multi-core fabric infrastructure.
Market Demand for Efficient Data Center Fabric Solutions
The global data center market continues experiencing unprecedented growth driven by digital transformation initiatives, cloud computing adoption, and the exponential increase in data generation across industries. Organizations worldwide are migrating critical workloads to cloud environments, creating substantial demand for high-performance data center infrastructure capable of handling massive computational loads with minimal latency.
Enterprise customers increasingly require data center solutions that can seamlessly scale to accommodate fluctuating workloads while maintaining consistent performance levels. The rise of artificial intelligence, machine learning, and real-time analytics applications has intensified the need for sophisticated load balancing mechanisms that can efficiently distribute processing tasks across multi-core architectures without creating bottlenecks or performance degradation.
Financial services, healthcare, telecommunications, and e-commerce sectors represent the primary demand drivers for advanced data center fabric solutions. These industries process enormous volumes of time-sensitive data requiring ultra-low latency and high availability guarantees. Traditional load balancing approaches often fail to meet these stringent requirements, particularly in multi-core environments where resource allocation complexity increases exponentially.
The emergence of edge computing and Internet of Things deployments has further amplified market demand for intelligent load balancing solutions. Organizations need data center fabrics capable of dynamically adjusting to varying traffic patterns while optimizing resource utilization across distributed computing nodes. This requirement extends beyond simple traffic distribution to encompass sophisticated workload orchestration and real-time performance optimization.
Hyperscale cloud providers and colocation facilities face mounting pressure to maximize infrastructure efficiency while reducing operational costs. Inefficient load balancing directly impacts energy consumption, hardware utilization rates, and overall service quality, making optimized solutions essential for maintaining competitive advantages in increasingly saturated markets.
The growing adoption of containerized applications and microservices architectures has created additional complexity in load distribution requirements. Modern data center environments must support dynamic scaling, service discovery, and intelligent routing capabilities that traditional load balancing technologies cannot adequately address, driving sustained market demand for innovative fabric solutions.
Enterprise customers increasingly require data center solutions that can seamlessly scale to accommodate fluctuating workloads while maintaining consistent performance levels. The rise of artificial intelligence, machine learning, and real-time analytics applications has intensified the need for sophisticated load balancing mechanisms that can efficiently distribute processing tasks across multi-core architectures without creating bottlenecks or performance degradation.
Financial services, healthcare, telecommunications, and e-commerce sectors represent the primary demand drivers for advanced data center fabric solutions. These industries process enormous volumes of time-sensitive data requiring ultra-low latency and high availability guarantees. Traditional load balancing approaches often fail to meet these stringent requirements, particularly in multi-core environments where resource allocation complexity increases exponentially.
The emergence of edge computing and Internet of Things deployments has further amplified market demand for intelligent load balancing solutions. Organizations need data center fabrics capable of dynamically adjusting to varying traffic patterns while optimizing resource utilization across distributed computing nodes. This requirement extends beyond simple traffic distribution to encompass sophisticated workload orchestration and real-time performance optimization.
Hyperscale cloud providers and colocation facilities face mounting pressure to maximize infrastructure efficiency while reducing operational costs. Inefficient load balancing directly impacts energy consumption, hardware utilization rates, and overall service quality, making optimized solutions essential for maintaining competitive advantages in increasingly saturated markets.
The growing adoption of containerized applications and microservices architectures has created additional complexity in load distribution requirements. Modern data center environments must support dynamic scaling, service discovery, and intelligent routing capabilities that traditional load balancing technologies cannot adequately address, driving sustained market demand for innovative fabric solutions.
Current State and Challenges in Multi-Core Load Distribution
Multi-core data center fabric environments currently face significant challenges in achieving optimal load distribution across processing units and network resources. The existing load balancing mechanisms, primarily designed for single-core architectures, struggle to effectively manage the complex interdependencies between CPU cores, memory hierarchies, and network fabric components. Traditional round-robin and weighted distribution algorithms fail to account for the nuanced performance characteristics of multi-core systems, where cache coherency, NUMA topology, and inter-core communication latencies significantly impact overall system performance.
