Enhance Machine Vision Systems for Faster Data Processing
APR 3, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Machine Vision Processing Speed Enhancement Goals
Machine vision systems have evolved from simple pattern recognition tools to sophisticated real-time processing platforms capable of handling complex visual data streams. The historical trajectory shows a progression from early industrial inspection systems operating at frame rates of 10-30 fps to modern high-speed applications demanding processing capabilities exceeding 1000 fps. This evolution has been driven by advances in sensor technology, computational hardware, and algorithmic optimization techniques.
The current landscape of machine vision processing faces significant performance bottlenecks as applications demand increasingly faster response times while maintaining high accuracy levels. Traditional processing architectures struggle to meet the computational demands of modern applications such as autonomous vehicle navigation, high-speed manufacturing quality control, and real-time medical imaging diagnostics. These systems must process massive amounts of visual data within millisecond timeframes while executing complex algorithms for object detection, classification, and tracking.
Contemporary machine vision systems encounter fundamental challenges in balancing processing speed with computational accuracy. The primary limitation stems from the sequential nature of traditional image processing pipelines, where each stage must complete before the next can begin. Additionally, the exponential growth in image resolution and the complexity of modern computer vision algorithms create computational bottlenecks that existing hardware architectures cannot efficiently address.
The technological advancement trajectory indicates a shift toward parallel processing architectures, edge computing integration, and specialized hardware acceleration. Emerging trends include the adoption of neuromorphic computing principles, where processing mimics biological vision systems for enhanced efficiency. Furthermore, the integration of artificial intelligence and machine learning algorithms directly into hardware components promises to revolutionize processing speed capabilities.
Primary enhancement goals focus on achieving sub-millisecond processing latencies for critical applications while maintaining or improving accuracy metrics. Target specifications include processing 4K resolution images at rates exceeding 500 fps, reducing power consumption by 40% compared to current systems, and enabling real-time processing of multiple concurrent video streams. These objectives aim to support next-generation applications in autonomous systems, industrial automation, and augmented reality platforms where instantaneous visual processing is essential for operational success.
The current landscape of machine vision processing faces significant performance bottlenecks as applications demand increasingly faster response times while maintaining high accuracy levels. Traditional processing architectures struggle to meet the computational demands of modern applications such as autonomous vehicle navigation, high-speed manufacturing quality control, and real-time medical imaging diagnostics. These systems must process massive amounts of visual data within millisecond timeframes while executing complex algorithms for object detection, classification, and tracking.
Contemporary machine vision systems encounter fundamental challenges in balancing processing speed with computational accuracy. The primary limitation stems from the sequential nature of traditional image processing pipelines, where each stage must complete before the next can begin. Additionally, the exponential growth in image resolution and the complexity of modern computer vision algorithms create computational bottlenecks that existing hardware architectures cannot efficiently address.
The technological advancement trajectory indicates a shift toward parallel processing architectures, edge computing integration, and specialized hardware acceleration. Emerging trends include the adoption of neuromorphic computing principles, where processing mimics biological vision systems for enhanced efficiency. Furthermore, the integration of artificial intelligence and machine learning algorithms directly into hardware components promises to revolutionize processing speed capabilities.
Primary enhancement goals focus on achieving sub-millisecond processing latencies for critical applications while maintaining or improving accuracy metrics. Target specifications include processing 4K resolution images at rates exceeding 500 fps, reducing power consumption by 40% compared to current systems, and enabling real-time processing of multiple concurrent video streams. These objectives aim to support next-generation applications in autonomous systems, industrial automation, and augmented reality platforms where instantaneous visual processing is essential for operational success.
Market Demand for High-Speed Vision Processing Systems
The global machine vision market is experiencing unprecedented growth driven by the increasing demand for automation across manufacturing, automotive, electronics, and pharmaceutical industries. Traditional vision systems are struggling to meet the real-time processing requirements of modern production lines, where millisecond-level decision-making capabilities are becoming critical for maintaining competitive advantage.
