

Comparing Disaggregated vs Clustered Memory for Signal Processing Tasks
MAY 12, 202610 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Disaggregated vs Clustered Memory Background and Objectives
The evolution of memory architectures has become a critical consideration in modern computing systems, particularly as data-intensive applications continue to push the boundaries of traditional hardware designs. Signal processing tasks, characterized by their high computational demands and substantial memory bandwidth requirements, represent a compelling use case for evaluating different memory organization strategies. The fundamental distinction between disaggregated and clustered memory architectures has emerged as a pivotal design decision that significantly impacts system performance, scalability, and resource utilization efficiency.
Disaggregated memory architecture represents a paradigm shift from traditional tightly-coupled memory systems, where memory resources are physically separated from compute nodes and accessed through high-speed interconnects. This approach enables dynamic memory allocation across multiple compute units, providing enhanced flexibility in resource management and improved utilization rates. The architecture allows for independent scaling of memory and compute resources, addressing the growing disparity between memory capacity requirements and processing power needs in modern signal processing applications.
Clustered memory architecture, conversely, maintains the conventional approach of co-locating memory resources with processing units within discrete clusters or nodes. Each cluster operates with dedicated memory pools, ensuring predictable access patterns and minimizing inter-node communication overhead. This architecture has historically dominated signal processing systems due to its deterministic performance characteristics and simplified programming models, making it particularly suitable for real-time applications with strict latency requirements.
The technological objectives driving this comparative analysis stem from the increasing complexity of signal processing workloads, including digital signal processing for telecommunications, image and video processing, radar systems, and emerging applications in artificial intelligence and machine learning. These applications demand not only high computational throughput but also efficient memory access patterns to handle large datasets and maintain real-time processing capabilities.
Contemporary signal processing tasks exhibit diverse memory access patterns, ranging from sequential streaming operations to random access requirements for complex algorithms. The choice between disaggregated and clustered memory architectures directly influences factors such as memory bandwidth utilization, latency characteristics, power consumption, and overall system scalability. Understanding these trade-offs is essential for optimizing system design decisions and achieving optimal performance for specific signal processing applications.
The primary objective of this technological investigation is to establish a comprehensive framework for evaluating the relative merits of disaggregated versus clustered memory architectures specifically within the context of signal processing tasks, ultimately guiding future system design decisions and identifying opportunities for architectural innovation.
Disaggregated memory architecture represents a paradigm shift from traditional tightly-coupled memory systems, where memory resources are physically separated from compute nodes and accessed through high-speed interconnects. This approach enables dynamic memory allocation across multiple compute units, providing enhanced flexibility in resource management and improved utilization rates. The architecture allows for independent scaling of memory and compute resources, addressing the growing disparity between memory capacity requirements and processing power needs in modern signal processing applications.
Clustered memory architecture, conversely, maintains the conventional approach of co-locating memory resources with processing units within discrete clusters or nodes. Each cluster operates with dedicated memory pools, ensuring predictable access patterns and minimizing inter-node communication overhead. This architecture has historically dominated signal processing systems due to its deterministic performance characteristics and simplified programming models, making it particularly suitable for real-time applications with strict latency requirements.
The technological objectives driving this comparative analysis stem from the increasing complexity of signal processing workloads, including digital signal processing for telecommunications, image and video processing, radar systems, and emerging applications in artificial intelligence and machine learning. These applications demand not only high computational throughput but also efficient memory access patterns to handle large datasets and maintain real-time processing capabilities.
Contemporary signal processing tasks exhibit diverse memory access patterns, ranging from sequential streaming operations to random access requirements for complex algorithms. The choice between disaggregated and clustered memory architectures directly influences factors such as memory bandwidth utilization, latency characteristics, power consumption, and overall system scalability. Understanding these trade-offs is essential for optimizing system design decisions and achieving optimal performance for specific signal processing applications.
The primary objective of this technological investigation is to establish a comprehensive framework for evaluating the relative merits of disaggregated versus clustered memory architectures specifically within the context of signal processing tasks, ultimately guiding future system design decisions and identifying opportunities for architectural innovation.
Market Demand for Advanced Signal Processing Memory Solutions
The signal processing industry is experiencing unprecedented growth driven by the proliferation of artificial intelligence, machine learning, and real-time data analytics applications. Traditional memory architectures are increasingly challenged by the demanding computational requirements of modern signal processing workloads, creating substantial market opportunities for advanced memory solutions that can deliver superior performance, scalability, and efficiency.
