

Graph-Constrained Reasoning for Efficient Data Mining Techniques
MAR 17, 20269 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
Graph-Constrained Data Mining Background and Objectives
Graph-constrained reasoning for efficient data mining represents a paradigm shift in how we approach complex data analysis challenges. Traditional data mining techniques often struggle with the inherent relational nature of modern datasets, where entities and their interconnections carry equal importance. The emergence of graph-based approaches addresses this limitation by explicitly modeling relationships as first-class citizens in the analytical process.
The historical development of this field traces back to early graph theory applications in the 1960s, evolving through social network analysis in the 1970s, and gaining momentum with the rise of web-scale data in the 2000s. The convergence of graph databases, machine learning, and distributed computing has created unprecedented opportunities for sophisticated reasoning over interconnected data structures.
Current technological evolution demonstrates a clear trajectory toward more sophisticated graph-constrained methodologies. The integration of knowledge graphs with machine learning models has enabled contextual reasoning that considers both local node properties and global structural patterns. This evolution reflects the growing recognition that many real-world problems are inherently relational and require analytical approaches that preserve and leverage these relationships.
The primary objective of graph-constrained reasoning in data mining centers on developing algorithms that can efficiently navigate and extract insights from complex relational structures while maintaining computational tractability. This involves creating methods that can simultaneously consider node attributes, edge properties, and topological constraints to identify meaningful patterns that would be invisible to traditional flat-data approaches.
A critical technical goal involves optimizing the balance between expressiveness and computational efficiency. Graph-constrained systems must handle increasingly large-scale networks while providing real-time or near-real-time analytical capabilities. This requires innovative approaches to graph partitioning, distributed processing, and approximate reasoning techniques that maintain analytical accuracy while achieving practical performance requirements.
The field aims to establish unified frameworks that can seamlessly integrate multiple types of constraints, including temporal dynamics, multi-layer relationships, and heterogeneous node types. These frameworks should support diverse analytical tasks ranging from pattern discovery and anomaly detection to predictive modeling and recommendation systems, all while respecting the underlying graph structure and domain-specific constraints that govern the data relationships.
The historical development of this field traces back to early graph theory applications in the 1960s, evolving through social network analysis in the 1970s, and gaining momentum with the rise of web-scale data in the 2000s. The convergence of graph databases, machine learning, and distributed computing has created unprecedented opportunities for sophisticated reasoning over interconnected data structures.
Current technological evolution demonstrates a clear trajectory toward more sophisticated graph-constrained methodologies. The integration of knowledge graphs with machine learning models has enabled contextual reasoning that considers both local node properties and global structural patterns. This evolution reflects the growing recognition that many real-world problems are inherently relational and require analytical approaches that preserve and leverage these relationships.
The primary objective of graph-constrained reasoning in data mining centers on developing algorithms that can efficiently navigate and extract insights from complex relational structures while maintaining computational tractability. This involves creating methods that can simultaneously consider node attributes, edge properties, and topological constraints to identify meaningful patterns that would be invisible to traditional flat-data approaches.
A critical technical goal involves optimizing the balance between expressiveness and computational efficiency. Graph-constrained systems must handle increasingly large-scale networks while providing real-time or near-real-time analytical capabilities. This requires innovative approaches to graph partitioning, distributed processing, and approximate reasoning techniques that maintain analytical accuracy while achieving practical performance requirements.
The field aims to establish unified frameworks that can seamlessly integrate multiple types of constraints, including temporal dynamics, multi-layer relationships, and heterogeneous node types. These frameworks should support diverse analytical tasks ranging from pattern discovery and anomaly detection to predictive modeling and recommendation systems, all while respecting the underlying graph structure and domain-specific constraints that govern the data relationships.
Market Demand for Efficient Graph-Based Data Mining Solutions
The global data mining market is experiencing unprecedented growth driven by the exponential increase in data generation across industries. Organizations are generating massive volumes of structured and unstructured data from diverse sources including social networks, IoT devices, financial transactions, and scientific research. Traditional data mining approaches struggle with the complexity and interconnected nature of modern datasets, creating a substantial demand for graph-based solutions that can effectively model and analyze relational data structures.
Enterprise adoption of graph-based data mining solutions is accelerating across multiple sectors. Financial institutions require sophisticated fraud detection systems that can identify complex transaction patterns and suspicious network behaviors. Social media platforms need advanced recommendation engines and community detection algorithms to enhance user engagement and content personalization. Healthcare organizations are seeking solutions for drug discovery, patient similarity analysis, and medical knowledge graph construction to improve treatment outcomes and research efficiency.