Contemporary data centers predominantly rely on software-defined load balancers that operate at the application layer, creating substantial overhead when managing traffic across thousands of cores distributed throughout fabric-connected nodes. These solutions typically exhibit latencies ranging from 50-200 microseconds per routing decision, which becomes prohibitive when handling the millions of concurrent connections characteristic of modern cloud workloads. The lack of hardware-accelerated load balancing capabilities further exacerbates performance bottlenecks, particularly in high-frequency trading and real-time analytics applications.
Network fabric integration presents another critical challenge, as current load balancing implementations inadequately leverage the advanced features of modern interconnect technologies such as InfiniBand, Ethernet RDMA, and emerging CXL protocols. The disconnect between network-level traffic distribution and core-level processing allocation results in suboptimal resource utilization, with studies indicating that typical multi-core environments achieve only 60-70% of theoretical performance capacity due to load imbalance issues.
Power consumption optimization remains largely unaddressed in existing load distribution strategies. Current approaches fail to consider the dynamic power characteristics of individual cores, leading to thermal hotspots and inefficient energy utilization patterns. The absence of real-time power-aware load balancing mechanisms results in up to 25% higher energy consumption compared to theoretically optimal distributions.
Scalability limitations become increasingly apparent as data center deployments expand beyond 10,000-core configurations. Existing centralized load balancing architectures create single points of failure and performance bottlenecks, while distributed approaches suffer from coordination overhead and consistency challenges that degrade performance as system scale increases.
Contemporary data centers predominantly rely on software-defined load balancers that operate at the application layer, creating substantial overhead when managing traffic across thousands of cores distributed throughout fabric-connected nodes. These solutions typically exhibit latencies ranging from 50-200 microseconds per routing decision, which becomes prohibitive when handling the millions of concurrent connections characteristic of modern cloud workloads. The lack of hardware-accelerated load balancing capabilities further exacerbates performance bottlenecks, particularly in high-frequency trading and real-time analytics applications.
Network fabric integration presents another critical challenge, as current load balancing implementations inadequately leverage the advanced features of modern interconnect technologies such as InfiniBand, Ethernet RDMA, and emerging CXL protocols. The disconnect between network-level traffic distribution and core-level processing allocation results in suboptimal resource utilization, with studies indicating that typical multi-core environments achieve only 60-70% of theoretical performance capacity due to load imbalance issues.
Power consumption optimization remains largely unaddressed in existing load distribution strategies. Current approaches fail to consider the dynamic power characteristics of individual cores, leading to thermal hotspots and inefficient energy utilization patterns. The absence of real-time power-aware load balancing mechanisms results in up to 25% higher energy consumption compared to theoretically optimal distributions.
Scalability limitations become increasingly apparent as data center deployments expand beyond 10,000-core configurations. Existing centralized load balancing architectures create single points of failure and performance bottlenecks, while distributed approaches suffer from coordination overhead and consistency challenges that degrade performance as system scale increases.
Existing Load Balancing Algorithms for Multi-Core Environments
01 Dynamic load distribution algorithms
Advanced algorithms are employed to dynamically distribute network traffic and computational loads across multiple servers or resources. These algorithms monitor real-time system performance metrics and automatically adjust load distribution to optimize resource utilization and prevent bottlenecks. The methods include weighted round-robin, least connections, and adaptive algorithms that respond to changing network conditions.- Dynamic load distribution algorithms: Advanced algorithms are employed to dynamically distribute workloads across multiple servers or processing units based on real-time system conditions. These algorithms monitor server capacity, response times, and current load levels to make intelligent routing decisions. The systems can automatically adjust distribution patterns to optimize performance and prevent bottlenecks in high-traffic scenarios.
- Server health monitoring and failover mechanisms: Comprehensive monitoring systems continuously track the health and availability of servers in a load-balanced environment. These mechanisms detect server failures, performance degradation, or maintenance requirements and automatically redirect traffic to healthy servers. The systems implement redundancy protocols to ensure service continuity and minimize downtime during server outages.
- Traffic routing and request distribution: Sophisticated routing mechanisms manage the distribution of incoming requests across multiple backend servers or services. These systems implement various distribution strategies including round-robin, weighted distribution, and priority-based routing. The routing logic considers factors such as geographic location, server capabilities, and current load to optimize request handling efficiency.