Manufacturing sectors are particularly driving demand for high-speed vision processing systems as they seek to implement Industry 4.0 initiatives. Quality control applications require instantaneous defect detection and classification, while robotic guidance systems need real-time object recognition and tracking capabilities. The automotive industry's shift toward electric vehicles and autonomous driving technologies has created substantial demand for advanced vision systems capable of processing multiple high-resolution camera feeds simultaneously.
Electronics manufacturing represents another significant market segment, where component placement accuracy and solder joint inspection require processing speeds that exceed current system capabilities. The miniaturization of electronic components demands higher resolution imaging combined with faster processing to maintain production throughput rates.
Pharmaceutical and food processing industries are increasingly adopting vision systems for packaging verification, contamination detection, and regulatory compliance. These applications require not only speed but also the ability to process complex algorithms for pattern recognition and anomaly detection in real-time environments.
The emergence of edge computing and artificial intelligence integration has expanded market expectations beyond traditional rule-based vision systems. Modern applications demand machine learning inference capabilities at the edge, requiring substantial computational power while maintaining low latency performance.
Geographic market distribution shows strong demand concentration in Asia-Pacific manufacturing hubs, North American automotive corridors, and European precision manufacturing regions. Each region presents unique requirements regarding processing speed, accuracy standards, and integration complexity.
Market growth is further accelerated by the increasing adoption of collaborative robotics, where vision systems must process environmental data rapidly to ensure safe human-robot interaction. This trend is expanding the addressable market beyond traditional industrial automation into service robotics and healthcare applications.
The convergence of 5G connectivity, edge AI processing, and advanced sensor technologies is creating new market opportunities for vision systems that can leverage distributed computing architectures while maintaining real-time performance standards.
Manufacturing sectors are particularly driving demand for high-speed vision processing systems as they seek to implement Industry 4.0 initiatives. Quality control applications require instantaneous defect detection and classification, while robotic guidance systems need real-time object recognition and tracking capabilities. The automotive industry's shift toward electric vehicles and autonomous driving technologies has created substantial demand for advanced vision systems capable of processing multiple high-resolution camera feeds simultaneously.
Electronics manufacturing represents another significant market segment, where component placement accuracy and solder joint inspection require processing speeds that exceed current system capabilities. The miniaturization of electronic components demands higher resolution imaging combined with faster processing to maintain production throughput rates.
Pharmaceutical and food processing industries are increasingly adopting vision systems for packaging verification, contamination detection, and regulatory compliance. These applications require not only speed but also the ability to process complex algorithms for pattern recognition and anomaly detection in real-time environments.
The emergence of edge computing and artificial intelligence integration has expanded market expectations beyond traditional rule-based vision systems. Modern applications demand machine learning inference capabilities at the edge, requiring substantial computational power while maintaining low latency performance.
Geographic market distribution shows strong demand concentration in Asia-Pacific manufacturing hubs, North American automotive corridors, and European precision manufacturing regions. Each region presents unique requirements regarding processing speed, accuracy standards, and integration complexity.
Market growth is further accelerated by the increasing adoption of collaborative robotics, where vision systems must process environmental data rapidly to ensure safe human-robot interaction. This trend is expanding the addressable market beyond traditional industrial automation into service robotics and healthcare applications.
The convergence of 5G connectivity, edge AI processing, and advanced sensor technologies is creating new market opportunities for vision systems that can leverage distributed computing architectures while maintaining real-time performance standards.
Current Bottlenecks in Machine Vision Data Processing
Machine vision systems face significant computational bottlenecks that severely limit their real-time processing capabilities. The primary constraint stems from the massive volume of high-resolution image data that must be processed within strict temporal windows. Modern industrial applications often require processing rates exceeding 1000 frames per second at resolutions of 4K or higher, creating data throughput demands that overwhelm traditional processing architectures.
Memory bandwidth limitations represent a critical bottleneck in current machine vision implementations. The continuous transfer of large image datasets between system memory and processing units creates substantial latency overhead. This issue becomes particularly pronounced when dealing with multi-spectral imaging or 3D vision applications, where data volumes can increase exponentially. The von Neumann architecture's inherent separation between memory and processing units exacerbates this challenge, forcing systems to spend more time moving data than actually processing it.