The telecommunications industry represents a significant market segment demanding graph-constrained reasoning capabilities for network optimization, customer churn prediction, and service quality management. Supply chain management has emerged as another critical application area where companies require real-time analysis of complex supplier networks, logistics optimization, and risk assessment across interconnected business relationships.
E-commerce and retail sectors are driving demand for graph-based customer behavior analysis, product recommendation systems, and market basket analysis. These applications require efficient processing of large-scale customer-product interaction graphs while maintaining real-time response capabilities for personalized shopping experiences.
The scientific research community, particularly in fields such as bioinformatics, chemistry, and materials science, requires specialized graph mining tools for molecular analysis, protein interaction studies, and compound discovery. Academic institutions and pharmaceutical companies are investing heavily in graph-based solutions for accelerating research and development processes.
Market growth is further fueled by the increasing adoption of knowledge graphs in enterprise search, semantic analysis, and artificial intelligence applications. Organizations are recognizing the value of graph-structured data representation for improving decision-making processes and extracting meaningful insights from complex datasets.
The demand for efficient graph-based data mining solutions is also driven by regulatory compliance requirements in industries such as banking, insurance, and healthcare, where organizations must analyze complex relationships and patterns to meet reporting and risk management obligations.
Enterprise adoption of graph-based data mining solutions is accelerating across multiple sectors. Financial institutions require sophisticated fraud detection systems that can identify complex transaction patterns and suspicious network behaviors. Social media platforms need advanced recommendation engines and community detection algorithms to enhance user engagement and content personalization. Healthcare organizations are seeking solutions for drug discovery, patient similarity analysis, and medical knowledge graph construction to improve treatment outcomes and research efficiency.
The telecommunications industry represents a significant market segment demanding graph-constrained reasoning capabilities for network optimization, customer churn prediction, and service quality management. Supply chain management has emerged as another critical application area where companies require real-time analysis of complex supplier networks, logistics optimization, and risk assessment across interconnected business relationships.
E-commerce and retail sectors are driving demand for graph-based customer behavior analysis, product recommendation systems, and market basket analysis. These applications require efficient processing of large-scale customer-product interaction graphs while maintaining real-time response capabilities for personalized shopping experiences.
The scientific research community, particularly in fields such as bioinformatics, chemistry, and materials science, requires specialized graph mining tools for molecular analysis, protein interaction studies, and compound discovery. Academic institutions and pharmaceutical companies are investing heavily in graph-based solutions for accelerating research and development processes.
Market growth is further fueled by the increasing adoption of knowledge graphs in enterprise search, semantic analysis, and artificial intelligence applications. Organizations are recognizing the value of graph-structured data representation for improving decision-making processes and extracting meaningful insights from complex datasets.
The demand for efficient graph-based data mining solutions is also driven by regulatory compliance requirements in industries such as banking, insurance, and healthcare, where organizations must analyze complex relationships and patterns to meet reporting and risk management obligations.
Current State and Challenges in Graph-Constrained Reasoning
Graph-constrained reasoning has emerged as a critical paradigm in modern data mining, leveraging structural relationships within data to enhance analytical capabilities. Currently, the field demonstrates significant advancement in integrating graph neural networks with traditional reasoning mechanisms, enabling more sophisticated pattern recognition and knowledge extraction from complex datasets. Leading research institutions and technology companies have developed various frameworks that combine graph topology with logical inference, creating hybrid systems capable of handling both structured and unstructured data mining tasks.
The technological landscape reveals substantial progress in scalable graph processing architectures, with distributed computing frameworks specifically designed for graph-constrained operations. Contemporary implementations utilize advanced algorithms such as graph attention networks, message-passing neural networks, and graph convolutional approaches to maintain reasoning consistency while processing large-scale datasets. These systems demonstrate improved performance in domains including social network analysis, biological pathway discovery, and recommendation systems.
However, significant technical challenges persist in achieving optimal efficiency and accuracy. Computational complexity remains a primary constraint, as graph-constrained reasoning operations often exhibit exponential time complexity when dealing with dense graph structures or complex reasoning chains. Memory management presents another critical bottleneck, particularly when processing dynamic graphs that require real-time updates while maintaining reasoning consistency across distributed computing environments.
Scalability limitations become pronounced when transitioning from laboratory environments to production systems handling millions of nodes and edges. Current solutions struggle with load balancing across heterogeneous computing resources, leading to performance degradation and increased latency. The integration of reasoning constraints with graph traversal algorithms introduces additional overhead that impacts overall system throughput.