Enterprise data centers and cloud service providers represent the largest market segment for advanced signal processing memory solutions. These organizations require high-throughput, low-latency memory systems to support real-time analytics, streaming data processing, and complex algorithmic computations. The growing adoption of edge computing and distributed processing architectures has intensified demand for memory solutions that can efficiently handle parallel signal processing tasks across multiple nodes.
The telecommunications sector constitutes another significant market driver, particularly with the ongoing deployment of 5G networks and the development of 6G technologies. Signal processing applications in telecommunications require memory systems capable of handling massive data streams with minimal latency. Network function virtualization and software-defined networking implementations demand flexible memory architectures that can adapt to varying workload characteristics and processing requirements.
Automotive and aerospace industries are emerging as high-growth market segments for specialized signal processing memory solutions. Advanced driver assistance systems, autonomous vehicle platforms, and satellite communication systems require real-time signal processing capabilities with stringent reliability and performance requirements. These applications often involve complex sensor fusion, image processing, and communication protocol handling that benefit from optimized memory architectures.
Scientific computing and research institutions represent a specialized but lucrative market segment. High-performance computing applications in fields such as radio astronomy, seismic analysis, and medical imaging require memory systems that can efficiently support large-scale signal processing algorithms. These applications often involve processing massive datasets with complex computational patterns that challenge conventional memory hierarchies.
The financial services industry has become an increasingly important market for signal processing memory solutions, driven by algorithmic trading, risk analysis, and fraud detection applications. These use cases require ultra-low latency memory access patterns and high-bandwidth data processing capabilities to maintain competitive advantages in time-sensitive trading environments.
Market demand is also being shaped by the growing emphasis on energy efficiency and total cost of ownership considerations. Organizations are seeking memory solutions that not only deliver superior performance but also optimize power consumption and operational costs, particularly in large-scale deployments where energy efficiency directly impacts profitability and environmental sustainability goals.
Enterprise data centers and cloud service providers represent the largest market segment for advanced signal processing memory solutions. These organizations require high-throughput, low-latency memory systems to support real-time analytics, streaming data processing, and complex algorithmic computations. The growing adoption of edge computing and distributed processing architectures has intensified demand for memory solutions that can efficiently handle parallel signal processing tasks across multiple nodes.
The telecommunications sector constitutes another significant market driver, particularly with the ongoing deployment of 5G networks and the development of 6G technologies. Signal processing applications in telecommunications require memory systems capable of handling massive data streams with minimal latency. Network function virtualization and software-defined networking implementations demand flexible memory architectures that can adapt to varying workload characteristics and processing requirements.
Automotive and aerospace industries are emerging as high-growth market segments for specialized signal processing memory solutions. Advanced driver assistance systems, autonomous vehicle platforms, and satellite communication systems require real-time signal processing capabilities with stringent reliability and performance requirements. These applications often involve complex sensor fusion, image processing, and communication protocol handling that benefit from optimized memory architectures.
Scientific computing and research institutions represent a specialized but lucrative market segment. High-performance computing applications in fields such as radio astronomy, seismic analysis, and medical imaging require memory systems that can efficiently support large-scale signal processing algorithms. These applications often involve processing massive datasets with complex computational patterns that challenge conventional memory hierarchies.
The financial services industry has become an increasingly important market for signal processing memory solutions, driven by algorithmic trading, risk analysis, and fraud detection applications. These use cases require ultra-low latency memory access patterns and high-bandwidth data processing capabilities to maintain competitive advantages in time-sensitive trading environments.
Market demand is also being shaped by the growing emphasis on energy efficiency and total cost of ownership considerations. Organizations are seeking memory solutions that not only deliver superior performance but also optimize power consumption and operational costs, particularly in large-scale deployments where energy efficiency directly impacts profitability and environmental sustainability goals.
Current State of Memory Architectures in Signal Processing
Signal processing applications today rely on diverse memory architectures that have evolved to address the unique computational demands of real-time data processing, high-throughput operations, and latency-sensitive workloads. The current landscape encompasses both traditional clustered memory systems and emerging disaggregated memory approaches, each presenting distinct advantages for different signal processing scenarios.