Algorithm complexity poses another fundamental constraint, especially in deep learning-based vision systems. Convolutional neural networks and advanced image processing algorithms require extensive computational resources for feature extraction, object detection, and classification tasks. The iterative nature of these algorithms, combined with their dependency on floating-point operations, creates processing delays that scale poorly with image resolution and complexity.
Hardware limitations in existing processing units further compound these challenges. Traditional CPUs lack the parallel processing capabilities required for efficient image processing, while GPUs, despite their parallel architecture, suffer from power consumption and thermal management issues in industrial environments. Field-programmable gate arrays offer customization benefits but require extensive development time and specialized expertise.
Real-time synchronization requirements create additional bottlenecks, particularly in multi-camera systems or applications requiring precise timing coordination. The need to maintain frame synchronization across multiple data streams while ensuring deterministic processing latency introduces complex scheduling challenges that current systems struggle to address efficiently.
Power consumption constraints in embedded and mobile machine vision applications further limit processing capabilities. The trade-off between computational performance and energy efficiency forces system designers to compromise on processing speed, particularly in battery-powered or thermally constrained environments where sustained high-performance operation is not feasible.
Memory bandwidth limitations represent a critical bottleneck in current machine vision implementations. The continuous transfer of large image datasets between system memory and processing units creates substantial latency overhead. This issue becomes particularly pronounced when dealing with multi-spectral imaging or 3D vision applications, where data volumes can increase exponentially. The von Neumann architecture's inherent separation between memory and processing units exacerbates this challenge, forcing systems to spend more time moving data than actually processing it.
Algorithm complexity poses another fundamental constraint, especially in deep learning-based vision systems. Convolutional neural networks and advanced image processing algorithms require extensive computational resources for feature extraction, object detection, and classification tasks. The iterative nature of these algorithms, combined with their dependency on floating-point operations, creates processing delays that scale poorly with image resolution and complexity.
Hardware limitations in existing processing units further compound these challenges. Traditional CPUs lack the parallel processing capabilities required for efficient image processing, while GPUs, despite their parallel architecture, suffer from power consumption and thermal management issues in industrial environments. Field-programmable gate arrays offer customization benefits but require extensive development time and specialized expertise.
Real-time synchronization requirements create additional bottlenecks, particularly in multi-camera systems or applications requiring precise timing coordination. The need to maintain frame synchronization across multiple data streams while ensuring deterministic processing latency introduces complex scheduling challenges that current systems struggle to address efficiently.
Power consumption constraints in embedded and mobile machine vision applications further limit processing capabilities. The trade-off between computational performance and energy efficiency forces system designers to compromise on processing speed, particularly in battery-powered or thermally constrained environments where sustained high-performance operation is not feasible.
Existing High-Speed Vision Processing Solutions
01 Parallel processing architectures for enhanced vision system performance
Machine vision systems can utilize parallel processing architectures to significantly increase data processing speed. By distributing computational tasks across multiple processing units or cores, these systems can handle large volumes of image data simultaneously. This approach includes the use of multi-core processors, GPU acceleration, and specialized parallel computing frameworks that enable real-time image analysis and object recognition. The parallel architecture reduces bottlenecks in data flow and improves overall system throughput.- Parallel processing architectures for enhanced vision system performance: Machine vision systems can utilize parallel processing architectures to significantly increase data processing speed. By distributing computational tasks across multiple processing units or cores, these systems can handle large volumes of image data simultaneously. This approach includes the use of multi-core processors, GPU acceleration, and specialized parallel computing frameworks that enable real-time image analysis and object recognition. The parallel architecture reduces processing latency and improves throughput for complex vision algorithms.