Quality assurance and validation represent ongoing challenges, as graph-constrained reasoning systems require sophisticated mechanisms to ensure logical consistency and prevent reasoning loops. Existing validation frameworks lack standardized benchmarks for evaluating reasoning accuracy across different graph topologies and constraint types. The absence of comprehensive testing methodologies hampers the development of robust, production-ready systems.
Interoperability issues further complicate deployment scenarios, as different graph databases and reasoning engines employ incompatible data formats and query languages. This fragmentation limits the adoption of graph-constrained reasoning techniques across diverse organizational infrastructures and constrains the development of unified solutions that can leverage multiple data sources effectively.
The technological landscape reveals substantial progress in scalable graph processing architectures, with distributed computing frameworks specifically designed for graph-constrained operations. Contemporary implementations utilize advanced algorithms such as graph attention networks, message-passing neural networks, and graph convolutional approaches to maintain reasoning consistency while processing large-scale datasets. These systems demonstrate improved performance in domains including social network analysis, biological pathway discovery, and recommendation systems.
However, significant technical challenges persist in achieving optimal efficiency and accuracy. Computational complexity remains a primary constraint, as graph-constrained reasoning operations often exhibit exponential time complexity when dealing with dense graph structures or complex reasoning chains. Memory management presents another critical bottleneck, particularly when processing dynamic graphs that require real-time updates while maintaining reasoning consistency across distributed computing environments.
Scalability limitations become pronounced when transitioning from laboratory environments to production systems handling millions of nodes and edges. Current solutions struggle with load balancing across heterogeneous computing resources, leading to performance degradation and increased latency. The integration of reasoning constraints with graph traversal algorithms introduces additional overhead that impacts overall system throughput.
Quality assurance and validation represent ongoing challenges, as graph-constrained reasoning systems require sophisticated mechanisms to ensure logical consistency and prevent reasoning loops. Existing validation frameworks lack standardized benchmarks for evaluating reasoning accuracy across different graph topologies and constraint types. The absence of comprehensive testing methodologies hampers the development of robust, production-ready systems.
Interoperability issues further complicate deployment scenarios, as different graph databases and reasoning engines employ incompatible data formats and query languages. This fragmentation limits the adoption of graph-constrained reasoning techniques across diverse organizational infrastructures and constrains the development of unified solutions that can leverage multiple data sources effectively.
Existing Graph-Constrained Data Mining Approaches
01 Graph pruning and simplification techniques
Methods for improving reasoning efficiency by reducing graph complexity through pruning irrelevant nodes and edges, simplifying graph structures, and removing redundant connections. These techniques help minimize computational overhead while preserving essential graph properties and relationships necessary for accurate reasoning.- Graph pruning and simplification techniques: Methods for improving reasoning efficiency by reducing graph complexity through pruning irrelevant nodes and edges, simplifying graph structures, and removing redundant connections. These techniques help minimize computational overhead while preserving essential graph properties and relationships necessary for accurate reasoning.
- Constraint-based graph traversal optimization: Approaches that utilize predefined constraints to guide graph traversal and limit search space during reasoning processes. These methods employ constraint propagation, boundary conditions, and rule-based filtering to reduce the number of paths explored, thereby accelerating inference and decision-making operations on graph structures.
- Parallel and distributed graph processing: Techniques for enhancing reasoning efficiency through parallel computation and distributed processing of graph data. These methods partition graphs into subgraphs, enable concurrent processing across multiple processors or nodes, and implement load balancing strategies to achieve faster reasoning results on large-scale graph structures.
- Graph neural network acceleration: Methods for improving reasoning efficiency using optimized graph neural network architectures and inference acceleration techniques. These approaches include model compression, layer optimization, attention mechanisms, and hardware acceleration to speed up graph-based learning and reasoning tasks while maintaining accuracy.
- Incremental and adaptive graph reasoning: Strategies that enable efficient reasoning through incremental updates and adaptive processing of dynamic graphs. These methods avoid complete graph recomputation by processing only changed portions, implementing caching mechanisms, and dynamically adjusting reasoning strategies based on graph characteristics and query patterns.