- Session management and persistence: Advanced session handling techniques ensure that user sessions are properly maintained across multiple servers in a load-balanced environment. These systems implement session affinity, sticky sessions, or distributed session storage to maintain user state consistency. The mechanisms handle session replication and synchronization to provide seamless user experiences during server transitions.
- Cloud-based and scalable load balancing: Modern cloud-native load balancing solutions provide automatic scaling capabilities and integration with cloud infrastructure services. These systems can dynamically provision and deprovision resources based on demand patterns and implement elastic scaling policies. The solutions support containerized environments, microservices architectures, and hybrid cloud deployments for maximum flexibility and efficiency.
02 Server health monitoring and failover mechanisms
Comprehensive monitoring systems continuously assess server health, performance metrics, and availability status. When servers become unavailable or performance degrades below acceptable thresholds, automatic failover mechanisms redirect traffic to healthy servers. These systems include heartbeat monitoring, response time analysis, and graceful degradation strategies to maintain service continuity.Expand Specific Solutions03 Traffic routing and request distribution
Sophisticated routing mechanisms manage incoming requests and distribute them efficiently across available resources. These systems analyze request characteristics, server capabilities, and current load conditions to make optimal routing decisions. The approach includes geographic routing, content-based distribution, and session affinity management to ensure consistent user experiences.Expand Specific Solutions04 Scalable architecture and resource management
Architectural frameworks designed to handle varying loads through horizontal and vertical scaling mechanisms. These systems automatically provision additional resources during peak demand periods and scale down during low usage to optimize costs. The architecture supports elastic scaling, resource pooling, and distributed processing capabilities.Expand Specific Solutions05 Performance optimization and bandwidth management
Advanced techniques for optimizing system performance through intelligent bandwidth allocation, caching strategies, and connection management. These methods include traffic shaping, quality of service controls, and adaptive bandwidth allocation based on application requirements and network conditions. The optimization ensures efficient resource utilization while maintaining service quality.Expand Specific Solutions
Key Players in Data Center Infrastructure and Fabric Solutions
The load balancing optimization in multi-core data center fabric environments represents a rapidly evolving market in the growth stage, driven by increasing demand for high-performance computing and cloud infrastructure. The market demonstrates substantial scale with significant investments from major technology corporations. Technology maturity varies considerably across key players, with established infrastructure giants like Intel Corp., IBM, and Cisco Technology leading in hardware-optimized solutions, while cloud providers such as Alibaba Cloud and Microsoft Corp. advance software-defined approaches. Networking specialists including Mellanox Technologies and Ericsson contribute specialized fabric technologies, whereas emerging companies like Liqid focus on composable infrastructure innovations. The competitive landscape shows convergence between traditional hardware vendors and cloud-native solution providers, indicating a maturing ecosystem with diverse technological approaches addressing multi-core load balancing challenges.
Intel Corp.
Technical Solution: Intel's load balancing optimization focuses on hardware-accelerated solutions through their Data Plane Development Kit (DPDK) and Smart Network Interface Cards (SmartNICs). Their approach leverages Intel's multi-core processors with integrated load balancing engines that can process millions of packets per second while maintaining consistent performance across cores. The solution includes Intel's Resource Director Technology (RDT) for cache allocation and memory bandwidth monitoring, enabling fine-grained resource management in data center environments. Intel's platform supports both software-defined networking (SDN) controllers and hardware-based load balancing with real-time telemetry and analytics capabilities for dynamic workload distribution.
Strengths: Deep hardware integration with high-performance packet processing capabilities and extensive ecosystem support. Weaknesses: Limited to Intel-based infrastructure and requires specialized knowledge for optimal configuration.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei's load balancing solution integrates their CloudEngine data center switches with intelligent traffic management algorithms that support both traditional and cloud-native applications. Their approach utilizes AI-powered network optimization through the iMaster NCE-Fabric management platform, which provides automated load distribution across multi-core server environments. The system implements advanced traffic engineering with support for segment routing and network slicing capabilities, enabling fine-grained control over traffic flows and quality of service parameters. Huawei's solution includes predictive analytics for proactive load balancing adjustments and comprehensive monitoring tools for real-time performance optimization across large-scale data center deployments.