Clustered memory architectures remain the dominant paradigm in contemporary signal processing systems. These architectures integrate memory resources closely with processing units, typically featuring multi-level cache hierarchies, local DRAM modules, and specialized memory controllers optimized for sequential and predictable access patterns. High-performance computing clusters used for radar signal processing, software-defined radio systems, and digital signal processing applications predominantly employ clustered configurations where each node maintains dedicated memory resources.
Modern clustered implementations leverage advanced memory technologies including DDR5, HBM3, and specialized signal processing memory modules that provide deterministic latency characteristics essential for real-time applications. Graphics processing units and field-programmable gate arrays commonly used in signal processing workloads exemplify this approach, featuring tightly coupled memory subsystems designed to maximize bandwidth utilization and minimize access latency for streaming data operations.
Disaggregated memory architectures represent an emerging paradigm gaining traction in large-scale signal processing deployments. These systems separate memory resources from compute nodes, creating shared memory pools accessible through high-speed interconnects such as CXL, InfiniBand, or custom fabric solutions. Early implementations focus on distributed signal processing frameworks where multiple processing nodes require access to large shared datasets or intermediate processing results.
Current disaggregated solutions primarily target batch processing scenarios, distributed beamforming applications, and large-scale spectrum analysis tasks where the benefits of resource pooling and dynamic allocation outweigh the inherent network latency overhead. Several cloud service providers have begun offering disaggregated memory services specifically designed for signal processing workloads, enabling elastic scaling of memory resources independent of compute capacity.
The technical challenges facing both architectures center on bandwidth optimization, latency management, and coherency maintenance. Clustered systems struggle with memory wall limitations and resource underutilization, while disaggregated approaches must overcome network-induced latency and complexity in maintaining data consistency across distributed memory pools.
Clustered memory architectures remain the dominant paradigm in contemporary signal processing systems. These architectures integrate memory resources closely with processing units, typically featuring multi-level cache hierarchies, local DRAM modules, and specialized memory controllers optimized for sequential and predictable access patterns. High-performance computing clusters used for radar signal processing, software-defined radio systems, and digital signal processing applications predominantly employ clustered configurations where each node maintains dedicated memory resources.
Modern clustered implementations leverage advanced memory technologies including DDR5, HBM3, and specialized signal processing memory modules that provide deterministic latency characteristics essential for real-time applications. Graphics processing units and field-programmable gate arrays commonly used in signal processing workloads exemplify this approach, featuring tightly coupled memory subsystems designed to maximize bandwidth utilization and minimize access latency for streaming data operations.
Disaggregated memory architectures represent an emerging paradigm gaining traction in large-scale signal processing deployments. These systems separate memory resources from compute nodes, creating shared memory pools accessible through high-speed interconnects such as CXL, InfiniBand, or custom fabric solutions. Early implementations focus on distributed signal processing frameworks where multiple processing nodes require access to large shared datasets or intermediate processing results.
Current disaggregated solutions primarily target batch processing scenarios, distributed beamforming applications, and large-scale spectrum analysis tasks where the benefits of resource pooling and dynamic allocation outweigh the inherent network latency overhead. Several cloud service providers have begun offering disaggregated memory services specifically designed for signal processing workloads, enabling elastic scaling of memory resources independent of compute capacity.
The technical challenges facing both architectures center on bandwidth optimization, latency management, and coherency maintenance. Clustered systems struggle with memory wall limitations and resource underutilization, while disaggregated approaches must overcome network-induced latency and complexity in maintaining data consistency across distributed memory pools.
Existing Memory Solutions for Signal Processing Workloads
01 Cache memory optimization and hierarchical memory systems
Advanced cache memory architectures that implement multi-level caching strategies to improve data access speeds and reduce memory latency. These systems utilize sophisticated algorithms for cache management, prefetching, and data locality optimization to enhance overall memory performance in computing systems.- Cache memory optimization and hierarchical memory systems: Advanced cache memory architectures that implement multi-level caching strategies to improve data access speeds and reduce memory latency. These systems utilize sophisticated algorithms for cache management, prefetching mechanisms, and hierarchical memory structures that optimize the flow of data between different memory levels. The implementations focus on reducing cache misses and improving overall system throughput through intelligent cache replacement policies and memory hierarchy optimization.
- Memory controller and access scheduling mechanisms: Sophisticated memory controllers that manage data flow and access patterns to maximize memory bandwidth utilization and minimize access conflicts. These systems implement advanced scheduling algorithms, queue management techniques, and arbitration mechanisms to optimize memory access patterns. The controllers feature intelligent buffering strategies and dynamic priority management to enhance overall memory subsystem performance.