02 Constraint-based graph traversal optimization
Approaches that utilize predefined constraints to guide and optimize graph traversal algorithms, reducing the search space and improving query response times. These methods incorporate domain-specific rules and constraints to eliminate unnecessary paths and focus computational resources on relevant graph regions during reasoning operations.Expand Specific Solutions03 Parallel and distributed graph processing
Techniques for enhancing reasoning efficiency through parallel computation and distributed processing of graph structures. These methods partition graphs across multiple processing units, enable concurrent execution of reasoning tasks, and implement load balancing strategies to maximize throughput and minimize latency in large-scale graph reasoning applications.Expand Specific Solutions04 Graph embedding and representation learning
Methods that transform graph structures into efficient vector representations to accelerate reasoning operations. These approaches use neural networks and machine learning techniques to encode graph topology and node features into low-dimensional embeddings, enabling faster similarity computations and inference while maintaining semantic relationships.Expand Specific Solutions05 Adaptive graph indexing and caching strategies
Systems that implement intelligent indexing structures and caching mechanisms to improve graph query performance. These solutions create optimized index structures for frequently accessed graph patterns, maintain cache hierarchies for intermediate reasoning results, and dynamically adjust storage strategies based on query patterns and access frequencies.Expand Specific Solutions
Key Players in Graph Mining and Reasoning Technologies
The graph-constrained reasoning for efficient data mining techniques market represents an emerging technological frontier currently in its early-to-mid development stage. The competitive landscape spans diverse sectors including established technology giants like IBM, Microsoft, and Oracle alongside specialized players such as NEC Laboratories and emerging companies like DataWalk SA. Market size remains nascent but shows significant growth potential driven by increasing demand for sophisticated data analytics solutions. Technology maturity varies considerably across participants - while IBM and Microsoft leverage extensive AI/ML capabilities and cloud infrastructure, companies like Alipay and Visa International focus on financial data applications, and academic institutions including MIT, University of Tokyo, and Carnegie Mellon University contribute foundational research. The fragmented nature suggests the technology is still consolidating, with no clear dominant player yet established in this specialized data mining segment.
International Business Machines Corp.
Technical Solution: IBM has developed advanced graph-constrained reasoning systems through their Watson platform and IBM Research initiatives. Their approach integrates knowledge graphs with machine learning algorithms to enable efficient data mining across large-scale datasets. The company leverages graph neural networks (GNNs) combined with constraint satisfaction techniques to optimize query processing and pattern discovery. IBM's solution incorporates semantic reasoning capabilities that can handle complex relationships within structured and unstructured data, enabling more accurate and contextually relevant mining results. Their graph-constrained framework supports real-time analytics and can scale to handle enterprise-level data volumes while maintaining computational efficiency through optimized graph traversal algorithms.
Strengths: Mature enterprise solutions with proven scalability and robust semantic reasoning capabilities. Weaknesses: High implementation complexity and significant computational resource requirements for large-scale deployments.
Microsoft Technology Licensing LLC
Technical Solution: Microsoft has implemented graph-constrained reasoning through their Azure Cognitive Services and Microsoft Graph platform. Their approach utilizes advanced graph algorithms integrated with Azure's cloud infrastructure to provide scalable data mining solutions. The system employs constraint-based optimization techniques that leverage graph topology to improve mining efficiency and reduce computational overhead. Microsoft's solution incorporates machine learning models that can adapt to different graph structures and constraint types, enabling flexible deployment across various domains. Their framework supports distributed processing and can handle heterogeneous data sources while maintaining consistency through graph-based constraint enforcement mechanisms.
Strengths: Strong cloud integration with excellent scalability and comprehensive developer tools. Weaknesses: Dependency on Azure ecosystem and potential vendor lock-in concerns for enterprise customers.