Strengths: Comprehensive end-to-end networking solutions with competitive pricing and strong presence in emerging markets. Weaknesses: Geopolitical restrictions in certain regions and concerns about technology transfer and security compliance.
Core Innovations in Dynamic Load Distribution Techniques
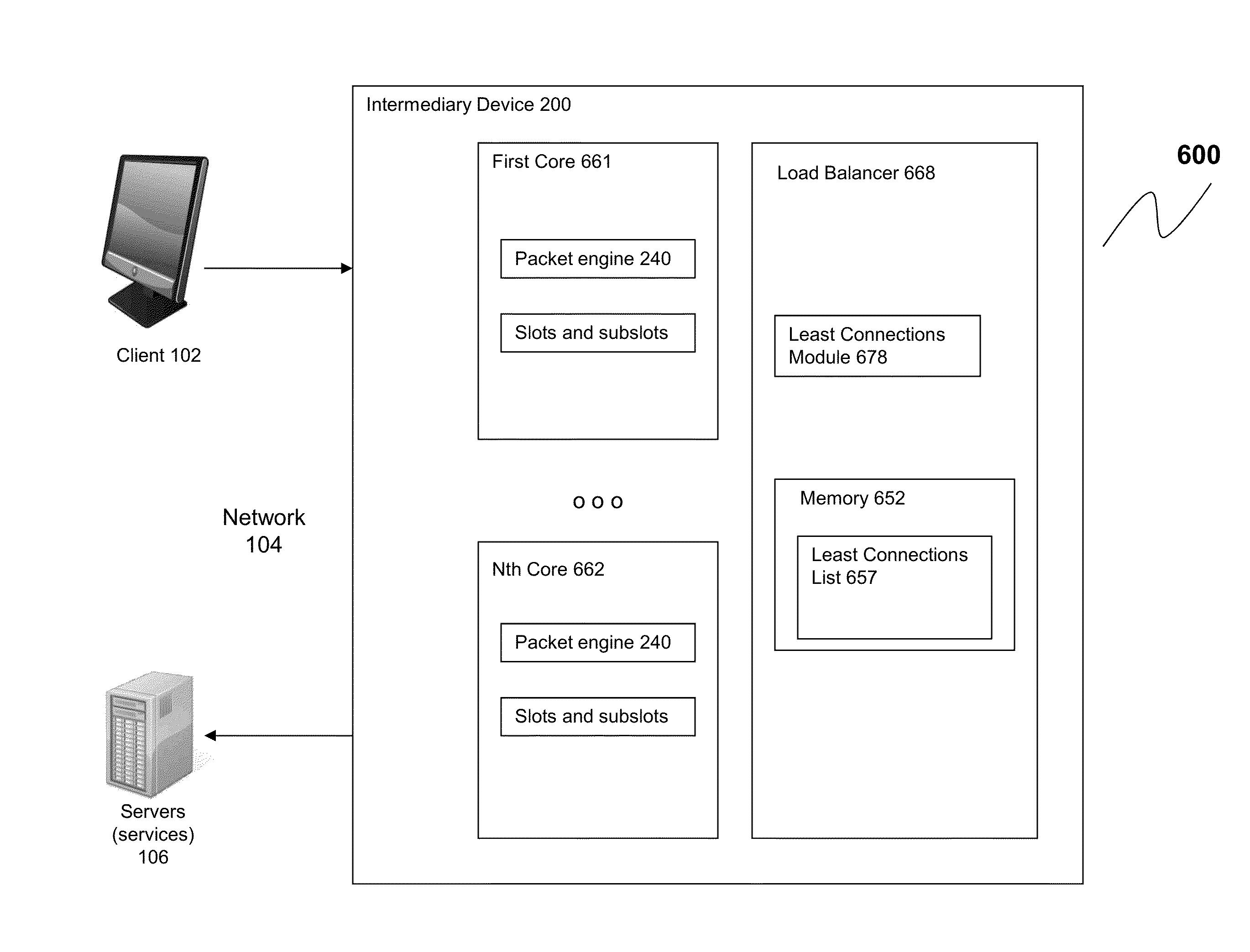
Load Balance Connections Per Server In Multi-Core/Multi-Blade System
PatentActiveUS20100325280A1
Innovation
- A hardware-based load balancer with accumulator logic circuits on each blade aggregates local counter values and transmits global counter values to management processors, reducing the processing load and memory requirements by eliminating the need for central core processor involvement in aggregation.