- Non-volatile memory integration and hybrid memory architectures: Integration of non-volatile memory technologies with traditional volatile memory to create hybrid memory systems that combine the benefits of both technologies. These architectures implement intelligent data placement algorithms, wear leveling mechanisms, and performance optimization techniques specific to non-volatile memory characteristics. The systems feature advanced memory management units that handle the complexities of mixed memory types while maintaining high performance and data integrity.
- Memory bandwidth optimization and parallel access techniques: Advanced techniques for maximizing memory bandwidth through parallel access methods, multi-channel memory configurations, and sophisticated data distribution strategies. These systems implement intelligent memory interleaving, concurrent access mechanisms, and bandwidth allocation algorithms to achieve optimal memory throughput. The architectures feature specialized memory interfaces and data path optimizations designed to eliminate bottlenecks and maximize data transfer rates.
- Memory virtualization and address translation mechanisms: Sophisticated memory virtualization systems that implement advanced address translation, memory mapping, and virtual memory management techniques. These architectures feature intelligent translation lookaside buffers, page management algorithms, and memory protection mechanisms that enable efficient virtual memory operations. The systems optimize address translation overhead while providing robust memory isolation and efficient memory space utilization through advanced mapping strategies.
02 Memory controller and bandwidth optimization techniques
Memory controller designs that optimize data transfer rates and bandwidth utilization between processors and memory modules. These techniques include advanced scheduling algorithms, memory interleaving, and dynamic memory management to maximize throughput and minimize access conflicts in high-performance computing environments.Expand Specific Solutions03 Non-volatile memory integration and hybrid storage systems
Integration of non-volatile memory technologies with traditional volatile memory to create hybrid storage architectures that combine the speed of RAM with the persistence of storage devices. These systems implement intelligent data placement and migration strategies to optimize performance while maintaining data integrity.Expand Specific Solutions04 Memory virtualization and address translation mechanisms
Virtual memory management systems that provide efficient address translation and memory mapping capabilities. These architectures implement advanced page management, memory protection, and virtual-to-physical address translation to enable efficient memory utilization and system security in multi-tasking environments.Expand Specific Solutions05 Parallel memory access and multi-channel architectures
Memory architectures designed to support parallel data access through multiple channels and banks, enabling simultaneous memory operations to increase overall system throughput. These designs incorporate advanced arbitration mechanisms and data path optimization to handle concurrent memory requests efficiently.Expand Specific Solutions
Key Players in Memory Architecture and Signal Processing
The disaggregated versus clustered memory architecture for signal processing represents a rapidly evolving competitive landscape in the mature computing infrastructure market. The industry is transitioning from traditional clustered memory systems toward more flexible disaggregated approaches, driven by increasing demands for scalable AI and signal processing workloads. Major technology incumbents like Intel Corp., IBM, Microsoft, and AMD are leading development alongside specialized players such as Western Digital Technologies and Mellanox Technologies. The market demonstrates high technical maturity with established semiconductor giants competing against emerging companies like NeuReality Ltd., which focuses specifically on AI inference optimization. Asian technology leaders including Samsung Electronics, Huawei Technologies, and various Chinese state-backed entities are also investing heavily in memory architecture innovations, indicating strong global competition and significant market potential across telecommunications, automotive, and enterprise computing sectors.
Intel Corp.
Technical Solution: Intel has developed comprehensive memory architecture solutions for signal processing, including their Optane DC persistent memory technology that bridges the gap between traditional DRAM and storage. Their approach focuses on memory pooling and disaggregation through technologies like Intel Memory Drive Technology, which enables flexible memory allocation across compute nodes. For signal processing workloads, Intel's architecture supports both clustered memory configurations through their Xeon processors with integrated memory controllers, and disaggregated memory through CXL (Compute Express Link) technology that allows memory to be shared across multiple processors, providing dynamic memory allocation and improved resource utilization for intensive signal processing applications.
Strengths: Industry-leading CXL technology implementation, extensive ecosystem support, proven scalability for enterprise workloads. Weaknesses: Higher power consumption compared to specialized solutions, complex configuration requirements.
International Business Machines Corp.