Core Innovations in Graph Reasoning Optimization
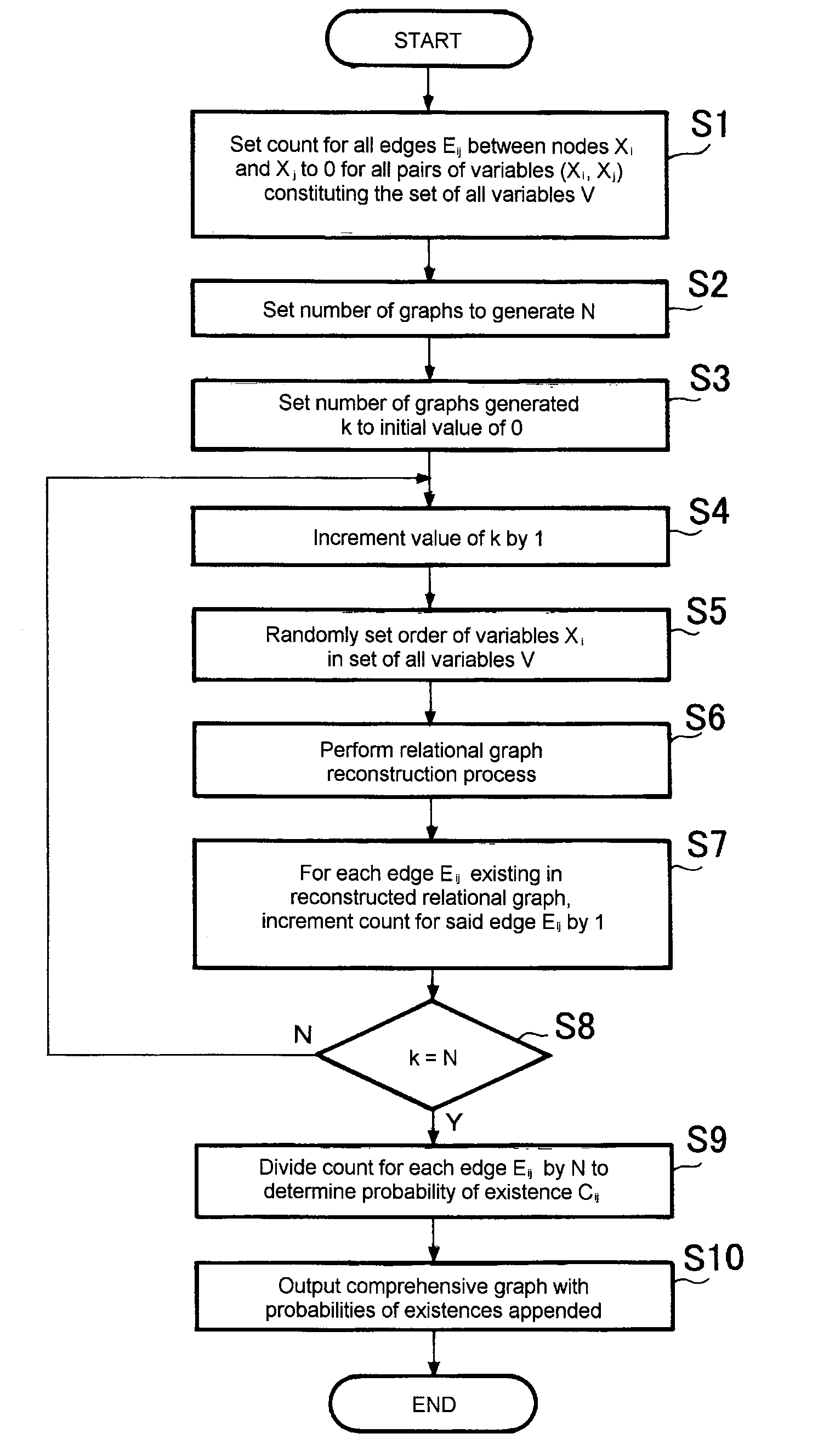
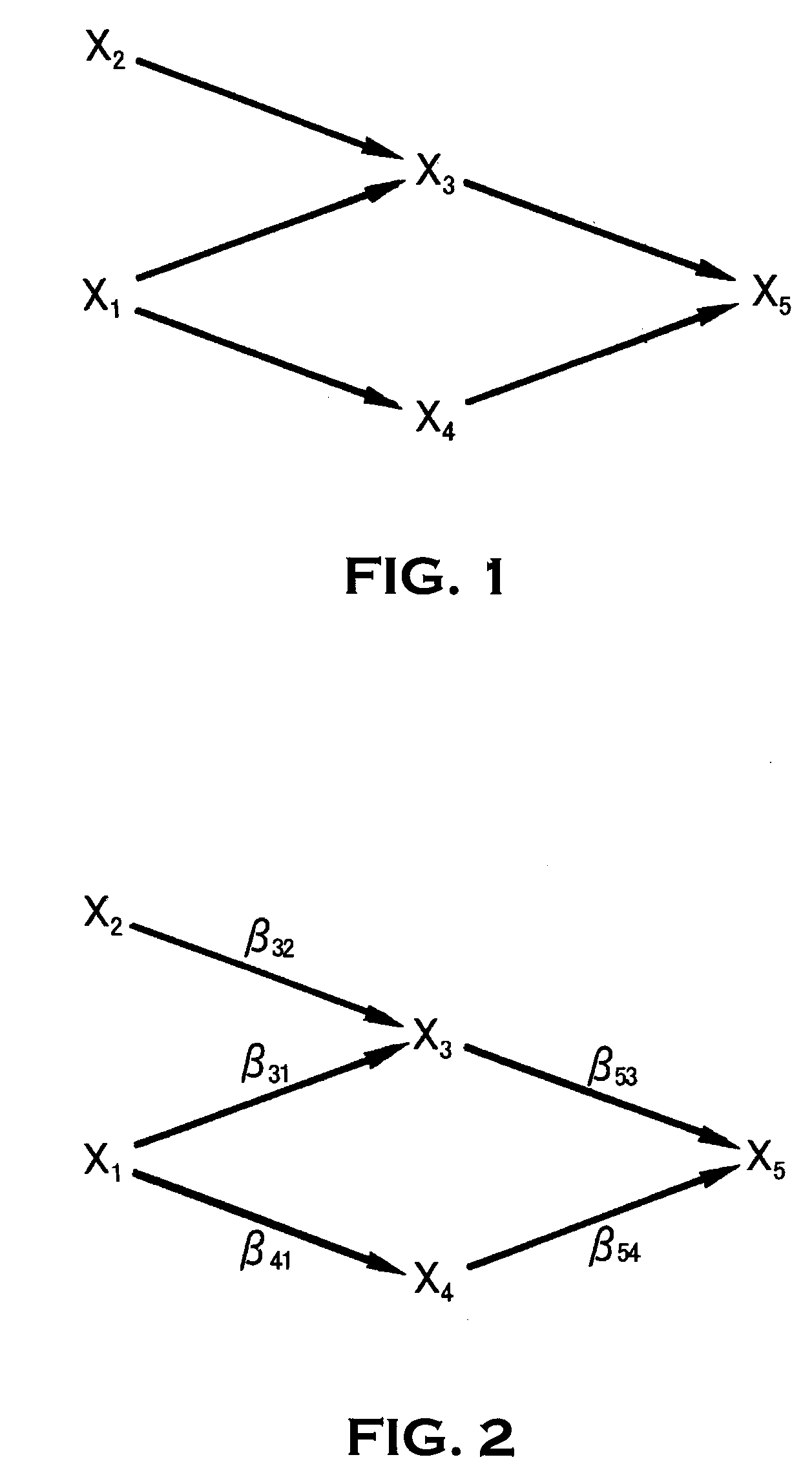
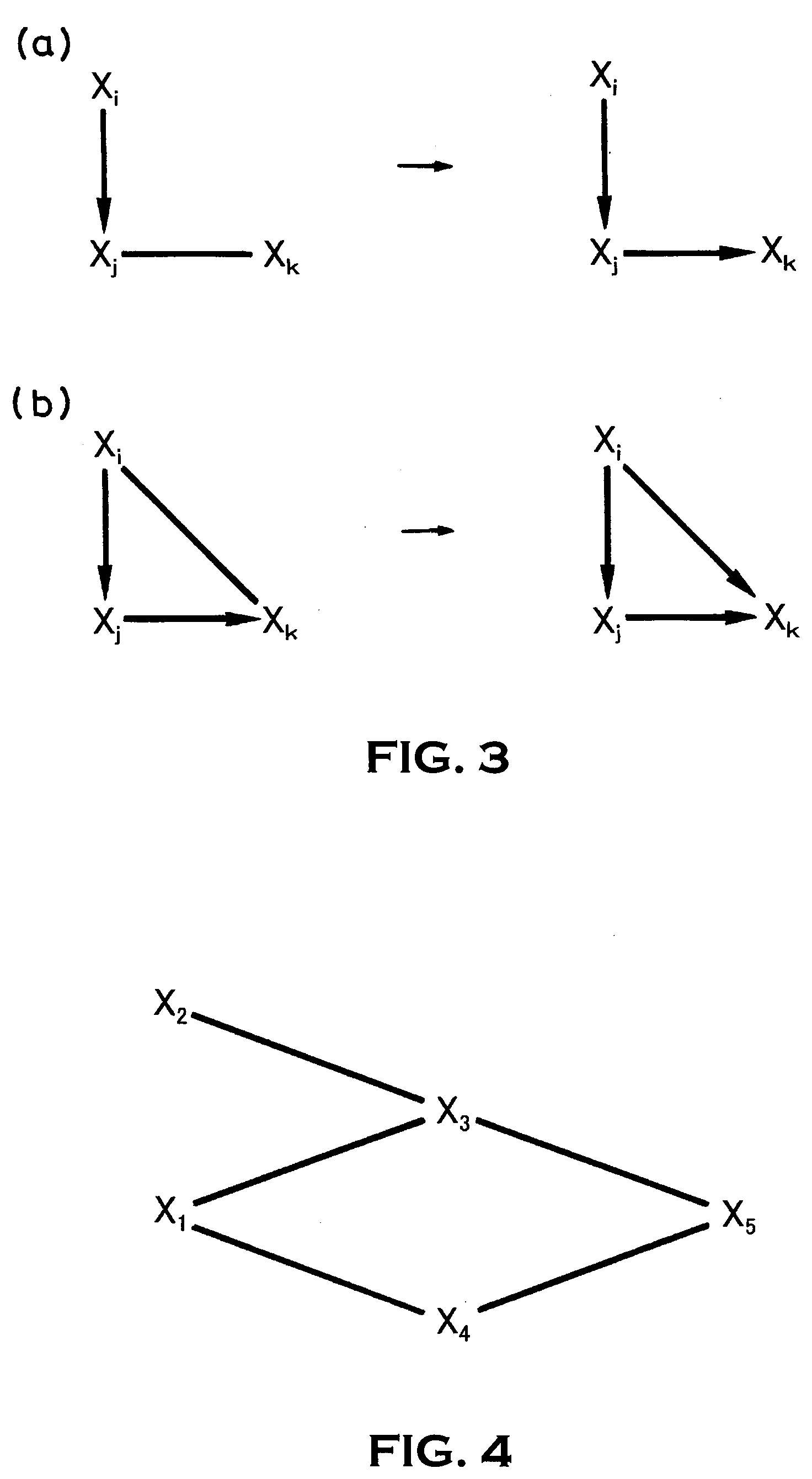
Graph generating method, graph generating program and data mining system
PatentInactiveUS20070203870A1
Innovation
- A graph generating method and program that establish nodes for variables, determine conditional independence, convert undirected edges to arrows based on V-structures and orientation rules, and calculate an inverse correlation matrix to avoid errors, while generating multiple graphs to calculate edge probabilities and output comprehensive graphs showing relationship probabilities.

Dimensional Reduction Mechanisms for Representing Massive Communication Network Graphs for Structural Queries
PatentInactiveUS20110074786A1
Innovation
- A method for dimensionality reduction of massive communication network graphs using a contraction-based methodology to transform the graphs into a smaller, representative form, allowing for efficient indexing and retrieval while maintaining key characteristics, enabling structural queries.




Privacy and Security Considerations in Graph Data Mining
Privacy and security considerations represent critical challenges in graph-constrained reasoning systems for data mining, as these techniques often process sensitive relational information that can reveal