Systems and methods for least connection load balancing by multi-core device
PatentActiveUS9088501B2
Innovation
- Implementing a subslotting scheme where services are assigned to subslots across multiple packet engines, with each slot tracking active connections, to distribute traffic evenly and mitigate skew by updating service allocations based on connection changes.

Energy Efficiency Standards for Data Center Operations
Energy efficiency has become a critical operational imperative for modern data centers, particularly as multi-core fabric environments continue to expand in scale and complexity. The growing computational demands and increasing power consumption have prompted the development of comprehensive energy efficiency standards that directly impact load balancing optimization strategies.
Current energy efficiency frameworks primarily focus on Power Usage Effectiveness (PUE) metrics, which measure the ratio of total facility energy consumption to IT equipment energy usage. Leading standards include the ISO/IEC 30134 series, ASHRAE 90.4, and the EU Code of Conduct for Data Centres. These standards establish baseline requirements for cooling systems, power distribution, and server utilization rates that directly influence load balancing decisions in multi-core environments.
The Energy Star certification program has established specific criteria for data center infrastructure, requiring facilities to demonstrate measurable improvements in energy performance. These standards mandate dynamic power management capabilities, which necessitate sophisticated load balancing algorithms that can adapt to varying power constraints while maintaining service quality across distributed multi-core systems.
Emerging regulatory frameworks, such as the European Union's Energy Efficiency Directive and California's Title 24 standards, impose stricter requirements on data center operators to implement real-time energy monitoring and optimization systems. These regulations directly impact load balancing strategies by requiring workload distribution algorithms to consider power consumption as a primary optimization parameter alongside traditional performance metrics.
The Green Grid's maturity model provides a structured approach to energy efficiency implementation, defining progressive levels of sophistication in power management. Advanced levels require predictive analytics and machine learning capabilities that can optimize load distribution based on energy consumption patterns, thermal characteristics, and renewable energy availability.
Industry-specific standards, such as those developed by the Telecommunications Infrastructure Standard (TIA-942) and the Uptime Institute's Tier classifications, establish energy efficiency requirements that influence architectural decisions in multi-core fabric design. These standards emphasize the importance of redundancy and scalability while maintaining optimal energy utilization ratios.
Recent developments in energy efficiency standards increasingly focus on carbon footprint reduction and renewable energy integration. The Science Based Targets initiative and RE100 commitments are driving data center operators to implement load balancing strategies that prioritize workload scheduling during periods of renewable energy availability, fundamentally changing traditional optimization approaches in multi-core environments.
Current energy efficiency frameworks primarily focus on Power Usage Effectiveness (PUE) metrics, which measure the ratio of total facility energy consumption to IT equipment energy usage. Leading standards include the ISO/IEC 30134 series, ASHRAE 90.4, and the EU Code of Conduct for Data Centres. These standards establish baseline requirements for cooling systems, power distribution, and server utilization rates that directly influence load balancing decisions in multi-core environments.
The Energy Star certification program has established specific criteria for data center infrastructure, requiring facilities to demonstrate measurable improvements in energy performance. These standards mandate dynamic power management capabilities, which necessitate sophisticated load balancing algorithms that can adapt to varying power constraints while maintaining service quality across distributed multi-core systems.
Emerging regulatory frameworks, such as the European Union's Energy Efficiency Directive and California's Title 24 standards, impose stricter requirements on data center operators to implement real-time energy monitoring and optimization systems. These regulations directly impact load balancing strategies by requiring workload distribution algorithms to consider power consumption as a primary optimization parameter alongside traditional performance metrics.
The Green Grid's maturity model provides a structured approach to energy efficiency implementation, defining progressive levels of sophistication in power management. Advanced levels require predictive analytics and machine learning capabilities that can optimize load distribution based on energy consumption patterns, thermal characteristics, and renewable energy availability.