Technical Solution: IBM has pioneered disaggregated memory architectures through their Power Systems and z/Architecture platforms, specifically designed for high-performance computing and signal processing applications. Their approach utilizes advanced memory virtualization and partitioning technologies that allow memory resources to be dynamically allocated across processing units. IBM's solution includes their Memory Inception technology which enables memory disaggregation at the hardware level, supporting both local clustered memory for low-latency operations and remote memory access for large-scale signal processing tasks. The architecture incorporates intelligent memory management algorithms that optimize data placement based on signal processing workload characteristics and access patterns.
Strengths: Advanced virtualization capabilities, enterprise-grade reliability, sophisticated memory management algorithms. Weaknesses: High implementation costs, limited compatibility with non-IBM hardware ecosystems.
Core Innovations in Disaggregated Memory Technologies
Method and apparatus for managing disaggregated memory
PatentActiveUS20190138341A1
Innovation
- A method and apparatus that dynamically detect memory access patterns in virtual systems, adjusting memory block sizes and operations (load, store, mapping, and un-mapping) based on temporal variations, using a disaggregated memory manager to reduce remote memory accesses and optimize memory bandwidth usage by varying the size of memory blocks and managing their state and position with descriptors.




Apparatus for managing disaggregated memory and method thereof
PatentInactiveUS20190114079A1
Innovation
- A method and apparatus that assign memory pages between local and remote memory, using LRU distance-based performance prediction to reassess and reassign memory resources, ensuring that the target performance ratio is met by dynamically adjusting the local memory size based on access patterns.
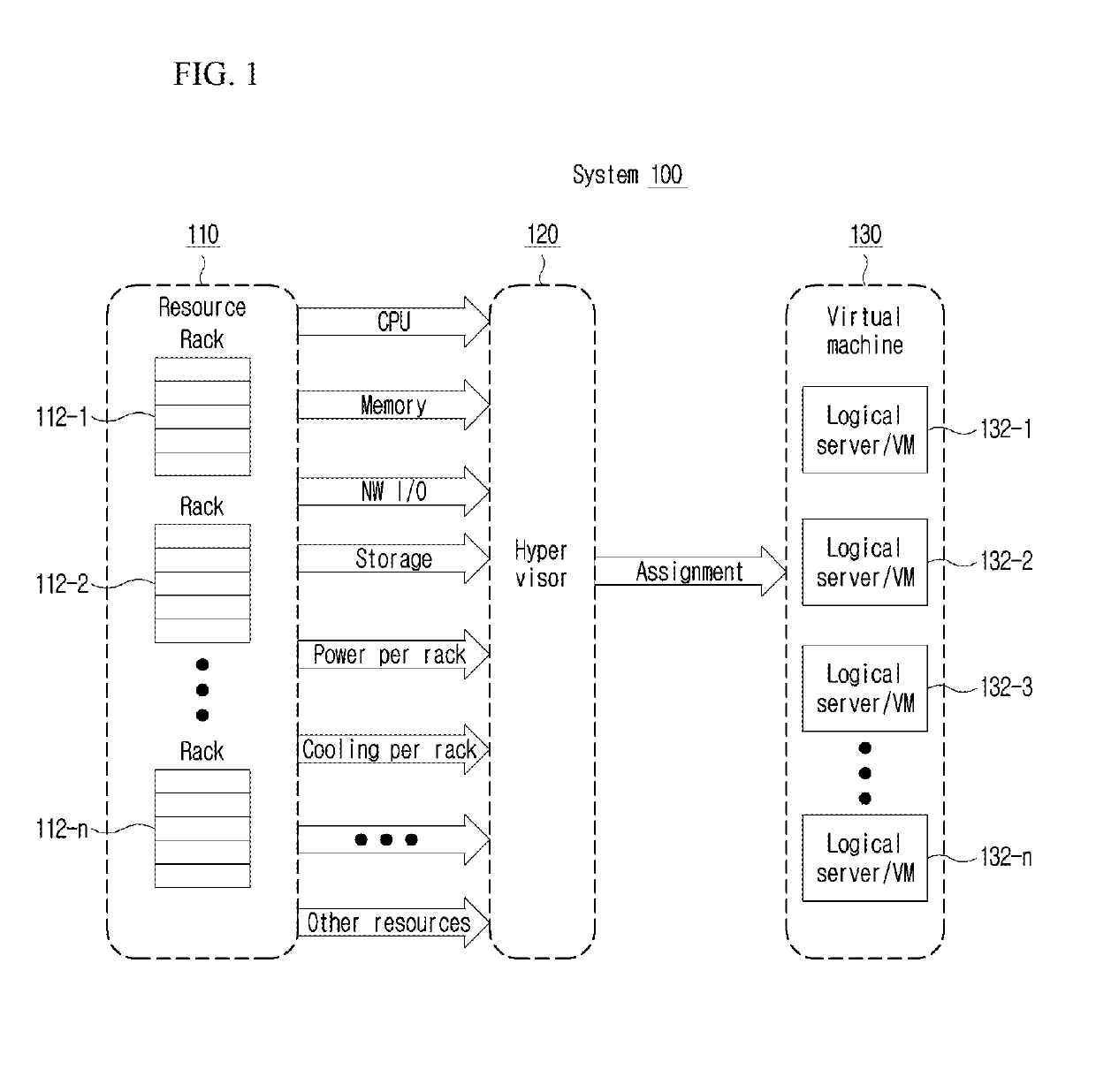



Performance Benchmarking Methodologies for Memory Systems
Performance benchmarking methodologies for memory systems require specialized approaches when evaluating disaggregated versus clustered architectures in signal processing contexts. Traditional benchmarking frameworks often fall short in capturing the nuanced performance characteristics that emerge from different memory organization strategies, necessitating the development of comprehensive evaluation protocols tailored to signal processing workloads.
Latency measurement techniques form the cornerstone of memory system evaluation, particularly for signal processing applications where timing predictability directly impacts system performance. Standard benchmarking approaches utilize synthetic workloads to measure access latencies, but signal processing tasks demand more sophisticated methodologies that account for temporal locality patterns and burst access behaviors. Advanced profiling tools must capture both average and tail latencies, as signal processing algorithms often exhibit sensitivity to worst-case memory access times.