personal, organizational, or strategic insights. Graph structures inherently contain rich contextual information through node attributes and edge relationships, making traditional anonymization approaches insufficient for protecting individual privacy while maintaining analytical utility.
The primary privacy risks in graph data mining stem from structural inference attacks, where adversaries can exploit graph topology to re-identify anonymized nodes or infer sensitive attributes. Graph-constrained reasoning amplifies these concerns by leveraging sophisticated algorithms that can detect subtle patterns and correlations across interconnected data points, potentially exposing information that simpler analytical methods would miss.
Differential privacy has emerged as a fundamental approach for protecting graph data, though implementing it effectively requires careful consideration of the graph's structural properties. Adding calibrated noise to graph statistics, edge weights, or node features can preserve privacy while enabling meaningful analysis, but the challenge lies in balancing privacy guarantees with the accuracy requirements of reasoning algorithms.
Secure multi-party computation protocols offer another avenue for privacy-preserving graph mining, enabling multiple parties to collaboratively analyze distributed graph data without revealing their individual datasets. These approaches are particularly relevant for cross-organizational data mining initiatives where competitive or regulatory constraints prevent direct data sharing.
Homomorphic encryption techniques allow computation on encrypted graph data, though current implementations face significant computational overhead challenges when applied to complex graph reasoning algorithms. Recent advances in partially homomorphic schemes show promise for specific graph mining operations while maintaining acceptable performance levels.
Access control mechanisms must address the dynamic nature of graph-constrained reasoning, where query results can inadvertently expose sensitive information through inference chains. Implementing fine-grained permission systems that consider both direct data access and potential inference paths requires sophisticated policy frameworks that can adapt to evolving analytical requirements while maintaining security boundaries.
The primary privacy risks in graph data mining stem from structural inference attacks, where adversaries can exploit graph topology to re-identify anonymized nodes or infer sensitive attributes. Graph-constrained reasoning amplifies these concerns by leveraging sophisticated algorithms that can detect subtle patterns and correlations across interconnected data points, potentially exposing information that simpler analytical methods would miss.