- Hardware acceleration using dedicated vision processors: Dedicated hardware accelerators and specialized vision processors can be integrated into machine vision systems to optimize data processing speed. These include field-programmable gate arrays (FPGAs), application-specific integrated circuits (ASICs), and digital signal processors (DSPs) designed specifically for image processing tasks. Hardware acceleration enables faster execution of computationally intensive operations such as filtering, edge detection, and feature extraction, while reducing power consumption compared to general-purpose processors.
- Optimized data pipeline and memory management: Efficient data pipeline design and memory management strategies can substantially improve processing speed in machine vision systems. This includes implementing high-speed data transfer protocols, utilizing direct memory access (DMA) techniques, and optimizing buffer management to minimize data movement overhead. Advanced caching strategies and memory hierarchies ensure that image data is readily available to processing units, reducing wait times and enabling continuous high-speed operation.
- Adaptive algorithm optimization and preprocessing techniques: Machine vision systems can employ adaptive algorithms and intelligent preprocessing techniques to enhance processing speed without sacrificing accuracy. This includes region-of-interest (ROI) detection to focus computational resources on relevant image areas, multi-resolution processing strategies, and dynamic algorithm selection based on scene complexity. Preprocessing steps such as image compression, downsampling, and noise reduction can reduce the data volume that needs to be processed while maintaining essential information for analysis.
- Real-time data streaming and distributed processing systems: Implementation of real-time data streaming architectures and distributed processing systems enables machine vision applications to handle high-speed continuous data flows. These systems utilize edge computing, cloud-based processing, and hybrid architectures that distribute computational loads across multiple nodes. Network optimization, low-latency communication protocols, and efficient data serialization methods ensure rapid data transmission between acquisition, processing, and decision-making components, enabling real-time responses in industrial automation and surveillance applications.
02 Hardware acceleration using specialized processors
Implementing dedicated hardware accelerators such as FPGAs, ASICs, or specialized vision processors can dramatically improve processing speed in machine vision systems. These specialized components are optimized for specific vision tasks like edge detection, pattern matching, and image filtering, offering superior performance compared to general-purpose processors. Hardware acceleration enables real-time processing of high-resolution images and video streams with minimal latency.Expand Specific Solutions03 Optimized data pipeline and memory management
Efficient data pipeline design and memory management strategies are crucial for maximizing processing speed in machine vision systems. This includes implementing high-speed data transfer protocols, utilizing direct memory access techniques, and optimizing buffer management to minimize data transfer overhead. Smart caching strategies and memory hierarchy optimization ensure that image data is readily available to processing units, reducing wait times and improving throughput.Expand Specific Solutions04 Adaptive resolution and region-of-interest processing
Machine vision systems can enhance processing speed by implementing adaptive resolution techniques and region-of-interest processing. These methods focus computational resources on relevant areas of an image while reducing processing requirements for less critical regions. By dynamically adjusting image resolution based on content complexity and processing only selected regions, systems can achieve faster processing times without sacrificing accuracy in critical areas.Expand Specific Solutions05 Algorithm optimization and machine learning acceleration
Optimizing vision algorithms and leveraging machine learning acceleration techniques can significantly improve data processing speed. This includes implementing efficient algorithms for image preprocessing, feature extraction, and object detection, as well as utilizing neural network accelerators for deep learning-based vision tasks. Techniques such as model compression, quantization, and pruning enable faster inference times while maintaining accuracy, making real-time vision applications more feasible.Expand Specific Solutions
Key Players in Machine Vision and Processing Hardware
The machine vision systems market for enhanced data processing is experiencing rapid growth, driven by increasing demand for real-time analytics across manufacturing, automotive, and consumer electronics sectors. The industry is in a mature expansion phase with established players like Cognex Corp., NVIDIA Corp., and Sony Group Corp. leading specialized vision solutions, while tech giants IBM, Samsung Electronics, and Huawei Technologies leverage their broader AI and semiconductor capabilities. Technology maturity varies significantly - companies like Zebra Technologies and Banner Engineering offer proven industrial automation solutions, whereas emerging players like Insightness AG focus on brain-inspired tracking technologies. The competitive landscape spans from hardware specialists (Qualcomm, Fujitsu) to software-centric firms (Virtualitics), with academic institutions like Peking University and University of Tokyo contributing foundational research, creating a diverse ecosystem addressing different aspects of accelerated machine vision processing.