Throughput evaluation methodologies require careful consideration of memory bandwidth utilization patterns specific to signal processing workloads. Unlike general-purpose computing tasks, signal processing applications typically demonstrate highly regular access patterns with significant spatial locality. Benchmarking frameworks must incorporate streaming access patterns, vectorized operations, and concurrent memory channel utilization to accurately assess system capabilities under realistic operating conditions.
Scalability assessment protocols become particularly critical when comparing disaggregated and clustered memory architectures. Benchmarking methodologies must evaluate performance scaling characteristics across varying data sizes, processing node counts, and memory capacity configurations. This requires systematic testing frameworks that can isolate the impact of memory organization choices from other system variables while maintaining statistical significance across multiple test iterations.
Energy efficiency measurement represents an increasingly important dimension in memory system benchmarking. Signal processing workloads often operate under strict power constraints, making energy-per-operation metrics essential for comprehensive evaluation. Benchmarking methodologies must incorporate power monitoring capabilities that can distinguish between memory subsystem energy consumption and overall system power draw, enabling accurate assessment of architectural efficiency trade-offs.
Workload representativeness ensures that benchmarking results translate to real-world signal processing scenarios. Effective methodologies incorporate diverse signal processing kernels including FFT operations, digital filtering, convolution algorithms, and matrix computations. These representative workloads must span different computational intensities and memory access patterns to provide comprehensive performance characterization across the spectrum of signal processing applications.
Latency measurement techniques form the cornerstone of memory system evaluation, particularly for signal processing applications where timing predictability directly impacts system performance. Standard benchmarking approaches utilize synthetic workloads to measure access latencies, but signal processing tasks demand more sophisticated methodologies that account for temporal locality patterns and burst access behaviors. Advanced profiling tools must capture both average and tail latencies, as signal processing algorithms often exhibit sensitivity to worst-case memory access times.
Throughput evaluation methodologies require careful consideration of memory bandwidth utilization patterns specific to signal processing workloads. Unlike general-purpose computing tasks, signal processing applications typically demonstrate highly regular access patterns with significant spatial locality. Benchmarking frameworks must incorporate streaming access patterns, vectorized operations, and concurrent memory channel utilization to accurately assess system capabilities under realistic operating conditions.
Scalability assessment protocols become particularly critical when comparing disaggregated and clustered memory architectures. Benchmarking methodologies must evaluate performance scaling characteristics across varying data sizes, processing node counts, and memory capacity configurations. This requires systematic testing frameworks that can isolate the impact of memory organization choices from other system variables while maintaining statistical significance across multiple test iterations.