Differential privacy has emerged as a fundamental approach for protecting graph data, though implementing it effectively requires careful consideration of the graph's structural properties. Adding calibrated noise to graph statistics, edge weights, or node features can preserve privacy while enabling meaningful analysis, but the challenge lies in balancing privacy guarantees with the accuracy requirements of reasoning algorithms.
Secure multi-party computation protocols offer another avenue for privacy-preserving graph mining, enabling multiple parties to collaboratively analyze distributed graph data without revealing their individual datasets. These approaches are particularly relevant for cross-organizational data mining initiatives where competitive or regulatory constraints prevent direct data sharing.
Homomorphic encryption techniques allow computation on encrypted graph data, though current implementations face significant computational overhead challenges when applied to complex graph reasoning algorithms. Recent advances in partially homomorphic schemes show promise for specific graph mining operations while maintaining acceptable performance levels.
Access control mechanisms must address the dynamic nature of graph-constrained reasoning, where query results can inadvertently expose sensitive information through inference chains. Implementing fine-grained permission systems that consider both direct data access and potential inference paths requires sophisticated policy frameworks that can adapt to evolving analytical requirements while maintaining security boundaries.
Computational Complexity and Performance Optimization
Graph-constrained reasoning in data mining presents significant computational challenges that directly impact system performance and scalability. The inherent complexity stems from the need to process large-scale graph structures while maintaining reasoning accuracy, creating a fundamental trade-off between computational efficiency and analytical depth. Traditional graph algorithms often exhibit polynomial or exponential time complexities, making them unsuitable for real-time applications or large datasets.
The computational complexity of graph-constrained reasoning varies significantly based on the underlying graph topology and reasoning mechanisms employed. Dense graphs with high connectivity require O(n²) or higher complexity for basic traversal operations, while sparse graphs can achieve near-linear performance. Advanced reasoning tasks, such as subgraph isomorphism or pattern matching, introduce additional complexity layers that can escalate to NP-complete problems, necessitating sophisticated optimization strategies.
Performance optimization in this domain focuses on several key areas: algorithmic efficiency, memory management, and parallel processing capabilities. Graph partitioning techniques enable distributed processing by decomposing large graphs into manageable subcomponents, reducing overall computational load. Indexing strategies, including graph-specific data structures like adjacency lists and compressed sparse representations, significantly improve query response times and memory utilization.
Modern optimization approaches leverage approximation algorithms and heuristic methods to achieve acceptable performance levels while maintaining reasoning quality. Techniques such as graph sampling, pruning strategies, and incremental processing allow systems to handle dynamic graph updates efficiently. Additionally, hardware acceleration through GPU computing and specialized graph processing units provides substantial performance improvements for parallel graph operations.
The integration of machine learning models with graph-constrained reasoning introduces additional optimization considerations. Model inference overhead, feature extraction complexity, and training data preparation all contribute to the overall computational burden. Optimization strategies must balance model accuracy with inference speed, often requiring careful selection of graph neural network architectures and training methodologies to achieve optimal performance in production environments.
The computational complexity of graph-constrained reasoning varies significantly based on the underlying graph topology and reasoning mechanisms employed. Dense graphs with high connectivity require O(n²) or higher complexity for basic traversal operations, while sparse graphs can achieve near-linear performance. Advanced reasoning tasks, such as subgraph isomorphism or pattern matching, introduce additional complexity layers that can escalate to NP-complete problems, necessitating sophisticated optimization strategies.
Performance optimization in this domain focuses on several key areas: algorithmic efficiency, memory management, and parallel processing capabilities. Graph partitioning techniques enable distributed processing by decomposing large graphs into manageable subcomponents, reducing overall computational load. Indexing strategies, including graph-specific data structures like adjacency lists and compressed sparse representations, significantly improve query response times and memory utilization.
Modern optimization approaches leverage approximation algorithms and heuristic methods to achieve acceptable performance levels while maintaining reasoning quality. Techniques such as graph sampling, pruning strategies, and incremental processing allow systems to handle dynamic graph updates efficiently. Additionally, hardware acceleration through GPU computing and specialized graph processing units provides substantial performance improvements for parallel graph operations.
The integration of machine learning models with graph-constrained reasoning introduces additional optimization considerations. Model inference overhead, feature extraction complexity, and training data preparation all contribute to the overall computational burden. Optimization strategies must balance model accuracy with inference speed, often requiring careful selection of graph neural network architectures and training methodologies to achieve optimal performance in production environments.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!