Industry-specific standards, such as those developed by the Telecommunications Infrastructure Standard (TIA-942) and the Uptime Institute's Tier classifications, establish energy efficiency requirements that influence architectural decisions in multi-core fabric design. These standards emphasize the importance of redundancy and scalability while maintaining optimal energy utilization ratios.
Recent developments in energy efficiency standards increasingly focus on carbon footprint reduction and renewable energy integration. The Science Based Targets initiative and RE100 commitments are driving data center operators to implement load balancing strategies that prioritize workload scheduling during periods of renewable energy availability, fundamentally changing traditional optimization approaches in multi-core environments.
Performance Benchmarking and Optimization Metrics
Performance benchmarking in multi-core data center fabric environments requires comprehensive metrics that capture both system-level efficiency and application-specific requirements. Traditional throughput and latency measurements, while fundamental, must be augmented with multi-dimensional metrics that reflect the complexity of modern distributed workloads. Key performance indicators include request completion rates, queue depth variations, CPU utilization across cores, memory bandwidth consumption, and network fabric utilization patterns.
Latency distribution analysis represents a critical component of load balancing optimization, extending beyond simple average response times to examine tail latencies at 95th, 99th, and 99.9th percentiles. These metrics reveal system behavior under stress conditions and help identify bottlenecks that affect user experience. Additionally, jitter measurements and latency variance provide insights into system stability and predictability, which are essential for real-time applications and service level agreement compliance.
Resource utilization metrics must encompass both computational and network fabric dimensions. CPU core utilization patterns, cache hit ratios, memory access patterns, and inter-core communication overhead provide visibility into computational efficiency. Network-specific metrics include fabric link utilization, packet loss rates, buffer occupancy levels, and congestion indicators across different fabric tiers. These measurements help identify imbalances and guide optimization strategies.
Scalability benchmarks evaluate system performance under varying load conditions and core configurations. Load ramp-up tests, sustained throughput measurements, and graceful degradation analysis under overload conditions provide insights into system limits and optimal operating ranges. Fairness metrics assess how evenly workloads are distributed across available cores and whether certain applications or traffic types receive preferential treatment.
Energy efficiency metrics have become increasingly important in data center environments. Power consumption per transaction, performance-per-watt ratios, and thermal characteristics under different load balancing configurations help optimize operational costs while maintaining performance targets. These metrics enable comprehensive evaluation of load balancing algorithms beyond pure performance considerations.
Optimization targets should align with specific application requirements and business objectives. Real-time applications prioritize consistent low latency, while batch processing workloads focus on maximum throughput. Multi-objective optimization frameworks that balance competing requirements provide more realistic performance evaluation scenarios than single-metric approaches.
Latency distribution analysis represents a critical component of load balancing optimization, extending beyond simple average response times to examine tail latencies at 95th, 99th, and 99.9th percentiles. These metrics reveal system behavior under stress conditions and help identify bottlenecks that affect user experience. Additionally, jitter measurements and latency variance provide insights into system stability and predictability, which are essential for real-time applications and service level agreement compliance.
Resource utilization metrics must encompass both computational and network fabric dimensions. CPU core utilization patterns, cache hit ratios, memory access patterns, and inter-core communication overhead provide visibility into computational efficiency. Network-specific metrics include fabric link utilization, packet loss rates, buffer occupancy levels, and congestion indicators across different fabric tiers. These measurements help identify imbalances and guide optimization strategies.
Scalability benchmarks evaluate system performance under varying load conditions and core configurations. Load ramp-up tests, sustained throughput measurements, and graceful degradation analysis under overload conditions provide insights into system limits and optimal operating ranges. Fairness metrics assess how evenly workloads are distributed across available cores and whether certain applications or traffic types receive preferential treatment.
Energy efficiency metrics have become increasingly important in data center environments. Power consumption per transaction, performance-per-watt ratios, and thermal characteristics under different load balancing configurations help optimize operational costs while maintaining performance targets. These metrics enable comprehensive evaluation of load balancing algorithms beyond pure performance considerations.
Optimization targets should align with specific application requirements and business objectives. Real-time applications prioritize consistent low latency, while batch processing workloads focus on maximum throughput. Multi-objective optimization frameworks that balance competing requirements provide more realistic performance evaluation scenarios than single-metric approaches.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!