Energy efficiency measurement represents an increasingly important dimension in memory system benchmarking. Signal processing workloads often operate under strict power constraints, making energy-per-operation metrics essential for comprehensive evaluation. Benchmarking methodologies must incorporate power monitoring capabilities that can distinguish between memory subsystem energy consumption and overall system power draw, enabling accurate assessment of architectural efficiency trade-offs.
Workload representativeness ensures that benchmarking results translate to real-world signal processing scenarios. Effective methodologies incorporate diverse signal processing kernels including FFT operations, digital filtering, convolution algorithms, and matrix computations. These representative workloads must span different computational intensities and memory access patterns to provide comprehensive performance characterization across the spectrum of signal processing applications.
Energy Efficiency Considerations in Memory Design
Energy efficiency represents a critical design parameter when evaluating disaggregated versus clustered memory architectures for signal processing applications. The fundamental difference in power consumption patterns between these two approaches stems from their distinct data access methodologies and physical infrastructure requirements.
Disaggregated memory systems typically exhibit higher baseline power consumption due to the network infrastructure required for remote memory access. The constant operation of high-speed interconnects, network interface cards, and switching equipment creates a persistent energy overhead that remains relatively constant regardless of actual memory utilization. However, this architecture offers superior energy scalability, allowing organizations to power down unused memory pools independently and achieve fine-grained power management across distributed resources.
Clustered memory configurations demonstrate more predictable energy profiles with lower infrastructure overhead. The proximity of memory to processing units reduces the energy cost per memory transaction, as data travels shorter distances through lower-power pathways. This architecture particularly benefits signal processing workloads with high temporal locality, where frequent access to the same memory regions can leverage cache hierarchies more effectively.
The energy efficiency equation becomes more complex when considering dynamic workload characteristics. Signal processing tasks often exhibit bursty memory access patterns, where periods of intensive computation alternate with relatively idle phases. Disaggregated systems can capitalize on these patterns by implementing aggressive power management strategies, potentially achieving lower overall energy consumption during low-utilization periods.
Memory bandwidth utilization significantly impacts energy efficiency in both architectures. Disaggregated systems may suffer from energy inefficiency when network bandwidth is underutilized, as the fixed infrastructure costs remain constant. Conversely, clustered systems can achieve better energy proportionality, where power consumption more closely tracks actual computational demand.
Advanced power management techniques, including dynamic voltage and frequency scaling, memory compression, and intelligent prefetching, can be implemented differently across these architectures. Disaggregated systems benefit from centralized power management policies that can optimize energy usage across multiple compute nodes, while clustered systems excel at localized optimizations that reduce unnecessary data movement and associated energy costs.
Disaggregated memory systems typically exhibit higher baseline power consumption due to the network infrastructure required for remote memory access. The constant operation of high-speed interconnects, network interface cards, and switching equipment creates a persistent energy overhead that remains relatively constant regardless of actual memory utilization. However, this architecture offers superior energy scalability, allowing organizations to power down unused memory pools independently and achieve fine-grained power management across distributed resources.
Clustered memory configurations demonstrate more predictable energy profiles with lower infrastructure overhead. The proximity of memory to processing units reduces the energy cost per memory transaction, as data travels shorter distances through lower-power pathways. This architecture particularly benefits signal processing workloads with high temporal locality, where frequent access to the same memory regions can leverage cache hierarchies more effectively.
The energy efficiency equation becomes more complex when considering dynamic workload characteristics. Signal processing tasks often exhibit bursty memory access patterns, where periods of intensive computation alternate with relatively idle phases. Disaggregated systems can capitalize on these patterns by implementing aggressive power management strategies, potentially achieving lower overall energy consumption during low-utilization periods.
Memory bandwidth utilization significantly impacts energy efficiency in both architectures. Disaggregated systems may suffer from energy inefficiency when network bandwidth is underutilized, as the fixed infrastructure costs remain constant. Conversely, clustered systems can achieve better energy proportionality, where power consumption more closely tracks actual computational demand.
Advanced power management techniques, including dynamic voltage and frequency scaling, memory compression, and intelligent prefetching, can be implemented differently across these architectures. Disaggregated systems benefit from centralized power management policies that can optimize energy usage across multiple compute nodes, while clustered systems excel at localized optimizations that reduce unnecessary data movement and associated energy costs.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!