Cognex Corp.
Technical Solution: Cognex specializes in industrial machine vision systems with proprietary PatMax pattern matching technology that processes images up to 50x faster than traditional correlation methods. Their VisionPro software suite incorporates advanced algorithms for geometric pattern matching, optical character verification, and defect detection with sub-pixel accuracy. The company's In-Sight vision systems feature integrated processing units capable of handling multiple inspection tasks simultaneously, reducing cycle times by up to 30% in manufacturing environments.
Strengths: Specialized industrial focus, proven reliability in harsh environments, extensive application expertise. Weaknesses: Limited to industrial applications, higher cost per unit, less flexibility for custom applications.
International Business Machines Corp.
Technical Solution: IBM implements machine vision acceleration through their Power10 processors with integrated AI accelerators and their Watson Visual Recognition service. Their approach combines edge computing with hybrid cloud architecture, utilizing compressed neural networks and quantization techniques to achieve up to 5x faster inference while maintaining accuracy. The company's Maximo Visual Inspection platform leverages automated defect detection algorithms optimized for industrial environments, processing thousands of images per minute with minimal latency.
Strengths: Enterprise-grade reliability, strong hybrid cloud capabilities, extensive industry partnerships. Weaknesses: Higher implementation costs, complex integration requirements, declining hardware market presence.
Core Innovations in Vision Processing Acceleration
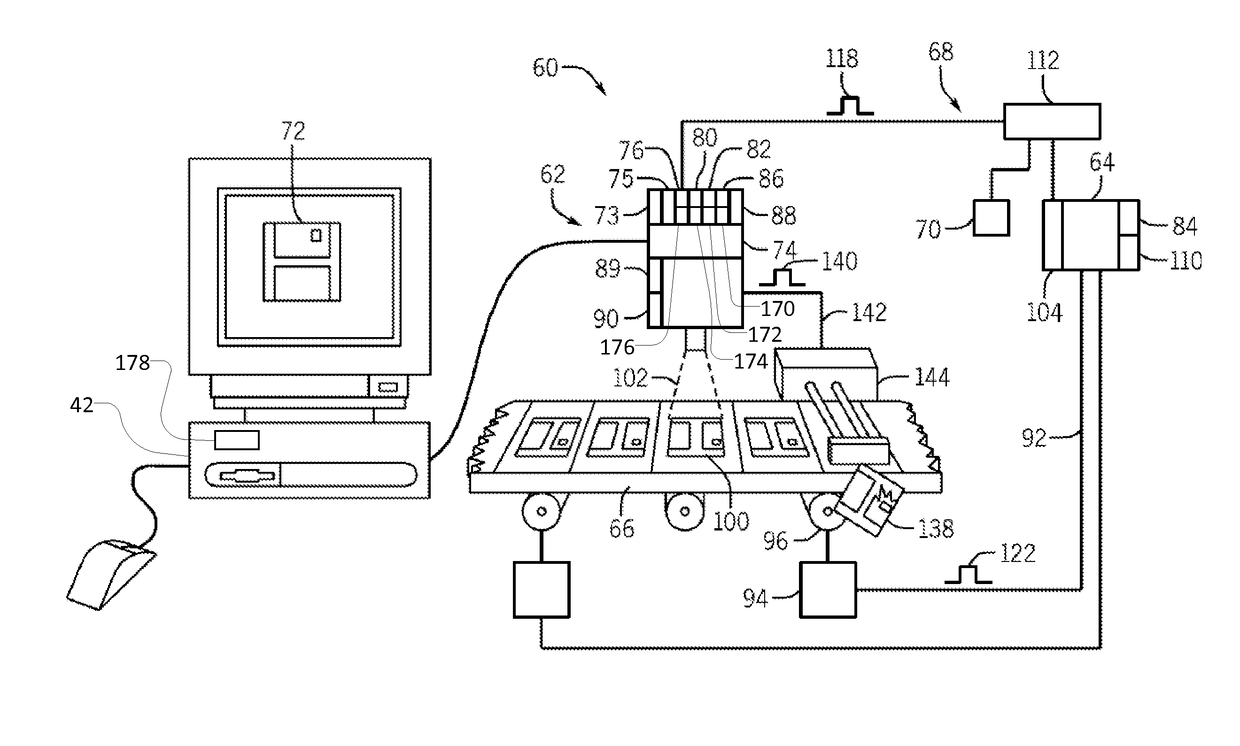
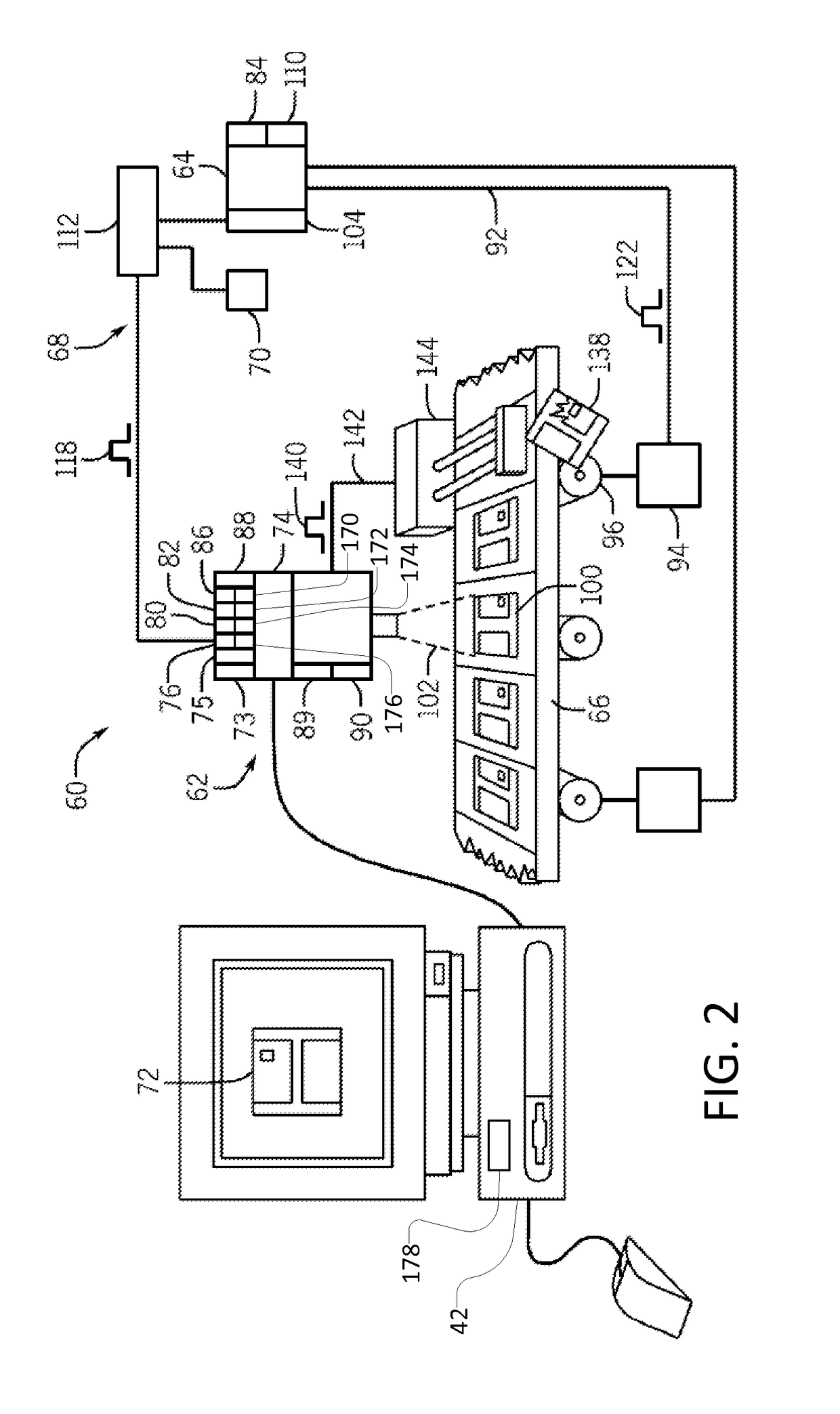
Machine vision systems and methods with predictive motion control
PatentActiveUS10083496B2
Innovation
- The system calculates object position using motion data from a motion controller, eliminating the need for a separate encoder by generating a virtual axis and image acquisition trigger signals based on this data, ensuring synchronized motion and image capture.

End to end differentiable machine vision systems, methods, and media
PatentActiveUS11922609B2
Innovation
- A differentiable image signal processor (ISP) is trained using semi-supervised learning to adapt raw images from a new sensor into the same visual domain as the training data, allowing joint optimization with the perception module without the need for labelled data, using a block-wise differentiable architecture with functional modules for specific image processing tasks.




Edge Computing Integration for Vision Systems
Edge computing integration represents a paradigmatic shift in machine vision system architecture, fundamentally transforming how visual data is processed and analyzed. This approach relocates computational resources from centralized cloud infrastructures to distributed edge nodes positioned closer to data sources, enabling real-time processing capabilities that are essential for modern vision applications.
The integration of edge computing with machine vision systems addresses critical latency challenges inherent in traditional cloud-based architectures. By deploying specialized edge devices equipped with dedicated vision processing units, systems can achieve sub-millisecond response times, making them suitable for applications requiring immediate decision-making such as autonomous vehicles, industrial quality control, and real-time surveillance systems.
Modern edge computing platforms leverage heterogeneous computing architectures combining CPUs, GPUs, and specialized AI accelerators like Intel's Movidius or NVIDIA's Jetson series. These platforms provide optimized inference engines specifically designed for computer vision workloads, enabling efficient execution of deep learning models while maintaining low power consumption profiles suitable for deployment in resource-constrained environments.
The distributed nature of edge computing facilitates scalable vision system deployments across multiple locations while reducing bandwidth requirements. Instead of transmitting raw video streams to centralized processing centers, edge nodes perform local analysis and transmit only relevant metadata or processed results, significantly reducing network overhead and associated costs.
Security and privacy considerations are inherently enhanced through edge computing integration, as sensitive visual data remains localized rather than being transmitted to external cloud services. This approach addresses regulatory compliance requirements and data sovereignty concerns while maintaining system performance and reliability.
Implementation strategies for edge computing integration involve careful consideration of workload partitioning between edge nodes and cloud resources. Critical real-time processing tasks are executed locally, while computationally intensive model training and system updates are managed through cloud connectivity, creating hybrid architectures that optimize both performance and resource utilization.
The integration of edge computing with machine vision systems addresses critical latency challenges inherent in traditional cloud-based architectures. By deploying specialized edge devices equipped with dedicated vision processing units, systems can achieve sub-millisecond response times, making them suitable for applications requiring immediate decision-making such as autonomous vehicles, industrial quality control, and real-time surveillance systems.
Modern edge computing platforms leverage heterogeneous computing architectures combining CPUs, GPUs, and specialized AI accelerators like Intel's Movidius or NVIDIA's Jetson series. These platforms provide optimized inference engines specifically designed for computer vision workloads, enabling efficient execution of deep learning models while maintaining low power consumption profiles suitable for deployment in resource-constrained environments.
The distributed nature of edge computing facilitates scalable vision system deployments across multiple locations while reducing bandwidth requirements. Instead of transmitting raw video streams to centralized processing centers, edge nodes perform local analysis and transmit only relevant metadata or processed results, significantly reducing network overhead and associated costs.
Security and privacy considerations are inherently enhanced through edge computing integration, as sensitive visual data remains localized rather than being transmitted to external cloud services. This approach addresses regulatory compliance requirements and data sovereignty concerns while maintaining system performance and reliability.
Implementation strategies for edge computing integration involve careful consideration of workload partitioning between edge nodes and cloud resources. Critical real-time processing tasks are executed locally, while computationally intensive model training and system updates are managed through cloud connectivity, creating hybrid architectures that optimize both performance and resource utilization.
AI Hardware Optimization for Vision Applications
The optimization of AI hardware for machine vision applications represents a critical convergence of specialized computing architectures and real-time image processing demands. Modern vision systems require substantial computational throughput to handle high-resolution image streams, complex feature extraction algorithms, and real-time decision-making processes that traditional general-purpose processors cannot efficiently support.
Graphics Processing Units (GPUs) have emerged as the dominant hardware platform for vision applications due to their parallel processing capabilities. NVIDIA's Tesla and RTX series, along with AMD's Instinct lineup, provide thousands of cores optimized for matrix operations fundamental to convolutional neural networks. These architectures excel at simultaneous pixel processing and can achieve processing speeds exceeding 1000 frames per second for standard resolution inputs when properly optimized.
Field-Programmable Gate Arrays (FPGAs) offer another compelling approach for vision system acceleration. Intel's Arria and Stratix series, alongside Xilinx's Zynq and Kintex platforms, provide reconfigurable logic that can be tailored specifically for vision algorithms. FPGAs deliver deterministic latency performance and power efficiency advantages, making them particularly suitable for edge deployment scenarios where consistent response times are critical.
Application-Specific Integrated Circuits (ASICs) represent the pinnacle of hardware optimization for vision applications. Companies like Google with their Tensor Processing Units (TPUs) and Apple with their Neural Engine have demonstrated how custom silicon can achieve order-of-magnitude improvements in both performance and energy efficiency compared to general-purpose alternatives.
Emerging neuromorphic computing architectures, including Intel's Loihi and IBM's TrueNorth chips, introduce event-driven processing paradigms that align more closely with biological vision systems. These platforms show particular promise for dynamic vision sensor applications and continuous learning scenarios.
The integration of specialized memory architectures, including High Bandwidth Memory (HBM) and processing-in-memory technologies, addresses the critical bottleneck of data movement in vision systems. These innovations enable sustained high-throughput processing by minimizing the latency and energy costs associated with frequent memory access patterns typical in image processing workflows.
Graphics Processing Units (GPUs) have emerged as the dominant hardware platform for vision applications due to their parallel processing capabilities. NVIDIA's Tesla and RTX series, along with AMD's Instinct lineup, provide thousands of cores optimized for matrix operations fundamental to convolutional neural networks. These architectures excel at simultaneous pixel processing and can achieve processing speeds exceeding 1000 frames per second for standard resolution inputs when properly optimized.
Field-Programmable Gate Arrays (FPGAs) offer another compelling approach for vision system acceleration. Intel's Arria and Stratix series, alongside Xilinx's Zynq and Kintex platforms, provide reconfigurable logic that can be tailored specifically for vision algorithms. FPGAs deliver deterministic latency performance and power efficiency advantages, making them particularly suitable for edge deployment scenarios where consistent response times are critical.
Application-Specific Integrated Circuits (ASICs) represent the pinnacle of hardware optimization for vision applications. Companies like Google with their Tensor Processing Units (TPUs) and Apple with their Neural Engine have demonstrated how custom silicon can achieve order-of-magnitude improvements in both performance and energy efficiency compared to general-purpose alternatives.
Emerging neuromorphic computing architectures, including Intel's Loihi and IBM's TrueNorth chips, introduce event-driven processing paradigms that align more closely with biological vision systems. These platforms show particular promise for dynamic vision sensor applications and continuous learning scenarios.
The integration of specialized memory architectures, including High Bandwidth Memory (HBM) and processing-in-memory technologies, addresses the critical bottleneck of data movement in vision systems. These innovations enable sustained high-throughput processing by minimizing the latency and energy costs associated with frequent memory access patterns typical in image processing workflows.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!